The targets that Application Ingestion and Replication support depend on the sources specified for the application ingestion and replication tasks.
The following table shows the target types that are supported (S) for each load type:
Target Type
Initial Load
Incremental Load
Initial and Incremental Loads
Amazon Redshift
S
S
S
Amazon S3
S
S
S
Apache Kafka
-
S
-
Databricks
S
S
S
Google BigQuery
S
S
S
Google Cloud Storage
S
S
S
Microsoft Azure Data Lake Storage Gen2
S
S
S
Microsoft Azure SQL Database
S
S
S
Microsoft SQL Server
S
S
S
Microsoft Azure Synapse Analytics
S
S
S
Microsoft Fabric OneLake
S
S
S
Oracle
S
S
S
Oracle Cloud Infrastructure (OCI) Object Storage
S
S
S
PostgreSQL
S
S
S
Snowflake
S
S
S
The following table lists the targets that Application Ingestion and Replication support for each source type:
Source type
Supported target type
Adobe Analytics
Amazon Redshift, Amazon S3, Apache Kafka, Databricks, Google BigQuery, Google Cloud Storage, Microsoft Azure Data Lake Storage Gen2, Microsoft Azure Synapse Analytics, Microsoft Fabric OneLake, Oracle, Oracle Cloud Infrastructure Object Storage, and Snowflake
Google Analytics
Amazon Redshift, Amazon S3, Apache Kafka, Databricks, Google BigQuery, Google Cloud Storage, Microsoft Azure Data Lake Storage Gen2, Microsoft Azure Synapse Analytics, Microsoft Fabric OneLake, Oracle, Oracle Cloud Infrastructure Object Storage, and Snowflake
Marketo
Amazon Redshift, Amazon S3, Apache Kafka, Databricks, Google BigQuery, Google Cloud Storage, Microsoft Azure Data Lake Storage Gen2, Microsoft Azure Synapse Analytics, Microsoft Fabric OneLake, Oracle, Oracle Cloud Infrastructure Object Storage, and Snowflake
Microsoft Dynamics 365
Amazon Redshift, Amazon S3, Apache Kafka, Databricks, Google BigQuery, Google Cloud Storage, Microsoft Azure Data Lake Storage Gen2, Microsoft Azure Synapse Analytics, Microsoft Azure SQL Database, Microsoft SQL Server, Microsoft Fabric OneLake, Oracle, Oracle Cloud Infrastructure Object Storage, and Snowflake
NetSuite
Amazon Redshift, Amazon S3, Apache Kafka, Databricks, Google BigQuery, Google Cloud Storage, Microsoft Azure Data Lake Storage Gen2, Microsoft Azure Synapse Analytics, Microsoft Fabric OneLake, Oracle, Oracle Cloud Infrastructure Object Storage, and Snowflake
Oracle Fusion Cloud
- Using REST API - Amazon Redshift, Amazon S3, Apache Kafka, Databricks, Google BigQuery, Google Cloud Storage, Microsoft Azure Data Lake Storage Gen2, Microsoft Azure Synapse Analytics, Microsoft Fabric OneLake, Oracle, Oracle Cloud Infrastructure Object Storage, and Snowflake
- Using BICC - Amazon Redshift, Amazon S3, Apache Kafka, Databricks, Google BigQuery, Google Cloud Storage, Microsoft Azure Data Lake Storage Gen2, Microsoft Azure Synapse Analytics, Microsoft Fabric OneLake, Oracle, Oracle Cloud Infrastructure Object Storage, and Snowflake
Salesforce
Amazon Redshift, Amazon S3, Apache Kafka, Databricks, Google BigQuery, Google Cloud Storage, Microsoft Azure Data Lake Storage Gen2, Microsoft Azure Synapse Analytics, Oracle, Microsoft Azure SQL Database, Microsoft SQL Server, Microsoft Fabric OneLake, PostgreSQL, and Snowflake
Salesforce Marketing Cloud
Amazon Redshift, Amazon S3, Databricks, Google BigQuery, Google Cloud Storage, Microsoft Azure Data Lake Storage Gen2, Microsoft Azure Synapse Analytics, Microsoft Fabric OneLake, Oracle, Oracle Cloud Infrastructure Object Storage, and Snowflake
SAP
- Using SAP ODP Extractor connector - Amazon Redshift, Amazon S3, Apache Kafka, Databricks, Google BigQuery, Google Cloud Storage, Microsoft Azure Data Lake Storage Gen2, Microsoft Azure Synapse Analytics, Microsoft Fabric OneLake, Oracle, Oracle Cloud Infrastructure Object Storage, and Snowflake
- Using SAP Mass Ingestion connector - Amazon Redshift, Amazon S3, Apache Kafka, Databricks, Google BigQuery, Google Cloud Storage, Microsoft Azure Data Lake Storage Gen2, Microsoft Azure Synapse Analytics, Microsoft Azure SQL Database, Microsoft SQL Server, Microsoft Fabric OneLake, Oracle, Oracle Cloud Infrastructure Object Storage, PostgreSQL, and Snowflake
- Using SAP OData V2 connector - Snowflake
ServiceNow
Amazon Redshift, Apache Kafka, Databricks, Amazon S3, Google BigQuery, Google Cloud Storage, Microsoft Azure Data Lake Storage Gen2, Microsoft Azure Synapse Analytics, Microsoft Fabric OneLake, Oracle, Oracle Cloud Infrastructure Object Storage, and Snowflake
Workday
- SOAP. Amazon Redshift, Amazon S3, Apache Kafka, Databricks, Google BigQuery, Google Cloud Storage, Microsoft Azure Data Lake Storage Gen2, Microsoft Azure Synapse Analytics, Microsoft Fabric OneLake, Oracle, Oracle Cloud Infrastructure Object Storage, and Snowflake
- RaaS. Amazon Redshift, Amazon S3, Databricks, Google BigQuery, Google Cloud Storage, Microsoft Azure Data Lake Storage Gen2, Microsoft Azure Synapse Analytics, Microsoft Fabric OneLake, Oracle, Oracle Cloud Infrastructure Object Storage, and Snowflake (for initial load)
Zendesk
Amazon Redshift, Amazon S3, Apache Kafka, Databricks, Google BigQuery, Google Cloud Storage, Microsoft Azure Data Lake Storage Gen2, Microsoft Azure Synapse Analytics, Microsoft Fabric OneLake, Oracle, Oracle Cloud Infrastructure Object Storage, and Snowflake
To determine the connectors to use for the target types, see Connectors and Connections > Application Ingestion and Replication connectors.
Guidelines for Amazon Redshift targets
Consider the following guidelines when you use Amazon Redshift targets:
Target preparation
Ensure that the Redshift database user has the following minimum permissions required for Application Ingestion and Replication:
grant create on database <database_name> to <username>; grant create on schema <schema_name> to <username>;
If you use Redshift role-based access control (RBAC), grant these permissions to the appropriate roles. With these permissions, users can perform all Application Ingestion and Replication operations, including deploying tasks, having target tables created at runtime, and redeploying, resynchronizing, and resuming jobs.
To check if a user already has the permissions required to access the database and schema, use the following system functions:
Note: If you create a new database user, you must explicitly grant the permissions needed to access the existing database, schema, and table objects to that user.
Usage considerations
•Before writing data to Amazon Redshift target tables, application ingestion and replication jobs stage the data in an Amazon S3 bucket. You must specify the name of the bucket when you configure the application ingestion and replication task. The ingestion jobs use the COPY command to load the data from the Amazon S3 bucket to the Amazon Redshift target tables. For more information about the COPY command, see the Amazon Web Services documentation.
•When you define a connection for an Amazon Redshift target, provide the access key and secret access key for the Amazon S3 bucket in which you want the application ingestion and replication jobs to stage the data before loading it to the Amazon Redshift target tables.
