The Hierarchy Processor transformation can convert a hierarchical input group to a flattened denormalized output group.
For example, you have a shop maintenance file that contains customer and vehicle information for all your customers. You want to denormalize the vehicle maintenance data and exclude personal information about the customers.
Defining flattened output with the Hierarchy Processor transformation
Use the Hierarchy Processor tab to map incoming fields to output fields. The flattened output option allows you to create denormalized output.
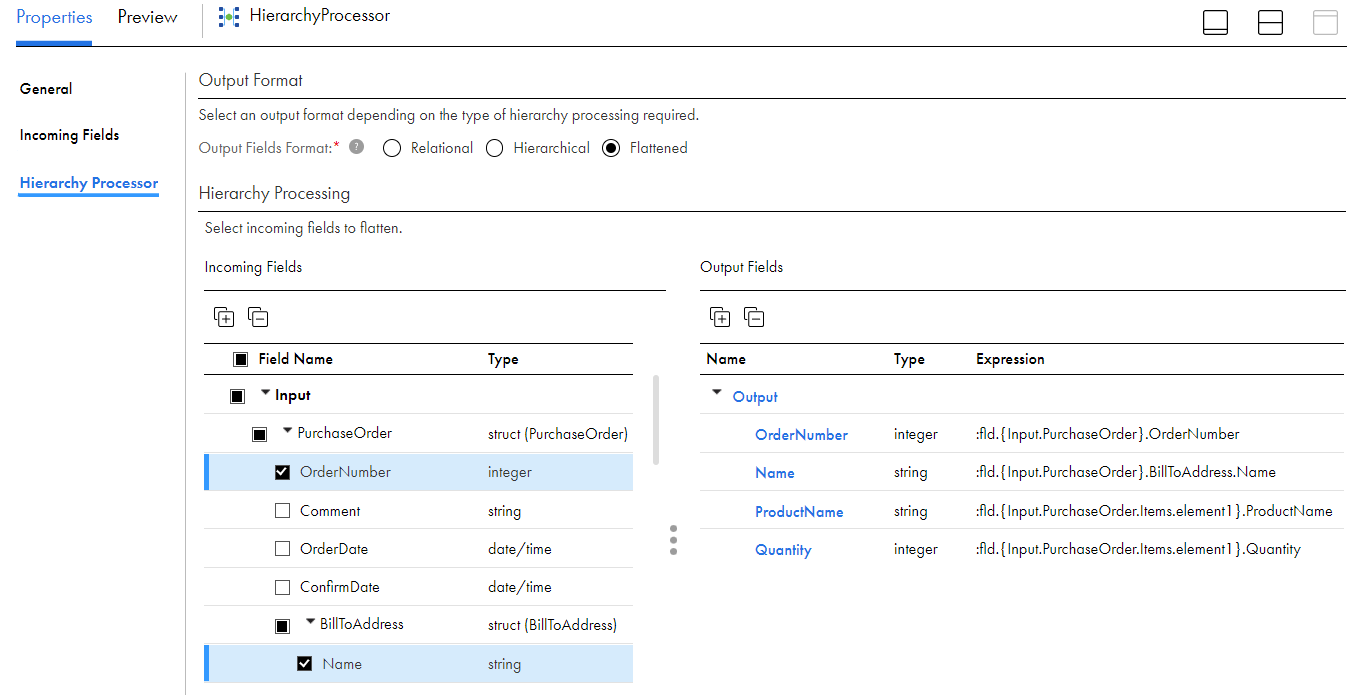
The following image shows the Hierarchy Processor tab with hierarchical input and flattened output:
1Output format. Select Flattened to convert hierarchical input into denormalized output.
2Incoming fields. View the incoming data schema and field types.
3Output fields. View the output fields as you create the output file.
4Configure the output. Select incoming fields to build the flattened output file schema.
5Output field names. Click on a field name to modify the field name.
6Expression. View the field expressions to determine the input to output field mappings.
7Delete. Use to delete output fields.
Tip:
Use the maximize icon and resize the Incoming Fields panel or Output Fields panel to see the information you need.
