Before you set up your environment, perform the prerequisite tasks.
Complete the following tasks:
•Verify that you have the correct privileges in your organization.
•Learn how the Secure Agent and the self-service cluster access resources on your cloud platform.
Verify privileges in your organization
Verify that you are assigned the correct privileges for advanced configurations in your organization.
Privileges for advanced configurations provide you varying access levels to the Advanced Clusters page in Administrator as well as Monitor.
Make sure that you have the read permissions to view the advanced configurations and monitor the self-service clusters.
Learn about resource access
To process data, the Secure Agent and the self-service cluster access the resources that are part of a job, including resources on the cloud platform, source and target data, and staging and log locations.
The agent and the cluster access resources to perform the following tasks:
•Design a mapping.
•Connect to a self-service cluster.
•Run a job, including a data preview job.
•Poll logs.
Designing a mapping
When you design a mapping, the Secure Agent accesses sources and targets so that you can read and write data. For example, when you add a Source transformation to a mapping, the Secure Agent accesses the source to display the fields that you can use in the rest of the mapping. The Secure Agent also accesses the source when you preview data.
To access a source or target, the Secure Agent uses the connection properties. For example, the Secure Agent might use the user name and password that you provide in the connection properties to access a database.
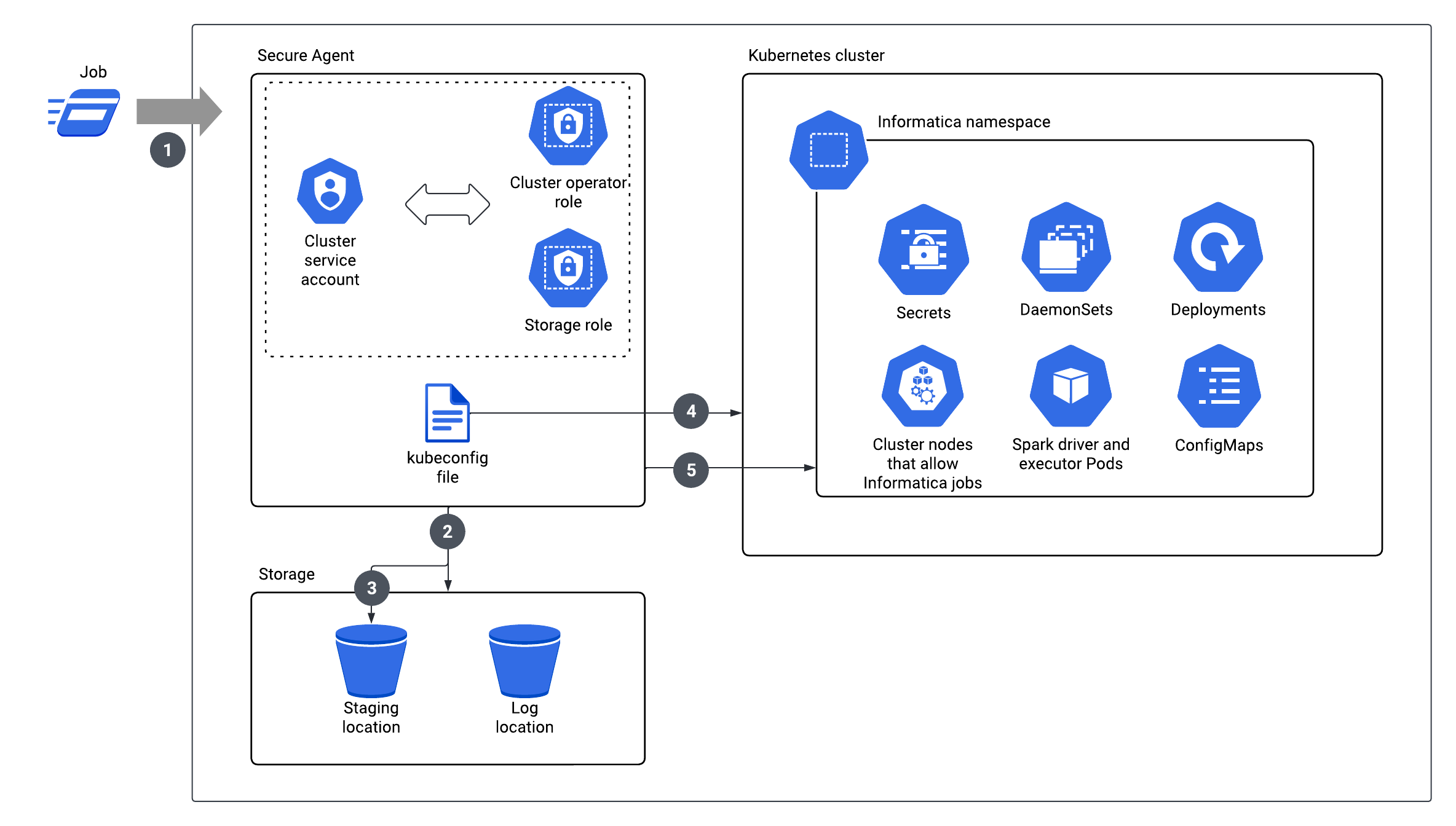
Connecting to a self-service cluster
To use a Kubernetes cluster as a self-service cluster, the Secure Agent connects to the Kubernetes cluster and creates Informatica-specific Kubernetes resources within a particular namespace in the cluster.
