You can either use the Mapping - SQL ELT mapping type to directly create a mapping in SQL ELT mode, or you can first create a mapping and then enable SQL ELT optimization from the mapping task properties.
You can only use SQL ELT when you connect to a SQL warehouse to read from and write to Databricks tables.
Create a mapping in SQL ELT mode
In a mapping in SQL ELT mode, you don't have to specify an optimization type. Data Integration pushes the transformation logic by default to the target database.
You can run a mapping in SQL ELT mode to load data from the following data sources to Databricks:
•Amazon S3
•Databricks
•Google Cloud Storage
•Microsoft Azure Data Lake Storage Gen2
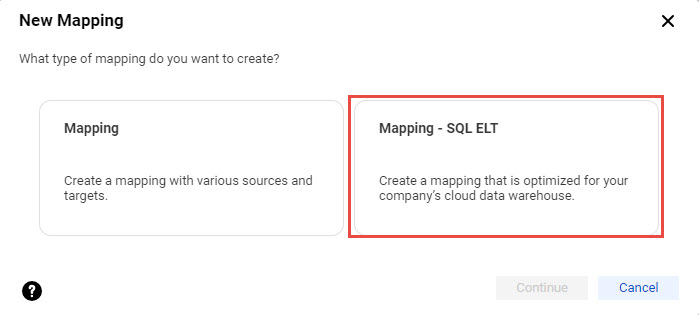
1To create a mapping in SQL ELT mode, you create a mapping and select Mapping - SQL ELT as the mapping type.
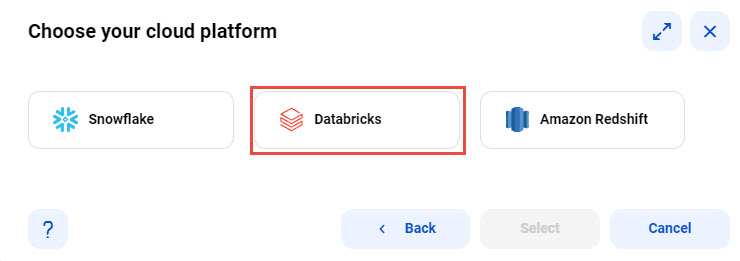
2Select the cloud ecosystem where you want all the mapping logic to be processed.
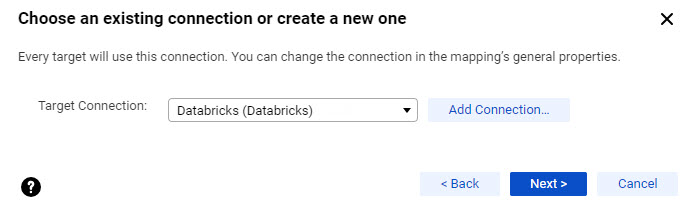
3You're then prompted to select the target connection.
The mapping is automatically configured with the target connection you chose.
You can add additional transformations to the mapping. The transformations available in the transformation palette are transformations that the target endpoint can process. You can also preview data for individual transformations to validate the mapping logic.
In a task enabled with SQL ELT optimization, you can select the optimization type to push some or all the transformation logic. Data Integration pushes the transformation logic to the source or target database based on the optimization type you specify in the task properties.
To enable SQL ELT optimization, add the configured mapping or mapping in advanced mode to a mapping task, and then enable SQL ELT optimization in the mapping task.
You can configure Full, Source, and other optimization configurations in the SQL ELT optimization advanced session properties on the Runtime Options tab. Data Integration processes any transformation logic that isn't pushed to the sources and targets on the on the Data Integration Server and on an advanced cluster.
You can enable SQL ELT optimization in a mapping task to load data from the following data sources to Databricks: