Architecture and Components
Enterprise Data Preparation uses a number of components to search, discover, and prepare data.
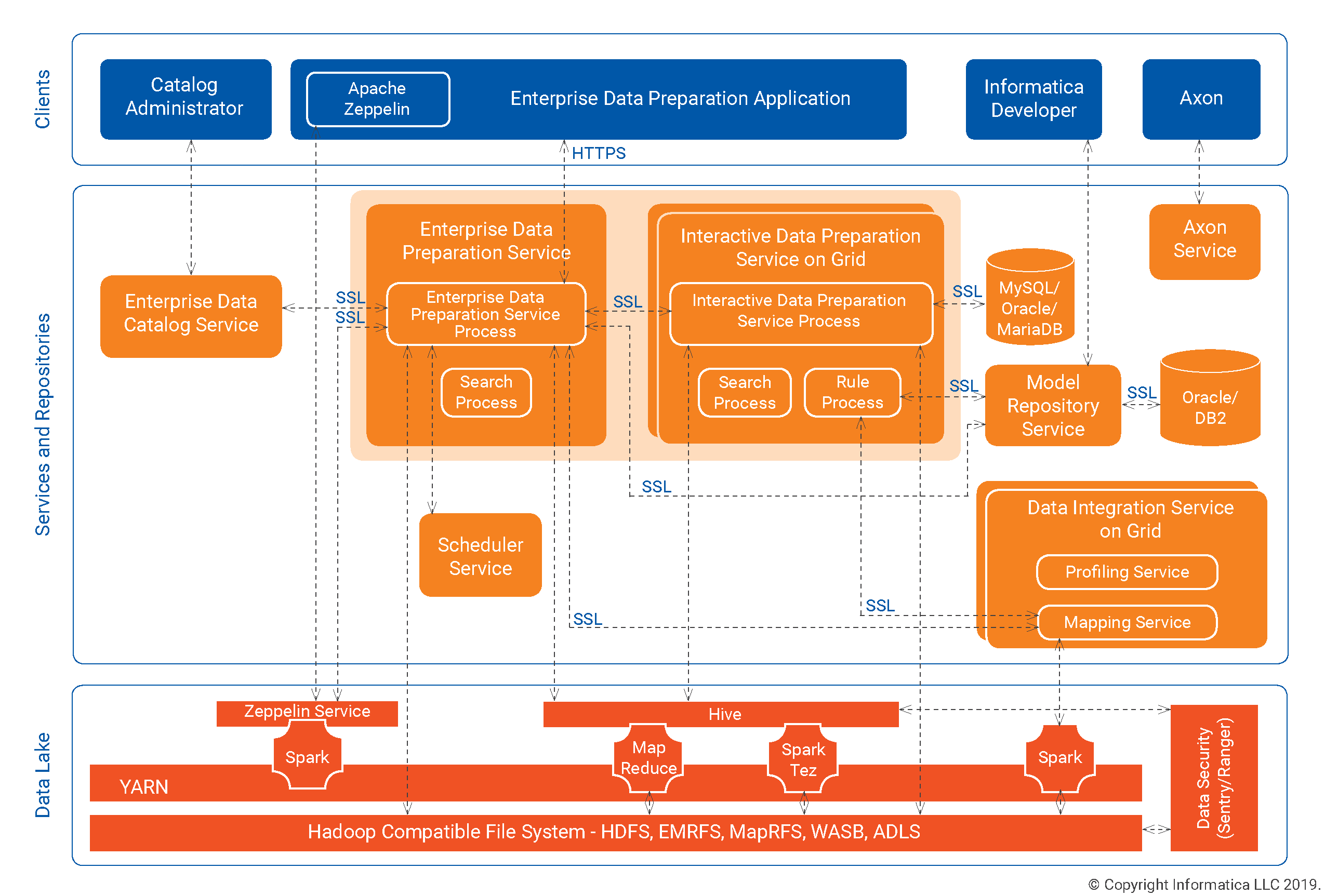
The following image provides an overview of the Enterprise Data Preparation deployment architecture:
Clients
Administrators and analysts use several clients to prepare and publish data in Enterprise Data Preparation. Clients can use Hyper Text Transfer Protocol Secure (HTTPS) to connect securely to Informatica application services.
Enterprise Data Preparation uses the following clients:
- Informatica Catalog Administrator
- Administrators use Informatica Catalog Administrator to administer the resources, scanners, schedules, attributes, and connections that are used to create the catalog. The catalog represents an indexed inventory of all the information assets in an enterprise.
- Informatica Administrator
- Administrators use Informatica Administrator (the Administrator tool) to manage the application services that Enterprise Data Preparation requires. They also use the Administrator tool to administer the Informatica domain and security and to monitor the mappings run during the upload and publishing processes.
- Enterprise Data Preparation application
- Analysts use the Enterprise Data Preparation application to search, discover, and prepare data that resides in the data lake. Analysts combine, cleanse, transform, and structure the data to prepare the data for analysis. When analysts finish preparing the data, they publish the transformed data back to the data lake to make available to other analysts.
- Informatica Developer
- Administrators use Informatica Developer (the Developer tool) to view the mappings created when analysts publish prepared data in the Enterprise Data Preparation application. Administrators then operationalize the mappings so that data is regularly written to the data lake.
