Multi-Server Architecture
Synopsis
More and more customers face the need to increase the size of their item and product assortment which is managed in Informatica PIM. Not only the pure object count for these objects increase, but also the number of fields per item. Business needs for more distribution channels and a collaborative approach for maintenance increase the number of jobs as well as the concurrent users which work using the PIM Desktop as well as PIM Web or other clients attached by the Service API.
The only option to increase performance on the Server in the past was to increase the number of CPU's or CPU Cores. However, this so called vertical scalability has a natural limit in the availability and cost of high-end multi core CPU's. The solution to this problem is horizontal scalability.
By adding additional application servers to the PIM installation the customer can further increase the performance and the maximum load the system can handle. Additionally the customer can use mid-size hardware for these application servers, keeping the hardware costs for the PIM solution at a reasonable figure.
Demand for Multi-Server
The new multi server architecture of PIM provides answers to multiple issues customers face in high load scenarios.
Response times worsen with more and more users working concurrently
By adding additional application servers the users will be distributed across these servers - which increases the response time for every single user.
Background jobs interfere with users
Background jobs like Import, Merge or Export put high load on the application server which leads again to bad response times for users. Informatica PIM 8 multi-server edition can separate the execution of jobs and client requests. You can specify dedicated servers for background job processing as well as client connections. This helps to prevent that an executing background job affects users.
More channels with bigger assortments need to be updated
Background jobs are affected by the increased total number of objects in the PIM system. The more products and items are exported or imported the longer it will take. At the same time the number of distribution channels which should be updated with this data increase as well. Sooner or later the day won't have enough hours to execute all those jobs.
By adding multiple application servers for background job processing the PIM 8 multi-server edition can update more channels in the same amount of time.
High-End Multi-Core CPU Systems are expensive
High-End impose tremendous costs on the application landscape. Two mid-size application servers are usually way cheaper then a single high-end one. Informatica PIM 8 multi-server edition distributes mass-data operations on all available application servers. It can't handle "just" more users or more background jobs, it also provides faster execution time for a single job by distributing the load of that job to all application servers. Using this technology the customer is able to leverage cheaper hardware by providing multiple application servers.
Architecture
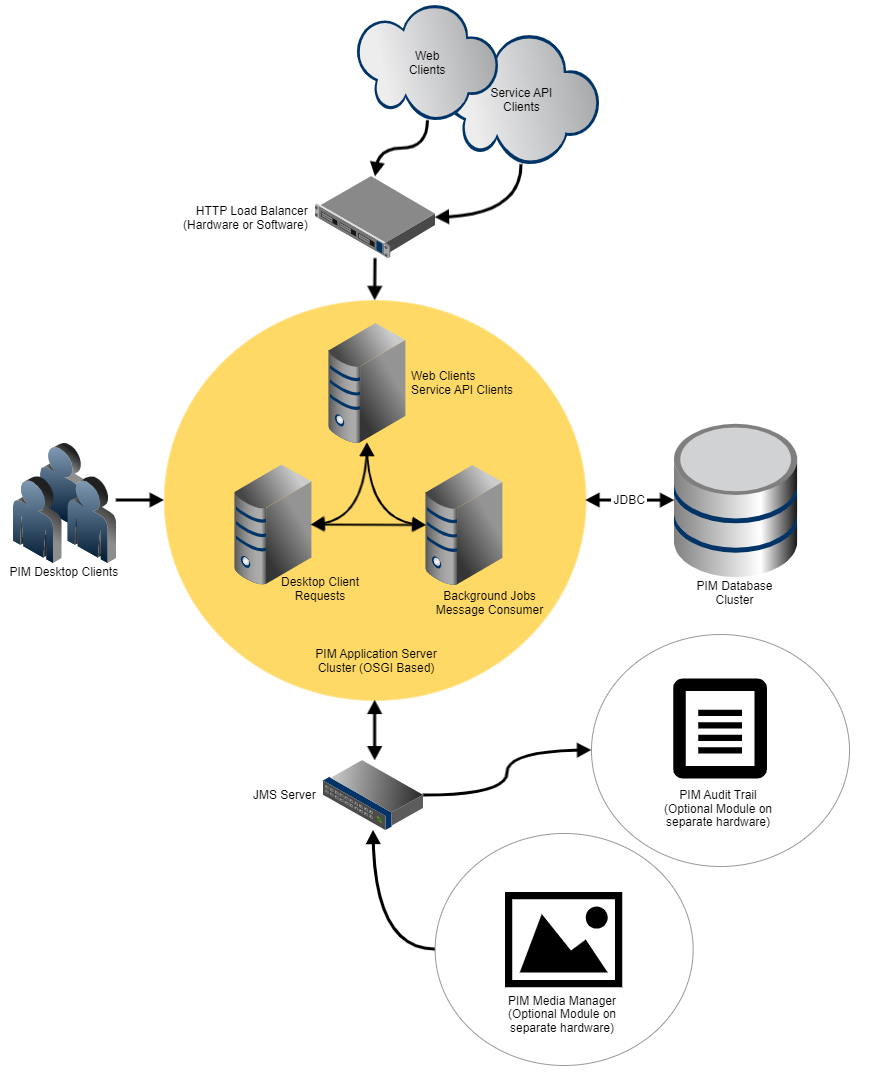
Multiple application servers can be combined to form a cluster. The application servers are connected with each other, so every server has a connection to all other servers. This eliminates the need for a centralized server which is by definition a single-point of failure and usually a scalability bottleneck in terms of communication overload (since all messages must go through him).
All servers have the full application functionality. In case of a server shutdown or a hardware failure, other servers can (and will) take the load of the missing server. This reduces the need for special fail over hardware.
