In a mapping, you can configure a Target transformation to represent a Hive target object. You can use a mapping task to write data to Hive targets.
The following table describes the Hive target properties that you can configure in a Target transformation in mappings:
Property
Description
Connection
Name of the target connection.
Target type
Type of the target object.
Select one of the following types:
- Single Object. Select to specify a single Hive target object.
- Parameter. Specify a parameter where you define values that you want to update without having to edit the task.
Object
Target object for a single target.
You can select an existing target object or create a new target at runtime.
Operation
The target operation. You can choose from the following options:
Insert
Inserts data to a Hive target.
Upsert (Update or Insert)1
Performs an upsert operation to the Hive target. You must also select the Update as Upsert property for upsert to work. The Secure Agent performs the following tasks:
- If the entries already exist in the Hive target, the Secure Agent updates the data.
- If the entries do not exist in the Hive target, the Secure Agent inserts the data.
Update1
Updates data to the Hive target.
Delete1
Deletes data in the Hive target.
Data Driven1
Determines if the agent inserts, updates, or deletes records in the Hive target table based on the expression you specify.
Note: Reject operation is ignored for the data driven operation type.
Update Columns1
Columns that identify rows in the target table to update or upsert data.
Select the key columns where you want to upsert or update data in the Hive target table.
Required if you select the Upsert (Update or Insert) option.
Data Driven Condition1
Enables you to define expressions that flag rows for an insert, update, or delete operation when you select the Data Driven operation type.
Note: Reject operation is ignored for the data driven operation type.
1Applies only to mappings in advanced mode.
The following table describes the properties that you can configure when you use the Create New at Runtime option in a Target transformation in mappings:
Property
Description
Object Name
The name for the target table.
External Table
The type of Hive tables such as managed or external to write the data.
Select the check box if you want to create an external table. Clear the checkbox if you want to create a managed table.
Table Location
The path to the managed or external table in the Hive target to store the data.
If you do not specify a path, Data Integration uses the default warehouse directory configured in the Hive server.
Number of Buckets
The number of buckets to create if the table contains bucket columns.
Stored As
The format to store the data in the table location you specify.
You can choose from the following formats:
- Avro
- Orc
- Parquet
- RC file
- Sequence file
- Text file
Additional Table Properties
List of key-value comma-separated pairs of additional properties that you want to configure to create the target table.
Enclose both the key and value within double quotes and specify the following format to include additional properties: "<property name>"="<value>"
For example, you can configure additional properties such as compression formats or to include comments in the Hive target table by specifying the following properties:
The following table describes the Hive target advanced properties that you can configure in a Target transformation in mappings:
Property
Description
Update as Upsert1
Upserts any records flagged for upsert.
This property is required when you select the Upsert (Update or Insert) option and you want to upsert data.
Important: When you select the Update operation and also provide the Update as Upsert flag, the agent supports the upsert operation, not the update operation.
Truncate Target
Truncates the database target table before inserting new rows.
Select the Truncate Target check box to truncate the target table before inserting all rows.
By default, the Truncate Target check box is not selected.
PreSQL
SQL statement that you want to run before writing data to the target.
PostSQL
SQL statement that you want to run after writing the data to the target.
Schema Override
Overrides the schema of the target object at runtime.
Table Override
Overrides the table of the target object at runtime.
Forward Rejected Rows
Determines whether the transformation passes rejected rows to the next transformation or drops rejected rows. By default, the mapping task forwards rejected rows to the next transformation.
If you select the Forward Rejected Rows option, the Secure Agent flags the rows for reject and writes them to the reject file.
If you do not select the Forward Rejected Rows option, the Secure Agent drops the rejected rows and writes them to the session log file. The Secure Agent does not write the rejected rows to the reject file.
1Applies only to mappings in advanced mode.
Writing data to a Hive target
You can use an existing target or create a new target at runtime to write data to Hive.
1Click New > Mappings, and then click Create.
2Based on your requirement, you can click Switch to Advanced
3In the Target Properties page, specify the name and provide a description in the General tab.
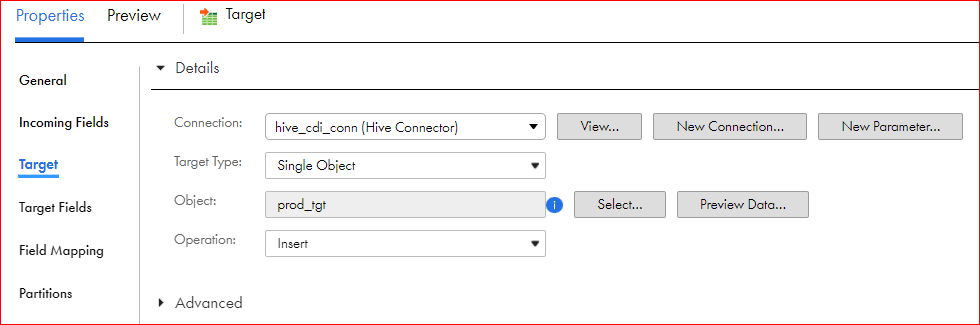
4Click the Target tab.
