Reference Data and Dicitionaries
Introduction
Reference tables already exist in DQ SDK. When setting up a dataquality project for PIM in IDQ Developer, there are usually a lot of internal tables that are used for rules execution, which are also called reference dictionaries or reference tables. Because of that it is now possible to manage some of the reference table entries in PIM with a dedicated user interface for this purpose.
Use case scenarios for reference tables
Reference tables may be tables simply containing error messages, but also tables for profanity checks etc. Another good example use case is color standardization tables. In PIM terms the color would be defined as an attribute of an item. Imagine pullovers in a web shop that have effectively the same color, but the description of the colors is different - f.e. "Deep red" and "Crimson". This may confuse the customer as well as the customer and suppliers.
So a DQ standardization mapplet rule may define that an incoming color value from the input port is mapped ("standardized") to another certain value as output value. F.e. both the color values "Deep red" and "Crimson" may be standardized to "Red" whereas "Azure" is standardized to "White".
Reference tables must be exported from IDQ developer as flat csv files with the .dic extension inside a zip archive.
Then they must be reimported again in PIM via reference data upload dialog in order to be usable during dq rules execution. If changes are made to these tables inside the IDQ Developer, the export/import process has to be done again.
Managing reference tables in PIM
Since 7.1 it is possible to manage some of those tables directly within PIM itself, which makes life easier for changes and check of data by sight. Consider again standardize color values example. Maybe someone made a mistake in the original dictionary for color standardization (the color "Mauve" was accidentally standardized to the color "Black"). If a reference table is managed in PIM you do not need to access the IDQ developer, make changes and export and import them again into PIM. Instead you can edit all the values in the PIM client and manually "release" the complete dictionary for dataquality execution by a simple click.
These sketches shall provide a rough overview of the possible import and management actions for reference tables, with detailed description following.
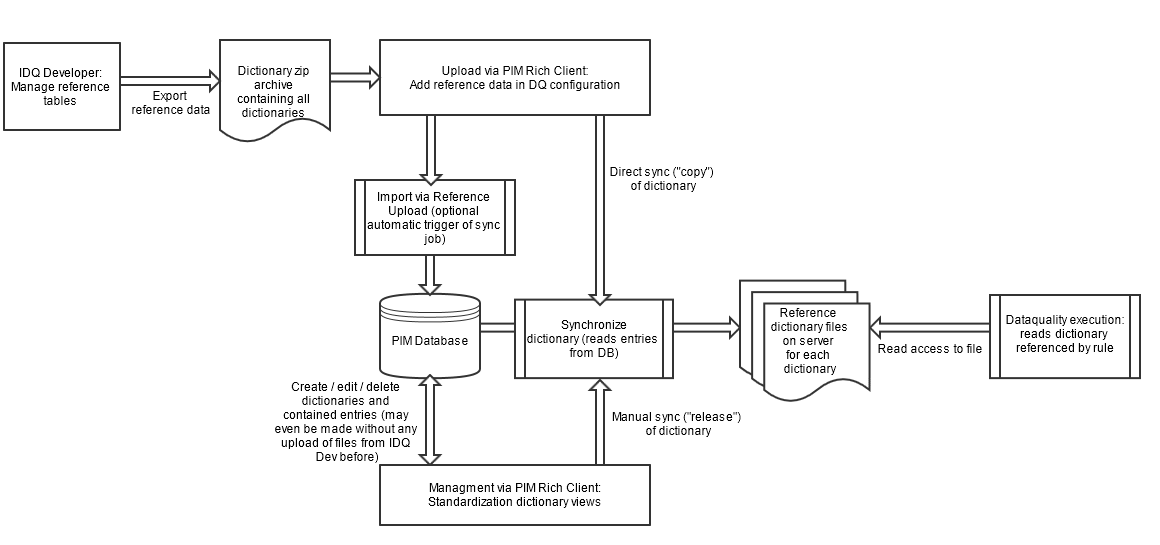
Reference Table definition in Mapplet Rules
To start contributing a IDQ rule you need to implement your custom IDQ rule within the IDQ Developer environment. This is done by combining different transformations within a IDQ Mapplet. The process of building a own IDQ rule is not part of this knowledgbe base page, we only want to discuss which PIM related task you need to do in terms of reference data.
Rules often use certain lookup tables or dictionaries to have a fixed set of lookup values for different kind of purposes - like the 'Standardize Color' example explained before. Rules refer to a certain table, they are not directly contained in the rule itself, thus they are also reusable for several rules. Note that in our current PIM setup we only allow flat file dictionary tables. Tables via database access is not supported at the moment. The content of the tables may be empty if you manage the entries in PIM anyway. Important is only the information that a rule refers to a certain table. Note that references consist of a full project path, which will later be reflected exactly in PIM.
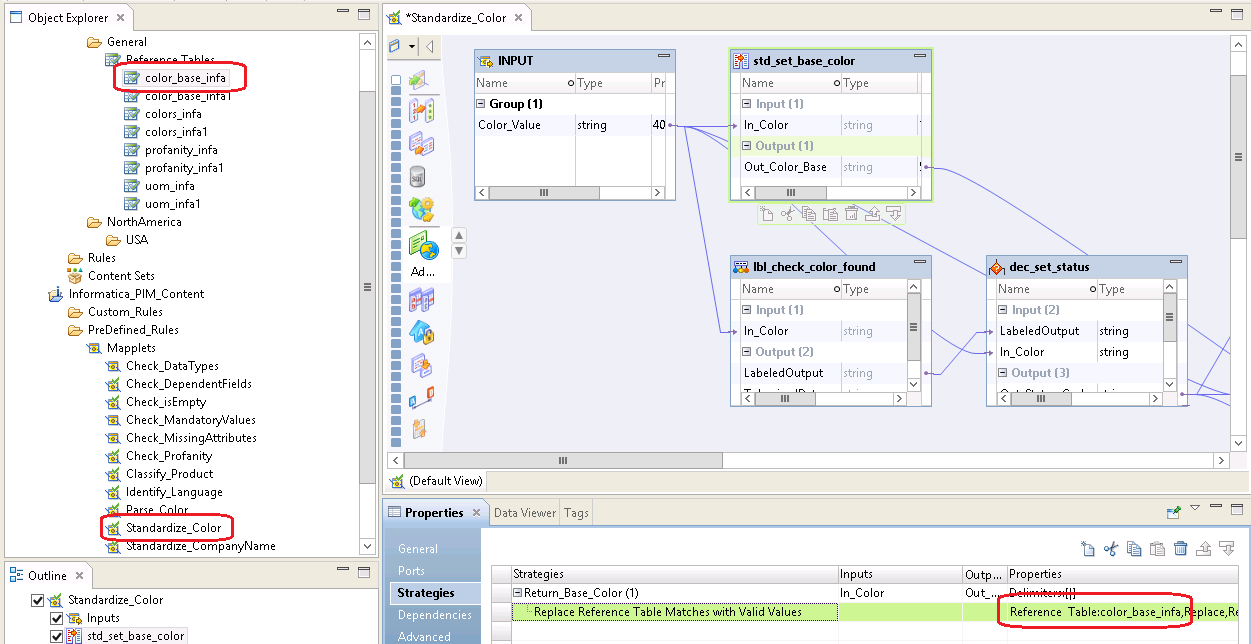
When rules and tables are finished both are to be exported (rules as xml and dictionaries inside zip file) in order to be usable in PIM. You can export projects via the IDQ Developer menu File -> Export -> Export object metadata file. Then the appropriate xml and zip file is generated.
A predefined rule set xml file is delivered with PIM together with a predefined dictionaries zip file.
Import dictionaries
There are two ways to import reference tables into PIM:
Import from reference data zip archive with possiblity to define certain actions for each reference data file inside
Import via import perspective (standard import process)
Reference data upload from zip archives
PIM is delivered with a standard rule set also containing the reference tables inside a zip file. It may also happen that new rules using new reference tables are created or updated inside IDQ developer and then the new dictionaries are also exported as a zip archive.
Now there are several use case scenarios what to do with the dictionaries:
use them as they are for dq execution and do not import the values into the PIM database. This may be either because
the data does probably not change very often
the data is for internal usage f.e. error messages
the data is not manageable in PIM because the data model needs exactly one or two columns in each row
import them into the PIM database possibly overwriting existing values. The imported data may then be further managed. After an import into the database the updated data may be
made immediatelly accessible for dq execution
made accessible for dq execution later in case the administrator wants to check the values first
In order to reflect all the use cases here, the reference data upload dialog in the data quality configuration view has been enhanced by offering a new dialog. When selecting a zip archive from the file choice dialog the "Adding reference data" dialog appears (see screenshot).
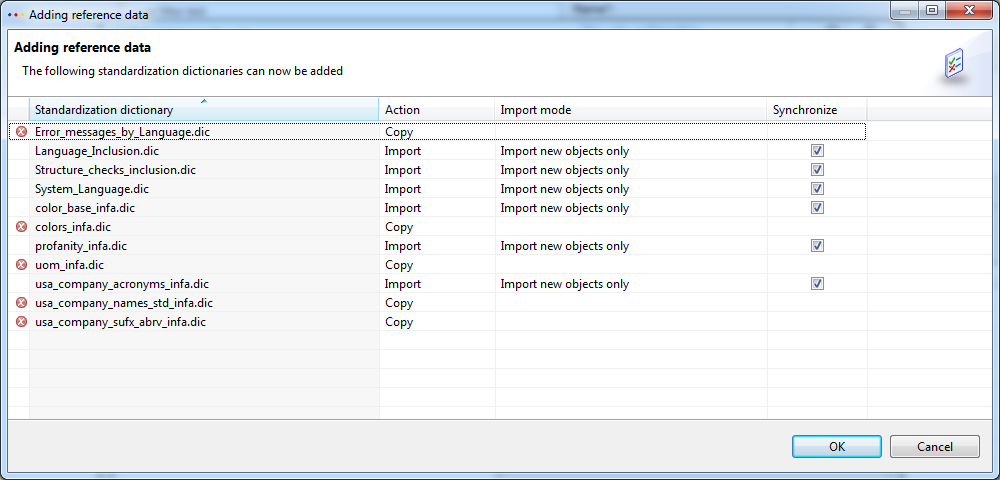
The selected zip archive is analyzed and lists all dictionary files (.dic extension) inside the zip archive. The purpose of this dialog is to configure the actions for each dictionary:
"Import" : import dictionary into PIM (manage by PIM). If a dictionary is not in PIM database yet, it will be created prior to an import.
There are additional options to be selectedimport options can be configured (the same as in the import perspective when starting an import): "Import or update all objects", "Import only new objects" and "Update existing objects only"
The default is set to "Import only new objects" in case the dictionary already exists in PIM, otherwise to "Import or update all objects"the dictionary can be marked to be synced from db to server folder for immediate use during dq execution (sync column in table)
"Copy": copy the dictionary to the folder (synced) directly without any data import into PIM, no matter whether a dictionary with the same identifier already exists in PIM or not - this way the data is also ready to go for immediate usage for dq execution
"Ignore": do none of the above with the dictionary, neither import nor directly copy to the server folder
Not all dictionaries are manageable and thus importable in PIM. To be importable, a dictionary file
must be a csv file with comma as separator
always have the same number of columns in each row
either have always 1 column or 2 columns
must not contain empty rows
If a dictionary is not importable, a cross error sign hints the user about it. In this case only the actions "Copy" and "Ignore" are available.
The name of a dictionary file is shown in the "Standardization dictionary" column. The full path or identifier of the dictionary inside the zip file can be seen by hovering over the dictionary (= file) name repsectively identifier.
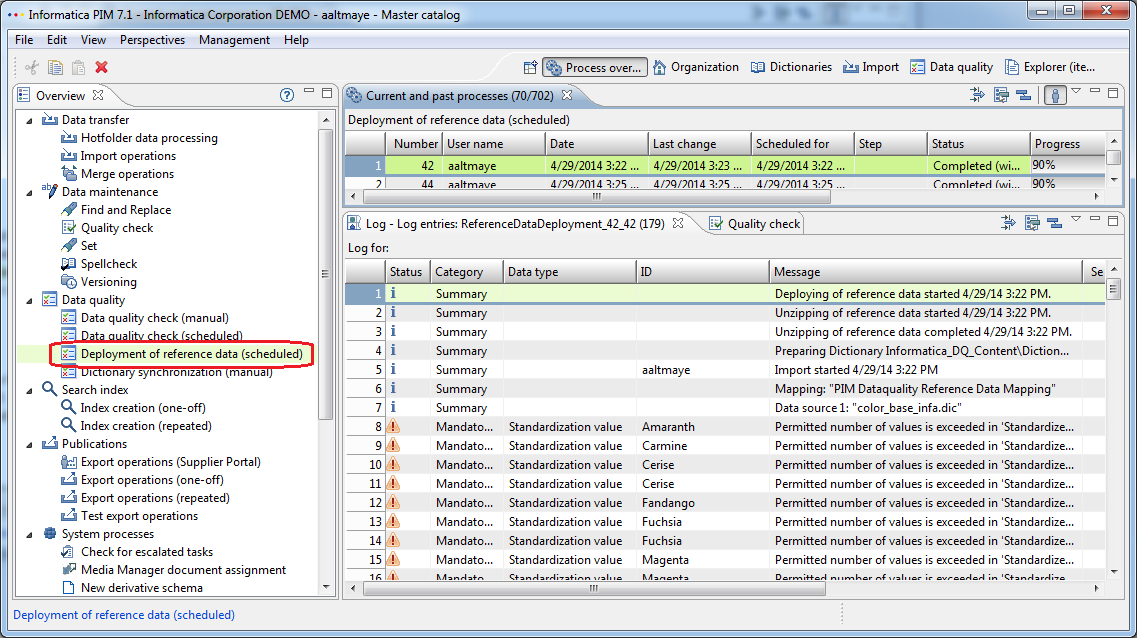
On Ok click, the reference data upload finally triggers a reference data upload job where the previously made configuration in the ui is processed and the proper actions are made for each dictionary file inside the zip archive.
Such jobs can be found as "Deployment of reference data (scheduled)" in the "Data Quality" Job Group (see screenshot below). As always such a job contains detailed information about every step (import steps,sync, occured errors and warnings etc.).
A more detailed explanation of the Synchronization process is described bewlow in the chapter "Manual release of Reference Tables for DQ execution" since the same is done there.
The reference upload dialog is accessible as long as the dq right "Data quality configuration, general access" is granted. There are no additional action permission checks on the ui side per dictionary, also no checks for ACL rights. The job is executed with the user that triggered the reference upload job. If there are any missing rights (action or ACL), this will be logged into the problem log of the job.
Standard import process
Reference table values may be imported via the import perspective. "Standardization Value" has been added to the list of importable entities. When starting an import, the target standardization dictionary to import to must be selected (see screenshot).
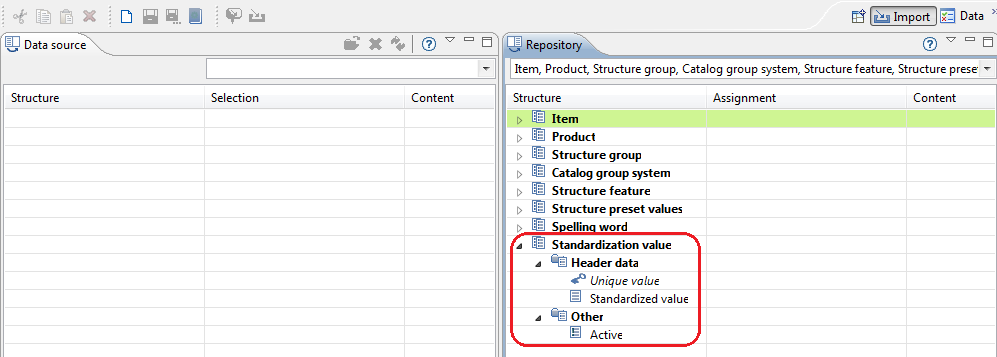
Standardization entries managment in the Dictionary perspective
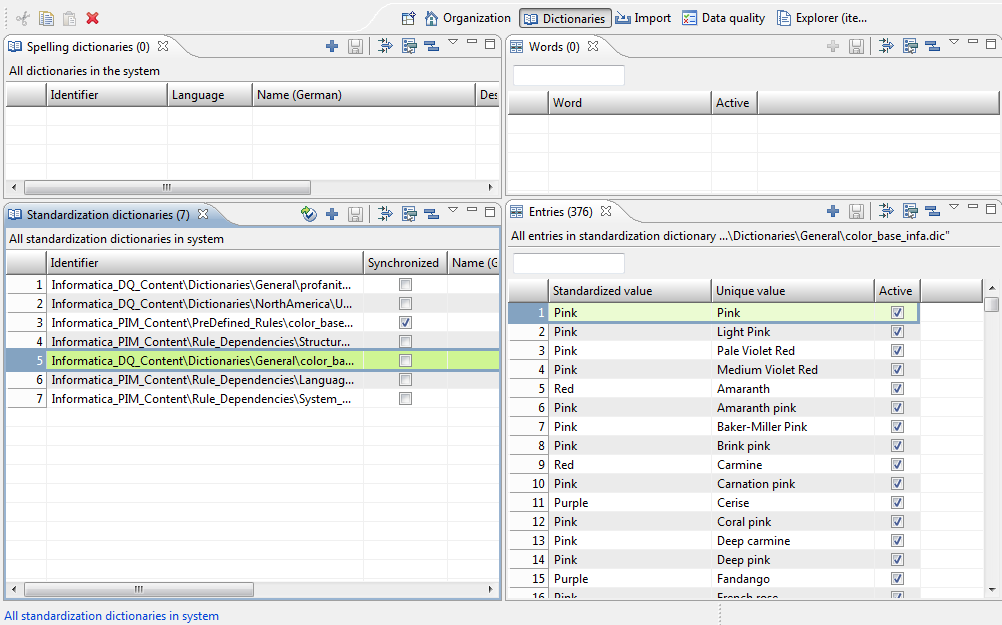
All PIM managed reference tables and their entries are managed in the Dictionaries Perspective. The views are just below the spellcheck dictionaries views, see screenshot. Because there are many standardization rule use cases the views are called "Standardization Dictionaries" and "Entries".
Note that
To access any of these views the action right "Standardization dictionaries, general access" is needed.
The action right "Manage standardization dictionaries" is needed to create/delete/edit dictionaries in "Standardization Dictionaries" view.
The action right "Manage values for standardization dictionaries" is needed to create/delete/edit values in the "Entries" view.
Technical Note
Standardization dictionaries use the same root entity as spellcheck dictionaries. The field 'Alternative Value' is used to represent the standardized value column and there is an new additional field "Synced" to show whether the actual state of the dictionary is being used by dq execution.
The "Entries" view on the right side refers to the currently selected dictionary on the left side. The "Unique Value" column is the unique key for all entries, whereas values in the "Standardized value" column may occur several times. In the context of the Standardized colors example this means that f.e. "Deep Black" may be standardized to "Standard Black" and "Onyx Black" to "Standard Black" as well. The identifier of a dictionary must always reflect the project folder structure in IDQ Developer to provide uniqueness of the dictionary. F.e. profanity checks may have the same name, but are located in different folders, like maybe "Informatica_PIM_Content/Italian_Text/profanity.dic" and "Informatica_PIM_Content/English_Text/profanity.dic".
