Data Quality - How-To, Best practices and usage strategies
Rules of thumb to decide when to use Data Quality or use other options
Data quality rules may serve different purposes: data cleansing, data generation, the typical quality check (data is ok) or also a mixture of all.
DQ execution is not always the best choice to reach your business goal, because it may be difficult to map the Product 360 world to a model that allows correct DQ execution. Also performance and accessibility aspects have to be considered.
So sometimes it is better to use a customization (Import functions, Post Import Steps etc.) instead of DQ.
DQ is most useful, if the resulting DQ status of an item is used:
for (manual) cleansing of data, for example in context of a workflow task that contains all items with a failed DQ status
in context of an automatic process like merge or import (items with a failed DQ status won't be merged)
DQ is not recommended (and the proposal would be a customization):
in general, if the DQ status is not used for follow up processes as described above
calls to Product360 via Rest calls in a Java Transformation that are not performant and/or complex e.g.
usage of many input ports to gather several data. This may slow down the execution time since these fields result in a too big sql statement to be performant (3900 characters in resulting sql statement part is the limit). An example is the concatenation of dozens of text attributes.
solving duplication detection problems. An example would be involving item id duplication checks on products of an item which are retrieved via rest calls.
in general rebuilding a large portion of the hierarchical and referential Product360 data model inside a DQ rule mapplet instead of simply using only the input data from the input ports of a rule mapplet.
In these cases one could think about avoiding usage of DQ checks and instead finding another way to reach the business goal - like a customization with extension points.
Never do this
Never create, delete or modify objects in the context of the DQ execution itself (i.e. through DB update tries or API calls). If you desire to write back values (i.e. standardized fields) make sure to use output ports of the rule itself for that.
Never use database connection access to our databases in DQ rules, neither for reading nor for writing. It is not supported by Product 360. If read access is needed, please use the Rest Service API (again, only read access in that case).
Never change our OOB rule packages like 'Informatica_PIM_Content.xml' and do not re-export OOB rules from IDQ Developer. Otherwise we can not guarantee that they still work.
Building rules and rule packages
Defining custom projects
As all rules in the Informatica Developer, custom rules have to be part of a project folder. This may be inside the folder 'Informatica_PIM_Content/Custom_Rules/' but also any other folder.
Please keep in mind that DQ project folders must be visible in Product 360 to be usable. This means adjusting the Product 360 preference 'dataquality.visible.rule.locations' which has the default folders 'Informatica_PIM_Content/PreDefined_Rules/' and 'Informatica_PIM_Content/Custom_Rules/'.
Implementing rules
Base Output ports and automatic field mapping
When executing a quality check, the following output ports are mandatory: status and message. With the status both manual and automatic following steps may be performed, and then for example workflows may be generated containing the items with the failed quality check.
The Product 360 fields that must be defined for these output ports are
an output field mapped to 'QualityStatusEntry.Message'. When opening the field selection dialog the field can be found as field 'Message' in the 'Status' category. The output port name is preferentially 'Status_Message'.
another output field mapped to the Product 360 field 'QualityStatusEntry.Status'. When opening the field selection dialog the field can be found as field 'Status' in the 'Status' category. The output port name is preferentially 'Status_Code'.
For convenience, it is best to stick to the port names 'Status_Code' and 'Status_Message'.
In case a rule mapplet is designed for a specific use case and thus only makes sense for specific Product 360 fields, then it could be useful to use auto mapping of mapplet ports to fields. This feature is described in the Data Quality subsection 'Auto-Assignment of Ports to Fields'. Especially for the both status output ports it makes a lot of sense to always use that feature since the mapping is always the same.
Object IDs for unique identification of objects
One of the main challenges to keep in mind is that data passed to the actual execution is done in a "flat way", row by row. So there is no immediate way to pass aggregations or other relationship between objects. So when writing back the status to Product 360, Product 360 would assume that the object that has been passed into data quality at a certain position is also received at the same position or row. But
when defining a subentity as input port, data quality execution automatically is permuting over all qualifications, thus creating new rows
it may happen that certain rows are filtered out in the rule logic
or the sorting of the rows changes for any reasons
With the Base input/output ports used, this would make it impossible for Product 360 to determine the target object for which the output data has to be written.
