Mapping Execution Plans
The Data Integration Service generates an execution plan to run mappings on a Blaze, Spark, or Hive engine. The Data Integration Service translates the mapping logic into code that the run-time engine can execute. You can view the plan in the Developer tool before you run the mapping and in the Administrator tool after you run the mapping.
The Data Integration Service generates mapping execution plans to run on the following engines:
- Informatica Blaze engine
- The Blaze engine execution plan simplifies the mapping into segments. It contains tasks to start the mapping, run the mapping, and clean up the temporary tables and files. It contains multiple tasklets and the task recovery strategy. It also contains pre- and post-grid task preparation commands for each mapping before running the main mapping on a Hadoop cluster. A pre-grid task can include a task such as copying data to HDFS. A post-grid task can include tasks such as cleaning up temporary files or copying data from HDFS.
- Spark engine
- The Spark execution plan shows the run-time Scala code that runs the mapping logic. A translation engine translates the mapping into an internal representation of the logic. The internal representation is rendered into Scala code that accesses the Spark API. You can view the Scala code in the execution plan to debug the logic.
- Hive engine
- The Hive execution plan is a series of Hive queries. The plan contains tasks to start the mapping, run the mapping, and clean up the temporary tables and files. You can view the Hive execution plan that the Data Integration Service generates before you run the mapping. When the Data Integration Service pushes the mapping to the Hive engine, it has a Hive executor that can process the mapping. The Hive executor simplifies the mapping to an equivalent mapping with a reduced set of instructions and generates a Hive execution plan.
Blaze Engine Execution Plan Details
You can view details of the Blaze engine execution plan in the Administrator tool and Developer tool.
In the Developer tool, the Blaze engine execution plan appears as a workflow. You can click on each component in the workflow to get the details.
The following image shows the Blaze execution plan in the Developer tool:
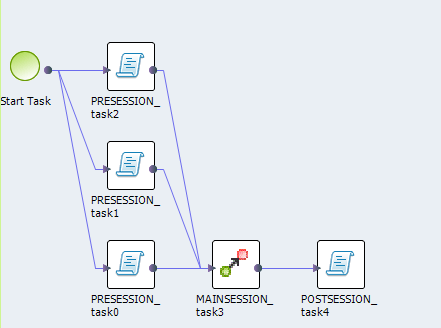
The Blaze engine execution plan workflow contains the following components:
- •Start task. The workflow start task.
- •Command task. The pre-processing or post-processing task for local data.
- •Grid mapping. An Informatica mapping that the Blaze engine compiles and distributes across a cluster of nodes.
- •Grid task. A parallel processing job request sent by the Blaze engine executor to the Grid Manager.
- •Grid segment. Segment of a grid mapping that is contained in a grid task.
- •Tasklet. A partition of a grid segment that runs on a separate DTM.
In the Administrator tool, the Blaze engine execution plan appears as a script.
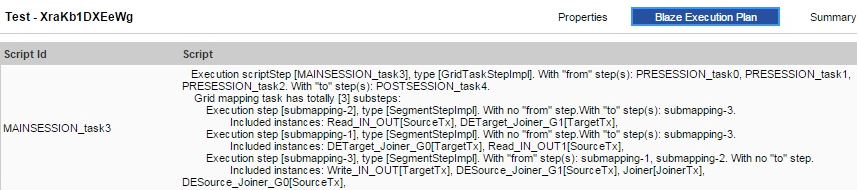
The following image shows the Blaze execution script:
In the Administrator tool, the Blaze engine execution plan has the following details:
- •Script ID. Unique identifier for the Blaze engine script.
- •Script. Blaze engine script that the Data Integration Service generates based on the mapping logic.
- •Depends on. Tasks that the script depends on. Tasks include other scripts and Data Integration Service tasks, like the Start task.
Spark Engine Execution Plan Details
You can view the details of a Spark engine execution plan from the Administrator tool or Developer tool.
The Spark engine execution plan shows the Scala code to run in the Hadoop cluster.
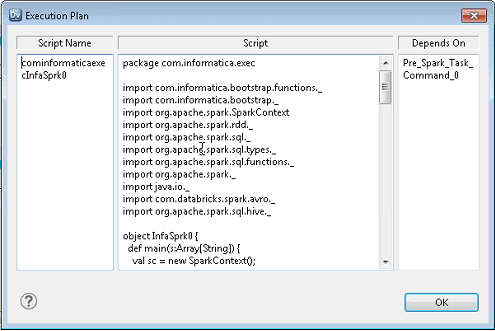
The following image shows the execution plan for a mapping to run on the Spark engine:
The Spark engine execution plan has the following details:
- •Script ID. Unique identifier for the Spark engine script.
- •Script. Scala code that the Data Integration Service generates based on the mapping logic.
- •Depends on. Tasks that the script depends on. Tasks include other scripts and Data Integration Service tasks.
Hive Engine Execution Plan Details
You can view the details of a Hive engine execution plan for a mapping from the Administrator tool or Developer tool.
The following table describes the properties of a Hive engine execution plan:
Property | Description |
|---|
Script Name | Name of the Hive script. |
Script | Hive script that the Data Integration Service generates based on the mapping logic. |
Depends On | Tasks that the script depends on. Tasks include other scripts and Data Integration Service tasks, like the Start task. |
Note: Effective in version 10.2.1, the MapReduce mode of the Hive run-time engine is deprecated, and Informatica will drop support for it in a future release. The Tez mode remains supported.
When you choose to run a mapping in the Hadoop environment, the Blaze and Spark run-time engines are selected by default.
Previously, the Hive run-time engine was also selected.
If you select Hive to run a mapping, the Data Integration Service will use Tez. You can use the Tez engine only on the following Hadoop distributions:
- •Amazon EMR
- •Azure HDInsight
- •Hortonworks HDP
In a future release, when Informatica drops support for MapReduce, the Data Integration Service will ignore the Hive engine selection and run the mapping on Blaze or Spark.
Viewing the Execution Plan for a Mapping in the Developer Tool
You can view the Hive or Blaze engine execution plan for a mapping that runs in a Hadoop environment. You do not have to run the mapping to view the execution plan in the Developer tool.
Note: You can also view the execution plan in the Administrator tool.
1. To view the execution plan in the Developer tool, select the Data Viewer view for the mapping and click Show Execution Plan.
2. Select the Data Viewer view.
3. Select Show Execution Plan.
The Data Viewer view shows the details for the execution plan.