フラット化された出力の処理
階層プロセッサトランスフォーメーションにより、階層入力グループを、フラット化された非正規化出力グループに変換できます。
例えば、すべての顧客の顧客情報と車両情報を含むショップメンテナンスファイルがあるとします。車両のメンテナンスデータを非正規化し、顧客に関する個人情報を除外するとします。
階層プロセッサトランスフォーメーションを使用したフラット化済みの出力の定義
[階層プロセッサ]タブを使用して、受信フィールドを出力フィールドにマッピングします。フラット化された出力オプションを使用すると、非正規化出力を作成できます。
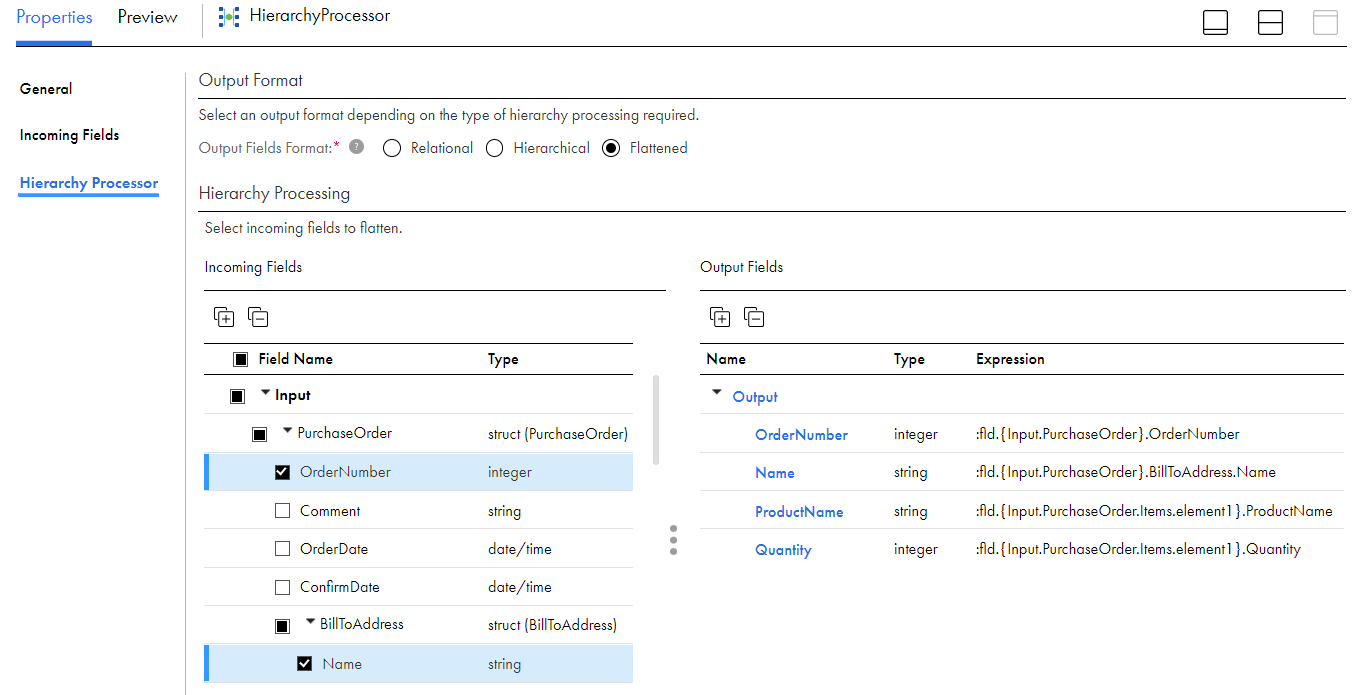
次の図に、階層入力とフラット化された出力を持つ[階層プロセッサ]タブを示します。
- 1出力形式。[フラット化済み]を選択して、階層入力を非正規化出力に変換します。
- 2受信フィールド。受信データスキーマとフィールドタイプを表示します。
- 3出力フィールド出力ファイルの作成時に、出力フィールドを表示します。
- 4出力の設定。受信フィールドを選択して、フラット化された出力ファイルスキーマを構築します。
- 5出力フィールド名。フィールド名をクリックして、フィールド名を変更します。
- 6式。フィールド式を表示して、入力から出力へのフィールドマッピングを指定します。
- 7削除。出力フィールドを削除する場合に使用します。
ヒント: 最大化アイコンを使用したり、[受信フィールド]パネルや[出力フィールド]パネルのサイズを変更したりすると、必要な情報を確認できます。
フラット化された出力を使用して階層プロセッサトランスフォーメーションを定義するには、次のタスクを実行します。
1[フラット化済み]出力形式を選択します。
2 出力に追加する受信フィールドを選択して、トランスフォーメーション出力を設定します。
3オプション。出力フィールドの名前を変更します。
4オプション。出力フィールドを削除します。
フラット化された出力グループへの受信フィールドの追加
出力には、受信フィールドを個別に追加することや入力グループ全体を追加することができます。受信フィールドを出力グループに追加すると、必要に応じて、出力フィールドの名前の変更や出力フィールドの削除ができます。
出力フィールドを追加するには、追加する入力フィールドまたは入力グループの横にあるチェックボックスをオンにします。親を選択するとすべての子項目が自動的に選択されますが、不要なエントリを選択解除することもできます。また、出力から不要なエントリを削除することもできます。
階層データのフラット化
受信階層フィールドを出力に追加すると、出力スキーマのすべてのフィールドが自動的にフラット化されます。
フラット化された階層データの例
受信フィールドが、構造と配列の階層内に含まれています。出力のOrderNumber、Name、ProductName、Quantityの4つのフィールドのみが必要です。
受信フィールドを出力に追加するには、適切なチェックボックスをオンにします。
次の図に、入力と出力を示します。
フラット化された出力グループとフィールドの名前変更
フラット化された形式で受信フィールドを出力グループに追加した後に、必要に応じてこれらのフィールドの名前を変更できます。また、出力グループの名前も変更できます。
出力フィールドの名前を変更するには、フィールド名をクリックします。出力グループの名前を変更するには、出力グループ名をクリックします。
以下の表に、出力フィールドのプロパティを示します。
プロパティ | 説明 |
|---|
名前 | 出力フィールドの名前です。 |
タイプ | 現在のフィールドのデータ型。データ型を変更することはできません。 |
精度 | フィールドの合計有効桁数。精度を変更することはできません。 |
スケール | 小数点以下の桁数。スケールを変更することはできません。 |
式の形式
フラット化された出力を使用すると、式はデフォルトに固定され、変更できなくなります。ただし、デフォルトの式の構文を理解している場合は、各出力フィールドのソースの場所を簡単に特定することができます。
ヒント: 出力グループにフィールドを追加するには、受信フィールド名の横にあるチェックボックスを使用します。これは、リレーショナル出力または階層出力に使用する[追加]リンクとは異なります。
階層プロセッサトランスフォーメーションは、さまざまなデータセットからの情報を処理できます。一部のフィールド名は、異なるデータセット間で一意ではない場合があります。その結果、同じフィールド名が別のデータセットまたは同じデータセットの階層内で使用される可能性があるため、フィールドをその名前で単純に参照することはできません。
階層プロセッサトランスフォーメーションの式の構文は、式トランスフォーメーションで使用される構文とは異なります。
階層プロセッサトランスフォーメーションでフィールドを参照するには、次の構文を使用します。
:fld.{input_group_name.field_name}.field_name
次の表に、構文の詳細を示します。
