Snowflake Objects in Mappings
When you create a mapping, you can configure a Source or Target transformation to represent a Snowflake object.
Pushdown Optimization
Snowflake Connector supports Full and Source pushdown optimization with an ODBC connection that uses Snowflake ODBC drivers.
To perform pushdown optimization, you must specify the ODBC Subtype connection property as Snowflake in the ODBC connection and use the ODBC connection in the Snowflake Mapping Configuration task.
Note: Snowflake Connector does not support upsert operation in a full pushdown optimization.
Add the Pushdown Optimization property under Advanced Session Properties tab when you create a Mapping Configuration task and select Full or To Source in the Session Property Value field. You cannot configure target-side pushdown optimization.
Note: You need to apply EBF CON-7357 to use Pushdown Optimization option. Contact Informatica Global Customer Support to install the Informatica EBF CON-7357.
Pushdown Optimization Functions
The following table summarizes the availability of pushdown functions in a Snowflake database. Columns marked with an X indicate that the function can be pushed to the Snowflake database by using source-side or full pushdown optimization. Columns marked with a dash (-) symbol indicate that the function cannot be pushed to the database.
Function | Pushdown | Function | Pushdown | Function | Pushdown |
|---|
ABORT() | - | INITCAP() | X | REG_MATCH() | - |
ABS() | X | INSTR() | X | REG_REPLACE | - |
ADD_TO_DATE() | X | IS_DATE() | - | REPLACECHR() | X |
AES_DECRYPT() | - | IS_NUMBER() | - | REPLACESTR() | X |
AES_ENCRYPT() | - | IS_SPACES() | - | REVERSE() | - |
ASCII() | X | ISNULL() | X | ROUND(DATE) | - |
AVG() | X | LAST() | - | ROUND(NUMBER) | X |
CEIL() | X | LAST_DAY() | X | RPAD() | X |
CHOOSE() | - | LEAST() | - | RTRIM() | X |
CHR() | X | LENGTH() | X | SET_DATE_PART() | - |
CHRCODE() | - | LN() | X | SIGN() | X |
COMPRESS() | - | LOG() | X | SIN() | X |
CONCAT() | X | LOOKUP | - | SINH() | X |
COS() | X | LOWER() | X | SOUNDEX() | - |
COSH() | X | LPAD() | X | SQRT() | X |
COUNT() | X | LTRIM() | X | STDDEV() | X |
CRC32() | - | MAKE_DATE_TIME() | - | SUBSTR() | X |
CUME() | - | MAX() | X | SUM() | X |
DATE_COMPARE() | X | MD5() | - | SYSDATE() | X |
DATE_DIFF() | X | MEDIAN() | X | SYSTIMESTAMP() | X |
DECODE() | X | METAPHONE() | - | TAN() | X |
DECODE_BASE64() | - | MIN() | X | TANH() | X |
DECOMPRESS() | - | MOD() | X | TO_BIGINT | X |
ENCODE_BASE64() | - | MOVINGAVG() | - | TO_CHAR(DATE) | X |
EXP() | X | MOVINGSUM() | - | TO_CHAR(NUMBER) | X |
FIRST() | - | NPER() | - | TO_DATE() | X |
FLOOR() | X | PERCENTILE() | - | TO_DECIMAL() | X |
FV() | - | PMT() | - | TO_FLOAT() | X |
GET_DATE_PART() | X | POWER() | X | TO_INTEGER() | X |
GREATEST() | - | PV() | - | TRUNC(DATE) | - |
IIF() | X | RAND() | - | TRUNC(NUMBER) | X |
IN() | X | RATE() | - | UPPER() | X |
INDEXOF() | - | REG_EXTRACT() | - | VARIANCE() | X |
The following table lists the pushdown operators that can be used in a Snowflake database:
Operator | Pushdown |
|---|
+ | Supported |
- | Supported |
* | Supported |
/ | Supported |
% | Supported |
|| | Supported |
> | Supported |
= | Supported |
>= | Supported |
<= | Supported |
!= | Supported |
AND | Supported |
OR | Supported |
NOT | Supported |
^= | Supported |
Rules and Guidelines for Pushdown Optimization Functions
Use the following rules and guidelines when you push functions to a Snowflake database:
- •To push the TRUNC(DATE) function to the Snowflake database, you must define the date and format arguments.
