Persistence Model
Data sources
Since HPM has multiple data sources we provide a corresponding extension point for the application layer to introduce the data sources and to provide needed configuration settings for the JPA persistence-units. Additionally to that the persistence layer gives access to the needed JPA objects so the application layer can also use raw JPQL statements if they absolutely must.
Extension point
The application layer contributes the datasources to the com.heiler.ppm.persistence.db.datasource extension point. The extension-point provides elements for the data source (identifier, alias) as well as the jpa persistence unit. The standard HPM application contributes three data sources MAIN, MASTER and SUPPLIER. For every supported database system there must be a separate persistence unit contribution which provides the configuration file for this unit. A persistence unit is a combination of the DataSource and the database management system with the corresponding link to the configuration file. All persistence unit configuration files are located in the configuration area's sub-directory called: database
Configuration files do have a naming schema like this: [HPM:dataSourceIdentifier].properties.template.[HPM:dbmsIdentifier] (e.g. main.properties.template.MSSQL2005)
Data source registry
The data source registry which can be obtained with PersistenceLayer.getContext().getDataSourceRegistry() provides methods to aquire a JPA EntityManager. Please take a look at the corresponding javadoc for DataSourceRegistry for details on the available methods.
Connection Pool
HPM uses the Tomcat connection pool which can be configured using the persistence-unit configuration files located in the configurationArea/database. Please see the connection pool documentation for details.
Persistence model
The Heiler Product Manager persistence model is build using standard java persistence technologies (JPA). The HPM platform provides base classes and interfaces which can (or sometimes must) be implemented by the application layer in order to function properly in the HPM context.
Example of an application level .db bundle: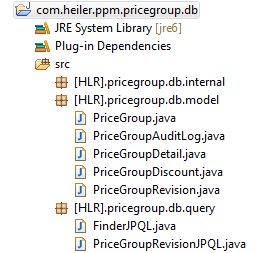
The persistence model must follow certain naming conventions as well as implementation rules which assure that the generic HPM functions can use them properly. These conventions are described in further sections. Additionally to that it makes life easier for everyone when similar things are implemented the same way.
Bundles
The persistence layer is strictly separated from other parts of the application and therefore we use own bundles for this layer. All persistence classes as well as JPQL named queries must be located in the plugins which end with .db. For example: com.heiler.ppm.article.db or com.heiler.ppm.catalog.db
This separation has to be maintained since we might need the persistence layer in the database setup again - without the whole HPM application.
Dependencies
The persistence model must not have any dependency to other then .db bundles or to third party libraries which are not already reexported by the platform .db bundles. It must be guaranteed that the set of all .db bundles can work on their own without having any dependency to .core, .server or .ui bundles, either directly or indirectly!
Model classes
Model classes (aka JPA Entities) must be located in the .model package and named exactly like the corresponding database table. Note that they must conform to the Java Bean standard, therefore the members must not be named like the database columns regarding the case of the first character.
JPA limitations
Generic functionality in HPM makes heavy usage of the JPA annotations as well as the meta models of the JPA provider etc. For abitrary reasons we had to limit the available JPA functionalities a bit.
Only bi-directional relations are allowed currently (so every @OneToMany annotation should have corresponding @ManyToOne)
Only 1:n or 1:1 relations are allowed, direct n:m mappings are not supported
The primary key of every jpa entity must be a bigint column named id which uses either a sequence or is an identity column
Only use attribute level annotations, no annotation on getters and setters
Only use sets for collections, no lists!
Only use objects, no primitives (Long instead of long!)
Every JPA entity must also have an implemented toString() method which omits null values.
Note: only return the string values of own members, no containment references (not the parent, no children) should be logged in the toString() method
Available interfaces/base classes which must or can be used
Persistable
The persistable interface is a maker interface which identifies a class as a HPM persistable object. All persistence model classes must implement this interface, either directly or through a base class or interface.
Deletable
The deletable class provides members, methods and annotations for the SoftDelete feature which has been introduced with HPM 5.3. JPA Entities which must support the soft delete feature should subclass this class, directly or indirectly.
The deletable class also declares all JPA filters for the SoftDelete feature (aliveOnly, deadOnly, deadSince), so they do not have to be declared in the model class itself. For performance reasons, all @OneToMany attributes should have the following JPA filters (for SoftDelete feature) annotated:
@Filters( { @Filter( name = Persistable.FILTER_ALIVE_ONLY ), @Filter( name = Persistable.FILTER_DEAD_ONLY ), @Filter( name = Persistable.FILTER_DEAD_SINCE ) } )
Auditable
The auditable class extends the deletable class and adds members, methods and annotations for the physical audit log functionality which has also been introduced in HPM 5.3.
JPA Entities which must store when and by whom they have been created, changed, deleted should subclass from Auditable.
