Big Data Management Engines
When you run a big data mapping, you can choose to run the mapping in the native environment or a Hadoop environment. If you run the mapping in a Hadoop environment, the mapping will run on one of the following job execution engines:
- •Blaze engine
- •Spark engine
- •Hive engine
For more information about how Big Data Management uses each engine to run mappings, workflows, and other tasks, see the chapter about Big Data Management Engines.
Blaze Engine Architecture
To run a mapping on the Informatica Blaze engine, the Data Integration Service submits jobs to the Blaze engine executor. The Blaze engine executor is a software component that enables communication between the Data Integration Service and the Blaze engine components on the Hadoop cluster.
The following Blaze engine components appear on the Hadoop cluster:
- •Grid Manager. Manages tasks for batch processing.
- •Orchestrator. Schedules and processes parallel data processing tasks on a cluster.
- •Blaze Job Monitor. Monitors Blaze engine jobs on a cluster.
- •DTM Process Manager. Manages the DTM Processes.
- •DTM Processes. An operating system process started to run DTM instances.
- •Data Exchange Framework. Shuffles data between different processes that process the data on cluster nodes.
The following image shows how a Hadoop cluster processes jobs sent from the Blaze engine executor:
The following events occur when the Data Integration Service submits jobs to the Blaze engine executor:
- 1. The Blaze Engine Executor communicates with the Grid Manager to initialize Blaze engine components on the Hadoop cluster, and it queries the Grid Manager for an available Orchestrator.
- 2. The Grid Manager starts the Blaze Job Monitor.
- 3. The Grid Manager starts the Orchestrator and sends Orchestrator information back to the LDTM.
- 4. The LDTM communicates with the Orchestrator.
- 5. The Grid Manager communicates with the Resource Manager for available resources for the Orchestrator.
- 6. The Resource Manager handles resource allocation on the data nodes through the Node Manager.
- 7. The Orchestrator sends the tasks to the DTM Processes through the DTM Process Manger.
- 8. The DTM Process Manager continually communicates with the DTM Processes.
- 9. The DTM Processes continually communicate with the Data Exchange Framework to send and receive data across processing units that run on the cluster nodes.
Application Timeline Server
The Hadoop Application Timeline Server collects basic information about completed application processes. The Timeline Server also provides information about completed and running YARN applications.
The Grid Manager starts the Application Timeline Server in the Yarn configuration by default.
The Blaze engine uses the Application Timeline Server to store the Blaze Job Monitor status. On Hadoop distributions where the Timeline Server is not enabled by default, the Grid Manager attempts to start the Application Timeline Server process on the current node.
If you do not enable the Application Timeline Server on secured Kerberos clusters, the Grid Manager attempts to start the Application Timeline Server process in HTTP mode.
Spark Engine Architecture
The Data Integration Service can use the Spark engine on a Hadoop cluster to run Model repository mappings.
To run a mapping on the Spark engine, the Data Integration Service sends a mapping application to the Spark executor. The Spark executor submits the job to the Hadoop cluster to run.
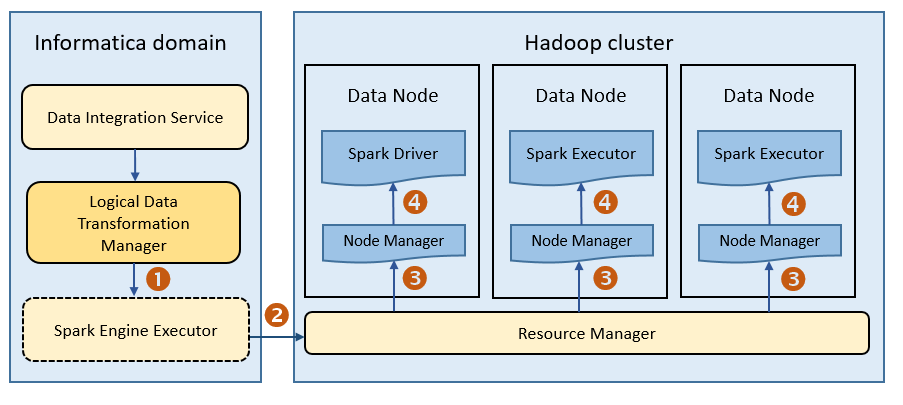
The following image shows how a Hadoop cluster processes jobs sent from the Spark executor:
The following events occur when Data Integration Service runs a mapping on the Spark engine:
- 1. The Logical Data Transformation Manager translates the mapping into a Scala program, packages it as an application, and sends it to the Spark executor.
- 2. The Spark executor submits the application to the Resource Manager in the Hadoop cluster and requests resources to run the application.
- 3. The Resource Manager identifies the Node Managers that can provide resources, and it assigns jobs to the data nodes.
- 4. Driver and Executor processes are launched in data nodes where the Spark application runs.
Hive Engine Architecture
The Data Integration Service can use the Hive engine to run Model repository mappings or profiles on a Hadoop cluster.
To run a mapping or profile on the Hive engine, the Data Integration Service creates HiveQL queries based on the transformation or profiling logic. The Data Integration Service submits the HiveQL queries to the Hive driver. The Hive driver converts the HiveQL queries to MapReduce or Tez jobs, and then sends the jobs to the Hadoop cluster.
Note: Effective in version 10.2.1, the MapReduce mode of the Hive run-time engine is deprecated, and Informatica will drop support for it in a future release. The Tez mode remains supported.
The Tez engine can process jobs on Hortonworks HDP, Azure HDInsight, and Amazon Elastic MapReduce. To use Cloudera CDH including Apache Hadoop, the jobs can process only on the MapReduce engine.
When you run a mapping on the Spark engine that launches Hive tasks, the mapping runs either on the MapReduce or on the Tez engines. For example, Hortonworks HDP cluster launches Hive tasks on MapReduce or Tez engines. A Cloudera CDH cluster launches Hive tasks on MapReduce engine.
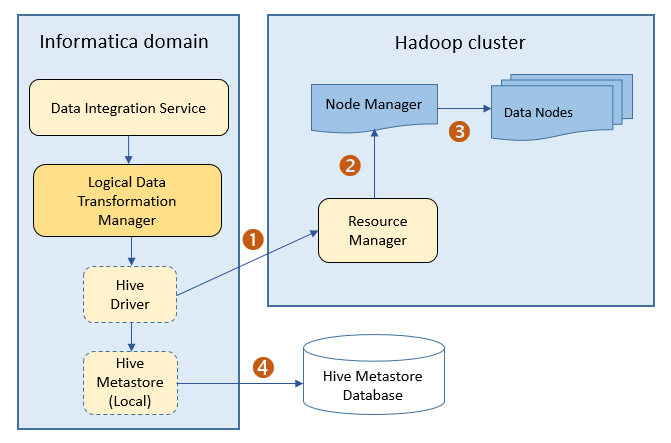
The following image shows the architecture of how a Hadoop cluster processes MapReduce or Tez jobs sent from the Hive driver:
The following events occur when the Hive driver sends jobs to the Hadoop cluster:
- 1. The Hive driver sends the MapReduce or Tez jobs to the Resource Manager in the Hadoop cluster.
- 2. The Resource Manager sends the jobs request to the Node Manager that retrieves a list of data nodes that can process the MapReduce or Tez jobs.
- 3. The Node Manager assigns MapReduce or Tez jobs to the data nodes.
- 4. The Hive driver also connects to the Hive metadata database through the Hive metastore to determine where to create temporary tables. The Hive driver uses temporary tables to process the data. The Hive driver removes temporary tables after completing the task.