The following image shows how the Secure Agent interacts with the Kubernetes cluster:
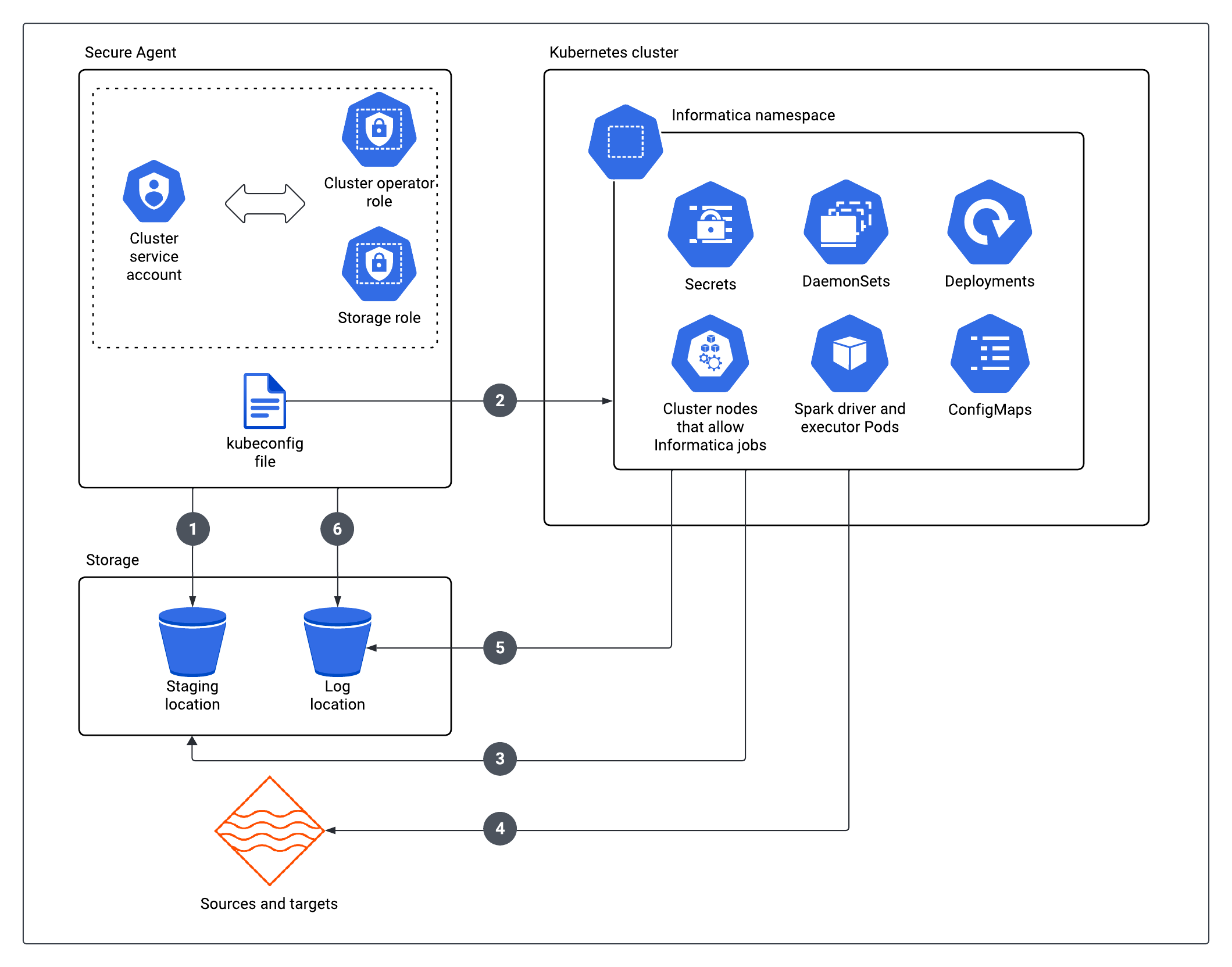
Running a job
To run a job, the Secure Agent and the resources in the Informatica-specific namespace of the Kubernetes cluster access the staging and log locations as well as the sources and targets in the job. To process the data in the job, Informatica uses the nodes in the Kubernetes cluster that you assign to Informatica through node labels and tolerations.
When a developer runs a job from a service like Data Integration, the pending Kubernetes Pods from the Spark job can also trigger the Kubernetes cluster to scale out through the Cluster AutoScaler that you deploy on the Kubernetes cluster.
The following image shows how the Secure Agent and the self-service cluster access resources to run a job:
Polling logs
When you use Monitor, the Secure Agent accesses the log location to poll logs. To poll logs from the log location, the Secure Agent uses the storage role.