•When you ingest data from a source to an Amazon Redshift target, the application ingestion and replication job fails if the data source contains more than 32 data fields or columns that are defined as primary keys.
•Incremental load jobs and combined initial and incremental load jobs generate a recovery table named INFORMATICA_CDC_RECOVERY on the target to store internal service information. The data in the recovery table prevents the jobs that are restarted after a failure from propagating previously processed data again. The recovery table is generated in the schema of the target tables.
Guidelines for Amazon S3, Google Cloud Storage, Microsoft Azure Data Lake Storage Gen2, Microsoft Fabric OneLake, and Oracle Cloud Object Storage targets
Consider the following guidelines when you use Amazon S3, Google Cloud Storage, Microsoft Azure Data Lake Storage Gen2, Microsoft Fabric OneLake, and Oracle Cloud Infrastructure (OCI) Object Storage targets:
•When you configure an application ingestion and replication task for an Amazon S3, Google Cloud Storage, Microsoft Azure Data Lake Storage Gen2, Microsoft Fabric OneLake, or Oracle Cloud Object Storage target, you can select CSV, Avro, or Parquet as the format for the output files that contain the source data to be applied to the target.
•If you select CSV as the output file format, Application Ingestion and Replication creates the following files on the target for each source field:
- schema.ini file that describes the schema of the field. The file also includes some settings for the output file on the target.
- Output files that contain the data stored in the source field. Application Ingestion and Replication names the output files based on the name of the source field with an appended date and time.
The schema.ini file lists the sequence of columns for the rows in the corresponding output file. The following table describes the columns in the schema.ini file:
Column
Description
ColNameHeader
Indicates whether the source data files include column headers.
Format
Format of the output files. Application Ingestion and Replication uses a comma (,) to delimit column values.
CharacterSet
Character set that is used for the corresponding output file. By default, Application Ingestion and Replication generates the files in the UTF-8 character set.
COL<sequence_number>
Name and data type of the source field.
Note: You must not edit the schema.ini file.
•If you select the Avro output format, you can select an Avro format type, a file compression type, an Avro data compression type, and the directory that stores the Avro schema definitions generated for each source table. The schema definition files have the following naming pattern: schemaname_tablename.txt.
•If you select the Parquet output format, you can optionally select a compression type that Parquet supports.
•For application ingestion and replication tasks configured for Microsoft Azure Data Lake Storage Gen2 and Microsoft Fabric OneLake targets, Application Ingestion and Replication creates an empty directory on the target for each empty source field.
•For Amazon S3 targets, if you do not specify an access key and secret key in the connection properties, Application Ingestion and Replication tries to find the AWS credentials by using the default credential provider chain that is implemented by the DefaultAWSCredentialsProviderChain class. For more information, see the Amazon Web Services documentation.
•When an incremental load job or combined initial and incremental load job configured for a target that uses the CSV output format propagates an Update operation that changed primary key values on the source, the job performs a Delete operation on the associated target row and then performs an Insert operation on the same row to replicate the change made to the source object. The Delete operation writes the before image to the target and the subsequent Insert image writes the after image to the target.
For Update operations that do not change primary key values, application ingestion and replication jobs process each Update operation as a single operation and writes only the after image to the target. Application Ingestion and Replication processes each Update operation performed on the source as a Delete operation followed by an Insert operation on the target.
Default directory structure of CDC files on Amazon S3, Google Cloud Storage, Microsoft Azure Data Lake Storage Gen2, and Microsoft Fabric OneLake targets
Application ingestion and replication jobs create directories on Amazon S3, Google Cloud Storage, Microsoft Azure Data Lake Storage Gen2, and Microsoft Fabric OneLake targets to store information about change data processing.
The following directory structure is created by default on the targets:
The following table describes the directories in the default structure:
Folder
Description
connection_folder
Contains the Application Ingestion and Replication objects. This folder is specified in the Folder Path field of the Amazon S3 connection properties, in the Directory Path field of the Microsoft Azure Data Lake Storage Gen2 connection properties, or in the Lakehouse Path field of the Microsoft Fabric OneLake connection properties.
Note: This folder is not created for Google Cloud Storage targets.
job_folder
Contains job output files. This folder is specified in the Directory field on the Target page of the application ingestion and replication task wizard.
cycle/Completed
Contains a subfolder for each completed CDC cycle. Each cycle subfolder contains a completed cycle file.
cycle/Contents
Contains a subfolder for each CDC cycle. Each cycle subfolder contains a cycle contents file.
data
Contains output data files and schema files for each object.
data/object_name/Schema/V1
Contains a schema file.
Note: Application Ingestion and Replication does not save a schema file in this folder if the output files use the Parquet format.
data/object_name/Data
Contains a subfolder for each CDC cycle that produces output data files.
Cycle directories
Application Ingestion and Replication uses the following pattern to name cycle directories:
[dt=]yyyy-mm-dd-hh-mm-ss
The "dt=" prefix is added to cycle folder names if you select the Add Directory Tags check box on the Target page of the application ingestion and replication task wizard.
Cycle contents files
Cycle contents files are located in cycle/Contents/cycle_folder subdirectories. Cycle contents files contain a record for each object that has had a DML event during the cycle. If no DML operations occurred on an object in the cycle, the object does not appear in the cycle contents file.
Application Ingestion and Replication uses the following pattern to name cycle content files:
Cycle-contents-timestamp.csv
A cycle contents csv file contains the following information:
•Object name
•Cycle name
•Path to the cycle folder for the object
•Start sequence for the object
•End sequence for the object
•Number of Insert operations
•Number of Update operations
•Number of Delete operations
•Combined load jobs only. Number of Insert operations encountered during the initial load phase
•Combined load jobs only. Number of Delete operations encountered during the initial load phase
•Schema version
•Path to the schema file for the schema version
Note: If the output data files use the Parquet format, Application Ingestion and Replication does not save a schema file at the path that is specified in the cycle contents file. Instead, use the schema file in the folder that is specified in the Avro Schema Directory field on the Target page of the application ingestion and replication task wizard.
Completed cycle files
Completed cycle files are located in cycle/Completed/completed_cycle_folder subdirectories. An application ingestion and replication job creates a cycle file in this subdirectory after a cycle completes. If this file is not present, the cycle has not completed yet.
Application Ingestion and Replication uses the following pattern to name completed cycle files:
Cycle-timestamp.csv
A completed cycle csv file contains the following information:
•Cycle name
•Cycle start time
•Cycle end time
•Current sequence number at the time the cycle ended
•Path to the cycle contents file
•Reason for the end of cycle
Valid reason values are:
- NORMAL_COMMIT. A commit operation was encountered after the cycle had reached the DML limit or the end of the cycle interval. A cycle can end only on a commit boundary.
- NORMAL_EXPIRY. The cycle ended because the cycle interval expired. The last operation was a commit.
- Combined load jobs only:BACKLOG_COMPLETED. The cycle ended because CDC backlog processing completed. The CDC backlog consists of events captured during the initial load phase of the combined job. The backlog includes potential DML changes captured at the beginning or end of the initial load phase and during the transition from the initial load phase to the main CDC incremental processing.
- Combined load jobs only:INITIAL_LOAD_COMPLETED. The cycle ended because the initial load completed.
- Combined load jobs only:RESYNC_STARTED. The cycle ended because the object resync initiated.
Output data files
The data files contain records that include the following information:
•Operation type. Valid values are:
- I for Insert operations
- E for Update operations
- D for Delete operations
- Combined load jobs only:X for Delete operations encountered during the initial load phase of a combined load job
- Combined load jobs only:Y for Insert operations encountered during the initial load phase of a combined load job
•Sortable sequence number. In combined initial and incremental load jobs, the sortable sequence number contains a 20-digit prefix that can be used to align rows with the resync version and the load job. The prefix is a combination of the following attributes:
1Incarnation. This nine-digit number is incremented each time the object is resynced. The initial value is 1.