構文部分 | 説明 |
|---|
.fld. | 階層プロセッサトランスフォーメーションの式の構文を示します。 |
input_group_name | 入力グループまたはデータセットの名前。 |
field_name | 最上位のフィールドでない場合は、フルパス名を含むフィールドの名前。 配列タイプのフィールドがある場合は、配列名を含めます。配列がプリミティブで配列名がない場合は、配列名としてelemを使用します。 構造または配列内のフィールドの場合、実際のフィールド名は右中括弧の外側で指定します。 |
.field_name | 構造または配列内のフィールドを参照する場合にのみ、field_nameの部分を含めます。以下のガイドラインに従ってください。 - - 構造内のフィールドの場合、field_name部分は次の形式を使用します: .structName.fieldname
- - 配列内のフィールドの場合、field_name部分は次の形式を使用します: .fieldName
|
JSONデータを使用したマッピングの実行
JSON形式のデータを含む階層プロセッサトランスフォーメーションを含んだマッピングを実行するには、マッピングタスクを使用する必要があります。
JSON入力の読み取り
JSONデータを読み取る場合、入力ファイルは、複数行のスキーマに基づくものと単一行のスキーマに基づくものがあります。
次のサンプルは、JSONスキーマを1行で示したものです。
{"Name":"Tom","Street":"2100 Seaport Blvd","City":"Redwood City","State":"CA","Country":"USA","Zip":"94063"}
次のサンプルは、複数の行にまたがるJSONスキーマを示しています。
{
"Name": "Tom",
"Surname": "Day",
"City": "Redwood City",
"State": "CA",
"Country": "USA",
"Zip": "94063"
}
デフォルトでは、階層プロセッサトランスフォーメーションは各JSONスキーマを単一行として読み取ります。複数行にまたがる入力を読み取るには、複数行のJSONファイルを読み取るようにソーストランスフォーメーションで形式オプションを設定できます。
JSON出力の書き込み
JSONデータを書き込む場合は、各出力レコードを個別のファイルに書き込むか、すべての出力レコードを1つのファイルに書き込むことができます。
デフォルトでは、各出力レコードは個別のファイルに書き込まれます。出力レコードを1つのJSON形式のファイルに書き込むには、マッピングタスクで次のSparkセッションプロパティを設定します。
セッションプロパティ名 | セッションプロパティ値 |
|---|
spark.sql.shuffle.partitions | 1 |
階層からフラット化済みの例
階層データをリレーショナルデータに変換し、そのデータをターゲットファイルに非正規化形式で書き込むとします。
ショップのメンテナンスファイルに、顧客と顧客の車両情報が含まれています。このファイルは階層JSONファイルであり、会社のショップアプリケーションによって生成されています。
次のJSONスクリプトは、マッピングを実行する前のショップメンテナンスソース入力を示しています。
{
"people": [{
"personal": {
"age": 20,
"gender": "M",
"name": {
"first": "John",
"last": "Doe"
}
},
"vehicles": [{
"type": "car",
"model": "Honda Civic",
"insurance": {
"policy_num": "HA12345"
},
"maintenance": [{
"desc": "oil change",
"cost": "111.50",
"summary": [{
"line1": "0w20",
"line2": "synthetic"
}, {
"line1": "2.0L 4-cyl",
"line2": "4.4 quarts"
}]
}, {
"desc": "new tires",
"cost": "425.00",
"summary": [{
"line1": "235/40R18",
"line2": "4 tires"
}, {
"line1": "All Season",
"line2": "No spare"
}]
}]
}, {
"type": "truck",
"model": "Dodge Ram",
"insurance": {
"policy_num": "DR12345"
},
"maintenance": [{
"desc": "new tires",
"cost": "299.99",
"summary": [{
"line1": "275/60R20",
"line2": "2 tires"
}, {
"line1": "All Season",
"line2": "No spare"
}]
}, {
