When you create a mapping, you can configure a Source or Target transformation to represent an Amazon Redshift V2 object. Additionally, you can configure Lookups for mappings and mapping tasks.
Consider the following rules and guidelines when you configure Amazon Redshift V2 objects in mappings:
•If you use a simple filter in a mapping, you must specify the filter condition in the YYYY-MM-DD HH24:MI:SS.MS format. If you use an advanced filter, you must specify the filter condition in the date_time_fix.f_timestamp < to_date('2012-05-24 09:13:57','YYYY-MM-DD HH24:MI:SS.MS') format.
•When you define queries for sources or targets and the table names or the column names contain special characters, you must enclose the table names or column names in double quotes.
•To write special characters in the source column names to the target, you can configure a Target transformation in the mapping to create a new target at runtime. Enable the Exact Source Field Names in Target property in the Create New at Runtime window. You cannot view this checkbox if you select an existing object. This feature does not apply for mappings in advanced mode.
•If the Amazon Redshift table or schema name contains a forward slash (/), the mapping fails.
•When you select an Amazon Redshift V2 object that contains a boolean data type and preview the data, the value of the boolean data type appears truncated and displays only the first letter.
•If a field contains a Date or Datetime data type, the Data Preview tab displays the field value with an offset of +4 hours.
•When you read or write data using a mapping in advanced mode, the source table name must not contain unicode or special characters.
Amazon Redshift V2 sources in mappings
In a mapping, you can configure a Source transformation to represent an Amazon Redshift V2 source.
The following table describes the Amazon Redshift V2 source properties that you can configure in a Source transformation:
Property
Description
Connection
Name of the source connection. Select a source connection, or click New Parameter to define a new parameter for the source connection.
Source type
Type of the source object.
Select any of the following source object:
- Single Object
- Multiple Objects. You can use implicit joins and advanced relationships with multiple objects.
- Query. When you select the source type as query, you must map all the fields selected in the query in the Field Mapping tab.
- Parameter
Note:
You cannot override the source query object and multiple objects at runtime using parameter files in a mapping.
When you select the source type as query, the boolean values are written as 0 or false to the target.
The query that you specify must not end with a semicolon (;).
Object
Name of the source object.
You can select single or multiple source objects.
Parameter
Select an existing parameter for the source object or click New Parameter to define a new parameter for the source object. The Parameter property appears only if you select Parameter as the source type. If you want to overwrite the parameter at runtime, select the Overwrite Parameter option.
Filter
Filters records based on the filter condition.
You can specify a simple filter or an advanced filter.
Sort
Sorts records based on the conditions you specify. You can specify the following sort conditions:
- Not parameterized. Select the fields and type of sorting to use.
- Parameterized. Use a parameter to specify the sort option.
The following table describes the Amazon Redshift V2 advanced source properties that you can configure in a Source transformation:
Property
Description
Read Mode
Specifies the read mode to read data from the Amazon Redshift source.
You can select one of the following read modes:
- Direct1. Reads data directly from the Amazon Redshift source without staging the data in Amazon S3.
- Staging. Reads data from the Amazon Redshift source by staging the data in the S3 bucket.
Default is Staging.
Fetch Size1
Determines the number of rows to read in one resultant set from Amazon Redshift. Applies only when you select the Direct read mode.
Default is 10000.
Note:
If you specify fetch size 0 or if you don't specify a fetch size, the entire data set is read directly at the same time than in batches.
S3 Bucket Name*
Amazon S3 bucket name for staging the data.
You can also specify the bucket name with the folder path. If you provide an Amazon S3 bucket name that is in a different region than the Amazon Redshift cluster, you must configure the REGION attribute in the Unload command options.
Enable Compression*
Compresses the staging files into the Amazon S3 staging directory.
The task performance improves when the Secure Agent compresses the staging files. Default is selected.
Staging Directory Location1*
Location of the local staging directory.
When you run a task in Secure Agent runtime environment, specify a directory path that is available on the corresponding Secure Agent machine in the runtime environment.
Specify the directory path in the following manner: <staging directory>
For example, C:\Temp. Ensure that you have the write permissions on the directory.
Unload Options*
Unload command options.
Add options to the Unload command to extract data from Amazon Redshift and create staging files on Amazon S3. Provide an Amazon Redshift Role Amazon Resource Name (ARN).
Specify a directory on the machine that hosts the Secure Agent.
Note:
If you do not add the options to the Unload command manually, the Secure Agent uses the default values.
Treat NULL Value as NULL*
Retains the null values when you read data from Amazon Redshift.
Encryption Type*
Encrypts the data in the Amazon S3 staging directory.
You can select the following encryption types:
- None
- SSE-S3
- SSE-KMS
You cannot use CSE-SMK encryption type for Amazon Redshift V2 Connector.
Default is None.
Download S3 Files in Multiple Parts1*
Downloads large Amazon S3 objects in multiple parts.
When the file size of an Amazon S3 object is greater than 8 MB, you can choose to download the object in multiple parts in parallel.
Default is 5 MB.
Multipart Download Threshold Size1*
The maximum threshold size to download an Amazon S3 object in multiple parts.
Default is 5 MB.
Schema Name
Overrides the default schema name.
Note:
You cannot configure a custom query when you use the schema name.
Source Table Name
Overrides the default source table name.
Ensure that the metadata and column order in the override table match those in the source table imported during design time.
Note:
When you select the source type as
Multiple Objects
or
Query
, you cannot use the
Source Table Name
option.
Pre-SQL
The pre-SQL commands to run a query before you read data from Amazon Redshift. You can also use the UNLOAD or COPY command. The command you specify here is processed as a plain text.
Post-SQL
The post-SQL commands to run a query after you write data to Amazon Redshift. You can also use the UNLOAD or COPY command. The command you specify here is processed as a plain text.
Select Distinct
Selects unique values.
The Secure Agent includes a SELECT DISTINCT statement if you choose this option. Amazon Redshift ignores trailing spaces. Therefore, the Secure Agent might extract fewer rows than expected.
Note:
If you select the source type as query or use the
SQL Query
property and select the
Select Distinct
option, the Secure Agent ignores the
Select Distinct
option.