5Select the target connection and the target type.
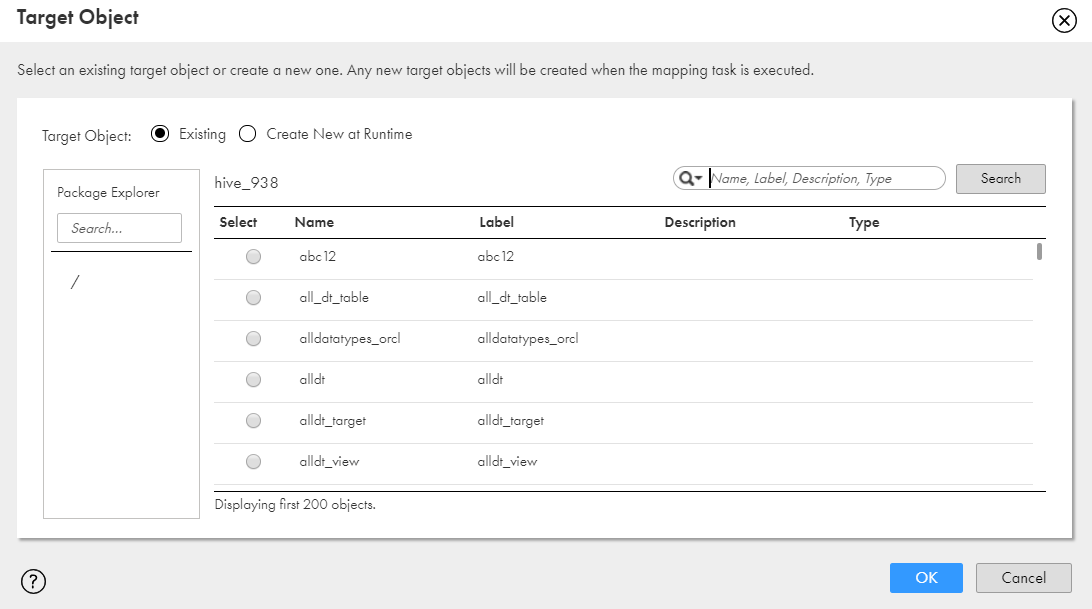
6Click Select to select a target object.
7Select an existing target object from the list and click OK.
8To create a new Hive target at runtime, select Create New at Runtime, and specify the required properties for the Hive target object.
9Select the target operation that you want to use.
10Select the advanced properties that you want to configure for the target object.
11Click Save.
Column partitioning for targets
You can organize tables or data sets into partitions to group the same type of data based on a column.
You can use an existing Hive target that has partitioned columns to write the data or you can configure partitions when you create a new Hive target at runtime.
When you create a new target at runtime, you can select the incoming columns that you want to add as partition columns. Include the partition columns from the list of fields that display in Partition Fields on the Partitions tab in the Target transformation.
When you select the columns as partitioned columns, the default data type for the columns is set to String. You cannot edit the data type of a partitioned column in the Hive target object. You can add, delete, and change the order of the partition fields, if required. You must not give the same partition order for multiple columns.
You can also create buckets to divide large data sets into more manageable parts. To configure buckets, you must first specify the number of buckets when you create a new target at runtime. After you specify the number, select the bucket fields, and then select the partitioning fields.
Data Integration creates all the fields that you select for partitioning in the target based on the partition order you specify. For example, you can create a table to write employee joining details categorized in the following hierarchical order, such as month, hour, year, and date.
Adding columns as partitions to the target
In this example, you want to create a table to write sales data from retail stores spread across Asia Pacific to a Hive table. You want to write data to partitions categorized based on country, state, and outlet names so that you can run queries easily across data split in partitions.
1Configure a target transformation with the Create New at Runtime option.
2To include a bucket, in the Create New at Runtime properties, specify the number of buckets you want in the target.
Include a bucket if you want to split incoming data into a bucket.
