In Data Integration, use the file ingestion and replication task wizard to configure a file ingestion and replication task.
On the wizard pages, complete the following configuration tasks:
1Define basic task information, such as the task name, project location and runtime environment.
2Configure the source.
3Configure the target.
4Optionally, configure one or more file-processing actions.
5Optionally, set the runtime options.
As you work through the task wizard, you can click Save to save your work at any time. When you have completed the wizard, click Finish to save the task and close the wizard.
Before you begin, verify that the prerequisites are met. For more information, see Before you begin.
Before you begin
Before you create file ingestion and replication tasks, verify that the following conditions exist:
•Check that your organization has licenses for File Ingestion and Replication and the FMI packages.
•The Data Ingestion and Replication application is running on the Secure Agent.
•Source and target connections exist, based on the sources from where you want to transfer files and the targets to where you want to transfer files.
Defining basic task information
To begin defining a file ingestion and replication task, you must first enter some basic information about the task, such as task name, project or project folder location, and runtime environment.
1Start the task wizard in one of the following ways:
- On the Home page, click the Ingest panel and select File Ingestion and Replication Task.
- In the navigation bar on the Explore page or the Home page, click New to open the New Asset dialog box. Then, select Data Ingestion and Replication > File Ingestion and Replication and click Create.
Note:
If your organization does not have a custom license for application, database, file, or streaming ingestion and replication, the Data Ingestion and Replication category still appears but you cannot select and configure an ingestion and replication task of the unlicensed task type or types.
The Definition page of the file ingestion and replication task wizard appears.
2Configure the following properties:
Property
Description
Task Name
Name of the file ingestion and replication task. The names of file ingestion and replication tasks must be unique within the organization. Task names can contain alphanumeric characters, spaces, and underscores. Names must begin with an alphabetic character or underscore.
Task names are not case sensitive.
Location
Project or folder in which the task will reside.
Description
Optional description of the task. Maximum length is 1024 characters.
Runtime Environment
Runtime environment that runs the task.
File ingestion and replication tasks can run on a Secure Agent or Cloud Hosted Agent. They cannot run in a serverless runtime environment.
3Click Next.
To edit a file ingestion and replication task, on the Explore page, navigate to the task. In the row that contains the task, from the Actions menu, select Edit.
Configuring the source
To configure the source, select a source type and a source connection from which to transfer files and then configure source options.
1On the Source page, select the source type.
2Select a source connection type and a source connection.
If a new connection is created in your organization for the selected connection type while you are on this page, it might not appear in the connections list right away. Click the refresh icon to see all the available connections.
The file ingestion and replication task uses the following source connection types:
- Local folder
- Advanced FTP V2
- Advanced FTPS V2
- Advanced SFTP V2
- Amazon S3 V2
- Cloud Integration Hub
- Google Cloud Storage V2
- Hadoop Files V2
- Microsoft Azure Blob Storage V3
- Microsoft Azure Data Lake Store Gen2
- Microsoft Azure Data Lake Store V3
- Microsoft Fabric OneLake
- Oracle Cloud Object Storage
3Based on the source connection that you select, enter the source options.
Options that appear on the Source tab of the task wizard vary based on the type of source connection that you select.
4Click Next.
The Target tab appears.
Advanced FTP V2 source properties
When you define a file ingestion and replication task with an Advanced FTP V2 source, you must enter source options on the Source tab of the task wizard. The options vary based on the file pickup method that you select for the task.
Note:
You can overwrite the file name pattern, folder, and table parameters, and define your own variable for sources by using the job resource of the File Ingestion and Replication REST API. For more information, see Jobs.
The following table describes the source options:
Option
Description
File Pickup
The file ingestion and replication task supports the following file pickup methods:
- By Pattern. The file ingestion and replication task picks up files by pattern.
- By File List. The file ingestion and replication task picks up files based on a file list.
Source Directory
Directory from where files are transferred. The default value is the source directory specified in the connection.
You can enter a relative path to the source file system. To enter a relative path, start the path with a period, followed by a slash (./). The path is relative to the source directory specified in the connection.
Add Parameters
Create an expression and add it as a Source Directory parameter. For more information, see Source and target parameters.
File Pattern
This applies when File Pickup is By Pattern. File name pattern to use for selecting the files to transfer. The pattern can be a regular expression or a pattern with wildcard characters.
The following wildcard characters are allowed:
- An asterisk (*) to represent any number of characters.
- A question mark (?) to represent a single character.