SQL Query
Overrides the default SQL query.
Enclose column names in double quotes. The SQL query is case sensitive. Specify an SQL statement supported by the Amazon Redshift database.
When you specify the columns in the SQL query, ensure that the column name in the query matches the source column name in the mapping.
Temporary Credential Duration
The time duration during which an IAM user can use the dynamically generated temporarily credentials to access the AWS resource. Enter the time duration in seconds.
Default is 900 seconds.
If you require more than 900 seconds, you can set the time duration up to a maximum of 12 hours in the AWS console and then enter the same time duration in this property.
Tracing Level
Use the verbose tracing level to get the amount of detail that appears in the log for the Source transformation.
1Does not apply to mappings in advanced mode.
*Does not apply to direct read mode.
Rules and guidelines for reading data
You need to follow some rules and guidelines for the read operation.
Direct read mode
Consider the following rules and guidelines when you read directly from an Amazon Redshift source:
•The order of data written to the target in the direct read mode is different from the order of data written after Amazon S3 staging.
•The precision values are rounded-off to the 6th precision for real data types and to the 14th precision for double data types.
•NULL values in char and varchar data types are written to the target without quotes.
•Trailing spaces in the char data type columns appear with trailing spaces in the target. In comparison, the trailing spaces are truncated when you set the source with staging mode.
Filter using IS NULL or IS NOT NULL operators
When you convert a simple filter condition with the IS NULL or IS NOT NULL operators to an advanced filter, these operators are converted into SQL functions and the resultant query fails. To avoid this issue when you use these operators, you need to use the Amazon Redshift compatible syntax in the advanced filter condition.
Rules and guidelines for configuring SQL query
Consider the following rules and guidelines when you configure an SQL query:
•When you select the source type as Query, you can override a SQL query over a custom query by setting the flag precedenceToSQLOverrideOverCustomQuery=True in the JVM option. Ensure that the number of columns in the overridden SQL query is same as the custom query.
•When you run a mapping in advanced mode and define a SQL query with alldatatypes, the target columns with the boolean data type appear as NULL.
•When you select individual columns but not all the columns in an SQL query in a mapping in advanced mode, the values are written as NULL to the Redshift target.
•When you use a parameterized query source type in a mapping to read from multiple tables, and you configure a join for one or more tables that have the same column names, the mapping fails.
For example, see the following SQL query that involves a full outer join between two tables EMPLOYEE and DEPARTMENT that are part of the SALES.PUBLIC schema, where two columns have the same name, CITY:
SELECT EMP_ID, NAME, CITY, DEPT_ID, DEPT_NAME, CITY FROM SALES.PUBLIC.EMPLOYEE FULL OUTER JOIN SALES.PUBLIC.DEPARTMENT ON EMP_ID = DEPT_ID
To distinguish the conflicting column names, add aliases that the database can refer to while joining the tables:
SELECT e.EMP_ID, e.NAME, e.CITY as ecity,d.DEPT_ID, d.DEPT_NAME, d.CITY as dcity FROM SALES.PUBLIC.EMPLOYEE e FULL OUTER JOIN SALES.PUBLIC.DEPARTMENT d ON e.EMP_ID = d.DEPT_ID
Adding multiple source objects
When you create a Source transformation, you can select Amazon Redshift V2 multiple object as the source type and then configure a join to combine the tables. You can define a relationship condition or a query to join the tables.
1In the Source transformation, click the Source Type as Multiple Objects.
2From the Actions menu, click Add Source Object.
3Select the source object that you want to add from the displayed list.
4Click OK.
5From the Related Objects Actions menu, select Advanced Relationship:
6In the Advanced Relationship window, you can click Add Object to add more objects.
7Click OK.
8Set your own conditions or specify a query to define the relationship between the tables:
Note:
When you configure a join expression, select the fields and define a join condition or a query syntax. To join two tables, you can specify a simple condition. For example,
employee.department=dept.id
. To join more than two tables, you must specify the complete query. For example,
<schema_name>.<table_name1> LEFT OUTER JOIN <schema_name>.<table_name2> ON <schema_name>.<table_name1>.<column_name1>=<schema_name>.<table_name2>.<column_name2>
9Click OK.
The following image shows an example of an advanced join condition defined between the Amazon Redshift V2 tables:
Rules and guidelines for adding multiple source objects
Consider the following rules and guidelines when you add multiple source objects:
•You cannot configure partitioning when you use the advanced relationship option.
•You must specify double quotes for the table name when you use a reserved word for the table name and the column name.
•You cannot use a self join when you add multiple source objects.
•When you use special characters in column names for an advanced relationship, the query formed is not correct and the mapping task fails.
•When you click Add Object to add more objects in the Advanced Relationship window, the table might not load or take a lot of time to load. Import the object again.
•You cannot search for a schema when you add a related source object. You must scroll down and manually select the schema.
•You can use the full outer-join condition only with the =, ,, and AND operators.
•When you use the advanced relationship option and specify the join queries with the schema name override, the mapping fails. The mapping fails with the following join queries:
- inner join
- left outer-join
- right outer-join
- full outer-join
- cross join
•When you override the schema name and configure an advanced filter on a related source object, you must specify the schema name in the filter condition. Use the following syntax for the filter condition:
public.alldatatypes_src.f_smallint=1
•When you override the schema name and configure an advanced filter on a related source object, the Secure Agent applies the advanced filter only on the parent object and not on the related source object.
•When you select parent and child objects that have a primary key and foreign key relationship, and the foreign key of the related object is also a primary key in the table, the mapping task fails when you create a target.
•When you select the Multiple Objects source type, add a source object, for example, emp, and define a primary key and foreign key relationship on different columns, for example, emp.id and dept.d_id, the mapping fails with the following error:
[FATAL] Unload/Copy command failed with error: Invalid operation: column emp.d_id does not exist.
The Select Related Objects list shows the join condition for the dept related object as emp.d_id=dept.d_id, even though the emp table does not have a d_id column.
•When you select the Multiple Objects source type, ensure that the selected table names do not contain a period (.).
Amazon Redshift V2 targets in mappings
To write data to Amazon Redshift, configure an Amazon Redshift V2 object as the target in a mapping.
