Mapping Run-time Properties
The mapping run-time properties depend on the execution environment that you select for the mapping.
Configure the following mapping run-time properties:
- •Validation Environment
- •Execution Environment
- •Reject File Directory
- •Maximum Parallelism
- •Target Commit Interval
- •Stop On Errors
- •Mapping Impersonation User Name
- •Suggested Parallelism
- •Hive Connection
Validation Environment
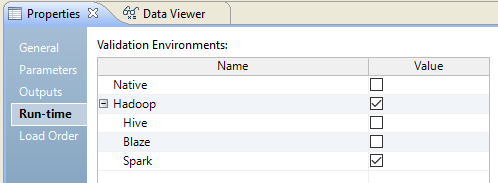
The validation environment indicates whether the Developer tool validates the mapping definition for the native execution environment, the Hadoop execution environment, or both. When you run a mapping in the native environment, the Data Integration Service processes the mapping.
Based on your license, you can run a mapping in the Hadoop environment. When you run a mapping in the Hadoop environment, the Data Integration Service pushes the mapping execution to the Hadoop cluster through a Hadoop connection. The Hadoop cluster processes the mapping.
When you choose the Hadoop execution environment, you can select the Blaze, Spark, or Hive engine to process the mapping.
The following image shows the validation environment:
Choose both validation environments if you want to test the mapping in the native environment before you run the mapping in the Hadoop environment. Or, choose both validation environments if you want to define the execution environment value in a parameter when you run the mapping.
If you choose both environments, you must choose the execution environment for the mapping in the run-time properties.
Default is native.
Execution Environment
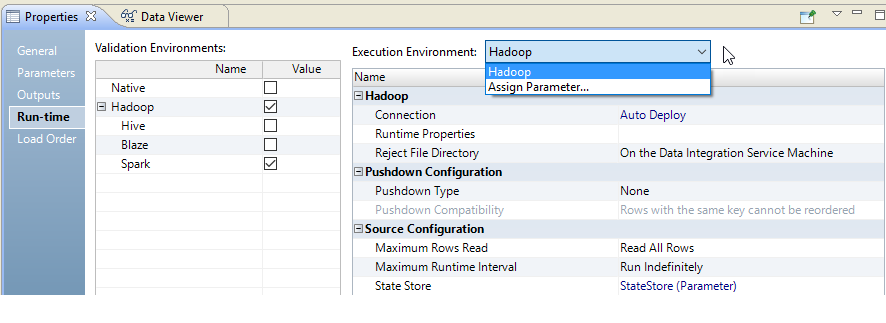
Select the execution environment to use when the mapping runs. When you run a mapping in the native environment, the Data Integration Service processes the mapping. If you installed Big Data Management, you can run a mapping in the Hadoop environment. The Data Integration Service pushes the processing to nodes on a Hadoop cluster. When you select the Hadoop environment, you can also select the engine to push the mapping logic to the Hadoop cluster.
You can use a mapping parameter to indicate the execution environment. Configure a string parameter. When you select the execution environment, click Assign Parameter, and select the parameter that you configured.
The following image shows where to select the mapping execution environment:
When you choose the execution environment, the Developer tool saves one of the associated validation environments for the mapping run.
Reject File Directory
If you run mappings in the Hadoop environment, you can choose where to store the reject files if the Hadoop connection is configured with a reject file directory. The Blaze engine can write reject files to the Hadoop environment for flat file, HDFS, and Hive targets. The Spark and Hive engines can write reject files to the Hadoop environment for flat file and HDFS targets.
You can write reject files to the Data Integration Service machine or to the Hadoop cluster. Or, you can defer to the Hadoop connection configuration.
Choose one of the following options:
- •On the Data Integration Service machine. The Data Integration Service stores the reject files based on the RejectDir system parameter.
- •On the Hadoop Cluster. The reject files are moved to the reject directory configured in the Hadoop connection. If the directory is not configured, the mapping will fail.
- •Defer to the Hadoop Connection. The reject files are moved based on whether the reject directory is enabled in the Hadoop connection properties. If the reject directory is enabled, the reject files are moved to the reject directory configured in the Hadoop connection. Otherwise, the Data Integration Service stores the reject files based on the RejectDir system parameter.