- •The Snowflake aggregate functions accept only one argument, which is a field set for the aggregate function. The agent ignores any filter condition defined in the argument. In addition, ensure that all fields mapped to the target are listed in the GROUP BY clause.
- •To push the TO_CHAR() function to the Snowflake database, you must define the date and format arguments.
- •When you push the SYSTIMESTAMP() and SYSDATE() functions to the Snowflake database, do not specify any format. The Snowflake database returns the complete time stamp.
- •You cannot push the TO_BIGINT() or TO_INTEGER() function with more than one argument to the Snowflake database.
- •When you push the REPLACECHR() or REPLACESTR() function to the Snowflake database, the agent ignores the caseFlag argument.
For example, both REPLACECHR(false, in_F_CHAR, 'a', 'b') and REPLACECHR(true, in_F_CHAR, 'a', 'b') return the same value.
- •You cannot use millisecond and microsecond values when you push functions to the Snowflake database.
- •You can use nanosecond values in the ADD_TO_DATE() and TRUNC(DATE) functions only.
- •To push the TRUNC(DATE), GET_DATE_PART(), and DATE_DIFF() functions to the Snowflake database, you must use the following time formats as arguments:
- - D
- - DDD
- - HH
- - MI
- - MM
- - SS
- - YYYY
For example, TRUNC(<datefieldname>, 'dd').
Snowflake Sources in Mappings
In a mapping, you can configure a source transformation to represent a Snowflake source.
You can configure partitioning to optimize the mapping performance at run time when you read data from Snowflake. The partition type controls how the agent distributes data among partitions at partition points. You can define the partition type as key range partitioning. With partitioning, the agent distributes rows of source data based on the number of threads that you define as partition.
Note: Ensure that the source table name and field names are not case sensitive.
The following table describes the Snowflake source properties that you can configure in a Source transformation:
Property | Description |
|---|
Connection | Name of the source connection. |
Source Type | Type of the source object. Select Single Object, Multiple Objects, or Parameter. |
Object | The source object for the task. Select the source object for a single source. When you select the multiple source option, you can add source objects and configure relationship between them. |
Filter | Filters records based on the filter condition. Configure a simple filter. |
Sort | Sorts records based on the conditions you specify. You can specify the following sort conditions: - - Not parameterized. Select the fields and type of sorting to use.
- - Parameterized. Use a parameter to specify the sort option.
|
The following table describes the advanced properties that you can configure in a Source transformation:
Advanced Property | Description |
|---|
Database | Overrides the database specified in the connection. |
Schema | Overrides the schema specified in the connection. |
Warehouse | Overrides the Snowflake warehouse name specified in the connection. |
Role | Overrides the Snowflake role assigned to user, specified in the connection. |
Pre SQL | SQL statement that is executed prior to start of a read operation. For example, if you want to update records in the database before you read the records from the table, specify a Pre-SQL statement. |
Post SQL | SQL statement that is executed after completion of a read operation. For example, if you want to delete some records after the latest records load, specify a Post-SQL statement. |
Tracing Level | Determines the amount of detail that appears in the log file. You can select Terse, Normal, Verbose Initialization, or Verbose Data. Default value is Normal. |
Key Range Partitioning
You can configure key range partitioning when you use a Mapping Configuration task to read data from Snowflake sources. With key range partitioning, the agent distributes rows of source data based on the field that you define as partition keys. The agent compares the field value to the range values for each partition and sends rows to the appropriate partitions.
Use key range partitioning for columns that have an even distribution of data values. Otherwise, the partitions might have unequal size. For example, a column might have 10 rows between key values 1 and 1000 and the column might have 999 rows between key values 1001 and 2000. If the mapping includes multiple sources, use the same number of key ranges for each source.
