To configure a mapping, perform the following tasks:
1Define the mapping.
2Configure the source.
3Configure the data flow. Add, and configure transformations, and draw links to represent the flow of data.
Tip:
You can copy and paste transformations within or between open mappings.
4Configure the target.
5Optionally, create parameters to be defined in the mapping task.
6Save and validate the mapping.
Defining a mapping
To define a mapping, create or edit a mapping, specify the mapping name and location, and optionally enter a mapping description.
1To create a new mapping, click New > Data Integration > Mapping > Create.
To edit a mapping, on the Explore page, navigate to the mapping. In the row that contains the mapping, click Actions and select Edit.
2If the New Mapping dialog box appears, select the mapping type and then click Continue.
3If you create a mapping in SQL ELT mode, select the target connection or create a new target connection and then click Next.
4To specify the mapping name and location, in the Mapping Properties panel, enter a name for the mapping and change the location. Or, you can use the default values if desired.
The default mapping name is Mapping followed by a sequential number.
Mapping names can contain alphanumeric characters and underscores (_). Maximum length is 100 characters.
The following reserved words cannot be used:
- AND
- OR
- NOT
- PROC_RESULT
- SPOUTPUT
- NULL
- TRUE
- FALSE
- DD_INSERT
- DD_UPDATE
- DD_DELETE
- DD_REJECT
If the Explore page is currently active and a project or folder is selected, the default location for the asset is the selected project or folder. Otherwise, the default location is the location of the most recently saved asset.
You can change the name or location after you save the mapping using the Explore page.
5Optionally, enter a description of the mapping.
Maximum length is 4000 characters.
Configuring the source
To configure the source, edit the Source transformation.
1On the mapping canvas, click the Source transformation.
2To specify a name and description for the Source transformation, in the Properties panel, click General.
Transformation names can contain alphanumeric characters and underscores (_). Maximum length is 75 characters.
The following reserved words cannot be used:
- AND
- OR
- NOT
- PROC_RESULT
- SPOUTPUT
- NULL
- TRUE
- FALSE
- DD_INSERT
- DD_UPDATE
- DD_DELETE
- DD_REJECT
You can enter a description if desired.
Maximum length is 4000 characters.
3Click the Source tab and configure source details, query options, and advanced properties.
Source details, query options, and advanced properties vary based on the connection type. For more information, see the help for the appropriate connector.
In the source details, select the source connection and source object. For some connection types, you can select multiple source objects.
If your organization administrator has configured Enterprise Data Catalog integration properties and you've added objects to the mapping from the Data Catalog page, you can select the source object from the Inventory panel. The Inventory panel isn't available in mappings in SQL ELT mode.
You can also configure parameters for the source connection and source object.
In advanced mode, you can add an intelligent structure model to the Source transformation for some source types that use an Amazon S3 or Microsoft Azure Data Lake connection. You must create the model before you can add it to the mapping. For more information about intelligent structure models, see Components.
4To configure a source filter or sort options, expand Query Options. Click Configure to configure a filter or sort option.
5Click the Fields tab to add or remove source fields, to update field metadata, or to synchronize fields with the source.
You can't update field metadata for mappings in SQL ELT mode.
6To save your changes and continue, click Save.
Configuring the data flow
To configure the data flow, optionally add transformations to the mapping.
1To add a transformation, perform either of the following actions:
- On the transformation palette, drag the transformation onto the mapping canvas. If you drop the transformation between two transformations that are connected, the Mapping Designer automatically connects the new transformation to the two transformations.
- On the mapping canvas, hover over the link between transformations or select an unconnected transformation and click the Add Transformation icon. Then select a transformation from the menu.
2On the General tab, enter a name and description for the transformation.
3Link the new transformation to appropriate transformations on the canvas.
When you link transformations, the downstream transformation inherits the incoming fields from the previous transformation.
For a Joiner transformation, draw a master link and a detail link.
4To preview fields, configure the field rules, or rename fields, click Incoming Fields.
5Configure additional transformation properties, as needed.
The properties that you configure vary based on the type of transformation you create. For more information about transformations and transformation properties, see Transformations.
6To save your changes and continue, click Save.
7To add another transformation, repeat these steps.
Configuring the target
To configure the target, edit the Target transformation.
1On the mapping canvas, click the Target transformation.
2Link the Target transformation to the appropriate upstream transformation.
3On the General tab, enter the target name and optional description.
4Click the Incoming Fields tab to preview incoming fields, configure field rules, or rename fields.
5Click the Target tab and configure target details and advanced properties.
Target details and advanced target properties vary based on the connection type. For more information, see the help for the appropriate connector.
In the target details, select the target connection, target object, and target operation. In mappings in SQL ELT mode, the target connection is automatically configured with the connection you selected when you created the mapping.
If your organization administrator has configured Enterprise Data Catalog integration properties, and you have added objects to the mapping from the Data Catalog page, you can select the target object from the Inventory panel. The Inventory panel isn't available in mappings in SQL ELT mode.
You can also configure parameters for the target connection and target object.
6Click Field Mapping and map the fields that you want to write to the target.
Rules and guidelines for mapping configuration
Use the following rules and guidelines when you configure a mapping:
•A mapping does not need a Source transformation if it includes a Mapplet transformation and the mapplet includes a source.
