When you create a mapping, you can configure a Source or Target transformation to represent a Teradata object. After you configure a mapping, deploy the mapping in a mapping task.
Teradata Sources in Mappings
In a mapping, you can configure a Source transformation to represent a single Teradata source or multiple Teradata sources.
The following table describes the Teradata source properties that you can configure in a Source transformation:
Property
Description
Connection
Select the source connection, or click New Connection to create one. Alternatively, you can define a connection parameter in the mapping and enter a specific connection in each mapping task that is associated with the mapping.
Source type
Type of the source object. Select one of the following types:
- Single Object. Select to specify a single Teradata object.
- Multiple Objects. Select to specify multiple Teradata objects.
- Parameter. Select to specify a parameter name. You can configure the source object in a mapping task associated with a mapping that uses this source transformation.
Object
Name of the source object. Select the source object for a single source.
When you select the multiple source objects option, you can add multiple related source objects and configure relationships between them. You can use existing relationships or custom relationships to join multiple source objects.
When you create a custom relationship to join multiple Teradata objects, you can use only the Inner and Outer join types to join the objects.
If you select Parameter, create or select the parameter for the source object.
The following table describes the Teradata source advanced properties that you can configure in a Source transformation:
Advanced Property
Description
Driver Tracing Level
Determines Teradata PT API tracing at the driver level:
- TD_OFF. Teradata PT API disables tracing.
- TD_OPER. Teradata PT API enables tracing for driver-specific activities for Teradata.
- TD_OPER_CLI. Teradata PT API enables tracing for activites involving CLIv2.
- TD_OPER_NOTIFY. Teradata PT API enables tracing for activities involving the Notify feature.
- TD_OPER_OPCOMMON. Teradata PT API enables tracing for activities involving the operator common library.
- TD_OPER_ALL. Teradata PT API enables all driver-level tracing.
Default is TD_OFF.
Infrastructure Tracing Level
Determines Teradata PT API tracing at the infrastructure level:
- TD_OFF. Teradata PT API disables tracing.
- TD_OPER. Teradata PT API enables tracing for driver-specific activities for Teradata.
- TD_OPER_CLI. Teradata PT API enables tracing for activites involving CLIv2.
- TD_OPER_NOTIFY. Teradata PT API enables tracing for activities involving the Notify feature.
- TD_OPER_OPCOMMON. Teradata PT API enables tracing for activities involving the operator common library.
- TD_OPER_ALL. Teradata PT API enables all driver-level tracing.
Default is TD_OFF.
You must enable the driver tracing level before you can enable the infrastructure tracing level.
Trace File Name
File name and path of the Teradata PT API trace file.
Default path is $PM_HOME. Default file name is <Name of the TPT Operator>_timestamp. For example, EXPORTER_20091221.
Query Band Expression
The query band expression to be passed to the Teradata PT API.
A query band expression is a set of name-value pairs that identify a query’s originating source. In the expression, each name-value pair is separated by a semicolon and the expression ends with a semicolon. For example, ApplicationName=Informatica;Version=9.0.1;ClientUser=A;.
Spool Mode
Determines the spool mode Teradata PT API uses to extract data from Teradata.
You can select one of the following spool modes:
- Spool. Teradata PT API spools data while extracting data from Teradata.
- NoSpool. Teradata PT API does not spool data while extracting data from Teradata. If the database does not support the NoSpool option, Teradata PT API uses the Spool option.
- NoSpoolOnly. Teradata PT API does not spool while extracting data from Teradata.
Default is Spool.
SQL Override Query
The SQL statement to override the default query used to read data from the Teradata source. The data type, number, and order of columns in the select clause must match with the Teradata source object.
Select Distinct
Selects distinct rows and eliminates duplicate rows.
Tracing Level
Determines the amount of detail that appears in the log for the source. you can choose Terse, Normal, Verbose Initialization, or Verbose Data tracing level.
Default is Normal.
Partitioning for Teradata Sources
When you read data from Teradata sources, you can configure partitioning to read data in parallel and optimize the mapping performance at run time.
The Secure Agent distributes rows of data based on the number of partitions you define. Click the Partitions tab in the Source transformation to define the number of partitions you want to use to read data in parallel.
Rules and Guidelines for Partitioning
Consider the following rules and guidelines when you configure partitioning for Teradata sources:
•If the mapping contains multiple Teradata sources, configure the same number of partitions for all the Teradata sources. Otherwise, the mapping validation fails.
