When you configure a mapping to use an Open Table target, configure the target properties.
Specify the name and description of the Open Table target. Configure the target and advanced target properties for the Open Table object in a Target transformation.
The following table describes the properties that you can configure in a Target transformation:
Property
Description
Connection
Name of the target connection.
You can select an existing connection, create a new connection, or define parameter values for the target connection property.
If you want to overwrite the target connection properties at run time, select the Allow parameter to be overridden at run time option.
Target Type
Type of the Open Table target object.
You can choose from the following target types:
- Single Object. Select to specify a single Open Table object.
- Parameter. Select to specify a parameter name. You can configure the target object in a mapping task associated with a mapping that uses this Target transformation.
Parameter
A parameter file where you define values that you want to update without having to edit the task.
Select an existing parameter for the target object or click New Parameter to define a new parameter for the target object.
The Parameter property appears only if you select parameter as the target type.
If you want to overwrite the target object at run time, select the Allow parameter to be overridden at run time option.
When the task runs, the Secure Agent uses the parameters from the file that you specify in the advanced session properties.
Object
Name of the target object.
You can select an existing object from the list or create a target object at run time. For information on creating the target object at run time, see the Create a target table at runtime for AWS Glue Catalog topic.
Note: You cannot create a target object at runtime if you configure Hive Metastore catalog in the connection.
Operation
Type of the target operation.
Select one of the following operations:
- Insert
- Update
- Upsert
- Delete
Note: You cannot configure the Data Driven operation on an Open Table target.
Update Columns
Select the unique key column as the condition field for the update, upsert, or delete operations in an Open Table target.
The following table describes the advanced properties that you can configure in a Target transformation:
Property
Description
Truncate Target
If enabled, the Secure Agent truncates the target table before loading the data.
By default, the checkbox is not selected.
Iceberg Advanced Properties
The properties that you want to configure for the Iceberg tables.
Enter the properties in the following format:
<parameter name>=<parameter value>
If you enter more than one property, enter each property in a new line.
When you use AWS Glue Catalog with Amazon S3 and the source and target buckets are in different regions, you must specify the Amazon S3 bucket region property in the following format for the update, upsert, or delete target operations:
In a mapping, when you use AWS Glue Catalog with Amazon S3 and they are in different regions, you must specify the Amazon S3 bucket region property in the following format:
BucketRegion=<bucket-region-name>
In a mapping in advanced mode, when you use AWS Glue Catalog with Amazon S3 and they are in different regions, you must specify the Amazon S3 bucket ARN property in the following format:
s3.access-points.<bucket-name>=<S3-bucket-ARN>
When you use Hive metastore with Amazon S3 and the source and target are in different regions, you must specify the Amazon S3 bucket region property in the following format:
When you use REST Catlog with Amazon S3 and the source and target are in different regions, you must specify the Amazon S3 bucket region property in the following format:
The properties that you want to configure for the Delta Lake tables.
Enter the properties in the following format:
<parameter name>=<parameter value>
If you enter more than one property, enter each property in a new line.
When you use AWS Glue Catalog with Amazon S3 and they are in different regions, you must specify the Amazon S3 bucket region property in the following format:
BucketRegion=<bucket-region-name>
UpdateMode
Loads data to the target based on the mode you specify.
This property applies when you select the Update or Upsert operation.
Select one of the following modes:
- Update As Update. Updates records in the target table if the specified unique key column value matches with the incoming column value.
- Update Else Insert. Updates records in the target table if the specified unique key column value matches with the incoming column value. If the unique key column value does not match, the mapping inserts a new row with the records.
Pre-SQL
Pre-SQL queries to run before writing data to Apache Iceberg Open Table formats.
You can enter multiple queries separated by a semicolon.
- For mappings, ensure that the SQL queries use a valid Athena SQL syntax.
- For mappings in advanced mode, ensure that the SQL queries use a valid Spark SQL syntax.
You must prefix the table name with the <OpenTableCatalog> string and the database name.
For example, <OpenTableCatalog>.databasename.tablename
The database name and table name identifiers in the queries must be in lowercase.
If the pre-SQL query fails, the mapping also fails.
Post-SQL
Post-SQL queries to run after writing data to Apache Iceberg Open Table formats.
You can enter multiple queries separated by a semicolon.
