The mapping template extracts patient information from the PID segment in HL7 messages and converts it to relational format, and the attached file includes intelligent structure models that contain the schemas for the conversion. To create a different intelligent structure model, you can use a different HL7 file as input to the intelligent structure model and regenerate the schema. For more information, see the following Knowledge Base article: FAQs on Using Intelligent Structure Discovery to Parse HL7 Messages.
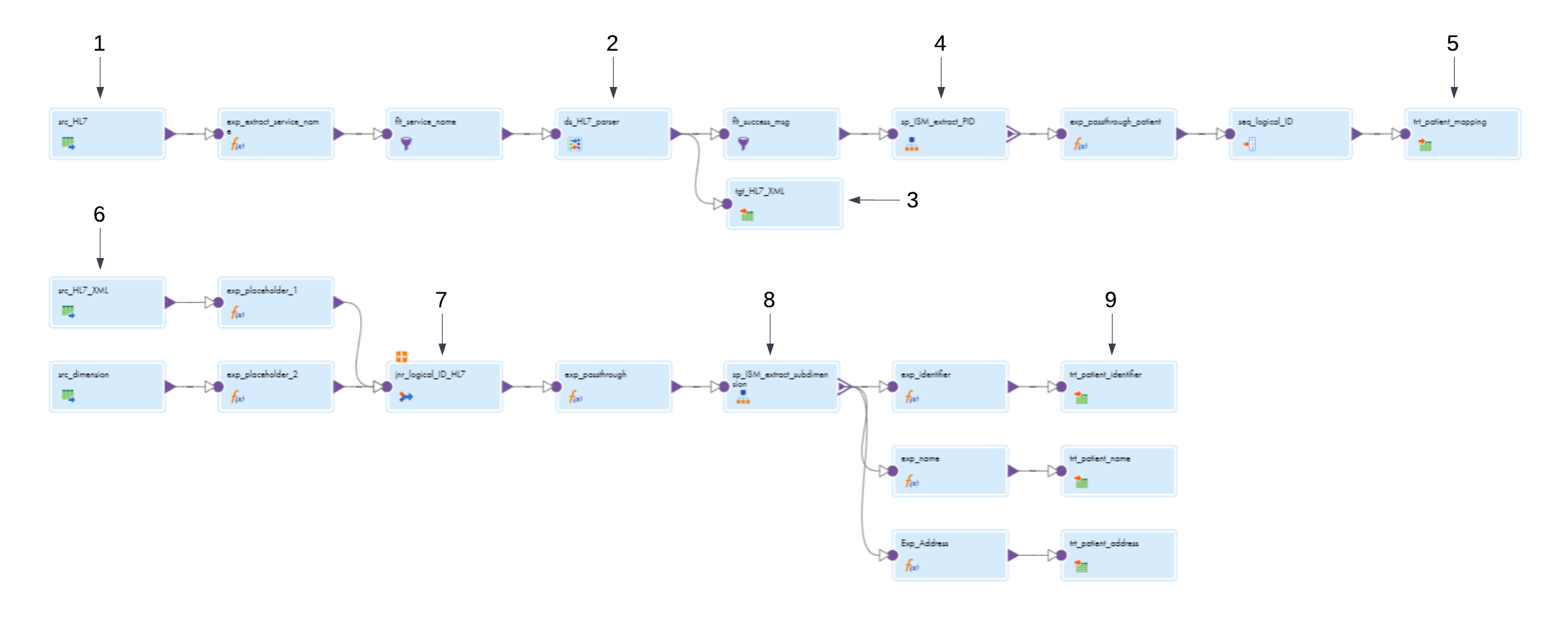
The following image shows the transformations in the mapping template:
The sources and targets are parameterized in the mapping template, so you can perform one of the following tasks:
•Replace the parameters with specific connections and objects in the Source and Target transformations.
•Leave the parameters in the Source and Target transformations and specify sources and targets in the mapping task or use a parameter file.
The mapping template contains the following notable transformations:
1. Source transformation (first flow)
The Source transformation reads an HL7 file as a source. You can use a flat file connection, an SFTP connection to a remote server, or a Kafka connection to access the HL7 data.
The source can be one of the following types:
- Single object
- File list to process multiple files
- Command if the files are stored on the same Linux machine that runs the Secure Agent
- Parameter if you want to specify the source in the mapping task
2. Data Services transformation (first flow)
The Data Services transformation uses the name of the HL7 parser data service to access the data service in the data services repository. The HL7 parser reads the incoming patient and health information in the HL7 file and converts the data to XML format.
3. Target transformation for XML output (first flow)
The target transformation writes the XML output to an intermediary target. To write the data to the target files, you can use any target connection that writes XML data, such as a flat file, relational, or MLLP connection.
4. Structure Parser transformation (first flow)
The Structure Parser transformation uses an intelligent structure model to convert the XML data to relational format.
5. Target transformation for relational output (first flow)
The Target transformation writes the relational output to a relational target to load the dimension table. To write the data to a relational target, use a relational connection.
6. Source transformations (second flow)
The Source transformations read the intermediary XML output and the relational output from the first flow.
7. Joiner transformation (second flow)
The Joiner transformation combines the data from both sources.
8. Structure Parser transformation (second flow)
The Structure Parser transformation uses an intelligent structure model to convert the data to relational format.
9. Target transformations (second flow)
The Target transformations write the relational output to relational targets to load subdimension tables. To write the data to a relational target, use a relational connection.