Optimization for the Hadoop Environment
Optimize the Hadoop environment to increase performance.
You can optimize the Hadoop environment in the following ways:
- Configure a highly available Hadoop cluster.
- You can configure the Data Integration Service and the Developer tool to read from and write to a highly available Hadoop cluster. The steps to configure a highly available Hadoop cluster depend on the type of Hadoop distribution. For more information about configuration steps for a Hadoop distribution, see the Informatica Big Data Management Hadoop Integration Guide.
- Compress data on temporary staging tables.
- You can enable data compression on temporary staging tables to increase mapping performance.
- Run mappings on the Blaze engine.
- Run mappings on the highly available Blaze engine. The Blaze engine enables restart and recovery of grid tasks and tasklets by default.
- Perform parallel sorts.
- When you use a Sorter transformation in a mapping, the Data Integration Service enables parallel sorting by default when it pushes the mapping logic to the Hadoop cluster. Parallel sorting improves mapping performance.
- Partition Joiner transformations.
- When you use a Joiner transformation in a Blaze engine mapping, the Data Integration Service can apply map-side join optimization to improve mapping performance. The Data Integration Service applies map-side join optimization if the master table is smaller than the detail table. When the Data Integration Service applies map-side join optimization, it moves the data to the Joiner transformation without the cost of shuffling the data.
- Truncate partitions in a Hive target.
- You can truncate partitions in a Hive target to increase performance. To truncate partitions in a Hive target, you must choose to both truncate the partition in the Hive target and truncate the target table.
- Assign resources on Hadoop clusters.
- You can use schedulers to assign resources on a Hadoop cluster. You can use a capacity scheduler or a fair scheduler depending on the needs of your organization.
- Configure YARN queues to share resources on Hadoop clusters.
- You can configure YARN queues to redirect jobs on the Hadoop cluster to specific queues. The queue where a job is assigned defines the resources that are allocated to perform the job.
- Label nodes in a Hadoop cluster.
- You can label nodes in a Hadoop cluster to divide the cluster into partitions that have specific characteristics.
- Optimize Sqoop mappings on the Spark engine.
- The Data Integration Service can optimize the performance of Sqoop pass-through mappings that run on the Spark engine.
Blaze Engine High Availability
The Blaze engine is a highly available engine that determines the best possible recovery strategy for grid tasks and tasklets.
Based on the size of the grid task, the Blaze engine attempts to apply the following recovery strategy:
- •No high availability. The Blaze engine does not apply a recovery strategy.
- •Full restart. Restarts the grid task.
Enabling Data Compression on Temporary Staging Tables
To optimize performance when you run a mapping in the Hadoop environment, you can enable data compression on temporary staging tables. When you enable data compression on temporary staging tables, mapping performance might increase.
To enable data compression on temporary staging tables, complete the following steps:
- 1. Configure the Hive connection to use the codec class name that the Hadoop cluster uses to enable compression on temporary staging tables.
- 2. Configure the Hadoop cluster to enable compression on temporary staging tables.
Hadoop provides following compression libraries for the following compression codec class names:
Compression Library | Codec Class Name | Performance Recommendation |
|---|
Zlib | org.apache.hadoop.io.compress.DefaultCodec | n/a |
Gzip | org.apache.hadoop.io.compress.GzipCodec | n/a |
Snappy | org.apache.hadoop.io.compress.SnappyCodec | Recommended for best performance. |
Bz2 | org.apache.hadoop.io.compress.BZip2Codec | Not recommended. Degrades performance. |
LZO | com.hadoop.compression.lzo.LzoCodec | n/a |
Step 1. Configure the Hive Connection to Enable Data Compression on Temporary Staging Tables
Use the Administrator tool or the Developer tool to configure the Hive connection. You can edit the Hive connection properties to configure the codec class name that enables data compression on temporary staging tables.
1. In the Hive connection properties, edit the properties to run mappings in a Hadoop cluster.
2. Select Temporary Table Compression Codec.
3. Choose to select a predefined codec class name or enter a custom codec class name.
- - To select a predefined codec class name, select a compression library from the list.
- - To enter a custom codec class name, select custom from the list and enter the codec class name that matches the codec class name in the Hadoop cluster.