To define a Hierarchy Processor transformation with flattened output, perform the following tasks:
1Select the Flattened output format.
2 Configure the transformation output by selecting incoming fields to add to the output.
3Optional. Rename output fields.
4Optional. Delete output fields.
Adding incoming fields to flattened output groups
You can add incoming fields to the output individually or you can add an entire input group. After you add the incoming fields to the output group, you can rename or delete output fields as needed.
To add output fields, select the check box next to the input field or input group that you want to add. Selecting a parent automatically selects all child items, but you can deselect the entries that you do not want. You can also delete any unneeded entries from the output.
Flatten hierarchical data
When you add incoming hierarchical fields to the output, all fields in the output schema are automatically flattened.
Example of flattened hierarchical data
The incoming fields are contained within a hierarchy of structs and arrays. You just need four fields in the output: OrderNumber, Name, ProductName, and Quantity.
Select the appropriate check boxes to add the incoming fields to the output.
The following image shows the input and output:
Renaming flattened output group and fields
After you add incoming fields to the output group in the flattened format, you can change the names of these fields if necessary. You can also change the name of the output group.
To change the name of any output field, click on the field name. To change the name of the output group, click on the output group name.
The following table describes the properties for the output fields:
Property
Description
Name
The name of the output field.
Type
The data type of the current field. You cannot change the data type.
Precision
The total number of significant digits in the field. You cannot change the precision.
Scale
The number of digits to the right of the decimal point. You cannot change the scale.
Expression format
When you use the flattened output, the expression is fixed to the default and can't be changed. But if you understand the syntax of the default expression, you can easily identify the source location of each output field.
Tip:
To add fields to the output group, use the check boxes next to the incoming field names. This differs from the Add link that you use for relational or hierarchical output.
The Hierarchy Processor transformation can process information from different data sets. Some of the field names might not be unique among the different data sets. As a result, you can't simply reference the field by its name, because the same field name might be used in a different data set, or within the hierarchy of the same data set.
The syntax of the expressions in the Hierarchy Processor transformation differs from that used in the Expression transformation.
To reference a field in a Hierarchy Processor transformation, use the following syntax:
:fld.{input_group_name.field_name}.field_name
The following table describes the syntax in more detail:
Syntax part
Description
.fld.
Denotes the Hierarchy Processor transformation expression syntax.
input_group_name
Name of the input group or dataset.
field_name
Name of the field, including the full path name if it's not a top-level field.
If any field is of the type array, include the array name. If an array is primitive and has no array name, use elem as the array name.
For fields within a struct or an array, the actual field name is specified outside of the closing brace.
.field_name
Include the field_name portion only when referencing a field within a struct or an array. Follow these guidelines:
- For fields within a struct, the field_name portion uses the format: .structName.fieldname
- For fields within an array, the field_name portion uses the format: .fieldName
Running a mapping with JSON data
To run a mapping that contains a Hierarchy Processor transformation with JSON-formatted data, you need to use a mapping task.
Reading JSON input
When you read JSON data, the input files can be based on a schema with multiple lines or on a schema with a single line.
The following sample shows a JSON schema on a single line:
By default, the Hierarchy Processor transformation reads each JSON schema as a single line. To read input that spans across multiple lines, you can configure the formatting options in the Source transformation to read multiple-line JSON files.
Writing JSON output
When you write JSON data, you can write each output record to a separate file, or you can write all output records to one file.
By default, each output record is written to a separate file. To write the output records to one JSON-formatted file, set the following Spark session property in the mapping task:
Session Property Name
Session Property Value
spark.sql.shuffle.partitions
1
Hierarchical to flattened example
You want to convert hierarchical data to relational data and write the data to a target file in denormalized format.
A shop maintenance file contains the customer and vehicle information for customers. The file is in hierarchical JSON format and is generated by your company's shop application.
The following JSON script shows the shop maintenance source input before you run the mapping:


 selected; personal (struct) not selected; vehicles (array) selected. The vehicles array contains the type, model, insurance (struct), with policy_num field. The Output Fields panel contains one output group with the following string fields: type, model, policy_num, desc, cost, line1, line2.")