2Schema version. This nine-digit number is incremented each time a schema drift change is propagated for the object. The initial value is 1.
3Phase. This two-digit number changes when transition from unload, to backlog, to CDC is performed. Valid values are:
▪ 00 for Truncation, which is the first data record written during initial load or resync
▪ 01 for a normal insert during initial load or resync
▪ 02 for a change detected during the initial load
▪ 03 for a change detected after the initial load or resync is completed but before the transition back to the main CDC phase
▪ 04 for a change detected during the normal CDC phase
•Data fields
Note: Insert and Delete records contain only after images. Update records contain both before and after images.
Custom directory structure for output files on Amazon S3, Google Cloud Storage, Microsoft Fabric OneLake, and ADLS Gen2 targets
You can configure a custom directory structure for the output files that initial load, incremental load, and combined initial and incremental load jobs write to Amazon S3, Google Cloud Storage, Microsoft Azure Data Lake Storage (ADLS) Gen2, and Microsoft Fabric OneLake targets if you do not want to use the default structure.
Initial loads
By default, initial load jobs write output files to tablename_timestamp subdirectories under the parent directory. For Amazon S3 and ADLS Gen2 targets, the parent directory is specified in the target connection properties if the Connection Directory as Parent check box is selected on the Target page of the task wizard.
•In an Amazon S3 connection, this parent directory is specified in the Folder Path field.
•In an ADLS Gen2 connection, the parent directory is specified in the Directory Path field.
For Google Cloud Storage targets, the parent directory is the bucket container specified in the Bucket field on the Target page of the task wizard.
For Microsoft Fabric OneLake targets, the parent directory is the path specified in the Lakehouse Path field in the Microsoft Fabric OneLake connection properties.
You can customize the directory structure to suit your needs. For example, for initial loads, you can write the output files under a root directory or directory path that is different from the parent directory specified in the connection properties to better organize the files for your environment or to find them more easily. Or you can consolidate all output files for a table directly in a directory with the table name rather than write the files to separate timestamped subdirectories, for example, to facilitate automated processing of all of the files.
To configure a directory structure, you must use the Data Directory field on the Target page of the ingestion task wizard. The default value is {TableName}_{Timestamp}, which causes output files to be written to tablename_timestamp subdirectories under the parent directory. You can configure a custom directory path by creating a directory pattern that consists of any combination of case-insensitive placeholders and directory names. The placeholders are:
•{TableName} for a target table name
•{Timestamp} for the date and time, in the format yyyymmdd_hhmissms, at which the initial load job started to transfer data to the target
•{Schema} for the target schema name
•{YY} for a two-digit year
•{YYYY} for a four-digit year
•{MM} for a two-digit month value
•{DD} for a two-digit day in the month
A pattern can also include the following functions:
•toLower() to use lowercase for the values represented by the placeholder in parentheses
•toUpper() to use uppercase for the values represented by the placeholder in parentheses
By default, the target schema is also written to the data directory. If you want to use a different directory for the schema, you can define a directory pattern in the Schema Directory field.
Example 1
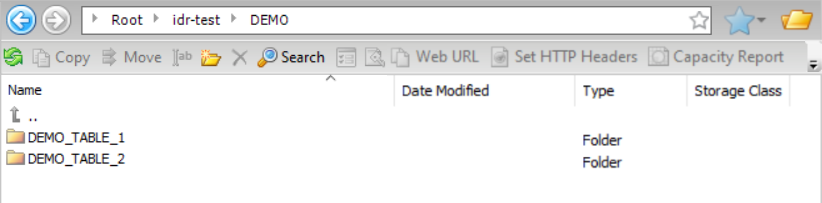
You are using an Amazon S3 target and want to write output files and the target schema to the same directory, which is under the parent directory specified in the Folder Path field of the connection properties. In this case, the parent directory is idr-test/DEMO/. You want to write all of the output files for a table to a directory that has a name matching the table name, without a timestamp. You must complete the Data Directory field and select the Connection Directory as Parent check box.
Based on this configuration, the resulting directory structure is:
Example 2
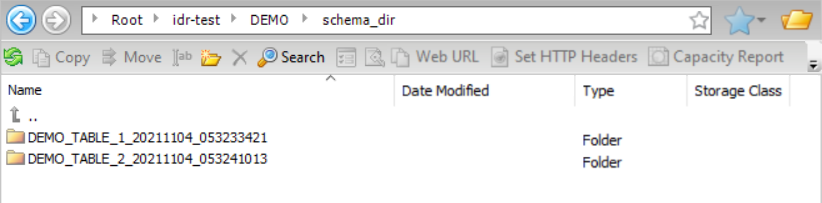
You are using an Amazon S3 target and want to write output data files to a custom directory path and write the target schema to a separate directory path. To use the directory specified in the Folder Path field in the Amazon S3 connection properties as the parent directory for the data directory and schema directory, select Connection Directory as Parent. In this case, the parent directory is idr-test/DEMO/. In the Data Directory and Schema Directory fields, define directory patterns by using a specific directory name, such as data_dir and schema_dir, followed by the default {TableName}_{Timestamp} placeholder value. The placeholder creates tablename_timestamp destination directories.
Based on this configuration, the resulting data directory structure is:
And the resulting schema directory structure is:
Incremental loads and combined initial and incremental loads
By default, incremental load and combined initial and incremental load jobs write cycle files and data files to subdirectories under the parent directory. However, you can create a custom directory structure to organize the files to best suit your organization's requirements.
This feature applies to application ingestion and replication incremental load jobs that have a Salesforce source and Amazon S3, Google Cloud Storage, Microsoft Fabric OneLake, or Microsoft Azure Data Lake Storage (ADLS) Gen2 targets.
For Amazon S3 and ADLS Gen2 targets, the parent directory is set in the target connection properties if the Connection Directory as Parent check box is selected on the Target page of the task wizard.
•In an Amazon S3 connection, the parent directory is specified in the Folder Path field.
•In an ADLS Gen2 connection, the parent directory is specified in the Directory Path field.
For Google Cloud Storage targets, the parent directory is the bucket container specified in the Bucket field on the Target page of the task wizard.
For Microsoft Fabric OneLake targets, the parent directory is the path specified in the Lakehouse Path field in the Microsoft Fabric OneLake connection properties.
You can customize the directory structure to suit your needs. For example, you can write the data and cycle files under a target directory for the task instead of under the parent directory specified in the connection properties. Alternatively, you can 1) consolidate table-specific data and schema files under a subdirectory that includes the table name, 2) partition the data files and summary contents and completed files by CDC cycle, or 3) create a completely customized directory structure by defining a pattern that includes literal values and placeholders. For example, if you want to run SQL-type expressions to process the data based on time, you can write all data files directly to timestamp subdirectories without partitioning them by CDC cycle.
To configure a custom directory structure for an incremental load task, define a pattern for any of the following optional fields on the Target page of the ingestion task wizard:
Field
Description
Default
Task Target Directory
Name of a root directory to use for storing output files for an incremental load task.
If you select the Connection Directory as Parent option, you can still optionally specify a task target directory. It will be appended to the parent directory to form the root for the data, schema, cycle completion, and cycle contents directories.
This field is required if the {TaskTargetDirectory} placeholder is specified in patterns for any of the following directory fields.
None
Connection Directory as Parent
Select this check box to use the parent directory specified in the connection properties.
This field is not available for the Microsoft Fabric OneLake target.
Selected
Data Directory
Path to the subdirectory that contains the data files.
In the directory path, the {TableName} placeholder is required if data and schema files are not partitioned by CDC cycle.
{TaskTargetDirectory}/data/{TableName}/data
Schema Directory
Path to the subdirectory in which to store the schema file if you do not want to store it in the data directory.
In the directory path, the {TableName} placeholder is required if data and schema files are not partitioned by CDC cycle.
{TaskTargetDirectory}/data/{TableName}/schema
Cycle Completion Directory
Path to the directory that contains the cycle completed file.
