データベース取り込みおよびレプリケーションタスクとデータ統合タスクフローの統合
レプリケーション後のトランスフォーメーションを実行するには、データ統合タスクフローをトリガして取り込まれたデータを処理および変換するデータベース取り込みとレプリケーションタスクを設定できます。
この機能は、サポートされている任意のロードタイプを使用し、Amazon Redshift、Oracle、SQL Server、またはSnowflakeターゲットを持つタスクで使用できます。また、初期ロードタイプを使用し、Amazon S3、Azure SQL Database、Databricks、Google BigQuery、Google Cloud Storage、Kafka、Microsoft Azure Data Lake Storage Gen2、Microsoft Azure Synapse Analytics、Microsoft Fabric OneLake、Oracle Cloud Object Storage、またはPostgreSQLターゲットを持つタスクでも使用できます。
データベース取り込みとレプリケーションタスクを定義するときに、[タスクフローで実行]オプションを選択して、タスクをデータ統合のタスクフローに追加できるようにすることができます。Amazon Redshift、Oracle、Snowflake(Superpipeなし)、またはSQL Serverターゲットを使用した増分ロードジョブおよび組み合わせロードジョブの場合、必要に応じて[サイクルIDの追加]オプションを選択して、ターゲットテーブルにサイクルIDメタデータを含めます。[サイクルID]カラムは、行が更新されたサイクルを識別します。これはパラメータとしてタスクフローに渡され、トランスフォーメーションロジックを実行する行をフィルタリングするために使用できます。
データ統合でタスクフローを設定するときに、タスクをイベントソースとして選択し、取り込まれたデータを変換する適切なトランスフォーメーションタイプを追加できます。
設定タスクフロー:
- 1データ取り込みおよびレプリケーションタスク設定ウィザードで、データベース取り込みとレプリケーションタスクを定義する際に、次のオプションを選択します。
- - (オプション)[ターゲット]ページの[サイクルIDの追加]。このオプションを選択すると、各CDCサイクルに対して生成されたサイクルIDがターゲットテーブルに追加されます。Amazon Redshift、Oracle、SQL Serve ターゲット、およびSuperpipeオプションを使用しないSnowflakeターゲットに適用されます。
- - [スケジュールおよびランタイムオプション]ページの[タスクフローで実行]。このオプションにより、データ統合でタスクフローを定義するときにタスクを選択できるようになります。
- 2タスクの定義が完了したら、[保存]で保存します。
- 3データ統合でタスクフローを定義するには、ホームページの[調整]パネルをクリックします。
- 4タスクフローにデータベース取り込みとレプリケーションタスクを追加するには、次の手順を実行します。
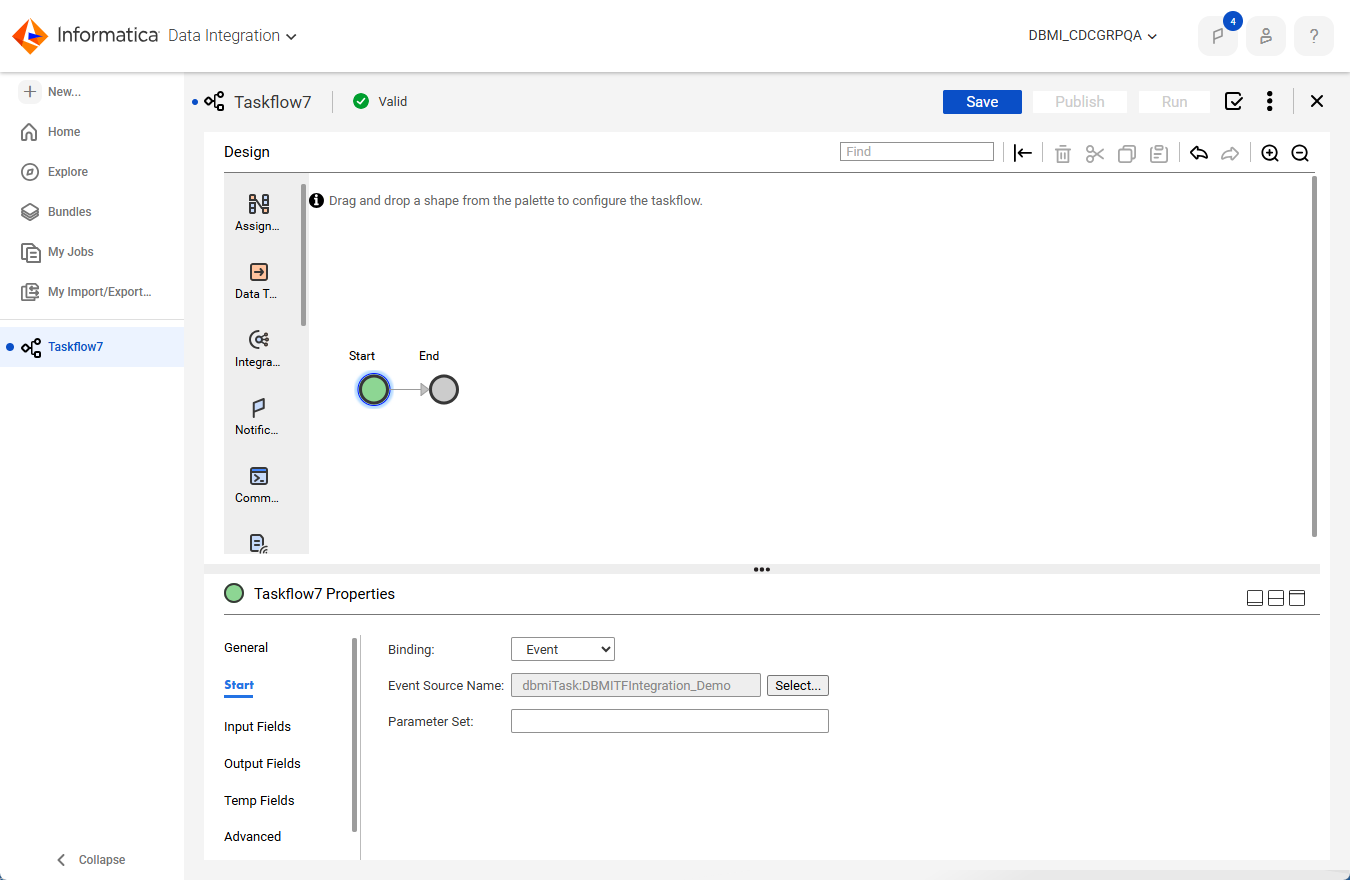
- a[タスクのプロパティ]で、[開始]をクリックします。
- b[バインディング]フィールドで[イベント]を選択します。
- c[イベントソース名]フィールドで、[選択]をクリックします。その後、[イベントソースの選択]ダイアログボックスで、データベース取り込みとレプリケーションタスクを選択して、[選択]をクリックします。
注: タスクリストは、タスクタイプごとにフィルタリングできます。
- d[イベントソース名]フィールドと[入力フィールド]にタスク名を表示されていることを確認します。例:
- eタスクフローを保存してパブリッシュします。
タスクフローは、初期ロードタスクが正常に完了したとき、または増分ロード操作の各CDCサイクルの後に開始するように自動的にトリガーされます。CDCサイクルが終了しても、前のタスクフローの実行がまだ実行中の場合、データはキューに入れられ、前のタスクフローが完了するまで待機します。