To configure a task, click the Ingest panel on the Home page and then complete the following configuration steps in the task wizard:
1Define basic task information, such as the task name, project location, runtime environment, and load type.
2Configure the source.
3Configure the target.
4Configure the task schedule and runtime options.
Click Next or Back to navigate from one page to another. At any point, you can click Save to save the information that you have entered until then.
After you complete all the wizard pages, save the information and then click Deploy to make the task available as an executable job to the Secure Agent.
Before you begin
Before you configure an application ingestion and replication task, complete the following prerequisite tasks in Administrator:
•Verify that the Secure Agent in your runtime environment is running and you can access the Data Ingestion and Replication service.
•Define the source and target connections.
Integrating Application Ingestion and Replication Tasks with Data Integration Taskflows
You can configure application ingestion and replication tasks to trigger Data Integration taskflows that process and transform the ingested data. This feature is available for tasks that have any supported load type, source type, and target type.
When you define an application ingestion and replication task, you can select the Execute in Taskflow option to make the task available to add to taskflows in Data Integration. For incremental load and combined load jobs with an Amazon Redshift, Oracle, Snowflake (without Superpipe), or SQL Server target, you can optionally select the Add Cycle ID option to include cycle ID metadata in the target table. The Cycle ID column identifies the cycle in which the row got updated. It's passed as a parameter to the taskflow, where you can use it to filter the rows on which to execute transformation logic.
When you configure the taskflow in Data Integration, you can select the task as an event source and add any appropriate transformation type to transform the ingested data.
Configuration task flow:
1In the Data Ingestion and Replication task configuration wizard, select the following options when defining a application ingestion and replication task:
- (Optional) Add Cycle ID on the Target page. For incremental load jobs, this option adds the generated cycle ID for each CDC cycle to the target table. Applies to Amazon Redshift, Oracle, and SQL Server targets and to Snowflake targets that don't use the Superpipe option.
- Execute in Taskflow on the Schedule and Runtime Options page. This option makes the task available for selection when defining a taskflow in Data Integration.
2When done defining the task, Save it.
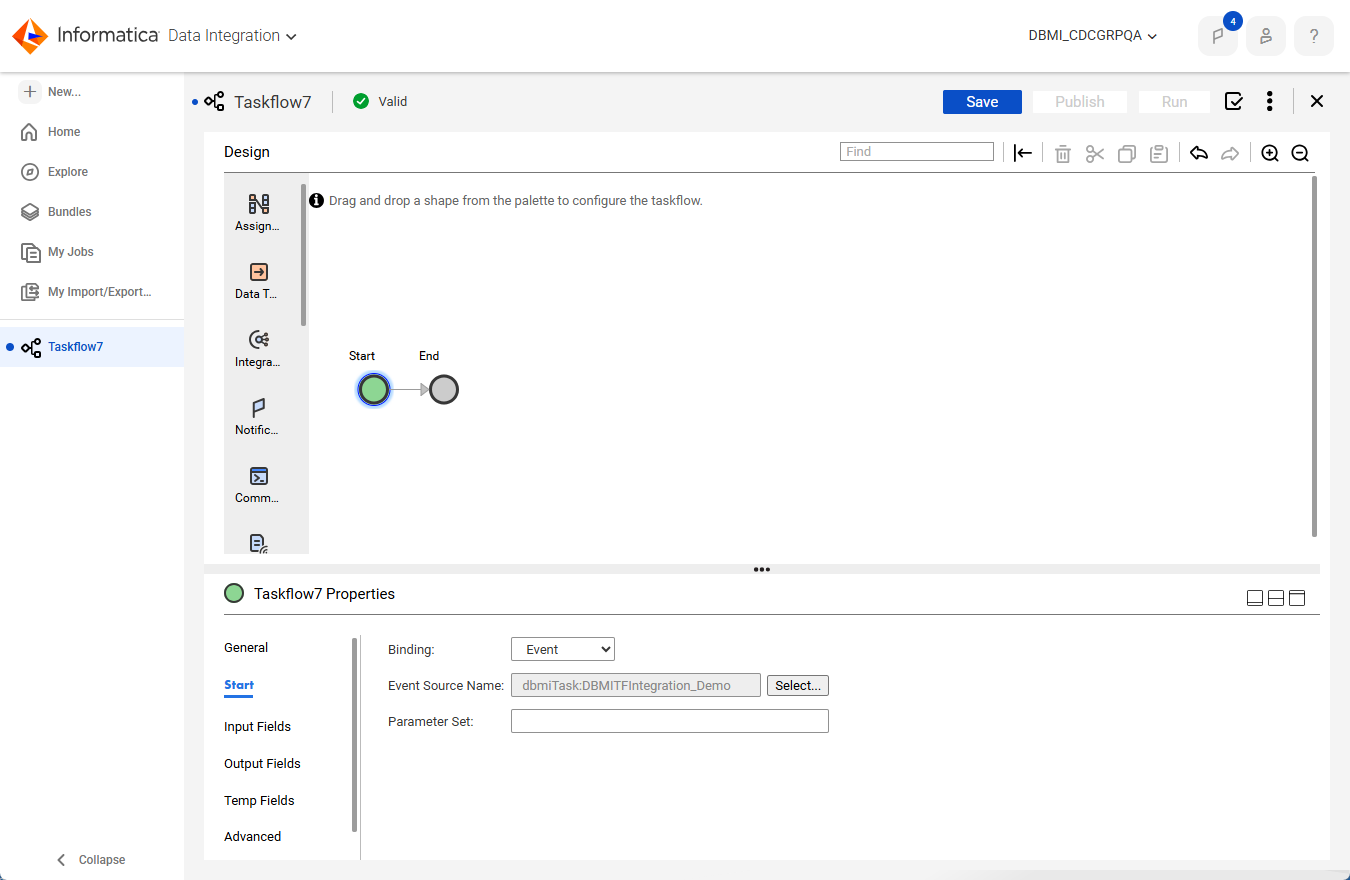
3To define a taskflow in Data Integration, click the Orchestrate panel on the Home page.
4To add the application ingestion and replication task in the taskflow, perform the following steps:
aUnder Task Properties, click Start.
bIn the Binding field, select Event.
cIn the Event Source Name field, click Select. Then in Select Event Source dialog box, select the database ingestion and replication task and click Select.
Note: You can filter the list of tasks by task type.
dCheck that the Event Source Name field and Input Fields display the task name. For example:
The taskflow is automatically triggered to start when either the initial load task successfully completes or after each CDC cycle in an incremental load operation. If a CDC cycle ends but the previous taskflow run is still running, the data is queued and waits for the previous taskflow to complete.
Defining basic task information
To define an application ingestion and replication task, you must first enter some basic information about the task, such as the task name, project or project folder location, and load operation type.
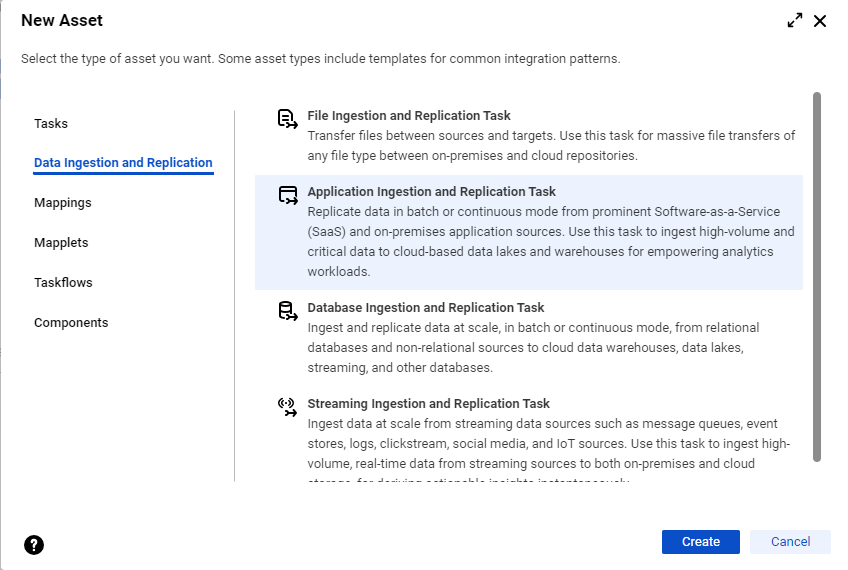
1Start the task wizard in one of the following ways:
- On the Home page, click the Ingest panel and select Application Ingestion and Replication Task.
- In the navigation bar on the Explore page or the Home page, click New to open the New Asset dialog box. Then, select Data Ingestion and Replication > Application Ingestion and Replication and click Create.
Note: If your organization does not have a custom license for application, database, file, or streaming ingestion and replication, the Data Ingestion and Replication category still appears but you cannot select and configure an ingestion and replication task of the unlicensed task type or types.
The Definition page of the application ingestion and replication task wizard appears.
2Configure the following properties:
Property
Description
Name
Name of the application ingestion and replication task.
The name of the application ingestion and replication task must be unique within the organization. The name can contain alphanumeric characters, spaces, periods (.), commas (,), underscores (_), plus signs (+), and hyphens (-).
Task names are not case sensitive. The maximum length is 50 characters.
Note: If you include spaces in the name of an application ingestion and replication task, the spaces do not appear in the name of the job associated with the task.
Location
Project or folder in which you want to store the task.
Runtime Environment
The runtime environment in which you want to run the task.
The runtime environment must be a Secure Agent group that consists of one or more Secure Agents. A Secure Agent is a lightweight program that runs tasks and enables secure communication.
For application ingestion and replication tasks, the Cloud Hosted Agent is not supported and does not appear in the Runtime Environment list.
You can use serverless runtime environments hosted on Microsoft Azure for application ingestion and replication initial load jobs only for some sources.
Tip: Click the Refresh icon to refresh the list of runtime environments.
Description
A brief description of the task.
Maximum length is 4000 characters.
Load Type
Type of load operation that you want the application ingestion and replication task to perform. You can select one of the following load types for the task:
- Initial Load: Loads data read at a specific point in time from the source application to the target in a batch operation. You can perform an initial load to materialize a target to which incremental change data will be sent.
- Incremental Load: Propagates source data changes to a target continuously or until the job is stopped or ends. The job propagates the changes that have occurred since the last time the job ran or from a specific start point for the first job run.
- Initial and Incremental Load: Performs an initial load of point-in-time data to the target and then automatically switches to propagating incremental data changes made to the same source objects on a continuous basis.
3Click Next.
Configuring the source
You can configure the source on the Source page of the application ingestion and replication task wizard.
Before you configure the source, ensure that the connection to the source is created in Administrator for the runtime environment that your organization uses.
1From the Connection list, select the connection configured for the source application. The connection type appears in parentheses after the connection name.
The list includes only the connections that are valid for the load type that you selected on the Definition page.
Note: After you deploy the ingestion task, you cannot change the connection without undeploying the associated ingestion job. After you change the connection, you must deploy the task again.
2Based on the type of source that you want to configure, perform the steps described in the following topics:
On the Source page of the application ingestion and replication task wizard, you can specify the objects that you want to ingest and configure the advanced properties for your Adobe Analytics source. You can also specify custom properties to address unique environments and special use cases.
1In the Path to Report Configuration File field, enter the path to the JSON file that contains the report configurations.
2In the Object Selection section, select Select All only if you want to select all source objects and fields for data replication. You cannot edit the selection in subsequent fields.
The Objects Selected field shows the count of all selected objects. If you have many source objects, the interface might take a long time to fetch them.
Alternatively, you can use rules to define a subset of source objects to replicate.
3To use rules to select the source objects, make sure that the Select All check box is cleared and then add rules.
When rule-based selection is used, you can refine the set of selected objects by object under Object View and also set an option for trimming spaces in character data.
Note: The default "Include *" rule selects all source objects accessed with the selected connection. To see how many objects are selected by this rule, click the Refresh icon to display the object count in Total Objects Selected and click Apply Rules to see the object count in Object View.
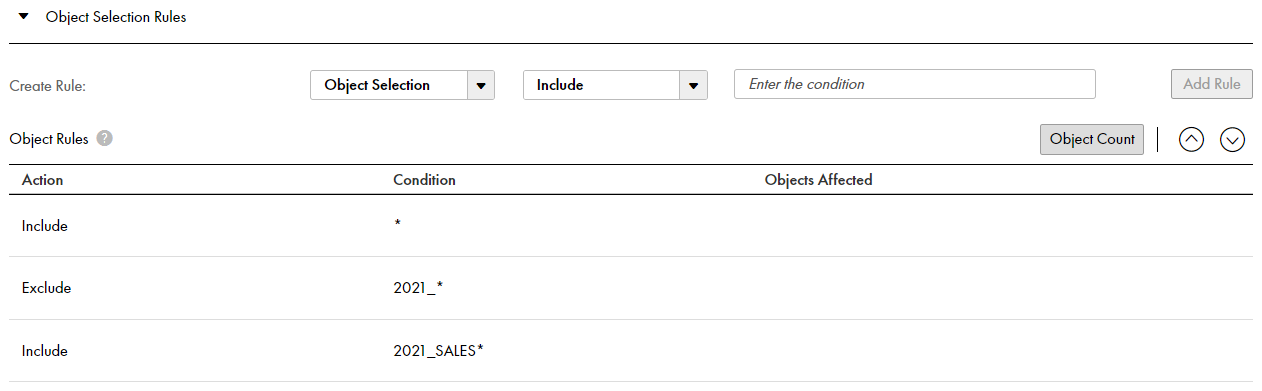
To add a rule:
aClick the Add Rule (+) icon above the first table under Rules. A row is added to define a new rule.
bIn the Object Rule field, select Include or Exclude to create an inclusion or exclusion rule, respectively.
cIn the Condition column, enter an object name or an object-name mask that includes one or more wildcards to identify the source objects to include in or exclude from object selection. Use the following guidelines:
▪ A mask can contain one or both of the following wildcards: an asterisk (*) wildcard to represent one or more characters and a question mark (?) wildcard to represent a single character. A wildcard can occur multiple times in a mask value and can occur anywhere in the value.
▪ The task wizard is case sensitive. Enter the object names or masks in the case with which the objects were defined.
▪ Do not include delimiters such as quotation marks or brackets, even if the source uses them.
▪ If an object name includes special characters such as a backslash (\), asterisk(*), dollar sign ($), caret (^), or question mark (?), escape each special character with a backslash (\) when you enter the rule.
dDefine additional rules as needed.
The rules are processed in the order in which they're listed, from top to bottom. Use the arrow icons to change the order.
eWhen finished, click Apply Rules.
Tip: Click the Refresh icon to the right of the Updated timestamp to refresh the Objects Affected and Total Objects Selected counts.
After you apply rules, if you add, delete, or change rules, you must click Apply Rules again. Click the Refresh icon to update the object counts. If you delete all rules without clicking Apply Rules, a validation error occurs at deployment, even if the Object View list still lists objects. If you switch to Select All, the rules no longer appear.
4To perform trim actions on the fields of the source objects that were selected based on rules, create field action rules.
Perform the following steps to create a field action rule:
aSelect Field Action as the rule type.
bFrom the adjacent list, select one of the following action types:
▪ LTRIM. Trims spaces to the left of character field values.
▪ RTRIM. Trims spaces to the right of character field values.
▪ TRIM. Trims spaces to the left of and to the right of character field values.
cIn the condition field, enter a field name or a field-name mask that includes one or more asterisk (*) or question mark (?) wildcards. The value that you enter is matched against fields of the selected source objects to identify the fields to which the action applies.
dClick Add Rule.
Note: You can define multiple rules for different action types or for the same action type with different conditions. The field action rules are processed in the order in which they are listed in the Rules list. The rule at the top of the list is processed first. You can use the arrow icons to change the order in which the rules are listed.
5Under Object View, view the selected objects, including the number of fields in each object and the field names and data types.
- If you selected Select All, the list of objects is view only.
- If you applied rules, you can refine the set of selected objects by clicking the check box next to individual objects. Deselect any objects that you do not want to replicate, or select additional objects to replicate. Click the Refresh icon to update the selected objects count.
Note: The first time you change a check box setting for an object, the rules are no longer in effect. The selections under Object View take precedence. However, if you click the Add Rule (+) icon again, the objects that you deselected or selected individually are reflected as new rules in the Rules list and the rules once again take precedence. If you want to return to the Object View list, click Apply Rules again.
For each object, you can view a list of field names and data types. Click the highlighted number of fields in the Fields column to list the fields to the right.
To search for objects and fields, in the drop-down list above Fields, select Object Name, Fields, or All and then enter a search string in the Find box and click Search. You can include a single asterisk (*) wildcard at the beginning or end of the string.
6To download a list of source objects that match the selection rules, perform the following steps:
aFrom the List Objects by Rule Type list, select the type of selection rule for which you want to download the list of selected source objects.
bIf you want to include the fields in the list, select Include Fields.
cClick the Download icon.
The list of source objects that match the selection rules is downloaded to your local drive.
The information in the downloaded file is in the following format:
status,object_name,object_type,field_name,comment
The following table describes the information in the downloaded file:
Field
Description
status
Indicates whether Application Ingestion and Replication includes or excludes the source object from processing. The possible values are:
- E. The object is excluded from processing by an Exclude rule.
- I. The object is included for processing.
- X. The object is excluded from processing even though it matches the selection rules. The comment field in the file provides details on why the object is excluded.
object_name
Name of the source object.
object_type
Type of the source object. The possible values are:
- O: Indicates an object.
- F: Indicates a field.
field_name
Name of the source field. This information appears only if you selected the Include Fields check box before downloading the list.
comment
Reason why a source object is excluded from processing even though it matches the selection rules.
7Expand the Advanced section.
8For initial load and combined initial and incremental load tasks, specify the date and time when the ingestion job should start replicating the source data.
Note: The date and time must be in the time zone specified for ReportSuiteID in the JSON file with report configurations
9For initial load tasks, specify the date and time when the ingestion job should stop replicating the source data.
Note: The date and time must be in the time zone specified for ReportSuiteID in the JSON file with report configurations
10For incremental load tasks, in the Initial Start Point for Incremental Load field, specify the point in the source data stream from which the ingestion job associated with the application ingestion and replication task starts extracting change records.
Note: You must specify the date and time in Coordinated Universal Time (UTC).
11For incremental load tasks and combined initial and incremental load tasks, in the CDC Interval field, specify the time interval in which the application ingestion and replication job runs to retrieve the change records for incremental load. The default interval is 1 day.
12In the Fetch Size field, enter the number of records that the application ingestion and replication job associated with the task reads at a time from the source. The default value is 50000.
13In the Custom Properties section, you can specify custom properties that Informatica provides for special cases. To add a property, add the property name and value, and then click Add Property.
The custom properties are usually configured to address unique environments and special use cases.
Note: Specify the custom properties only at the direction of Informatica Global Customer Support.
14Click Next.
Configuring a Google Analytics source
On the Source page of the application ingestion and replication task wizard, you can specify the objects that you want to ingest and configure the advanced properties for your Google Analytics source. You can also specify custom properties to address unique environments and special use cases.
1In the Account ID field, enter the unique identifier of your Google Analytics service account.
2In the Property ID field, enter the unique identifier of the property whose data you want to replicate.
3In the View ID field, enter the unique identifier of the view whose data you want to replicate.
4In the Path to Report Configuration File field, enter the path to the JSON file that contains the report configurations.
5In the Report Selection section, select Select All only if you want to select all source reports for data replication. You cannot edit the selection in subsequent dimensions & metrics.
The Reports Selected field shows the count of all selected reports. If you have many source reports, the interface might take a long time to fetch them.
Alternatively, you can use rules to define a subset of source reports to replicate.
6If you selected Rule-based Selection, create the rules to select the source reports that you want to replicate on the target.
By default, an Include rule configured to select all source reports is defined in the task. If you do not want to replicate all the source reports, you can define additional Include rules and Exclude rules to select the specific reports that you want to replicate.
Perform the following steps to create a report selection rule:
aSelect Report Selection as the rule type.
bFrom the adjacent list, select Include or Exclude as the action that you want the rule to perform.
cIn the condition field, enter a report name or a report-name mask to specify the source reports that you want to include in or exclude from the list of selected reports.
dClick Add Rule.
The rule appears in the Rules list.
To refine the selection, you can define additional Include rules and Exclude rules. The report selection rules are processed in the order in which they are listed in the Rules list. The rule at the top of the list is processed first. You can use the arrow icons to change the order in which the rules are listed. For an example of using multiple rules, see Example of rules for selecting source objects.
After you create the rules, you can click Report Count to display the number of source reports that match each rule in the Objects Affected column and the total number of reports selected based on all the selection rules in the Total Reports Selected field.
eTo preview the reports to be selected based on all rules, click Apply Rules.
The reports are listed on the Selected Reports tab. The list shows the report names and column count.
To search for tables and columns, you can either browse the list of objects or enter a search string in the Find box.
Tip: Click the Refresh icon next to the Updated date to refresh the total reports count and the list of reports selected based on the current rules. You can check the results of new rules in this manner. Click the Settings icon to control the line spacing in the list of reports, from Comfortable (most spacing) to Compact (least spacing).
7To perform trim actions on the columns of the source reports that were selected based on rules, create column action rules.
Perform the following steps to create a column action rule:
aSelect Column Action as the rule type.
bFrom the adjacent list, select one of the following action types:
▪ LTRIM. Trims spaces to the left of character column values.
▪ RTRIM. Trims spaces to the right of character column values.
▪ TRIM. Trims spaces to the left of and to the right of character column values.
cIn the condition field, enter a column name or a column-name mask that includes one or more asterisk (*) or question mark (?) wildcards. The value that you enter is matched against columns of the selected source reports to identify the columns to which the action applies.
dClick Add Rule.
Note: You can define multiple rules for different action types or for the same action type with different conditions. The column action rules are processed in the order in which they are listed in the Rules list. The rule at the top of the list is processed first. You can use the arrow icons to change the order in which the rules are listed.
8Under Report View, view the selected reports, including the number of rules in each report.
- If you selected Select All, the list of reports is view only.
- If you applied rules, you can refine the set of selected reports by clicking the check box next to individual report. Deselect any report that you do not want to replicate, or select additional reports to replicate. Click the Refresh icon to update the selected reports count.
Note: The first time you change a check box setting for a report, the rules are no longer in effect. The selections under Report View take precedence. However, if you click the Add Rule (+) icon again, the reports that you deselected or selected individually are reflected as new rules in the Rules list and the rules once again take precedence. If you want to return to the Report View list, click Apply Rules again.