{TaskTargetDirectory}/cycle/completed
Cycle Contents Directory
Path to the directory that contains the cycle contents files.
{TaskTargetDirectory}/cycle/contents
Use Cycle Partitioning for Data Directory
Causes a timestamp subdirectory to be created for each CDC cycle, under each data directory.
If this option is not selected, individual data files are written to the same directory without a timestamp, unless you define an alternative directory structure.
Selected
Use Cycle Partitioning for Summary Directories
Causes a timestamp subdirectory to be created for each CDC cycle, under the summary contents and completed subdirectories.
Selected
List Individual Files in Contents
Lists individual data files under the contents subdirectory.
If Use Cycle Partitioning for Summary Directories is cleared, this option is selected by default. All of the individual files are listed in the contents subdirectory unless you can configure custom subdirectories by using the placeholders, such as for timestamp or date.
If Use Cycle Partitioning for Data Directory is selected, you can still optionally select this check box to list individual files and group them by CDC cycle.
Not selected if Use Cycle Partitioning for Summary Directories is selected.
Selected if you cleared Use Cycle Partitioning for Summary Directories.
A directory pattern consists of any combination of case-insensitive placeholders, shown in curly brackets { }, and specific directory names. The following placeholders are supported:
•{TaskTargetDirectory} for a task-specific base directory on the target to use instead of the directory the connection properties
•{TableName} for a target table name
•{Timestamp} for the date and time, in the format yyyymmdd_hhmissms
•{Schema} for the target schema name
•{YY} for a two-digit year
•{YYYY} for a four-digit year
•{MM} for a two-digit month value
•{DD} for a two-digit day in the month
Note: The timestamp, year, month, and day placeholders indicate when the CDC cycle started when specified in patterns for data, contents, and completed directories, or indicate when the CDC job started when specified in the schema directory pattern.
Example 1
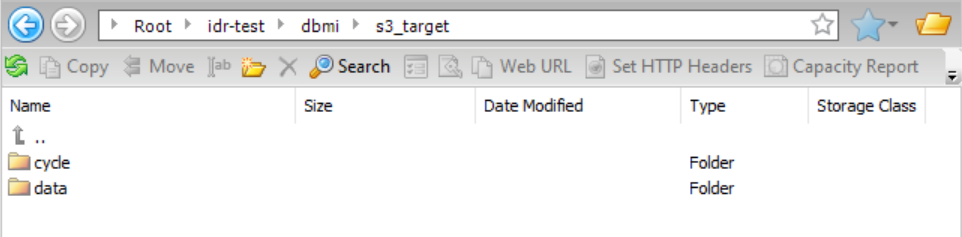
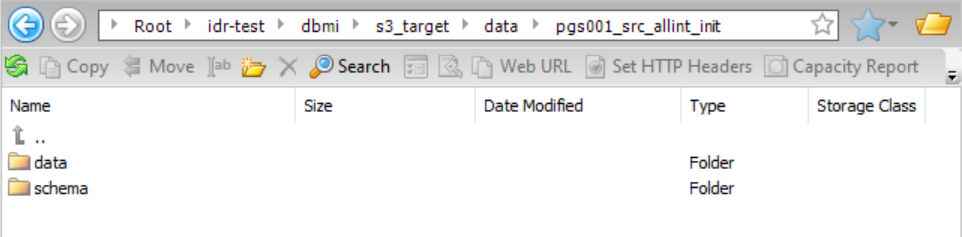
You want to accept the default directory settings for incremental load jobs as displayed in the task wizard. The target type is Amazon S3. Because the Connection Directory as Parent check box is selected by default, the parent directory path that is specified in the Folder Path field of the Amazon S3 connection properties is used. This parent directory is idr-test/dbmi/. You also must specify a task target directory name, in this case, s3_target, because the {TaskTargetDirectory} placeholder is used in the default patterns in the subsequent directory fields. The files in the data directory and schema directory will be grouped by table name because the {TableName} placeholder is included in their default patterns. Also, because cycle partitioning is enabled, the files in the data directory, schema directory, and cycle summary directories will be subdivided by CDC cycle.
Based on this configuration, the resulting data directory structure is:
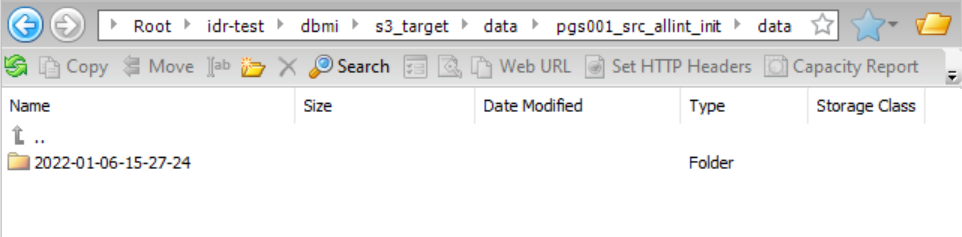
If you drill down on the data folder and then on a table in that folder (pgs001_src_allint_init), you can access the data and schema subdirectories:
If you drill down on the data folder, you can access the timestamp directories for the data files:
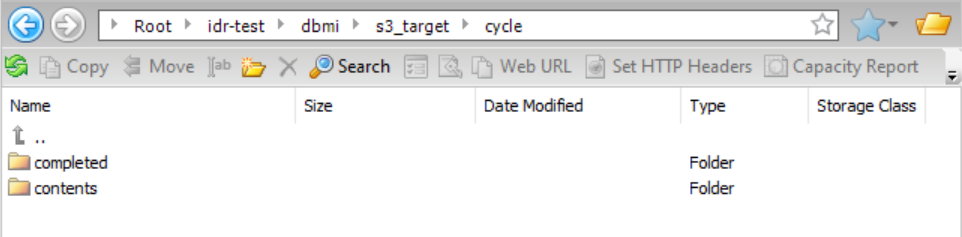
If you drill down on cycle, you can access the summary contents and completed subdirectories:
Example 2
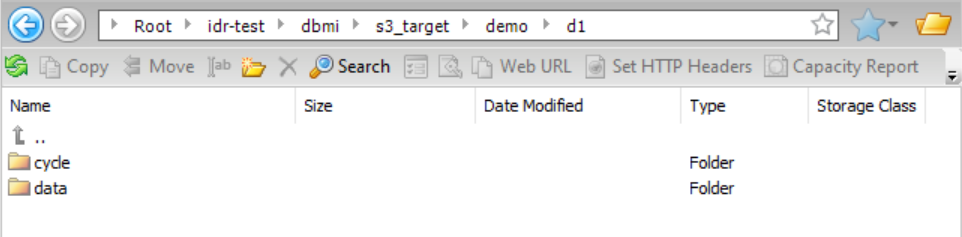
You want to create a custom directory structure for incremental load jobs that adds the subdirectories "demo" and "d1" in all of the directory paths except in the schema directory so that you can easily find the files for your demos. Because the Connection Directory as Parent check box is selected, the parent directory path (idr-test/dbmi/) that is specified in the Folder Path field of the Amazon S3 connection properties is used. You also must specify the task target directory because the {TaskTargetDirectory} placeholder is used in the patterns in the subsequent directory fields. The files in the data directory and schema directory will be grouped by table name. Also, because cycle partitioning is enabled, the files in the data, schema, and cycle summary directories will be subdivided by CDC cycle.
Based on this configuration, the resulting data directory structure is:
Guidelines for Apache Kafka targets
Consider the following guidelines when you use Apache Kafka targets:
•Application Ingestion and Replication supports Apache Kafka, Confluent Kafka, Amazon Managed Streaming for Apache Kafka (MSK), and Kafka-enabled Azure Event Hubs as targets for incremental load jobs. All of these Kafka target types use the Kafka connection type.