If you configure the mapping run-time properties to defer to the Hadoop connection, the reject files for all mappings with this configuration are moved based on whether you choose to write reject files to Hadoop for the active Hadoop connection. You do not need to change the mapping run-time properties manually to change the reject file directory.
For example, if the reject files are currently moved to the Data Integration Service machine and you want to move them to the directory configured in the Hadoop connection, edit the Hadoop connection properties to write reject files to Hadoop. The reject files of all mappings that are configured to defer to the Hadoop connection are moved to the configured directory.
You might also want to choose to defer to the Hadoop connection when the connection is parameterized to alternate between multiple Hadoop connections. For example, the parameter might alternate between one Hadoop connection that is configured to move reject files to the Data Integration Service machine and another Hadoop connection that is configured to move reject files to the directory configured in the Hadoop connection. If you choose to defer to the Hadoop connection, the reject files are moved depending on the active Hadoop connection in the connection parameter.
Maximum Parallelism
Maximum parallelism is valid for the native execution environment. Maximum parallelism refers to the maximum number of parallel threads that process a single mapping pipeline stage. An administrator sets maximum parallelism for the Data Integration Service to a value greater than one to enable mapping partitioning. The administrator sets the maximum parallelism in the Administrator tool.
The default maximum parallelism value for a mapping is Auto. Each mapping uses the maximum parallelism value defined for the Data Integration Service. You can change the default maximum parallelism value to define a maximum value for a particular mapping. When maximum parallelism is set to different integer values for the Data Integration Service and the mapping, the Data Integration Service uses the minimum value.
Default is Auto. Maximum is 64.
For more information about partitioning, see
Partitioned Mappings.
Target Commit Interval
The target commit interval refers to the number of rows that you want to use as a basis for a commit. The Data Integration Service commits data based on the number of target rows that it processes and the constraints on the target table. The Data Integration Service tunes the commit intervals. The default commit interval is 10,000 rows.
The commit interval is an approximate interval for the Data Integration Service to issue the commit. The Data Integration Service might issue a commit before, on, or after, the commit interval. In general, the Data Integration Service checks the target commit interval after writing a complete writer buffer block.
Stop on Errors
This function stops the mapping if a nonfatal error occurs in the reader, writer, or transformation threads. Default is disabled.
The following types of errors cause the mapping to stop when you enable Stop on Errors:
- Reader errors
- Errors encountered by the Data Integration Service while reading the source database or the source files. Reader errors can include alignment errors while running a session in Unicode mode.
- Writer errors
- Errors encountered by the Data Integration Service while writing to the target database or to the target files. Writer errors can include key constraint violations, loading nulls into a not null field, and database trigger responses.
- Transformation errors
- Errors encountered by the Data Integration Service while transforming data. Transformation errors can include conversion errors and any condition set up as an ERROR, such as null input.
Mapping Impersonation User Name
A mapping impersonation user name is valid for the native and Hadoop execution environment. Use mapping impersonation to impersonate the Data Integration Service user that connects to Hive, HBase, or HDFS sources and targets that use Kerberos authentication.
Enter a user name in the following format: <Hadoop service name>/<hostname>@<YOUR-REALM>
Where:
- •Hadoop service name is the name of the Hadoop service that the Hive, HBase, or HDFS source or target resides.
- •Host name is the name or IP address of the Hadoop service.
- •YOUR-REALM is the Kerberos realm.
You can only use the following special characters as delimiters: '/' and '@'
Suggested Parallelism
Suggested parallelism is valid for the native execution environment when the Maximum Parallelism property is assigned to a value greater than one or to a parameter. Suggested number of parallel threads that process the transformation pipeline stage.
When you define a suggested parallelism value for a transformation, the Data Integration Service considers the value when it determines the optimal number of threads for that transformation pipeline stage. You might want to define a suggested parallelism value to optimize performance for a transformation that contains many ports or performs complicated calculations.
Default is Auto, which means that the transformation uses the maximum parallelism value defined for the mapping. Maximum is 64.
Hadoop Connection
A Hadoop connection is valid for the Hadoop execution environment. A Hadoop connection defines the connection information that the Data Integration Service requires to push the mapping execution to the Hadoop cluster.
Select the Hadoop connection to run the mapping on the Hadoop cluster. You can assign a user-defined parameter for the Hadoop Connection. Define the parameter on the Parameters view of the mapping.