For each report, you can view a list of columns. Click the highlighted number of columns in Columns to list the fields to the right.
To search for objects and fields, in the drop-down list above Columns, select Report Name, Columns, or All and then enter a search string in the Find box and click Search. You can include a single asterisk (*) wildcard at the beginning or end of the string.
9To download a list of source reports that match the selection rules, perform the following steps:
aFrom the List Reports by Rule Type list, select the type of selection rule for which you want to download the list of selected source reports.
bIf you want to include the columns in the list, select Include Columns.
cClick the Download icon.
The list of source reports that match the selection rules is downloaded to your local drive.
The information in the downloaded file is in the following format:
The following table describes the information in the downloaded file:
Field
Description
status
Indicates whether Application Ingestion and Replication includes or excludes the source report from processing. The possible values are:
- E. The report is excluded from processing by an Exclude rule.
- I. The report is included for processing.
- X. The report is excluded from processing even though it matches the selection rules. The comment field in the file provides details on why the report is excluded.
report_name
Name of the source report.
report_type
Type of the source report. The possible values are:
- O: Indicates a report.
- F: Indicates a column.
column_name
Name of the source column. This information appears only if you selected the Include Columns check box before downloading the list.
comment
Reason why a source report is excluded from processing even though it matches the selection rules.
10Expand the Advanced section.
11For initial load and combined initial and incremental load tasks, specify the date and time when the ingestion job should start replicating the source data.
12For initial load tasks, specify the date and time when the ingestion job should stop replicating the source data.
13For incremental load tasks, in the Initial Start Point for Incremental Load field, specify the point in the source data stream from which the ingestion job associated with the application ingestion and replication task starts extracting change records.
Note: You must specify the date in the time zone configured for the Google Analytics view.
14For incremental load tasks and combined initial and incremental load tasks, in the CDC Interval field, specify the time interval in which the application ingestion and replication job runs to retrieve the change records for incremental load. The default interval is 1 day.
15In the Fetch Size field, enter the number of records that the application ingestion and replication job associated with the task reads at a time from the source. The default value is 50000.
16In the Custom Properties section, you can specify custom properties that Informatica provides for special cases. To add a property, add the property name and value, and then click Add Property.
The custom properties are usually configured to address unique environments and special use cases.
Note: Specify the custom properties only at the direction of Informatica Global Customer Support.
17Click Next.
Configuring a Marketo source
On the Source page of the application ingestion and replication task wizard, you can specify the objects that you want to ingest and configure the advanced properties for your Marketo source. You can also specify custom properties to address unique environments and special use cases.
1In the Object Selection section, select Select All only if you want to select all source objects and fields for data replication. You cannot edit the selection in subsequent fields.
The Objects Selected field shows the count of all selected objects. If you have many source objects, the interface might take a long time to fetch them.
Alternatively, you can use rules to define a subset of source objects to replicate.
2To use rules to select the source objects, make sure that the Select All check box is cleared and then add rules.
When rule-based selection is used, you can refine the set of selected objects by object under Object View and also set an option for trimming spaces in character data.
Note: The default "Include *" rule selects all source objects accessed with the selected connection. To see how many objects are selected by this rule, click the Refresh icon to display the object count in Total Objects Selected and click Apply Rules to see the object count in Object View.
To add a rule:
aClick the Add Rule (+) icon above the first table under Rules. A row is added to define a new rule.
bIn the Object Rule field, select Include or Exclude to create an inclusion or exclusion rule, respectively.
cIn the Condition column, enter an object name or an object-name mask that includes one or more wildcards to identify the source objects to include in or exclude from object selection. Use the following guidelines:
▪ A mask can contain one or both of the following wildcards: an asterisk (*) wildcard to represent one or more characters and a question mark (?) wildcard to represent a single character. A wildcard can occur multiple times in a mask value and can occur anywhere in the value.
▪ The task wizard is case sensitive. Enter the object names or masks in the case with which the objects were defined.
▪ Do not include delimiters such as quotation marks or brackets, even if the source uses them.
▪ If an object name includes special characters such as a backslash (\), asterisk(*), dollar sign ($), caret (^), or question mark (?), escape each special character with a backslash (\) when you enter the rule.
dDefine additional rules as needed.
The rules are processed in the order in which they're listed, from top to bottom. Use the arrow icons to change the order.
eWhen finished, click Apply Rules.
Tip: Click the Refresh icon to the right of the Updated timestamp to refresh the Objects Affected and Total Objects Selected counts.
After you apply rules, if you add, delete, or change rules, you must click Apply Rules again. Click the Refresh icon to update the object counts. If you delete all rules without clicking Apply Rules, a validation error occurs at deployment, even if the Object View list still lists objects. If you switch to Select All, the rules no longer appear.
3To perform trim actions on the fields of the source objects that were selected based on rules, create field action rules.
Perform the following steps to create a field action rule:
aSelect Field Action as the rule type.
bFrom the adjacent list, select one of the following action types:
▪ LTRIM. Trims spaces to the left of character field values.
▪ RTRIM. Trims spaces to the right of character field values.
▪ TRIM. Trims spaces to the left of and to the right of character field values.
cIn the condition field, enter a field name or a field-name mask that includes one or more asterisk (*) or question mark (?) wildcards. The value that you enter is matched against fields of the selected source objects to identify the fields to which the action applies.
dClick Add Rule.
Note: You can define multiple rules for different action types or for the same action type with different conditions. The field action rules are processed in the order in which they are listed in the Rules list. The rule at the top of the list is processed first. You can use the arrow icons to change the order in which the rules are listed.
4Under Object View, view the selected objects, including the number of fields in each object and the field names and data types.
- If you selected Select All, the list of objects is view only.
- If you applied rules, you can refine the set of selected objects by clicking the check box next to individual objects. Deselect any objects that you do not want to replicate, or select additional objects to replicate. Click the Refresh icon to update the selected objects count.
Note: The first time you change a check box setting for an object, the rules are no longer in effect. The selections under Object View take precedence. However, if you click the Add Rule (+) icon again, the objects that you deselected or selected individually are reflected as new rules in the Rules list and the rules once again take precedence. If you want to return to the Object View list, click Apply Rules again.
For each object, you can view a list of field names and data types. Click the highlighted number of fields in the Fields column to list the fields to the right.
To search for objects and fields, in the drop-down list above Fields, select Object Name, Fields, or All and then enter a search string in the Find box and click Search. You can include a single asterisk (*) wildcard at the beginning or end of the string.
5To download a list of source objects that match the selection rules, perform the following steps:
aFrom the List Objects by Rule Type list, select the type of selection rule for which you want to download the list of selected source objects.
bIf you want to include the fields in the list, select Include Fields.
cClick the Download icon.
The list of source objects that match the selection rules is downloaded to your local drive.
The information in the downloaded file is in the following format:
The following table describes the information in the downloaded file:
Field
Description
status
Indicates whether Application Ingestion and Replication includes or excludes the source object from processing. The possible values are:
- E. The object is excluded from processing by an Exclude rule.
- I. The object is included for processing.
- X. The object is excluded from processing even though it matches the selection rules. The comment field in the file provides details on why the object is excluded.
MARKETO
Name of the source application.
object_name
Name of the source object.
object_type
Type of the source object. The possible values are:
- O: Indicates an object.
- F: Indicates a field.
field_name
Name of the source field. This information appears only if you selected the Include Fields check box before downloading the list.
comment
Reason why a source object is excluded from processing even though it matches the selection rules.
6Expand the Advanced section.
7For initial load tasks, in the Start Date field, specify the date on which the ingestion job associated with the application ingestion and replication task starts reading records from lead and custom objects on the source.
8For incremental load tasks, in the Initial Start Point for Incremental Load field, specify the point in the source data stream from which the ingestion job associated with the application ingestion and replication task starts extracting change records.
Note: You must specify the date and time in Coordinated Universal Time (UTC).
9For incremental load tasks and combined initial and incremental load tasks, in the CDC Interval field, specify the time interval in which the application ingestion and replication job runs to retrieve the change records for incremental load. The default interval is 5 minutes.
10In the Custom Properties section, you can specify custom properties that Informatica provides for special cases. To add a property, add the property name and value, and then click Add Property.
The custom properties are usually configured to address unique environments and special use cases.
Note: Specify the custom properties only at the direction of Informatica Global Customer Support.
11Click Next.
Configuring a Microsoft Dynamics 365 source
On the Source page of the application ingestion and replication task wizard, you can specify the tables that you want to ingest and configure the advanced properties for your Microsoft Dynamics 365 source. You can also specify custom properties to address unique environments and special use cases.
1In the Table Selection section, select Select All only if you want to select all source tables and columns for data replication. You cannot edit the selection in subsequent columns.
The Tables Selected field shows the count of all selected tables. If you have many source tables, the interface might take a long time to fetch them.
Alternatively, you can use rules to define a subset of source tables to replicate.
2To use rules to select the source objects, make sure that the Select All check box is cleared and then add rules.
When rule-based selection is used, you can refine the set of selected tables by table under Table View and also set an option for trimming spaces in character data.
Note: The default "Include *" rule selects all source tables accessed with the selected connection. To see how many tables are selected by this rule, click the Refresh icon to display the table count in Total Tables Selected and click Apply Rules to see the table count in Table View.
To add a rule:
aClick the Add Rule (+) icon above the first table under Rules. A row is added to define a new rule.
bIn the Table Rule column, select Include or Exclude to create an inclusion or exclusion rule, respectively.
cIn the Condition column, enter an object name or an object-name mask that includes one or more wildcards to identify the source objects to include in or exclude from object selection. Use the following guidelines:
▪ A mask can contain one or both of the following wildcards: an asterisk (*) wildcard to represent one or more characters and a question mark (?) wildcard to represent a single character. A wildcard can occur multiple times in a mask value and can occur anywhere in the value.
▪ The task wizard is case sensitive. Enter the object names or masks in the case with which the objects were defined.
▪ Do not include delimiters such as quotation marks or brackets, even if the source uses them.
▪ If an object name includes special characters such as a backslash (\), asterisk(*), dollar sign ($), caret (^), or question mark (?), escape each special character with a backslash (\) when you enter the rule.
dDefine additional rules as needed.
The rules are processed in the order in which they're listed, from top to bottom. Use the arrow icons to change the order.
eWhen finished, click Apply Rules.
Tip: Click the Refresh icon to the right of the Updated timestamp to refresh the Tables Affected and Total Tables Selected counts.
After you apply rules, if you add, delete, or change rules, you must click Apply Rules again. Click the Refresh icon to update the table counts. If you delete all rules without clicking Apply Rules, a validation error occurs at deployment, even if the Table View list still lists tables. If you switch to Select All, the rules no longer appear.
3To perform trim actions on the columns of the source tables that were selected based on rules, create column action rules.
Perform the following steps to create a column action rule:
aSelect Column Action as the rule type.
bFrom the adjacent list, select one of the following action types:
▪ LTRIM. Trims spaces to the left of character column values.
▪ RTRIM. Trims spaces to the right of character column values.
▪ TRIM. Trims spaces to the left of and to the right of character column values.
cIn the condition field, enter a column name or a column-name mask that includes one or more asterisk (*) or question mark (?) wildcards. The value that you enter is matched against columns of the selected source tables to identify the columns to which the action applies.
dClick Add Rule.
Note: You can define multiple rules for different action types or for the same action type with different conditions. The column action rules are processed in the order in which they are listed in the Rules list. The rule at the top of the list is processed first. You can use the arrow icons to change the order in which the rules are listed.
4Under Table View, view the selected tables, including the number of columns in each table.
- If you selected Select All, the list of tables is view only.
- If you applied rules, you can refine the set of selected tables by clicking the check box next to individual table. Deselect any report that you do not want to replicate, or select additional tables to replicate. Click the Refresh icon to update the selected tables count.
Note: The first time you change a check box setting for a table, the rules are no longer in effect. The selections under Table View take precedence. However, if you click the Add Rule (+) icon again, the tables that you deselected or selected individually are reflected as new rules in the Rules list and the rules once again take precedence. If you want to return to the Table View list, click Apply Rules again.
For each table, you can view a list of columns. Click the highlighted number of columns in Columns to list the fields to the right.
To search for tables and columns, in the drop-down list above Columns, select Table Name, Columns, or All and then enter a search string in the Find box and click Search. You can include a single asterisk (*) wildcard at the beginning or end of the string.
5To download a list of source tables that match the selection rules, perform the following steps:
aFrom the List Tables by Rule Type list, select the type of selection rule for which you want to download the list of selected source tables.
bIf you want to include the columns in the list, select Include Columns.
cClick the Download icon.
The list of source tables that match the selection rules is downloaded to your local drive.
The information in the downloaded file is in the following format:
status,table_name,table_type,column_name,comment
The following table describes the information in the downloaded file:
Field
Description
status
Indicates whether Application Ingestion and Replication includes or excludes the source table from processing. The possible values are:
- E. The table is excluded from processing by an Exclude rule.
- I. The table is included for processing.
- X. The table is excluded from processing even though it matches the selection rules. The comment field in the file provides details on why the table is excluded.
table_name
Name of the source table.
table_type
Type of the source object. The possible values are:
- O: Indicates a table.
- F: Indicates a column.
column_name
Name of the source column. This information appears only if you selected the Include Columns check box before downloading the list.
comment
Reason why a source table is excluded from processing even though it matches the selection rules.
6For incremental load tasks and combined initial and incremental load tasks, expand the Advanced section.
7For incremental load tasks, in the Initial Start Point for Incremental Load field, specify the point in the source data stream from which the ingestion job associated with the application ingestion and replication task starts extracting change records.
Note: You must specify the date and time in Coordinated Universal Time (UTC).
8For incremental load tasks and combined initial and incremental load tasks, in the CDC Interval field, specify the time interval in which the application ingestion and replication job runs to retrieve the change records for incremental load. The default interval is 5 minutes.
9In the Custom Properties section, you can specify custom properties that Informatica provides for special cases. To add a property, add the property name and value, and then click Add Property.
The custom properties are usually configured to address unique environments and special use cases.
Note: Specify the custom properties only at the direction of Informatica Global Customer Support.
10Click Next.
Configuring a NetSuite source
On the Source page of the application ingestion and replication task wizard, you can specify the tables that you want to ingest and configure the advanced properties for your NetSuite source. You can also specify custom properties to address unique environments and special use cases.
1In the Table Selection section, select Select All only if you want to select all source tables and columns for data replication. You cannot edit the selection in subsequent columns.
The Tables Selected field shows the count of all selected tables. If you have many source tables, the interface might take a long time to fetch them.
Alternatively, you can use rules to define a subset of source tables to replicate.
2To use rules to select the source objects, make sure that the Select All check box is cleared and then add rules.
When rule-based selection is used, you can refine the set of selected tables by table under Table View and also set an option for trimming spaces in character data.
Note: The default "Include *" rule selects all source tables accessed with the selected connection. To see how many tables are selected by this rule, click the Refresh icon to display the table count in Total Tables Selected and click Apply Rules to see the table count in Table View.
To add a rule:
aClick the Add Rule (+) icon above the first table under Rules. A row is added to define a new rule.
bIn the Table Rule column, select Include or Exclude to create an inclusion or exclusion rule, respectively.
cIn the Condition column, enter an object name or an object-name mask that includes one or more wildcards to identify the source objects to include in or exclude from object selection. Use the following guidelines:
▪ A mask can contain one or both of the following wildcards: an asterisk (*) wildcard to represent one or more characters and a question mark (?) wildcard to represent a single character. A wildcard can occur multiple times in a mask value and can occur anywhere in the value.
▪ The task wizard is case sensitive. Enter the object names or masks in the case with which the objects were defined.
▪ Do not include delimiters such as quotation marks or brackets, even if the source uses them.
▪ If an object name includes special characters such as a backslash (\), asterisk(*), dollar sign ($), caret (^), or question mark (?), escape each special character with a backslash (\) when you enter the rule.
dDefine additional rules as needed.
The rules are processed in the order in which they're listed, from top to bottom. Use the arrow icons to change the order.
eWhen finished, click Apply Rules.
Tip: Click the Refresh icon to the right of the Updated timestamp to refresh the Tables Affected and Total Tables Selected counts.
After you apply rules, if you add, delete, or change rules, you must click Apply Rules again. Click the Refresh icon to update the table counts. If you delete all rules without clicking Apply Rules, a validation error occurs at deployment, even if the Table View list still lists tables. If you switch to Select All, the rules no longer appear.
3To perform trim actions on the columns of the source tables that were selected based on rules, create column action rules.
Perform the following steps to create a column action rule:
aSelect Column Action as the rule type.
bFrom the adjacent list, select one of the following action types:
▪ LTRIM. Trims spaces to the left of character column values.
▪ RTRIM. Trims spaces to the right of character column values.
▪ TRIM. Trims spaces to the left of and to the right of character column values.
cIn the condition field, enter a column name or a column-name mask that includes one or more asterisk (*) or question mark (?) wildcards. The value that you enter is matched against columns of the selected source tables to identify the columns to which the action applies.
dClick Add Rule.
Note: You can define multiple rules for different action types or for the same action type with different conditions. The column action rules are processed in the order in which they are listed in the Rules list. The rule at the top of the list is processed first. You can use the arrow icons to change the order in which the rules are listed.
4Under Table View, view the selected tables, including the number of columns in each table.
- If you selected Select All, the list of tables is view only.
- If you applied rules, you can refine the set of selected tables by clicking the check box next to individual table. Deselect any report that you do not want to replicate, or select additional tables to replicate. Click the Refresh icon to update the selected tables count.
- For each table, you can view a list of columns. Click the highlighted number of columns in Columns to list the fields to the right.
- You can also individually clear or reselect the columns in a selected table. To view or change the columns from which data will be replicated for a selected table, click the highlighted number of columns under Columns. The column names and data types are displayed to the right. By default, all the fields are selected for a selected source object. To clear a column or reselect it, click the check box next to the column name. You can't clear a primary key column.
5To download a list of source tables that match the selection rules, perform the following steps:
aFrom the List Tables by Rule Type list, select the type of selection rule for which you want to download the list of selected source tables.
bIf you want to include the columns in the list, select Include Columns.
cClick the Download icon.
The list of source tables that match the selection rules is downloaded to your local drive.
The information in the downloaded file is in the following format:
status,table_name,table_type,column_name,comment
The following table describes the information in the downloaded file:
Field
Description
status
Indicates whether Application Ingestion and Replication includes or excludes the source table from processing. The possible values are:
- E. The table is excluded from processing by an Exclude rule.
- I. The table is included for processing.
- X. The table is excluded from processing even though it matches the selection rules. The comment field in the file provides details on why the table is excluded.
table_name
Name of the source table.
table_type
Type of the source object. The possible values are:
- O: Indicates a table.
- F: Indicates a column.
column_name
Name of the source column. This information appears only if you selected the Include Columns check box before downloading the list.
comment
Reason why a source table is excluded from processing even though it matches the selection rules.
6Expand the Advanced section.
7For incremental load tasks, in the Initial Start Point for Incremental Load field, specify the point in the source data stream from which the ingestion job associated with the application ingestion and replication task starts extracting change records.
Note: You must specify the date and time in Greenwich Mean Time (GMT).
8For incremental load tasks and combined initial and incremental load tasks, in the CDC Interval field, specify the time interval in which the application ingestion and replication job runs to retrieve the change records for incremental load. The default interval is 5 minutes.
9In the Fetch Size field, enter the number of records that the application ingestion and replication job associated with the task reads at a time from the source. Default is 5000.
10In the Custom Properties section, you can specify custom properties that Informatica provides for special cases. To add a property, add the property name and value, and then click Add Property.
The custom properties are usually configured to address unique environments and special use cases.
Note: Specify the custom properties only at the direction of Informatica Global Customer Support.
11Click Next.
Configuring an Oracle Fusion Cloud source
On the Source page of the application ingestion and replication task wizard, you can specify the objects that you want to ingest and configure the advanced properties for your Oracle Fusion Cloud source. You can also specify custom properties to address unique environments and special use cases.
1Select one of the following replication approaches:
- Select REST to extract data from various applications of Oracle Fusion such as ERP, SCM, HCM, Sales, and Services, and transfer data to the target.
- Select BICC (Business Intelligence Cloud Connector) to extract bulk data from the source to the target.
2From the Oracle Fusion Application list, select the application from which you want to replicate data.
3In the Object Selection section, select Select All only if you want to select all source objects and fields for data replication. You cannot edit the selection in subsequent fields.
The Objects Selected field shows the count of all selected objects. If you have many source objects, the interface might take a long time to fetch them.
Alternatively, you can use rules to define a subset of source objects to replicate.
4To use rules to select the source objects, make sure that the Select All check box is cleared and then add rules.
When rule-based selection is used, you can refine the set of selected objects by object under Object View and also set an option for trimming spaces in character data.
Note: The default "Include *" rule selects all source objects accessed with the selected connection. To see how many objects are selected by this rule, click the Refresh icon to display the object count in Total Objects Selected and click Apply Rules to see the object count in Object View.
To add a rule:
aClick the Add Rule (+) icon above the first table under Rules. A row is added to define a new rule.
bIn the Object Rule field, select Include or Exclude to create an inclusion or exclusion rule, respectively.
cIn the Condition column, enter an object name or an object-name mask that includes one or more wildcards to identify the source objects to include in or exclude from object selection. Use the following guidelines:
▪ A mask can contain one or both of the following wildcards: an asterisk (*) wildcard to represent one or more characters and a question mark (?) wildcard to represent a single character. A wildcard can occur multiple times in a mask value and can occur anywhere in the value.
▪ The task wizard is case sensitive. Enter the object names or masks in the case with which the objects were defined.
▪ Do not include delimiters such as quotation marks or brackets, even if the source uses them.
▪ If an object name includes special characters such as a backslash (\), asterisk(*), dollar sign ($), caret (^), or question mark (?), escape each special character with a backslash (\) when you enter the rule.
dDefine additional rules as needed.
The rules are processed in the order in which they're listed, from top to bottom. Use the arrow icons to change the order.
eWhen finished, click Apply Rules.
Tip: Click the Refresh icon to the right of the Updated timestamp to refresh the Objects Affected and Total Objects Selected counts.
After you apply rules, if you add, delete, or change rules, you must click Apply Rules again. Click the Refresh icon to update the object counts. If you delete all rules without clicking Apply Rules, a validation error occurs at deployment, even if the Object View list still lists objects. If you switch to Select All, the rules no longer appear.