- For mappings, ensure that the SQL queries use a valid Athena SQL syntax.
- For mappings in advanced mode, ensure that the SQL queries use a valid Spark SQL syntax.
You must prefix the table name with the <OpenTableCatalog> string and the database name.
For example, <OpenTableCatalog>.databasename.tablename
The database name and table name identifiers in the queries must be in lowercase.
If the post-SQL query fails, the mapping also fails. If the mapping fails, the post-SQL query is not executed.
Snapshot Retention
Configurations to manage table history and optimize storage by automatically expiring snapshots and deleting data files that are no longer needed.
To enable snapshot retention, set the enable snapshot expiry property to true for the target table.
You can customize the following predefined properties:
- Snapshot retention period. Deletes all snapshots created before the specified number of days. The default value is 7d.
- Minimum snapshots to retain. Retains the latest number of specified snapshots, even if they're older than the retention period. The default value is 5.
- Expiry snapshot id. Deletes a particular snapshot you want to remove. Specify the snapshot ID of the snapshot.
Orphan File Cleanup*
Configurations to remove files that are not referenced by the table metadata.
To enable orphan file cleanup, set the enable orphan file cleanup property to true for the target table.
You can customize the following predefined property:
- Orphan file retention period. Deletes all orphan files created before the specified number of days. The default value is 3d.
Rewrite Manifest Files
Configuration to compact data files by combining small manifest files into fewer, larger ones.
To enable rewrite manifest files, set the enable rewrite manifest property to true for the target table.
*Applies only to mappings in advanced mode.
Create a target table at runtime for AWS Glue Catalog
You can use an existing target or create a target to hold the results of a mapping. If you choose to create the target, the agent creates the target if it does not exist already when you run the task.
To specify the target properties, perform the following tasks:
1Select the Target transformation in the mapping.
2To specify the target, click the Target tab.
3 Select the target connection.
4For the target type, choose Single Object or Parameter.
5Specify the target object or parameter.
6 To specify a target object, perform the following tasks:
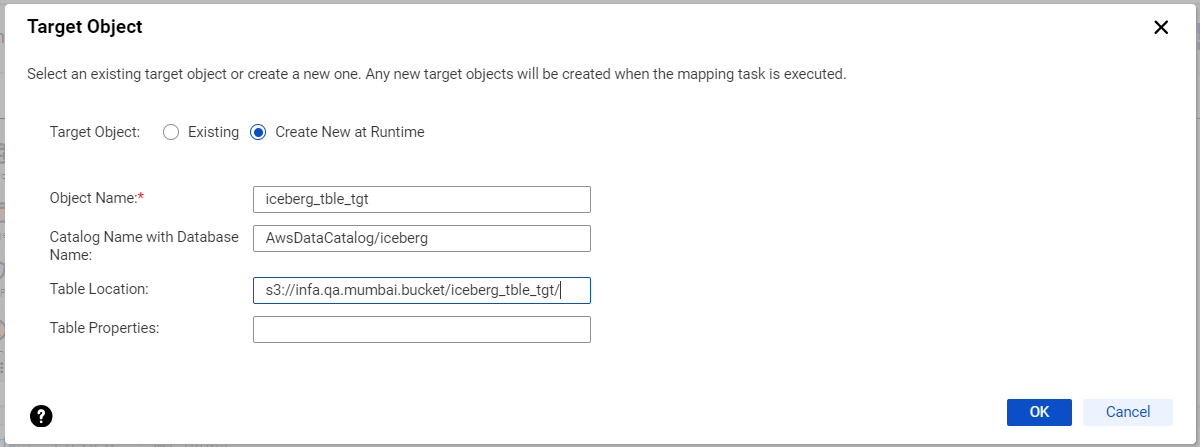
aClick Select and choose a target object. You can select an existing target object or create a new target object at runtime.
bTo create a target object at runtime, select Create New at Runtime.
cIn the Object Name field, enter the name of the target table that you want to create. The target table name must be in lowercase.
dIn the Catalog Name with Database Name field, enter the AWS Glue catalog name and database name in the following format: <catalogname>/<databasename>. The database name must be in lowercase.
eIn the Table Location field, enter the location of the target table data.
fSpecify the table properties to optimize the table configuration settings.