•If you configure more than one partition for a Teradata source, you cannot write data to a Teradata target.
Teradata Targets in Mappings
In a mapping, you can configure a Target transformation to represent a single Teradata API target.
The following table describes the Teradata target properties that you can configure in a Target transformation:
Property
Description
Connection
Select the target connection, or click New Connection to create one. Alternatively, you can define a connection parameter in the mapping and enter a specific connection in each mapping task that is associated with the mapping.
Target Type
Type of the target object. Select Single Object or Parameter.
Object
Name of the target object. Select one of the following types:
- Existing. Select to specify an existing target.
- Create New at Runtime. Select to create the target object when you run the task. Enter the name of the object, and then click OK.
If you select Parameter, create or select the parameter for the target object.
Operation
Target operation. Select Insert, Update, Upsert, Delete, or Data Driven.
Note:
When you define a DD_UPDATE expression in the data driven condition, ensure that you map the NOT NULL columns.
The following table describes the Teradata target advanced properties that you can configure in a Target transformation:
Property
Description
Update Else Insert
Teradata PT API updates existing rows and inserts other rows as if marked for update. If disabled, Teradata PT API updates existing rows only.
The Secure Agent ignores this attribute when you treat source rows as inserts or deletes.
Default is disabled.
Truncate Table
Teradata PT API deletes all rows in the Teradata target before it loads data.
Default is disabled.
Mark Missing Rows
Specifies how Teradata PT API handles rows that do not exist in the target table:
- None. If Teradata PT API receives a row marked for update or delete but it is missing in the target table, Teradata PT API does not mark the row in the error table.
- For Update. If Teradata PT API receives a row marked for update but it is missing in the target table, Teradata PT API marks the row as an error row.
- For Delete. If Teradata PT API receives a row marked for delete but it is missing in the target table, Teradata PT API marks the row as an error row.
- Both. If Teradata PT API receives a row marked for update or delete but it is missing in the target table, Teradata PT API marks the row as an error row.
Default is None.
Mark Duplicate Rows
Specifies how Teradata PT API handles duplicate rows when it attempts to insert or update rows in the target table:
- None. If Teradata PT API receives a row marked for insert or update that causes a duplicate row in the target table, Teradata PT API does not mark the row in the error table.
- For Insert. If Teradata PT API receives a row marked for insert but it exists in the target table, Teradata PT API marks the row as an error row.
- For Update. If Teradata PT API receives a row marked for update that causes a duplicate row in the target table, Teradata PT API marks the row as an error row.
- Both. If Teradata PT API receives a row marked for insert or update that causes a duplicate row in the target table, Teradata PT API marks the row as an error row.
This attribute is available for the Update and Stream system operators.
Default is For Insert.
Mark Extra Rows
Specifies how Teradata PT API marks error rows when it attempts to update or delete multiple rows in the target table:
- None. If Teradata PT API receives a row marked for update or delete that affects multiple rows in the target table, Teradata PT API does not mark the row in the error table.
- For Update. If Teradata PT API receives a row marked for update that affects multiple rows in the target table, Teradata PT API marks the row in the error table.
- For Delete. If Teradata PT API receives a row marked for delete that affects multiple rows in the target table, Teradata PT API marks the row in the error table.
- Both. If Teradata PT API receives a row marked for update or delete that affects multiple rows in the target table, Teradata PT API marks the row in the error table.
Default is Both.
Log Database
Name of the database that stores the log tables.
Log Table Name
Name of the restart log table.
Error Database
Name of the database that stores the error tables.
Error Table Name1
Name of the first error table.
Error Table Name2
Name of the second error table.
Work Table Database
Name of the database that stores the work tables.
Work Table Name
Name of the work table.
Macro Database
Name of the database that stores the macros Teradata PT API creates when you select the Stream system operator.
The Stream system operator uses macros to modify tables. It creates macros before Teradata PT API begins loading data and removes them from the database after Teradata PT API loads all rows to the target.
If you do not specify a macro database, Teradata PT API stores the macros in the log database.
Drop Log/Error/Work Tables
Drops existing log, error, and work tables for a session when the session starts.
Default is disabled.
Serialize
Uses the Teradata PT API serialize mechanism to reduce locking overhead when you select the Stream system operator.
