Berechnungskomponente
Die Berechnungskomponente des Datenintegrationsdiensts ist der Data Transformation Manager (DTM) für die Ausführung. Der DTM extrahiert, lädt und wandelt Daten um, um einen Datenumwandlungsjob abzuschließen.
Der DTM muss auf einem Knoten mit der Berechnungsrolle ausgeführt werden. Ein Knoten mit der Berechnungsrolle kann Berechnungen durchführen, die von Anwendungsdiensten angefragt werden.
Data Transformation Manager für die Ausführung
Der Data Transformation Manager (DTM) für die Ausführung extrahiert, lädt und wandelt Daten um, um einen Datenumwandlungsjob wie eine Vorschau bzw. ein Mapping auszuführen.
Wenn ein Dienstmodul im Datenintegrationsdienst eine Anfrage zur Ausführung eines Jobs erhält, sendet es diese Anfrage an den LDTM. Der LDTM optimiert und kompiliert den Job und sendet den kompilierten Job dann an den DTM. Es wird eine DTM-Instanz gestartet, um den Job auszuführen und die Anfrage abzuschließen.
Eine DTM-Instanz ist eine bestimmte, logische Darstellung des DTM. Der Datenintegrationsdienst führt mehrere DTM-Instanzen aus, um mehrere Anfragen abzuschließen. So führt der Datenintegrationsdienst beispielsweise jedes Mal, wenn er vom Developer Tool eine Anfrage wegen einer Mapping-Vorschau erhält, eine separate DTM-Instanz aus.
Der DTM schließt die folgenden Jobtypen ab:
- •Mappings ausführen bzw. eine Vorschau davon anzeigen
- •Mappings in Arbeitsabläufen ausführen
- •Vorschau von Umwandlungen anzeigen
- •SQL-Datendienste ausführen oder abfragen
- •Webdienstvorgänge ausführen
- •Datenprofile ausführen bzw. eine Vorschau davon anzeigen
- •Scorecards generieren
Richtlinie für DTM-Ressourcenzuweisung
Die Richtlinie für die Ressourcenzuweisung durch den Data Transformation Manager legt fest, wie die CPU-Ressourcen für Aufgaben zugewiesen werden. Der DTM weist CPU-Ressourcen mithilfe einer Richtlinie für die bedarfsabhängige Ressourcenzuweisung zu.
Wenn der DTM ein Mapping ausführt, konvertiert er dieses in eine Gruppe von Aufgaben. Beispiele:
- •Initialisieren und Deinitialisieren von Pipelines
- •Lesen von Daten aus der Quelle
- •Umwandeln von Daten
- •Schreiben von Daten in das Ziel
Der DTM weist CPU-Ressourcen nur dann zu, wenn eine DTM-Aufgabe einen Thread erfordert. Wenn eine Aufgabe abgeschlossen oder inaktiv ist, gibt sie den Thread an einen Thread-Pool zurück. Der DTM verwendet die Threads im Thread-Pool für andere DTM-Aufgaben wieder.
Verarbeitungs-Threads
Wenn der DTM Mappings ausführt, verwendet er Reader-, Umwandlungs- und Writer-Pipelines, die parallel ausgeführt werden, um Daten zu extrahieren, zu transformieren und zu laden.
Der DTM trennt ein Mapping in Pipeline-Stages und verwendet einen Reader-Thread, einen Umwandlungs-Thread und einen Writer-Thread zur Verarbeitung jeder Stage. Jede Pipeline-Stage wird in einem der folgenden Threads ausgeführt:
- •Reader-Thread, der die Datenextraktion aus der Quelle durch den DTM steuert.
- •Umwandlungs-Thread, der die Datenverarbeitung in der Pipeline durch die DTM-Prozesse steuert.
- •Writer-Thread, der den Datenladevorgang in das Ziel durch den DTM steuert.
Da die Pipeline drei Stages enthält, kann der DTM gleichzeitig drei Zeilensätze verarbeiten und die Mapping-Leistung optimieren. Während der Reader-Thread beispielsweise den dritten Zeilensatz verarbeitet, verarbeitet der Umwandlungs-Thread den zweiten Zeilensatz und der Writer-Thread den ersten Zeilensatz.
