マッピング設定 Mapping Designerを使用してマッピングを設定します。
マッピングを設定するには、次のタスクを実行します。
1 2 3 ヒント: 開いているマッピング内または開いているマッピング間で、トランスフォーメーションをコピーして貼り付けることができます。
4 5 マッピング タスクで定義されるパラメータを作成します。6 マッピングの定義 マッピングを定義するには、マッピングを作成または編集して、マッピングの名前と場所を指定し、必要に応じてマッピングの説明を入力します。
1 [新規] > [マッピング] をクリックして、以下のいずれかのタスクを実行します。
Mapping Designerが開きます。
2 マッピングの名前と場所を指定するには、 [マッピングのプロパティ] パネルでマッピングの名前を入力し、場所を変更します。または、必要に応じてデフォルト値を使用できます。
デフォルトでは、マッピング名は、マッピングの後に連番が付けられたものになります。
マッピング名には、英数字とアンダースコア(_)を使用できます。最大長は100文字です。
次の予約語は使用できません。
- - - - - - - - - - - - [Explore (参照)]ページが現在アクティブになっていて、プロジェクトまたはフォルダが選択されている場合、アセットのデフォルトの場所はその選択されているプロジェクトまたはフォルダです。そうでない場合、デフォルトの場所は直近で保存されたアセットの場所です。
[エクスプローラ] ページを使用して、マッピングを保存した後で、名前または場所を変更できます。
3 必要に応じて、マッピングの説明を入力します。
最大長は4000文字です。
ソースの設定 ソースを設定するには、ソーストランスフォーメーションを編集します。
1 マッピングキャンバスで、ソーストランスフォーメーションをクリックします。
2 ソーストランスフォーメーションの名前と説明を指定するには、 [プロパティ] パネルで [全般] をクリックします。
トランスフォーメーション名には、英数字とアンダースコア(_)を使用できます。最大長は75文字です。
次の予約語は使用できません。
- - - - - - - - - - - - 必要に応じて、説明を入力できます。
最大長は4000文字です。
3 [ソース] タブをクリックして、ソースの詳細、クエリオプション、および詳細プロパティを設定します。
ソースの詳細、クエリオプション、および詳細プロパティは、接続タイプによって異なります。詳細については、該当するコネクタのヘルプを参照してください。
ソースの詳細では、ソース接続とソースオブジェクトを選択します。一部の接続タイプでは、複数のソースオブジェクトを選択できます。
組織の管理者によってEnterprise Data Catalog統合プロパティが設定されており、[データカタログ] ページでオブジェクトをマッピングに追加した場合は、[インベントリ] パネルからソースオブジェクトを選択できます。[インベントリ] パネルは、SQL ELTモードのマッピングでは使用できません。
ソース接続とソースオブジェクトのパラメータも設定できます。
詳細モードでは、Amazon S3またはMicrosoft Azure Data Lake接続を使用する一部のソースタイプのソーストランスフォーメーションに、インテリジェント構造モデルを追加できます。モデルをマッピングに追加する前に、モデルを作成する必要があります。インテリジェント構造モデルの詳細については、「コンポーネント 」を参照してください。
4 ソースフィルタまたはソートオプションを設定するには、 [クエリオプション] を展開します。 [設定] をクリックして、フィルタまたはソートオプションを設定します。
5 [フィールド] タブをクリックして、ソースフィールドを追加または削除し、フィールドメタデータを更新し、フィールドをソースと同期します。
SQL ELTモードのマッピングではフィールドメタデータを更新できません。
6 変更を保存して続行するには、 [保存] をクリックします。
データフローの設定 データフローを設定するには、オプションでマッピングにトランスフォーメーションを追加します。
1 トランスフォーメーションを追加するには、以下のいずれかのアクションを実行します。
- - 2 [全般] タブで、トランスフォーメーションの名前と説明を入力します。
3 新しいトランスフォーメーションを、キャンバス上の適切なトランスフォーメーションにリンクします。
トランスフォーメーションをリンクすると、ダウンストリームトランスフォーメーションは以前のトランスフォーメーションから追加フィールドを継承します。
ジョイナトランスフォーメーションの場合は、マスタリンクと詳細リンクを設定します。
4 フィールドのプレビュー、フィールドルールの設定、またはフィールド名の変更を行うには、 [追加フィールド] をクリックします。
5 必要に応じて、トランスフォーメーションの追加プロパティを設定します。
設定するプロパティは、作成するトランスフォーメーションのタイプによって変わります。トランスフォーメーションおよびトランスフォーメーションのプロパティの詳細については、「トランスフォーメーション 」を参照してください。
6 変更を保存して続行するには、 [保存] をクリックします。
7 別のトランスフォーメーションを追加するには、これらの手順を繰り返します。