Default is enabled.
Pack
Number of statements to pack into a request when you select the Stream system operator.
Must be a positive, nonzero integer.
Default is 20. Minimum is 1. Maximum is 600.
Pack Maximum
Causes Teradata PT API to determine the maximum number of statements to pack into a request when you select the Stream system operator.
Default is disabled.
Buffers
Determines the maximum number of request buffers that may be allocated for the Teradata PT API job when you select the Stream system operator. Teradata PT API determines the maximum number of request buffers according to the following formula:
Maximum number of records that can be stored in the error table before Teradata PT API terminates the Stream system operator job.
Must be -1 or a positive, nonzero integer.
Default is -1, which specifies an unlimited number of records.
Replication Override
Specifies how Teradata PT API overrides the normal replication services controls for an active Teradata PT API session:
- On. Teradata PT API overrides normal replication services controls for the active session.
- Off. Teradata PT API disables override of normal replication services for the active session when change data capture is active.
- None. Teradata PT API does not send an override request to the Teradata Database.
Default is None.
Driver Tracing Level
Determines Teradata PT API tracing at the driver level:
- TD_OFF. Teradata PT API disables tracing.
- TD_OPER. Teradata PT API enables tracing for driver-specific activities for Teradata.
- TD_OPER_ALL. Teradata PT API enables all driver-level tracing.
- TD_OPER_CLI. Teradata PT API enables tracing for activities involving CLIv2.
- TD_OPER_NOTIFY. Teradata PT API enables tracing for activities involving the Notify feature.
- TD_OPER_OPCOMMON. Teradata PT API enables tracing for activities involving the operator common library.
Default is TD_OFF.
Infrastructure Tracing Level
Determines Teradata PT API tracing at the infrastructure level:
- TD_OFF. Teradata PT API disables tracing.
- TD_OPER. Teradata PT API enables tracing for driver-specific activities for Teradata.
- TD_OPER_ALL. Teradata PT API enables all driver-level tracing.
- TD_OPER_CLI. Teradata PT API enables tracing for activities involving CLIv2.
- TD_OPER_NOTIFY. Teradata PT API enables tracing for activities involving the Notify feature.
- TD_OPER_OPCOMMON. Teradata PT API enables tracing for activities involving the operator common library.
Default is TD_OFF.
You must enable the driver tracing level before you can enable the infrastructure tracing level.
Trace File Name
File name and path of the Teradata PT API trace file. Default path is $PM_HOME. Default file name is <Name of the TPT Operator>_timestamp. For example, LOAD_20091221.
Pause Acquisition
Causes load operation to pause before the session loads data to the Teradata PT API target. Disable when you want to load the data to the target.
Default is disabled.
Query Band Expression
The query band expression to be passed to the Teradata PT API.
A query band expression is a set of name-value pairs that identify a query’s originating source. In the expression, each name-value pair is separated by a semicolon and the expression ends with a semicolon. For example, ApplicationName=Informatica;Version=9.0.1;ClientUser=A;.
Serialize Columns
Specifies an ordered list of columns that need to be serialized for the stream operator. Separate each column by semicolon.
Use this option to serialize based on a single column or set of columns. You can specify a value when you enable the serialize mechanism.
Default is blank. You can specify a value when you enable the serialize mechanism.
Replacement Character
Character to use in place of an unsupported Teradata unicode character in the Teradata database while loading data to targets. You can enter one character.
Database Version
Teradata database version. If you specified a character used in place of an unsupported character while loading data to Teradata targets, specify the version of the target Teradata database.
Use this attribute in conjunction with the Replacement Character attribute. The Secure Agent ignores this attribute if you did not specify a replacement character while loading data to Teradata targets.
Default is 8x-13x.
System Operator
The Teradata PT API operator type. You can select one of the following options:
- Load. Bulk loads data into an empty Teradata database table.
- Update. Performs update, insert, upsert, and delete operations against Teradata database tables.
- Stream. Performs update, insert, upsert, and delete operations against Teradata database tables in near real-time mode.
- Parameter. Allows you to parameterize the system operator through a parameter file.
This property is applicable when you use the Load operator.
Defines the maximum buffer size in kilobytes to be allocated to the Teradata PT API job for writing data.
If you do not enter a value and you use TTU version 15.10 or 16.10, Teradata Connector sets the value as 1024 KB for optimal performance. This setting is in line with Teradata's recommendation.
