Hot folder
Naming information
The internal name for the Hotfolder feature is Inbox. That means that all technical terms like java classes or packages contain the substring inbox instead of hotFolder.
Introduction
This document is intended for consultants which initially configure and customize the hotfolder. It is recommended to read the user manual before reading this document to get an overview and the intention of the hotfolder. This document contains more technical details which are useful for customization and configuration. In addition it contains limitations and solution recommendations for a proper usage of the hotfolder. This should prevent an ineffective or inadequate use which can lead to unexpected or bad behavior.
There are several ways to import data into Product 360. All of these methods need a mapping beforehand. These mappings are created in the Mapping Studio of the Product Manager and are distinguished by their purposes.
The first way to get data into the Product 360 is the classical way via the manual import. This way should be used if a one-time import is planned, or at least the import process can not be automated.
The second way of data integration is via the web interface of the Supplier Exchange. This way has the advantages, that external organizations such as suppliers or translation agencies can submit and validate their data directly, with reduced effort on Product 360 side. When using this method the suppliers are also able to submit their media assets, which directly are uploaded to the media portal and synchronized with the Product 360 server.
The third way of onbording data is the hotfolder, which this document is about.
The general idea of the hotfolder is to provide an automated file based interface with other internal systems like ERP systems. A typical use case would be to synchronize item prices. Hereby one or more folders are being watched, and incoming files are compared by their names with patterns (e.g. *_ERP_prices.csv) which are defined in the hotfolder configurations. If the file matches to one of these patterns it is further processed, e.g it is waited for additional files defined in the same group or an import is scheduled instantly with the defined parameters.
Preconditions
This chapter contains a few things which have to be considered before creating new hotfolder configurations or groups.
Mappings used in the hotfolder
Since version 6.0, import mappings are stored centralized on server side in the database. With this server side management of import mappings a signature of the mappings for specific purposes exclusively was introduced. One of these purposes is the usage for the "Hotfolder".
Only mappings with this purpose can be chosen for a hotfolder configuration.
If a mapping is used by the hotfolder, (meaning a hotfolder configuration exists where this mapping is selected), it should not be deleted. The hotfolder configurations will be inconsistent if a used mapping is deleted. In order to delete such a mapping and prevent inconsistent hotfolder configuration it has to be removed from all referencing hotfolder configurations first. It is not sufficient to disable these hotfolder configurations.
Rights
Creating, editing and deleting import mappings for the purpose "Hotfolder" needs a special action right (not only the general right to create and work with import mappings). This right is called "configure hotfolder" and is also needed to see and to save mappings with the purpose "Hotfolder".
If you try to edit or delete an import mapping that has the purpose flag set to "Hotfolder" and is referenced (means used) by a hotfolder entry then a warning is shown.
The administration of the hotfolder itself – using the import mappings and assigning it to file patterns etc. is permitted with the same rights.
Settings (configuration of the hotfolder)
Folder locations
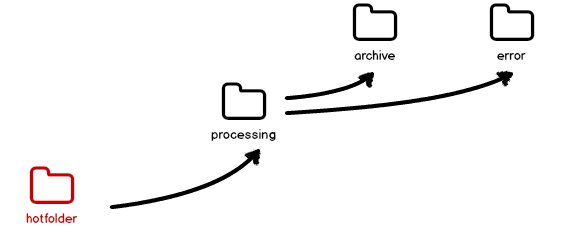
The hotfolder uses 4 folders:
Hotfolder: This is the folder in which the incoming files should be placed.
Processing folder: In this folder the files are moved as soon as they are detected and an prefix with the actual date will be added.
Archive folder: If the import finished, the file will be moved from the processing folder to this folder.
Error folder: If the processing within the hotfolder fails, the affected files are moved from the processing folder to this folder.
The locations of the hotfolders, processing folder, the archive folder and the error folder are specified in the server.properties file in the section Fileserver Settings. If more than one hotfolder is specified, the folder have to be separated using a semicolon, e.g. "c:/inbox/hotfolder;d:/inbox/anotherFolder". If some of the folders do not exist, they are created during the start of the server. The corresponding chapter of the server.properties is shown below:
### Inbox Settings ###inbox.hotfolders = ${filestorage.dir.shared}/inbox/hotfolderinbox.processingfolder = ${filestorage.dir.shared}/inbox/processinginbox.archivefolder = ${filestorage.dir.shared}/inbox/archiveinbox.errorfolder = ${filestorage.dir.shared}/inbox/errorShares can be used without known limitations.
If hotfolders are not specified the hotfolder is not active. If hotfolders are specified but the archive folder or the error folder are not specified, the server start is aborted.
Configuration of file trigger, file matcher and default file sorter
The file trigger, file matcher and file sorter can be configured in the plugin_customization.ini file using the settings com.heiler.ppm.importer5.inbox.core/activeMatcher, com.heiler.ppm.importer5.inbox.core/activeFileTrigger and com.heiler.ppm.importer5.inbox.core/defaultFileSorter. As value the ID of the corresponding extension point contribution has to be specified. If the contribution could not be found, server start is aborted.