For example, you can specify the following regular expression:
([a-zA-Z0-9\s_\\.\-\(\):])+(.doc|.docx|.pdf)$
File Date
This applies when File Pickup is By Pattern. A date and time expression for filtering the files to transfer.
Select one of the following options:
- Greater than or Equal. Filters files that are modified on or after the specified date and time.
To specify a date, click the calendar. To specify a time, click the clock.
- Less than or Equal. Filters files that are modified before or on the specified date and time.
- Equal. Filters files that are modified on the specified date and time.
Click the calendar to select the date and the clock to select the time.
- Days before today. Filters files that are modified within the specified number of days until the current date (today). Enter the number of days. The current date calculation starts from 00:00 hours.
For example, if you schedule the file ingestion and replication task to run weekly and want to filter for the files that were modified in the previous week, set Days before today to 7. The task will pick up any file with a date between 7 days ago and the date on which it runs.
Time Zone
This applies when File Pickup is By Pattern. If you selected a File Date option, enter the time zone of the location where the files are located.
File Size
This applies when File Pickup is By Pattern. Filters the files to transfer based on file size. Enter the file size, select the file size unit, and filter options.
Select one of the following filter options:
- Greater than or Equal. Filters files that are greater than or equal to the specified size.
- Less than or Equal. Filters files that are less than or equal to the specified size.
- Equal. Filters files that have the specified size.
File path containing the list of files
This applies when File Pickup is By File List. Select this option to provide the file path that contains the list of files to pick up. Ensure that you enter a comma-separated list of file names in the file.
File list
This applies when File Pickup is By File List. Select this option to provide the list of files to pick up and enter a comma-separated list of file names.
Skip Duplicate Files
Indicates whether to skip duplicate files. If you select this option, the file ingestion and replication task does not transfer files that have the same name and file size as another file. The file ingestion and replication task marks these files as duplicate in the job log. If you do not select this option, the task transfers all files, even files with duplicate names and creation dates.
For more information about transferring skip duplicate files information, see Skip duplicate files.
Check file stability
Indicates whether to verify that a file is stable before a file ingestion and replication task attempts to pick it. The task skips unstable files it detects in the current run.
Stability check interval
This applies when you enable the Check file stability option. Time in seconds that a file ingestion and replication task waits to check the file stability.
For example, if the stability time is 15 seconds, the file ingestion and replication task detects all the files in the source folder that match the defined file pattern, it waits for 15 seconds, and then it processes only the stable files.
The interval ranges between 10 seconds to 300 seconds. Default is 10 seconds.
Batch Size
The number of files a file ingestion and replication task can transfer in a batch.
Default is 5. The maximum number of files you can transfer in a batch is 20.
The maximum value of the batch varies based on whether the files are transferred through an intermediate staging area.
Transfer Mode
File transfer mode. Select one of the following modes:
- Auto. File Ingestion and Replication determines the transfer mode.
- ASCII.
- Binary.
Note:
If a binary file transfer is interrupted due to a network disruption, the file event displays an interrupted status. Run the file ingestion and replication job again to resume the transfer of the interrupted files.
After File Pickup
Determines what to do with the source files after the files are transferred.
Select one of the following options:
- Keep the files in the source directory.
- Delete the files from the source directory.
- Rename the files in the source directory. You must specify a file name suffix that the file ingestion and replication task adds to the file name when renaming the files. Enter one of the following variables:
- ($date)
- ($time)
- ($timestamp)
- ($runId)
- Archive the files to a different location. You must specify an archive directory which is the absolute path or relative path from the source file system.
Advanced FTPS V2 source properties
When you define a file ingestion and replication task with an Advanced FTPS V2 source, you must enter source properties on the Source tab of the task wizard. The options vary based on the file pickup method that you select for the task.
Note:
You can overwrite the file name pattern, folder, and table parameters, and define your own variable for sources by using the job resource of the File Ingestion and Replication REST API. For more information, see Jobs.
The following table describes the source options:
Option
Description
File Pickup
The file ingestion and replication task supports the following file pickup methods:
- By Pattern. The file ingestion and replication task picks up files by pattern.
- By File List. The file ingestion and replication task picks up files based on a file list.
Source Directory
Directory from where files are transferred. The default value is the source directory specified in the connection.
You can enter a relative path to the source file system. To enter a relative path, start the path with a period, followed by a slash (./). The path is relative to the source directory specified in the connection.