5To perform trim actions on the fields of the source objects that were selected based on rules, create field action rules.
Perform the following steps to create a field action rule:
aSelect Field Action as the rule type.
bFrom the adjacent list, select one of the following action types:
▪ LTRIM. Trims spaces to the left of character field values.
▪ RTRIM. Trims spaces to the right of character field values.
▪ TRIM. Trims spaces to the left of and to the right of character field values.
cIn the condition field, enter a field name or a field-name mask that includes one or more asterisk (*) or question mark (?) wildcards. The value that you enter is matched against fields of the selected source objects to identify the fields to which the action applies.
dClick Add Rule.
Note: You can define multiple rules for different action types or for the same action type with different conditions. The field action rules are processed in the order in which they are listed in the Rules list. The rule at the top of the list is processed first. You can use the arrow icons to change the order in which the rules are listed.
6Under Object View, view the selected objects, including the number of fields in each object and the field names and data types.
- If you selected Select All, the list of objects is view only.
- If you applied rules, you can refine the set of selected objects by clicking the check box next to individual objects. Deselect any objects that you do not want to replicate, or select additional objects to replicate. Click the Refresh icon to update the selected objects count.
Note: The first time you change a check box setting for an object, the rules are no longer in effect. The selections under Object View take precedence. However, if you click the Add Rule (+) icon again, the objects that you deselected or selected individually are reflected as new rules in the Rules list and the rules once again take precedence. If you want to return to the Object View list, click Apply Rules again.
For each object, you can view a list of field names and data types. Click the highlighted number of fields in the Fields column to list the fields to the right.
To search for objects and fields, in the drop-down list above Fields, select Object Name, Fields, or All and then enter a search string in the Find box and click Search. You can include a single asterisk (*) wildcard at the beginning or end of the string.
7To download a list of source objects that match the selection rules, perform the following steps:
aFrom the List Objects by Rule Type list, select the type of selection rule for which you want to download the list of selected source objects.
bIf you want to include the fields in the list, select Include Fields.
cClick the Download icon.
The list of source objects that match the selection rules is downloaded to your local drive.
The information in the downloaded file is in the following format:
status,object_name,object_type,field_name,comment
The following table describes the information in the downloaded file:
Field
Description
status
Indicates whether Application Ingestion and Replication includes or excludes the source object from processing. The possible values are:
- E. The object is excluded from processing by an Exclude rule.
- I. The object is included for processing.
- X. The object is excluded from processing even though it matches the selection rules. The comment field in the file provides details on why the object is excluded.
object_name
Name of the source object.
object_type
Type of the source object. The possible values are:
- O: Indicates an object.
- F: Indicates a field.
field_name
Name of the source field. This information appears only if you selected the Include Fields check box before downloading the list.
comment
Reason why a source object is excluded from processing even though it matches the selection rules.
To search for tables and columns, you can either browse the list of objects or enter a search string in the Find box.
8Expand the Advanced section.
9For incremental load tasks, in the Initial Start Point for Incremental Load field, specify the point in the source data stream from which the ingestion job associated with the application ingestion and replication task starts extracting change records.
Note: You must specify the date and time in the time zone configured for the Oracle Fusion Cloud instance.
10For incremental load tasks and combined initial and incremental load tasks, in the CDC Interval field, specify the time interval in which the application ingestion and replication job runs to retrieve the change records for incremental load. The default interval is 5 minutes.
11Select the Include Child Objects option to get the child object data of an object using an Oracle Fusion Cloud source. This applies only for the REST replication approach and for all load types only when the target is Google Big Query.
12In the Fetch Size field, enter the number of records that the application ingestion and replication job associated with the task reads at a time from the source. The default value is 50000.
13In the Custom Properties section, you can specify custom properties that Informatica provides for special cases. To add a property, add the property name and value, and then click Add Property.
The custom properties are usually configured to address unique environments and special use cases.
Note: Specify the custom properties only at the direction of Informatica Global Customer Support.
14Click Next.
Configuring a Salesforce source
On the Source page of the application ingestion and replication task wizard, you can specify the objects that you want to ingest and configure the advanced properties for your Salesforce source. You can also specify custom properties to address unique environments and special use cases.
1For initial load tasks and combined initial and incremental load tasks, select the type of Salesforce API that you want to use to retrieve the source data.
Options are:
- Standard (REST) API: Replicates source fields of Base64 data type. Informatica recommends that you use the Bulk API 2.0 unless you want to ingest fields of Base64 data type or objects that are not supported by Bulk API 2.0 during initial loading of data. All incremental load activities use only the standard REST API.
- Bulk API 2.0: Excludes replication of source fields of Base64 data type. Bulk API 2.0 is the default API for initial load tasks and the initial load of the combined initial and incremental load tasks.
- Bulk API: Uses bulk API 1.0 for primary-key chunking to achieve parallel processing in Salesforce that optimizes the performance and speed of initial and combined initial and incremental load jobs. Use this option to handle large-scale data from Salesforce.
Note: By default, incremental load tasks can capture and replicate change data from source fields of Base64 data type.
2In the Object Selection section, select Select All only if you want to select all source objects and fields for data replication. You cannot edit the selection in subsequent fields.
The Objects Selected field shows the count of all selected objects. If you have many source objects, the interface might take a long time to fetch them.
Alternatively, you can use rules to define a subset of source objects to replicate.
3To use rules to select the source objects, make sure that the Select All check box is cleared and then add rules.
When rule-based selection is used, you can refine the set of selected objects by object under Object View and also set an option for trimming spaces in character data.
Note: The default "Include *" rule selects all source objects accessed with the selected connection. To see how many objects are selected by this rule, click the Refresh icon to display the object count in Total Objects Selected and click Apply Rules to see the object count in Object View.
To add a rule:
aClick the Add Rule (+) icon above the first table under Rules. A row is added to define a new rule.
bIn the Object Rule field, select Include or Exclude to create an inclusion or exclusion rule, respectively.
cIn the Condition column, enter an object name or an object-name mask that includes one or more wildcards to identify the source objects to include in or exclude from object selection. Use the following guidelines:
▪ A mask can contain one or both of the following wildcards: an asterisk (*) wildcard to represent one or more characters and a question mark (?) wildcard to represent a single character. A wildcard can occur multiple times in a mask value and can occur anywhere in the value.
▪ The task wizard is case sensitive. Enter the object names or masks in the case with which the objects were defined.
▪ Do not include delimiters such as quotation marks or brackets, even if the source uses them.
▪ If an object name includes special characters such as a backslash (\), asterisk(*), dollar sign ($), caret (^), or question mark (?), escape each special character with a backslash (\) when you enter the rule.
dDefine additional rules as needed.
The rules are processed in the order in which they're listed, from top to bottom. Use the arrow icons to change the order.
eWhen finished, click Apply Rules.
Tip: Click the Refresh icon to the right of the Updated timestamp to refresh the Objects Affected and Total Objects Selected counts.
After you apply rules, if you add, delete, or change rules, you must click Apply Rules again. Click the Refresh icon to update the object counts. If you delete all rules without clicking Apply Rules, a validation error occurs at deployment, even if the Object View list still lists objects. If you switch to Select All, the rules no longer appear.
4To perform trim actions on the fields of the source objects that were selected based on rules, create field action rules.
Perform the following steps to create a field action rule:
aSelect Field Action as the rule type.
bFrom the adjacent list, select one of the following action types:
▪ LTRIM. Trims spaces to the left of character field values.
▪ RTRIM. Trims spaces to the right of character field values.
▪ TRIM. Trims spaces to the left of and to the right of character field values.
cIn the condition field, enter a field name or a field-name mask that includes one or more asterisk (*) or question mark (?) wildcards. The value that you enter is matched against fields of the selected source objects to identify the fields to which the action applies.
dClick Add Rule.
5Under Object View, view the selected objects, including the number of fields in each object and the field names and data types.
- If you selected Select All, the list of objects are view only.
- If you applied rules, you can refine the set of selected objects by clicking the check box next to individual objects. Clear any objects that you do not want to replicate, or select additional objects to replicate. Click the Refresh icon to update the selected objects count.
- You can also individually clear or reselect the fields in a selected source object. To view or change the fields from which data will be replicated for a selected object, click the highlighted number of fields in the Fields column. The field names and data types are displayed to the right. By default, all the fields are selected for a selected source object. To clear a column or reselect it, click the check box next to the field name. You can't clear a primary key column.
6To download a list of source objects that match the selection rules, perform the following steps:
aFrom the List Objects by Rule Type list, select the type of selection rule for which you want to download the list of selected source objects.
bIf you want to include the fields in the list, select Include Fields.
cClick the Download icon.
The list of source objects that match the selection rules is downloaded to your local drive.
The information in the downloaded file is in the following format:
status,object_name,object_type,field_name,comment
The following table describes the information in the downloaded file:
Field
Description
status
Indicates whether Application Ingestion and Replication includes or excludes the source object from processing. The possible values are:
- E. The object is excluded from processing by an Exclude rule.
- I. The object is included for processing.
- X. The object is excluded from processing even though it matches the selection rules. The comment field in the file provides details on why the object is excluded.
object_name
Name of the source object.
object_type
Type of the source object. The possible values are:
- O: Indicates an object.
- F: Indicates a field.
field_name
Name of the source field. This information appears only if you selected the Include Fields check box before downloading the list.
comment
Reason why a source object is excluded from processing even though it matches the selection rules.
7Expand the Advanced section.
8For incremental load tasks, in the Initial Start Point for Incremental Load field, specify the point in the source data stream from which the ingestion job associated with the application ingestion and replication task starts extracting change records.
Note: You must specify the date and time in Greenwich Mean Time (GMT).
9For incremental load tasks and combined initial and incremental load tasks, in the CDC Interval field, specify the time interval in which the application ingestion and replication job runs to retrieve the change records for incremental load. The default interval is 5 minutes.
10In the Fetch Size field, enter the number of records that the application ingestion and replication job associated with the task reads at a time from the source. The default value for initial load operations is 50000 and the default value for incremental load operations is 2000.
Note: For combined initial and incremental load tasks, you must specify the fetch size separately for initial load operations and incremental load operations.
11For initial load and combined initial and incremental load tasks, select Include Archived and Deleted Rows to replicate the archived and soft-deleted rows from the source during the initial loading of data.
12For initial load and combined initial and incremental load tasks, select Enable Partitioning to partition the source objects for initial loading. In the Chunk Size field, enter the number of records to be processed in a single partition. Based on the chunk size, bulk jobs are created in Salesforce. The default value is 50000 and the minimum value is 100.
When you partition an object, the application ingestion and replication job processes the records for each partition in parallel. Application Ingestion and Replication determine the range of partitions by equal distribution of primary key values of an object.
Note: You can partition the objects only if you select Bulk API 2.0 as the Salesforce API.
13Select Include Base64 Fields to replicate the source fields of Base64 data type.
14If you selected the Include Base64 Fields check box, in the Maximum Base64 Body Size field, specify the body size for Base64 encoded data. The default body size for Base64 encoded data is 7 MB.
15In the Custom Properties section, you can specify custom properties that Informatica provides for special cases. To add a property, add the property name and value, and then click Add Property.
The custom properties are usually configured to address unique environments and special use cases.
Note: Specify the custom properties only at the direction of Informatica Global Customer Support.
16Click Next.
Configuring a Salesforce Marketing Cloud source
On the Source page of the application ingestion and replication task wizard, you can specify the objects that you want to ingest and configure the advanced properties for your Salesforce Marketing Cloud source. You can also specify custom properties to address unique environments and special use cases.
1In the MID field, enter the unique Member Identification code assigned to your Salesforce Marketing Cloud account.
2In the Object Selection section, select Select All only if you want to select all source objects and fields for data replication. You cannot edit the selection in subsequent fields.
The Objects Selected field shows the count of all selected objects. If you have many source objects, the interface might take a long time to fetch them.
Alternatively, you can use rules to define a subset of source objects to replicate.
3To use rules to select the source objects, make sure that the Select All check box is cleared and then add rules.
When rule-based selection is used, you can refine the set of selected objects by object under Object View and also set an option for trimming spaces in character data.
Note: The default "Include *" rule selects all source objects accessed with the selected connection. To see how many objects are selected by this rule, click the Refresh icon to display the object count in Total Objects Selected and click Apply Rules to see the object count in Object View.
To add a rule:
aClick the Add Rule (+) icon above the first table under Rules. A row is added to define a new rule.
bIn the Object Rule field, select Include or Exclude to create an inclusion or exclusion rule, respectively.
cIn the Condition column, enter an object name or an object-name mask that includes one or more wildcards to identify the source objects to include in or exclude from object selection. Use the following guidelines:
▪ A mask can contain one or both of the following wildcards: an asterisk (*) wildcard to represent one or more characters and a question mark (?) wildcard to represent a single character. A wildcard can occur multiple times in a mask value and can occur anywhere in the value.
▪ The task wizard is case sensitive. Enter the object names or masks in the case with which the objects were defined.
▪ Do not include delimiters such as quotation marks or brackets, even if the source uses them.
▪ If an object name includes special characters such as a backslash (\), asterisk(*), dollar sign ($), caret (^), or question mark (?), escape each special character with a backslash (\) when you enter the rule.
dDefine additional rules as needed.
The rules are processed in the order in which they're listed, from top to bottom. Use the arrow icons to change the order.
eWhen finished, click Apply Rules.
Tip: Click the Refresh icon to the right of the Updated timestamp to refresh the Objects Affected and Total Objects Selected counts.
After you apply rules, if you add, delete, or change rules, you must click Apply Rules again. Click the Refresh icon to update the object counts. If you delete all rules without clicking Apply Rules, a validation error occurs at deployment, even if the Object View list still lists objects. If you switch to Select All, the rules no longer appear.
4To perform trim actions on the fields of the source objects that were selected based on rules, create field action rules.
Perform the following steps to create a field action rule:
aSelect Field Action as the rule type.
bFrom the adjacent list, select one of the following action types:
▪ LTRIM. Trims spaces to the left of character field values.
▪ RTRIM. Trims spaces to the right of character field values.
▪ TRIM. Trims spaces to the left of and to the right of character field values.
cIn the condition field, enter a field name or a field-name mask that includes one or more asterisk (*) or question mark (?) wildcards. The value that you enter is matched against fields of the selected source objects to identify the fields to which the action applies.
dClick Add Rule.
5Under Object View, view the selected objects, including the number of fields in each object and the field names and data types.
- If you selected Select All, the list of objects is view only.
- If you applied rules, you can refine the set of selected objects by clicking the check box next to individual objects. Deselect any objects that you do not want to replicate, or select additional objects to replicate. Click the Refresh icon to update the selected objects count.
Note: The first time you change a check box setting for an object, the rules are no longer in effect. The selections under Object View take precedence. However, if you click the Add Rule (+) icon again, the objects that you deselected or selected individually are reflected as new rules in the Rules list and the rules once again take precedence. If you want to return to the Object View list, click Apply Rules again.
For each object, you can view a list of field names and data types. Click the highlighted number of fields in the Fields column to list the fields to the right.
To search for objects and fields, in the drop-down list above Fields, select Object Name, Fields, or All and then enter a search string in the Find box and click Search. You can include a single asterisk (*) wildcard at the beginning or end of the string.
6To download a list of source objects that match the selection rules, perform the following steps:
aFrom the List Objects by Rule Type list, select the type of selection rule for which you want to download the list of selected source objects.
bIf you want to include the fields in the list, select Include Fields.
cClick the Download icon.
The list of source objects that match the selection rules is downloaded to your local drive.
The information in the downloaded file is in the following format:
status,object_name,object_type,field_name,comment
The following table describes the information in the downloaded file:
Field
Description
status
Indicates whether Application Ingestion and Replication includes or excludes the source object from processing. The possible values are:
- E. The object is excluded from processing by an Exclude rule.
- I. The object is included for processing.
- X. The object is excluded from processing even though it matches the selection rules. The comment field in the file provides details on why the object is excluded.
object_name
Name of the source object.
object_type
Type of the source object. The possible values are:
- O: Indicates an object.
- F: Indicates a field.
field_name
Name of the source field. This information appears only if you selected the Include Fields check box before downloading the list.
comment
Reason why a source object is excluded from processing even though it matches the selection rules.
7Expand the Advanced section.
8In the Batch Size field, enter the number of records that the application ingestion and replication job associated with the task reads at a time from the source. Default is 2500.
9In the Custom Properties section, you can specify custom properties that Informatica provides for special cases. To add a property, add the property name and value, and then click Add Property.
The custom properties are usually configured to address unique environments and special use cases.
Note: Specify the custom properties only at the direction of Informatica Global Customer Support.
10Click Next.
Configuring an SAP source with SAP ODP Extractor connector
On the Source page of the application ingestion and replication task wizard, you can specify the data sources that you want to ingest, and configure the advanced properties for your SAP ECC or SAP S4/HANA source using the SAP ODP Extractor connector. You can also specify custom properties to address unique environments and special use cases.
1From the Context list, select the context containing the source data sources that you want to replicate on the target.
SAP ODP Extractor Connector supports the following ODP providers or contexts for all load types:
Providers/Context
Source SAP System and ODPs
SAP Service Application Programming Interface (S-API)
SAP Data Sources/Extractors without Enterprise Search (ESH)
HANA
SAP HANA Information View
BW
SAP NetWeaver Business Warehouse
ABAP_CDS
ABAP Core Data Services
SAP SLT
SLT Queue
2In the Data Source Selection section, select Select All only if you want to select all source reports for data replication. You cannot edit the selection in subsequent dimensions & metrics.
The Data Source Selected field shows the count of all selected reports. If you have many source reports, the interface might take a long time to fetch them.
Alternatively, you can use rules to define a subset of source reports to replicate.
3To use rules to select the data sources, make sure that the Select All check box is cleared and then add rules.
When rule-based selection is used, you can refine the set of selected data source by data source under Data Source View and also set an option for trimming spaces in character data.
Note: The default "Include *" rule selects all data source accessed with the selected connection. To see how many reports are selected by this rule, click the Refresh icon to display the report count in Total Data Source Selected and click Apply Rules to see the data source count in Data Source View.
To add a rule:
aClick the Add Rule (+) icon above the first data source under Rules. A row is added to define a new rule.
bIn the Data Source Rule column, select Include or Exclude to create an inclusion or exclusion rule, respectively.
cIn the condition field, enter a data source name or a data source-name mask to specify the data sources that you want to include in or exclude from the list of selected data sources.
dDefine additional rules as needed.
The rules are processed in the order in which they're listed, from top to bottom. Use the arrow icons to change the order.
eWhen finished, click Apply Rules.
Tip: Click the Refresh icon to the right of the Updated timestamp to refresh the Data Sources Affected and Total Data Sources Selected counts.
After you apply rules, if you add, delete, or change rules, you must click Apply Rules again. Click the Refresh icon to update the report counts. If you delete all rules without clicking Apply Rules, a validation error occurs at deployment, even if the Data Sources View list still lists reports. If you switch to Select All, the rules no longer appear.
4To perform trim actions on the fields of the data sources that were selected based on rules, create field action rules.
Perform the following steps to create a field action rule:
aSelect Field Action as the rule type.
bFrom the adjacent list, select one of the following action types:
▪ LTRIM. Trims spaces to the left of character field values.
▪ RTRIM. Trims spaces to the right of character field values.
▪ TRIM. Trims spaces to the left of and to the right of character field values.
cIn the condition field, enter a field name or a field-name mask that includes one or more asterisk (*) or question mark (?) wildcards. The value that you enter is matched against fields of the selected data sources to identify the fields to which the action applies.
dClick Add Rule.
Note: You can define multiple rules for different action types or for the same action type with different conditions. The field action rules are processed in the order in which they are listed in the Rules list. The rule at the top of the list is processed first. You can use the arrow icons to change the order in which the rules are listed.
5Under Data Source View, view the selected data sources, including the number of fields in each data source.
- If you selected Select All, the list of data sources is view only.
- If you applied rules, you can refine the set of selected data sources by clicking the check box next to individual data source. Deselect any data source that you do not want to replicate, or select additional data sources to replicate. Click the Refresh icon to update the selected data sources count.
Note: The first time you change a check box setting for a data source, the rules are no longer in effect. The selections under Data Source View take precedence. However, if you click the Add Rule (+) icon again, the data sources that you deselected or selected individually are reflected as new rules in the Rules list and the rules once again take precedence. If you want to return to the Data Source View list, click Apply Rules again.
For each data source, you can view a list of fields. Click the highlighted number of columns in the Fields column to list the fields to the right.
To search for data columns and fields, in the drop-down list above Fields, select Data Source Name, Fields, or All and then enter a search string in the Find box and click Search. You can include a single asterisk (*) wildcard at the beginning or end of the string.
6To download a list of data sources that match the selection rules, perform the following steps:
aFrom the List Data Sources by Rule Type list, select the type of selection rule for which you want to download the list of selected data sources.
bIf you want to include the fields in the list, select Include Fields.
cClick the Download icon.
The list of data sources that match the selection rules is downloaded to your local drive.
The information in the downloaded file is in the following format:
The following table describes the information in the downloaded file:
Field
Description
status
Indicates whether Application Ingestion and Replication includes or excludes the data source from processing. The possible values are:
- E. The data source is excluded from processing by an Exclude rule.
- I. The data source is included for processing.
- X. The data source is excluded from processing even though it matches the selection rules. The comment field in the file provides details on why the data source is excluded.
data source_name
Name of the data source.
data source_type
Type of the source object. The possible values are:
- O: Indicates a data source.
- F: Indicates a field.
field_name
Name of the source field. This information appears only if you selected the Include Fields check box before downloading the list.
comment
Reason why a data source is excluded from processing even though it matches the selection rules.
7Expand the Advanced section.
8For incremental load tasks, in the Initial Start Point for Incremental Load field, specify the point in the source data stream from which the ingestion job associated with the application ingestion and replication task starts extracting change records.
Note: By default, the ingestion job retrieves the change records from the latest available position in the data stream.
9For incremental load tasks and combined initial and incremental load tasks, in the CDC Interval field, specify the time interval in which the application ingestion and replication job runs to retrieve the change records for incremental load. The default interval is 5 minutes.
Note: The CDC interval must be less than the data retention period configured in the SAP system for the Operational Delta Queue (ODQ).