# ----------------------------# HPM Hot folder configuration# ----------------------------# The active file pattern matcher which evaluates the filename with the configured patterns. Custom file pattern matcher# can be contributed via the extension point "com.heiler.importer5.inbox.server.matcher". Note that only ONE can be active.# Three file pattern matchers exist in the standard HPM:# RegularExpressionFilePatternMatcher# SimpleFilePatternMatcher# GroupingFilePatternMatcher# Default value is "GroupingFilePatternMatcher"com.heiler.ppm.importer5.inbox.core/activeMatcher=GroupingFilePatternMatcher # The id of the active file trigger.# Default value is "IntervalFileTrigger"com.heiler.ppm.importer5.inbox.core/activeFileTrigger=IntervalFileTrigger# interval in milliseconds# Default value is 1000# com.heiler.ppm.importer5.inbox.core/intervalFileTrigger.interval = 1000# number of intervals that are grouped together, means files that are detected within this number of intervals, are processed in one step.# Default value is 1# com.heiler.ppm.importer5.inbox.core/intervalFileTrigger.numberOfIntervalsToGroup = 1# maximum number of parallelly scheduled inbox jobs# Default value is 6# com.heiler.ppm.importer5.inbox.core/maxNumberOfParallelScheduledInboxJobs = 6# The default file sorter shown in the GUI. The file sorter sorts the files in case several files are detected in the hot folder.# Custom file sorters can be contributed via the extension point "com.heiler.ppm.importer5.inbox.core.fileSorter"# Two file sorters exist in the standard HPM:# com.heiler.ppm.importer5.inbox.core.FileSorterLastModified# com.heiler.ppm.importer5.inbox.core.FileSorterNumbered# Default value is "com.heiler.ppm.importer5.inbox.core.FileSorterLastModified"com.heiler.ppm.importer5.inbox.core/defaultFileSorter=com.heiler.ppm.importer5.inbox.core.FileSorterLastModifiedIf nothing is specified the interval file trigger, the grouping file matcher (wildcards: *, # and ?) and the last-modified file sorter are used.
Update interval for file trigger
The setting com.heiler.ppm.importer5.inbox.core/intervalFileTrigger.interval in plugin_customization.ini file specifies how often the file trigger scans the hotfolder. The default setting and also minimum value for the interval is 1 second. There is no maximum value, but its dubious to take an interval about 1 week of course. Note that decimal values are not allowed here.
Number of intervals to group
The setting com.heiler.ppm.importer5.inbox.core/intervalFileTrigger.numberOfIntervalsToGroup in plugin_customization.ini file specifies the number of detection intervals, which are grouped together, in order to process files, detected within these detection intervals, in one step. The default setting is 1, which means no grouping of detection intervals.
This grouping of several files detected one by one is important, when having several hotfolder groups with more than one hotfolder configuration each, because here the consistency of the incoming set of files is essential. Such a delayed detection of files may also be caused by the operating system, when copying or moving many files in one step into the hotfolder.
Example: the interval is configured to 1 second (see above), the number of intervals to group is set to 2. The first file is put into the hotfolder, and it is detected by the IntervalFileTrigger, but it will not be processed immediately. After a second a second file is put into the hotfolder, and it is then also detected by the IntervalFileTrigger. After this second detection step, both files will be processed together at once.
Maximum number of parallel scheduled Hotfolder (=inbox) jobs
The setting com.heiler.ppm.importer5.inbox.core/maxNumberOfParallelScheduledInboxJobs in plugin_customization.ini file specifies the maximum number of Hotfolder (=inbox) jobs that are scheduled in parallel. The default setting is 6.
Hotfolder status
To get an overview over the current status of the hotfolder, an information box can be opened by selecting the menu File / Show hotfolder status.
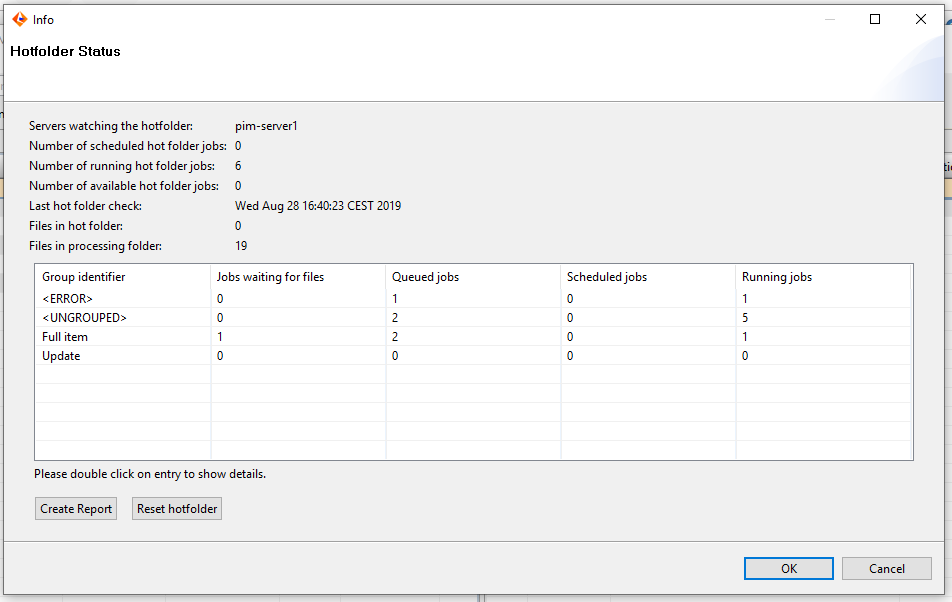
The box shows various information like the number of currently running hot folder jobs, the number of files in the processing folder etc.
The "Create Report" button creates a text file that contains all the information shown in the dialog box together with additional information like hotfolder configuration, hotfolder groups and thread dumps. The created file can be sent to the support in case the hotfolder does not work as expected.
The "Reset hotfolder" button allows a restart of the hotfolder processing logic. The following steps are executed:
hotfolder watcher threads are stopped
the currently running hotfolder jobs and corresponding import jobs are stopped
all files in the processing folder are moved into the error folder
hotfolder watcher threads are started again
The dialog box shows also detail information for each group including the internal groups <ERROR> (for hotfolder jobs reporting errors) and <UNGROUPED> for inbox configuration that do not belong to a group.
The available columns are:
Jobs waiting for files: Number of hotfolder jobs which are still waiting for files to fill all slots in the hotfolder group
Queued jobs: Number of hotfolder jobs that could not be scheduled because the number of running jobs reached the maximum number of hotfolder jobs (defaults to 6, excluding error jobs) or another jobs is already running for this group
Scheduled jobs: Number of hotfolder jobs that have been scheduled but are not running yet
Running jobs: Number of hotfolder jobs that are running
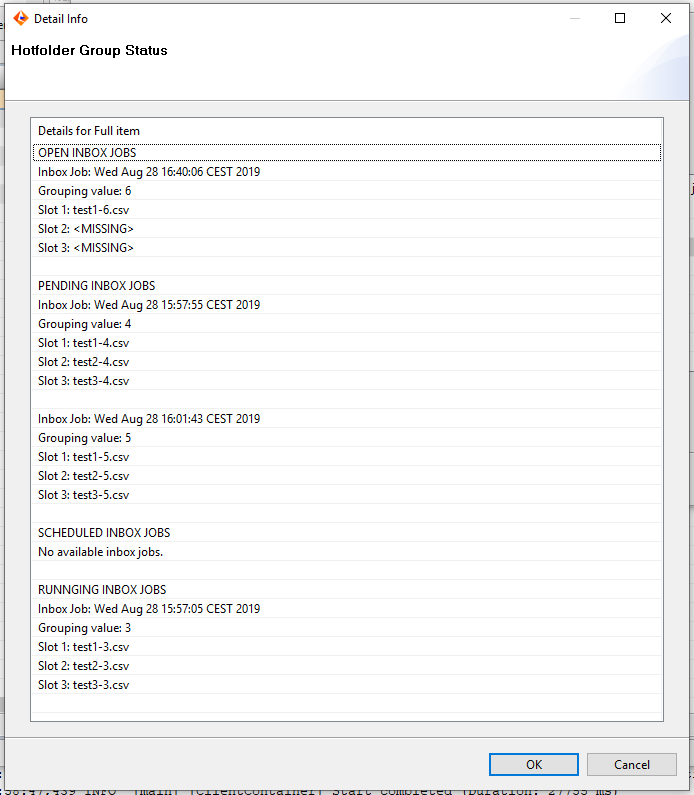
By double clicking on a row you get more details:
Fail over handling
Crash of hotfolder server
In case the server which is observing the hotfolder crashes, another server overtakes this role automatically. The files that are currently in the processing folder, are processed again to ensure that each file is at least processed once. Some files or part of some files may be imported twice by the system in this case.
If only one server was running and crashed, the files in the processing folder are picked up by a newly started server and processed before all files that are in the hotfolder.
Crash of a job server
In case a server crashes that is executing an import that has been started by the hotfolder, the import job is rescheduled on a job server that is still running or after the job server is up again.