To indicate the Kafka target type, you must specify Kafka producer properties in the task definition or Kafka connection properties. To specify these properties for a task, enter a comma-separated list of key:value pairs in the Producer Configuration Properties field on the Target page of the task wizard. To specify the producer properties for all tasks that use a Kafka connection, enter the list of properties in the Additional Connection Properties field in the connection properties. You can override the connection-level properties for specific tasks by also defining producer properties at the task level. For more information about producer properties, see the Apache Kafka, Confluent Kafka, Amazon MSK, or Azure Event Hubs for Kafka documentation.
• If you select AVRO as the output format for a Kafka target, Application Ingestion and Replication generates a schema definition file for each table with a name in the following format:
schemaname_tablename.txt
•If a source schema change is expected to alter the target in an incremental load job, Application Ingestion and Replication regenerates the Avro schema definition file with a unique name that includes a timestamp:
schemaname_tablename_YYYYMMDDhhmmss.txt
This unique naming pattern preserves older schema definition files for audit purposes.
•If you have a Confluent Kafka target that uses Confluent Schema Registry to store schemas, you must configure the following settings on the Target page of the task wizard:
- In the Output Format field, select AVRO.
- In the Avro Serialization Format field, select None.
•You can specify Kafka producer properties in either the Producer Configuration Properties field on the Target page of the task wizard or in the Additional Connection Properties field in the Kafka connection properties. Enter property=value pairs that meet your business needs and that are supported by your Kafka vendor.
For example, if you use Confluent Kafka, you can use the following entry in either the Producer Configuration Properties field or Additional Connection Properties field to specify the Schema Registry URL and enable basic authentication:
If you use Amazon MSK, you can use the following Additional Connection Properties entry to enable IAM role authentication for access to Amazon MSK targets:
Ensure that you enable IAM role authentication on the Amazon EC2 instance where the Secure Agent is installed.
For more information about Kafka properties, see the documentation of your Kafka vendor.
•Application Ingestion and Replication incremental load jobs can replicate change data to Kafka targets that support SASL_SSL secured access, including Confluent Kafka, Amazon MSK, and Azure Event Hubs targets. In Administrator, you must configure a Kafka connection that includes the appropriate properties in the Additional Connection Properties field. For example, for Azure Event Hubs, you could use the following Additional Connection Properties entry to enable SASL_SSL:
•Since the July 2025 release of Data Ingestion and Replication, newly deployed jobs send the checkpoint information into the Kafka header for each message. The checkpoint information is retrieved from the Kafka header when the job is restarted. Previously, the checkpoint information was only persisted in the checkpoint file in the Secure Agent. Because of this enhancement, newly deployed jobs that have a Kafka target are not restricted from running on other Secure Agents due to having a Kafka target.
Guidelines for Databricks targets
Consider the following guidelines when you use Databricks targets:
• When you use a Databricks target for the first time, perform the following steps before you configure an application ingestion and replication task for the target:
1In the Databricks connection properties, set the JDBC Driver Class Name property to com.databricks.client.jdbc.Driver.
2On Windows, install Visual C++ Redistributable Packages for Visual Studio 2013 on the computer where the Secure Agent runs.
•For incremental load jobs, you must enable Change Data Capture (CDC) for all source fields.
• You can access Databricks tables created on top of the following storage types:
- Microsoft Azure Data Lake Storage (ADLS) Gen2
- Amazon Web Services (AWS) S3
The Databricks connection uses a JDBC URL to connect to the Databricks cluster. When you configure the target, specify the JDBC URL and credentials to use for connecting to the cluster. Also define the connection information that the target uses to connect to the staging location in Amazon S3 or ADLS Gen2.
•Before writing data to Databricks target tables, application ingestion and replication jobs stage the data in an Amazon S3 bucket or ADLS directory. You must specify the directory for the data when you configure the application ingestion and replication task.
Note: Application Ingestion and Replication does not use the ADLS Staging Filesystem Name and S3 Staging Bucket properties in the Databricks connection properties to determine the directory.
•Application Ingestion and Replication uses jobs that run once to load data from staging files on AWS S3 or ADLS Gen2 to external tables.
By default, Application Ingestion and Replication runs jobs on the cluster that is specified in the Databricks connection properties. If you want to run the jobs on another cluster, set the dbDeltaUseExistingCluster custom property to false on the Target page in the application ingestion and replication task wizard.
•If the cluster specified in the Databricks connection properties is not up and running, the application ingestion and replication job waits for the cluster to start. By default, the job waits for 10 minutes. If the cluster does not start within 10 minutes, the connection times out and deployment of the job fails.
If you want to increase the timeout value for the connection, set the dbClusterStartWaitingTime custom property to the maximum time in seconds for which the ingestion and replication job must wait for the cluster to be up and running. You can set the custom property on the Target page in the application ingestion and replication task wizard.
•By default, Application Ingestion and Replication uses the Databricks COPY INTO feature to load data from the staging file to Databricks target tables. You can disable it for all load types by setting the writerDatabricksUseSqlLoad custom property to false on the Target page in the application ingestion and replication task wizard.
•If you use an AWS cluster, you must specify the S3 Service Regional Endpoint value in the Databricks connection properties. For example:
s3.us-east-2.amazonaws.com
Before you can test a Databricks connection. you must specify the JDBC URL in the SQL Endpoint JDBC URL field in the Databricks connection properties. After you test the connection, remove the SQL Endpoint JDBC URL value. Otherwise, when you define an application ingestion and replication task that uses the connection, a design-time error occurs because Application Ingestion and Replication tries to use the JDBC URL as well as the required Databricks Host, Cluster ID, Organization ID, and Databricks Token values to connect to target, resulting in login failures.
•Processing of Rename Field operations on Databricks target tables, without the need to rewrite the underlying Parquet files, requires the Databricks Column Mapping feature with Databricks Runtime 10.2 or later. If you set the Rename Field option to Replicate on the Schedule and Runtime Options page in the task wizard, you must alter the generated target table to set the following Databricks table properties after task deployment and before you run the job:
ALTER TABLE <target_table> SET TBLPROPERTIES ( 'delta.columnMapping.mode' = 'name', 'delta.minReaderVersion' = '2', 'delta.minWriterVersion' = '5')
These properties enable the Databricks Column Mapping feature with the required reader and writer versions. If you do not set these properties, the application ingestion and replication job will fail.
•Application ingestion and replication that have Databricks targets can get schema information for generating the target tables from Databricks Unity Catalog. To enable access to information in a Unity Catalog, specify the catalog name in the Catalog Name field in the Databricks connection properties. The catalog name is appended to the SQL Warehouse JDBC URL value for a data warehouse.
Note: Catalog use is optional for SQL warehouses and does not apply to job clusters.
If you use Unity Catalog, a personal storage location is automatically provisioned. To use the personal staging location, in the Staging Environment field of the connection properties, select Personal Staging Location. The Parquet data files for ingestion jobs can then be staged to the local personal storage location, which has a data retention period of 7 days. By default, the staging location is stage://tmp/<user_name> in the root AWS or Azure location. The <user_name> is taken from the Database Token connection property. This user must have read and write access to the personal staging location.
•If you generated Databricks unmanaged tables as the target tables and no longer need a target unmanaged table, use a SQL DROP TABLE statement to delete the table from the target database. You must not manually delete the external directory in Amazon S3 or Azure Data Lake Storage for the unmanaged table. If you do so and try to deploy another job that uses that table, the deployment fails with a Metadata Handler error.
Guidelines for Google BigQuery targets
Consider the following guidelines when you use Google BigQuery targets:
•When you use a Google BigQuery target for the first time, perform the following steps before you configure an application ingestion and replication task for the target:
1Download the Google BigQuery JDBC driver SimbaJDBCDriverforGoogleBigQuery42_1.6.1.1002 from the Google Cloud website.
2Copy only the GoogleBigQueryJDBC42.jar file from the installation zip to the following directory:
Note: If other Google BigQuery driver .jar files exist in that directory, remove them. They're now bundled with Application Ingestion and Replication.