10In the Fetch Size field, enter the size of data that the application ingestion and replication job associated with the task reads at a time from the source. The value must be in megabytes (MB). The default value for initial load tasks is 2 and the default value for combined initial and incremental load tasks is 8.
11In the Custom Properties section, you can specify custom properties that Informatica provides for special cases. To add a property, add the property name and value, and then click Add Property.
The custom properties are usually configured to address unique environments and special use cases.
Note: Specify the custom properties only at the direction of Informatica Global Customer Support.
12Click Next.
Configuring an SAP source with SAP OData V2 connector
On the Source page of the application ingestion and replication task wizard, you can specify the tables that you want to ingest and configure the advanced properties for your SAP source. You can also specify custom properties to address unique environments and special use cases.
1In the OData Service Name field, select the OData service from where you want to retrieve data.
Based on the service type selected in your OData V2 connection, the list either shows the specific SAP service if you chose the default option, or display all available services on the SAP Gateway.
2In the Table Selection section, select Select All only if you want to select all source tables and columns for data replication. You cannot edit the selection in subsequent columns.
The Tables Selected field shows the count of all selected tables. If you have many source tables, the interface might take a long time to fetch them.
Alternatively, you can use rules to define a subset of source tables to replicate.
3To use rules to select the source objects, make sure that the Select All check box is cleared and then add rules.
When rule-based selection is used, you can refine the set of selected tables by table under Table View and also set an option for trimming spaces in character data.
Note: The default "Include *" rule selects all source tables accessed with the selected connection. To see how many tables are selected by this rule, click the Refresh icon to display the table count in Total Tables Selected and click Apply Rules to see the table count in Table View.
To add a rule:
aClick the Add Rule (+) icon above the first table under Rules. A row is added to define a new rule.
bIn the Table Rule column, select Include or Exclude to create an inclusion or exclusion rule, respectively.
cIn the Condition column, enter an object name or an object-name mask that includes one or more wildcards to identify the source objects to include in or exclude from object selection. Use the following guidelines:
▪ A mask can contain one or both of the following wildcards: an asterisk (*) wildcard to represent one or more characters and a question mark (?) wildcard to represent a single character. A wildcard can occur multiple times in a mask value and can occur anywhere in the value.
▪ The task wizard is case sensitive. Enter the object names or masks in the case with which the objects were defined.
▪ Do not include delimiters such as quotation marks or brackets, even if the source uses them.
▪ If an object name includes special characters such as a backslash (\), asterisk(*), dollar sign ($), caret (^), or question mark (?), escape each special character with a backslash (\) when you enter the rule.
dDefine additional rules as needed.
The rules are processed in the order in which they're listed, from top to bottom. Use the arrow icons to change the order.
eWhen finished, click Apply Rules.
Tip: Click the Refresh icon to the right of the Updated timestamp to refresh the Tables Affected and Total Tables Selected counts.
After you apply rules, if you add, delete, or change rules, you must click Apply Rules again. Click the Refresh icon to update the table counts. If you delete all rules without clicking Apply Rules, a validation error occurs at deployment, even if the Table View list still lists tables. If you switch to Select All, the rules no longer appear.
4To perform trim actions on the columns of the source tables that were selected based on rules, create column action rules.
Perform the following steps to create a column action rule:
aSelect Column Action as the rule type.
bFrom the adjacent list, select one of the following action types:
▪ LTRIM. Trims spaces to the left of character column values.
▪ RTRIM. Trims spaces to the right of character column values.
▪ TRIM. Trims spaces to the left of and to the right of character column values.
cIn the condition field, enter a column name or a column-name mask that includes one or more asterisk (*) or question mark (?) wildcards. The value that you enter is matched against columns of the selected source tables to identify the columns to which the action applies.
dClick Add Rule.
Note: You can define multiple rules for different action types or for the same action type with different conditions. The column action rules are processed in the order in which they are listed in the Rules list. The rule at the top of the list is processed first. You can use the arrow icons to change the order in which the rules are listed.
5Under Table View, view the selected tables, including the number of columns in each table.
- If you selected Select All, the list of tables is view only.
- If you applied rules, you can refine the set of selected tables by clicking the check box next to individual table. Deselect any report that you do not want to replicate, or select additional tables to replicate. Click the Refresh icon to update the selected tables count.
Note: The first time you change a check box setting for a table, the rules are no longer in effect. The selections under Table View take precedence. However, if you click the Add Rule (+) icon again, the tables that you deselected or selected individually are reflected as new rules in the Rules list and the rules once again take precedence. If you want to return to the Table View list, click Apply Rules again.
For each table, you can view a list of columns. Click the highlighted number of columns in Columns to list the fields to the right.
To search for tables and columns, in the drop-down list above Columns, select Table Name, Columns, or All and then enter a search string in the Find box and click Search. You can include a single asterisk (*) wildcard at the beginning or end of the string.
6To download a list of source tables that match the selection rules, perform the following steps:
aFrom the List Tables by Rule Type list, select the type of selection rule for which you want to download the list of selected source tables.
bIf you want to include the columns in the list, select Include Columns.
cClick the Download icon.
The list of source tables that match the selection rules is downloaded to your local drive.
The information in the downloaded file is in the following format:
status,table_name,table_type,column_name,comment
The following table describes the information in the downloaded file:
Field
Description
status
Indicates whether Application Ingestion and Replication includes or excludes the source table from processing. The possible values are:
- E. The table is excluded from processing by an Exclude rule.
- I. The table is included for processing.
- X. The table is excluded from processing even though it matches the selection rules. The comment field in the file provides details on why the table is excluded.
table_name
Name of the source table.
table_type
Type of the source object. The possible values are:
- O: Indicates a table.
- F: Indicates a column.
column_name
Name of the source column. This information appears only if you selected the Include Columns check box before downloading the list.
comment
Reason why a source table is excluded from processing even though it matches the selection rules.
7Expand the Advanced section.
8For incremental load tasks, in the Initial Start Point for Incremental Load field, specify the point in the source data stream from which the ingestion job associated with the application ingestion and replication task starts extracting change records.
Note: You must specify the date and time in Greenwich Mean Time (GMT).
9For incremental load tasks and combined initial and incremental load tasks, in the CDC Interval field, specify the time interval in which the application ingestion and replication job runs to retrieve the change records for incremental load. The default interval is 5 minutes.
10In the Fetch Size field, enter the number of records that the application ingestion and replication job associated with the task reads at a time from the source. Default is 50000.
Note: For combined initial and incremental load tasks, you must specify the fetch size separately for initial load operations and incremental load operations.
11In the Custom Properties section, you can specify custom properties that Informatica provides for special cases. To add a property, add the property name and value, and then click Add Property.
The custom properties are usually configured to address unique environments and special use cases.
Note: Specify the custom properties only at the direction of Informatica Global Customer Support.
12Click Next.
Configuring an SAP source with SAP Mass Ingestion connector
On the Source page of the application ingestion and replication task wizard, you can specify the tables that you want to ingest for your SAP ECC source using the SAP Mass Ingestion connector. You can also specify custom properties to address unique environments and special use cases.
1In the Table Selection section, select Select All only if you want to select all source tables and columns for data replication. You cannot edit the selection in subsequent columns.
The Tables Selected field shows the count of all selected tables. If you have many source tables, the interface might take a long time to fetch them.
Alternatively, you can use rules to define a subset of source tables to replicate.
2To use rules to select the source objects, make sure that the Select All check box is cleared and then add rules.
When rule-based selection is used, you can refine the set of selected tables by table under Table View and also set an option for trimming spaces in character data.
To add a rule:
aClick the Add Rule (+) icon above the first table under Rules. A row is added to define a new rule.
bIn the Table Rule column, select Include or Exclude to create an inclusion or exclusion rule, respectively.
cIn the Condition column, enter an object name or an object-name mask that includes one or more wildcards to identify the source objects to include in or exclude from object selection. Use the following guidelines:
▪ A mask can contain one or both of the following wildcards: an asterisk (*) wildcard to represent one or more characters and a question mark (?) wildcard to represent a single character. A wildcard can occur multiple times in a mask value and can occur anywhere in the value.
▪ The task wizard is case sensitive. Enter the object names or masks in the case with which the objects were defined.
▪ Do not include delimiters such as quotation marks or brackets, even if the source uses them.
▪ If an object name includes special characters such as a backslash (\), asterisk(*), dollar sign ($), caret (^), or question mark (?), escape each special character with a backslash (\) when you enter the rule.
dDefine additional rules as needed.
The rules are processed in the order in which they're listed, from top to bottom. Use the arrow icons to change the order.
eWhen finished, click Apply Rules.
Tip: Click the Refresh icon to the right of the Updated timestamp to refresh the Tables Affected and Total Tables Selected counts.
After you apply rules, if you add, delete, or change rules, you must click Apply Rules again. Click the Refresh icon to update the table counts. If you delete all rules without clicking Apply Rules, a validation error occurs at deployment, even if the Table View list still lists tables. If you switch to Select All, the rules no longer appear.
3To perform trim actions on the columns of the source tables that were selected based on rules, create column action rules.
Perform the following steps to create a column action rule:
aSelect Column Action as the rule type.
bFrom the adjacent list, select one of the following action types:
▪ LTRIM. Trims spaces to the left of character column values.
▪ RTRIM. Trims spaces to the right of character column values.
▪ TRIM. Trims spaces to the left of and to the right of character column values.
cIn the condition field, enter a column name or a column-name mask that includes one or more asterisk (*) or question mark (?) wildcards. The value that you enter is matched against columns of the selected source tables to identify the columns to which the action applies.
dClick Add Rule.
Note: You can define multiple rules for different action types or for the same action type with different conditions. The column action rules are processed in the order in which they are listed in the Rules list. The rule at the top of the list is processed first. You can use the arrow icons to change the order in which the rules are listed.
4Under Table View, view the selected tables, including the number of columns in each table.
- If you selected Select All, the list of tables is view only.
- If you applied rules, you can refine the set of selected tables by clicking the check box next to individual table. Deselect any report that you do not want to replicate, or select additional tables to replicate. Click the Refresh icon to update the selected tables count.
- For each table, you can view a list of columns. Click the highlighted number of columns in Columns to list the fields to the right.
- You can also individually clear or reselect the columns in a selected table. To view or change the columns from which data will be replicated for a selected table, click the highlighted number of columns under Columns. The column names and data types are displayed to the right. By default, all the fields are selected for a selected source object. To clear a column or reselect it, click the check box next to the column name. You can't clear a primary key column.
5 To download a list of source objects that match the selection rules, perform the following steps:
aFrom the List Tables by Rule Type list, select the type of selection rule for which you want to download the list of selected tables.
bInclude the columns in the list, select Include Columns.
cClick the download icon.
The list of source objects that match the selection rules is downloaded to your local drive.
The information in the downloaded file is in the following format:
status,object_name,object_type,field_name,comment
The following table describes the information in the downloaded file:
Field
Description
status
Indicates whether Application Ingestion and Replication includes or excludes the source object from processing. The possible values are:
- E. The object is excluded from processing by an Exclude rule.
- I. The object is included for processing.
- X. The object is excluded from processing even though it matches the selection rules. The comment field in the file provides details on why the object is excluded.
table_name
Name of the table.
- O. Indicates a table.
- F. Indicates a column.
- V. Indicates a view.
table_type
Type of the table. The possible values are:
field_name
Name of the source field. This information appears only if you selected the Include Columns check box before downloading the list.
comment
Reason why a table is excluded from processing even though it matches the selection rules.
6In the Custom Properties section, you can specify custom properties that Informatica provides for special cases. To add a property, add the property name and value, and then click Add Property. The custom properties are usually configured to address unique environments and special use cases.
Note: Specify the custom properties only at the direction of Informatica Global Customer Support.
7 For incremental load tasks, in the Schema field, enter the underlying database schema that includes the source tables. Perform the following steps to enter the schema value:
aLog in to the SAP application.
bBrowse to System > Status.
cCheck the Owner value. Enter this value in the Schema field.
8If you are defining an incremental load task that has an SAP source and one or more of the selected source tables are not enabled for change data capture, you can generate a script for enabling CDC, and then run or download the script.
aIn the CDC Script field, select Enable CDC for all columns. This enables CDC for all columns in the selected source tables.
bTo run the script, click Execute.
If you don't have a database role or privilege that allows you to run the script, click the download icon to download the script. The script file name uses the following format: cdc_script_taskname_number.txt. Then, ask your database administrator to run the script.
Make sure the script runs before you run the database ingestion task.
9To create and download a list of the source tables that match the table selection criteria, perform the following substeps:
aIf you used rule-based table selection, in the Tables Name list, select the type of selection rules that you want to use. The options are:
▪ Include Rules Only
▪ Exclude Rules Only
▪ Include And Exclude Rules
bTo list the columns, regardless of the table selection method that you used, select the Include Columns check box.
cClick the download icon.
The downloaded list that includes columns uses the following format:
The following table describes the information that is displayed in the downloaded list:
Field
Description
status
Indicates whether Application Ingestion and Replication excludes the source table or column from processing because it has an unsupported type. Valid values are:
- E. The object is excluded from processing by an Exclude rule.
- I. The object is included in processing.
- X. The object is excluded from processing because it is an unsupported type of object. For example, unsupported types of objects include columns with unsupported data types and tables that include only unsupported columns. The comment field provides information about the unsupported types.
schema_name
Specifies the name of the source schema.
table_name
Specifies the name of the source table.
object_type
Specifies the type of the source object. Valid values are:
- C. Column.
- T. Table.
column_name
Specifies the name of the source column. This information appears only if you selected the Columns check box.
comment
Specifies the reason why a source object of an unsupported type is excluded from processing even though it matches the selection rules.
10Under Advanced, set the advanced properties that are available for your source type and load type.
Property
Source and Load Type
Description
Enable Persistent Storage
SAP source with SAP Mass Ingestion connector - incremental load and combined initial and incremental loads
Select this check box to enable persistent storage of transaction data in a disk buffer so that the data can be consumed continually, even when the writing of data to the target is slow or delayed.
Benefits of using persistent storage are faster consumption of the source transaction logs, less reliance on log archives or backups, and the ability to still access the data persisted in disk storage after restarting an ingestion job.
Initial Start Point for Incremental Load
SAP source with SAP Mass Ingestion connector - incremental load
Set this field to customize the position in the source logs from which the application ingestion and replication job starts reading change records the first time it runs.
The Latest Available option provides the latest available position in the database log or structure.
11Click Next.
Schema change handling
You can choose how the SAP Mass Ingestion connector handles schema changes that you make to some data object types.
Schema change handling for an SAP S4 HANA source
By default, if you make changes to the schema, the SAP Mass Ingestion connector detects the schema changes and generates an alert message.
Note: You can disable the schema detection using a custom property. For more information, contact Informatica Global Customer Support.
A schema change includes one or more of the following changes to the data object:
- Fields are added
- Fields are deleted
- Fields are renamed
- Field data type, precision, or scale is updated
You can handle the schema changes based on the following conditions:
- If you make a schema change to the data object while an incremental load job is in the Up and Running status, the SAP Mass Ingestion connector generates an alert message. When the alert appears, the processing of the data object stops, and you must create a new initial job with the changed data object. Run the new incremental job after the initial job completes successfully.
- If you make a schema change to the data object while an incremental load job is in the Stopped status, you must drop the trigger and the shadow table on the data object where the changes were made. Activate the data object through the SAP user interface and create a new initial job with the updated data object. After the initial job completes successfully, run the new incremental job.
Note: Run the incremental job immediately after the initial job completes successfully to prevent data loss.
Schema change handling for an SAP ECC source
If you make schema changes to the data object, the processing of the data object stops, and the SAP Mass Ingestion connector generates an alert message. Further changes to the data object are not captured.
A schema change includes one or more of the following changes to the data object:
- Fields are added
- Fields are deleted
- Fields are renamed
- Field data type, precision, or scale is updated
You can handle the schema changes based on the following conditions:
- If you make a schema change to the data object for a combined load job, the SAP Mass Ingestion connector generates an alert message. You can then resynchronize the data object.
- If you make a schema change to the data object for an incremental load job, you must create and run an initial job with the changed data object. After the initial job completes successfully, run the new incremental job with the changed data object.
Note: Run the incremental job immediately after the initial job completes successfully to prevent data loss.
Configuring a ServiceNow source
On the Source page of the application ingestion and replication task wizard, you can specify the tables that you want to ingest and configure the advanced properties for your ServiceNow source. You can also specify custom properties to address unique environments and special use cases.
1In the Table Selection section, select Select All only if you want to select all source tables and columns for data replication. You cannot edit the selection in subsequent columns.
The Tables Selected field shows the count of all selected tables. If you have many source tables, the interface might take a long time to fetch them.
Alternatively, you can use rules to define a subset of source tables to replicate.
2To use rules to select the source objects, make sure that the Select All check box is cleared and then add rules.
When rule-based selection is used, you can refine the set of selected tables by table under Table View and also set an option for trimming spaces in character data.
Note: The default "Include *" rule selects all source tables accessed with the selected connection. To see how many tables are selected by this rule, click the Refresh icon to display the table count in Total Tables Selected and click Apply Rules to see the table count in Table View.
To add a rule:
aClick the Add Rule (+) icon above the first table under Rules. A row is added to define a new rule.
bIn the Table Rule column, select Include or Exclude to create an inclusion or exclusion rule, respectively.
cIn the Condition column, enter an object name or an object-name mask that includes one or more wildcards to identify the source objects to include in or exclude from object selection. Use the following guidelines:
▪ A mask can contain one or both of the following wildcards: an asterisk (*) wildcard to represent one or more characters and a question mark (?) wildcard to represent a single character. A wildcard can occur multiple times in a mask value and can occur anywhere in the value.
▪ The task wizard is case sensitive. Enter the object names or masks in the case with which the objects were defined.
▪ Do not include delimiters such as quotation marks or brackets, even if the source uses them.
▪ If an object name includes special characters such as a backslash (\), asterisk(*), dollar sign ($), caret (^), or question mark (?), escape each special character with a backslash (\) when you enter the rule.
dDefine additional rules as needed.
The rules are processed in the order in which they're listed, from top to bottom. Use the arrow icons to change the order.
eWhen finished, click Apply Rules.
Tip: Click the Refresh icon to the right of the Updated timestamp to refresh the Tables Affected and Total Tables Selected counts.
After you apply rules, if you add, delete, or change rules, you must click Apply Rules again. Click the Refresh icon to update the table counts. If you delete all rules without clicking Apply Rules, a validation error occurs at deployment, even if the Table View list still lists tables. If you switch to Select All, the rules no longer appear.
3To perform trim actions on the columns of the source tables that were selected based on rules, create column action rules.
Perform the following steps to create a column action rule:
aSelect Column Action as the rule type.
bFrom the adjacent list, select one of the following action types:
▪ LTRIM. Trims spaces to the left of character column values.
▪ RTRIM. Trims spaces to the right of character column values.
▪ TRIM. Trims spaces to the left of and to the right of character column values.
cIn the condition field, enter a column name or a column-name mask that includes one or more asterisk (*) or question mark (?) wildcards. The value that you enter is matched against columns of the selected source tables to identify the columns to which the action applies.
dClick Add Rule.
Note: You can define multiple rules for different action types or for the same action type with different conditions. The column action rules are processed in the order in which they are listed in the Rules list. The rule at the top of the list is processed first. You can use the arrow icons to change the order in which the rules are listed.
4Under Table View, view the selected tables, including the number of columns in each table.
- If you selected Select All, the list of tables is view only.
- If you applied rules, you can refine the set of selected tables by clicking the check box next to individual table. Deselect any report that you do not want to replicate, or select additional tables to replicate. Click the Refresh icon to update the selected tables count.
Note: The first time you change a check box setting for a table, the rules are no longer in effect. The selections under Table View take precedence. However, if you click the Add Rule (+) icon again, the tables that you deselected or selected individually are reflected as new rules in the Rules list and the rules once again take precedence. If you want to return to the Table View list, click Apply Rules again.
For each table, you can view a list of columns. Click the highlighted number of columns in Columns to list the fields to the right.
To search for tables and columns, in the drop-down list above Columns, select Table Name, Columns, or All and then enter a search string in the Find box and click Search. You can include a single asterisk (*) wildcard at the beginning or end of the string.
5To download a list of source tables that match the selection rules, perform the following steps:
aFrom the List Tables by Rule Type list, select the type of selection rule for which you want to download the list of selected source tables.
bIf you want to include the columns in the list, select Include Columns.
cClick the Download icon.
The list of source tables that match the selection rules is downloaded to your local drive.
The information in the downloaded file is in the following format:
status,table_name,table_type,column_name,comment
The following table describes the information in the downloaded file:
Field
Description
status
Indicates whether Application Ingestion and Replication includes or excludes the source table from processing. The possible values are:
- E. The table is excluded from processing by an Exclude rule.
- I. The table is included for processing.
- X. The table is excluded from processing even though it matches the selection rules. The comment field in the file provides details on why the table is excluded.
table_name
Name of the source table.
table_type
Type of the source object. The possible values are:
- O: Indicates a table.
- F: Indicates a column.
column_name
Name of the source column. This information appears only if you selected the Include Columns check box before downloading the list.
comment
Reason why a source table is excluded from processing even though it matches the selection rules.
6For incremental load tasks, in the Initial Start Point for Incremental Load field, specify the point in the source data stream from which the ingestion job associated with the application ingestion and replication task starts extracting change records.
Note: You must specify the date and time in Greenwich Mean Time (GMT).
7For incremental load tasks and combined initial and incremental load tasks, in the CDC Interval field, specify the time interval in which the application ingestion and replication job runs to retrieve the change records for incremental load. The default interval is 5 minutes.
8In the Fetch Size field, enter the number of records that the application ingestion and replication job associated with the task reads at a time from the source. Default is 10000.
9In the Custom Properties section, you can specify custom properties that Informatica provides for special cases. To add a property, add the property name and value, and then click Add Property.
The custom properties are usually configured to address unique environments and special use cases.
Note: Specify the custom properties only at the direction of Informatica Global Customer Support.
10Click Next.
Configuring a Workday source
On the Source page of the application ingestion and replication task wizard, you can specify the operations that you want to ingest and configure the advanced properties for your Workday source. You can also specify custom properties to address unique environments and special use cases.
1From the Workday API list, select the type of web service that you want to use to read source data.
Options are:
- SOAP: Uses SOAP APIs to extract Workday data.
