Duplicate Record Exception Mapping Example
An organization runs a data project to review customer data. The organization determines that the customer data contains multiple duplicate records. The organization needs to manually review some of the records that might be duplicates.
You create a data quality mapping to identify the duplicate customer records. The mapping includes the Match transformation. The Duplicate Record Exception transformation receives the results from the Match transformation. The Duplicate Record Exception transformation writes each record cluster with an uncertain status to a database table. A data analyst reviews the data in the Analyst tool and determines which records are duplicate records.
Duplicate Record Exception Mapping
Configure a Duplicate Record Exception mapping that examines customer records and finds duplicate records.
The following figure shows the Duplicate Record Exception mapping:
The mapping contains the following objects:
- Customer_Details
- The data source that might contain duplicate records.
- mat_MatchData
- A Match transformation that examines the customer data to determine if records match. The Match transformation creates a numeric score that represents the degree of similarity between two column values. An algorithm calculates a match score as a decimal value in the range 0 through 1. An algorithm assigns a score of one when two column values are identical.
- exc_Consolidate
- A Duplicate Record Exception transformation that determines which records are possible duplicate customers, known duplicate customers, or unique customer records.
- Write_GoodMatches_Customer table
- Table that receives all the records that do not need manual review. The Duplicate Record Exception transformation writes duplicate records and unique records to this table.
- Target_CustomerConsolidate table
- The Exception transformation writes the possible duplicate records to the Target_CustomerConsolidate table. Records in this table require manual review in the Analyst tool.
Match Transformation
The Match transformation receives the customer data and performs an identity match.
Configure the Match transformation for the Clusters-Match All output type. The Match transformation returns matching records in clusters. Each record in a cluster must match at least one other record in the cluster with a score greater than or equal to the match threshold. The match threshold is .75.
Select the Division matching strategy on the Match transformation Strategies tab. The Division strategy is a predefined matching strategy that identifies an organization based on the address fields. On the Match transformation Strategies tab, choose the input ports to examine in a match. Configure the strategy weight as .5.
The following figure shows the Division strategy configuration for the Match transformation:
The Match transformation adds cluster information to each output record. The transformation also adds a unique RowID to each record.
Duplicate Record Exception Input Groups
The Duplicate Record Exception transformation has two input groups. The transformation has a Data group that receives the customer data. The transformation has the Control group that contains the match score for the row, the row identifier, and the cluster ID.
The following figure shows the input groups in the Exception transformation:
The Data group contains the customer data. The customer data includes a customer ID, contact, title, and address fields. The Control group is the additional metadata that the Match transformation added for each customer record. The Control group contains the match score, the rowID, and the cluster ID.
Duplicate Record Exception Example Configuration View
Define the upper and lower thresholds on the Configuration view. Identify where the transformation writes the duplicate customer records, the possible duplicate records, and the unique customer records.
The following figure shows the Duplicate Record Exception transformation Configuration view:
The following table describes the configuration settings:
Option | Setting |
|---|
Lower threshold | .80 |
Upper threshold | .95 |
Automatic Consolidation | Standard Output table |
Manual Consolidation | Duplicate Record table |
Unique Records | Standard Output table |
Click Generate duplicate record table to create the duplicate record table. Do not create a separate table for the unique records. The transformation writes the unique records to the Standard Output table.
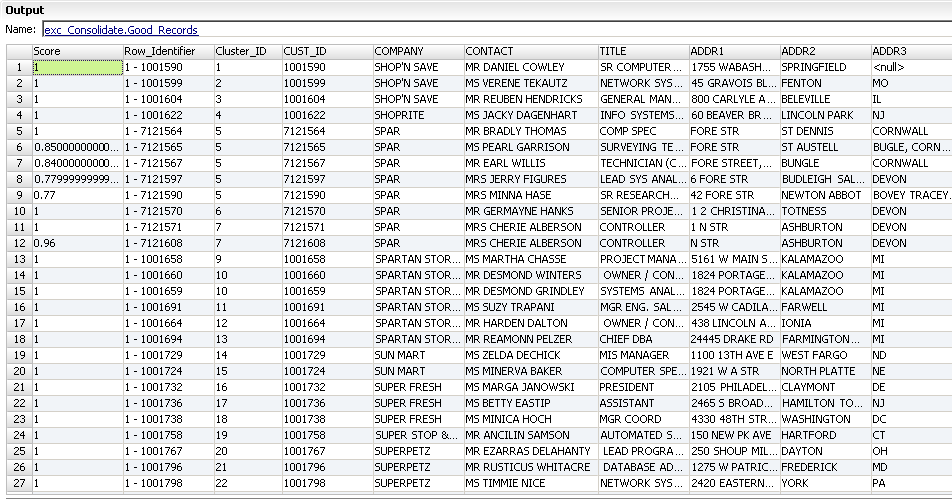
Standard Output Table Records
The Write_GoodMatches_Customer target table receive rows from the Standard Output group. The table receives unique records and it receives records that are duplicates. These records do not require manual review.