3Restart the Secure Agent.
•You must have a service account in your Google account to access Google BigQuery and Google Cloud Storage.
•Ensure that you have the client_email, project_id, private_key, and region ID values for the service account. Enter the values in the corresponding Service Account ID, Project ID, Service Account Key, and Region ID connection properties when you create a Google BigQuery connection.
•If you want to configure a timeout interval for a Google BigQuery connection, specify the timeout interval property in the Provide Optional Properties field of the connection properties. Use the following format:
"timeout": "<timeout_interval_in_seconds>"
•You must have read and write access to the following entities:
- Google BigQuery datasets that contain the target tables.
- Google Cloud Storage path where Application Ingestion and Replication creates the staging file.
•Application ingestion and replication jobs configured for Google BigQuery targets do not replicate the modification and renaming of source fields on the target.
•For incremental load tasks, you must enable source database Change Data Capture (CDC) on all source fields.
• You must have the following permissions to write data to a Google BigQuery table:
- bigquery.datasets.get
- bigquery.datasets.getIamPolicy
- bigquery.models.*
- bigquery.routines.*
- bigquery.tables.create
- bigquery.tables.delete
- bigquery.tables.export
- bigquery.tables.get
- bigquery.tables.getData
- bigquery.tables.list
- bigquery.tables.update
- bigquery.tables.updateData
- bigquery.tables.updateTag
- resourcemanager.projects.get
- resourcemanager.projects.list
- bigquery.jobs.create
•When you deploy application ingestion and replication jobs, Application Ingestion and Replication generates Google BigQuery target tables clustered by primary key or unique key columns, by default. Each key column must have one of the following data types that Google BigQuery supports for clustering:
- STRING
- INT64
- NUMERIC
- BIGNUMERIC
- DATE
- DATETIME
- TIMESTAMP
- BOOL
- GEOGRAPHY
If any column in the primary key or unique key has an unsupported data type, that column is skipped during clustering. For example, if the primary key contains the C1, C2, C3, C4, C5 columns and C2 has an unsupported data type, the target table is created with the C1, C3, C4, and C5 columns in the CLUSTER BY clause.
Guidelines for Microsoft Azure Synapse Analytics targets
Consider the following guidelines when you use Microsoft Azure Synapse Analytics targets:
•To deploy and run an application ingestion and replication task with a Microsoft Azure Synapse Analytics target, the target connection must specify a database user who has the CONTROL permission on the target database. To grant the CONTROL permission to the user, use the following SQL statements:
USE database_name; GRANT CONTROL TO user_name;
The CONTROL permission is required for initial load, incremental load, and combined initial and incremental load jobs. The permission allows Application Ingestion and Replication to create target tables and database objects such as external data source, external file format, and database scoped credential objects if they do not exist in the database. The CONTROL permission is specifically required for creating external data source and database scoped credential objects.
Note: You must manually create the master key. To create the master key, you must have the CONTROL permission on the database.
•Application ingestion and replication jobs first send data to a Microsoft Azure Data Lake Storage Gen2 staging file before writing the data to Microsoft Azure Synapse Analytics target tables. The staging file uses the hexadecimal x1d separator as the field delimiter. After the data is written to the target, the data stored in the table-specific directory that includes the staging files are deleted.
•If you use Microsoft Azure Data Lake Storage Gen2 with a Microsoft Azure Synapse Analytics connection, you must enable the Hierarchical namespace option in Microsoft Azure Data Lake Storage. With this setting, blob storage is not recommended.
•When you configure an application ingestion and replication task for a Microsoft Azure Synapse Analytics target, ensure that each source object that you select for replication meets the following criteria:
- The object must not contain more than 1024 fields and the size of each field must be less than 500 KB.
- The object must not contain any record that is greater than 1 MB in size.
- The object must not contain more than 32 primary keys.
- The cluster index key must not contain data that is greater than 900 bytes in size.
- The primary keys of the object must be of a data type that Microsoft Azure Synapse Analytics supports for primary keys.
•Incremental load jobs and combined initial and incremental load jobs generate a recovery table named INFORMATICA_CDC_RECOVERY on the target to store internal service information. The data in the recovery table prevents the jobs that are restarted after a failure from propagating previously processed data again. The recovery table is generated in the schema of the target tables.
•After an application ingestion and replication job loads data to a Microsoft Azure Synapse Analytics target by using external tables, the job does not drop the log tables and external tables created on the target, even though these tables might be re-created when the job starts again.
•Application ingestion and replication jobs configured for Microsoft Azure Synapse Analytics targets do not replicate the renaming of source fields on the target.
Guidelines for Microsoft Azure SQL Database and SQL Server targets
Consider the following guidelines when using Microsoft Azure SQL Database and Microsoft SQL Server targets with SAP (using SAP Mass Ingestion connector), Microsoft Dynamics 365, and Salesforce sources for all load types. Microsoft SQL Database targets include on -premises, Microsoft Amazon RDS (Relational Database Service) for SQL Server, and Azure SQL Managed Instance targets.
The following list identifies considerations for preparing and using Microsoft SQL Database and Microsoft SQL Serve targets:
•The SQL Server JDBC driver is delivered with Application Ingestion and Replication. You do not need to install it separately.
•The Application Ingestion and Replication user requires following database roles, at minimum, to create target tables and write data to the tables:
- db_datareader
- db_datawriter
- db_ddladmin
•In Administrator, when you define a SQL Server connection for connecting to a SQL Server target, set the following required connection properties:
- SQL Server Version. This property is no longer used. If you select a version, it is ignored.
- Authentication Mode. Select SQL Server Authentication or Windows Authentication v2.
- User Name
- Password
- Host
- Port
- Database Name
- Schema
- Code Page
Optionally, to use SSL encryption for the target connection, you can set the Encryption Method property to one of the following options: SSL, Request SSL, or Login SSL. If you enable encryption, also set the following properties:
- Crypto Protocol Version
- Validate Server Certificate. Select True.
- Trust Store
- Trust Store Password
- Host Name in Certificate
Other connection properties are not supported.
•Application ingestion and replication incremental load and initial and incremental load jobs with a SQL Server target generate a LOG table based on the target table schema, together with a number of additional metadata columns. The LOG table is created right before the change data is flushed to the target. The incoming DML data is inserted to the LOG table by supplying a local CSV file to Bulk Copy API of the SQL Server driver. A merge apply statement is generated based on the information in the LOG table and the DML operations are applied to the actual target table. When this is complete, the LOG table is dropped. The LOG table might cause a temporary spike in additional space or size requirements in the customer database instance when running multiple jobs or a job with multiple tables. The space and size required by the LOG table depends on the number of rows received as part of a flush cycle.
•The number of fields in a source object that an application ingestion and replication incremental load or an initial and incremental load job can propagate to a SQL Server target must not exceed 508 fields. If a source object contains more than 508 fields, the job fails while creating the LOG table.
•Application ingestion and replication incremental load jobs generate a recovery table named INFORMATICA_CDC_RECOVERY on the target to store internal service information that prevents jobs restarted after a failure from propagating previously processed data again. This recovery table is generated in the same schema as the target tables.