Extension points
File Trigger
File triggers are responsible for detecting new files in one or more hotfolders. There is a default file trigger, checking the hotfolders in a configurable interval which can be replaced by a custom file trigger. To replace the file trigger, the extension point com.heiler.ppm.importer5.inbox.core.trigger is provided. The extension point expects an id, a name and java class which implements the interface FileTrigger. The id has to be unique and will be used in the configuration file to identify the active file trigger, while the name is just for logging purposes. If you create your own file trigger, extend your class from the default implementation FileTriggerBaseImpl. This class implements the corresponding interface and already contains the required observer (see Observer pattern) functionality, which is used to inform the inbox manager about new files. Only implement the interface if you have special Logic concerning the observer functionality, but we don´t see any use case for that until now.
Noteworthy things
If you write your own file trigger, don´t miss to implement the stopObserving() method properly. A lot of unexpectable things can happen, if the observer still runs although the hotfolder was already shut down.
You should always check if the file which has been detected is locked by another programm or process. This is also the case when the file trigger detects a file during the copy process. Then only a part will be copied, which leads to errors. To prevent this scenarios the FileTriggerBaseImplcontains an isLocked(File) Method which checks if the file is locked.
A code example from the default IntervalFileTrigger is shown below:
/** * This class is a default implementation of the {@link FileTrigger}, provided by the standard software. It checks one * or more folders for new files in a given time interval and notifies all registered listeners. The time interval * can be configured via the preferences.ini file. * @author twilhelm * @since 6.0 */public class IntervalFileTrigger extends FileTriggerBaseImpl{ public static final String IMPORT_INBOX_INTERVAL_PREFERENCE = "intervalFileTrigger.interval"; //$NON-NLS-1$ public static final String IMPORT_INBOX_HOTFOLDERS_PREFERENCE = "intervalFileTrigger.hotFolders"; //$NON-NLS-1$ private static final long DEFAULT_INTERVAL_IN_MS = 1 * 1000L; // 1 second private long interval; private File[] hotFolders; private List< Timer > timerList = new ArrayList< Timer >(); @Override public void startObserving( File... hotFolders ) throws CoreException { this.hotFolders = hotFolders; this.interval = getInterval(); for ( File hotFolder : this.hotFolders ) { Timer timer = new Timer(); timer.schedule( new FolderTimer( hotFolder ), 0, this.interval ); this.timerList.add( timer ); } } @Override public void stopObserving() { for ( Timer timer : this.timerList ) { timer.cancel(); } } /** * Returns the time interval in milliseconds from the preference.ini file. In this interval the configured folder will * be checked for new files * @throws CoreException if the specified interval could be parsed */ private long getInterval() throws CoreException { String intervalString = PreferenceUtil.getServerPreference( Activator.PLUGIN_ID, IMPORT_INBOX_INTERVAL_PREFERENCE, String.valueOf( DEFAULT_INTERVAL_IN_MS ) ); try { return Long.parseLong( intervalString ); } catch ( NumberFormatException e ) { String msg = Messages.getString( "IntervalFileTrigger.error.invalidValue" ); //$NON-NLS-1$ msg = MessagesUtils.replace( msg, false, intervalString, IMPORT_INBOX_INTERVAL_PREFERENCE ); IStatus status = new StatusExt( Categories.DATATYPE, IStatus.ERROR, Activator.PLUGIN_ID, 0, msg, e ); throw new CoreException( status ); } } /** * This class executes the folder check in the defined interval * @author twilhelm * @see Timer#schedule(TimerTask, Date, long) */ private class FolderTimer extends TimerTask { private File folder; /** * @param folder */ public FolderTimer( File folder ) { this.folder = folder; } @Override public void run() { LoginManager.getInstance() .impersonate( LoginTokenUtils.getSystemToken() ); File[] files = this.folder.listFiles(); List< File > unlockedFiles = new ArrayList< File >(); for ( File file : files ) { if ( file.isFile() && !isLocked( file ) ) { unlockedFiles.add( file ); } } if ( unlockedFiles.size() > 0 ) { fireNewFileDetected( unlockedFiles.toArray( new File[unlockedFiles.size()] ) ); } } }}File Matcher
File matchers are responsible to determine the corresponding hotfolder configuration for a detected file. The patterns of ALL hotfolder configurations will be checked against the file name by the matcher and only if exactly one configuration matches, the file will be processed. There are three default file matchers, one which uses regular expressions of java, one which uses the wildcards * and ? and one which allows to group files using #. In addition to that, it is also possible to write your own file matcher. Therefore the extension point com.heiler.ppm.importer5.inbox.core.matcher is provided. The extension point expects an id and a Java class which implements the interface FilePatternMatcher. The id has to be unique and will be used in the configuration file to identify the active file matcher. The extension point was enhanced in version 10.0 and allows the returning of a grouping value. The grouping value is used to grouped files in case of a multi-file hotfolder import. All files with the same grouping value, like a timestamp or a counter, are imported together.
Noteworthy things
There are different notations for regular expressions. Although they tried to unify them, there are still small differences, so please see the JavaDoc for more detailed information
Regular expressions are very complex and can easily lead to a missconfiguration of the hotfolder, so only use this file matcher if you are really familiar with regular expressions
Switching the file matcher is not a good idea because existing hotfolder configurations can break.