Add Parameters
Create an expression to add it as a Source Directory parameter. For more information, see Source and target parameters.
Include files from sub-folders
This applies when File Pickup is By Pattern. Transfer files from all subfolders under the defined source directory.
File Pattern
This applies when File Pickup is By Pattern. File name pattern to use for selecting the files to transfer. The pattern can be a regular expression or a pattern with wildcard characters.
The following wildcard characters are allowed:
- An asterisk (*) to represent any number of characters.
- A question mark (?) to represent a single character.
For example, you can specify the following regular expression:
([a-zA-Z0-9\s_\\.\-\(\):])+(.doc|.docx|.pdf)$
File Date
This applies when File Pickup is By Pattern. A date and time expression for filtering the files to transfer.
Select one of the following options:
- Greater than or Equal. Filters files that are modified on or after the specified date and time.
To specify a date, click the calendar. To specify a time, click the clock.
- Less than or Equal. Filters files that are modified before or on the specified date and time.
- Equal. Filters files that are modified on the specified date and time.
Click the calendar to select the date and the clock to select the time.
- Days before today. Filters files that are modified within the specified number of days until the current date (today). Enter the number of days. The current date calculation starts from 00:00 hours.
For example, if you schedule the file ingestion and replication task to run weekly and want to filter for the files that were modified in the previous week, set Days before today to 7. The task will pick up any file with a date between 7 days ago and the date on which it runs.
Time Zone
This applies when File Pickup is By Pattern. If you selected a File Date option, enter the time zone of the location where the files are located.
File Size
This applies when File Pickup is By Pattern. Filters the files to transfer based on file size. Enter the file size, select the file size unit, and filter options.
Select one of the following filter options:
- Greater than or Equal. Filters files that are greater than or equal to the specified size.
- Less than or Equal. Filters files that are less than or equal to the specified size.
- Equal. Filters files that have the specified size.
File path containing the list of files
This applies when File Pickup is By File List. This applies when File Pickup is By File List. Select this option to provide the file path that contains the list of files to pick up. Ensure that you enter a comma-separated list of file names in the file.
File list
This applies when File Pickup is By File List. This applies when File Pickup is By File List. Select this option to provide the list of files to pick up and enter a comma-separated list of file names.
Skip Duplicate Files
Indicates whether to skip duplicate files. If you select this option, the file ingestion and replication task does not transfer files that have the same name and file size as another file. The file ingestion and replication task marks these files as duplicate in the job log. If you do not select this option, the task transfers all files, even files with duplicate names and creation dates.
Check file stability
Indicates whether to verify that a file is stable before a file ingestion and replication task attempts to pick it. The task skips unstable files it detects in the current run.
Stability check interval
This applies when you enable the Check file stability option. Time in seconds that a file ingestion and replication task waits to check the file stability.
For example, if the stability time is 15 seconds, the file ingestion and replication task detects all the files in the source folder that match the defined file pattern, it waits for 15 seconds, and then it processes only the stable files.
The interval ranges between 10 seconds to 300 seconds. Default is 10 seconds.
Batch Size
The number of files a file ingestion and replication task can transfer in a batch.
Default is 5. The maximum number of files you can transfer in a batch is 20.
Transfer Mode
File transfer mode. Select one of the following modes:
- Auto. File Ingestion and Replication determines the transfer mode.
- ASCII.
- Binary.
Note:
If a binary file transfer is interrupted due to a network disruption, the file event displays an interrupted status. Run the file ingestion and replication job again to resume the transfer of the interrupted files.
After File Pickup
Determines what to do with the source files after the files are transferred.
Select one of the following options:
- Keep the files in the source directory.
- Delete the files from the source directory.
- Rename the files in the source directory. You must specify a file name suffix that the file ingestion and replication task adds to the file name when renaming the files. Enter one of the following variables:
- ($date)
- ($time)
- ($timestamp)
- ($runId)
- Archive the files to a different location. You must specify an archive directory which is the absolute path or relative path from the source file system.
Advanced SFTP V2 source properties
When you define a file ingestion and replication task with an Advanced SFTP V2 source, you must enter source options on the Source tab of the task wizard. The options vary based on the file pickup method that you select for the task.
Note:
You can overwrite the file name pattern, folder, and table parameters, and define your own variable for sources by using the job resource of the File Ingestion and Replication REST API. For more information, see Jobs.
The following table describes the source options:
Option
Description
File Pickup
The file ingestion and replication task supports the following file pickup methods:
- By Pattern. The file ingestion and replication task picks up files by pattern.