- Apache Zeppelin
- Enterprise Data Preparation integrates with Apache Zeppelin to enable users to assess and validate data by visualizing published assets.
- Informatica Axon Data Governance
- Enterprise Data Preparation integrates with the Axon Data Governance knowledge repository tool to provide data governance and compliance.
Application Services and Repositories
Enterprise Data Preparation requires application services and repositories to complete operations.
Use the Administrator tool to create and manage the application services and configure connections to repositories. Application services can use the Secure Sockets Layer (SSL) protocol to connect securely to other services and to repository databases.
Enterprise Data Preparation requires the following application services:
- Enterprise Data Preparation Service
The Enterprise Data Preparation Service is an application service that runs the Enterprise Data Preparation application in the Informatica domain. When an analyst publishes prepared data, the Enterprise Data Preparation Service converts each recipe into a mapping.
When an analyst uploads data, the Enterprise Data Preparation Service connects to the HDFS system in the Hadoop cluster to temporarily stage the data. When an analyst previews data, the Enterprise Data Preparation Service connects to the Hadoop cluster to read from the Hive table.
- Interactive Data Preparation Service
The Interactive Data Preparation Service is an application service that manages data preparation within Enterprise Data Preparation. When an analyst prepares data in a project, the Interactive Data Preparation Service connects to the Data Preparation repository to store worksheet metadata. The service connects to the Hadoop cluster to read sample data or all data from the Hive table, depending on the size of the data. The service connects to the HDFS system in the Hadoop cluster to store the sample data being prepared in the worksheet.
When you create the Enterprise Data Preparation Service, you must associate it with a Interactive Data Preparation Service.
- Data Preparation repository
- When an analyst prepares data in a project, the Interactive Data Preparation Service stores worksheet metadata in the Data Preparation repository.
- Catalog Service
The Catalog Service is an application service that runs Enterprise Data Catalog in the Informatica domain. The Catalog Service manages the catalog of information assets in the Hadoop cluster.
When an analyst searches for assets in Enterprise Data Preparation, the Enterprise Data Preparation Service connects to the Catalog Service to return search results from the metadata stored in the catalog.
When you create the Enterprise Data Preparation Service, you must associate it with a Catalog Service.
- Model Repository Service
The Model Repository Service is an application service that manages the Model repository. When an analyst creates projects, the Enterprise Data Preparation Service connects to the Model Repository Service to store the project metadata in the Model repository. When an analyst publishes prepared data, the Enterprise Data Preparation Service connects to the Model Repository Service to store the converted mappings in the Model repository.
You must associate the Enterprise Data Preparation Service with a Model Repository Service. Informatica recommends that you create a dedicated Model Repository Service and Model repository for use by Enterprise Data Preparation.
If you configure Enterprise Data Preparation to use rules, you must associate the Model Repository Service that manages the Model repository in which rule objects and metadata are stored with the Interactive Data Preparation Service.
- Model repository
- When an analyst creates a project, the Enterprise Data Preparation Service connects to the Model Repository Service to store the project metadata in the Model repository. When an analyst publishes prepared data, the Enterprise Data Preparation Service converts each recipe to a mapping. The Enterprise Data Preparation Service connects to the Model Repository Service to store the converted mappings in the Model repository.
- Data Integration Service
The Data Integration Service is an application service that performs data integration tasks for Enterprise Data Preparation. When an analyst uploads data or publishes prepared data, the Enterprise Data Preparation Service connects to the Data Integration Service to write the data to a Hive table in the Hadoop cluster.
You must associate the Enterprise Data Preparation Service with a Data Integration Service. Informatica recommends that you create a dedicated Data Integration Service for use by Enterprise Data Preparatione.
If you configure Enterprise Data Preparation to use rules, you must associate a Data Integration Service with the Interactive Data Preparation Service. The Data Integration Service is required to run rules during data preparation.
Data Lake
The data lake used by Enterprise Data Preparation is a centralized repository of large volumes of structured and unstructured data. A data lake can contain different types of data, including raw data, refined data, master data, transactional data, log file data, and machine data.
The data lake can be deployed on-premise or in the cloud. The data lake utilizes Hive, the Spark engine, and a Hadoop-compatible file system. The data lake must be collocated with the Informatica application services associated with Enterprise Data Preparation. For example, if the data lake is deployed in Amazon EMR, you must also deploy Enterprise Data Preparation, Enterprise Data Catalog, and the Informatica services in Amazon EMR.
Enterprise Data Preparation works with the security mechanism used by the cluster, including Kerberos, Apache Ranger, and Apache Sentry, to securely access data in the data lake.
You can upload assets such as comma-separated value files as Hive tables in the data lake using Enterprise Data Preparation.
You can also ingest data from external sources outside the data lake using Hadoop tools or Informatica Mass Ingestion.
You can prepare a Hive or file-based asset that exists in Enterprise Data Catalog. When you prepare a file-based asset, Enterprise Data Preparation creates an external temporary table in the Hive schema specified in the Enterprise Data Preparation Service.
When you publish prepared data, Enterprise Data Preparation writes the transformed input source to a Hive table or to a file in the data lake.