Server Roles
A server role is a logical categorization of server instances. Currently these roles are defined at deployment time of the cluster. A server instance can also incorporate multiple roles (that's how the single server deployment is realized). The fact that these roles are pure logical roles and do not imply a different deployment approach in terms of bundles and features will provide the possibility to have dynamic roles in the future.
Client Server
The "client server" role defines that this server handles rich client requests. So rich clients are allowed to connect to this server and send requests etc. Multiple servers can have this role.
Job Server
The "job server" role defines that this server executes server side jobs like import, export, merge, search/replace etc. Multiple servers can have this role.
Web Server / Service API
All application server instances are identical in terms of installed functionality and have the needed server components for web client requests or service API requests. An explicit "web" or "service api" role is not available since this is defined by the load balancer anyway.
Message Queue Consumer Server
A server which has this role is allowed to consume messages from the message queues defined in the section "Message Queue Settings" of the server.properties file. The default queue configurations in the server.properties file are used for the communication from Product 360 to BPM and vice versa. Also all DQ jobs which get triggered by entity change and entity created triggers are written to a message queue and will be consumed by all servers which have this server role.
Load Balancing
Client Requests
Clients connect during start-up with an arbitrary server of the network, it actually doesn't matter which one since all servers know the whole network (which servers are there, which clients are connected to which server). From this "lookup" server he receives the list of available servers which have the "client server" role. In case there are only "job servers" available, the client will also connect to to a job server. After the determination of available servers, the client disconnects from the lookup server and reconnects to the one with the least number of connected clients. Clients stay connected to the server the whole time they run.
Jobs
The Quartz job framework we utilize is capable of having multi-server deployments. All jobs to be executed are stored in the database. Every "job server" in the network will now poll the quartz tables and see if there are new jobs to do, up till all job worker threads are full. This way, the jobs will be balanced on all servers. A differentiation between job types is not supported.
Web Clients and Service API Clients
Web and Service API clients are similar in the way they connect to the server, both use the standard HTTP/HTTPS protocols. Therefore we suggest to use a hardware or software load balancing functionality which is available from various vendors. Please make sure that the load balancer is configured to use "sticky sessions" in case of the web clients. The service API is stateless, so it's not required there, but recommended due to the caching logic inside the service API.
Message Queue Consumer Server
The messages from message queues are evenly distributed to all servers with the appropriate server role to consume messages from the queue. Additionally the thread count for consuming from a specific queue and writing to specific queues can be customized in the section "Message Queue Settings" of the server.properties file.