Sometimes, I see a low performance with the default Minimum Number of Rows for Split Process per Column and Maximum Number of Columns per Mapping values. How can I improve the data profiling task performance?
This issue might occur for large data sources where the number of rows is less than 100,000,000 and there are more than 50 columns. In this case, Data Profiling chooses column-based criteria and creates one subtask for every 50 columns. This consumes a lot of memory and processing power.
To resolve this issue, you can set the Minimum Number of Rows for Split Process per Column option to a higher value and the Maximum Number of Columns per Mapping option to a lower value.
For example, if a data source contains 10,000,000 rows and 100 columns, the data profiling task creates two subtasks with the default configuration. This consumes a lot of memory and results in a longer run time. In this case, you can retain the default value of Minimum Number of Rows for Split Process per Column and set the Maximum Number of Columns per Mapping option to 25. Data Profiling creates four subtasks which optimizes the performance and resource utilization. In addition, you can also increase the Secure Agent concurrency from the default 2 to (n), where n = Integer (0.8* number of cores) on the machine where Secure Agent runs.
Can I increase the Secure Agent concurrency to optimize the Data Profiling performance?
Yes, in addition to configuring the advanced options for data profiling tasks, you can configure the Secure Agent concurrency which impacts Data Profiling performance.
For example, assume that a data source contains 10,000,000 rows and 100 columns and the machine on which the Secure Agent runs has 4 cores.
To optimize the performance, perform the following steps:
1In Administrator, configure maxDTMProcesses to a value n, where n = Integer (0.8 * number of cores) on the machine where Secure Agent runs. In this case, set maxDTMProcesses to 3.
2In Data Profiling, create a profile for the data source.
3On the Schedule page, set Maximum Number of Columns per Mapping to 15.
4Save and run the profile.
In this case, Data Profiling generates 7 subtasks.
When I configure the Maximum Number of Columns per Mapping option to 20 for a data source with 100 columns, I see 8 subtasks for the profile on the My Jobs tab. Why do I see more subtasks than required?
When you create and run a profile, the following subtasks are generated and run:
- Fetching the source row count-<number_of_chosen_rows>. This task is generated only once for a profile run.
- Generating data profiling mappings. This subtask is generated only once for a profile run.
- s_profiling. The number of subtasks generated are based on the Minimum Number of Rows for Split Process per Column and Maximum Number of Columns per Mapping values. In this case, five subtasks are generated.
- Loading data from staging area to metric store. This task is generated only once for a profile run.
In this case, the total number of subtasks created for the task is eight subtasks.
What are the connections that create multiple mapping subtasks for a profile job?
The following is a list of connections that create multiple mapping subtasks for a profile job:
- Oracle
- SQL Server
- Flat File
- Azure Synapse SQL (ODBC)
- Amazon Redshift v2
- Snowflake Data Cloud
How can I confirm the number of mapping subtasks each profile job creates?