To uniquely identify an object through the whole process define an input and an output port, e.g. 'inObjectID' and 'outObjectID'. The Product 360 field that always has to be used for the mapping is a special marker field with the identifier 'Object_ID'. When opening the field selection dialog, it can be found as 'Object code number'. The below screenshot shows how this looks like for the GDSN rule 'Calc_ConditionalSum'.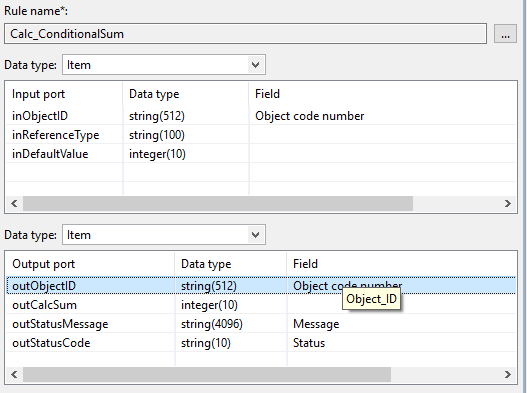
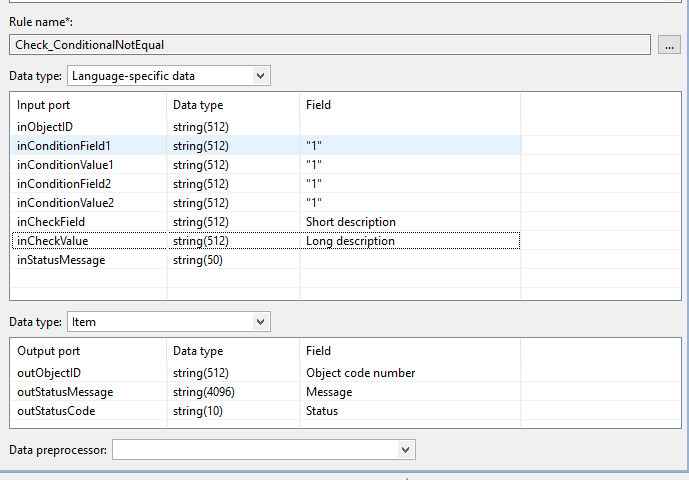
Example: Rule that checks whether all qualifications for two language dependent field are not equal.
Define Data type 'Language-specific data' in Input ports section of the rule configuration:
The resulting rule execution checks if values are all not equal and the status of the item is set to failed if one of the checks fails. This is done by aggregating the status of the item - see Expression MIN(statusCode) in the screenshot below. The rows respectively objects are identified and grouped by the ObjectId.
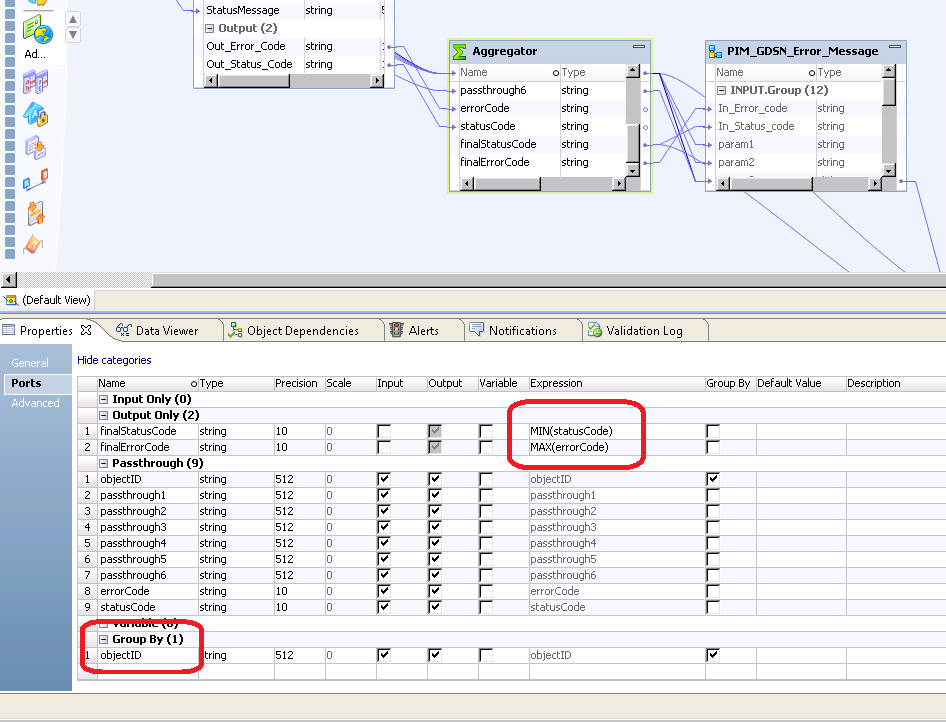
It is advised to always define and use such an object id, even if not needed at the first glance. The reason is that this way to prevent breaking the interface later, in case the rule mapplet is already used in production for some for rule configurations.
Special handling of items that do not have qualifications for subitems
A rule configuration may have a subentity defined, e.g. the language dependent text for an item. In case there is currently no persisted qualification for that subentity, then there will be no data quality execution for that item. The resulting DQ status is persisted as ok though. With the example of the item text, if there is no text defined yet, then the rule configuration execution always yields ok as result status.