"desc": "oil change",
"cost": "111.50",
"summary": [{
"line1": "5w30",
"line2": "conventional"
}, {
"line1": "5.7L V8",
"line2": "7.0 quarts"
}]
}]
}],
"source": "internet"
}, {
"personal": {
"age": 24,
"gender": "F",
"name": {
"first": "Jane",
"last": "Roberts"
}
},
"vehicles": [{
"type": "car",
"model": "Toyota Camry",
"insurance": {
"policy_num": "TC98765"
},
"maintenance": [{
"desc": "tires rotated",
"cost": "389.50",
"summary": [{
"line1": "4 tires",
"line2": "leak repairs"
}]
}, {
"desc": "oil change",
"cost": "59.50",
"summary": [{
"line1": "0w20",
"line2": "special"
}]
}]
}, {
"type": "car",
"model": "Honda Accord",
"insurance": {
"policy_num": "HA98765"
},
"maintenance": [{
"desc": "new air filter",
"cost": "399.50",
"summary": [{
"line1": "17220-6B2-A00",
"line2": "rebuild assembly"
}]
}, {
"desc": "new brakes",
"cost": "799.50",
"summary": [{
"line1": "2-443344586",
"line2": "rear brake kit"
}]
}]
}],
"source": "phone"
}]
}
車両のメンテナンスデータを非正規化し、顧客の個人情報を除外するとします。
次の手順を実行して、ターゲットファイルを作成および設定します。
- 1手順1.マッピングを設計します。
- 2手順2.出力グループを設定します。
- 3手順3.マッピングを実行します。
手順1。マッピングを設計します
最初の手順として、Mapping Designerで、ソースおよびターゲットのトランスフォーメーションを使用して階層プロセッサを設定します。
Mapping Designerで次の手順を実行します。
- 1ショップのメンテナンスファイルをソースオブジェクトとして、ソーストランスフォーメーションをマッピングに追加します。
- 2階層プロセッサトランスフォーメーションをマッピングに追加し、ショップメンテナンスを入力ソースとして接続します。
- 3階層プロセッサトランスフォーメーションで、出力形式として[フラット化済み]を選択します。
- 4ターゲットトランスフォーメーションをマッピングに追加し、階層プロセッサトランスフォーメーションの出力をこのターゲットオブジェクトに接続します。
マッピングは次の図のようになります。
手順2。出力グループを設定します
基本的なマッピングを設定した後に、車両ショップのメンテナンスデータを使用して出力グループを作成します。
階層プロセッサトランスフォーメーションで次の手順を実行します。
- 1最上位の入力グループを選択します。これにより、すべての入力フィールドが自動的に選択され、出力に追加されます。
- 2personal(struct)をクリアします。これにより、構造内のすべての要素が自動的にクリアされ、出力から削除されます。
受信フィールドと出力フィールドは、次の図のようになります。
![[階層プロセッサ]タブが表示され、[出力形式フラット化済み]が選択されています。[受信フィールド]パネルには、次のフィールドを持つ1つの入力グループが表示されます: 選択済みのpeople(array)、未選択のpersonal(struct)、選択済みのvehicles(array)。vehicles配列には、policy_numフィールドを持つtype、model、insurance(struct)が含まれています。[出力フィールド]パネルには、type、model、policy_num、desc、cost、line1、line2の文字列フィールドを持つ1つのOutputグループが含まれています。](../jj-cloud-transformations/images/GUID-234162D3-D1BB-48E1-B39D-4A5B90B24DFC-low.png "[階層プロセッサ]タブが表示され、[出力形式フラット化済み]が選択されています。[受信フィールド]パネルには、次のフィールドを持つ1つの入力グループが表示されます: 選択済みのpeople(array)、未選択のpersonal(struct)、選択済みのvehicles(array)。vehicles配列には、policy_numフィールドを持つtype、model、insurance(struct)が含まれています。[出力フィールド]パネルには、type、model、policy_num、desc、cost、line1、line2の文字列フィールドを持つ1つのOutputグループが含まれています。")