When you enable the source partition, the Secure Agent uses the pass-through partitioning to write data to Amazon Redshift to optimize the mapping performance at run time. Specify the name and description of the Amazon Redshift V2 target. Configure the target and advanced properties for the target object.
The following table describes the target properties that you can configure in a Target transformation:
Property
Description
Connection
Name of the target connection. Select a target connection, or click New Parameter to define a new parameter for the target connection.
Target Type
Type of the target object.
Select Single Object or Parameter.
Object
Name of the target object.
You can select an existing target object or create a new target object at runtime. To create a new target at runtime, select the Create New at Runtime option
Creates a new target at runtime based on the table type and the path you specify.
Specify the object name, table type, and path to create a new object at runtime.
Create New at Runtime
Applies to the Create New at Runtime option.
Determines if you can create a target object at runtime with the same field names as the source.
Use Exact Source Field Names in Target1
Applies to the Create New at Runtime option. This option does not appear for an existing target.
Select to retain all the source field names in the target exactly as in the source, including any special characters. If you disable this option, special characters in the source are replaced with underscore characters in the target.
Default is disabled.
Parameter
Select an existing parameter for the target object or click New Parameter to define a new parameter for the target object.
The Parameter property appears only if you select Parameter as the target type. If you want to overwrite the parameter at runtime, select the Overwrite Parameter option.
Operation
Type of the target operation.
Select one of the following operations:
- Insert
- Update
- Upsert
- Delete
- Data Driven1
Select Data Driven if you want to create a mapping to capture changed data from a CDC source.
Data Driven Condition
Enables you to define expressions that flag rows for an insert, update, delete, or reject operation.
You must specify the data driven condition for non-CDC sources. For CDC sources, you must leave the field empty as the rows in the CDC source tables are already marked with the operation types.
Note:
Appears only when you select
Data Driven
as the operation type.
Update Columns
Select columns you want to use as a logical primary key for performing update, upsert, and delete operations on the target.
Note:
This field is not required if the target table already has a primary key.
Create Target
Creates a new target.
When you create a new target, enter a value of the following fields:
- Name: Enter a name for the target object.
- Path: Provide a schema name and create a target table within the schema. By default, the field is empty.
1Doesn't apply to mappings in advanced mode.
The following table describes the Amazon Redshift V2 advanced target properties:
Property
Description
S3 Bucket Name
Amazon S3 bucket name for writing the files to Amazon Redshift target.
You can also specify the bucket name with the folder path. If you provide an Amazon S3 bucket name that is in a different region than the Amazon Redshift cluster, you must configure the REGION attribute in the Copy command options.
Enable Compression
Compresses the staging files before writing the files to Amazon Redshift.
The task performance improves when the Secure Agent compresses the staged files. Default is selected.
Staging Directory Location1
Location of the local staging directory.
When you run a task in Secure Agent runtime environment, specify a directory path that is available on the corresponding Secure Agent machine in the runtime environment.
Specify the directory path in the following manner: <staging directory>
For example, C:\Temp. Ensure that you have the write permissions on the directory.
Batch Size1
Minimum number of rows in a batch.
Enter a number greater than 0. Default is 2000000.
Max Errors per Upload Batch for INSERT
Number of error rows that causes an upload insert batch to fail.
Enter a positive integer. Default is 1.
If the number of errors is equal to or greater than the property value, the Secure Agent writes the entire batch to the error file.
Truncate Target Table Before Data Load
Deletes all the existing data in the Amazon Redshift target table before loading new data.
Require Null Value For Char and Varchar
Replaces the string value with NULL when you write data to Amazon Redshift columns of Char and Varchar data types.
Default is an empty string.
Note:
When you run a mapping to write null values to a table that contains a single column of the Int, Bigint, numeric, real, or double data type, the mapping fails. You must provide a value other than the default value in the
Require Null Value For Char And Varchar
property.
WaitTime In Seconds For S3 File Consistency1
Number of seconds to wait for the Secure Agent to make the staged files consistent with the list of files available on Amazon S3.
Default is 0.
Copy Options
Copy command options.
Add options to the Copy command to write data from Amazon S3 to the Amazon Redshift target when the default delimiter comma (,) or double-quote (") is used in the data. Provide the Amazon Redshift Role Amazon Resource Name (ARN).
Specify a directory on the machine that hosts the Secure Agent.
Note:
If you do not add the options to the Copy command manually, the Secure Agent uses the default values.
S3 Server Side Encryption
Indicates that Amazon S3 encrypts data during upload.
Provide a customer master key ID in the connection property to enable this property. Default is not selected.
S3 Client Side Encryption
You cannot use client-side encryption for Amazon Redshift V2 Connector.
Analyze Target Table
Runs an ANALYZE command on the target table.
The query planner on Amazon Redshift updates the statistical metadata to build and choose optimal plans to improve the efficiency of queries.
Vacuum Target Table
Recovers disk space and sorts the row in a specified table or all tables in the database.
You can select the following recovery options:
- None
- Full
- Sort Only
- Delete Only
- Reindex
Default is None.
Prefix to retain staging files on S3
Retains staging files on Amazon S3.
Provide both a directory prefix and a file prefix separated by a slash (/) or only a file prefix to retain staging files on Amazon S3. For example, backup_dir/backup_file or backup_file.
Success File Directory1
Directory for the Amazon Redshift success file.
Specify a directory on the machine that hosts the Secure Agent.
Error File Directory1
Directory for the Amazon Redshift error file.
Specify a directory on the machine that hosts the Secure Agent.
Treat Source Rows As
Overrides the default target operation.
Default is INSERT.
Select one of the following override options:
NONE
By default, none is enabled. The Secure Agent considers the task operation that you select in the Operation target property.
INSERT
Performs insert operation. If enabled, the Secure Agent inserts all rows flagged for insert. If disabled, the Secure Agent rejects the rows flagged for insert.
DELETE
Performs delete operation. If enabled, the Secure Agent deletes all rows flagged for delete. If disabled, the Secure Agent rejects all rows flagged for delete.
UPDATE and UPSERT
Performs update and upsert operations. To perform an update operation, you must map the primary key column and at least one column other than primary key column. You can select the following data object operation attributes:
- Update as Update: The Secure Agent updates all rows as updates.