Success File Directory
Not applicable.
Error File Directory
Not applicable.
Forward Rejected Rows
Not applicable.
Parameterize Teradata system operators through a parameter file
You can parameterize a Teradata system operator using a parameter file when you write data to a Teradata target.
To parameterize a system operator using a parameter file, perform the following steps in the Target transformation:
1In the System Operator field, select Parameter.
2Add the parameter value in the following format:
$SystemOperator
3Define the parameter that you added for the system operator in the parameter file.
4Place the parameter file in the following location and run the mapping task:
When you use a Teradata connection to run a mapping to write data to Teradata, you can configure partitioning for the Teradata target.
You do not have to specify the number of partitions for the target separately. The Secure Agent considers the same number of partitions for the target as the number defined for the source partitioning.
Mapping Example
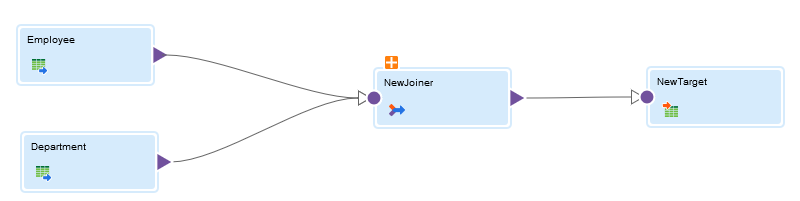
You want to read the employee and department information from a Teradata source, join the data, and then load the data to a Teradata target table.
Perform the following tasks to configure a mapping task:
1Create a Teradata mapping and enter a name and description.
The following image shows the Teradata mapping:
2Add a Source transformation to read employee information from Teradata using a Teradata connection. The source object used is a single object named Employee.
Some of the employee fields included are EMPID, EMPNAME, AGE, and DOB.
3Add another Source transformation to read the department information using a Teradata connection. The source object is a single object named Department.
Some of the business fields included are DEPTID, DEPTNAME, and DESCRIPTION.
4Add a Joiner transformation to join the employee and department information. Use the following Join condition for Master, Operator, and Detail:
Emp_DEPTID = DEPTID
5Add a Target transformation to write the joined data to a Teradata table using the Teradata connection. Perform the following tasks:
aSelect the Teradata connection.
bUse the insert operation and use a single target object named emp_dept_tgt.
cIn the Advanced Properties section, select Stream system operator and specify the data base version to which you want to connect.
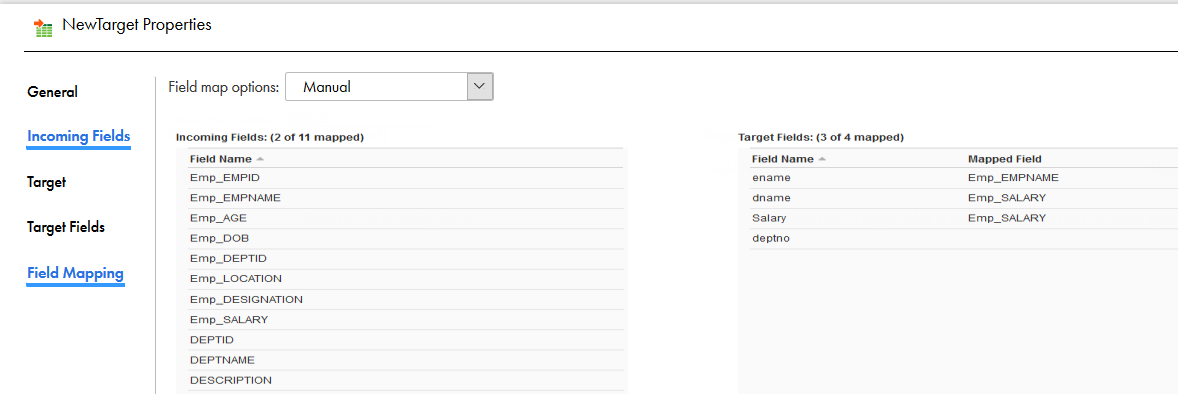
dIn the Field Mapping tab, select the incoming fields that you want in the target.
eThe following image shows the mapped fields:
6Configure a Teradata mapping task, add the mapping, and run the task.
The Secure Agent updates the target Teradata table.