- RaaS: Uses Workday Report-as-a-Service (RaaS) to extract source data from custom objects and fields through custom reports. You can use Workday RaaS only in initial load tasks.
2If you choose to use the SOAP API, perform the following steps:
aFrom the Product list, select Human Capital Management.
bFrom the Services list, select the Human Capital Management (HCM) services from which you want to ingest data to your target
You can select multiple services from the Services list.
cFrom the Output Type list, select the format in which you want the data to be stored on the target.
The ingestion jobs extract the source data in an XML structure. Based on the format that you select, the job writes the extracted data to the target as a single object in either JSON or XML format.
3If you choose to use the RaaS API, perform the following steps:
aIn the Number of Reports field, select the number of reports you want to extract from the source.
bIf you choose to extract a single report, in the Report Name or URL field, enter the name or URL of the custom report you want to read from the source.
cIf you choose to extract multiple reports, in the Report Configuration File field, enter the path to the CSV file that you created for the list of custom reports that you want to read from the source.
4In the Operation Selection section, select Select All only if you want to select all operations for data replication. You cannot edit the selection in subsequent operations.
The Operation Selected field shows the count of all selected operations. If you have many source operations, the interface might take a long time to fetch them.
Alternatively, you can use rules to define a subset of source operations to replicate.
5To use rules to select the source operations, make sure that the Select All check box is cleared and then add rules.
When rule-based selection is used, you can refine the set of selected operation by operation under Operation View and also set an option for trimming spaces in character data.
Note: The default "Include *" rule selects all operation accessed with the selected connection. To see how many operations are selected by this rule, click the Refresh icon to display the operation count in Total Operations Selected and click Apply Rules to see the operation count in Operation View.
To add a rule:
aClick the Add Rule (+) icon above the first operation under Rules. A row is added to define a new rule.
bIn the Operation Rule column, select Include or Exclude to create an inclusion or exclusion rule, respectively.
cIn the condition field, enter an operation name to specify the operations that you want to include in or exclude from the list of selected operation sources.
dDefine additional rules as needed.
The rules are processed in the order in which they're listed, from top to bottom. Use the arrow icons to change the order.
eWhen finished, click Apply Rules.
Tip: Click the Refresh icon to the right of the Updated timestamp to refresh the Operations Affected and Total Operations Selected counts.
After you apply rules, if you add, delete, or change rules, you must click Apply Rules again. Click the Refresh icon to update the operation counts. If you delete all rules without clicking Apply Rules, a validation error occurs at deployment, even if the Operations View list still lists operations. If you switch to Select All, the rules no longer appear.
6Under Operation View, view the selected operations, including the number of attributes in each operation.
- If you selected Select All, the list of operations is view only.
- If you applied rules, you can refine the set of selected operations by clicking the check box next to individual operation. Deselect any operation that you do not want to replicate, or select additional operations to replicate. Click the Refresh icon to update the selected operations count.
Note: The first time you change a check box setting for an operation, the rules are no longer in effect. The selections under Operation View take precedence. However, if you click the Add Rule (+) icon again, the operations that you deselected or selected individually are reflected as new rules in the Rules list and the rules once again take precedence. If you want to return to the Operation View list, click Apply Rules again.
For each operation, you can view a list of attributes. Click the highlighted number of attributes in the Attributes column to list the attributes to the right.
To search for operations and atributes, in the drop-down list above Attributes, select Operation Name, Attributes, or All and then enter a search string in the Find box and click Search. You can include a single asterisk (*) wildcard at the beginning or end of the string.
7To download a list of source operations that match the selection rules, perform the following steps:
aFrom the List Operations by Rule Type list, select the type of selection rule for which you want to download the list of selected source operations.
bClick the Download icon.
The list of source operations that match the selection rules is downloaded to your local drive.
The information in the downloaded file is in the following format:
status,operation_name,operation_type,comment
The following table describes the information in the downloaded file:
Field
Description
status
Indicates whether Application Ingestion and Replication includes or excludes the source operation from processing. The possible values are:
- E. The operation is excluded from processing by an Exclude rule.
- I. The operation is included for processing.
- X. The operation is excluded from processing even though it matches the selection rules. The comment field in the file provides details on why the operation is excluded.
operation_name
Name of the source operation.
operation_type
Type of the source object. The value O in this field indicates that the object is an operation.
comment
Reason why a source operation is excluded from processing even though it matches the selection rules.
8For incremental load tasks, in the Initial Start Point for Incremental Load field, specify the point in the source data stream from which the ingestion job associated with the application ingestion and replication task starts extracting change records.
Note: You must specify the date and time in Coordinated Universal Time (UTC).
9For incremental load tasks and combined initial and incremental load tasks, in the CDC Interval field, specify the time interval in which the application ingestion and replication job runs to retrieve the change records for incremental load. The default interval is 5 minutes.
10In the Fetch Size field, enter the number of records that the application ingestion and replication job associated with the task reads at a time from the source. Default is 100.
Note: The Fetch Size field appears only for the SOAP API.
11Select the Extract Non-default Fields check box to replicate the source fields that do not contain any default value.
Note: The Extract Non-default Fields check box appears only for the SOAP API.
12In the Custom Properties section, you can specify custom properties that Informatica provides for special cases. To add a property, add the property name and value, and then click Add Property.
The custom properties are usually configured to address unique environments and special use cases.
Note: Specify the custom properties only at the direction of Informatica Global Customer Support.
13Click Next.
Configuring a Zendesk source
On the Source page of the application ingestion and replication task wizard, you can specify the objects that you want to ingest and configure the advanced properties for your Zendesk source. You can also specify custom properties to address unique environments and special use cases.
1In the Object Selection section, select Select All only if you want to select all source objects and fields for data replication. You cannot edit the selection in subsequent fields.
The Objects Selected field shows the count of all selected objects. If you have many source objects, the interface might take a long time to fetch them.
Alternatively, you can use rules to define a subset of source objects to replicate.
2To use rules to select the source objects, make sure that the Select All check box is cleared and then add rules.
When rule-based selection is used, you can refine the set of selected objects by object under Object View and also set an option for trimming spaces in character data.
Note: The default "Include *" rule selects all source objects accessed with the selected connection. To see how many objects are selected by this rule, click the Refresh icon to display the object count in Total Objects Selected and click Apply Rules to see the object count in Object View.
To add a rule:
aClick the Add Rule (+) icon above the first table under Rules. A row is added to define a new rule.
bIn the Object Rule field, select Include or Exclude to create an inclusion or exclusion rule, respectively.
cIn the Condition column, enter an object name or an object-name mask that includes one or more wildcards to identify the source objects to include in or exclude from object selection. Use the following guidelines:
▪ A mask can contain one or both of the following wildcards: an asterisk (*) wildcard to represent one or more characters and a question mark (?) wildcard to represent a single character. A wildcard can occur multiple times in a mask value and can occur anywhere in the value.
▪ The task wizard is case sensitive. Enter the object names or masks in the case with which the objects were defined.
▪ Do not include delimiters such as quotation marks or brackets, even if the source uses them.
▪ If an object name includes special characters such as a backslash (\), asterisk(*), dollar sign ($), caret (^), or question mark (?), escape each special character with a backslash (\) when you enter the rule.
dDefine additional rules as needed.
The rules are processed in the order in which they're listed, from top to bottom. Use the arrow icons to change the order.
eWhen finished, click Apply Rules.
Tip: Click the Refresh icon to the right of the Updated timestamp to refresh the Objects Affected and Total Objects Selected counts.
After you apply rules, if you add, delete, or change rules, you must click Apply Rules again. Click the Refresh icon to update the object counts. If you delete all rules without clicking Apply Rules, a validation error occurs at deployment, even if the Object View list still lists objects. If you switch to Select All, the rules no longer appear.
3To perform trim actions on the fields of the source objects that were selected based on rules, create field action rules.
Perform the following steps to create a field action rule:
aSelect Field Action as the rule type.
bFrom the adjacent list, select one of the following action types:
▪ LTRIM. Trims spaces to the left of character field values.
▪ RTRIM. Trims spaces to the right of character field values.
▪ TRIM. Trims spaces to the left of and to the right of character field values.
cIn the condition field, enter a field name or a field-name mask that includes one or more asterisk (*) or question mark (?) wildcards. The value that you enter is matched against fields of the selected source objects to identify the fields to which the action applies.
dClick Add Rule.
Note: You can define multiple rules for different action types or for the same action type with different conditions. The field action rules are processed in the order in which they are listed in the Rules list. The rule at the top of the list is processed first. You can use the arrow icons to change the order in which the rules are listed.
4Under Object View, view the selected objects, including the number of fields in each object and the field names and data types.
- If you selected Select All, the list of objects is view only.
- If you applied rules, you can refine the set of selected objects by clicking the check box next to individual objects. Deselect any objects that you do not want to replicate, or select additional objects to replicate. Click the Refresh icon to update the selected objects count.
Note: The first time you change a check box setting for an object, the rules are no longer in effect. The selections under Object View take precedence. However, if you click the Add Rule (+) icon again, the objects that you deselected or selected individually are reflected as new rules in the Rules list and the rules once again take precedence. If you want to return to the Object View list, click Apply Rules again.
For each object, you can view a list of field names and data types. Click the highlighted number of fields in the Fields column to list the fields to the right.
To search for objects and fields, in the drop-down list above Fields, select Object Name, Fields, or All and then enter a search string in the Find box and click Search. You can include a single asterisk (*) wildcard at the beginning or end of the string.
5To download a list of source objects that match the selection rules, perform the following steps:
aFrom the List Objects by Rule Type list, select the type of selection rule for which you want to download the list of selected source objects.
bIf you want to include the fields in the list, select Include Fields.
cClick the Download icon.
The list of source objects that match the selection rules is downloaded to your local drive.
The information in the downloaded file is in the following format:
status,object_name,object_type,field_name,comment
The following table describes the information in the downloaded file:
Field
Description
status
Indicates whether Application Ingestion and Replication includes or excludes the source object from processing. The possible values are:
- E. The object is excluded from processing by an Exclude rule.
- I. The object is included for processing.
- X. The object is excluded from processing even though it matches the selection rules. The comment field in the file provides details on why the object is excluded.
object_name
Name of the source object.
object_type
Type of the source object. The possible values are:
- O: Indicates an object.
- F: Indicates a field.
field_name
Name of the source field. This information appears only if you selected the Include Fields check box before downloading the list.
comment
Reason why a source object is excluded from processing even though it matches the selection rules.
6For incremental load tasks and combined initial and incremental load tasks, expand the Advanced section.
7For incremental load tasks, in the Initial Start Point for Incremental Load field, specify the point in the source data stream from which the ingestion job associated with the application ingestion and replication task starts extracting change records.
Note: You must specify the date and time in Coordinated Universal Time (UTC).
8For incremental load tasks and combined initial and incremental load tasks, in the CDC Interval field, specify the time interval in which the application ingestion and replication job runs to retrieve the change records for incremental load. The default interval is 5 minutes.
9In the Custom Properties section, you can specify custom properties that Informatica provides for special cases. To add a property, add the property name and value, and then click Add Property.
The custom properties are usually configured to address unique environments and special use cases.
Note: Specify the custom properties only at the direction of Informatica Global Customer Support.
10Click Next.
Example of rules for selecting source objects
When you define a source for an application ingestion and replication task, you can define object selection rules to select the source objects that you want to load to the target. The following example demonstrates how you can use selection rules to select the required objects.
Example
A source has 1,000 objects with different prefixes. You want to select the objects that have the prefix "2021_SALES" and all objects with other prefixes except "2021_".
Define the following rules in the order in which they are listed:
•Rule 1: Rule Action=Include and Condition=* includes all objects on the source. When only the asterisk (*) wildcard is specified, all objects on the source are selected.
•Rule 2: Rule Action=Exclude and Condition=2021_* excludes the source objects that have names with the prefix "2021_".
•Rule 3: Rule Action=Include and Condition=2021_SALES* includes the source objects that have names with the prefix "2021_SALES".
The following image shows the rules in the Object Selection Rules section of the Source page:
Configuring the target
You can configure the target on the Target page of the application ingestion and replication task wizard.
Before you configure the target, ensure that the connection to the target is created in Administrator for the runtime environment that your organization uses.
1From the Connection list, select the connection configured for the source application. The connection type appears in parentheses after the connection name.
The list includes only the connections that are valid for the load type that you selected on the Definition page.
Note: After you deploy the ingestion task, you cannot change the connection without undeploying the associated ingestion job. After you change the connection, you must deploy the task again.
2Configure the target properties.
For descriptions of the target properties, see the following topics:
3If you want to rename the target objects that are associated with the selected source objects, define table renaming rules in the Table Renaming Rules section.
4If you want to override the default mappings of source data types to target data types, define custom data-type mapping rules in the Data Type Rules section.
5In the Custom Properties section, you can specify custom properties that Informatica provides for special cases. To add a property, click the Add Property icon, and then add the property name and value.
The custom properties are configured to address unique environments and special use cases.
Note: Specify the custom properties only at the direction of Informatica Global Customer Support.
6Click Next.
Renaming tables on the target
When you configure a target with an existing schema, you can optionally define rules for renaming the target tables that correspond to the selected source objects.
To create a rule for renaming tables, perform the following steps in the Table Renaming Rules section:
1In the Create Rule fields, enter the name of the source object that you want to rename and then enter the name that you want to assign to the target table corresponding to the object.
2Click Add Rule.
The rule is created and appears in the rules list.
You can define multiple table renaming rules. Unless a table matches multiple rules, the order in which the rules are processed does not depend on the order in which they are listed in the Table Renaming Rules section. If a table matches multiple rules, the last matching rule determines the name of the table.
To delete a rule, click the Delete icon on the row that contains the rule.
Example
You want to add the prefix "PROD_" to the names of target tables that are associated with all selected source objects. In the Table Renaming Rules section, enter the following values in the Create Rule fields:
•For the source, enter the asterisk (*) wildcard character to specify all the source objects that match the object selection rules defined on the Source page.
•For the target, enter PROD_* to add this prefix to the names of all target tables corresponding to the source objects.
Customizing data-type mappings
When you configure a target for an application ingestion and replication task, you can optionally define data-type mapping rules to override the default mappings of source data types to target data types.
For example, you can create a data-type rule that maps Salesforce ID fields that have no precision to Snowflake target NUMBER() columns that also have no precision, instead of using the default mapping to the Snowflake CHAR(72) data type.
To create a data-type mapping rule:
1Expand Data Type Rules.
2In the Create Rule fields, enter a source data type and the target data type that you want to map it to.
In the Source field, you can include the percent (%) wildcard to represent the data type precision, scale, or size, for example, NUMBER(%,4), NUMBER(8,%), or NUMBER(%). Use the wildcard to cover all source fields that have the same data type but use different precision, scale, or size values, instead of specifying each one individually. For example, enter FLOAT(%) to cover FLOAT(16), FLOAT(32), and FLOAT(84). You cannot enter the % wildcard in the target data type. A source data type that uses the % wildcard must map to a target data type that uses specific precision, scale, or size value. For example, you could map the source data type FLOAT(%) to a target data type specification such as NUMBER(38,10).
Note: Application Ingestion and Replication does not support the BYTE and CHAR semantics in data-type mappings rules.
3Click Add Rule.
The rule appears in the list of rules.
Notes:
•If a source data type has a default value, you must specify it in your rule. For example, you must use TIMESTAMP(6) instead of TIMESTAMP.
•You can define multiple data-type mapping rules for a target. However, you should define only one rule for a source data type. If you define multiple data-type rules for the same source data type with the same length or same precision and scale values, you will not be able to save the application ingestion and replication task.
•If you define multiple data-type rules for the same source data type but use the % wildcard to represent the length or precision and scale value in one rule and a specific length or precision and scale value in the second rule, the rule that contains the specific value is processed first, before the rule with the % wildcard. For example, if you map the source data types FLOAT(84) and FLOAT(%), the FLOAT(84) rule is processed first and then the FLOAT(%) rule is processed to cover any other FLOAT source columns with different sizes.
•After you deploy a task with custom mapping rules, you cannot edit the rules until the task is undeployed.
•In general, binary data types cannot be mapped to character data types.
•If a source data type requires a length or precision and scale value, make sure that you set the required attribute by using the % wildcard or a specific value, for example, VARCHAR(%) or VARCHAR(10).
•If you define an invalid mapping, an error message is written to the log.
Amazon Redshift target properties
When you define an application ingestion and replication task, you must specify the properties for your Amazon Redshift target on the Target page of the task wizard.
The following table describes the Amazon Redshift target properties that appear in Target section:
Property
Description
Target Creation
The only available option is Create Target Tables, which generates the target tables based on the source objects.
Schema
Select the target schema in which Application Ingestion and Replication creates the target tables.
Bucket
Specifies the name of the Amazon S3 bucket that stores, organizes, and controls access to the data objects that you load to Amazon Redshift.
Data Directory or Task Target Directory
Specifies the subdirectory where Application Ingestion and Replication stores output files for jobs associated with the task. This field is called Data Directory for an initial load job or Task Target Directory for an incremental load or combined initial and incremental load job.
The following table describes advanced target properties that appear under Advanced:
Property
Description
Add Cycle ID
Select this check box to add a metadata column that includes the cycle ID of each CDC cycle in each target table. A cycle ID is a number that's generated by the CDC engine for each successful CDC cycle. If you integrate the job with Data Integration taskflows, the job can pass the minimum and maximum cycle IDs in output fields to the taskflow so that the taskflow can determine the range of cycles that contain new CDC data. This capability is useful if data from multiple cycles accumulates before the previous taskflow run completes. By default, this check box is not selected.
Prefix for Metadata Columns
Add a prefix to the names of the added metadata columns to easily identify them and to prevent conflicts with the names of existing columns.
The default value is INFA_.
Enable Case Transformation
By default, target table names and column names are generated in the same case as the corresponding source names, unless cluster-level or session-level properties on the target override this case-sensitive behavior. If you want to control the case of letters in the target names, select this check box. Then select a Case Transformation Strategy option.
Case Transformation Strategy
If you selected Enable Case Transformation, select one of the following options to specify how to handle the case of letters in generated target table (or object) names and column (or field) names:
- Same as source. Use the same case as the source table (or object) names and column (or field) names.
- UPPERCASE. Use all uppercase.
- lowercase. Use all lowercase.
The default value is Same as source.
Note: The selected strategy will override any cluster-level or session-level properties on the target for controlling case.
Amazon S3 target properties
When you define an application ingestion and replication task, you must specify the properties for your Amazon S3 target on the Target page of the task wizard.
The following table describes the Amazon S3 target properties that appear in Target section:
Property
Description
Output Format
Select the format of the output file. Options are:
- CSV
- AVRO
- PARQUET
The default value is CSV.
Note: Output files in CSV format use double-quotation marks ("") as the delimiter for each field.
Add Headers to CSV File
If CSV is selected as the output format, select this check box to add a header with source column names to the output CSV file.
Parquet Compression Type
If the PARQUET output format is selected, you can select a compression type that is supported by Parquet. Options are:
- None
- Gzip
- Snappy
The default value is None, which means no compression is used.
Avro Format
If you selected AVRO as the output format, select the format of the Avro schema that will be created for each source table. Options are:
- Avro-Flat. This Avro schema format lists all Avro fields in one record.
- Avro-Generic. This Avro schema format lists all columns from a source table in a single array of Avro fields.
- Avro-Nested. This Avro schema format organizes each type of information in a separate record.
The default value is Avro-Flat.
Avro Serialization Format
If AVRO is selected as the output format, select the serialization format of the Avro output file. Options are:
- None
- Binary
- JSON
The default value is Binary.
Avro Schema Directory
If AVRO is selected as the output format, specify the local directory where Application Ingestion and Replication stores Avro schema definitions for each source table. Schema definition files have the following naming pattern:
schemaname_tablename.txt
Note: If this directory is not specified, no Avro schema definition file is produced.
File Compression Type
Select a file compression type for output files in CSV or AVRO output format. Options are:
- None
- Deflate
- Gzip
- Snappy
The default value is None, which means no compression is used.
Encryption type
Select the encryption type for the Amazon S3 files when you write the files to the target. Options are:
- None
- Client Side Encryption
- Client Side Encryption with KMS
- Server Side Encryption
- Server Side Encryption with KMS
The default is None, which means no encryption is used.
Avro Compression Type
If AVRO is selected as the output format, select an Avro compression type. Options are:
- None
- Bzip2
- Deflate
- Snappy
The default value is None, which means no compression is used.
Deflate Compression Level
If Deflate is selected in the Avro Compression Type field, specify a compression level from 0 to 9. The default value is 0.
Add Directory Tags
For incremental load and combined initial and incremental load tasks, select this check box to add the "dt=" prefix to the names of apply cycle directories to be compatible with the naming convention for Hive partitioning. This check box is cleared by default.
Task Target Directory
For incremental load and combined initial and incremental load tasks, the root directory for the other directories that hold output data files, schema files, and CDC cycle contents and completed files. You can use it to specify a custom root directory for the task. If you enable the Connection Directory as Parent option, you can still optionally specify a task target directory to use with the parent directory specified in the connection properties.
This field is required if the {TaskTargetDirectory} placeholder is specified in patterns for any of the following directory fields.
Data Directory
For initial load tasks, define a directory structure for the directories where Application Ingestion and Replication stores output data files and optionally stores the schema. To define directory pattern, you can use the following types of entries:
- The placeholders {SchemaName}, {TableName), {Timestamp}, {YY}, {YYYY}, {MM}, and {DD}, where {YY}, {YYYY}, {MM}, and {DD} are for date elements. The {Timestamp} values are in the format yyyymmdd_hhmissms. The generated dates and times in the directory paths indicate when the initial load job starts to transfer data to the target.
- Specific directory names.
- The toUpper() and toLower() functions, which force the values for an associated (placeholder) to uppercase or lowercase.
The default directory pattern is {TableName)_{Timestamp}.
For incremental load and combined initial and incremental load tasks, define a custom path to the subdirectory that contains the cdc-data data files. To define the directory pattern, you can use the following types of entries:
- The placeholders {TaskTargetDirectory}, {SchemaName}, {TableName), {Timestamp}, {YY}, {YYYY}, {MM}, and {DD}, where {YY}, {YYYY}, {MM}, and {DD} are for date elements. The {Timestamp} values are in the format yyyymmdd_hhmissms. The generated dates and times in the directory paths indicate when the CDC cycle started.