- Update else Insert: The Secure Agent updates existing rows and inserts other rows as if marked for insert.
For more information, see the Troubleshooting for Amazon Redshift V2 Connector topic.
Amazon Redshift V2 Connector does not support the Upsert operation in the Upgrade Strategy transformation. To use an Update Strategy transformation to write data to an Amazon Redshift target, you must select Treat Source Rows As as None.
By default, the Secure Agent performs the task operation based on the value that you specify in the Operation target property. However, if you specify an option in the Treat Source Rows As property, the Secure Agent ignores the value of that you specify in the Operation target property or in the Update Strategy transformation.
Override Target Query
Overrides the default update query that the Secure Agent generates for the update operation with the update query that you specify.
TransferManager Thread Pool Size1
Number of threads to write data in parallel.
Default is 10.
Pre-SQL
The pre-SQL commands to run a query before you read data from Amazon Redshift. You can also use the UNLOAD or COPY command. The command you specify here is processed as a plain text.
Post-SQL
The post-SQL commands to run a query after you write data to Amazon Redshift. You can also use the UNLOAD or COPY command. The command you specify here is processed as a plain text.
Preserve record order on write1
Retains the order of the records when you read data from a CDC source and write data to an Amazon Redshift target.
Use this property when you create a mapping to capture the changed record from a CDC source. This property enables you to avoid inconsistencies between the CDC source and target.
Minimum Upload Part Size1
Minimum size of the Amazon Redshift object to upload an object.
Default is 5 MB.
Number of files per batch1
Calculates the number of the staging files per batch.
If you do not provide the number of files, Amazon Redshift V2 Connector calculates the number of the staging files.
When you connect to Amazon Redshift serverless and do not provide the number of files, 20 files per batch is considered as the default value.
Schema Name
Overrides the default schema name.
Target table name
Overwrites the default target table name.
Ensure that the metadata and column order in the override table match those in the target table selected during design time.
Recovery Schema Name1
Schema that contains recovery information stored in the infa_recovery_table table on the target system to resume the extraction of the changed data from the last checkpoint.
Temporary Credential Duration
The time duration during which an IAM user can use the dynamically generated temporarily credentials to access the AWS resource. Enter the time duration in seconds.
Default is 900 seconds.
If you require more than 900 seconds, you can set the time duration maximum up to 12 hours in the AWS console and then enter the same time duration in this property.
Forward Rejected Rows
This property is not applicable for Amazon Redshift V2 Connector.
1Doesn't apply to mappings in advanced mode.
Rules and guidelines for creating a target
The Secure Agent converts the target table names that you specify in the Create Target field into lower case.
When you create a target, you can view and edit the metadata of the target object in the Target Fields tab. You can edit the data type, precision and define primary key of the columns in the target objects. To edit the metadata, click Options > Edit Metadata in the Target Fields tab.
Consider the following rules and guidelines when you create a target:
•When you create a target if the source table contains column of Text data type, the Secure Agent displays the following error message:
Unsupported datatype - 'text' for column 'LONGTXTAREA__C'
You must edit the data type of the source column in the Source transformation.
•You cannot parameterize the target at runtime.
•When you create a target and specify a table name or column name in uppercase or mixed case alphabets, the Secure Agent converts the target table name or column name into lowercase alphabets and the mapping task runs successfully. However, the tomcat log shows the following error message:
An unexpected exception occured while fetching metadata:[The following object is not found].
•When you create a target with Time data type, the new target will have the data type as Timestamp.
•When you run a mapping task with a vaccuum command using the pre-SQL or post-SQL queries, the mapping fails.
•When you write to a target and the target connection has Auto Create DBuser enabled, the new user cannot truncate a table created by an existing user.
Rules and guidelines to override the target query
You can specify a target query override to override the update query that the Secure Agent generates for the update operation.
Consider the following rules and guidelines when you use the override target query property for an Amazon Redshift target:
•Select Update for the Treat source rows as property in the advanced target properties.
•You cannot use the override target query for an upsert operation.
• Specify the override target query in the following format:
UPDATE <Target Schema Name here>.<Target TABLE NAME here> SET <column1> = {{TU}}.<column1>, <column2> = {{TU}}.<column2>, <column> = {{TU}}.<column> FROM {{TU}} WHERE <Target Schema Name>.<Target TABLE NAME here> .<update column1> = {{TU}}. <update column1> AND <Target Schema Name>.<Target TABLE NAME here> .<update column2> = {{TU}}. <update column2> AND … <Target Schema Name>.<Target TABLE NAME here> .<update column> = {{TU}}. <update column>
•Column names for :TU must match the target table column names.
•The WHERE column is mandatory in the query.
•You cannot use left, right, or full outer joins in the FROM column of an override target query statement.
• All the column names in the query must be qualified names and the table name and schema name must be associated with the column names.
Note: For the SET columns, Amazon Redshift does not allow a column name with a table. SET columns must have column names only.
•You must specify the override target query with a valid SQL syntax because Amazon Redshift V2 Connector replaces :TU with a temporary table name and does not validate the update query.
•You cannot change the order of the column mappings using the override target query.
•You cannot specify multiple override target queries for an update operation.
•When you use the override target query option, do not additionally configure an override for the schema and table name from the Schema Name and Target table name fields.
Amazon Redshift V2 lookups in mappings
You can create lookups for objects in an Amazon Redshift V2 mapping. You can retrieve data from an Amazon Redshift V2 lookup object based on the specified lookup condition.
Use an Amazon Redshift V2 Lookup transformation to look up data in an Amazon Redshift object. For example, the source table includes the customer code, but you want to include the customer name in the target table to make summary data easy to read. You can use the Amazon Redshift V2 Lookup transformation to look up the customer name in another Amazon Redshift object.
You can add the following lookups to a mapping:
•Connected with cached
•Connected with uncached. Applicable only to mappings.
•Unconnected with cached
•Dynamic lookup cache. Applicable only to mappings.
Use the JDBC URL specified in the connection properties to create lookups.
The following table describes the Amazon Redshift V2 lookup object properties that you can configure in a Lookup transformation:
Property
Description
Connection
Name of the lookup connection.
