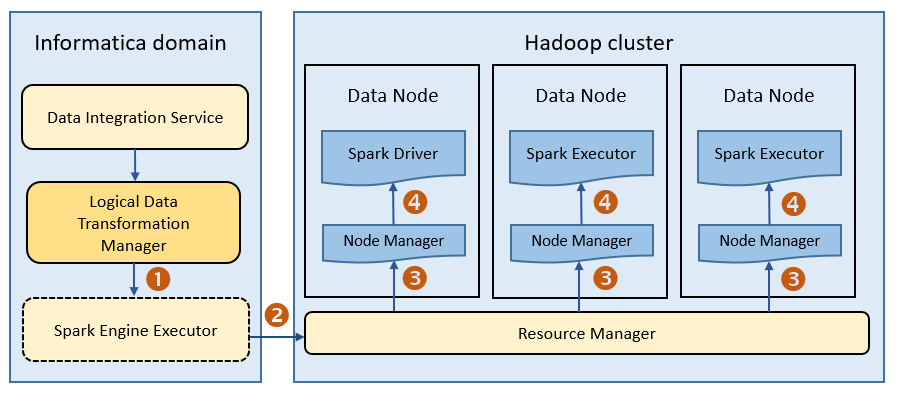
Spark Engine Architecture
The Data Integration Service can use the Spark engine on a Hadoop cluster to run Model repository mappings.
To run a mapping on the Spark engine, the Data Integration Service sends a mapping application to the Spark executor. The Spark executor submits the job to the Hadoop cluster to run.
The following image shows how a Hadoop cluster processes jobs sent from the Spark executor:
The following events occur when Data Integration Service runs a mapping on the Spark engine:
- 1. The Logical Data Transformation Manager translates the mapping into a Scala program, packages it as an application, and sends it to the Spark executor.
- 2. The Spark executor submits the application to the Resource Manager in the Hadoop cluster and requests resources to run the application.
- 3. The Resource Manager identifies the Node Managers that can provide resources, and it assigns jobs to the data nodes.
- 4. Driver and Executor processes are launched in data nodes where the Spark application runs.