A code example from the default SimpleFilePatternMatcher is shown below:
/** * This is a simple file pattern matcher which only evalutes '*' and '?' as special pattern character (also * known as <em>glob</em>). * * @author twilhelm * @author rengel * * @since 6.0 */public class SimpleFilePatternMatcher implements FilePatternMatcher{ @Override public MatchResult matchExt( String patternString, String fileName ) { Pattern pattern = RegularExpressionUtils.convertTextToRegExPattern( patternString, RegExMode.GLOB ); Matcher matcher = pattern.matcher( fileName ); return new MatchResult(matcher.matches, ""); } @Override public String getDescription() { return Messages.getString("SimpleFilePatternMatcher.matcher.description"); //$NON-NLS-1$ }}File Sorter
In the case that more than one file is detected in the hotfolder within the same interval, the files are ordered by the file sorter. Two file sorters are provided with the product installation package:
Last-modified file sorter:Sorts files by the last-modified date provided by the file system
Numbered file sorter: The files are sorted by a number post-fix in the filename, e.g., article_04.xml or article_20111215.xml
In addition, custom file sorters can be contributed at the extension point com.heiler.ppm.importer5.inbox.core.fileSorter. The custom file sorter has to implement the interface FileSorter, but its highly recommended to extend the default implementation FileSorterBaseImpl FileSorterBaseImpl.
While a default file sorter can be specified in the plugin_customization.ini file, for each hotfolder group an own file sorter can be defined.
Pre-Import Steps
Pre-import steps are optionally and intended to transform the incoming source file and or its content before importing finally. A pre-import step can trigger several imports and it is possible to cancel further processing. A pre-import step consists of a pre-import function and one or more parameters. The pre-import function is specified in the extension point com.heiler.ppm.importer5.inbox.core.preImportStepFunction. The extension point defines three attributes: id, an internationalized name and a class. The class has to implement the interface PreImportStepExecutor.
For every hotfolder configuration one or more pre-import steps can be defined.
Currently, there are no built-in pre-import step functions provided.
Pre-import step parameters
Each pre-import step can have multiple parameters which are defined in the extension point. The concrete values of these parameters can be specified in the UI.
Keys of an enumeration used by a multi value parameter must not contain semicolons.
Pre-import steps without mapping
It's possible to create hotfolder configurations which only consist of one or more pre-import steps and have no mapping assigned. These configurations have the purpose to prepare the files for the import, a possible pre-import step would be to to extract files from a zip archive and place them again into the hotfolder so that they are recognized by the respective patterns created for these files. This pre-import step configuration would have e.g the pattern *.zip.
An other imaginable pre-import step without a mapping would be a pre-import steps which recognizes a special file and splits it into several other files, which are again placed into the hotfolder. The purpose of this would e.g be to import these files with different import settings such as into different supplier catalogs.
Examples for pre-import step functions
Example 1: ModifyFile
First an example is shown for a pre-import step function that adds a column to a CSV file containing an identifier.
The contribution to the extension point looks like:
<extension point="com.heiler.ppm.importer5.inbox.core.preImportStepFunction"> <PreImportStepFunction class="com.heiler.ppm.custom.preimport.ModifyFile" id="com.heiler.ppm.importer5.inbox.core.ModifyFile" name="ModifyFile"> <parameter id="prefix" mandatory="true" name="prefix" order="1" visible="true"> <value-class fix-class="java.lang.String"> </value-class> </parameter> <parameter id="initialSeqNumber" mandatory="true" name="initialSeqNumber" order="2" visible="true"> <value-class fix-class="java.lang.String"> </value-class> </parameter> </PreImportStepFunction> </extensionThe implementation of the function executor is shown below:
package com.heiler.ppm.custom.preimport; import java.io.File;import java.io.IOException;import java.util.List;import java.util.Map;import org.apache.commons.io.FileUtils;import org.eclipse.core.runtime.CoreException;import org.eclipse.core.runtime.IStatus;import org.eclipse.core.runtime.Status;import com.heiler.ppm.commons.status.IStatusExt.Categories;import com.heiler.ppm.commons.status.StatusExt;import com.heiler.ppm.importer5.core.api.ImportProfile;import com.heiler.ppm.importer5.inbox.core.api.preImportStep.PreImportStepContext;import com.heiler.ppm.importer5.inbox.core.api.preImportStep.PreImportStepExecutor;import com.heiler.ppm.importer5.inbox.core.api.preImportStep.PreImportStepFunction;import com.heiler.ppm.importer5.inbox.core.api.preImportStep.PreImportStepResult;import com.heiler.ppm.importer5.inbox.core.internal.Activator;import com.heiler.ppm.mapper.core.api.CSVFileSettings; /** * A pre-import step function that takes an CSV file and adds a column containing an identifier. The identifier consists * of a prefix and a consecutive number. The prefix and the initial number are provided by parameters that can be * specified in the UI by the user. */public class ModifyFile implements PreImportStepExecutor{ @Override public PreImportStepResult execute( PreImportStepContext context, PreImportStepFunction function, Map< String, Object > parameters ) throws CoreException { try { String prefix = ( String ) parameters.get( "prefix" ); //$NON-NLS-1$ int seqNumber = Integer.parseInt(( String ) parameters.get( "initialSeqNumber" )); //$NON-NLS-1$ ImportProfile profile = context.getImportProfile(); CSVFileSettings fileSettings = ( CSVFileSettings ) profile.getDataSource( 0 ) .getFileSettings(); String encoding = fileSettings.getEncoding(); String columnDelimiter = fileSettings.getColumnDelimiter(); int headerRow = fileSettings.getHeadingRowIndex(); int firstDataRow = fileSettings.getDataStartRowIndex(); File sourceFile = context.getSourceFile(); File destFile = new File( sourceFile.getParent(), "modified_" + sourceFile.getName() ); //$NON-NLS-1$ List< String > lines = FileUtils.readLines( sourceFile, encoding ); if ( headerRow != -1 ) { String newHeader = "Identifier" + columnDelimiter + lines.get( headerRow ); //$NON-NLS-1$ lines.set( headerRow, newHeader ); } for ( int i = firstDataRow; i < lines.size(); i++ ) { String id = prefix + String.valueOf( seqNumber + i - firstDataRow ); String newLine = id + columnDelimiter + lines.get( i ); lines.set( i, newLine ); } FileUtils.writeLines( destFile, encoding, lines ); profile.getDataSource( 0 ) .setFile( destFile ); IStatus status = new Status( IStatus.OK, Activator.PLUGIN_ID, null ); return new PreImportStepResult( status, context.getImportProfile() ); } catch ( IOException ioe ) { String msg = "Unexpected IOException while executing pre-import step '" + function.getName() + "' "; //$NON-NLS-1$ //$NON-NLS-2$ StatusExt status = new StatusExt( Categories.SYSTEM, IStatus.ERROR, Activator.PLUGIN_ID, 0, msg, ioe ); throw new CoreException( status ); } }}Example 2: Unzip file
This is an example for a pre-import step function that unzips a zip file and extracts all included files into the hotfolder. The added files are processed by other hotfolder configurations.
The contribution to the extension point looks like:
<extension point="com.heiler.ppm.importer5.inbox.core.preImportStepFunction"> <PreImportStepFunction class="com.heiler.ppm.importer5.inbox.core.internal.preImportStep.example.UnzipFile" id="com.heiler.ppm.importer5.inbox.core.UnzipFile" name="UnzipFile"> </PreImportStepFunction></extension>The implementation of the function executor is shown below:
package com.heiler.ppm.custom.preimport;import java.io.File;import java.io.FileInputStream;import java.io.FileNotFoundException;import java.io.FileOutputStream;import java.io.IOException;import java.util.Map;import org.eclipse.core.runtime.CoreException;import org.eclipse.core.runtime.IStatus;import org.eclipse.core.runtime.Status;import com.heiler.ppm.commons.status.IStatusExt.Categories;import com.heiler.ppm.commons.status.StatusExt;import com.heiler.ppm.commons.util.MessagesUtils;import com.heiler.ppm.importer5.inbox.core.api.preImportStep.PreImportStepContext;import com.heiler.ppm.importer5.inbox.core.api.preImportStep.PreImportStepExecutor;import com.heiler.ppm.importer5.inbox.core.api.preImportStep.PreImportStepFunction;import com.heiler.ppm.importer5.inbox.core.api.preImportStep.PreImportStepResult;import com.heiler.ppm.importer5.inbox.core.internal.Activator;import com.heiler.ppm.problemlog.core.ProblemLog;import com.heiler.ppm.problemlog.core.ProblemLogFactory;import com.heiler.util.zip.ZipEntry;import com.heiler.util.zip.ZipInputStream; /** * A pre-import step function that unzips a zip file and extracts all included files into the hot folder. */public class UnzipFile implements PreImportStepExecutor{ @Override public PreImportStepResult execute( PreImportStepContext context, PreImportStepFunction function, Map< String, Object > parameters ) throws CoreException { try { File sourceFile = context.getSourceFile(); unzipFiles( sourceFile, context.getHotFolder(), context.getProblemLog() ); IStatus status = new Status( IStatus.OK, Activator.PLUGIN_ID, null ); return new PreImportStepResult( status, sourceFile ); } catch ( IOException ioe ) { String msg = "Unexpected IOException while executing pre-import step '" + function.getName() + "' "; //$NON-NLS-1$ //$NON-NLS-2$ StatusExt status = new StatusExt( Categories.SYSTEM, IStatus.ERROR, Activator.PLUGIN_ID, 0, msg, ioe ); throw new CoreException( status ); } } private void unzipFiles( File file, File destDir, ProblemLog problemLog ) throws