You can select an existing connection, create a new connection, or define parameter values for the lookup connection property.
If you want to overwrite the lookup connection properties at runtime, select the Allow parameter to be overridden at run time option.
Source Type
Type of the source object. Select Single Object, Query, or Parameter.
Note:
You cannot configure uncached lookups when you select the source type as query.
Parameter
A parameter file where you define values that you want to update without having to edit the task.
Select an existing parameter for the lookup object or click New Parameter to define a new parameter for the lookup object.
The Parameter property appears only if you select parameter as the lookup type.
If you want to overwrite the parameter at runtime, select the Allow parameter to be overridden at run time option.
When the task runs, the Secure Agent uses the parameters from the file that you specify in the advanced session properties.
Lookup Object
Name of the lookup object for the mapping.
Multiple Matches
Behavior when the lookup condition returns multiple matches. You can return all rows, any row, the first row, the last row, or an error.
You can select from the following options in the lookup object properties to determine the behavior:
- Return first row
- Return last row
- Return any row
- Return all rows
- Report error
Filter
Not applicable
Sort
Not applicable
The following table describes the Amazon Redshift V2 advanced lookup properties that you can configure in a Lookup transformation:
Property
Description
S3 Bucket Name1
Amazon S3 bucket name for staging the data.
You can also specify the bucket name with the folder path. If you provide an Amazon S3 bucket name that is in a different region than the Amazon Redshift cluster, you must configure the REGION attribute in the Unload command options.
Enable Compression1
Compresses the staging files into the Amazon S3 staging directory.
The task performance improves when the Secure Agent compresses the staging files. Default is selected.
Staging Directory Location1
Location of the local staging directory.
When you run a task in Secure Agent runtime environment, specify a directory path that is available on the corresponding Secure Agent machine in the runtime environment.
Specify the directory path in the following manner: <staging directory>
For example, C:\Temp. Ensure that you have the write permissions on the directory.
Does not apply to mappings in advanced mode.
Unload Options1
Unload command options.
Add options to the Unload command to extract data from Amazon Redshift and create staging files on Amazon S3. Provide an Amazon Redshift Role Amazon Resource Name (ARN).
You cannot use the NULL option in a mapping in advanced mode.
Specify a directory on the machine that hosts the Secure Agent.
Note:
If you do not add the options to the Unload command manually, the Secure Agent uses the default values.
Treat NULL Value as NULL1
Retains the null values when you read data from Amazon Redshift.
Encryption Type1
Encrypts the data in the Amazon S3 staging directory.
You can select the following encryption types:
- None
- SSE-S3
- SSE-KMS
You can only use SSE-S3 encryption in a mapping configured in advanced mode.
You cannot use CSE-SMK encryption type for Amazon Redshift V2 Connector.
Default is None.
Download S3 Files in Multiple Parts1
Downloads large Amazon S3 objects in multiple parts.
When the file size of an Amazon S3 object is greater than 8 MB, you can choose to download the object in multiple parts in parallel. Default is 5 MB.
Does not apply to mapping in advanced mode.
Multipart Download Threshold Size1
The maximum threshold size to download an Amazon S3 object in multiple parts.
Default is 5 MB.
Does not apply to mapping in advanced mode.
Schema Name
Overrides the default schema name.
Note:
You cannot configure a custom query when you use the schema name.
Source Table Name
Overrides the default source table name.
Note:
When you select the source type as
Multiple Objects
or
Query
, you cannot use the
Source Table Name
option.
Pre-SQL
The pre-SQL commands to run a query before you read data from Amazon Redshift. You can also use the UNLOAD or COPY command. The command you specify here is processed as a plain text.
Post-SQL
The post-SQL commands to run a query after you write data to Amazon Redshift. You can also use the UNLOAD or COPY command. The command you specify here is processed as a plain text.
Select Distinct1
Selects unique values.
The Secure Agent includes a SELECT DISTINCT statement if you choose this option. Amazon Redshift ignores trailing spaces. Therefore, the Secure Agent might extract fewer rows than expected.
Note:
If you select the source type as query or use the
SQL Query
property and select the
Select Distinct
option, the Secure Agent ignores the
Select Distinct
option.
SQL Query1
Overrides the default SQL query.
Enclose column names in double quotes. The SQL query is case sensitive. Specify an SQL statement supported by the Amazon Redshift database.
When you specify the columns in the SQL query, ensure that the column name in the query matches the source column name in the mapping.
Lookup Data Filter
Limits the number of lookups that the mapping performs on the cache of the lookup source table based on the value you specify in the filter condition.
This property is applicable when you select Single Object as the source type and enable lookup cache on the Advanced tab in the Lookup transformation properties.
Maximum length is 32768 characters.
For more information about this property, see Lookup source filter in Transformations.
Temporary Credential Duration1
The time duration during which an IAM user can use the dynamically generated temporarily credentials to access the AWS resource. Enter the time duration in seconds.
Default is 900 seconds.
If you require more than 900 seconds, you can set the time duration up to a maximum of 12 hours in the AWS console and then enter the same time duration in this property.
Tracing Level
Use the verbose tracing level to get the amount of detail that appears in the log for the Source transformation.
1 Does not apply to uncached lookups.
For more information about the Lookup transformation, see Transformations.
Unconnected Lookup transformation
You can configure an unconnected Lookup transformation for the Amazon Redshift source in a mapping. Use the Lookup transformation to retrieve data from Amazon Redshift based on a specified lookup condition.
An unconnected Lookup transformation is a Lookup transformation that is not connected to any source, target, or transformation in the pipeline.
An unconnected Lookup transformation receives input values from the result of a :LKP expression in another transformation. The Integration Service queries the lookup source based on the lookup ports and condition in the Lookup transformation and passes the returned value to the port that contains the :LKP expression. The :LKP expression can pass lookup results to an expression in another transformation.
For more information about the Lookup transformation, see Transformations.