Technical note
Although there may be dictionaries for the same purpose but with different, language dependent content (f.e. Italian and English profanity check tables), dictionaries in PIM are always stored with the language "Language independent".
The reason is that dictionaries are solely identified by their external identifier or path anyway - as described in the above example with the dictionaries named "profanity.dic" in the folders "Informatica_PIM_Content/Italian_Text/" and "Informatica_PIM_Content/English_Text/".
Manual release of Reference Tables for DQ execution
DQ rules which use a certain dictionary refer to a corresponding dictionary file on the server during execution. The path inside the dictionary folder is the same as the (external) dictionary identifier in the database. The DQ execution uses the current entries of the reference file, not the entries in the PIM database directly. The base folder for dictionary file is defined by the server property "dataquality.root.local". All dictionaries are contained in the path $dataquality.root.local + "\dictionaries".
So it is important to know that any changes to dictionary entries in the views are not immediately effective during dq rule execution. The reason for this is to have some sort of manual release process or workflow before any data is actually used by dq execution. This is reflected by the "Synced" flag in the standardization dictionaries table. As soon as changes have been made to the dictionary, the flag is set to false (unsynced).
On the other way round there is no automatic update of the PIM managed dictionary in the DB if the corresponding dictionary file changes in the server folder. So far dictionaries in DB and the corresponding file could coexist without influencing each other.
If a dictionary is unsynced for dq, a user may sync the dictionary with dq by pressing the sync button (see screenshot). The button is only enabled if the "Manage standardization dictionaries" action right is granted.
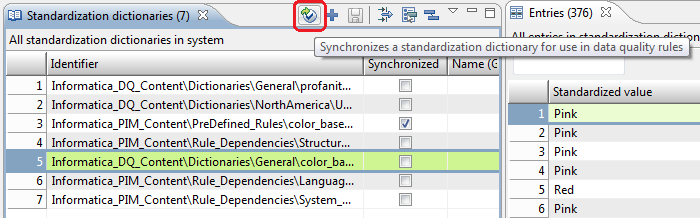
A job is then triggered which can be found as "Dictionary synhronization" in the "Data Quality" Job Group (see screenshot below).
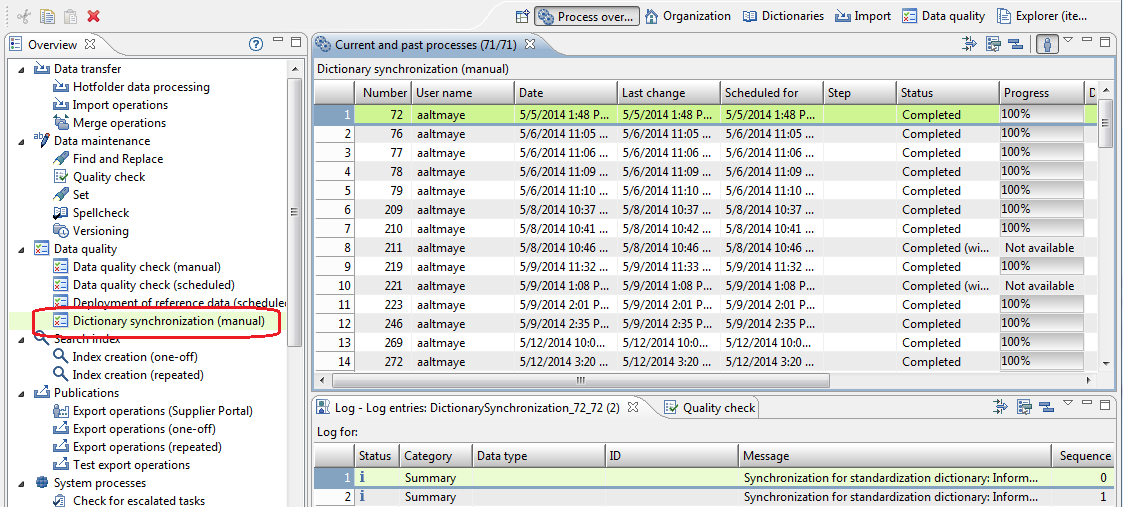
The job is executed as the user that triggered the job. Technically the job copies the entries of such a dictionary from the database to the configured dictionary folder on the server.
