Spark Engine Configuration
If you want to use the Spark runtime engine to run mappings in the Hadoop environment, perform the following configuration tasks in the Big Data Management installation.
- 1. Reset system settings to allow more processes and files.
- 2. Enable dynamic allocation.
- 3. Enable the Spark shuffle service.
The Spark engine can run mappings on all Hadoop distributions.
Reset System Settings to Allow More Processes and Files
If you want to use Spark to run mappings on the Hadoop cluster, increase operating system settings on the machine that hosts the Data Integration Service to allow more user processes and files.
To get a list of the operating system settings, including the file descriptor limit, run the following command:
- C Shell
- limit
- Bash Shell
- ulimit -a
Informatica service processes can use a large number of files. Set the file descriptor limit per process to 16,000 or higher. The recommended limit is 32,000 file descriptors per process.
To change system settings, run the limit or ulimit command with the pertinent flag and value. For example, to set the file descriptor limit, run the following command:
- C Shell
- limit -h filesize <value>
- Bash Shell
- ulimit -n <value>
Configure Dynamic Resource Allocation for Spark
You can dynamically adjust the resources that an application occupies based on the workload. This concept is known as dynamic allocation. You can configure dynamic allocation for mappings to run on the Spark engine.
You can configure dynamic resource allocation for Spark mappings to run on the following Hadoop distributions:
- •Amazon EMR
- •Cloudera
- •HortonWorks HDP
- •Other Hadoop distributions
Note: Individual Hadoop distribution vendors often publish information on configuring dynamic resource allocation for their cluster environments. Check their documentation for additional information for this task.
Configuring Dynamic Resource Allocation on Amazon EMR Clusters
1. Copy the Spark shuffle .jar file from the Hadoop distribution library on the cluster to the following directory:
/usr/lib/hadoop-yarn/lib
2. On each of the cluster nodes where Yarn node manager is running, open the following file for editing:
/etc/hadoop/conf/yarn-site.xml
3. Add the following properties and values to yarn-site.xml:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle,spark_shuffle</value>
</property><property>
<name>yarn.nodemanager.aux-services.spark_shuffle.class</name>
<value>org.apache.spark.network.yarn.YarnShuffleService</value>
</property>
4. On all nodes where the node manager runs, restart the yarn node manager service.
5. On the machine where the Data Integration Service runs, back up the following file and then open it for editing: <InformaticaInstallationDir>/services/shared/hadoop/amazon_emr<version_number>/infaConf/HadoopEnv.properties
6. Configure the following properties:
Property | Set Value to |
|---|
spark.dynamicAllocation.enabled | TRUE |
spark.shuffle.service.enabled | TRUE |
7. Locate the property spark.executor.instances and comment it out.
The commented-out property appears like the following example:
#spark.executor.instances=100
8. Save and close the file.
Dynamic allocation is configured for mappings to run on the Spark engine. You can see a message like this in the application log:
ExecutorAllocationManager: Requesting 2 new executors because tasks are backlogged (new desired total will be 3)
Configuring Dynamic Resource Allocation on Cloudera Clusters
1. On the machine where the Data Integration Service runs, back up the following file and then open it for editing: <InformaticaInstallationDir>/services/shared/hadoop/cloudera_cdh<version_number>/infaConf/HadoopEnv.properties
2. Configure the following properties:
Property | Set Value to |
|---|
spark.dynamicAllocation.enabled | TRUE |
spark.shuffle.service.enabled | TRUE |
3. Locate the property spark.executor.instances and comment it out.
The commented-out property appears like the following example:
#spark.executor.instances=100
4. On the cluster name node, use a command window to browse to the following directory: /opt/cloudera/parcels/CDH-<version>/lib/hadoop-yarn/lib/. Make sure one of the following .jar files is present:
- - spark-1.6.0-cdh<version_number>-yarn-shuffle.jar
- - spark-yarn-shuffle.jar
If the file is not present, or if an older version is present, use the .jar file bundled with the Informatica Big Data Management download. To access this file, use the Ambari or Cloudera cluster configuration browser to update the yarn.application.classpath property to include one of the following values, depending on your version of Spark:
- - For Spark 1.6x:
/opt/Informatica/services/shared/hadoop/cloudera_cdh5u8_custom/spark/lib/spark-1.6.0-cdh5.8.0-yarn-shuffle.jar
- - For Spark 2.0x:
/opt/Informatica/services/shared/spark/lib_spark_2.0.1_hadoop_2.6.0/yarn/spark-2.0.1-yarn-shuffle.jar
5. In the cluster configuration manager interface, browse to the following configuration screen: YARN Service Advance Configuration Snippet (Safety Valve) for yarn-site.xml. Add the following properties:
Name | Value |
|---|
yarn.nodemanager.aux-services | mapreduce_shuffle,spark_shuffle |
yarn.nodemanager.aux-services.spark_shuffle.class | org.apache.spark.network.yarn.YarnShuffleService |
The resulting screen should look like the following image:
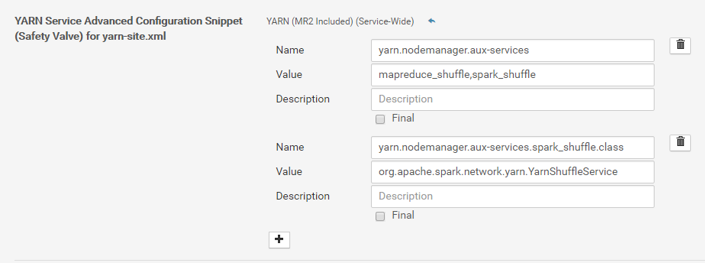
6. Restart the Yarn service on the cluster.
When the Yarn service restarts, look for the following message in the Yarn nodemanager log:
org.apache.spark.network.yarn.YarnShuffleService: Started YARN shuffle service for Spark on port 7337.