FileNotFoundException, IOException { ZipInputStream stream = new ZipInputStream( new FileInputStream( file ) ); ZipEntry nextEntry = stream.getNextEntry(); try { while ( nextEntry != null ) { if ( !nextEntry.isDirectory() ) { unzipEntry( stream, nextEntry, destDir, problemLog ); } nextEntry = stream.getNextEntry(); } } finally { stream.close(); } } private void unzipEntry( ZipInputStream stream, ZipEntry nextEntry, File destDir, ProblemLog problemLog ) throws FileNotFoundException, IOException { String entryName = nextEntry.getName(); String filename = new File( entryName ).getName(); FileOutputStream outStream = new FileOutputStream( new File( destDir, filename ) ); byte[] b = new byte[1024 * 1024]; try { while ( true ) { int bytesRead = stream.read( b ); if ( bytesRead == -1 ) { break; } outStream.write( b, 0, bytesRead ); } } finally { outStream.close(); } String msg = "Extracted file '{0_filename}'"; //$NON-NLS-1$ msg = MessagesUtils.replace( msg, true, filename ); IStatus status = new StatusExt( Categories.NOTE, IStatus.INFO, Activator.PLUGIN_ID, 0, msg, null ); problemLog.log( ProblemLogFactory.createProblem( status ) ); }}Groups
Grouping hotfolder configurations is a powerful but sometimes complex thing. The group mechanism should cover most of the possible scenarios, so customizing is not designated at this part. Also the group types mentioned below are not extendable.
Grouping pattern
Starting with version 10.0, files can be grouped by including # characters in the file pattern. # stands for a single character.
For example, a group imports products and items and the file names look like Product-0001.csv, Item-0001.csv, Product-0002.csv, Item-0002.csv etc, whereby Product-0001.csv and Item-0001.csv belong together and Product-0002.csv and Item-0002.csv.
By including a grouping pattern in the file name pattern, it is ensured that only files that belong together are imported together. In the above example, the file patterns would be Product-####.csv and Item-####.csv.
If the files are placed in the following order into the hotfolder: Product-0001.csv, Item-0002.csv, Product-0002.csv, Item-0001.csv, the files Product-0001.csv and Item-0001.csv and Product-0002.csv and Item-0002.csv are processed together. If just the file patterns Product-*.csv and Item-####.csv were used, Product-0001.csv and Item-0002.csv would be processed together, leading to import errors because Item-0002.csv expects products from the Product-0002.csv.
GroupTypes
The following table shows the different group types with their characteristics and configuration hints.
|
Name |
Usage |
Mapping |
Pattern |
Sequence |
Settings |
||
|
1 |
Sequential processing, no wait for files (multiple mappings, multiple files) |
Supplier delivers multiple different files at once, they should not be imported at the same time. |
Can be different |
Must be different |
not relevant / disabled |
Can be different |
Group does not wait for all files |
|
2 |
Multiple data extraction (multiple mappings, one file) |
Having one file mapped to several import mappings. |
Must be different |
Must be the same |
represents import order |
Can be different |
|
|
3 |
Multi-file import, wait for all files (one mapping, multiple files) |
A multi-file mapping is used. |
Must be the same |
Must be different |
Must be in the order of the files in the mapping |
Must be the same |
Group waits for all files. |
|
4 |
Sequential processing, wait for files (multiple mappings, multiple files) |
Multiple files with multiple mappings are processed in a fixed order. |
Must be different |
Must be different |
represents import order |
Can be different |
Group waits for all files. |
The hotfolder logic waits until all files for one group were put into the hotfolder and then it starts a hotfolder job.
Note: Before version 10.0, a hotfolder job was started as soon as the first file had been detected. That required a overly complex synchronization logic between the job watching the hotfolders and the already started hotfolder job. To increase robustness of the hotfolder processing, we changed that and start the hotfolder job after all necessary files were detected. The hotfolder information dialog shows now which groups are still waiting for files.
Group "Multi-file import, wait for all files (one mapping, multiple files)"
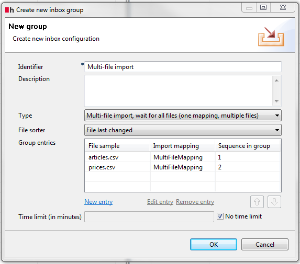
When using this group you have to consider that the order of the hotfolder configuration must correlate with the order of the files in the mapping. That means if you have a multi-file mapping for articles.csv (the first file) and prices.csv (the second file) like shown in the first figure below, the hotfolder configuration with sequence number 1 must be the articles.csv file and the hotfolder configuration with sequence number 2 must be prices.csv (see second figure). Note that this does not mean that the articles.csv file has to be put into the hotfolder before the prices.csv file. The order they are put into the hotfolder doesn´t matter.