Configuring an unconnected Lookup transformation
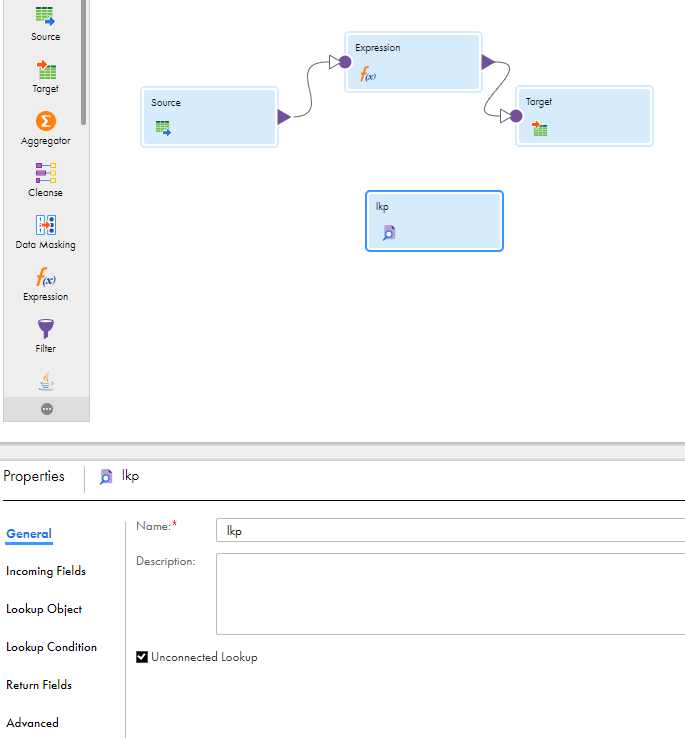
To configure an unconnected Lookup transformation, select the Unconnected Lookup option, add incoming fields, configure the lookup condition, and designate a return value. Then configure a lookup expression in a different transformation.
1Add a Lookup transformation in a mapping.
2On the General tab of the Lookup transformation, enable the Unconnected Lookup option.
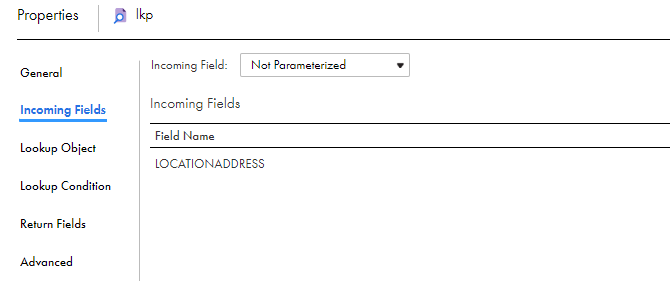
3On the Incoming Fields tab of the Lookup transformation, create an incoming field for each argument in the :LKP expression.
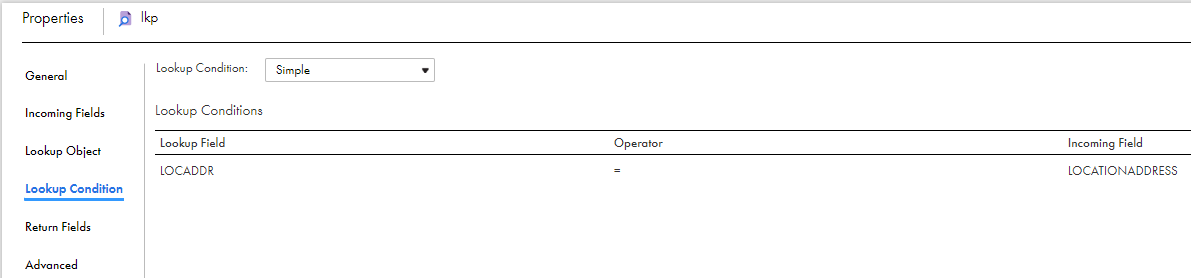
For each lookup condition you create, add an incoming field to the Lookup transformation.
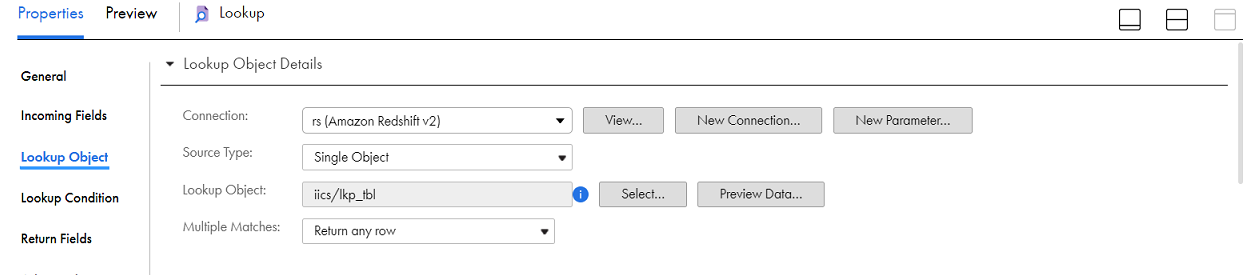
4In the Lookup Object tab, import the lookup object.
The Multiple Matches property value Return all rows in an unconnected lookup is not applicable.
5Designate a return value.
You can pass multiple input values into a Lookup transformation and return one column of data. Data Integration can return one value from the lookup query. Use the return field to specify the return value.
6Configure a lookup expression in another transformation.
Supply input values for an unconnected Lookup transformation from a :LKP expression in a transformation that uses an Expression transformation. The arguments are local input fields that match the Lookup transformation input fields used in the lookup condition.
7Map the fields with the target.
Enabling lookup caching
When you configure a Lookup transformation in a mapping, you can cache the lookup data during the runtime session.
When you select Lookup Caching Enabled, Data Integration queries the lookup source once and caches the values for use during the session, which can improve performance. You can specify the directory to store the cached lookup.
Lookup Cache Persistent
Use lookup cache persistent to save the lookup cache file to reuse it the next time Data Integration processes a Lookup transformation configured to use the cache.
You can specify the file name prefix to use with persistent lookup cache files in the Cache File Name Prefix field.
If the lookup table changes occasionally, you can enable the Re-cache from Lookup Source property to rebuild the lookup cache.
Dynamic Lookup Cache
Use a dynamic lookup cache to keep the lookup cache synchronized with the target. By default, the dynamic lookup cache is disabled and represents static cache.