- 3summary line1の出力フィールドをクリックし、名前を「Summary_line1」に変更します。
- 4summary line2についても、同様に名前の変更を行います。
次の図に、
[出力フィールドの編集]ダイアログボックスでフィールド名を編集する方法を示します。
![[出力フィールドの編集]ダイアログボックスに、Summary_line1に変更された出力フィールド名が表示されています。](../jj-cloud-transformations/images/GUID-4239CB4E-7DC9-4CE1-9E2F-24D2764DD327-low.png "[出力フィールドの編集]ダイアログボックスに、Summary_line1に変更された出力フィールド名が表示されています。")
- 5マッピングを確認します。
手順3。マッピングを実行します
最後の手順として、マッピングタスクを作成して実行し、JSON出力を生成します。
以下の手順を実行します。
- 1マッピングタスクを作成します。
- 2マッピングタスクを実行します。
- 3出力を確認します。
次の表に、マッピングを実行した後の、部分的に非正規化されたターゲット出力を示します。
type | model | policy_num | desc | cost | Summary_line1 | Summary_line2 | source |
|---|
car | Honda Civic | HA12345 | oil change | 111.5 | 0w20 | synthetic | internet |
car | Honda Civic | HA12345 | oil change | 111.5 | 2.0L 4-cyl | 4.4 quarts | internet |
car | Honda Civic | HA12345 | new tires | 425 | 235/40R18 | 4 tires | internet |
car | Honda Civic | HA12345 | new tires | 425 | All Season | No spare | internet |
truck | Dodge Ram | DR12345 | new tires | 299.99 | 275/60R20 | 2 tires | internet |
truck | Dodge Ram | DR12345 | new tires | 299.99 | All Season | No spare | internet |
truck | Dodge Ram | DR12345 | oil change | 111.5 | 5w30 | conventional | internet |
truck | Dodge Ram | DR12345 | oil change | 111.5 | 5.7L V8 | 7.0 quarts | internet |
car | Toyota Camry | TC98765 | tires rotated | 389.5 | 4 tires | leak repairs | phone |
car | Toyota Camry | TC98765 | oil change | 59.5 | 0w20 | special | phone |
car | Honda Accord | HA98765 | new air filter | 399.5 | 17220-6B2-A00 | rebuild assembly | phone |
car | Honda Accord | HA98765 | new brakes | 799.5 | 2-443344586 | rear brake kit | phone |
![[階層プロセッサ]タブが表示され、[出力形式フラット化済み]が選択されています。トランスフォーメーションには、左側のパネルに選択可能な受信フィールドが含まれ、右側のパネルに出力グループとフィールドが含まれます。出力フィールドへのリンクを使用すると、出力フィールドを変更できます。フィールド式は左側のパネルにも表示されます。](../jj-cloud-transformations/images/GUID-FC7254F4-63E4-4867-ADEA-5BBA5745DCAF-low.png "[階層プロセッサ]タブが表示され、[出力形式フラット化済み]が選択されています。トランスフォーメーションには、左側のパネルに選択可能な受信フィールドが含まれ、右側のパネルに出力グループとフィールドが含まれます。出力フィールドへのリンクを使用すると、出力フィールドを変更できます。フィールド式は左側のパネルにも表示されます。")