Intelligent Data Lake Concepts
To successfully administer Intelligent Data Lake, you must understand the concepts used in the product.
Catalog
A catalog is an indexed inventory of all the information assets in an enterprise. The assets can come from different types of enterprise systems. Assets can include such items as a database table, report, folder, user account, or business glossary definition.
The catalog provides a single comprehensive view of the data in the enterprise. The catalog contains metadata about each asset, including profile statistics, asset ratings, data domains, and data relationships. Metadata can come from scans of enterprise system repositories or from data enrichment by analysts.
You use Live Data Map to create the catalog. When you manage the catalog, you create resources to represent data sources. Each resource contains the properties required to connect to the data source, extract metadata from the data source, and load the metadata to the catalog.
Intelligent Data Lake requires that you use Live Data Map Administrator to create the following resource types for the catalog:
- Hive resource for the data lake
Create a Hive resource to represent the data lake. Create a schedule for the resource so that Live Data Map regularly extracts metadata from the Hive tables in the data lake. Analysts can use the Intelligent Data Lake application to search for, discover, and prepare data stored in the Hive tables.
- Resources for other enterprise systems
Create additional resources to represent other enterprise systems. You can create resources for data integration repositories, ETL and modeling tools and repositories, business glossaries, application databases, and other file storage and databases. Create a schedule for each resource so that Live Data Map regularly extracts metadata from the enterprise system.
Analysts can use the Intelligent Data Lake application to search for and discover data that resides in or outside the data lake. Analysts cannot prepare data stored outside the lake. However, when the catalog contains metadata across disparate enterprise systems, analysts can discover lineage and relationships between the data. They use this information to help identify which data they want to prepare and to help identify data that should be added to the data lake.
- Domain User resource
Use the DomainUsers resource in Live Data Map to create a list of users who have Informatica user accounts and can log in to the Intelligent Data Lake application. Create a schedule for the resource so that Live Data Map regularly extracts metadata from the Informatica user accounts.
When the catalog contains user metadata, the user information helps analysts discover the data. When analysts discover a data asset, the Intelligent Data Lake application lists other users who have used and prepared that data asset. This information helps analysts decide whether the data asset contains quality or trusted data.
Data Lake
A data lake is a centralized repository of large volumes of structured and unstructured data. A data lake can contain different types of data, including raw data, refined data, master data, transactional data, log file data, and machine data. In Intelligent Data Lake, the data lake is a Hadoop cluster.
Analysts use the Intelligent Data Lake application to search, discover, and prepare data that resides in the data lake. When analysts prepare the data, they combine, cleanse, and transform the data to create new insights.
Data can be added to the data lake in the following ways:
- Analysts use the Intelligent Data Lake application to upload data.
- Analysts can upload delimited text files to the data lake. When analysts upload data, Intelligent Data Lake writes the uploaded data to a Hive table in the data lake.
- Analysts use the Intelligent Data Lake application to publish prepared data.
- When analysts publish prepared data, Intelligent Data Lake writes the transformed input source to a Hive table in the data lake.
- Administrators run Informatica mappings to populate the data lake.
As an administrator, you can run Informatica mappings to read data from enterprise systems and write the data to Hive tables in the data lake. You can develop mappings or you can operationalize the mappings created during the Intelligent Data Lake publication process.
- Administrators and developers run third-party tools to load data into the data lake.
- Administrators, developers, or analysts can use data movement tools from other vendors to load data into the data lake.
Data Asset
A data asset is data that you work with as a unit. A data asset is one of the assets described in the catalog. Data assets can include items such as a flat file, table, or view. A data asset can include data stored in or outside the data lake.
Analysts use the Intelligent Data Lake application to search for and discover any assets included in the catalog. However, analysts can only prepare data assets that are stored in the data lake as Hive tables.
After analysts find the data asset they are interested in, they add the data asset to a project and then prepare the data for analysis. Data preparation includes combining, cleansing, transforming, and structuring data in project worksheets.
Data Publication
Data publication is the process of making prepared data available in the data lake.
When analysts publish prepared data, Intelligent Data Lake writes the transformed input source to a Hive table in the data lake. Other analysts can add the published data to their projects and create new data assets. Or analysts can use a third-party business intelligence or advanced analytic tool to run reports to further analyze the published data.
During the publication process, Live Data Map scans the published data to immediately add the metadata to the catalog.
Recipes and Mappings
A recipe includes the list of input sources and the steps taken to prepare data in a worksheet. When analysts publish prepared data, Intelligent Data Lake applies the recipe to the data in the input source. Intelligent Data Lake converts the recipe into an Informatica mapping and stores the mapping in the Model repository.
During the publication process, Intelligent Data Lake uses a similar naming convention for the projects and mappings stored in the Model repository. The mappings are accessible from the Developer tool. You can use the Developer tool to view the mappings generated from the recipes. You can operationalize the mappings to regularly load data with the new structure into the data lake.
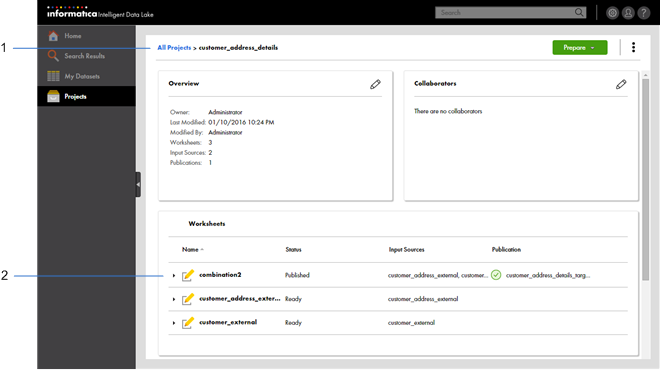
The following image displays a project named customer_address_details in the Intelligent Data Lake application. The project contains one worksheet with published data:
- 1. Project in the Intelligent Data Lake application
- 2. Worksheet with published data
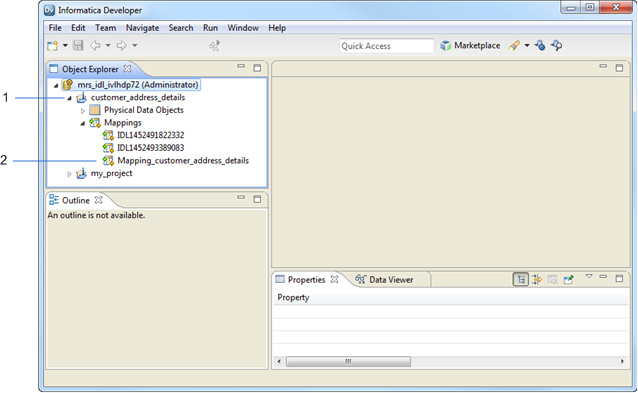
The following image displays the Object Explorer view in the Developer tool. The Object Explorer view displays the project and converted mapping stored in the Model repository during the publication of the prepared data in the customer_address_details project:
- 1. Project in the Developer tool
- 2. Converted mapping within the project