- By File List. The file ingestion and replication task picks up files based on a file list.
Source Directory
Directory from where files are transferred. The default value is the source directory specified in the connection.
You can enter a relative path to the source file system. To enter a relative path, start the path with a period, followed by a slash (./). The path is relative to the source directory specified in the connection.
This applies when File Pickup is By Pattern. Transfer files from all subfolders under the defined source directory.
File Pattern
This applies when File Pickup is By Pattern. File name pattern to use for selecting the files to transfer. The pattern can be a regular expression or a pattern with wildcard characters.
The following wildcard characters are allowed:
- An asterisk (*) to represent any number of characters.
- A question mark (?) to represent a single character.
For example, you can specify the following regular expression:
([a-zA-Z0-9\s_\\.\-\(\):])+(.doc|.docx|.pdf)$
File Date
This applies when File Pickup is By Pattern. A date and time expression for filtering the files to transfer.
Select one of the following options:
- Greater than or Equal. Filters files that are modified on or after the specified date and time.
To specify a date, click the calendar. To specify a time, click the clock.
- Less than or Equal. Filters files that are modified before or on the specified date and time.
- Equal. Filters files that are modified on the specified date and time.
Click the calendar to select the date and the clock to select the time.
- Days before today. Filters files that are modified within the specified number of days until the current date (today). Enter the number of days. The current date calculation starts from 00:00 hours.
For example, if you schedule the file ingestion and replication task to run weekly and want to filter for the files that were modified in the previous week, set Days before today to 7. The task will pick up any file with a date between 7 days ago and the date on which it runs.
Time Zone
This applies when File Pickup is By Pattern. If you selected a File Date option, enter the time zone of the location where the files are located.
File Size
This applies when File Pickup is By Pattern. Filters the files to transfer based on file size. Enter the file size, select the file size unit, and filter options.
Select one of the following filter options:
- Greater than or Equal. Filters files that are greater than or equal to the specified size.
- Less than or Equal. Filters files that are less than or equal to the specified size.
- Equal. Filters files that have the specified size
File path containing the list of files
This applies when File Pickup is By File List. Select this option to provide the file path that contains the list of files to pick up. Ensure that you enter a comma-separated list of file names in the file.
File list
This applies when File Pickup is By File List. Select this option to provide the list of files to pick up and enter a comma-separated list of file names.
Skip Duplicate Files
Indicates whether to skip duplicate files. If you select this option, the file ingestion and replication task does not transfer files that have the same name and file size as another file. The file ingestion and replication task marks these files as duplicate in the job log. If you do not select this option, the task transfers all files, including files with duplicate names.
Check file stability
Indicates whether to verify that a file is stable before a file ingestion and replication task attempts to pick it. The task skips unstable files it detects in the current run.
Stability check interval
This applies when you enable the Check file stability option. Time in seconds that a file ingestion and replication task waits to check the file stability.
For example, if the stability time is 15 seconds, the file ingestion and replication task detects all the files in the source folder that match the defined file pattern, it waits for 15 seconds, and then it processes only the stable files.
The interval ranges between 10 seconds to 300 seconds. Default is 10 seconds.
Batch Size
The number of files a file ingestion and replication task can transfer in a batch.
Default is 5. The maximum number of files you can transfer in a batch is 20.
After File Pickup
Determines what to do with the source files after the files are transferred.
Select one of the following options:
- Keep the files in the source directory.
- Delete the files from the source directory.
- Rename the files in the source directory. You must specify a file name suffix that the file ingestion and replication task adds to the file name when renaming the files. Enter one of the following variables:
- ($date)
- ($time)
- ($timestamp)
- ($runId)
- Archive the files to a different location. You must specify an archive directory which is the absolute path or relative path from the source file system.
Amazon S3 V2 source properties
When you define a file ingestion and replication task with an Amazon S3 V2 source, you must enter source options on the Source tab of the task wizard. The options vary based on the file pickup method that you select for the task.
Note:
You can overwrite the file name pattern, folder, and table parameters, and define your own variable for sources by using the job resource of the File Ingestion and Replication REST API. For more information, see Jobs.
The following table describes the source options:
Option
Description
File Pickup
The file ingestion and replication task supports the following file pickup methods:
- By Pattern. The file ingestion and replication task picks up files by pattern.
- By File List. The file ingestion and replication task picks up files based on a file list.