The following figure shows the Standard Output records that the Exception transformation returns:
The record contains the following fields:
- Score
- Match score that indicates the degree of similarity between a record and another record in the cluster. Records with a match score of one are duplicate records that do not need review. A cluster in which any record has a match score below the lower threshold is not a duplicate cluster.
- Row_Identifier
- A row number that uniquely identifies each row in the table. For this example, the row identifier contains the customer ID.
- Cluster ID
- A unique identifier for a cluster. Each record in a cluster receives the same cluster ID. The first four records in the sample output data are unique. Each record has a unique cluster ID. Rows five to nine belong to cluster five. Each record in this cluster is a duplicate record because of similarities in the address fields.
- Source Data Fields
- The Standard Output table group also receives all the source data fields.
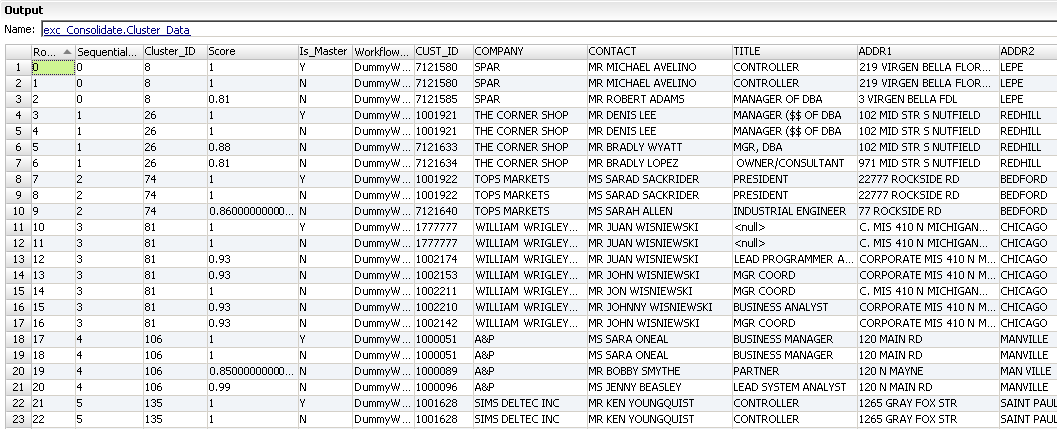
Cluster Output
The Target_CustomerConsolidate table receives records from the Cluster Output group. The Cluster Output group returns records that might be duplicate records. The records in the Target_CustomerConsolidate table need manual review in the Analyst tool.
The following image shows some of the records and the fields in the Target_CustomerConsolidate table:
The record contains the following fields:
- Row_Identifier
- A number that uniquely identifies each row in the table.
- Sequential Cluster ID
- A sequential identifier for each cluster to review in a Human task. The Duplicate Record Exception transformation adds the sequential cluster ID to records in the Cluster Data output group.
- Cluster ID
- A unique identifier for a cluster. The Match transformation assigns a cluster ID to all the output records. Duplicate records and possible duplicate records share a cluster ID. A unique record receives a cluster ID, but the record does not share the ID number with any other record.
- Score
- Match score that indicates the degree of similarity between a record and another record in the cluster. Records that require manual review have match scores less than .95 and greater than .80.
- Is Master
- Indicates whether the record is the preferred record in the cluster.
- WorkflowID
- The WorkflowID is DummyWorkflowID because the transformation is not in a workflow.
- Record Fields
- The other fields in the record contain the customer source data.