Wenn Sie über die Partitionierungsoption verfügen, kann der Datenintegrationsdienst den Parallelismus für Mappings und Profile maximieren. Wenn Sie den Parallelismus maximieren, unterteilt der DTM ein Mapping in Pipeline-Stages und nutzt zur Verarbeitung der einzelnen Stages mehrere Threads.
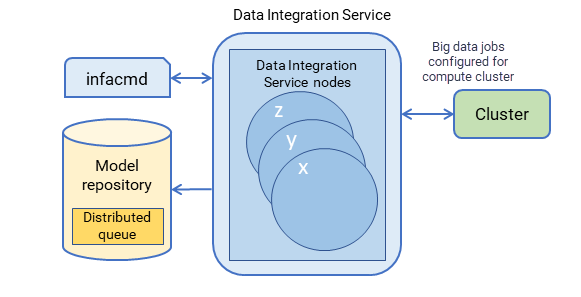
Datenintegrationsdienst Queueing
Der Datenintegrationsdienst verwendet eine verteilte Warteschlange, um Jobinformationen solange zu speichern, bis Ressourcen zum Ausführen des Jobs verfügbar sind. Die verteilte Warteschlange wird im Modellrepository gespeichert und gegebenenfalls vom Backup-Knoten oder von allen Knoten im Gitter gemeinsam genutzt.
Wenn Sie einen Zuordnungsjob oder eine Arbeitsablaufzuordnungsaufgabe ausführen, fügt der Datenintegrationsdienst den Job zur Warteschlange hinzu. Der Jobstatus wird im Inhaltsbereich des Administrator Tools als „In Warteschlange eingereiht“ angezeigt. Wenn Ressourcen verfügbar sind, entnimmt der Datenintegrationsdienst der Warteschlange einen Job und führt ihn aus.
Die folgende Abbildung zeigt den Speicherort der verteilten Warteschlange:
Stellen Sie sich folgenden Warteschlangenprozess vor:
- 1Ein Client übermittelt eine Jobanfrage an den Datenintegrationsdienst, der Jobmetadaten in der verteilten Warteschlange speichert.
- 2Stehen dem Datenintegrationsdienstknoten Ressourcen zur Verfügung, ruft der Datenintegrationsdienst den Job aus der Warteschlange ab und sendet ihn zur Verarbeitung an den verfügbaren Knoten.
- 3Fällt ein Knoten während der Ausführung eines Jobs aus, kann für den Job ein Failover auf einen anderen Knoten durchgeführt werden. Jeder Backup-Knoten oder Knoten im Gitter kann Jobs aus der Warteschlange übernehmen.
- 4Der unterbrochene Job wird auf dem neuen Knoten ausgeführt.
Wenn Sie einen Job ausführen, der nicht in die Warteschlange eingereiht werden kann, beginnt der Datenintegrationsdienst sofort mit der Ausführung des Jobs. Stehen nicht genügend Ressourcen zur Verfügung, schlägt der Job fehl. Der Job muss dann erneut ausgeführt werden, wenn entsprechende Ressourcen verfügbar sind.
Die folgenden Jobs können nicht in die Warteschlange eingereiht werden:
- •Jobs, die nicht bereitgestellt werden können, wie z. B. Vorschauen und Profile
- •Bedarfsorientierte Jobs
- •SQL-Abfragen
- •Webdienstanfragen
Sie können den Befehl infacmd ms abortAllJobs verwenden, um alle Jobs in der Warteschlange abzubrechen, oder mit dem Befehl infacmd ms purgeDatabaseWorkTables die Warteschlange löschen.
Ausgabedateien
Der DTM generiert Ausgabedateien, wenn er Mappings, in einem Arbeitsablauf enthaltene Mappings, Profile, SQL-Abfragen an einen SQL-Datendienst oder Vorgangsanfragen für Webdienste ausführt. Basierend auf den Cache-Einstellungen und den Zieltypen für die Umwandlung kann der DTM Cache-, Ablehnungs- und Zieldateien sowie temporäre Dateien erstellen.
Der DTM speichert Ausgabedateien standardmäßig in den Verzeichnissen, die durch die Ausführungsoptionen für den Datenintegrationsdienst definiert wurden.
Datenobjekte und -umwandlungen im Developer Tool verwenden Systemparameter, um auf die Werte der betreffenden Datenintegrationsdienst-Verzeichnisse zuzugreifen. Standardmäßig werden die Systemparameter Feldern im Einfachdateiverzeichnis, Cache-Dateiverzeichnis und temporären Dateiverzeichnis zugewiesen.