Source Directory
Amazon S3 folder path from where files are transferred, including the bucket name. The default value is the folder path value specified in the connection properties.
You can enter a relative path to the source file system. To enter a relative path, start the path with a period, followed by a slash (./). The path is relative to the source directory specified in the connection.
Note:
Ensure that you have sufficient privileges to access the bucket and specific folders.
Add Parameters
Create an expression to add it as a Folder Path parameter. For more information, see Source and target parameters.
Include files from sub-folders
This applies when File Pickup is By Pattern. Transfer files from all subfolders under the defined source directory.
File Pattern
This applies when File Pickup is By Pattern. File name pattern used to select the files to transfer.
In the pattern, you can use the following wildcard characters:
- An asterisk (*) to represent any number of characters.
- A question mark (?) to represent a single character.
File Date
This applies when File Pickup is By Pattern. A date and time expression for filtering the files to transfer.
Select one of the following options:
- Greater than or Equal. Filters files that are modified on or after the specified date and time.
To specify a date, click the calendar. To specify a time, click the clock.
- Less than or Equal. Filters files that are modified before or on the specified date and time.
- Equal. Filters files that are modified on the specified date and time.
Click the calendar to select the date and the clock to select the time.
- Days before today. Filters files that are modified within the specified number of days until the current date. Enter the number of days. The current date calculation starts from 00:00 hours.
For example, if you schedule the file ingestion and replication task to run weekly and want to filter for the files that were modified in the previous week, set Days before today to 7. The task will pick up any file with a date between 7 days ago and the date on which it runs.
Time Zone
This applies when File Pickup is By Pattern. If you selected a File Date option, enter the time zone of the location where the files are located.
File Size
This applies when File Pickup is By Pattern. Filters the files to transfer based on file size. Enter the file size, select the file size unit, and filter options.
Select one of the following filter options:
- Greater than or Equal. Filters files that are greater than or equal to the specified size.
- Less than or Equal. Filters files that are less than or equal to the specified size.
- Equal. Filters files that have the specified size.
The file path containing the list of files
This applies when File Pickup is By File List. Select this option to provide the path that contains the list of files to pick up and enter the file path. Ensure that you enter a comma-separated list of file names in the file.
File list
This applies when File Pickup is By File List. Select this option to provide the list of files to pick up and enter a comma-separated list of file names.
Skip Duplicate Files
Indicates whether to skip duplicate files. If you select this option, the file ingestion and replication task does not transfer files that have the same name and file size as another file. The file ingestion and replication task marks these files as duplicate in the job log. If you do not select this option, the task transfers all files, even files with duplicate names and creation dates.
Check file stability
Indicates whether to verify that a file is stable before a file ingestion and replication task attempts to pick it. The task skips unstable files it detects in the current run.
Stability check interval
This applies when you enable the Check file stability option. Time in seconds that a file ingestion and replication task waits to check the file stability.
For example, if the stability time is 15 seconds, the file ingestion and replication task detects all the files in the source folder that match the defined file pattern, it waits for 15 seconds, and then it processes only the stable files.
The interval ranges between 10 seconds to 300 seconds. Default is 10 seconds.
Batch Size
The number of files a file ingestion and replication task can transfer in a batch.
Default is 5.
The maximum value of the batch depends on whether the files transfer through an intermediate staging server.
A file ingestion and replication task does not transfer files through an intermediate staging server if the files are transferred from the following source to target endpoints:
- Amazon S3 to Amazon Redshift, if you choose to transfer files without using intermediate staging.
- Amazon S3 to Snowflake
Consider the following guidelines when you define a batch size:
- If files are transferred from the source to target without an intermediate staging server, the maximum number of files you can transfer in a batch is 8000.
- If files pass through an intermediate staging server, the maximum number of files you can transfer in a batch is 20.
- If you transfer files from any source to a Snowflake target, the maximum number of files you can transfer in a batch is 1000.
File Encryption Type
Type of Amazon S3 file encryption to use during file transfer.
Select one of the following options:
- None. Files are not encrypted during file transfer. Default is None.
- S3 server-side encryption. Amazon S3 encrypts the file by using AWS-managed encryption keys.
- S3 client-side encryption. Ensure that unrestricted policies are implemented for the AgentJVM, and that the master symmetric key for the connection is set.
S3 Accelerated Transfer
Select whether to use Amazon S3 Transfer Acceleration on the S3 bucket.
To use Transfer Acceleration, accelerated transfer must be enabled for the bucket. The following options are available:
- Disabled. Do not use Amazon S3 Transfer Acceleration.