In the application log on the cluster, look for the following message:
INFO util.Utils: Using initial executors = 0, max of spark.dynamicAllocation.initialExecutors, spark.dynamicAllocation.minExecutors and spark.executor.instances
Dynamic resource allocation is configured for mappings to run on the Spark engine.
Configuring Dynamic Resource Allocation on HortonWorks Clusters
1. On the machine where the Data Integration Service runs, back up the following file and then open it for editing: <InformaticaInstallationDir>/services/shared/hadoop/hortonworks_<version_number>/infaConf/HadoopEnv.properties
2. Configure the following properties:
Property | Set Value to |
|---|
spark.dynamicAllocation.enabled | TRUE |
spark.shuffle.service.enabled | TRUE |
3. Locate the property spark.executor.instances and comment it out.
The commented-out property appears like the following example:
#spark.executor.instances=100
4. On the cluster name node, use a command window to browse to the following directory: usr/hdp/<Current version>. Make sure one of the following .jar files are present:
- - /usr/hdp/<Current version>/spark/aux/spark-1.6.2.2.5.0.0-1245-yarn-shuffle.jar
- - /usr/hdp/<Current version>/spark2/aux/spark-2.0.0.2.5.0.0-1245-yarn-shuffle.jar
If the file is not present, or if an older version is present, use the .jar file bundled with the Informatica Big Data Management download. To access this file, use the Ambari or Cloudera cluster configuration browser to update the yarn.application.classpath property to include the following value:
/opt/Informatica/services/shared/spark/lib_spark_2.0.1_hadoop_2.6.0/yarn/spark-2.0.1-yarn-shuffle.jar
5. In the Ambari cluster configuration browser, select the YARN service and click the Advanced tab. Add the following properties if they do not exist.
Add the following properties in the Node Manager section:
Property | Value |
|---|
yarn.nodemanager.aux-services | mapreduce_shuffle,spark_shuffle,spark2_shuffle |
Add the following properties in the Advanced yarn-site section:
Property | Value |
|---|
yarn.nodemanager.aux-services.spark_shuffle.classpath | {stack_root}}/${hdp.version}/spark/aux/* |
yarn.nodemanager.aux-services.spark_shuffle.class | org.apache.spark.network.yarn.YarnShuffleService |
6. Restart the Yarn service on the cluster.
When the Yarn service restarts, look for the following message in the cluster console:
org.apache.spark.network.yarn.YarnShuffleService: Started YARN shuffle service for Spark on port <number>.
In the application log on the cluster, look for the following message:
Using initial executors = 0, max of spark.dynamicAllocation.initialExecutors, spark.dynamicAllocation.minExecutors and spark.executor.instances
Dynamic resource allocation is configured for mappings to run on the Spark engine.
Configure Dynamic Resource Allocation on Azure HDInsight and IBM Big Insights
1. On the machine where the Data Integration Service runs, back up the following file and then open it for editing: <InformaticaInstallationDir>/services/shared/hadoop/hortonworks_<version_number>/infaConf/HadoopEnv.properties
2. Configure the following properties:
Property | Set Value to |
|---|
spark.dynamicAllocation.enabled | TRUE |
spark.shuffle.service.enabled | TRUE |
3. Locate the property spark.executor.instances and comment it out.
The commented-out property appears like the following example:
#spark.executor.instances=100
4. Locate the Spark shuffle .jar file and note the location. The file is located in the following path: /opt/Informatica/services/shared/spark/lib_spark_2.0.1_hadoop_2.6.0/spark-network-shuffle_2.11-2.0.1.jar.
5. Add the Spark shuffle .jar file location to the classpath of each cluster node manager.
6. Edit the yarn-site.xml file in each cluster node manager.
The file is located in the following location: <Informatica installation directory>/services/shared/hadoop/hortonworks_<version>/conf/
- a. Change the value of the yarn.nodemanager.aux-services property as follows:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle,spark_shuffle</value>
</property>
- b. Add the following property-value pairs:
yarn.nodemanager.aux-services.spark_shuffle.class=org.apache.spark.network.yarn.YarnShuffleService
Dynamic resource allocation is configured for mappings to run on the Spark engine.
Configure Performance Properties
To improve performance of mappings that run on the Spark run-time engine, you can configure Spark properties within the Hadoop properties file, hadoopEnv.properties.
1. Open hadoopEnv.properties and back it up.
You can find the file in the following location: <Informatica installation directory>/services/shared/hadoop/<Hadoop_distribution_name>_<version_number>/infaConf/
2. Configure the following properties:
Property | Value | Description |
|---|
spark.dynamicAllocation.enabled | TRUE | Enables dynamic resource allocation. Required when you enable the external shuffle service. |
spark.shuffle.service.enabled | TRUE | Enables the external shuffle service. Required when you enable dynamic allocation. |
spark.scheduler.maxRegisteredResourcesWaitingTime | 15000 | The number of milliseconds to wait for resources to register before scheduling a task. Reduce this from the default value of 30000 to reduce any delay before starting the Spark job execution. |
spark.scheduler.minRegisteredResourcesRatio | 0.5 | The minimum ratio of registered resources to acquire before task scheduling begins. Reduce this from the default value of 0.8 to reduce any delay before starting the Spark job execution. |
3. Locate the spark.executor.instances property and place a # character at the beginning of the line to comment it out.
Note: If you enable dynamic allocation for the Spark engine, Informatica recommends that you comment out this property.
After editing, the line appears as follows:
#spark.executor.instances=100