•If it's not a mapping in SQL ELT mode, you can configure multiple branches within the data flow. If you create more than one data flow, configure the flow run order.
•Connect all transformations to the data flow.
•You can merge multiple upstream branches through a passive transformation only when all transformations in the branches are passive.
•Field, object, and schema names can have up to 255 characters.
•When you rename fields, update conditions and expressions that use the fields. Conditions and expressions, such as a Lookup condition or expression in an Expression transformation, don't inherit field name changes.
•To use a connection parameter and a specific object, use a connection and object in the mapping. When the mapping is complete, you can replace the connection with a parameter. Don't change the object after parameterizing the connection.
•When you use a parameter for an object, use parameters for all conditions or field mappings in the data flow that use fields from the object.
•You can copy and paste multiple transformations at once between the following open assets:
- Between mappings
- Between mapplets
- From a mapping to a mapplet
When you paste a transformation into another asset, all transformation attributes except parameter values are copied to the asset.
Rules and guidelines for mappings on GPU-enabled clusters
Use the following rules and guidelines when you configure a mapping that runs on a GPU-enabled advanced cluster:
•The size of a partition file must be smaller than the GPU memory size. To check the GPU memory size, refer to the AWS documentation for the selected worker instance type.
•The mapping cannot read from an Amazon Redshift source or a source based on an intelligent structure model.
•The mapping cannot write to a CSV file.
•If the mapping includes NaN values, the output is unpredictable.
•The mapping cannot process timestamp data types from a Parquet source.
•If you need to process decimal data from a CSV file, read the data as a string and then convert it to a float.
•When the mapping uses an Expression transformation, you can use only scientific functions and the following numeric functions:
- ABS
- CEIL
- FLOOR
- LN
- LOG
- POWER
- SQRT
To learn how to configure a GPU-enabled cluster, see the Administrator help.
Data flow run order
You can specify the order in which Data Integration runs the individual data flows in a mapping. Specify the flow run order when you want Data Integration to load the targets in the mapping in a particular order. For example, you might want to specify the flow run order when inserting, deleting, or updating tables with primary or foreign key constraints.
You might want to specify the flow run order to maintain referential integrity when updating tables that have primary or foreign key constraints. Or, you might want to specify the flow run order when you are processing staged data.
If a flow contains multiple targets, you cannot configure the load order of the targets within the flow.
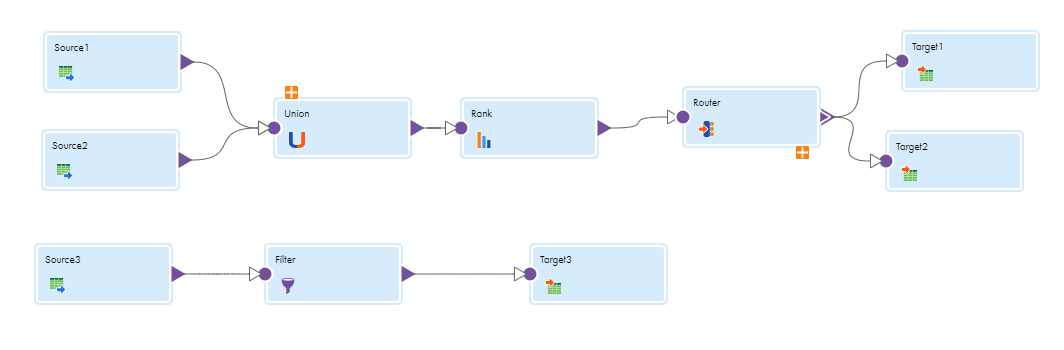
The following image shows a mapping with two data flows:
In this example, the top flow contains two pipelines and the bottom flow contains one pipeline. A pipeline is a source and all the transformations and targets that receive data from that source. When you configure the flow run order, you cannot configure the run order of the pipelines within a data flow.
The following image shows the flow run order for the mapping:
In this example, Data Integration runs the top flow first, and loads Target3 before running the second flow. When Data Integration runs the second flow, it loads Target1 and Target2 concurrently.
If you add another data flow to the mapping after you configure the flow run order, the new flow is added to the end of the flow run order by default.
If the mapping contains a mapplet, Data Integration uses the data flows in the last version of the mapplet that was synchronized. If you synchronize a mapplet and the new version adds a data flow to the mapping, the new flow is added to the end of the flow run order by default. You cannot specify the flow run order in mapplets.
You can specify the flow run order for data flows with any target type. You can define the data flow run order during SQL ELT optimization in a mapping that uses the following connections:
•Amazon Redshift V2
•Databricks Delta
•Google BigQuery V2
•Microsoft Azure Synapse SQL
•ODBC
•Snowflake Data Cloud
For more information, see the appropriate connector guides.
Note:
You can also specify the run order of data flows in separate mapping tasks with taskflows. Configure the taskflow to run the tasks in a specific order. For more information about taskflows, see Taskflows.
You can't specify the data flow run order in mappings in advanced mode or SQL ELT mode because these mappings can't have multiple flows.
Configuring the data flow run order
Configure the order in which Data Integration runs the data flows in a mapping.
1In the Mapping Designer, click Actions and select Flow Run Order.
2In the Flow Run Order dialog box, select a data flow and use the arrows to move it up or down.