Wenn ein Entwickler beispielsweise im Developer Tool eine Aggregatorumwandlung erstellt, ist der Systemparameter „CacheDir“ der Standardwert, der dem Cache-Verzeichnisfeld zugewiesen wird. Der Wert des Systemparameters „CacheDir“ wird in der Eigenschaft Cache-Verzeichnis für den Datenintegrationsdienst definiert. Entwickler können den Standardsystemparameter entfernen und einen anderen Wert für das Cache-Verzeichnis eingeben. Allerdings können Jobs nicht ausgeführt werden, wenn der Datenintegrationsdienst nicht auf das Verzeichnis zugreifen kann.
Im Developer Tool können Entwickler die standardmäßigen Systemparameter ändern, um für jede Umwandlung bzw. jedes Datenobjekt unterschiedliche Verzeichnisse zu definieren.
Cache-Dateien
Der DTM erstellt mindestens eine Cache-Datei für jede Aggregator-, Joiner-, Lookup-, Rang- und Sortiererumwandlung, die in einem Mapping, Profil, SQL-Datendienst oder Webdienstvorgangs-Mapping enthalten ist.
Wenn der DTM eine Umwandlung im Speicher nicht verarbeiten kann, schreibt er die Überlaufwerte in Cache-Dateien. Bei Abschluss des Jobs gibt der DTM den Cache-Speicher frei und löscht in der Regel die Cache-Dateien.
Der DTM speichert Cache-Dateien standardmäßig für Aggregator-, Joiner-, Lookup- und Rangumwandlungen in der Liste der Verzeichnisse, die durch die Eigenschaft „Cache-Verzeichnis“ für den Datenintegrationsdienst definiert wurden. Der DTM erstellt Index- und Daten-Cache-Dateien. Er benennt die Indexdatei mit PM*.idx und die Datendatei mit PM*.dat.
Der DTM speichert die Cache-Dateien für Sortiererumwandlungen in der Liste der Verzeichnisse, die durch die Eigenschaft „Temporäre Verzeichnisse“ für den Datenintegrationsdienst definiert wurden. Der DTM erstellt eine Sortierer-Cache-Datei.
Ablehnungsdateien
Der DTM erstellt eine Ablehnungsdatei für jede Zielinstanz in einem Mapping bzw. Webdienstvorgangs-Mapping. Wenn der DTM eine Zeile nicht in das Ziel schreiben kann, schreibt er die abgelehnte Zeile in die Ablehnungsdatei. Falls die Ablehnungsdatei keine abgelehnten Zeilen enthält, wird sie vom DTM beim Abschluss des Jobs gelöscht.
Der DTM speichert Ablehnungsdateien standardmäßig in dem Verzeichnis, das durch die Eigenschaft „Verzeichnis für abgelehnte Dateien“ für den Datenintegrationsdienst definiert wurde. Der DTM benennt Ablehnungsdateien basierend auf dem Namen des Zieldatenobjekts. Der Standardname für Ablehnungsdateien lautet <file_name>.bad.
Zieldateien
Falls ein Mapping oder Webdienstvorgangs-Mapping in ein Einfachdateiziel schreibt, erstellt der DTM die Zieldatei basierend auf der Konfiguration des Einfachdatei-Datenobjekts.
Der DTM speichert Zieldateien standardmäßig in der Liste der Verzeichnisse, die durch die Eigenschaft „Zielverzeichnis“ für den Datenintegrationsdienst definiert wurden. Der DTM benennt Zieldateien basierend auf dem Namen des Zieldatenobjekts. Der Standardname für Zieldateien lautet <file_name>.out.
Temporäre Dateien
Der DTM kann temporäre Dateien erstellen, wenn er Mappings, Profile, SQL-Abfragen oder Webdienstvorgangs-Mappings ausführt. Die temporären Dateien werden in der Regel beim Abschluss der Jobs gelöscht.
Der DTM speichert temporäre Dateien standardmäßig in der Liste der Verzeichnisse, die durch die Eigenschaft „Temporäre Verzeichnisse“ für den Datenintegrationsdienst definiert wurden. Der DTM speichert auch die Cache-Dateien für Sortiererumwandlungen in der Liste der Verzeichnisse, die durch die Eigenschaft „Temporäre Verzeichnisse“ definiert wurden.