Examples
Sequential processing, no wait for files (multiple mappings, multiple files)
Scenario: ERP system provides price updates every 10 minutes. The files are named price_update_X.csv whereby X is a number. The mapping which used be used is called UpdatePrices. A single import may take longer than 10 minutes.
Configuration:
Hotfolder configurations:
|
Identifier |
File sample |
Import mapping |
Hotfolder group |
Sequence in group |
Catalog |
Structure |
|
Price_Update |
price_update_*.xml |
UpdatePrices |
Price_Update |
|
Master |
Hotfolder groups:
|
Identifier |
Type |
File sorter |
Time limit (in minutes) |
|
Price_Update |
Sequential processing, no wait for files (multiple mappings, multiple files) |
Postfix in file (e.g. Prices_001.csv ) |
Behavior: The price imports will be processed sequentially and do not overlap. If there would be no group configuration, data inconsistency could occur because of parallel imports (e.g. price_update_2.csv is executed before price_update_1.csv)
Multiple data extraction (multiple mappings, one file)
Scenario: ERP system provides structure groups and items in one XML file named data_X.xml where X is a number. Two different mappings are stored in the database, one to import the structure groups named StructureGroup and one to import the items named Items. First the structure groups should be imported afterwards the items.
Configuration:
Hotfolder configurations:
|
Identifier |
File sample |
Import mapping |
Hotfolder group |
Sequence in group |
Catalog |
Structure |
|
ERP_Update_StructureGroups |
data_*.xml |
StructureGroups |
ERP_Update |
1 |
Classification |
|
|
ERP_Update_Items |
data_*.xml |
Items |
ERP_Update |
2 |
Master |
Hotfolder groups:
|
Identifier |
Type |
File sorter |
Time limit (in minutes) |
|
ERP_Update |
Multiple data extraction (multiple mappings, one file) |
Postfix in file (e.g. Prices_001.csv ) |
Behavior: The imports will be processed sequentially and do not overlap. The imports are executed depending on the sequence number, so first the structure groups are imported and then the items.
Without specifying an hotfolder group, the hotfolder process would be aborted as two hotfolder configurations exist for one file.
Behavior of groups
Group expect: An item and a price file.
Actual: Two item files
Behaviour: Hotfolder Job is aborted, first item file is moved to error folder, second file will be used for scheduling new hotfolder job.
Group expect: An item and a price file. Timeout is set to 10 min
Actual: Only an item file
Behaviour: Hotfolder job is aborted after specified timeout, item file will be moved to error folder
Import characteristic mime values via hotfolder
For a description how to import mime values via hotfolder, please have a look at the Knowledge Base section 'Import of characteristic values - Hotfolder Configuration for importing Characteristic Mime Values'.
Limitations
Throughput / Number of files per minute
The maximum throughput of the hotfolder is about one file per second. This is the absolute maximum defined by the management overhead like scheduling the import etc. Dependent on the complexity of the mappings and the sizes of the input files, the actual throughput is usually lower.
The hotfolder can handle peaks where more files are coming in than can be processed. In such a case, the import of files is delayed accordingly.
Maximum number of files at the same time
It is possible to put a large amount of files (including more than 1000 files) into the hotfolder at the same time. In such a case only a maximum of 6 (default) imports are performed at the same time.
The number of parallel imports can be changed by setting the property com.heiler.ppm.importer5.inbox.core/maxNumberOfParallelScheduledInboxJobs in the plugin_customization.ini file.
File size
Using large files in the hotfolder should be no problem due to the fact, that the import can also handle large files. Anyway, these files have to be treated carefully, considering that pre-importsteps as well as copy processes can take a long time. This can block other files which have been put into the hotfolder or lead to heavy load on the server.
Using small files (for example files that contain only a single item) has an impact on performance as it comes with a large overhead for scheduling jobs etc.
Number of hotfolder configurations resp. groups
Generally a large number of hotfolder configurations resp. groups should not be any problem, but right now, we don´t see any use cases where hundreds or thousands of hotfolder configurations resp. groups are needed. One main problem would be to configure hundreds of file patterns in a way that they only match the files you want, especially when using regular expressions.
Edit files directly in the hotfolder
Editing files lying in the hotfolder is not recommended. The hotfolder is just for auto import purposes. If a file has to be edited, it has to be copied to another directory first.
Usage of multiple hotfolders
We recommend to use a maximum number of 5 hotfolders. Please note that if more than one hotfolder is used, the processing of all files is still sequentially and not parallel.
Although multiple hotfolders can be configured it is not possible to "bind" a group to a special hotfolder. That means a group cannot be configured to take only the files of a special hotfolder. A possible workaround could be to add a pre or poststep to all files of a special hotfolder and adjust the file patterns of the group members.