Guidelines for Oracle targets
Target preparation
•Application Ingestion and Replication requires users to have certain privileges to load data to Oracle target databases. For on-premises Oracle targets, grant the following user privileges to the Application Ingestion and Replication user (cmid_user) who connects to the Oracle target:
GRANT CREATE SESSION TO cmid_user;
GRANT SELECT ON "PUBLIC".V$DATABASE TO cmid_user; GRANT SELECT ON "PUBLIC".V$CONTAINERS TO cmid_user;
GRANT SELECT ON DBA_USERS TO cmid_user; GRANT SELECT ON DBA_TABLES TO cmid_user; GRANT SELECT ON DBA_OBJECT_TABLES TO cmid_user; GRANT SELECT ON DBA_INDEXES TO cmid_user; GRANT SELECT ON DBA_OBJECTS TO cmid_user; GRANT SELECT ON DBA_VIEWS TO cmid_user;
GRANT CREATE TABLE <schema.table> TO cmid_user; <--Unless you grant on ANY TABLE GRANT SELECT ON ALL_CONSTRAINTS TO cmid_user; GRANT SELECT ON ALL_OBJECTS TO cmid_user;
GRANT SELECT ON SYS.TAB$ TO cmid_user; GRANT SELECT ON SYS.RECYCLEBIN$ TO cmid_user; GRANT SELECT ON SYS.COL$ TO cmid_user; <-- If cmid_user is the owner of the target schema GRANT SELECT ON SYS.CCOL$ TO <cmid_user>; GRANT SELECT ON SYS.CDEF$ TO cmid_user; GRANT SELECT ON SYS.OBJ$ TO cmid_user; GRANT SELECT ON SYS.COLTYPE$ TO cmid_user; GRANT SELECT ON SYS.ATTRCOL$ TO cmid_user; GRANT SELECT ON SYS.IDNSEQ$ TO cmid_user; GRANT SELECT ON SYS.ATTRCOL$ TO cmid_user; GRANT SELECT ON SYS.IDNSEQ$ TO cmid_user; GRANT SELECT ON SYS.IND$ TO cmid_user;
-- Grant the following if cmid_user is NOT the owner of the target schema. If you prefer, you -- can grant to individual target tables and indexes instead of to ANY TABLE or ANY INDEX. GRANT ALTER SESSION TO cmid_user; GRANT RESOURCE TO cmid_user; GRANT SELECT ANY TABLE TO cmid_user; GRANT SELECT ANY DICTIONARY TO <cmid_user>; GRANT ALTER ANY TABLE TO cmid_user; GRANT CREATE ANY TABLE TO cmid_user; GRANT DROP ANY TABLE TO cmid_user; GRANT INSERT ANY TABLE TO cmid_user; GRANT UPDATE ANY TABLE TO cmid_user; GRANT DELETE ANY TABLE TO cmid_user; GRANT CREATE ANY INDEX TO cmid_user; GRANT ALTER ANY INDEX TO cmid_user; GRANT DROP ANY INDEX TO cmid_user;
•For Amazon RDS for Oracle targets, log in to RDS as the master user and grant the following user privileges to the Application Ingestion and Replication user (cmid_user) who connects to the Oracle target:
GRANT CREATE SESSION TO cmid_user;
GRANT SELECT on "PUBLIC".V$DATABASE TO cmid_user;
GRANT SELECT on DBA_USERS TO cmid_user; GRANT SELECT on DBA_TABLES TO cmid_user; GRANT SELECT on DBA_INDEXES TO cmid_user; GRANT SELECT ON DBA_VIEWS TO cmid_user;
GRANT CREATE TABLE <schema.table> TO cmid_user; GRANT SELECT on SYS.TAB$ TO cmid_user; GRANT SELECT on SYS.COL$ TO cmid_user; GRANT SELECT on SYS.OBJ$ TO cmid_user; GRANT SELECT on SYS.IND$ TO cmid_user;
-- Grant the following if cmid_user is NOT the owner of the target schema. If you prefer, you -- can grant to individual target tables and indexes instead of to ANY TABLE or INDEX. GRANT ALTER SESSION TO cmid_user; GRANT RESOURCE TO cmid_user; GRANT SELECT ANY TABLE TO cmid_user; GRANT SELECT ANY DICTIONARY TO <cmid_user>; GRANT ALTER ANY TABLE TO cmid_user; GRANT CREATE ANY TABLE TO cmid_user; GRANT DROP ANY TABLE TO cmid_user; GRANT INSERT ANY TABLE TO cmid_user; GRANT UPDATE ANY TABLE TO cmid_user; GRANT DELETE ANY TABLE TO cmid_user; GRANT CREATE ANY INDEX TO cmid_user; GRANT ALTER ANY INDEX TO cmid_user; GRANT DROP ANY INDEX TO cmid_user;
Also, run the following Amazon RDS procedures to grant additional SELECT privileges to cmid_user:
•By default, Application Ingestion and Replication disables logging for the Oracle target tables to optimize performance. You can enable logging by setting the writerOracleNoLogging custom property to false on the Target page in the application ingestion and replication task wizard.
•Application Ingestion and Replication uses the minimum source constraints needed for replication when generating Oracle target objects. If a source has a primary key, the job preferentially uses the primary key and no other constraint when creating the target object. In application ingestion and replication tasks that have an SAP ECC source (Oracle based), if the source does not have a primary key but does have unique indexes, the task chooses the best unique index for replication in the following order of priority: 1) the unique index that has only NOT NULL columns, 2) if multiple unique indexes have only NOT NULL columns, the unique index with the least number of columns, or 3) if no source primary key or unique NOT NULL index exists, the unique index with the greatest number of columns. Only a single primary key or unique index is used.
Source object properties that are not required for replication, such as for storage and partitioning, are not reflected on the target.
Guidelines for PostgreSQL targets
Consider the following guidelines when you use PostgreSQL targets:
• To deploy and run an application ingestion task that includes a PostgreSQL target, the target connection must specify a database user who has the required privileges.
The user must have the CONNECT and TEMPORARY privileges for the database specified in the connection and the USAGE and CREATE privileges for the target schema specified in the target properties.
Use the following SQL statements to grant these privileges to a user role and then assign the role to a user:
CREATE ROLE dbmi_role; GRANT CONNECT ON DATABASE database TO dbmi_role; GRANT TEMPORARY ON DATABASE database TO dbmi_role; GRANT CREATE ON SCHEMA schema TO dbmi_role; GRANT USAGE ON SCHEMA schema TO dbmi_role; CREATE USER dbmi_user with PASSWORD 'password'; GRANT dbmi_role to dbmi_user;
Note: Privileges on the target tables that are generated when the job runs are granted to the user who runs the job.
•Application ingestion and replication incremental load jobs with a PostgreSQL target generate a LOG table based on the target table schema, with some additional metadata columns. The LOG table is created right before change data is flushed to the target. The incoming DML data is inserted to the LOG table by supplying a local CSV file to the Bulk Copy API of the PostgreSQL driver. A set of merge apply statements is generated based on the information in the LOG table, and then the DML operations are applied to the actual target table. After the DML changes are applied, the LOG table is dropped.
The LOG table might cause a temporary spike in additional space or size requirements in the customer database instance if you run multiple jobs or a job with multiple tables. The space and size required by the LOG table depends on the number of rows received as part of a flush cycle.
•The number of fields in a source object that an application ingestion and replication incremental load job can propagate to a PostgreSQL target must not exceed 796 fields. If a source object contains more than 796 fields, the job fails while creating the LOG table.
• The data inserted in a PostgreSQL table row depends on the page size configured for the instance. The default is 8 KB. If a row exceeds the page size, the job fails and Application Ingestion and Replication displays the following error:
SQL Error [54000]: ERROR: row is too big: size 9312, maximum size 8160
This error occurs when the data exceeds the configured page size and PostgreSQL can't persist the data.
For example:
- If the source table has 500 INT columns, the row size is 2000 bytes (500 * 4 bytes). The row fits within the page size (8192 bytes) and is successfully inserted.
- If the source table has 500 BIGINT columns, the row size is 4000 bytes (500 * 8 bytes). The row fits within the page size and is successfully inserted.
- If the source table has 500 VARCHAR (255) columns, the row size is 9000 bytes (500 * 18 bytes). As the row does not fit the page size, an error occurs.
•PostgreSQL supports a maximum length of 63 characters for source object identifiers. The deployment of application ingestion and replication tasks that have a PostgreSQL target will fail during validation if the length of any source table or column name exceeds 63 characters.
