Identity Match Analysis Example
You are a human resources officer at a software organization with development centers in different cities. The organization stores personnel records for staff members in a database at the head office. The development centers hire staff at regular intervals, and the centers send you the personnel data for the staff members that they hire.
You add the personnel records to a spreadsheet file, and you use the file data to update the employee database. You are concerned that the current file might contain duplicate identities.
You design a mapping to perform identity analysis on the employee records. You configure a Match transformation to search for duplicate identities in the spreadsheet file. You must also verify that the file data does not duplicate any employee data in the master database. You configure the Match transformation to compare the file data with the master data that you store for the organization employees.
Because the database is a master data set, you store the index data for the staff records in a persistent data store.
Create the Mapping
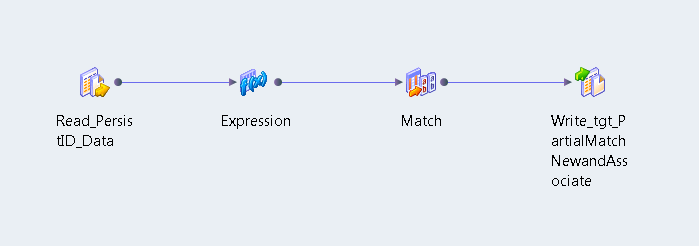
Create a mapping that looks for duplicate identities. The mapping reads a data source, adds a sequence identifier to the source records, performs identity analysis, and writes the results to a data target.
The following image shows the mapping in the Developer tool:
The mapping that you create contains the following objects:
Object Name | Description |
|---|
Read_PersistID_Data | Data source. Contains the employee names and details. |
Expression | Expression transformation. Adds sequence identifier values to the source data. |
Match | Match transformation. Analyzes the levels of duplication in the source data identities. |
Write_tgt_PartialMatchNewandAssociate | Data target. Contains the results of the identity analysis. |
Note: The mapping does not use a Key Generator transformation. In identity match analysis, the Key Generator transformation is optional.
Input Data Sample
The staff file contains the name of the employee, the city in which the employee works, and the designated role of the employee. You create a data source from the staff file in the Model repository. You add the data source to the mapping.
The following data fragment shows a sample of the employee data in the staff file:
Name | City | Designation |
|---|
Chaithra | Bangalore | SE |
Ramanan | Chennai | SSE |
Ramesh | Chennai | SSE |
Ramesh | Chennai | Lead |
Sunil | Bangalore | Principal |
Venu | Hyderabad | Principal |
Harish | Bangalore | SE |
Sachin | Bangalore | SSE |
Expression Transformation Configuration
When you configure the Expression transformation, connect all the data source ports that you want to include in the mapping output. Connect the ports as pass-through ports. Create an expression to add a sequence identification value to the ports.
The following expression creates the variable Init3 and adds the integer value 1267 to each sequence identifier:
Init3+1267
The following table describes the ports on the Expression transformation that reads the employee data source:
Name | Port Type | Port Group |
|---|
SEQID | bigint | Output Only |
Name | string | Passthrough |
City | string | Passthrough |
Designation | string | Passthrough |
Init3 | integer | Variable |
Match Transformation Configuration
Add a nonreusable Match transformation to the mapping to perform the identity analysis.
Perform the following tasks to configure the transformation:
- 1. Select the type of match analysis to perform.
- 2. Connect the input ports to the transformation.
- 3. Configure a strategy to compare the record data.
- 4. Select the type of match output data that the transformation creates.
- 5. Connect the output ports to a data target.
Select the Type of Match Operation
Use the options on the Match Type view to select the match operation.
The following image shows the Match Type view:
To compare the index data from the data source with the index data from the master data set, select Identity Match with Persistent Record ID. Update the persistence method so that the match analysis does not add data to the index tables. You can determine whether to update the index tables after you review the results of the mapping.
Use the DB Connection option to identify the database that contains the index data. Use the Persistent Store option to select the index tables.