If that satisfies the desired business use case, then nothing has to be done. However, when e.g. the requirement would be that there is at least one persisted qualification present, then further logic is required. That logic can be implemented by using a Java Transformation inside the used rule mapplet. All subitems would be retrieved via Rest Service List Read Request. If the resulting list from the read request is empty, then the rule returns not ok (failed) as output for the status port.
Alternatively this behavior can be changed to provide a left outer join. The left outer join can be configured in the server's plugin_customization.ini and is considered, when
either the rule mapplet used in a rule configuration is contained in the list of rules defined in the preference 'com.heiler.ppm.dataquality.server/dataquality.executor.useLeftOuterJoinForSubentity.rules'
or the rule configuration is contained in the list of rule configurations defined in the preference 'com.heiler.ppm.dataquality.server/dataquality.executor.useLeftOuterJoinForSubentity.ruleConfigurations'
An extra row for each such root item is then passed in case the root item has no sub entity records. If such an extra row is passed to dq execution, then the fields from the root item are filled with the appropriate value. Fields from the sub entity are filled with null values.
Example:
com.heiler.ppm.dataquality.server/dataquality.executor.useLeftOuterJoinForSubentity.rules = \ Informatica_PIM_Content/Custom_Rules/Check_SpecialAttributes;Informatica_PIM_Content/Custom_Rules/Check_Nutritionscom.heiler.ppm.dataquality.server/dataquality.executor.useLeftOuterJoinForSubentity.ruleConfigurations = \ Text_Category/Item_Text_Checks/Check_NutritionTexts;Attribute_Category/Product_Attributes_Checks/Check_Product_SpecialAttributes Futher details can be found in the comments of the plugin_customization.ini that is delivered with the Product 360 release package.
Usage of internal rest client inside java transformation, may pass created client to external code
The class 'InternalRestClient' was introduced for special purposes. One of these was to be able to make Service API calls inside DQ Java Transformation without having to define credentials for the created Web Resource Client. The reason for this was that there is no convenient way to pass the credentials to the DQ rule execution.
As an external developer, the InternalRestClient must only be used for the purpose of performing Product 360 Service API List Read Requests inside a DQ Java Transformation. Please have a look at the documentation Data Lookup via Java Transformations how to do this.
It might be desired to define and use custom Java code for reusability reasons. Or also make it easier to test via Unit tests e.g. in an environment outside IDQ Developer. In order to be able to do this, export all the java plugin projects as jar and then import them in IDQ developer into the Java Transformation as it is done for the Rest Client itself. Of course ensuring that the jar location is available for the IDQ Developer.
The Internal Rest Client that is created inside the Java code is then passed as parameter to the services of the custom component. For example if there is a method that determines the number of sub entity items of an item, this could look like this:
InternalRestClient restClient = createRestClient(); //do this as described in 'Data Lookup via Java Transformations'List<ItemRow> rows = collectRows(); // row objects created per incoming input rowCustomLogicClass customLogic = new CustomLogicClass(); // imported from custom exported pluginfor( ItemRow row : rows ) { int count = customLogic.getNumberOfTextSubitems( row.getItemNumber(), restClient ); if( count == 0 ) { row.setStatus( 0 ); // no subitems found -> not ok }}Internal paging when using Rest List Read Requests inside a Java Transformation
When using Rest Client inside a Java Transformation, executing a list read request may be slow and result in a large result.
The underlying queries to fetch the data are probably not optimized due to the large amount of item ids passed to that queries.
In this case, if the items are known by id, then an own internal paging logic could be used. The rest list read requests used there (using byItem report) would not use caching and there is a maximum amount of items that is predefined in the code (3900 characters in resulting sql statement part). The list of items is then separated into smaller parts, the pages, and then each list read request is executed passing the items of the page to the byItem report.The Rest Client call involves a large amount of fields (again the aforementioned 3900 characters in resulting sql statement part). This is the same problem as having a large amount of items - but in this case there is no known workaround like in the previous case. So here it is also recommended to use another solution than DQ.
when executing a read request it is not recommended to have caching enabled due to memory consumption
Exporting a custom rule package
For rule mapplets there is no versioning of rules, neither via file information itself nor via other data inside the mapplet XML files. This means that if a mapplet with a distinct name (project path + mapplet name) is uploaded via the Desktop Client, the version will be taken from the file just uploaded - no matter if the same mapplet is contained in another file. When restarting the server however, it is not deterministic from which of the files that specific mapplet will be taken.
So the recommendation here is to export all custom rules always in one package like custom_rules.xml and custom_rules.zip. And when doing this, all dependencies are included at one place as well in one XML file containing ONLY custom rule mapplets. Do not re-export OOB rule mapplets . This way it is also easier to manage and update dependent dictionaries (will then also be contained in one zip file).