If the cache is static, the data in the lookup cache does not change as the mapping task runs.
If the task uses the cache multiple times, the task uses the same data. If the cache is dynamic, the task updates the cache based on the actions in the task, so if the task uses the lookup multiple times, downstream transformations can use the updated data.
For information about lookup caching, see Transformations in the Data Integration documentation.
Rules and guidelines for configuring lookup transformations
Consider the following rules and guidelines when you configure an Amazon Redshift lookup transformation:
•You cannot use unconnected lookups for mappings in advanced mode.
•You cannot configure a dynamic lookup cache for mappings in advanced mode.
•A Lookup transformation with the On Multiple Matches property configured as Report Error, runs successfully without displaying an error message for mappings in advanced mode.
•You cannot use the SQL query property for uncached lookups.
•To use the IS NULL and IS NOT NULL operators in an uncached lookup, you need to set the -DENABLE_NULL_FLAG_FOR_UNCACHED_LOOKUP=true property as a JVM option under the DTM type in the Secure Agent properties. You can use only the = and != operators. The task fails if you use any other operator.
Mapping task with Oracle CDC sources example
Your organization needs to replicate real-time changed data from a mission-critical Oracle production system to minimize intrusive, non-critical work, such as offline reporting or analytical operations system. You can use Amazon Redshift V2 Connector to capture changed data from the Oracle CDC source and write the changed data to an Amazon Redshift target table. Add the Oracle CDC sources in mappings, and then run the associated mapping tasks to write the changed data to the target.
1In Data Integration, click New > Mapping > Create.
The New Mapping dialog box appears.
2 Enter a name and description for the mapping.
3On the Source transformation, specify a name and description in the general properties.
4On the Source tab, select the configured Oracle CDC connection and specify the required source properties.
5On the Target transformation, specify a name and description in the general properties.
6On the Target tab, perform the following steps to configure the target properties:
aIn the Connection field, select the Amazon Redshift V2 connection.
bIn the Target Type field, select the type of the target object.
cIn the Object field, select the required target object.
dIn the Operation field, select Data Driven to properly handle insert, update, and delete records from the source.
eIn the Data Driven Condition field, leave the field empty.
fIn the Advanced Properties section, provide the values of the required target properties. You must select the Preserve record order on write check box and enter the value of the Recovery Schema Name property.
7On the Field Mapping tab, map the incoming fields to the target fields. You can manually map an incoming field to a target field or automatically map fields based on the field names.
8In the Actions menu, click New Mapping Task.
The New Mapping Task page appears.
9On the Definition tab, enter the task name and select the configured mapping.
10On the CDC Runtime tab, specify the required properties.
For more information about the CDC Runtime properties, see the help for Oracle CDC Connector.
11On the Runtime Options tab, specify the following properties in the Advanced Session Properties section:
aSelect Commit on End of File from the menu, and keep the property disabled.
bSelect the Commit Type field as Source.
cSelect Recovery Strategy and set Resume from last checkpoint as the value of the property.
12Click Save > Run the mapping.
Alternatively, you can create a schedule that runs the mapping task on a recurring basis without manual intervention. You can define the schedule to minimize the time between mapping task runs.
In Monitor, you can monitor the status of the logs after you run the task.
Mapping in advanced mode example
You work for an organization that stores large amount of purchase order details, such as customer ID, item codes, and item quantity in Amazon S3. You need to port the data from Amazon S3 to another cloud-based environment to quickly analyze the purchase order details and to increase future revenues.
Create a mapping that runs in advanced mode to achieve faster performance when you read all the purchase records from Amazon S3 and write the records to an Amazon Redshift target.
1In Data Integration, click New > Mappings > Mapping.
2In the Mapping Designer, click Switch to Advanced.
The following image shows the Switch to Advanced button in the Mapping Designer.
3In the Switch to Advanced dialog box, click Switch to Advanced.
The Mapping Designer updates the mapping canvas to display the transformations and functions that are available in advanced mode.
4Enter a name, location, and description for the mapping.
5Add a Source transformation, and specify a name and description in the general properties.
6On the Source tab, perform the following steps to provide the source details to read data from the Amazon S3 source:
aIn the Connection field, select the Amazon S3 V2 source connection.
bIn the Source Type field, select the type of the source.
cIn the Object field, select the required object.
dIn the Advanced Properties section, provide the appropriate values.
7On the Fields tab, map the Amazon S3 source fields to the target fields.
8On the Target transformation, specify a name and description in the general properties.
9On the Target tab, perform the following steps to provide the target details to write data to the Amazon Redshift target:
aIn the Connection field, select the Amazon Redshift V2 target connection.
bIn the Target Type field, select the type of the target.
cIn the Object field, select the required object.
dIn the Operation field, select the required operation.
eIn the Advanced Properties section, provide appropriate values for the advanced target properties.
10Map the Amazon S3 source and the Amazon Redshift target.
11Click Save > Run to validate the mapping.
In Monitor, you can monitor the status of the logs after you run the task.
SQL transformation
You can configure an SQL transformation to process SQL queries midstream in an Amazon Redshift V2 mapping. You cannot configure an SQL transformation for a mapping in advanced mode.
When you add an SQL transformation to the mapping, on the SQL tab, you define the connection and the type of SQL that the transformation processes.
Stored procedure
You can configure an SQL transformation to call a stored procedure in Amazon Redshift. The stored procedure must exist in the Amazon Redshift database before you create the SQL transformation. When the SQL transformation processes a stored procedure, it passes input parameters to the stored procedure. The stored procedure passes the return value to the output fields of the transformation.
The following image shows a stored procedure in a SQL transformation:
Consider the following rules and guidelines for stored procedures:
•When the incoming fields from a stored procedure are of char or varchar data type, the SQL transformation applies a default precision of 256 for these fields, regardless of the precision defined at the database endpoint.
•When you use the same column names in the source table as in the table used in the stored procedure, the mapping task fails.
•When you specify the numeric data type, for example, numeric(10,2) for a column in a stored procedure, the mapping task fails.
•When you create a stored procedure in a mapping, the output port must not include the refcursor data type.
•You cannot read from multiple stored procedures that have the same name even if the input parameters that you specify for the stored procedures are different.