Only those entries are copied to the file that are marked as "Active" which also can be changed in the Entries view.
The format of the file is of course the same as always for dq dictionaries (comma separated csv files). This way PIM and IDQ developer have the same homogenous data structure which eases management usability on both sides.
The entries of a dictionary are all copied into a new temporary file during this process. When finished, the temporary file replaces the target file (that with the same dictionary identifier); during that replacement other such write processes are locked.
No job will be scheduled in case the dictionary is already synced.
On the other hand, a sync job will always be scheduled if the dictionary is not synced yet - even if there is already a job scheduled for that dictionary. In all cases the user will receive the ui feedback that the sync job has been successfully scheduled.
Even if the synchronization has been finished it may take some time until the updated data is used for the dataquality execution.
If there is already a dq execution running that already uses the updated dictionary, then this execution will not take the updated values.
Only "new" executions referencing that dictionary will use the updated values.
Deletion of dictionaries
Dictionaries that are deleted in the PIM database are also deleted in the server folder. This means that a reference dictionary with that name may not be used for dq execution any longer.
Change of dictionary identifier
The file with the old name will be deleted and a new one will be created with the same content. This means that a reference dictionary with the old name (identifier) may not be used for dq execution any longer.
The dictionary with the new name will be marked as not synced and therefor must be actively synced again.
Changes during dataquality execution
Changes to reference dictionaries during data quality execution is allowed and it is also permitted to sync dictionaries during execution.
The synchronization is finally only effective for the next started dq job execution. The process executing the dq rule caches the file content of the dictionary.
The reason to reuse the cache is to have one consistent dataquality run inside a dq job. Otherwise it could happen f.e. in the standardize color use case that inside the same job item colors would be standardized to different colors although they have the same original color.
Permissions overview
Action rights
"Standardization dictionaries, general access": The user is able to open the views Standardization dictionaries Standardization values and has a read access to all user defined dictionaries and values
"Standardization dictionaries, manage object rights": The user has a write access to all Standardization dictionary object rights
"Standardization dictionaries, read object rights": The user has a write access to all Standardization dictionary object rights
"Manage standardization dictionaries": The user is able to create, delete and edit dictionaries in the "Standardization Dictionaries" view. Also needed for synchronizations during the reference data upload process.
"Manage values for standardization dictionaries": The user is able to create, delete and edit values in the Standardization "Entries" view. Also needed for imports during the reference data upload process.
"Data quality configuration, general access": The reference upload dialog is only reachable within the dataquality configuration, so this action right is needed (already existent since 7.0.03)
Object ACL rights
As common with import processes standardization value imports also consider ACL rights (both via standard import perspective and via reference data upload dialog). That means that importing an entry is denied if trying to import entries to a dictionary to which the user has no write permission.
Entity report for standardization values
There is a new entity report for standardization values called "Standardization values by Standardization Dictionary" with the id "com.heiler.ppm.dictionary.core.StandardizationValuesByDictionary".
Important here are the parameters
'Dictionary' : refers to a unique dictionary by it's external identifier
'SearchQuery' : used for additional query parameters to refine the search
Rest Service API
This report is also incorporated into a rest service api call. F.e. to retrieve all words and their standardized values from the dictionary 'Colors Dutch' you would call
rest/V1.0/list/StandardizationValue/byDictionary?dictionary=Colors in holland&fields=StandardizationValue.Value,StandardizationValue.AlternativeValue