Note: The Match transformation reads the identity population, key level, key type, and key field property values from the metadata in the index database tables. The values match the corresponding properties on the transformation that created the index data store.
Connect the Input Ports
Connect the input data ports to the transformation. Verify that the port names, port order, data types, and precisions must match the port configurations of the transformation that created the data store.
The Match transformation uses preset input ports to determine the order in which it processes the records. The transformation uses a sequence identifier to track the records from the input ports to the matched pairs or clusters that it writes as output. The transformation uses a group key to sort the records that it processes.
Connect the preset ports to the following ports on the Expression transformation:
- •SequenceID. Connect to the SEQID port from the Expression transformation.
- •GroupKey. Connect to the City port from the from the Expression transformation.
Configure a Strategy for Identity Analysis
Use the options on the Strategies view to configure a strategy. The strategy determines the type of analysis that the transformation performs on the record data.
Select the Person_Name algorithm for the record data. Select the Name input port for analysis. Because the transformation creates a copies of the port data, you select the Name_1 port and Name_2 port.
Select the Match Output Type
Use the options on the Match Output view to define the output format for the results of the match analysis
The following image shows the Match Output view for single-source identity analysis:
You configure the transformation to organize the output records in clusters. Each cluster contains all the records that match at least one other record, based on the match properties that you specify. The match properties determine how the transformation compares the data source records to the index records.
The following table describes the match property options that you specify to analyze the staff record data:
Match Property | Option | Option Description |
|---|
Match | Partial | The transformation compares the data source records with the index data store. The transformation also compares the records within the data source with each other. |
Output | New and Associated Rows | The transformation writes every cluster that contains at least one record from the data source. The clusters can include records from the index data store. Because a cluster can contain a single record, the output contains all records in the data source. |
Connect the Output Ports
Connect the Match transformation output ports to the data target in the mapping. Select the ports that contain the record data that you want to write to the data target.
The transformation includes a series of preset ports for clustered data. Select the preset ports that indicate duplicate status of the records and identify the data source that stores each record.
The following ports contain data that you can use to find duplicate records and determine the source or the records:
- •The ClusterSize port indicates the number of records in a cluster. If a record belongs to a cluster with a cluster size greater than 1, the transformation considers the record to be a duplicate of another record.
- •The ClusterID port identifies the cluster that a record belongs to. Use the ClusterID data to find the records that are duplicates of the current record.
- •The PersistenceStatus port uses a code value to describe the relationship between the index data from the mapping source and the index data in the data store.
- •The PersistenceStatusDesc port returns a text description of the values on the PersistenceStatus port code.
You can use other ports to review the relationships between the cluster records. The link port values and driver port values indicate the extent of the similarity between the records in each cluster.
In the current example, you connect all the ports to the data target. To view the output data on the ports, run the Data Viewer.
Run the Data Viewer
Run the Data Viewer to review the results of the match analysis. By default, the Data Viewer shows all the output ports on the Match transformation. When you run the mapping, you update the data target with the data from the output ports.
The following image shows the output data in the Data Viewer:
The Data Viewer verifies that the file contains records that duplicate the data in the master data set.
Consider the following data values in the Data Viewer:
- •Each record in the data set belongs to a cluster that contains two or more records. Therefore, each record is a duplicate of at least one other record. The transformation assigns a cluster size of 1 to unique records. The data source does not contain any record that the master data set does not contain.
- •The PersistenceStatusDesc data identifies the origin of the record and indicates if the Match transformation adds the record to the index tables. The column indicates that each input record exists in the master data set. The transformation does not add data to the master data index.
Conclusion
The results of the match analysis indicate that the staff record file does not contain any record that the master data set does not contain. The persistence status descriptions indicate that the mapping does not update the index tables with any data from the data source. You discard the staff record file.
When you receive another update from the regional offices, you can create another file and compare it to the master data set. You can reuse the mapping and the index tables. Because you store the index data for the master data set in the database tables, you do not need to regenerate the index data.