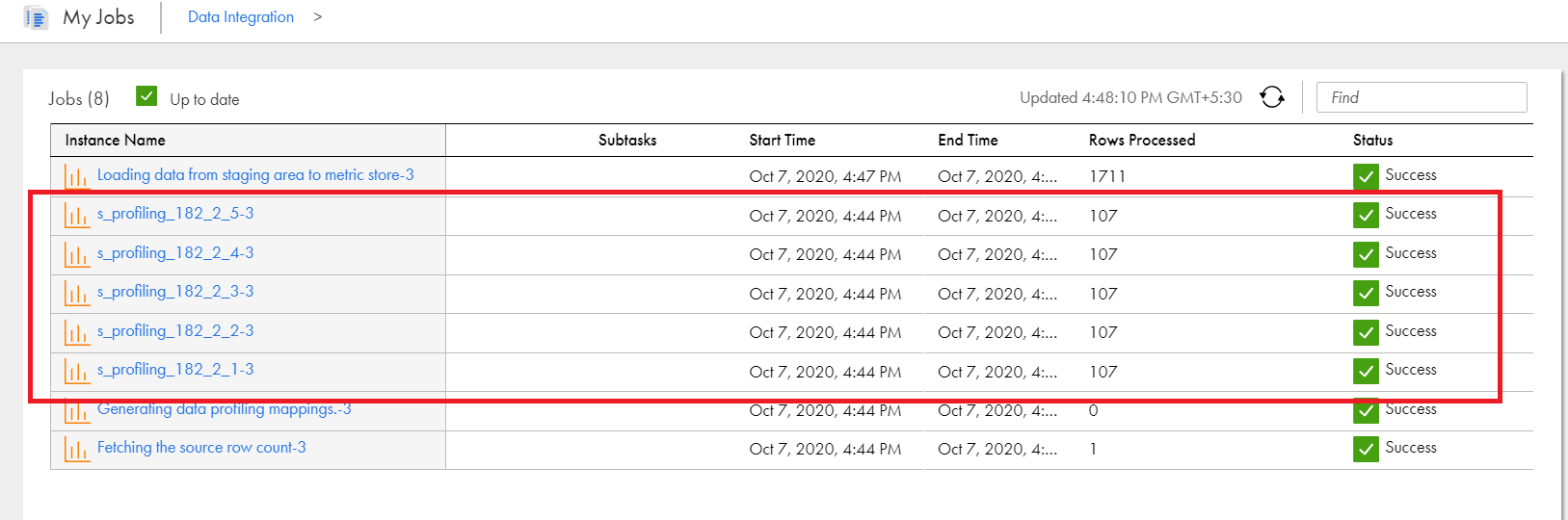
You can view the count of s_profiling jobs listed on the My Jobs tab. To view the s_profiling jobs, click the subtasks link on the My Jobs tab. For example, the following image displays the sample My Jobs tab with s_profiling jobs:
The profile job does not fail even if the Stop on Errors field value is set to a value that is less than equal to the sum of rows rejected.
This issue occurs when you apply multiple rules to a profile job. Data Profiling considers the maximum number of rows rejected by an individual rule. When a profile job includes multiple rules, Data Profiling stops the profile job on errors when the total number of reject rows cross the configuration of one of the rules, and not the sum of other rules.
I cannot view auto-assigned rules for the profiles after I change the source object or connection of my profile.
Data Profiling does not assign rules automatically when you edit and make changes to a profile.
The automatic rule association feature does not work for profiles that I created in R36.
Data Profiling associates rules automatically only if you create new profiles in 2021.07.M release (R37).
Profile job completes with the following warning message: Record length [] is longer than line sequential buffer length [] for <file location>. Record will be rejected. How do I resolve this issue?
To resolve this issue, increase the value of Line Sequential Buffer Length parameter till the error resolves. The parameter is located under the Advanced Options section on the Schedule tab of the profile.
Why is the length of the value frequency higher than the actual value frequency length on the Results page?
This issue might occur if the column data contains special characters such as an apostrophe ('). To resolve this issue, you can remove the special characters from the column data and rerun the profile.
The number of successful and unsuccessful rows in the preview does not show correct number of rows in the scorecard dashboard when you run a profile with random sampling for a specific number of rows?
The profile runs honour the sampling options whereas the drill down feature does not honour the sampling options. Due to this, the number of successful and unsuccessful rows shown in the preview does not match with the total number of rows shown in the Rule Occurrences table of the scorecard dashboard.
Data Profiling creates automatic rule specifications when insight validations have failed for columns that are either deselected from the profile definition or are deleted from the source. Can I delete these rules?
Yes, you can manually delete these rules from the Explorer tab.
Can you run native profiles using the serverless runtime environment?
Yes, you can run native profiles using the serverless runtime environment, but you cannot run Spark profiles.
Can you drilldown or query a profile that runs on a serverless runtime environment?
No, you cannot drilldown or query a profile that runs on a serverless runtime environment.