If you include the toUpper or toLower function, put the placeholder name in parentheses and enclose the both the function and placeholder in curly brackets, as shown in the preceding example.
- Specific directory names.
The default directory pattern is {TaskTargetDirectory}/data/{TableName}/data
Note: For Amazon S3 and Microsoft Azure Data Lake Storage Gen2 targets, Application Ingestion and Replication uses the directory specified in the target connection properties as the root for the data directory path when Connection Directory as Parent is selected. For Google Cloud Storage targets, Application Ingestion and Replication uses the Bucket name that you specify in the target properties for the ingestion task. For Microsoft Fabric OneLake targets, the parent directory is the path specified in the Lakehouse Path field in the Microsoft Fabric OneLake connection properties.
Connection Directory as Parent
Select this check box to use the directory value that is specified in the target connection properties as the parent directory for the custom directory paths specified in the task target properties. For initial load tasks, the parent directory is used in the Data Directory and Schema Directory. For incremental load and combined initial and incremental load tasks, the parent directory is used in the Data Directory, Schema Directory, Cycle Completion Directory, and Cycle Contents Directory.
This check box is selected by default. If you clear it, for initial loads, define the full path to the output files in the Data Directory field. For incremental loads, optionally specify a root directory for the task in the Task Target Directory.
Schema Directory
Specify a custom directory in which to store the schema file if you want to store it in a directory other than the default directory. For initial loads, previously used values if available are shown in a drop-down list for your convenience. This field is optional.
For initial loads, the schema is stored in the data directory by default. For incremental loads and combined initial and incremental loads, the default directory for the schema file is {TaskTargetDirectory}/data/{TableName}/schema
You can use the same placeholders as for the Data Directory field. Ensure that you enclose placeholders with curly brackets { }.
If you include the toUpper or toLower function, put the placeholder name in parentheses and enclose the both the function and placeholder in curly brackets, for example: {toLower(SchemaName)}
Note: Schema is written only to output data files in CSV format. Data files in Parquet and Avro formats contain their own embedded schema.
Cycle Completion Directory
For incremental load and combined initial and incremental load tasks, the path to the directory that contains the cycle completed file. Default is {TaskTargetDirectory}/cycle/completed.
Cycle Contents Directory
For incremental load and combined initial and incremental load tasks, the path to the directory that contains the cycle contents files. Default is {TaskTargetDirectory}/cycle/contents.
Use Cycle Partitioning for Data Directory
For incremental load and combined initial and incremental load tasks, causes a timestamp subdirectory to be created for each CDC cycle, under each data directory.
If this option is not selected, individual data files are written to the same directory without a timestamp, unless you define an alternative directory structure.
Use Cycle Partitioning for Summary Directories
For incremental load and combined initial and incremental load tasks, causes a timestamp subdirectory to be created for each CDC cycle, under the summary contents and completed subdirectories.
List Individual Files in Contents
For incremental load and combined initial and incremental load tasks, lists individual data files under the contents subdirectory.
If Use Cycle Partitioning for Summary Directories is cleared, this option is selected by default. All of the individual files are listed in the contents subdirectory unless you can configure custom subdirectories by using the placeholders, such as for timestamp or date.
If Use Cycle Partitioning for Data Directory is selected, you can still optionally select this check box to list individual files and group them by CDC cycle.
The following table describes the Amazon S3 advanced target properties that appear in Advanced section:
Property
Description
Add Operation Type
Select this check box to add a metadata column that records the source SQL operation type in the output that the job propagates to the target.
For incremental loads, the job writes "I" for insert, "U" for update, or "D" for delete. For initial loads, the job always writes "I" for insert.
By default, this check box is selected for incremental load and initial and incremental load jobs, and cleared for initial load jobs.
Add Operation Time
Select this check box to add a metadata column that records the source SQL operation timestamp in the output that the job propagates to the target.
For initial loads, the job always writes the current date and time.
By default, this check box is not selected.
Add Before Images
Select this check box to include UNDO data in the output that a job writes to the target.
For initial loads, the job writes nulls.
By default, this check box is not selected.
Databricks target properties
When you define an application ingestion and replication task, you must specify the properties for your Databricks target on the Target page of the task wizard.
The following table describes the Databricks target properties that appear in Target section:
Property
Description
Target Creation
The only available option is Create Target Tables, which generates the target tables based on the source objects.
Schema
Select the target schema in which Application Ingestion and Replication creates the target tables.
Apply Mode
For incremental load and combined initial and incremental load jobs, indicates how source DML changes, including inserts, updates, and deletes, are applied to the target. Options are:
- Standard. Accumulate the changes in a single apply cycle and intelligently merge them into fewer SQL statements before applying them to the target. For example, if an update followed by a delete occurs on the source row, no row is applied to the target. If multiple updates occur on the same column or field, only the last update is applied to the target. If multiple updates occur on different columns or fields, the updates are merged into a single update record before being applied to the target.
- Soft Deletes. Apply source delete operations to the target as soft deletes. A soft delete marks the deleted row as deleted without actually removing it from the database. For example, a delete on the source results in a change record on the target with "D" displayed in the INFA_OPERATION_TYPE column.
After enabling Soft Deletes, any update in the source table during normal or backlog mode results in the deletion of the matching record, insertion of the updated record, and marking of the INFA_OPERATION_TYPE operation as NULL in the target table. Similarly, inserting a record in the source table during backlog mode results in marking the INFA_OPERATION_TYPE operation as E in the target table record.
Consider using soft deletes if you have a long-running business process that needs the soft-deleted data to finish processing, to restore data after an accidental delete operation, or to track deleted values for audit purposes.
- Audit. Apply an audit trail of every DML operation made on the source tables to the target. A row for each DML change on a source table is written to the generated target table along with the audit columns you select under the Advanced section. The audit columns contain metadata about the change, such as the DML operation type, transaction ID, and before image. Consider using Audit apply mode when you want to use the audit history to perform downstream computations or processing on the data before writing it to the target database or when you want to examine metadata about the captured changes.
After enabling the Audit apply mode, any update in the source table during backlog or normal mode results in marking the INFA_OPERATION_TYPE operation as E in the target table record. Similarly, inserting a record in the source table during backlog mode results in marking the INFA_OPERATION_TYPE operation as E in the target table record.
Default is Standard.
Data Directory or Task Target Directory
Specifies the subdirectory where Application Ingestion and Replication stores output files for jobs associated with the task. This field is called Data Directory for an initial load job or Task Target Directory for an incremental load or combined initial and incremental load job.
Under Advanced, you can enter the following advanced target properties:
Property
Description
Add Operation Type
Select this check box to add a metadata column that records the source SQL operation type in the output that the job propagates to the target database or inserts into the target table.
This field is available only when the Apply Mode option is set to Audit or Soft Deletes.
In Audit mode, the job writes "I" for inserts, "U" for updates, "E" for upserts, or "D" for deletes to this metadata column.
In Soft Deletes mode, the job writes "D" for deletes or NULL for inserts and updates. When the operation type is NULL, the other "Add Operation..." metadata columns are also NULL. Only when the operation type is "D" will the other metadata columns contain non-null values.
By default, this check box is selected.
Add Operation Time
Select this check box to add a metadata column that records the source SQL operation timestamp in the output that the job propagates to the target.
By default, this check box is not selected.
Add Operation Sequence
Select this check box to add a metadata column that records a generated, ascending sequence number for each change operation that the job inserts into the target tables. The sequence number reflects the change stream position of the operation.
By default, this check box is not selected.
Add Before Images
Select this check box to include UNDO data in the output that a job writes to the target.
By default, this check box is not selected.
Prefix for Metadata Columns
Add a prefix to the names of the added metadata columns to easily identify them and to prevent conflicts with the names of existing columns.
The default value is INFA_.
Create Unmanaged Tables
Select this check box if you want the task to create Databricks target tables as unmanaged tables. After you deploy the task, you cannot edit this field to switch to managed tables.
By default, this option is cleared and managed tables are created.
If you selected either Personal Staging Location or Volume in the Staging Environment field in the selected Databricks target connection, this check box is disabled. You cannot use unmanaged tables in this situation.
For more information about Databricks managed and unmanaged tables, see the Databricks documentation.
Unmanaged Tables Parent Directory
If you choose to create Databricks unmanaged tables, you must specify a parent directory in Amazon S3 or Microsoft Azure Data Lake Storage to hold the Parquet files that are generated for each target table when captured DML records are processed.
Note: To use Unity Catalog, you must provide an existing external directory.
Staging File Format
Select the format of the staging files in the staging environment specified in the Databricks connection. The files hold data before it's loaded into Databricks tables.
Format options are:
- CSV
- Parquet
Default is CSV.
Google BigQuery target properties
When you define an application ingestion and replication task, you must specify the properties for your Google BigQuery target on the Target page of the task wizard.
The following table describes the Google BigQuery target properties that appear in the Target section:
Property
Description
Target Creation
The only available option is Create Target Tables, which generates the target tables based on the source objects.
Schema
Select the target schema in which Application Ingestion and Replication creates the target tables.
Apply Mode
For incremental load and combined initial and incremental load jobs, indicates how source DML changes, including inserts, updates, and deletes, are applied to the target. Options are:
- Standard. Accumulate the changes in a single apply cycle and intelligently merge them into fewer SQL statements before applying them to the target. For example, if an update followed by a delete occurs on the source row, no row is applied to the target. If multiple updates occur on the same column or field, only the last update is applied to the target. If multiple updates occur on different columns or fields, the updates are merged into a single update record before being applied to the target.
- Audit. Apply an audit trail of every DML operation made on the source tables to the target. A row for each DML change on a source table is written to the generated target table along with the audit columns you select under the Advanced section. The audit columns contain metadata about the change, such as the DML operation type, time, owner, transaction ID, generated ascending sequence number, and before image. Consider using Audit apply mode when you want to use the audit history to perform downstream computations or processing on the data before writing it to the target database or when you want to examine metadata about the captured changes.
- Soft Deletes. Apply source delete operations to the target as soft deletes. A soft delete marks the deleted row as deleted without actually removing it from the database. For example, a delete on the source results in a change record on the target with "D" displayed in the INFA_OPERATION_TYPE column.
Consider using soft deletes if you have a long-running business process that needs the soft-deleted data to finish processing, to restore data after an accidental delete operation, or to track deleted values for audit purposes.
Note: If you use Soft Deletes mode, you must not perform an update on the primary key in a source table. Otherwise, data corruption can occur on the target.
The default value is Standard.
Bucket
Specifies the name of an existing bucket container that stores, organizes, and controls access to the data objects that you load to Google Cloud Storage.
Data Directory or Task Target Directory
Specifies the subdirectory where Application Ingestion and Replication stores output files for jobs associated with the task. This field is called Data Directory for an initial load job or Task Target Directory for an incremental load or combined initial and incremental load job.
The following table describes the Google BigQuery target properties that appear in the Advanced section:
Property
Description
Add Last Replicated Time
Select this check box to add a metadata column that records the timestamp at which a record was inserted or last updated in the target table. For initial loads, all loaded records have the same timestamp. For incremental and combined initial and incremental loads, the column records the timestamp of the last DML operation that was applied to the target.
By default, this check box is not selected.
Add Operation Type
Select this check box to add a metadata column that records the source SQL operation type in the output that the job propagates to the target database or inserts into the audit table on the target system.
This field is available only when the Apply Mode option is set to Audit or Soft Deletes.
In Audit mode, the job writes "I" for inserts, "U" for updates, "E" for upserts, or "D" for deletes to this metadata column.
In Soft Deletes mode, the job writes "D" for deletes or NULL for inserts, updates, and upserts. When the operation type is NULL, the other "Add Operation..." metadata columns are also NULL. Only when the operation type is "D" will the other metadata columns contain non-null values.
By default, this check box is selected. You cannot deselect it if you are using soft deletes.
Add Operation Time
Select this check box to add a metadata column that records the source SQL operation timestamp in the output that the job propagates to the target tables.
This field is available only when Apply Mode is set to Audit or Soft Deletes.
By default, this check box is not selected.
Add Operation Sequence
Select this check box to add a metadata column that records a generated, ascending sequence number for each change operation that the job inserts into the target tables. The sequence number reflects the change stream position of the operation.
This field is displayed only when the Apply Mode option is set to Audit.
By default, this check box is not selected.
Add Before Images
Select this check box to add _OLD columns with UNDO "before image" data in the output that the job inserts into the target tables. You can then compare the old and current values for each data column. For a delete operation, the current value will be null.
This field is displayed only when the Apply Mode option is set to Audit.
By default, this check box is not selected.
Prefix for Metadata Columns
Add a prefix to the names of the added metadata columns to easily identify them and to prevent conflicts with the names of existing columns.
Do not include special characters in the prefix. Otherwise, task deployment will fail.
The default value is INFA_.
Enable Case Transformation
By default, target table names and column names are generated in the same case as the corresponding source names, unless cluster-level or session-level properties on the target override this case-sensitive behavior. If you want to control the case of letters in the target names, select this check box. Then select a Case Transformation Strategy option.
Case Transformation Strategy
If you selected Enable Case Transformation, select one of the following options to specify how to handle the case of letters in generated target table (or object) names and column (or field) names:
- Same as source. Use the same case as the source table (or object) names and column (or field) names.
- UPPERCASE. Use all uppercase.
- lowercase. Use all lowercase.
The default value is Same as source.
Note: The selected strategy will override any cluster-level or session-level properties on the target for controlling case.
Google Cloud Storage target properties
When you define an application ingestion and replication task, you must specify the properties for your Google Cloud Storage target on the Target page of the task wizard.
The following table describes the Google Cloud Storage target properties that appear in Target section:
Property
Description
Output Format
Select the format of the output file. Options are:
- CSV
- AVRO
- PARQUET
The default value is CSV.
Note: Output files in CSV format use double-quotation marks ("") as the delimiter for each field.
Add Headers to CSV File
If CSV is selected as the output format, select this check box to add a header with source column names to the output CSV file.
Parquet Compression Type
If the PARQUET output format is selected, you can select a compression type that is supported by Parquet. Options are:
- None
- Gzip
- Snappy
The default value is None, which means no compression is used.
Avro Format
If you selected AVRO as the output format, select the format of the Avro schema that will be created for each source table. Options are:
- Avro-Flat. This Avro schema format lists all Avro fields in one record.
- Avro-Generic. This Avro schema format lists all columns from a source table in a single array of Avro fields.
- Avro-Nested. This Avro schema format organizes each type of information in a separate record.
The default value is Avro-Flat.
Avro Serialization Format
If AVRO is selected as the output format, select the serialization format of the Avro output file. Options are:
- None
- Binary
- JSON
The default value is Binary.
Avro Schema Directory
If AVRO is selected as the output format, specify the local directory where Application Ingestion and Replication stores Avro schema definitions for each source table. Schema definition files have the following naming pattern:
schemaname_tablename.txt
Note: If this directory is not specified, no Avro schema definition file is produced.
File Compression Type
Select a file compression type for output files in CSV or AVRO output format. Options are:
- None
- Deflate
- Gzip
- Snappy
The default value is None, which means no compression is used.
Avro Compression Type
If AVRO is selected as the output format, select an Avro compression type. Options are:
- None
- Bzip2
- Deflate
- Snappy
The default value is None, which means no compression is used.
Deflate Compression Level
If Deflate is selected in the Avro Compression Type field, specify a compression level from 0 to 9. The default value is 0.
Add Directory Tags
For incremental load and combined initial and incremental load tasks, select this check box to add the "dt=" prefix to the names of apply cycle directories to be compatible with the naming convention for Hive partitioning. This check box is cleared by default.
Bucket
Specifies the name of an existing bucket container that stores, organizes, and controls access to the data objects that you load to Google Cloud Storage.
Task Target Directory
For incremental load and combined initial and incremental load tasks, the root directory for the other directories that hold output data files, schema files, and CDC cycle contents and completed files. You can use it to specify a custom root directory for the task. If you enable the Connection Directory as Parent option, you can still optionally specify a task target directory to use with the parent directory specified in the connection properties.
This field is required if the {TaskTargetDirectory} placeholder is specified in patterns for any of the following directory fields.
Data Directory
For initial load tasks, define a directory structure for the directories where Application Ingestion and Replication stores output data files and optionally stores the schema. To define directory pattern, you can use the following types of entries:
- The placeholders {SchemaName}, {TableName), {Timestamp}, {YY}, {YYYY}, {MM}, and {DD}, where {YY}, {YYYY}, {MM}, and {DD} are for date elements. The {Timestamp} values are in the format yyyymmdd_hhmissms. The generated dates and times in the directory paths indicate when the initial load job starts to transfer data to the target.
- Specific directory names.
- The toUpper() and toLower() functions, which force the values for an associated (placeholder) to uppercase or lowercase.
The default directory pattern is {TableName)_{Timestamp}.
For incremental load and combined initial and incremental load tasks, define a custom path to the subdirectory that contains the cdc-data data files. To define the directory pattern, you can use the following types of entries:
- The placeholders {TaskTargetDirectory}, {SchemaName}, {TableName), {Timestamp}, {YY}, {YYYY}, {MM}, and {DD}, where {YY}, {YYYY}, {MM}, and {DD} are for date elements. The {Timestamp} values are in the format yyyymmdd_hhmissms. The generated dates and times in the directory paths indicate when the CDC cycle started.
If you include the toUpper or toLower function, put the placeholder name in parentheses and enclose the both the function and placeholder in curly brackets, as shown in the preceding example.
- Specific directory names.
The default directory pattern is {TaskTargetDirectory}/data/{TableName}/data
Note: For Amazon S3 and Microsoft Azure Data Lake Storage Gen2 targets, Application Ingestion and Replication uses the directory specified in the target connection properties as the root for the data directory path when Connection Directory as Parent is selected. For Google Cloud Storage targets, Application Ingestion and Replication uses the Bucket name that you specify in the target properties for the ingestion task. For Microsoft Fabric OneLake targets, the parent directory is the path specified in the Lakehouse Path field in the Microsoft Fabric OneLake connection properties.
Schema Directory
Specify a custom directory in which to store the schema file if you want to store it in a directory other than the default directory. For initial loads, previously used values if available are shown in a drop-down list for your convenience. This field is optional.
For initial loads, the schema is stored in the data directory by default. For incremental loads and combined initial and incremental loads, the default directory for the schema file is {TaskTargetDirectory}/data/{TableName}/schema
You can use the same placeholders as for the Data Directory field. Ensure that you enclose placeholders with curly brackets { }.
If you include the toUpper or toLower function, put the placeholder name in parentheses and enclose the both the function and placeholder in curly brackets, for example: {toLower(SchemaName)}
Note: Schema is written only to output data files in CSV format. Data files in Parquet and Avro formats contain their own embedded schema.
Cycle Completion Directory
For incremental load and combined initial and incremental load tasks, the path to the directory that contains the cycle completed file. Default is {TaskTargetDirectory}/cycle/completed.
Cycle Contents Directory
For incremental load and combined initial and incremental load tasks, the path to the directory that contains the cycle contents files. Default is {TaskTargetDirectory}/cycle/contents.
Use Cycle Partitioning for Data Directory
For incremental load and combined initial and incremental load tasks, causes a timestamp subdirectory to be created for each CDC cycle, under each data directory.
If this option is not selected, individual data files are written to the same directory without a timestamp, unless you define an alternative directory structure.
Use Cycle Partitioning for Summary Directories
For incremental load and combined initial and incremental load tasks, causes a timestamp subdirectory to be created for each CDC cycle, under the summary contents and completed subdirectories.
List Individual Files in Contents
For incremental load and combined initial and incremental load tasks, lists individual data files under the contents subdirectory.
If Use Cycle Partitioning for Summary Directories is cleared, this option is selected by default. All of the individual files are listed in the contents subdirectory unless you can configure custom subdirectories by using the placeholders, such as for timestamp or date.
If Use Cycle Partitioning for Data Directory is selected, you can still optionally select this check box to list individual files and group them by CDC cycle.
The following table describes the Google Cloud Storage advanced target properties that appear in Advanced section:
Property
Description
Add Operation Type
Select this check box to add a metadata column that records the source SQL operation type in the output that the job propagates to the target.
For incremental loads, the job writes "I" for insert, "U" for update, or "D" for delete. For initial loads, the job always writes "I" for insert.
By default, this check box is selected for incremental load and initial and incremental load jobs, and cleared for initial load jobs.
Add Operation Time
Select this check box to add a metadata column that records the source SQL operation timestamp in the output that the job propagates to the target.
For initial loads, the job always writes the current date and time.
By default, this check box is not selected.
Add Before Images
Select this check box to include UNDO data in the output that a job writes to the target.
For initial loads, the job writes nulls.
By default, this check box is not selected.
Kafka target properties
When you define an application ingestion and replication task, you must specify the properties for your Kafka target on the Target page of the task wizard.
These properties apply to incremental load operations only.
The following table describes the Kafka target properties that appear in Target section:
Property
Description
Use Table Name as Topic Name
Indicates whether Application Ingestion and Replication writes messages that contain source data to separate topics, one for each source object, or writes all messages to a single topic.
Select this check box to write messages to separate table-specific topics. The topic names match the source table names, unless you add the source schema name, a prefix, or a suffix in the Include Schema Name, Table Prefix, or Table Suffix properties.
By default, this check box is cleared.
Include Schema Name
When Use Table Name as Topic Name is selected, this check box appears and is selected by default. This setting adds the source schema name in the table-specific topic names. The topic names then have the format schemaname_tablename.
If you do not want to include the schema name, clear this check box.
Table Prefix
When Use Table Name as Topic Name is selected, this property appears so that you can optionally enter a prefix to add to the table-specific topic names. For example, if you specify myprefix_, the topic names have the format myprefix_tablename. If you omit the underscore (_) after the prefix, the prefix is prepended to the table name.
Table Suffix
When Use Table Name as Topic Name is selected, this property appears so that you can optionally enter a suffix to add to the table-specific topic names. For example, if you specify _mysuffix, the topic names have the format tablename_mysuffix. If you omit the underscore (_) before the suffix, the suffix is appended to the table name.
Output Format
Select the format of the output file. Options are:
- CSV
- AVRO
- JSON
The default value is CSV.
Note: Output files in CSV format use double-quotation marks ("") as the delimiter for each field.
If your Kafka target uses Confluent Schema Registry to store schemas for incremental load jobs, you must select AVRO as the format.