For more information about stored procedures, see Transformations in the Data Integration documentation.
SQL query
You can configure an SQL transformation to process an entered query that you define in the SQL editor. The SQL transformation processes the query and returns the rows. The SQL transformation also returns any errors that occur from the underlying database or the user syntax.
You can process an entered query to call a stored procedure that returns a value or no values.
The following image shows an entered query in a SQL transformation:
Consider the following rules and guidelines for SQL queries:
•You cannot use the saved query type in an SQL transformation.
•You can specify only a single query in an entered query. Do not specify multiple queries.
•Do not use the COMMIT, ROLLBACK, and EXPLAIN PLAN statements in an entered query.
For more information about SQL queries, see Transformations in the Data Integration documentation.
Dynamic schema handling for mappings
You can choose how Data Integration handles changes that you make to the data object schemas. To refresh the schema every time the mapping task runs, you can enable dynamic schema handling in the task.
A schema change includes one or more of the following changes to the data object:
•Fields added.
•Fields updated for data type, precision, or scale.
Configure schema change handling on the Runtime Options page when you configure the task.
The following table describes the schema change handling options:
Option
Description
Asynchronous
Default. Data Integration refreshes the schema when you edit the mapping or mapping task, and when IDMC is upgraded.
Dynamic
Data Integration refreshes the schema every time the task runs.
You can choose from the following options to refresh the schema:
- Alter and Apply Changes.Data Integration alters the target schema and adds the new fields from the source.
- Drop Current and Recreate. Drops the existing target table and then recreates the target table at runtime using all the incoming metadata fields from the source.
- Don't Apply DDL Changes.Data Integration does not apply the schema changes to the target.
For more information, see the "Schema change handling" topic in Tasks.
Rules and guidelines for dynamic schema handling for mappings
Consider the following rules and guidelines when you enable dynamic schema change handling:
•Updates to the data types, precision, and scale are not applicable.
•Schema updates that involve a decrease in the precision of the Varchar data type are not applicable.
•When you use special characters in a target table column and select Alter and Apply Changes, the mapping task fails with an error.
•When you use a completely parameterized filter in a field mapping in a Source transformation and select the Dynamic option, the Runtime Options page does not display the options to refresh the schema.
•When you use an SQL override in a Source transformation and select Alter and Apply Changes, the mapping task fails with an error.
•When you add a field in the source as a primary key and select Alter and Apply Changes, the mapping task runs successfully and the field is propagated to target. However, the primary key is not considered.
•When you override the source table name or schema name and select the Alter and Apply Changes schema change handling option, and if new fields are added to the overridden source table, the mapping runs successfully. However, the Secure Agent does not fetch the newly added fields from the overridden source table.
Configuring key range partition
Configure key range partition to partition Amazon Redshift data based on field values.
1In Source Properties, click the Partitions tab.
2Select the required Partition Key from the list.
3Click Add New key Range to add partitions.
4Specify the Start range and End range.
Bulk processing for write operations
You can enable bulk processing to write large amounts of data to Amazon Redshift. Bulk processing utilizes minimal number of API calls and enhances performance of the write operation.
To enable bulk processing, specify the property -DENABLE_WRITER_BULK_PROCESSING=true in the Secure Agent properties:
Perform the following steps to configure bulk processing before you run a mapping:
1In Administrator, select the Secure Agent listed on the Runtime Environments tab.
2Click Edit.
3In the System Configuration Details section, select Data Integration Service as the service and DTM as the type.
4Edit the JVMOption1 property, and enter -DENABLE_WRITER_BULK_PROCESSING=true.
5Click Save.
Note:
Not applicable to mapping tasks configured with
SQL ELT optimization
.
Optimize the staging performance for a mapping
Data Integration, by default, creates a flat file locally in a temporary folder to stage the data before reading from and writing to Amazon Redshift. You can set Data Integration to optimize the staging performance.
If you do not set the optimization property, Data Integration performs staging without the optimized settings, which might impact the performance of the task.
Consider the following rules when you enable the optimization property:
•If you run a mapping enabled for SQL ELT optimization, the mapping runs without SQL ELT optimization.
•If the data contains timestamp data types with time zone, the job runs without staging the data in the local flat file.
•If the mapping contains Oracle CDC as a source and Amazon Redshift as the target, the job runs without staging the data in the local flat file.
•When you run a mapping to read multiline data from the source that contains CR or LF characters, the column data is split into multiple lines.
•When you enable the optimization property for the Source or Lookup transformation, the session log displays the following message for both trnsformations:
DTM Staging is enabled for connector for Source Instance.
To distinguish logs related to the Lookup transformation, look for the logging code LKPDP in the session log.
For example, LKPDP_1:READER_1_1> SDKS_38636 [2023-02-06 13:22:47.621] Plug-in #451600: DTM Staging is enabled for connector for Source Instance.
•When an Amazon Redshift source table contains NULL values in columns of char data type, the mapping runs successfully. However, data mismatch might occur in the target.
•When you use the ESCAPE=OFF unload command and run a mapping to read data from an Amazon Redshift source that contains delimiter characters, the data is truncated at the first occurrence of the delimiter.
Enabling Amazon Redshift Connector to optimize the staging performance
Perform the following steps to enable the Amazon Redshift V2 Connector to optimize the staging performance:
1In Administrator, click Runtime Environments.
2Edit the Secure Agent for which you want to set the property.
3In the System Configuration Details section, select the Service as Data Integration Server and the type as Tomcat.
4Set the value of the Tomcat property INFA_DTM_RDR_STAGING_ENABLED_CONNECTORS for the read operation, INFA_DTM_STAGING_ENABLED_CONNECTORS for the write operation, and INFA_DTM_LKP_STAGING_ENABLED_CONNECTORS for the cached lookup operation to the plugin ID of Amazon Redshift Connector.
You can find the plugin ID in the manifest file located in the following directory:
The following image shows the optimization property that you set for staging data in the DTM of the Secure Agent:
When you run the mapping, the flat file is created in the following directory in your machine: C:\Windows\Temp\AmazonRedshift\stage\<AmazonRedshift_Target.txt>
You can check the session logs to verify if the optimization property is enabled.