Web Search - Elasticsearch
An introduction to Product 360 - Web Search and how it works with Elasticsearch.
Product 360 - Web Search uses Elasticsearch 7.2.x. Please take care that most of the information about Elasticsearch are related to version 7.x and higher.
Introduction
Elasticsearch is a search engine based on the Lucene library. It provides a distributed, multitenant-capable full-text search engine with an HTTP web interface and schema-free JSON documents. Elasticsearch is developed in Java.
It has the following features:
Uses the Lucene library for full-text search
Faceted navigation
Query language supports structured as well as textual search
Flexible relevance - boost through function queries
JSON output formats over HTTP
Kibana - administration interface
Multi languages support
Multi-value fields
Extensible through plugins
Caching - queries, filters, and documents
Tolerant Searches with Elasticsearch
Elasticsearch provides capability to perform tolerant searches like Google does.
Examples:
|
Elasticsearch Text Analysis |
Given word |
Result |
|
Ngram |
election |
elec, lect, ecti, ctio,tion |
|
Stemmer, Snowball |
work |
works, working, worked, ... |
Internal Structure
Elasticsearch and the underlying Lucene framework uses an index to perform fast full-text searches.The concept is to ensure to get fast search response. The index takes more time to build.
Elasticsearch index is also called an inverted index, because it inverts a page-centric data structure (page -> words) to a keyword-centric data structure (word -> pages).
In database terminology, a Elasticsearch index corresponds to a table, a Elasticsearch document corresponds to a table row, and a Elasticsearch field corresponds to a table column.
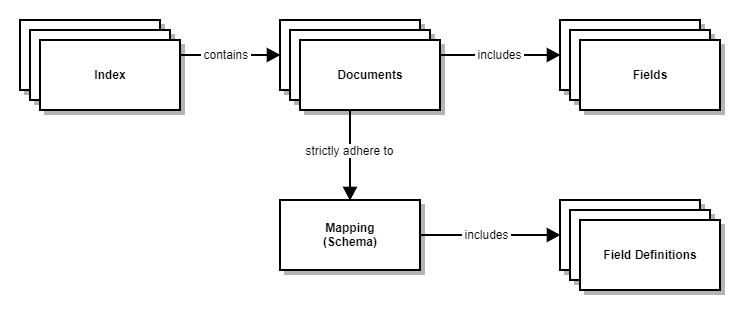
The index data are stored as de-normalized documents. Each documents contains fields which contains all necessary Product 360 data.
Web Search supported Elasticsearch Field Types
Each field defined in Web Search needs to adhere to any of the following Elasticsearch field types -
text
keyword
long
integer
double
float
Elasticsearch Analyzers, Tokenizers and Token Filters
Elasticsearch Analyzers, Tokenizers and Token Filters are defined in each index configuration file.
These help to perform better searches by indexing unstructured data. Each field can have its own set of analyzers, tokenizers and token filters.
More details on their usage can be found on the here: Text Analysis
Boost Factor
Each field can be assigned with a boost factor to get a better score value and to influence the order of the search result.
Parent-Child Relationship
Elasticsearch supports parent-child relationships using a special join field.
In Web Search, we can have an index containing Product, Variant and Item records' hierarchy using this join.
External links
Further information to Elasticsearch can be found here:
https://www.elastic.co/guide/en/elasticsearch/reference/7.x/index.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.x/analysis.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.x/analyzer.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.x/mapping-boost.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.x/parent-join.html