When you configure a mapping enabled for full SQL ELT optimization to write to multiple Snowflake targets using a Snowflake Data Cloud connection, you can specify the optimization context for multi-insert and slowly changing dimension type 2 merge scenarios.
You can specify the Optimization context type on the Runtime Options tab in a task. Based on the optimization context that you specify, Data Integration combines queries issued from multiple targets and constructs a single query for SQL ELT optimization and the task is optimized.
You can enable the following optimization modes in the task properties based on the target operations you specify in the mapping:
Multi-insert
Enable this mode when you insert data from a Snowflake source to multiple Snowflake targets. Data Integration combines the queries generated for each of the targets and issues a single query.
SCD Type 2 merge
Enable this mode when you write to two Snowflake targets, where you use one target to insert data and the other target to update data. Data Integration combines the queries for both the targets and issues a Merge query.
Default is None.
Understanding an SCD type 2 merge mapping
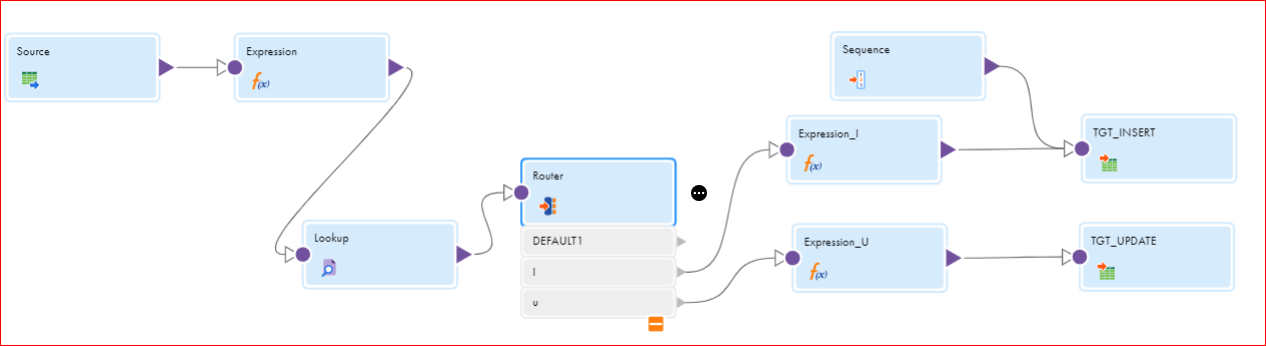
The SCD Type 2 merge mapping uses a Snowflake source and two target transformations that write to the same Snowflake table. One target transformation updates the table while the other transformation inserts data to the Snowflake table
The following image shows a mapping that writes slowly changing dimension data to a Snowflake target table:
Add lookup and expression transformations to compare source data against the existing target data. You enter the lookup conditions and source columns that you want the Data Integration to compare against the existing target.
For each source row without a matching primary key in the target, the Expression transformation marks the new row. For each source row with a matching primary key in the target, the Expression compares user-defined source and target columns. If those columns do not match, the Expression marks the row changed. The mapping then splits into two data flows.
The first data flow uses the Router transformation to pass only new rows to the Expression transformation. The Expression transformation inserts new rows to the target. A Sequence Generator creates a primary key for each row. The Expression transformation increases the increment between keys by 1,000 and creates a version number of 0 for each new row.
In the second data flow, the Router transformation passes only changed rows to pass to the Expression transformation. The Expression transformation inserts changed rows to the target. The Expression transformation increments both the key and the version number by one.
Restrictions
You cannot use a filter, joiner, and a custom SQL query in an SCD type 2 merge mapping.