Step 2. Configure the Hadoop Cluster to Enable Compression on Temporary Staging Tables
To enable compression on temporary staging tables, you must install a compression codec on the Hadoop cluster.
For more information about how to install a compression codec, refer to the Apache Hadoop or Hive documentation.
1. Verify that the native libraries for the compression codec class name are installed on every node on the cluster.
2. To include the compression codec class name that you want to use, update the property io.compression.codecs in core-site.xml. The value for this property is a comma separated list of all the codec class names supported on the cluster.
3. Verify that the Hadoop-native libraries for the compression codec class name that you want to use are installed on every node on the cluster.
4. Verify that the LD_LIBRARY_PATH variable on the Hadoop cluster includes the locations of both the native and Hadoop-native libraries where you installed the compression codec.
Parallel Sorting
To improve mapping performance, the Data Integration Service enables parallel sorting by default in a mapping that has a Sorter transformation and a flat file target.
The Data Integration Service enables parallel sorting for mappings in a Hadoop environment based on the following rules and guidelines:
- •The mapping does not include another transformation between the Sorter transformation and the target.
- •The data type of the sort keys does not change between the Sorter transformation and the target.
- •Each sort key in the Sorter transformation must be linked to a column in the target.
Truncating Partitions in a Hive Target
To truncate partitions in a Hive target, you must edit the write properties for the customized data object that you created for the Hive target in the Developer tool.
You can truncate partitions in a Hive target when you use the Blaze or Spark run-time engines to run the mapping.
1. Open the customized data object in the editor.
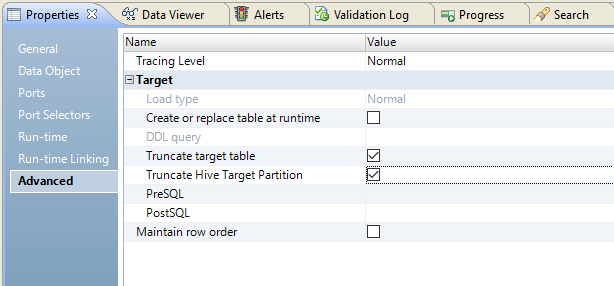
2. To edit write properties, select the Input transformation in the Write view, and then select the Advanced properties.
The following image shows the Advanced properties tab:
3. Select Truncate Hive Target Partition.
4. Select Truncate target table.
Scheduling, Queuing, and Node Labeling
You can use YARN schedulers, YARN queues, and node labels to optimize performance when you run a mapping in the Hadoop environment.
A YARN scheduler assigns resources to YARN applications on the Hadoop cluster while honoring organizational policies on sharing resources. You can configure YARN to use a fair scheduler or a capacity scheduler. A fair scheduler shares resources evenly among all jobs running on the cluster over time. A capacity scheduler allows multiple organizations to share a large cluster and distributes resources based on capacity allocations. The capacity scheduler guarantees each organization a certain capacity and distributes any excess capacity that is underutilized.
YARN queues are organizing structures for YARN schedulers and allow multiple tenants to share a cluster. The capacity of each queue specifies the percentage of cluster resources that are available for applications submitted to the queue. You can redirect Blaze, Spark, Hive, and Sqoop jobs to specific YARN queues.
Node labels allow YARN queues to run on specific nodes in a cluster. You can use node labels to partition a cluster into sub-clusters such that jobs run on nodes with specific characteristics. For example, you might label nodes that process data faster compared to other nodes. Nodes that are not labeled belong to the default partition. You can associate the node labels with capacity scheduler queues.
You can also use the node labels to configure the Blaze engine. When you use node labels to configure the Blaze engine, you can specify the nodes on the Hadoop cluster where you want the Blaze engine to run.
Note: You must install and configure Big Data Management for every node on the cluster, even if the cluster is not part of the queue you are using.
Enable Scheduling and Node Labeling
To enable scheduling and node labeling in the Hadoop environment, update the yarn-site.xml file in the domain environment.
Configure the following properties:
- yarn.resourcemanager.scheduler.class
- Defines the YARN scheduler that the Data Integration Service uses to assign resources on the cluster.
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.[Scheduler Type].[Scheduler Type]Scheduler</value>
</property>
- For example:
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
- yarn.node-labels.enabled
- Enables node labeling.