- Accelerated. Use Amazon S3 Transfer Acceleration.
- Dualstack Accelerated. Use Amazon S3 Transfer Acceleration on a dual-stack endpoint.
Minimum Download Part Size
Minimum download part size in megabytes when downloading a large file as a set of multiple independent parts.
Multipart Download Threshold
Multipart download minimum threshold in megabytes that is used to determine when to upload objects in multiple parts in parallel.
After File Pickup
Determines what to do with the source files after the task streams them to the target.
Select one of the following options:
- Keep the files in the source directory.
- Delete the files from the source directory.
- Rename the files in the source directory. You must specify a file name suffix that the file ingestion and replication task adds to the file name when renaming the files. Enter one of the following variables:
- ($date)
- ($time)
- ($timestamp)
- ($runId)
- Archive the files to a different location. You must specify an archive directory which is the absolute path or relative path to the source file system.
Cloud Integration Hub source properties
When you define a file ingestion and replication task with a Cloud Integration Hub source, you must enter source options on the Source tab of the task wizard.
The following table describes the source options:
Option
Description
File Pickup
The file ingestion and replication task picks up files based on a file list. The file list consist of a comma-separated list of file names. The file list option populates automatically from the Cloud Integration Hub subscription and you can't edit it.
Batch Size
The number of files a file ingestion and replication task can transfer in a batch.
Default is 5. The maximum number of files you can transfer in a batch is 20.
After File Pickup
Determines what to do with the source files after the files are transferred.
Select one of the following options:
- Keep the files in the source directory.
- Delete the files from the source directory.
- Rename the files in the source directory. You must specify a file name suffix that the file ingestion and replication task adds to the file name when renaming the files. Enter one of the following variables:
- ($date)
- ($time)
- ($timestamp)
- ($runId)
- Archive the files to a different location. You must enter the absolute path or relative path on the source file system.
Note:
•You can't configure a file ingestion and replication task using Cloud Integration Hub as both source and target.
•You can't manually run a file ingestion and replication task with Cloud Integration Hub as a source or a target. You must run the file ingestion and replication task from the Cloud Integration Hub service. For more information about running the task from the Cloud Integration Hub service, see Cloud Integration Hub user guide.
File listener source properties
Configure a file listener as a source type when you use the file listener to trigger the file ingestion and replication task.
To configure a file listener as a source, you must create a file listener in the Data Integration service. For more information about creating a file listener, see Components in the Data Integration help.
Note:
You cannot run the file ingestion and replication task with a file listener as a source from the file ingestion and replication user interface. A file ingestion and replication task with a file listener as a source runs automatically when the file listener starts.
The following table describes the source options:
Option
Description
File Pattern
File name pattern to use for selecting the files to transfer. The pattern can be a regular expression or a pattern with wildcard characters.
The following wildcard characters are allowed:
- An asterisk (*) to represent any number of characters.
- A question mark (?) to represent a single character.
For example, you can specify the following regular expression:
([a-zA-Z0-9\s_\\.\-\(\):])+(.doc|.docx|.pdf)$
Note:
File names cannot be more than 128 characters.
File Date
A date and time expression for filtering the files to transfer.
Select one of the following options:
- Greater than or Equal. Filters files that are modified on or after the specified date and time.
To specify a date, click the calendar. To specify a time, click the clock.
- Less than or Equal. Filters files that are modified before or on the specified date and time.
- Equal. Filters files that are modified on the specified date and time.
Click the calendar to select the date and the clock to select the time.
- Days before today. Filters files that are modified within the specified number of days until the current date (today). Enter the number of days. The current date calculation starts from 00:00 hours.
For example, if you schedule the file ingestion and replication task to run weekly and want to filter for the files that were modified in the previous week, set Days before today to 7. The task will pick up any file with a date between 7 days ago and the date on which it runs.
Time Zone
If you selected a File Date option, enter the time zone of the location where the files are located.
File Size
Filters the files to transfer based on file size. Enter the file size, select the file size unit, and filter options.
Select one of the following filter options:
- Greater than or Equal. Filters files that are greater than or equal to the specified size.
- Less than or Equal. Filters files that are less than or equal to the specified size.
- Equal. Filters files that have the specified size.
Skip Duplicate Files
Indicates whether to skip duplicate files. If you select this option, the file ingestion and replication task does not transfer files that have the same name and file size as another file. The file ingestion and replication task marks these files as duplicate in the job log. If you do not select this option, the task transfers all files, even files with duplicate names and creation dates.