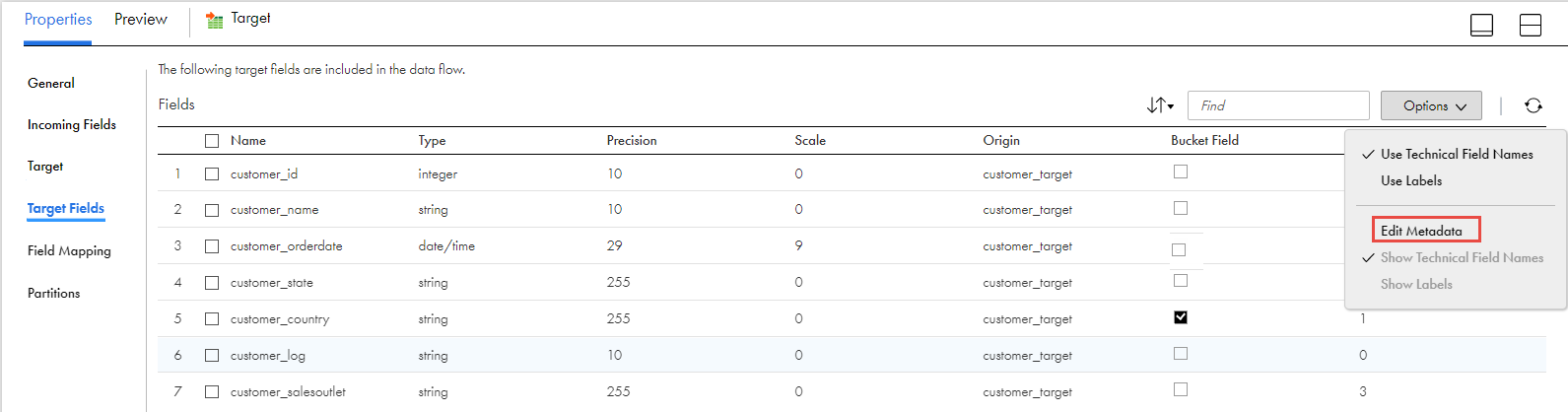
3On the Target Fields tab, edit the metadata, and then select the column that you want to include as a bucket field in the Hive target table.
You cannot edit the metadata for a column that you select for partitioning. If you need to include buckets, you must select the column that you want as a bucket on the Target Fields tab, and then select those columns for partitioning on the Partitions tab.
4Click the icon in the Partitions tab to add the partition columns for a target.
The following image shows the Partitions tab where you can add the partition columns:
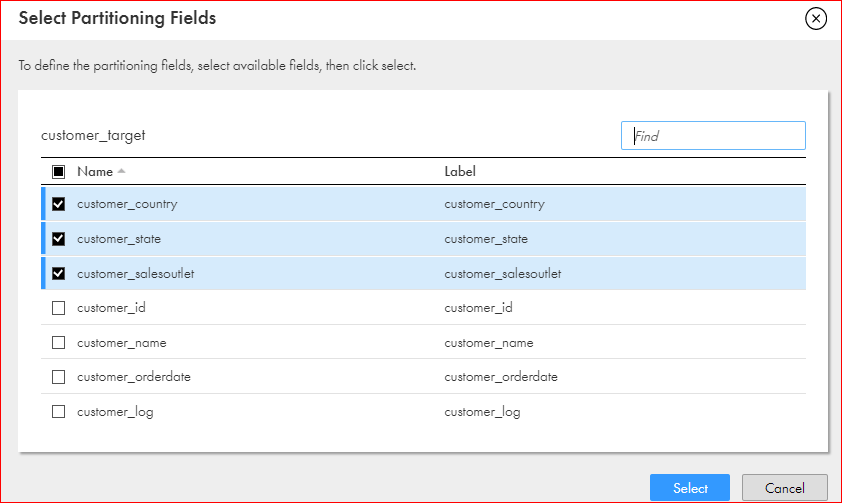
5On the Partitions tab, select the required partitioning fields from the list of incoming fields from the source:
6Click Select.
The Partitions tab shows the partition columns that you selected:
7If required, change the partition order using the up and down arrows as shown in the following image:
Note: Do not change the partitioning order in the Target Fields tab in the Target transformation. You can change the partitioning order only from the Partitions tab.
The columns that you select for partitioning are set by default to string while writing the data to the target.
Rules and guidelines for adding partitioning columns
Consider the following general rules and guidelines when you include partitioned columns to a target created at runtime:
•You cannot use an existing table to add partitioned columns.
•Parallel processing is not applicable for Hive Connector.
•If you specify a value greater than 1 for the number of buckets to include in the target, but you do not select the bucket columns in the Target Fields tab, Data Integration does not create the buckets in the target Hive table.
•You cannot create more than two partitions for a Hive target on the Cloudera CDP version 7.1.1 cluster.
•If you create a Hive target on the Cloudera EMR cluster and the data is of the RC file format, you cannot insert null values to the binary data type column.
Mapping
Consider the following rules and guidelines for mappings:
•When you select columns other than the String data type as partition columns for a target that you want to create at runtime, the data type is written as String in the target. You cannot select a field of the Binary data type for partitioning when you create a new target at runtime.
Mappings in advanced mode
You cannot select a field of the Binary data type for partitioning when you write data to the target.

 icon in the
icon in the