When you define key range partitioning for a column, the agent reads the rows that are within the specified partition range. For example, if you configure two partitions for a column with the ranges as 10 through 20 and 30 through 40, the agent does not read the rows 20 through 30 because these rows are not within the specified partition range.
You can configure a partition key for fields of the following data types:
- •Integer
- •String
- •Any type of number data type. However, you cannot use decimals in key range values.
- •Datetime. Use the following format to specify the date and time: YYYY-MM-DD HH24:MI:SS. For example, 1971-01-01 12:30:30
Note: If you specify the date and time in any other format, the task fails.
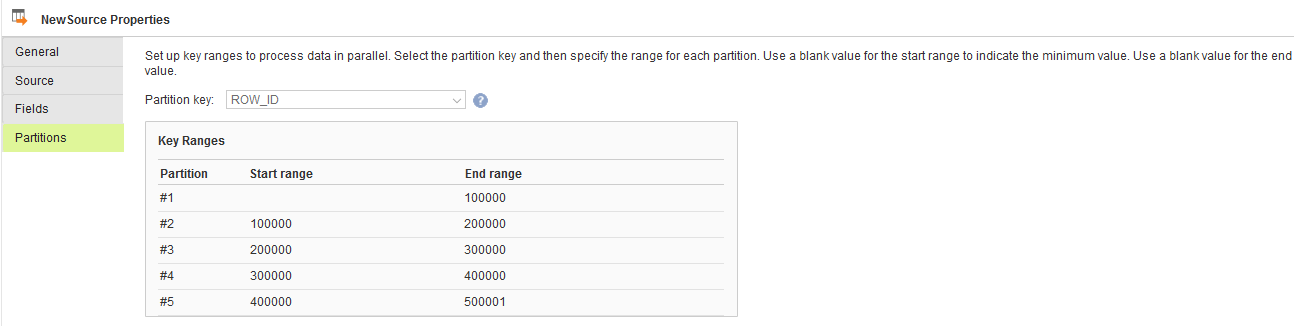
Configuring Key Range Partitioning
Perform the following steps to configure key range partitioning for Snowflake sources:
1. In the Source Properties page, click the Partitions tab.
2. Select the required partition key from the list.
3. Click Add New Key Range to define the number of partitions and the key ranges based on which the agent must partition data.
Use a blank value for the start range to indicate the minimum value. Use a blank value for the end range to indicate the maximum value.
The following image displays the details of Partitions tab:
Snowflake Targets in Mappings
In a mapping, you can configure a target transformation to represent a Snowflake target.
You can write data to an existing table or create a table in the target by using create target option.
Note: Ensure that the target table name and field names are not case sensitive.
You can configure partitioning to optimize the mapping performance at run time when you write data to Snowflake targets. The partition type controls how the agent distributes data among partitions at partition points. You can define the partition type as passthrough partitioning. With partitioning, the agent distributes rows of target data based on the number of threads that you define as partition.
The following table describes the Snowflake target properties that you can configure in a Target transformation:
Property | Description |
|---|
Connection | Name of the target connection. |
Target Type | Type of target object. |
Object | The target object for the task. Select the target object. You can either select an existing table or create a new table. |
Create Target | Creates a target. Enter the table name. Note: Make sure that the table name is in all caps. |
Operation | The target operation. Select Insert, Update, Upsert, or Delete. Note: You cannot use Data Driven operation in Target transformation. |
Update columns | The temporary key column to update data to or delete data from a Snowflake target. If you perform an update, update else insert, or delete operation and the Snowflake target does not include a primary key column, click Add to add a temporary key. You can select multiple columns. |
The following table describes the advanced properties that you can configure in a Target transformation:
Advanced Property | Description |
|---|
Database | Overrides the database specified in the connection. |
Schema | Overrides the schema specified in the connection. |
Warehouse | Overrides the Snowflake warehouse name specified in the connection. |
Role | Overrides the Snowflake role assigned to user specified in the connection. |
Pre SQL | SQL statement that is executed prior to start of a write operation. For example, if you want to assign sequence object to a primary key field of the target table before you write data to the table, specify a Pre-SQL. |
Post SQL | SQL statement that is executed after completion of write operation. For example, if you want to alter the table created by using create target option and assign constraints to the table before you write data to the table, specify a Post-SQL. |
Batch Row Size | Number of rows that the agent writes in a batch to the Snowflake target. |
Number of local staging files | Enter the number of local staging files. The agent writes data to the target, after the specified number of local staging files are created. |
Truncate Target Table | Truncates the database target table before inserting new rows. Select one of the following options: - - True. Truncates the target table before inserting all rows.