Batch Size
The number of files a file ingestion and replication task can transfer in a batch.
Default is 5.
After File Pickup
Determines what to do with the source files after the files are transferred.
Select one of the following filter options:
- Keep the files in the source directory.
- Delete the files from the source directory.
- Rename the files in the source directory. You must specify a file name suffix that the file ingestion and replication task adds to the file name when renaming the files. Enter one of the following variables:
- ($date)
- ($time)
- ($timestamp)
- ($runId)
- Archive the files to a different location. You must specify an archive directory.
Google Cloud Storage V2 source properties
When you define a file ingestion and replication task with a Google Cloud Storage V2 source, you must enter source options on the Source tab of the task wizard.
Note:
You can overwrite the file name pattern, folder, and table parameters, and define your own variable for sources by using the job resource of the File Ingestion and Replication REST API. For more information, see Jobs.
The following table describes the source options:
Option
Description
File Pickup
The file ingestion and replication task supports the following file pickup methods:
- By Pattern. The file ingestion and replication task picks up files by pattern.
- By File List. The file ingestion and replication task picks up files based on a file list.
Source Directory
Directory from where files are transferred.
You can enter a relative path to the source file system. To enter a relative path, start the path with a period, followed by a slash (./). The path is relative to the source directory specified in the connection.
Add Parameters
Create an expression to add it as a Source Directory parameter. For more information, see Source and target parameters.
Include files from sub-folders
Transfer files from all subfolders under the defined source directory.
File Pattern
File name pattern to use for selecting the files to transfer. The pattern can be a regular expression or a pattern with wildcard characters.
The following wildcard characters are allowed:
- An asterisk (*) to represent any number of characters.
- A question mark (?) to represent a single character.
For example, you can specify the following regular expression:
([a-zA-Z0-9\s_\\.\-\(\):])+(.doc|.docx|.pdf)$
File Date
A date and time expression for filtering the files to transfer.
Select one of the following options:
- Greater than or Equal. Filters files that are modified on or after the specified date and time.
To specify a date, click the calendar. To specify a time, click the clock.
- Less than or Equal. Filters files that are modified before or on the specified date and time.
- Equal. Filters files that are modified on the specified date and time.
Click the calendar to select the date and the clock to select the time.
- Days before today. Filters files that are modified within the specified number of days until the current date (today). Enter the number of days. The current date calculation starts from 00:00 hours.
For example, if you schedule the file ingestion and replication task to run weekly and want to filter for the files that were modified in the previous week, set Days before today to 7. The task will pick up any file with a date between 7 days ago and the date on which it runs.
Time Zone
If you selected a File Date option, enter the time zone of the location where the files are located.
File Size
Filters the files to transfer based on file size. Enter the file size, select the file size unit, and filter options.
Select one of the following filter options:
- Greater than or Equal. Filters files that are greater than or equal to the specified size.
- Less than or Equal. Filters files that are less than or equal to the specified size.
- Equal. Filters files that have the specified size.
Skip Duplicate Files
Indicates whether to skip duplicate files. If you select this option, the file ingestion and replication task does not transfer files that have the same name and file size as another file. The file ingestion and replication task marks these files as duplicate in the job log. If you do not select this option, the task transfers all files, even files with duplicate names and creation dates.
Check file stability
Indicates whether to verify that a file is stable before a file ingestion and replication task attempts to pick it. The task skips unstable files it detects in the current run.
Stability check interval
This applies when you enable the Check file stability option. Time in seconds that a file ingestion and replication task waits to check the file stability.
For example, if the stability time is 15 seconds, the file ingestion and replication task detects all the files in the source folder that match the defined file pattern, waits for 15 seconds, and processes only the stable files.
The interval ranges between 10 seconds to 300 seconds. Default is 10 seconds.
Batch Size
The number of files a file ingestion and replication task can transfer in a batch.
Default is 5.
The maximum batch size varies, based on the following conditions:
- If files are transferred from the source to target without an intermediate staging server, the maximum number of files you can transfer in a batch is 8000.
- If files pass through an intermediate staging server, the maximum number of files you can transfer in a batch is 20.
Note:
If you transfer files from Google Cloud Storage to Google BigQuery, the task transfers files with no intermediate staging server.
After File Pickup
Determines the actions to be performed on the source files after the files transfer. The following options are available:
- Keep files in the source directory.