<property>
<name>yarn.node-labels.enabled</name>
<value>TRUE</value>
</property>
- yarn.node-labels.fs-store.root-dir
- The HDFS location to update the node label dynamically.
<property>
<name>yarn.node-labels.fs-store.root-dir</name>
<value>hdfs://[Node name]:[Port]/[Path to store]/[Node labels]/</value>
</property>
Define YARN Queues
You can define multiple YARN queues to redirect jobs to specific queues. You can redirect Blaze, Spark, Hive, and Sqoop jobs.
To redirect jobs on the Blaze engine to a specific queue, configure the following Blaze configuration property in the Hadoop connection:
Property | Description |
|---|
YARN Queue Name | The YARN scheduler queue name used by the Blaze engine that specifies available resources on a cluster. |
To redirect jobs on the Spark engine to a specific queue, configure the following Spark configuration property in the Hadoop connection:
Property | Description |
|---|
YARN Queue Name | The YARN scheduler queue name used by the Spark engine that specifies available resources on a cluster. The name is case sensitive. |
To redirect jobs on the Hive engine to a specific queue, configure the following Hive connection property:
Property | Description |
|---|
Data Access Connection String | The Hive connection string to specify the queue name for Hive SQL override mappings on the Blaze engine. Use the following format: - - MapReduce. mapred.job.queue.name=<YARN queue name>
- - Tez. tez.queue.name=<YARN queue name>
For example, jdbc:hive2://business.com:10000/default;principal=hive/_HOST@INFAKRB?mapred.job.queue.name-root.test |
To redirect Sqoop jobs to a specific queue, configure the following JDBC connection property:
Property | Description |
|---|
Sqoop Arguments | The Sqoop connection-level argument to direct a MapReduce job to a specific YARN queue. Use the following format: -Dmapred.job.queue.name=<YARN queue name> If you do not direct the job to a specific queue, the Spark engine uses the default queue. |
Configure the Blaze Engine to Use Node Labels
If you enable node labeling in the Hadoop environment, you can use node labels to run Blaze components as YARN applications on specific cluster nodes.
To run Blaze components on the labeled cluster nodes, specify the node labels when you configure the Blaze engine.
To specify node labels on the Blaze engine, list the node labels in the following Hadoop connection property:
Property | Description |
|---|
Blaze YARN Node Label | Node label that determines the node on the Hadoop cluster where the Blaze engine runs. If you do not specify a node label, the Blaze engine runs on the nodes in the default partition. If the Hadoop cluster supports logical operators for node labels, you can specify a list of node labels. To list the node labels, use the operators && (AND), || (OR), and ! (NOT). |
Note: When the Blaze engine uses node labels, Blaze components might be redundant on the labeled nodes. If a node contains multiple labels and you specify the labels in different Hadoop connections, multiple Grid Manager, Orchestrator, or Job Monitor instances might run on the same node.
Spark Engine Optimization for Sqoop Pass-Through Mappings
When you run a Sqoop pass-through mapping on the Spark engine, the Data Integration Service optimizes mapping performance in the following scenarios:
- •You read data from a Sqoop source and write data to a Hive target that uses the Text format.
- •You read data from a Sqoop source and write data to an HDFS target that uses the Flat, Avro, or Parquet format.
If you want to disable the performance optimization, set the --infaoptimize argument to false in the JDBC connection or Sqoop mapping. For example, if you see data type issues after you run an optimized Sqoop mapping, you can disable the performance optimization.
Use the following syntax:
--infaoptimize false
Rules and Guidelines for Sqoop Spark Engine Optimization
Consider the following rules and guidelines when you run Sqoop mappings on the Spark engine:
- •The Data Integration Service does not optimize mapping performance in the following scenarios:
- - There are unconnected ports between the source and target in the mapping.
- - The data types of the source and target in the mapping do not match.
- - You write data to a partitioned Hive target table.
- - You run a mapping on an Azure HDInsight cluster that uses WASB to write data to an HDFS complex file target of the Parquet format.
- •If you configure Hive-specific Sqoop arguments to write data to a Hive target, Sqoop ignores the arguments.
- •If you configure a delimiter for a Hive target table that is different from the default delimiter, Sqoop ignores the delimiter.