The database tables must have the following columns in order to be able to use the Auditable interface properly:
|
Name |
Datatype |
Nullable |
|
CreationUserID |
bigint |
yes |
|
CreationTimestamp |
datetime |
yes |
|
ModificationUserID |
bigint |
yes |
|
ModificationTimestamp |
datetime |
yes |
|
DeletionUserID |
bigint |
yes |
|
DeletionTimestamp |
datetime |
yes |
AuditLogSupport
The AuditLogSupport class reflects the standard business audit log entity which has been introduced for every root entity of HPM 5.3. In contrast to the Auditable this class represents all members for the corresponding AuditLogEntity like ArticleAuditLog or CatalogAuditLog etc. The AuditLogSupport is no physical audit log only (which stores audit log in a simple but effective way for every table) but a more business driven feature. Clients can implement arbitraty AuditLogProviders which have then their own logging algorithms. AuditLogSupport is only available for root entities!
The database table which implements the audit log support must follow the following scheme:
The AuditLog table naming convention is: <Tablename of root entity>AuditLog (e.G. ArticleAuditLog, StructureGroupAuditLog etc.)
The table has a foreign key to it's corresponding root/revision root table and an unique index on the same and the classifier column. Therefore we have a 1:n relationship, where there can be only one record per item and classifier.
|
Name |
Datatype |
Nullable |
|
Classifier |
nvarchar(50) |
no |
|
CreationUserID |
bigint |
yes |
|
CreationTimestamp |
datetime |
yes |
|
ModificationUserID |
bigint |
yes |
|
ModificationTimestamp |
datetime |
yes |
|
DeletionUserID |
bigint |
yes |
|
DeletionTimestamp |
datetime |
yes |
|
Res_Text250_01 |
nvarchar(250) |
yes |
|
Res_Text250_02 |
nvarchar(250) |
yes |
|
Res_Text250_03 |
nvarchar(250) |
yes |
|
Res_Text250_04 |
nvarchar(250) |
yes |
|
Res_Text2G_01 |
ntext |
yes |
|
Res_Text2G_02 |
ntext |
yes |
|
Res_Text2G_03 |
ntext |
yes |
|
Res_Text2G_04 |
ntext |
yes |
|
Res_Text2G_05 |
ntext |
yes |
|
Res_Text2G_06 |
ntext |
yes |
|
Res_Text2G_07 |
ntext |
yes |
|
Res_Text2G_08 |
ntext |
yes |
|
Res_Bit_01 |
bit |
yes |
|
Res_Bit_02 |
bit |
yes |
|
Res_Bit_03 |
bit |
yes |
|
Res_Bit_04 |
bit |
yes |
|
Res_Bit_05 |
bit |
yes |
|
Res_Bit_06 |
bit |
yes |
|
Res_Bit_07 |
bit |
yes |
|
Res_Bit_08 |
bit |
yes |
|
Res_Int_01 |
bigint |
yes |
|
Res_Int_02 |
bigint |
yes |
|
Res_Int_03 |
bigint |
yes |
|
Res_Int_04 |
bigint |
yes |
|
Res_Int_05 |
bigint |
yes |
|
Res_Int_06 |
bigint |
yes |
|
Res_Int_07 |
bigint |
yes |
|
Res_Int_08 |
bigint |
yes |
|
Res_BigDecimal12_01 |
decimal(12,4) |
yes |
|
Res_BigDecimal12_02 |
decimal(12,4) |
yes |
|
Res_BigDecimal12_03 |
decimal(12,4) |
yes |
|
Res_BigDecimal12_04 |
decimal(12,4) |
yes |
|
Res_BigDecimal16_01 |
decimal(16,6) |
yes |
|
Res_BigDecimal16_02 |
decimal(16,6) |
yes |
|
Res_BigDecimal16_03 |
decimal(16,6) |
yes |
|
Res_BigDecimal16_04 |
decimal(16,6) |
yes |
|
Res_DateTime_01 |
datetime |
yes |
|
Res_DateTime_02 |
datetime |
yes |
|
Res_DateTime_03 |
datetime |
yes |
|
Res_DateTime_04 |
datetime |
yes |
Example
An abbreviated example of a typical HPM persistence model class: com.heiler.ppm.article.db.model.ArticleAttribute
@Entity@DynamicInsert@DynamicUpdate@Table( name = "`ArticleAttribute`" )public class ArticleAttribute extends Auditable implements FieldHandled{ @Id @GeneratedValue( strategy = GenerationType.AUTO, generator = "SEQ_ArticleAttribute" ) @SequenceGenerator( name = "SEQ_ArticleAttribute", sequenceName = "`SEQ_ArticleAttribute`", allocationSize = 50 ) @Column( name = "`ID`" ) private Long id = null; @ManyToOne( fetch = FetchType.LAZY ) @JoinColumn( name = "`ArticleRevisionID`", nullable = false ) private ArticleRevision articleRevision = null; @Column( name = "`Identifier`" ) private String identifier = null; @Column( name = "`NameInKeyLanguage`" ) private String nameInKeyLanguage = null; @OneToMany( mappedBy = "articleAttribute", cascade = CascadeType.ALL, fetch = FetchType.EAGER ) @Filters( { @Filter( name = Persistable.FILTER_ALIVE_ONLY ), @Filter( name = Persistable.FILTER_DEAD_ONLY ), @Filter( name = Persistable.FILTER_DEAD_SINCE ) } ) @Fetch( FetchMode.SUBSELECT ) private Set< ArticleAttributeLang > articleAttributeLangs = new HashSet< ArticleAttributeLang >(); public Long getId() { return this.id; } public void setId( Long newId ) { this.id = newId; } public Set< ArticleAttributeLang > getArticleAttributeLangs() { return this.articleAttributeLangs; } public void setArticleAttributeLangs( Set< ArticleAttributeLang > newArticleAttributeLangs ) { this.articleAttributeLangs = newArticleAttributeLangs; } //[...] getters and setters for all other fields too [...] @Override public String toString() { StringBuilder builder = new StringBuilder(); builder.append( "ArticleAttribute [" ); //$NON-NLS-1$ if ( this.id != null ) { builder.append( "id=" ); //$NON-NLS-1$ builder.append( this.id ); builder.append( ", " ); //$NON-NLS-1$ } if ( this.identifier != null ) { builder.append( "identifier=" ); //$NON-NLS-1$ builder.append( this.identifier ); builder.append( ", " ); //$NON-NLS-1$ } if ( this.nameInKeyLanguage != null ) { builder.append( "nameInKeyLanguage=" ); //$NON-NLS-1$ builder.append( this.nameInKeyLanguage ); builder.append( ", " ); //$NON-NLS-1$ } builder.append( "]" ); //$NON-NLS-1$ return builder.toString(); }}Extension point
Since JPA is not able to have modular persistence units HPM implemented it's own persistence unit configuration using the com.heiler.ppm.persistence.db.mapping extension point. JPA entity classes or packages containing JPA entities must be contributed to this extension point, for each persistence unit they should be available for.
The usual JPA implementations require some sort of persistence.xml file which contains the packages or classes which are available as JPA entities. Since HPM is a highly modular application we couldn't provide this kind of file at all - therefore we configured the JPA provider programatically
Named queries
Named queries offer a lot advantages over dynamic string concatenation or just normal HQL strings.
they will be cached by hibernate and JDBC which improves performance drastically in case they will be used often
they will be compiled at server startup which makes sure that - in case the server starts at all - all queries are at least syntactically correct
they are easy to use and to find if you follow our conventions
Conventions
Named queries have to be defined as annotations - usually they will be integrated in the JPA Entities which is, not a very good practice in our opinion. Therefore we use separate classes which only define the named queries and might also contain methods to apply the query to a jpa entity manager or something similar. Classes which contain named queries must be located in the .query package and should be named by the application area for which they contain queries of course.
Example
com.heiler.ppm.article.db.query.ArticleRelationJPQL
/** @formatter:off*/@NamedQueries( { @NamedQuery( name = ArticleRelationJPQL.FIND_ARTICLES_BY_CATALOGS, query = "SELECT ar.catalogId, ar.article.id, ar.entityId " + " FROM ArticleRevision ar " + " WHERE ar.catalogId IN (:catalogIds) ") } ) @MappedSuperclass/** @formatter:on */public class ArticleRelationJPQL{ public static final String FIND_ARTICLES_BY_CATALOGS = "hpm.articles.findArticlesByCatalogs"; //$NON-NLS-1$ public static final String PARAM_CATALOG_ID = "catalogIds"; //$NON-NLS-1$ /** * Finds all articles which belong to the given catalogs * @return query with articleRevision.catalogId, articleRevision.article.id, articleRevision.entityId */ public static Query findArticlesByCatalogs( EntityManager entityManager, Collection< Long > catalogIds ) { Query query = entityManager.createNamedQuery( FIND_ARTICLES_BY_CATALOGS ); query.setParameter( PARAM_CATALOG_ID, catalogIds ); return query; }}Formatter settings
The @formatter:off javadoc annotation will prevent the eclipse code formatting from reformating the named queries. This must be turned on in the Eclipse preferences:
MappedSuperclass
The @MappedSuperclass annotation makes sure that the class will be evaluated by the JPA provider although it is no real JPA entity.
Extension point
Classes containing named queries are also some kind of JPA entity and therefore must also be made visible to the persistence unit configuration by contributing the files or packages to the com.heiler.ppm.persistence.db.mapping extension point.
3rd party libraries
Since HPM 5.3 we rely on the JPA standard in all areas where possible. Sometime it is still necessary to have access to the underlying JPA provider's classes. HPM uses Hibernate as JPA provider which is located in the org.hibernate bundle in the target platform. You can obtain the Hibernate session using:
DataSourceRegistry dsr = PersisteLayer.getContext().getDataSourceRegistry();EntityManager entityManager = dsr.aquireManager(...);Session session = entityManager.unwrap(Session.class);To obtain the session factory use:
DataSourceRegistry dsr = PersisteLayer.getContext().getDataSourceRegistry();EntityManagerFactory factory = dsr.getFactory(...);SessionFactory sessionFactory = factory.unwrap(SessionFactory.class);