The July 2023 release of INFACore includes the following new features and enhancements.
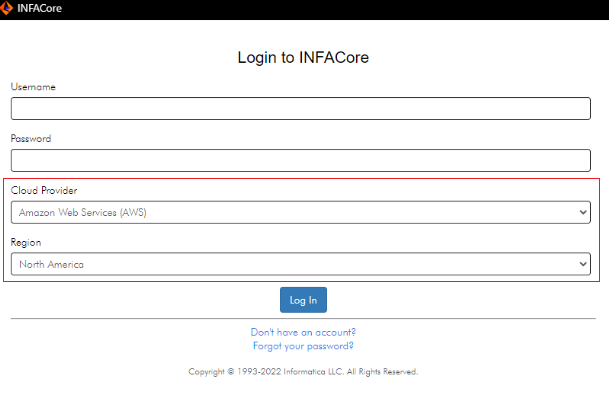
Cloud provider and region
When you log in to INFACore from the JupyterLab extension, the Log In page includes the cloud provider and region fields. The INFACore URL is created dynamically in a production POD. You do not need to explicitly enter the URL in your JupyterLab environment settings to log in to INFACore from JupyterLab in the production POD.
Select the cloud provider and region that correspond to the name of the POD (Point of Deployment) that your organization uses. This release includes only the Amazon Web Services (AWS) cloud provider and North America region.
For staging, test, and sandbox PODs, you need to manually enter the URL in your JupyterLab environment settings to log in to INFACore from JupyterLab.
Use Databricks as intermediate storage
You can use INFACore seamlessly within the Databricks ecosystem. For use cases that require intermediate staging of data, you have the option to configure a Databricks environment to stage the data temporarily. INFACore creates the Databricks native DataFrame for these use cases.
For more information on how to integrate Databricks with INFACore, see the INFACore SDK for Python documentation.
Advanced attributes for read and write operations
You can configure advanced attributes in the Python SDK code when you read from or write data to a data source. The advanced attribute options are listed when you call the get_advanced_config() method. To set the value of these attributes, call the set_advanced_config() method. The advanced attributes help you leverage additional functionalities in the data sources. For the list of advanced attributes that you can configure for a data source, see Connections for INFACore documentation.
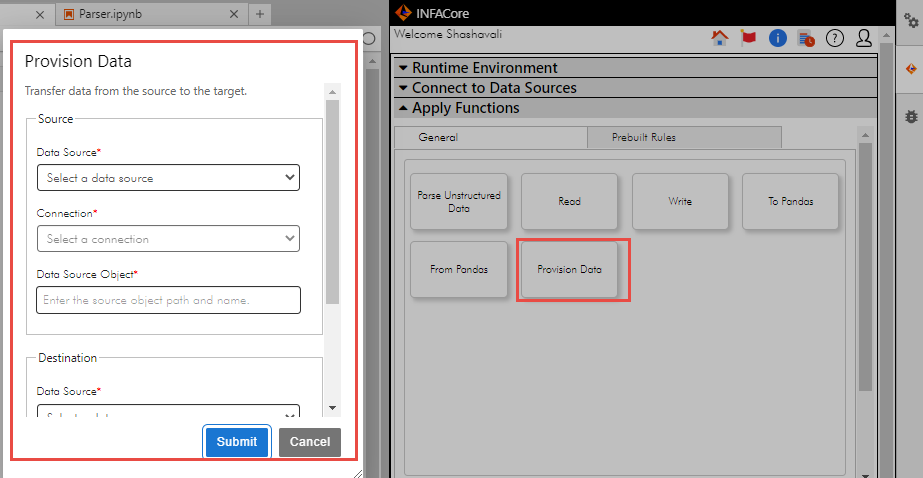
Provision data functionality
You can configure both the read and write operations together using the provision data function. Select the configured source and target connections and run the Python code to read from and write data. The provision data function simplifies the effort of configuring separate read and write operations and saves time.
For more information, see the JupyterLab Extension for INFACore documentation.