- - False. Inserts new rows without truncating the target table
Default is false. |
Additional Write Runtime Parameters | Specify additional runtime parameters. For example: remoteStage=CQA.CQA_SCHEMA.CQA_STAGE Separate multiple runtime parameters with &. |
Success File Directory | Not supported. |
Error File Directory | Not supported. |
Forward Rejected Rows | Determines whether the transformation passes rejected rows to the next transformation or drops rejected rows. By default, the agent forwards rejected rows to the next transformation. |
Configuring Directory for Local Staging Files
The Secure Agent creates the local staging files in a default temp directory. You can configure a different directory to store the local staging files.
To configure a different directory for the local staging files, perform the following steps:
1. Click Configure > Runtime Environments.
The Runtime Environments page appears.
2. Select the Secure Agent for which you want to set the custom configuration property.
3. Click Edit Secure Agent icon corresponding to the Secure Agent you want to edit.
The Edit Secure Agent page appears.
4. Select the Service as Data Integration Server in the System Configuration Details section.
5. Select the Type as DTM in the System Configuration Details section.
6. Set the JVM option to -Djava.io.tmpdir=E:\Snowflake\temp.
7. Click OK.
8. Restart the Secure Agent.
Snowflake Lookups in Mappings
You can create lookups for objects in Snowflake connection. You can retrieve data from a Snowflake lookup object based on the specified lookup condition.
When you configure a lookup in Snowflake, you select the lookup connection and lookup object. You also define the behavior when a lookup condition returns more than one match.
The following table describes the Snowflake lookup object properties that you can configure in a Lookup transformation:
Property | Description |
|---|
Connection | Name of the lookup connection. |
Source Type | Type of the source object. Select Single Object or Parameter. |
Lookup Object | Name of the lookup object for the mapping. |
Multiple Matches | Behavior when the lookup condition returns multiple matches. Select Return any row, Return all rows, or Report error. |
Filter | Not supported. |
Sort | Not supported. |
The following table describes the Snowflake lookup object advanced properties that you can configure in a Lookup transformation:
Advanced Property | Description |
|---|
Database | Overrides the database specified in the connection. |
Schema | Overrides the schema specified in the connection. |
Warehouse | Overrides the Snowflake warehouse name specified in the connection. |
Role | Overrides the Snowflake role assigned to user specified in the connection. |
Pre SQL | Not supported. |
Post SQL | Not supported. |
Rules and Guidelines for Snowflake Objects
Consider the following rules and guidelines for Snowflake objects used as sources, targets, and lookups in mappings:
- •Ensure that the source or target table names and field names are not case sensitive.
- •The table name or field name must not contain any special characters other than "_".
- •You can read or write data of Binary data type, which is in Hexadecimal format.
- •You cannot write semi-structured data to the target. For example, XML, JSON, AVRO, or PARQUET data.
- •You cannot read or write the nanoseconds portion of the data.
- •You cannot specify more than one Pre-SQL or Post-SQL query in the source or target transformation.
- •The agent reads or writes the maximum float value, which is 1.7976931348623158e+308, as infinity.
- •If a Snowflake lookup object contains fields with String data type of maximum or default precision and the row size exceeds the maximum row size, the task fails.
- •You can use the following formats to specify filter values of Datetime data type:
- - YYYY-MM-DD HH24:MI:SS
- - YYYY/MM/DD HH24:MI:SS
- - MM/DD/YYYY HH24:MI:SS