JSON Format
If JSON is selected as the output format, select the level of detail of the output. Options are:
- Concise. This format records only the most relevant data in the output, such as the operation type and the column names and values.
- Verbose. This format records detailed information, such as the table name and column types.
Avro Format
If you selected AVRO as the output format, select the format of the Avro schema that will be created for each source table. Options are:
- Avro-Flat. This Avro schema format lists all Avro fields in one record.
- Avro-Generic. This Avro schema format lists all columns from a source table in a single array of Avro fields.
- Avro-Nested. This Avro schema format organizes each type of information in a separate record.
The default value is Avro-Flat.
Avro Serialization Format
If AVRO is selected as the output format, select the serialization format of the Avro output file. Options are:
- Binary
- JSON
- None
The default value is Binary.
If you have a Confluent Kafka target that uses Confluent Schema Registry to store schemas, select None. Otherwise, Confluent Schema Registry does not register the schema. Do not select None if you are not using Confluent Scheme Registry.
Avro Schema Directory
If AVRO is selected as the output format, specify the local directory where Database Ingestion and Replication stores Avro schema definitions for each source table. Schema definition files have the following naming pattern:
schemaname_tablename.txt
Note: If this directory is not specified, no Avro schema definition file is produced.
If a source schema change is expected to alter the target, the Avro schema definition file is regenerated with a unique name that includes a timestamp, in the following format:
schemaname_tablename_YYYYMMDDhhmmss.txt
This unique naming pattern ensures that older schema definition files are preserved for audit purposes.
Avro Compression Type
If AVRO is selected as the output format, select an Avro compression type. Options are:
- None
- Bzip2
- Deflate
- Snappy
The default value is None, which means no compression is used.
The following table describes the advanced Kafka target properties that appear under Advanced:
Property
Description
Add Operation Type
Select this check box to add a metadata column that includes the source SQL operation type in the output that the job propagates to the target.
The job writes "I" for insert, "U" for update, or "D" for delete.
By default, this check box is selected.
Add Operation Time
Select this check box to add a metadata column that records the source SQL operation timestamp in the output that the job propagates to the target.
By default, this check box is not selected.
Add Before Images
Select this check box to include UNDO data in the output that a job writes to the target.
By default, this check box is not selected.
Async Write
Controls whether to use synchronous delivery of messages to Kafka.
- Clear this check box to use synchronous delivery. Kafka must acknowledge each message as received before Application Ingestion and Replication sends the next message. In this mode, Kafka is unlikely to receive duplicate messages. However, performance might be slower.
- Select this check box to use asynchronous delivery. Application Ingestion and Replication sends messages as soon as possible, without regard for the order in which the changes were retrieved from the source.
By default, this check box is selected.
Producer Configuration Properties
Specify a comma-separated list of key=value pairs to enter Kafka producer properties for Apache Kafkatargets.
You can specify Kafka producer properties in either this field or in the Additional Connection Properties field in the Kafka connection.
If you enter the producer properties in this field, the properties pertain to the application ingestion and replication jobs associated with this task only. If you enter the producer properties for the connection, the properties pertain to jobs for all tasks that use the connection definition, unless you override the connection-level properties for specific tasks by also specifying properties in the Producer Configuration Properties field.
For information about Kafka producer properties, see the Apache Kafka documentation.
Microsoft Azure Data Lake Storage Gen2 target properties
When you define an application ingestion and replication task, you must specify the properties for your Microsoft Azure Data Lake Storage Gen2 target on the Target page of the task wizard.
The following table describes the Microsoft Azure Data Lake Storage Gen2 target properties that appear in Target section:
Property
Description
Output Format
Select the format of the output file. Options are:
- CSV
- AVRO
- PARQUET
The default value is CSV.
Note: Output files in CSV format use double-quotation marks ("") as the delimiter for each field.
Add Headers to CSV File
If CSV is selected as the output format, select this check box to add a header with source column names to the output CSV file.
Parquet Compression Type
If the PARQUET output format is selected, you can select a compression type that is supported by Parquet. Options are:
- None
- Gzip
- Snappy
The default value is None, which means no compression is used.
Avro Format
If you selected AVRO as the output format, select the format of the Avro schema that will be created for each source table. Options are:
- Avro-Flat. This Avro schema format lists all Avro fields in one record.
- Avro-Generic. This Avro schema format lists all columns from a source table in a single array of Avro fields.
- Avro-Nested. This Avro schema format organizes each type of information in a separate record.
The default value is Avro-Flat.
Avro Serialization Format
If AVRO is selected as the output format, select the serialization format of the Avro output file. Options are:
- None
- Binary
- JSON
The default value is Binary.
Avro Schema Directory
If AVRO is selected as the output format, specify the local directory where Application Ingestion and Replication stores Avro schema definitions for each source table. Schema definition files have the following naming pattern:
schemaname_tablename.txt
Note: If this directory is not specified, no Avro schema definition file is produced.
File Compression Type
Select a file compression type for output files in CSV or AVRO output format. Options are:
- None
- Deflate
- Gzip
- Snappy
The default value is None, which means no compression is used.
Avro Compression Type
If AVRO is selected as the output format, select an Avro compression type. Options are:
- None
- Bzip2
- Deflate
- Snappy
The default value is None, which means no compression is used.
Deflate Compression Level
If Deflate is selected in the Avro Compression Type field, specify a compression level from 0 to 9. The default value is 0.
Add Directory Tags
For incremental load and combined initial and incremental load tasks, select this check box to add the "dt=" prefix to the names of apply cycle directories to be compatible with the naming convention for Hive partitioning. This check box is cleared by default.
Task Target Directory
For incremental load and combined initial and incremental load tasks, the root directory for the other directories that hold output data files, schema files, and CDC cycle contents and completed files. You can use it to specify a custom root directory for the task. If you enable the Connection Directory as Parent option, you can still optionally specify a task target directory to use with the parent directory specified in the connection properties.
This field is required if the {TaskTargetDirectory} placeholder is specified in patterns for any of the following directory fields.
Data Directory
For initial load tasks, define a directory structure for the directories where Application Ingestion and Replication stores output data files and optionally stores the schema. To define directory pattern, you can use the following types of entries:
- The placeholders {SchemaName}, {TableName), {Timestamp}, {YY}, {YYYY}, {MM}, and {DD}, where {YY}, {YYYY}, {MM}, and {DD} are for date elements. The {Timestamp} values are in the format yyyymmdd_hhmissms. The generated dates and times in the directory paths indicate when the initial load job starts to transfer data to the target.
- Specific directory names.
- The toUpper() and toLower() functions, which force the values for an associated (placeholder) to uppercase or lowercase.
The default directory pattern is {TableName)_{Timestamp}.
For incremental load and combined initial and incremental load tasks, define a custom path to the subdirectory that contains the cdc-data data files. To define the directory pattern, you can use the following types of entries:
- The placeholders {TaskTargetDirectory}, {SchemaName}, {TableName), {Timestamp}, {YY}, {YYYY}, {MM}, and {DD}, where {YY}, {YYYY}, {MM}, and {DD} are for date elements. The {Timestamp} values are in the format yyyymmdd_hhmissms. The generated dates and times in the directory paths indicate when the CDC cycle started.
If you include the toUpper or toLower function, put the placeholder name in parentheses and enclose the both the function and placeholder in curly brackets, as shown in the preceding example.
- Specific directory names.
The default directory pattern is {TaskTargetDirectory}/data/{TableName}/data
Note: For Amazon S3 and Microsoft Azure Data Lake Storage Gen2 targets, Application Ingestion and Replication uses the directory specified in the target connection properties as the root for the data directory path when Connection Directory as Parent is selected. For Google Cloud Storage targets, Application Ingestion and Replication uses the Bucket name that you specify in the target properties for the ingestion task. For Microsoft Fabric OneLake targets, the parent directory is the path specified in the Lakehouse Path field in the Microsoft Fabric OneLake connection properties.
Connection Directory as Parent
Select this check box to use the directory value that is specified in the target connection properties as the parent directory for the custom directory paths specified in the task target properties. For initial load tasks, the parent directory is used in the Data Directory and Schema Directory. For incremental load and combined initial and incremental load tasks, the parent directory is used in the Data Directory, Schema Directory, Cycle Completion Directory, and Cycle Contents Directory.
This check box is selected by default. If you clear it, for initial loads, define the full path to the output files in the Data Directory field. For incremental loads, optionally specify a root directory for the task in the Task Target Directory.
Schema Directory
Specify a custom directory in which to store the schema file if you want to store it in a directory other than the default directory. For initial loads, previously used values if available are shown in a drop-down list for your convenience. This field is optional.
For initial loads, the schema is stored in the data directory by default. For incremental loads and combined initial and incremental loads, the default directory for the schema file is {TaskTargetDirectory}/data/{TableName}/schema
You can use the same placeholders as for the Data Directory field. Ensure that you enclose placeholders with curly brackets { }.
If you include the toUpper or toLower function, put the placeholder name in parentheses and enclose the both the function and placeholder in curly brackets, for example: {toLower(SchemaName)}
Note: Schema is written only to output data files in CSV format. Data files in Parquet and Avro formats contain their own embedded schema.
Cycle Completion Directory
For incremental load and combined initial and incremental load tasks, the path to the directory that contains the cycle completed file. Default is {TaskTargetDirectory}/cycle/completed.
Cycle Contents Directory
For incremental load and combined initial and incremental load tasks, the path to the directory that contains the cycle contents files. Default is {TaskTargetDirectory}/cycle/contents.
Use Cycle Partitioning for Data Directory
For incremental load and combined initial and incremental load tasks, causes a timestamp subdirectory to be created for each CDC cycle, under each data directory.
If this option is not selected, individual data files are written to the same directory without a timestamp, unless you define an alternative directory structure.
Use Cycle Partitioning for Summary Directories
For incremental load and combined initial and incremental load tasks, causes a timestamp subdirectory to be created for each CDC cycle, under the summary contents and completed subdirectories.
List Individual Files in Contents
For incremental load and combined initial and incremental load tasks, lists individual data files under the contents subdirectory.
If Use Cycle Partitioning for Summary Directories is cleared, this option is selected by default. All of the individual files are listed in the contents subdirectory unless you can configure custom subdirectories by using the placeholders, such as for timestamp or date.
If Use Cycle Partitioning for Data Directory is selected, you can still optionally select this check box to list individual files and group them by CDC cycle.
The following table describes the Microsoft Azure Data Lake Storage Gen2 advanced target properties that appear in Advanced section:
Property
Description
Add Operation Type
Select this check box to add a metadata column that records the source SQL operation type in the output that the job propagates to the target.
For incremental loads, the job writes "I" for insert, "U" for update, or "D" for delete. For initial loads, the job always writes "I" for insert.
By default, this check box is selected for incremental load and initial and incremental load jobs, and cleared for initial load jobs.
Add Operation Time
Select this check box to add a metadata column that records the source SQL operation timestamp in the output that the job propagates to the target.
For initial loads, the job always writes the current date and time.
By default, this check box is not selected.
Add Before Images
Select this check box to include UNDO data in the output that a job writes to the target.
For initial loads, the job writes nulls.
By default, this check box is not selected.
Microsoft Azure Synapse Analytics target properties
When you define an application ingestion and replication task, you must specify the properties for your Microsoft Azure Synapse Analytics target on the Target page of the task wizard.
The following table describes the Microsoft Azure Synapse Analytics target properties that appear in Target section:
Property
Description
Target Creation
The only available option is Create Target Tables, which generates the target tables based on the source objects.
Schema
Select the target schema in which Application Ingestion and Replication creates the target tables. The schema name that is specified in the connection properties is displayed by default.
This field is case sensitive. Therefore, ensure that you entered the schema name in the connection properties in the correct case.
The following table describes advanced Microsoft Azure Synapse Analytics target properties under Advanced :
Property
Description
Add Last Replicated Time
Select this check box to add a metadata column that records the timestamp at which a record was inserted or last updated in the target table. For initial loads, all loaded records have the same timestamp. For incremental and combined initial and incremental loads, the column records the timestamp of the last DML operation that was applied to the target.
By default, this check box is not selected.
Prefix for Metadata Columns
Add a prefix to the names of the added metadata columns to easily identify them and to prevent conflicts with the names of existing columns.
Do not include special characters in the prefix. Otherwise, task deployment will fail.
The default value is INFA_.
Microsoft Fabric OneLake target properties
When you define an application ingestion and replication task that has a Microsoft Fabric OneLake target, you must enter some target properties on the Target page of the task wizard.
The following table describes the Microsoft Fabric OneLake target properties that appear in Target section:
Property
Description
Output Format
Select the format of the output file. Options are:
- CSV
- AVRO
- PARQUET
The default value is CSV.
Note: Output files in CSV format use double-quotation marks ("") as the delimiter for each field.
Add Headers to CSV File
If CSV is selected as the output format, select this check box to add a header with source column names to the output CSV file.
Parquet Compression Type
If the PARQUET output format is selected, you can select a compression type that is supported by Parquet. Options are:
- None
- Gzip
- Snappy
The default value is None, which means no compression is used.
Avro Format
If you selected AVRO as the output format, select the format of the Avro schema that will be created for each source table. Options are:
- Avro-Flat. This Avro schema format lists all Avro fields in one record.
- Avro-Generic. This Avro schema format lists all columns from a source table in a single array of Avro fields.
- Avro-Nested. This Avro schema format organizes each type of information in a separate record.
The default value is Avro-Flat.
Avro Serialization Format
If AVRO is selected as the output format, select the serialization format of the Avro output file. Options are:
- None
- Binary
- JSON
The default value is Binary.
Avro Schema Directory
If AVRO is selected as the output format, specify the local directory where Application Ingestion and Replication stores Avro schema definitions for each source table. Schema definition files have the following naming pattern:
schemaname_tablename.txt
Note: If this directory is not specified, no Avro schema definition file is produced.
File Compression Type
Select a file compression type for output files in CSV or AVRO output format. Options are:
- None
- Deflate
- Gzip
- Snappy
The default value is None, which means no compression is used.
Avro Compression Type
If AVRO is selected as the output format, select an Avro compression type. Options are:
- None
- Bzip2
- Deflate
- Snappy
The default value is None, which means no compression is used.
Deflate Compression Level
If Deflate is selected in the Avro Compression Type field, specify a compression level from 0 to 9. The default value is 0.
Add Directory Tags
For incremental load and combined initial and incremental load tasks, select this check box to add the "dt=" prefix to the names of apply cycle directories to be compatible with the naming convention for Hive partitioning. This check box is cleared by default.
Task Target Directory
For incremental load and combined initial and incremental load tasks, the root directory for the other directories that hold output data files, schema files, and CDC cycle contents and completed files. You can use it to specify a custom root directory for the task.
This field is required if the {TaskTargetDirectory} placeholder is specified in patterns for any of the following directory fields.
Data Directory
For initial load tasks, define a directory structure for the directories where Application Ingestion and Replication stores output data files and optionally stores the schema. To define directory pattern, you can use the following types of entries:
- The placeholders {SchemaName}, {TableName), {Timestamp}, {YY}, {YYYY}, {MM}, and {DD}, where {YY}, {YYYY}, {MM}, and {DD} are for date elements. The {Timestamp} values are in the format yyyymmdd_hhmissms. The generated dates and times in the directory paths indicate when the initial load job starts to transfer data to the target.
- Specific directory names.
- The toUpper() and toLower() functions, which force the values for an associated (placeholder) to uppercase or lowercase.
The default directory pattern is {TableName)_{Timestamp}.
For incremental load and combined initial and incremental load tasks, define a custom path to the subdirectory that contains the cdc-data data files. To define the directory pattern, you can use the following types of entries:
- The placeholders {TaskTargetDirectory}, {SchemaName}, {TableName), {Timestamp}, {YY}, {YYYY}, {MM}, and {DD}, where {YY}, {YYYY}, {MM}, and {DD} are for date elements. The {Timestamp} values are in the format yyyymmdd_hhmissms. The generated dates and times in the directory paths indicate when the CDC cycle started.
If you include the toUpper or toLower function, put the placeholder name in parentheses and enclose the both the function and placeholder in curly brackets, as shown in the preceding example.
- Specific directory names.
The default directory pattern is {TaskTargetDirectory}/data/{TableName}/data
Note: For Amazon S3 and Microsoft Azure Data Lake Storage Gen2 targets, Application Ingestion and Replication uses the directory specified in the target connection properties as the root for the data directory path when Connection Directory as Parent is selected. For Google Cloud Storage targets, Application Ingestion and Replication uses the Bucket name that you specify in the target properties for the ingestion task. For Microsoft Fabric OneLake targets, the parent directory is the path specified in the Lakehouse Path field in the Microsoft Fabric OneLake connection properties.
Schema Directory
Specify a custom directory in which to store the schema file if you want to store it in a directory other than the default directory. For initial loads, previously used values if available are shown in a drop-down list for your convenience. This field is optional.
For initial loads, the schema is stored in the data directory by default. For incremental loads and combined initial and incremental loads, the default directory for the schema file is {TaskTargetDirectory}/data/{TableName}/schema
You can use the same placeholders as for the Data Directory field. Ensure that you enclose placeholders with curly brackets { }.
If you include the toUpper or toLower function, put the placeholder name in parentheses and enclose the both the function and placeholder in curly brackets, for example: {toLower(SchemaName)}
Note: Schema is written only to output data files in CSV format. Data files in Parquet and Avro formats contain their own embedded schema.
Cycle Completion Directory
For incremental load and combined initial and incremental load tasks, the path to the directory that contains the cycle completed file. Default is {TaskTargetDirectory}/cycle/completed.
Cycle Contents Directory
For incremental load and combined initial and incremental load tasks, the path to the directory that contains the cycle contents files. Default is {TaskTargetDirectory}/cycle/contents.
Use Cycle Partitioning for Data Directory
For incremental load and combined initial and incremental load tasks, causes a timestamp subdirectory to be created for each CDC cycle, under each data directory.
If this option is not selected, individual data files are written to the same directory without a timestamp, unless you define an alternative directory structure.
Use Cycle Partitioning for Summary Directories
For incremental load and combined initial and incremental load tasks, causes a timestamp subdirectory to be created for each CDC cycle, under the summary contents and completed subdirectories.
List Individual Files in Contents
For incremental load and combined initial and incremental load tasks, lists individual data files under the contents subdirectory.
If Use Cycle Partitioning for Summary Directories is cleared, this option is selected by default. All of the individual files are listed in the contents subdirectory unless you can configure custom subdirectories by using the placeholders, such as for timestamp or date.
If Use Cycle Partitioning for Data Directory is selected, you can still optionally select this check box to list individual files and group them by CDC cycle.
Microsoft SQL Server target properties
When you define an application ingestion and replication task, you must specify the properties for the Microsoft SQL Server target.
The following table describes the target properties that appear under Target:
Property
Description
Target Creation
The Create Target Tables option generates the target tables based on the source tables.
Note: After the target table is created, Application Ingestion and Replication intelligently handles the target tables on subsequent job runs. Application Ingestion and Replication might truncate or re-create the target tables depending on specific circumstances.
Schema
Select the target schema in which Application Ingestion and Replication creates the target tables. The schema name that is specified in the connection properties is displayed by default.
This field is case sensitive. Therefore, ensure that you entered the schema name in the connection properties in the correct case.
The following table describes advanced target properties that appear under Advanced:
Property
Description
Add Last Replicated Time
Select this check box to add a metadata column that records the timestamp at which a record was inserted or last updated in the target table. For initial loads, all loaded records have the same timestamp. For incremental and combined initial and incremental loads, the column records the timestamp of the last DML operation that was applied to the target.
By default, this check box is not selected.
Add Cycle ID
Select this check box to add a metadata column that includes the cycle ID of each CDC cycle in each target table. A cycle ID is a number that's generated by the CDC engine for each successful CDC cycle. If you integrate the job with Data Integration taskflows, the job can pass the minimum and maximum cycle IDs in output fields to the taskflow so that the taskflow can determine the range of cycles that contain new CDC data. This capability is useful if data from multiple cycles accumulates before the previous taskflow run completes. By default, this check box is not selected.
Prefix for Metadata Columns
Add a prefix to the names of the added metadata columns to easily identify them and to prevent conflicts with the names of existing columns.
Do not include special characters in the prefix. Otherwise, task deployment will fail.
The default value is INFA_.
Oracle Cloud Object Storage target properties
When you define a application ingestion and replication task that has an Oracle Cloud Object Storage target, you must enter some target properties on the Target tab of the task wizard.
Under Target, you can enter the following Oracle Cloud Object Storage target properties:
Property
Description
Output Format
Select the format of the output file. Options are:
- CSV
- AVRO
- PARQUET
The default value is CSV.
Note: Output files in CSV format use double-quotation marks ("") as the delimiter for each field.
Add Headers to CSV File
If CSV is selected as the output format, select this check box to add a header with source column names to the output CSV file.
Parquet Compression Type
If the PARQUET output format is selected, you can select a compression type that is supported by Parquet. Options are:
- None
- Gzip
- Snappy
The default value is None, which means no compression is used.
Avro Format
If you selected AVRO as the output format, select the format of the Avro schema that will be created for each source table. Options are:
- Avro-Flat. This Avro schema format lists all Avro fields in one record.
- Avro-Generic. This Avro schema format lists all columns from a source table in a single array of Avro fields.
- Avro-Nested. This Avro schema format organizes each type of information in a separate record.
The default value is Avro-Flat.
Avro Serialization Format
If AVRO is selected as the output format, select the serialization format of the Avro output file. Options are:
- None
- Binary
- JSON
The default value is Binary.
Avro Schema Directory
If AVRO is selected as the output format, specify the local directory where Application Ingestion and Replication stores Avro schema definitions for each source table. Schema definition files have the following naming pattern:
schemaname_tablename.txt
Note: If this directory is not specified, no Avro schema definition file is produced.
File Compression Type
Select a file compression type for output files in CSV or AVRO output format. Options are:
- None
- Deflate
- Gzip
- Snappy
The default value is None, which means no compression is used.
Avro Compression Type
If AVRO is selected as the output format, select an Avro compression type. Options are:
- None
- Bzip2
- Deflate
- Snappy
The default value is None, which means no compression is used.
Deflate Compression Level
If Deflate is selected in the Avro Compression Type field, specify a compression level from 0 to 9. The default value is 0.
Add Directory Tags
For incremental load and combined initial and incremental load tasks, select this check box to add the "dt=" prefix to the names of apply cycle directories to be compatible with the naming convention for Hive partitioning. This check box is cleared by default.