•Application ingestion and replication incremental load jobs generate a recovery table named INFORMATICA_CDC_RECOVERY on the target to store internal service information that prevents jobs restarted after a failure from propagating previously processed data again. This recovery table is generated in the same schema as the target tables.
Guidelines for Snowflake targets
Target preparation
Target preparation varies depending on whether you use the Superpipe feature for high performance streaming of data to Snowflake target tables or write data to intermediate stage files.
With Superpipe
If you use the Superpipe feature, complete the following steps:
1Create a Data Ingestion and Replication user. Use the following SQL statement:
create user INFACMI_User password = 'Xxxx@xxx';
2Create a new user role and grant it to the Data Ingestion and Replication user. Use the following SQL statements:
create role INFACMI_superpipe; grant role INFACMI_superpipe to user INFACMI_User;
3Grant usage on the Snowflake virtual warehouse to the new role. Use the following SQL statement:
grant usage on warehouse warehouse_name to role INFACMI_superpipe;
4Grant usage on the Snowflake database to the new role. Use the following SQL statement:
grant usage on database INFACMI_DB1 to role INFACMI_superpipe;
5Create a new schema. Use the following SQL statements:
use database INFACMI_DB1; create schema sh_superpipe;
6Grant create stream, create view, and create table privileges on the new Snowflake schema to the new role. Use the following SQL statement:
grant create stream, create view, create table, usage on schema INFACMI_DB1.sh_superpipe to role INFACMI_superpipe;
7Set the default role for the newly created user. Use the following SQL statement:
alter user INFACMI_User set default_role=INFACMI_superpipe;
8Define a Snowflake Data Cloud connection to the target. You must use the KeyPair option as the authentication method. See Connectors and Connections > Snowflake Data Cloud connection properties.
9Generate a private key with OpenSSL version 3.x.x and one of the following ciphers:
- AES128
- AES128-CBC
- AES256
- AES-256-CBC
Use the following openssl commands to generate and format the private key:
10Generate the public key. Use the following openssl command, in which the -in option references the file (rsa_key.p8) that contains the encrypted private key:
11In Snowflake, assign the public key to the Snowflake user. Use the following SQL command:
alter user INFACMI_User set rsa_public_key='key_value’;
Next step: When you create an ingestion task, select the Superpipe option on the Target page of the task wizard. You can also optionally specify a Merge Frequency value, which controls the frequency at which change data rows are merged and applied to the Snowflake target table.
Without Superpipe
If you do NOT use the Superpipe feature for Snowflake targets, complete the following steps as the ACCOUNTADMIN user:
1Create a Data Ingestion and Replication user. Use one of the following SQL statements:
create user INFACMI_User password = 'Xxxx@xxx';
or
replace user INFACMI_User password = 'Xxxx@xxx';
2Create a new role and grant the role to the Data Ingestion and Replication user. Use the following SQL statements:
create role INFA_CMI_Role; grant role INFA_CMI_Role to user INFACMI_User;
3Grant usage on the Snowflake virtual warehouse to the new role. Use the following SQL statement:
grant usage on warehouse CMIWH to role INFA_CMI_Role;
4Grant usage on the Snowflake database to the new role. Use the following SQL statement:
grant usage, CREATE SCHEMA on database CMIDB to role INFA_CMI_Role;
5Set the default role for the newly created user. Use the following SQL statement:
alter user INFACMI_User set default_role=INFA_CMI_Role;
Also, as the INFACMI_User, create a new schema:
create schema CMISchema;
Note: If the user's default role is used for ingestion tasks and does not have the required privileges, the following error will be issued at runtime:
SQL compilation error: Object does not exist, or operation cannot be performed.
Usage guidelines
•Data Ingestion and Replication provides alternative methods of moving data to a Snowflake Data Cloud target:
- If you select the Superpipe option when defining an ingestion task, the ingestion job uses the Snowpipe Streaming API to stream rows of data directly to the target tables with low latency. This method is available for all load types. You must use KeyPair authentication.
- If you do not use Superpipe, ingestion jobs first write the data to data files in an internal stage, which has the name you specify in the task definition.
•If you do not use Superpipe and the internal stage specified in the target properties for an ingestion job does not exist, Database Ingestion and Replication automatically creates the stage by running the following SQL command:
Create stage if not exists "Schema"."Stage_Bucket"”
For the command to run successfully, the following privilege must be granted to your user role:
GRANT CREATE STAGE ON SCHEMA "Schema" TO ROLE <your_role>;
•When you define a connection for a Snowflake target, you must set the Additional JDBC URL Parameters field to database=target_database_name. Otherwise, when you try to define the target in the application ingestion and replication task wizard, an error message indicating that the list of schemas cannot be retrieved appears.
•When you define a connection for a Snowflake target using the KeyPair option as the authentication method and you generate the private key with OpenSSL 3.x.x version, use AES128, AES128-CBC, AES256, or AES-256-CBC cipher while generating the private key. Run the following command:
Data Ingestion and Replication supports the following ciphers:
- AES128
- AES128-CBC
- AES256
- AES-256-CBC
- CAMELLIA-256-CBC
- CAMELLIA-256-CTR
- ARIA-256-CTR
•Incremental load jobs generate a recovery table named INFORMATICA_CDC_RECOVERY on the target to store internal service information. The data in the recovery table prevents the jobs that are restarted after a failure from propagating previously processed data again. The recovery table is generated in the schema that contains the target tables.
•Application ingestion and replication incremental load and combined load jobs that have a Snowflake target create transient _LOG tables to stage data on the target instead of permanent tables, by default. To prevent permanent tables from being created, the Snowflake Time Travel and Fail-safe features are disabled by default. The use of transient tables helps reduce _LOG table storage consumption and associated costs. With transient tables, however, you can't use the Superpipe option. If you need to create permanent tables, you can set the target snowflakeStagingTransientTable custom property to false.
•In an application ingestion and replication task configured for change data capture that runs at scheduled intervals and detects changes based on record timestamps, only the most recent change for each record is captured during each interval. If a record undergoes multiple updates within the same interval, the CDC process captures only the latest change, while earlier changes made within that interval are not recorded.
•Before stopping an application ingestion and replication incremental load or combined load job that has a Snowflake target and uses the Superpipe option, ensure that all ingested data in the change stream has been merged into the target. Otherwise, if the job is not restarted for an extended period or before the stream expires, any data that remains in the stream is lost and can’t be recovered.
•The object must not contain any record that is greater than 16 MB.
•For Snowflake targets, you cannot alter the scale of NUMBER fields or change the data type of an existing field to a different data type because Snowflake does not support these actions.
Configure private connectivity to Snowflake
You can access Snowflake using AWS or Azure Private Link endpoints.
The AWS or Azure Private Link setup ensures that the connection to Snowflake uses the AWS or Azure internal network and does not take place over the public Internet.
Application Ingestion and Replication supports only some of the primitive and logical data types that Avro schemas provide.
A primitive data type is a type that allows you to represent a single data value. A logical type is an Avro primitive or complex type with extra attributes to represent a derived type. This topic applies to all target types that support Avro or Parquet output format.
The following table lists the primitive Avro data types that Application Ingestion and Replication supports:
Primitive data type
Description
INT
32-bit signed integer
LONG
64-bit signed integer
FLOAT
Single precision (32-bit) IEEE 754 floating-point number
DOUBLE
Double precision (64-bit) IEEE 754 floating-point number
BYTES
Sequence of 8-bit unsigned bytes
STRING
Unicode character sequence
The following table lists the logical Avro data types that Application Ingestion and Replication supports:
Logical data type
Description
DECIMAL
An arbitrary-precision signed decimal number of the form unscaled × 10 -scale
DATE
A date, without reference to a time or time zone.
TIME
A time of day that has the precision of 1 millisecond or 1 microsecond, without reference to a time zone or date.
TIMESTAMP
A date and time value that has the precision of 1 millisecond or microsecond, without reference to a particular calendar or time zone.