Developing Data Engineering Integration Mappings for Subscriptions
To develop a Data Engineering Integration mapping for a subscription, perform the following steps in the Developer tool:
- 1. Create source and target connections. The source connection is a Hive connection to the Data Integration Hub publication repository and the target connection is a connection to the subscribing application.
- 2. Create source and target data objects.
- 3. Create a mapping, add the source and target objects to the mapping, and connect ports between the source and the target.
- 4. Add Data Integration Hub parameters to the mapping.
- 5. Add a Filter query to the source. You can filter subscriptions by publication instance ID, publication date, and publication date partition.
Note: If you are creating a mapping for an unbound subscription you do not need add a filter query to the mapping.
- 6. Configure the mapping run-time environment and create an application from the mapping.
The following image shows a sample subscription mapping:
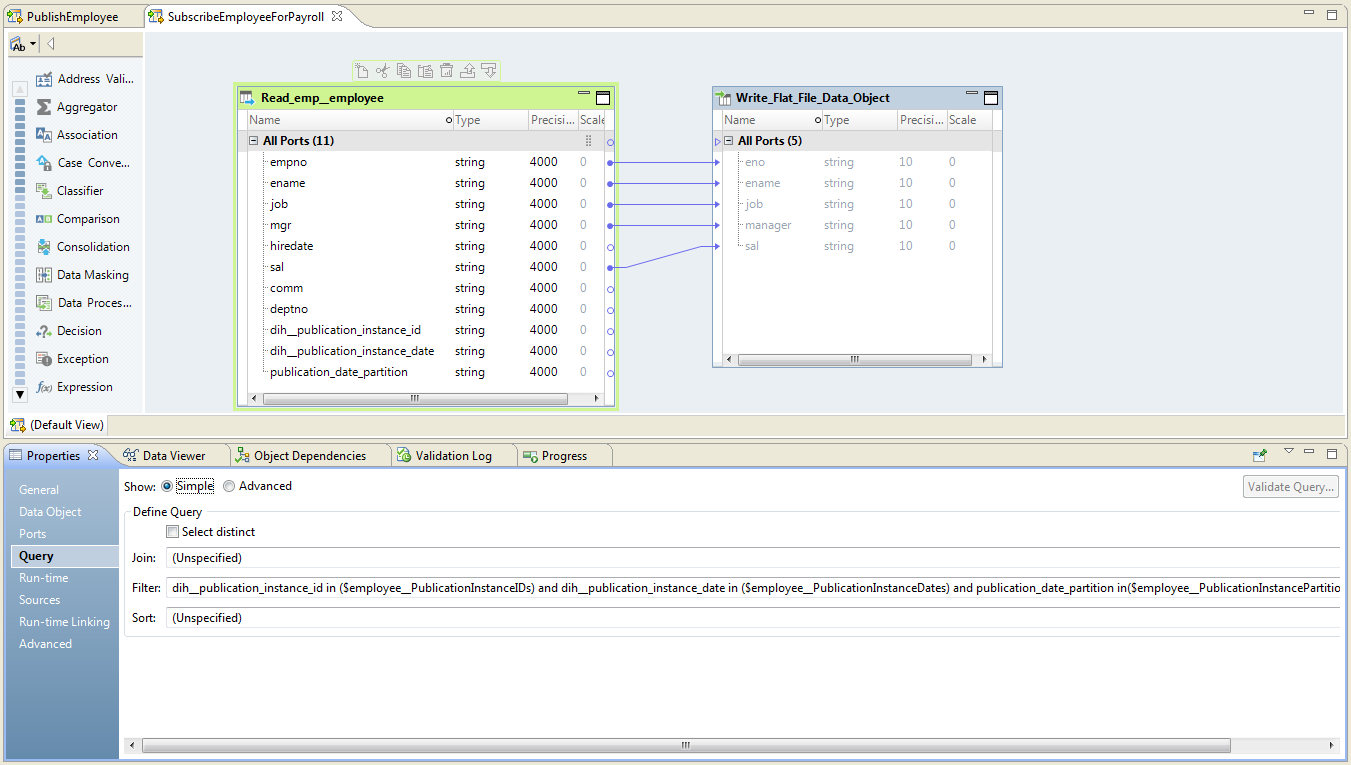
Step 1. Create Source and Target Connections
1. Create a Hive source connection to the Data Integration Hub publication repository. Hive must belong to the cluster where the mappings run.
2. Create an Oracle or a Flat File target connection to the subscribing application.
Step 2. Create Source and Target Data Objects
Create data objects under Physical Data Objects.
1. Create a source data object and select the table in the source connection to consume. The object must be a relational Hive data object.
2. Create a target data object and select the table in the target connection subscribes to the data. The object can be a relational data object or a flat file data object.
Step 3. Create a Mapping with Source and Target
1. Create and name a new mapping.
2. Add the source physical data object to the mapping as a Reader.
3. Add the target physical data object to the mapping as a Writer.
4. Link all the ports from the source object to the identical ports in the target object. For example, if your topic table includes the column ENAME, link the ENAME port in the source object to the ENAME port in the target object.
Step 4. Add Data Integration Hub Parameters to the Mapping
 Add the following parameters to the mapping:
Add the following parameters to the mapping: <TOPIC_NAME>__DXPublicationInstanceIDs
<TOPIC_NAME>__DXPublicationInstanceDates
<TOPIC_NAME>__DXPublicationInstancePartitionDate
Where <TOPIC_NAME> is the name of the topic from which the subscriber consumes the data.
Step 5. Add a Filter Query to the Reader Object
If you are creating a mapping for an unbound subscription do not add a filter query to the mapping.
1. Configure a Filter query on the source with the following mapping parameters:
<TOPIC_NAME>__DXPublicationInstanceIDs
<TOPIC_NAME>__DXPublicationInstanceDates
<TOPIC_NAME>__DXPublicationInstancePartitionDate
Where <TOPIC_NAME> is the name of the topic from which the subscriber consumes the data.
Do not enclose filter query parameters within quotation marks.
For example, use the following format for a filter query with a filter condition on the partition date parameter:
dih__publication_instance_id in ($MY_TOPIC__PublicationInstanceIDs) and dih__publication_instance_date in ($MY_TOPIC__PublicationInstanceDates) and publication_date_partition in ($MY_TOPIC__PublicationInstancePartition_Date)
2. Save the mapping.
Step 6. Configure the Mapping Run-time Environment and Create an Application
1. In the Properties pane select Run-time, and then, under Validation Environments, select Hadoop and then select Hive. Verify that Native is not selected.
2. Create an application from the mapping.
The mapping is deployed to the Data Integration Service for Hadoop environment.