ターゲットの設定 ターゲットを設定するには、ターゲットトランスフォーメーションを編集します。
1 マッピングキャンバスで、 ターゲット トランスフォーメーションをクリックします。
2 ターゲットトランスフォーメーションを適切なアップストリームトランスフォーメーションにリンクします。
3 [全般] タブで、ターゲット名と必要に応じて説明を入力します。
4 [受信フィールド] タブをクリックして、受信フィールドのプレビュー、フィールドルールの設定、またはフィールドの名前変更を行います。
5 [ターゲット] タブをクリックして、ターゲットの詳細および詳細プロパティを設定します。
ターゲットの詳細および詳細ターゲットプロパティは、接続タイプによって異なります。詳細については、該当するコネクタのヘルプを参照してください。
ターゲットの詳細では、ターゲット接続、ターゲットオブジェクト、およびターゲット操作を選択します。SQL ELTモードのマッピングでは、マッピングの作成時に選択した接続でターゲット接続が自動的に設定されます。
組織の管理者によってEnterprise Data Catalog統合プロパティが設定されていて、[Data Catalog] ページでオブジェクトをマッピングに追加した場合、[インベントリ] パネルからターゲットオブジェクトを選択できます。[インベントリ] パネルは、SQL ELTモードのマッピングでは使用できません。
ターゲット接続とターゲットオブジェクトのパラメータも設定できます。
6 [フィールドマッピング] をクリックして、書き込むフィールドをターゲットにマップします。
マッピング設定のルールとガイドライン マッピングを設定するときは、次のルールおよびガイドラインに従ってください。
GPU対応クラスタでのマッピングに関するルールとガイドライン GPU対応の詳細クラスタ で実行されるマッピングを設定する場合は、次のルールとガイドラインを使用してください。
• • • • • • • - - - - - - - GPU対応のクラスタを設定する方法については、Administratorヘルプを参照してください。
データフロー実行順序 データ統合 がマッピングで個別のデータフローを実行する順序を指定できます。データ統合 でマッピング内のターゲットを特定の順序でロードする場合は、フローの実行順序を指定します。例えば、プライマリキーまたは外部キーの制約のあるテーブルを挿入、削除、または更新するときに、フローの実行順序を指定することをお勧めします。
プライマリキーまたは外部キーの制約があるテーブルを更新するときに、参照整合性を維持するためにフローの実行順序を指定することができます。または、ステージングされたデータを処理するときにフローの実行順序を指定することをお勧めします。
フローに複数のターゲットが含まれている場合、フロー内のターゲットのロード順序は設定できません。
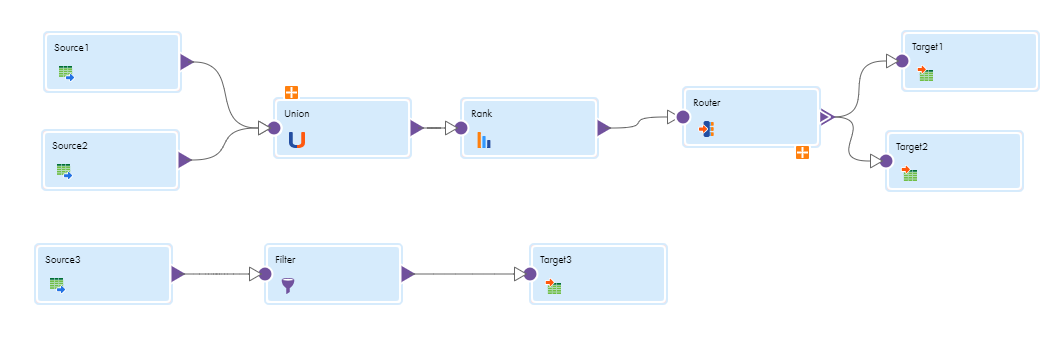
次の図は、2つのデータフローを使用したマッピングを示しています。
この例では、上位のフローには2つのパイプラインが含まれ、下位のフローには1つのパイプラインが含まれています。パイプラインは、ソースと、そのソースからデータを受信するすべてのトランスフォーメーションとターゲットです。フローの実行順序を設定する場合、データフロー内のパイプラインの実行順序を設定することはできません。
次の画像は、マッピングのフロー実行順序を示しています。
この例では、データ統合 は最初に上位のフローを実行し、2番目のフローを実行する前にTarget3をロードします。データ統合 は2番目のフローを実行すると、Target1とTarget2を同時にロードします。
フローの実行順序を設定した後に別のデータフローをマッピングに追加すると、新しいフローはデフォルトでフローの実行順序の最後に追加されます。
マッピングにマップレットが含まれている場合、データ統合 は同期されたマップレットの最後のバージョンのデータフローを使用します。マップレットを同期し、新しいバージョンがデータフローをマッピングに追加する場合、新しいフローはデフォルトでフロー実行順序の最後に追加されます。マップレットでフローの実行順序を指定することはできません。
任意のターゲットタイプのデータフローのフロー実行順序を指定できます。次の接続を使用するマッピングで、SQL ELTの最適化中にデータフローの実行順序を定義できます。
• • • • • • 詳細については、該当するコネクタガイドを参照してください。
注: タスクフローを使用して、個別のマッピングタスクでデータフローの実行順序を指定することもできます。特定の順序でタスクを実行するようにタスクフローを設定します。タスクの詳細については、「タスクフロー」を参照してください。
詳細モードまたは SQL ELTモードのマッピングには複数のフローを設定することができないため、データフローの実行順序を指定することはできません。
データフロー実行順序の設定 データ統合 がマッピングでデータフローを実行する順序を設定します。
1 Mapping Designerで、 [アクション] をクリックし、 [フロー実行順序] を選択します。
2 [フロー実行順序] ダイアログボックスで、データフローを選択し、矢印を使用してそれを上下に移動します。
3 [保存] をクリックします。