Task Target Directory
For incremental load and combined initial and incremental load tasks, the root directory for the other directories that hold output data files, schema files, and CDC cycle contents and completed files. You can use it to specify a custom root directory for the task. If you enable the Connection Directory as Parent option, you can still optionally specify a task target directory to use with the parent directory specified in the connection properties.
This field is required if the {TaskTargetDirectory} placeholder is specified in patterns for any of the following directory fields.
Connection Directory as Parent
Select this check box to use the directory value that is specified in the target connection properties as the parent directory for the custom directory paths specified in the task target properties. For initial load tasks, the parent directory is used in the Data Directory and Schema Directory. For incremental load and combined initial and incremental load tasks, the parent directory is used in the Data Directory, Schema Directory, Cycle Completion Directory, and Cycle Contents Directory.
This check box is selected by default. If you clear it, for initial loads, define the full path to the output files in the Data Directory field. For incremental loads, optionally specify a root directory for the task in the Task Target Directory.
Data Directory
For initial load tasks, define a directory structure for the directories where Application Ingestion and Replication stores output data files and optionally stores the schema. To define directory pattern, you can use the following types of entries:
- The placeholders {SchemaName}, {TableName), {Timestamp}, {YY}, {YYYY}, {MM}, and {DD}, where {YY}, {YYYY}, {MM}, and {DD} are for date elements. The {Timestamp} values are in the format yyyymmdd_hhmissms. The generated dates and times in the directory paths indicate when the initial load job starts to transfer data to the target.
- Specific directory names.
- The toUpper() and toLower() functions, which force the values for an associated (placeholder) to uppercase or lowercase.
The default directory pattern is {TableName)_{Timestamp}.
For incremental load and combined initial and incremental load tasks, define a custom path to the subdirectory that contains the cdc-data data files. To define the directory pattern, you can use the following types of entries:
- The placeholders {TaskTargetDirectory}, {SchemaName}, {TableName), {Timestamp}, {YY}, {YYYY}, {MM}, and {DD}, where {YY}, {YYYY}, {MM}, and {DD} are for date elements. The {Timestamp} values are in the format yyyymmdd_hhmissms. The generated dates and times in the directory paths indicate when the CDC cycle started.
If you include the toUpper or toLower function, put the placeholder name in parentheses and enclose the both the function and placeholder in curly brackets, as shown in the preceding example.
- Specific directory names.
The default directory pattern is {TaskTargetDirectory}/data/{TableName}/data
Note: For Amazon S3 and Microsoft Azure Data Lake Storage Gen2 targets, Application Ingestion and Replication uses the directory specified in the target connection properties as the root for the data directory path when Connection Directory as Parent is selected. For Google Cloud Storage targets, Application Ingestion and Replication uses the Bucket name that you specify in the target properties for the ingestion task. For Microsoft Fabric OneLake targets, the parent directory is the path specified in the Lakehouse Path field in the Microsoft Fabric OneLake connection properties.
Schema Directory
Specify a custom directory in which to store the schema file if you want to store it in a directory other than the default directory. For initial loads, previously used values if available are shown in a drop-down list for your convenience. This field is optional.
For initial loads, the schema is stored in the data directory by default. For incremental loads and combined initial and incremental loads, the default directory for the schema file is {TaskTargetDirectory}/data/{TableName}/schema
You can use the same placeholders as for the Data Directory field. Ensure that you enclose placeholders with curly brackets { }.
If you include the toUpper or toLower function, put the placeholder name in parentheses and enclose the both the function and placeholder in curly brackets, for example: {toLower(SchemaName)}
Note: Schema is written only to output data files in CSV format. Data files in Parquet and Avro formats contain their own embedded schema.
Cycle Completion Directory
For incremental load and combined initial and incremental load tasks, the path to the directory that contains the cycle completed file. Default is {TaskTargetDirectory}/cycle/completed.
Cycle Contents Directory
For incremental load and combined initial and incremental load tasks, the path to the directory that contains the cycle contents files. Default is {TaskTargetDirectory}/cycle/contents.
Use Cycle Partitioning for Data Directory
For incremental load and combined initial and incremental load tasks, causes a timestamp subdirectory to be created for each CDC cycle, under each data directory.
If this option is not selected, individual data files are written to the same directory without a timestamp, unless you define an alternative directory structure.
Use Cycle Partitioning for Summary Directories
For incremental load and combined initial and incremental load tasks, causes a timestamp subdirectory to be created for each CDC cycle, under the summary contents and completed subdirectories.
List Individual Files in Contents
For incremental load and combined initial and incremental load tasks, lists individual data files under the contents subdirectory.
If Use Cycle Partitioning for Summary Directories is cleared, this option is selected by default. All of the individual files are listed in the contents subdirectory unless you can configure custom subdirectories by using the placeholders, such as for timestamp or date.
If Use Cycle Partitioning for Data Directory is selected, you can still optionally select this check box to list individual files and group them by CDC cycle.
Under Advanced, you can enter the following advanced target properties to add metadata columns for each delete operation or each DML change recorded in the audit table.
Field
Description
Add Operation Type
Select this check box to add a metadata column that records the source SQL operation type in the output that the job propagates to the target.
For incremental loads, the job writes "I" for insert, "U" for update, or "D" for delete. For initial loads, the job always writes "I" for insert.
By default, this check box is selected for incremental load and initial and incremental load jobs, and cleared for initial load jobs.
Add Operation Time
Select this check box to add a metadata column that records the source SQL operation timestamp in the output that the job propagates to the target.
For initial loads, the job always writes the current date and time.
By default, this check box is not selected.
Add Before Images
Select this check box to include UNDO data in the output that a job writes to the target.
By default, this check box is not selected.
Oracle target properties
When you define an application ingestion and replication task, you must specify the properties for your Oracle target on the Target page of the task wizard.
The following table describes the Oracle target properties that appear in Target section:
Property
Description
Target Creation
The only available option is Create Target Tables, which generates the target tables based on the source objects.
Schema
Select the target schema in which Application Ingestion and Replication creates the target tables.
Apply Mode
For incremental load and combined initial and incremental load jobs, indicates how source DML changes, including inserts, updates, and deletes, are applied to the target. Options are:
- Standard. Accumulate the changes in a single apply cycle and intelligently merge them into fewer SQL statements before applying them to the target. For example, if an update followed by a delete occurs on the source row, no row is applied to the target. If multiple updates occur on the same column or field, only the last update is applied to the target. If multiple updates occur on different columns or fields, the updates are merged into a single update record before being applied to the target.
- Audit. Apply an audit trail of every DML operation made on the source tables to the target. A row for each DML change on a source table is written to the generated target table along with the audit columns you select under the Advanced section. The audit columns contain metadata about the change, such as the DML operation type, time, owner, transaction ID, generated ascending sequence number, and before image. Consider using Audit apply mode when you want to use the audit history to perform downstream computations or processing on the data before writing it to the target database or when you want to examine metadata about the captured changes.
The default value is Standard.
Note: The Audit apply mode applies for an SAP source with SAP Mass Ingestion connector.
The following table describes the advanced target properties that you can set under Advanced. All properties except Add Last Replicated Time and Prefix for Metadata Columns are available only if you set Apply Mode to Audit.
Field
Description
Add Last Replicated Time
Select this check box to add a metadata column that records the timestamp in UTC format at which a record was inserted or last updated in the target table. For initial loads, all loaded records have the same timestamp. For incremental and combined initial and incremental loads, the column records the timestamp of the last DML operation that was applied to the target.
By default, this check box is not selected.
Add Operation Type
Select this check box to add a metadata column that records the source SQL operation type in the output that the job propagates to the target database or inserts into the target table.
The job writes "I" for insert, "U" for update, or "D" for delete.
By default, this check box is selected.
Add Operation Time
Select this check box to add a metadata column that records the source SQL operation timestamp in the output that the job propagates to the target table.
By default, this check box is not selected.
Add Operation Sequence
Select this check box to add a metadata column that records a generated, ascending sequence number for each change operation that the job inserts into the target tables. The sequence number reflects the change stream position of the operation.
By default, this check box is not selected.
Add Before Images
Select this check box to add _OLD columns with UNDO "before image" data in the output that the job inserts into the target tables. You can then compare the old and current values for each data column. For a delete operation, the current value will be null.
By default, this check box is not selected.
Add Cycle ID
Select this check box to add a metadata column that includes the cycle ID of each CDC cycle in each target table. A cycle ID is a number that's generated by the CDC engine for each successful CDC cycle. If you integrate the job with Data Integration taskflows, the job can pass the minimum and maximum cycle IDs in output fields to the taskflow so that the taskflow can determine the range of cycles that contain new CDC data. This capability is useful if data from multiple cycles accumulates before the previous taskflow run completes. By default, this check box is not selected.
Prefix for Metadata Columns
Add a prefix to the names of the added metadata columns to easily identify them and to prevent conflicts with the names of existing columns.
The default value is INFA_.
Enable Case Transformation
By default, target table names and column names are generated in the same case as the corresponding source names. If you want to control the case of letters in the target names, select this check box. Then select a Case Transformation Strategy option.
Case Transformation Strategy
If you selected Enable Case Transformation, select one of the following options to specify how to handle the case of letters in generated target table (or object) names and column (or field) names:
- Same as source. Use the same case as the source table (or object) names and column (or field) names.
- UPPERCASE. Use all uppercase.
- lowercase. Use all lowercase.
The default value is Same as source.
PostgreSQL target properties
When you define an application ingestion and replication task, you must specify the properties for PostgreSQL target on the Target page of the task wizard.
The following table describes the PostgreSQL target properties that appear in Target section:
Property
Description
Target Creation
The only available option is Create Target Tables, which generates the target tables based on the source objects.
Schema
Select the target schema in which Application Ingestion and Replication creates the target tables.
Snowflake Data Cloud target properties
When you define an application ingestion and replication task, you must specify the properties for your Snowflake target on the Target page of the task wizard.
The following table describes the Snowflake target properties that appear in Target section:
Property
Description
Target Creation
The only available option is Create Target Tables, which generates the target tables based on the source objects.
Schema
Select the target schema in which Application Ingestion and Replication creates the target tables.
Stage
The name of internal staging area that holds the data read from the source before the data is written to the target tables. This name must not include spaces. If the staging area does not exist, it will be automatically created.
Note: This field is not available if you selected the Superpipe option in the Advanced Target Properties.
Apply Mode
For incremental load and combined initial and incremental load jobs, indicates how source DML changes, including inserts, updates, and deletes, are applied to the target. Options are:
- Standard. Accumulate the changes in a single apply cycle and intelligently merge them into fewer SQL statements before applying them to the target. For example, if an update followed by a delete occurs on the source row, no row is applied to the target. If multiple updates occur on the same column or field, only the last update is applied to the target. If multiple updates occur on different columns or fields, the updates are merged into a single update record before being applied to the target.
- Soft Deletes. Apply source delete operations to the target as soft deletes. A soft delete marks the deleted row as deleted without actually removing it from the database. For example, a delete on the source results in a change record on the target with "D" displayed in the INFA_OPERATION_TYPE column.
After enabling Soft Deletes, any update in the source table during normal or backlog mode results in the deletion of the matching record, insertion of the updated record, and marking of the INFA_OPERATION_TYPE operation as NULL in the target table. Similarly, inserting a record in the source table during backlog mode results in marking the INFA_OPERATION_TYPE operation as E in the target table record.
Consider using soft deletes if you have a long-running business process that needs the soft-deleted data to finish processing, to restore data after an accidental delete operation, or to track deleted values for audit purposes.
- Audit. Apply an audit trail of every DML operation made on the source tables to the target. A row for each DML change on a source table is written to the generated target table along with the audit columns you select under the Advanced section. The audit columns contain metadata about the change, such as the DML operation type, transaction ID, and before image. Consider using Audit apply mode when you want to use the audit history to perform downstream computations or processing on the data before writing it to the target database or when you want to examine metadata about the captured changes.
After enabling the Audit apply mode, any update in the source table during backlog or normal mode results in marking the INFA_OPERATION_TYPE operation as E in the target table record. Similarly, inserting a record in the source table during backlog mode results in marking the INFA_OPERATION_TYPE operation as E in the target table record.
Note: The Audit apply mode applies for SAP source with SAP Mass Ingestion connector.
Default is Standard.
Under Advanced, you can enter the following advanced target properties:
Field
Description
Add Last Replicated Time
Select this check box to add a metadata column that records the timestamp at which a record was inserted or last updated in the target table. For initial loads, all loaded records have the same timestamp, except for Snowflake targets that use the Superpipe option where minutes and seconds might vary slightly. For incremental and combined initial and incremental loads, the column records the timestamp of the last DML operation that was applied to the target.
By default, this check box is not selected.
Add Operation Type
Add a metadata column that includes the source SQL operation type in the output that the job propagates to the target tables. The column is named INFA_OPERATION_TYPE by default.
This field is displayed only when the Apply Mode option is set to Audit or Soft Deletes.
In Audit mode, the job writes "I" for inserts, "U" for updates, "E" for upserts, or "D" for deletes to this metadata column.
In Soft Deletes mode, the job writes "D" for deletes or NULL for inserts and updates. When the operation type is NULL, the other "Add Operation..." metadata columns are also NULL. Only when the operation type is "D" will the other metadata columns contain non-null values.
By default, this check box is selected. You cannot deselect it.
Add Operation Time
Select this check box to add a metadata column that records the source SQL operation timestamp in the output that the job propagates to the target tables.
This field is available only when Apply Mode is set to Audit or Soft Deletes.
By default, this check box is not selected.
Add Operation Sequence
Select this check box to add a metadata column that records a generated, ascending sequence number for each change operation that the job inserts into the target tables. The sequence number reflects the change stream position of the operation.
This field is available only when Apply Mode is set to Audit.
By default, this check box is not selected.
Add Before Images
Select this check box to add _OLD columns with UNDO "before image" data in the output that the job inserts into the target tables. You can then compare the old and current values for each data column. For a delete operation, the current value will be null.
This field is available only when Apply Mode is set to Audit.
By default, this check box is not selected.
Add Cycle ID
Select this check box to add a metadata column that includes the cycle ID of each CDC cycle in each target table. A cycle ID is a number that's generated by the CDC engine for each successful CDC cycle. If you integrate the job with Data Integration taskflows, the job can pass the minimum and maximum cycle IDs in output fields to the taskflow so that the taskflow can determine the range of cycles that contain new CDC data. This capability is useful if data from multiple cycles accumulates before the previous taskflow run completes. By default, this check box is not selected.
Note: If you select this option, you can't also select the Superpipe option for the Snowflake target.
Prefix for Metadata Columns
Add a prefix to the names of the added metadata columns to easily identify them and to prevent conflicts with the names of existing columns.
The default value is INFA_.
Superpipe
Select this check box to use the Snowpipe Streaming API to quickly stream rows of data directly to Snowflake Data Cloud target tables with low latency instead of first writing the data to stage files. This option is available for all load types.
When you configure the target connection, select KeyPair authentication.
By default, this check box is selected. Deselect it if you want to write data to intermediate stage files.
Note: If you enable the Superpipe option for a task that uses the Soft Deletes apply mode, make sure the source tables contain a primary key.
Merge Frequency
When Superpipe is selected, you can optionally set the frequency, in seconds, at which change data rows are merged and applied to the Snowflake target tables.
The merge frequency affects how often the stream change data is merged to the Snowflake base table. A Snowflake view joins the stream change data with the base table. Set this value to balance the costs of merging data to the base table with the performance of view join processing.
This field applies to incremental load and combined initial and incremental load tasks. Valid values are 60 through 604800 seconds. Default is 3600 seconds.
Enable Case Transformation
By default, target table names and column names are generated in the same case as the corresponding source names, unless cluster-level or session-level properties on the target override this case-sensitive behavior. If you want to control the case of letters in the target names, select this check box. Then select a Case Transformation Strategy option.
Case Transformation Strategy
If you selected Enable Case Transformation, select one of the following options to specify how to handle the case of letters in generated target table (or object) names and column (or field) names:
- Same as source. Use the same case as the source table (or object) names and column (or field) names.
- UPPERCASE. Use all uppercase.
- lowercase. Use all lowercase.
The default value is Same as source.
Note: The selected strategy will override any cluster-level or session-level properties on the target for controlling case.
Configuring schedule and runtime options
On the Schedule and Runtime Options page in the application ingestion and replication task wizard, you can specify a schedule for running the initial load jobs and configure the runtime options for jobs of all load types.
1In the Schema Drift Options section, specify the schema drift option to use for each type of Data Definition Language (DDL) operation.
Note: The Schema Drift Options section appears only for incremental load and combined initial and incremental load tasks. Additionally, this section appears only for the sources that support automatic detection of schema changes.
The following table describes the schema drift options that you can specify for the DDL operations:
Option
Description
Ignore
Does not replicate DDL changes that occur on the source schema to the target.
Replicate
Allows the application ingestion and replication job to replicate the DDL changes to the target.
The types of supported DDL operations are:
- Add Column
- Modify Column
- Drop Column
- Rename Column
Application ingestion and replication jobs doesn't support modifying or renaming columns for Google BigQuery target, and adding columns for Oracle targets.
Stop Job
Stops the application ingestion and replication job.
Stop Object
Stops processing the source object on which the DDL change occurred.
Note: When one or more objects are excluded from replication because of the Stop Object schema drift option, the status of the job changes to Running with Warning. The application ingestion and replication job cannot retrieve the data changes that occurred on the source object after the job stops processing the changes. This action leads to data loss on the target. To avoid data loss, you must re-synchronize the source and target objects that the job stopped processing before you resume the application ingestion and replication job.
2Optionally, in the Advanced section, modify the value in the Number of Rows in Output File value to specify the maximum number of rows that the application ingestion and replication task writes to an output file for an Amazon Redishift, Amazon S3, Google Big Query, Google Cloud Storage, Microsoft Azure Data Lake Storage, Microsoft Azure Synapse Analytics, Microsoft Fabric OneLake, Oracle, or Snowflake target.
Valid values are 1 through 100000000 and the default value is 100000 rows.
Note: For incremental load and combined initial and incremental load operations, change data is flushed to the target either when the specified number of rows is reached or when the flush latency period expires and the job is not in the middle of processing a transaction. The flush latency period is the time that the job waits for more change data before flushing data to the target. The latency period is set to 10 seconds and cannot be changed.
3For initial load jobs only, optionally clear the File Extension Based on File Type check box if you want the output data files for Amazon S3, Google Cloud Storage, Microsoft Azure Data Lake Storage, or Microsoft Fabric OneLake targets to have the .dat extension. This check box is selected by default, which causes the output files to have file-name extensions based on their file types.
Note: For incremental load jobs with these target types, this option is not available. Application Ingestion and Replication always uses output file-name extensions based on file type.
4Optionally, configure an apply cycle. An apply cycle is a cycle of applying change data that starts with fetching the intermediate data from the source and ends with the commit of the data to the target. For continuous replication, the source processes the data in multiple low-latency apply cycles.
For application ingestion and replication incremental load tasks that have Amazon S3, Google Cloud Storage, Microsoft Azure Data Lake Storage Gen2, or Microsoft Fabric OneLake targets, you can configure the following apply cycle options:
Option
Description
Apply Cycle Interval
Specifies the amount of time that must elapse before an application ingestion and replication job ends an apply cycle. You can specify days, hours, minutes, and seconds or specify values for a subset of these time fields leaving the other fields blank.
The default value is 15 minutes.
Apply Cycle Change Limit
Specifies the number of records that must be processed before an application ingestion and replication job ends an apply cycle. When this record limit is reached, the ingestion job ends the apply cycle and writes the change data to the target.
The default value is 10000 records.
Note: During startup, jobs might reach this limit more frequently than the apply cycle interval if they need to catch up on processing a backlog of older data.
Low Activity Flush Interval
Specifies the amount of time, in hours, minutes, or both, that must elapse during a period of no change activity on the source before an application ingestion and replication job ends an apply cycle. When this time limit is reached, the ingestion job ends the apply cycle and writes the change data to the target.
If you do not specify a value for this option, a database ingestion job ends apply cycles only after either the Apply Cycle Change Limit or Apply Cycle Interval limit is reached.
No default value is provided.
5For incremental load jobs that have an Apache Kafka target, configure the following checkpointing options:
Option
Description
Checkpoint All Rows
Indicates whether a database ingestion job performs checkpoint processing for every message that is sent to the Kafka target.
Note: If this check box is selected, the Checkpoint Every Commit, Checkpoint Row Count, and Checkpoint Frequency (secs) options are ignored.
Checkpoint Every Commit
Indicates whether an application ingestion and replication job performs checkpoint processing for every commit that occurs on the source.
Checkpoint Row Count
Specifies the maximum number of messages that an application ingestion and replication job sends to the target before adding a checkpoint. If you set this option to 0, a database ingestion job does not perform checkpoint processing based on the number of messages. If you set this option to 1, a database ingestion jobs add a checkpoint for each message.
Checkpoint Frequency (secs)
Specifies the maximum number of seconds that must elapse before an application ingestion and replication job adds a checkpoint. If you set this option to 0, a database ingestion job does not perform checkpoint processing based on elapsed time.
6If you want the application ingestion and replication job associated with the task to run in specific intervals based on a schedule, select Run this task based on a schedule in the Schedule section, and then select a predefined schedule for the job.
By default, Do not run this task based on a schedule is selected, which configures the job to run only when it is manually triggered.
Note: This field is available only for initial load tasks.
You can view and edit the job schedule options in Administrator. If you edit the schedule, the changes are automatically applied to all the jobs that are configured to run based on the schedule. If you change the schedule for a task that is already deployed, the updated schedule is automatically applied to the application ingestion and replication job associated with the task.
If a job is about to be triggered based on its schedule when its previous run is still in progress, Application Ingestion and Replication does not run the job and allows the job run that is already in progress to complete.
7Under Taskflow, if you want to make the application ingestion and replication task, after it's deployed, available in Data Integration to add to a taskflow, select Execute in Taskflow. You can then include the task as an event source in the taskflow and add transformations to transform the ingested data. Available for initial load and incremental load tasks with Snowflake targets that don't use the Superpipe option
8In the Custom Properties section, you can specify custom properties that Informatica provides for special cases. To add a property, click the Add Property icon, and then add the property name and value.
The custom properties are configured to address unique environments and special use cases.
Note: Specify the custom properties only at the direction of Informatica Global Customer Support.