- Delete files from the source directory.
- Rename the files in the source directory. You must specify a file name suffix that the file ingestion and replication task adds to the file name when renaming the files. Enter one of the following variables:
- ($date)
- ($time)
- ($timestamp)
- ($runId)
- Archive the files to a different location. You must specify an archive directory, which is the absolute path or relative path from the source file system. An archive directory helps you maintain a sub-folder structure from the source file system.
For example, if /root/archive is the archive directory, /root/test is the source directory, sub1 and sub2 are the directories within the source directory, and you choose to include files from sub-folders, then the folder structure of the archive directory is /root/archive/sub1, /root/archive/sub2.
Hadoop Files V2 source properties
When you define a file ingestion and replication task with an Hadoop Files V2 source, you must enter source options on the Source tab of the task wizard. The options vary based on the file pickup method that you select for the task.
Note:
You can overwrite the file name pattern, folder, and table parameters, and define your own variable for sources by using the job resource of the File Ingestion and Replication REST API. For more information, see Jobs.
The following table describes the source options:
Option
Description
File Pickup
The file ingestion and replication task supports the following file pickup methods:
- By Pattern. The file ingestion and replication task picks up files by pattern.
- By File List. The file ingestion and replication task picks up files based on a file list.
Source Directory
Directory from where files are transferred.
Add Parameters
Create an expression to add it as a Source Directory parameter. For more information, see Source and target parameters.
Include files from sub folders
This applies when File Pickup is By Pattern. Transfer files from all subfolders under the defined source directory.
File Pattern
This applies when File Pickup is By Pattern. File name pattern used to select the files to transfer. Based on the file pattern that you have selected, enter the file name patterns.
Select one of the following file patterns:
- Wildcard. Use the following wildcard character filters:
- An asterisk (*) to represent any number of characters.
- A question mark (?) to represent a single character.
- Regex. Use regular expression to match the pattern type. Consider the following samples:
- ^(?!.*(?:out|baz|foo)).*$ all except
Identifies all files except for files whose name contains out, foo, and baz.
- ([a-zA-Z0-9\s_\\.\-\(\):])+(.doc|.docx|.pdf)$
Identifies all files that have an extension of doc, docx, or pdf.
- ^(?!out).*\.txt$
Identifies all text files except for files whose name contains out.txt.
File Date
This applies when File Pickup is By Pattern. A date and time expression for filtering the files to transfer.
Select one of the following options:
- Greater than or Equal. Filters files that are modified on or after the specified date and time.
To specify a date, click the calendar. To specify a time, click the clock.
- Less than or Equal. Filters files that are modified before or on the specified date and time.
- Equal. Filters files that are modified on the specified date and time.
Click the calendar to select the date and the clock to select the time.
- Days before today. Filters files that are modified within the specified number of days until the current date (today). Enter the number of days. The current date calculation starts from 00:00 hours.
For example, if you schedule the file ingestion and replication task to run weekly and want to filter for the files that were modified in the previous week, set Days before today to 7. The task will pick up any file with a date between 7 days ago and the date on which it runs.
Time Zone
This applies when File Pickup is By Pattern. If you selected a File Date option, enter the time zone of the location where the files are located.
File Size
This applies when File Pickup is By Pattern. Filters the files to transfer based on file size. Enter the file size, select the file size unit, and filter options.
Select one of the following filter options:
- Greater than or Equal. Filters files that are greater than or equal to the specified size.
- Less than or Equal. Filters files that are less than or equal to the specified size.
- Equal. Filters files that have the specified size.
File path containing the list of files
This applies when File Pickup is By File List. Select this option to provide the file path that contains the list of files to pick up. Ensure that you enter a comma-separated list of file names in the file.
File list
This applies when File Pickup is By File List. Select this option to provide the list of files to pick up and enter a comma-separated list of file names.
Skip Duplicate Files
Indicates whether to skip duplicate files. If you select this option, the file ingestion and replication task does not transfer files that have the same name and file size as another file. The file ingestion and replication task marks these files as duplicate in the job log. If you do not select this option, the task transfers all files, even files with duplicate names and creation dates.
Check file stability
Indicates whether to verify that a file is stable before a file ingestion and replication task attempts to pick it. The task skips unstable files it detects in the current run.
Stability check interval
This applies when you enable the Check file stability option. Time in seconds that a file ingestion and replication task waits to check the file stability.
For example, if the stability time is 15 seconds, the file ingestion and replication task detects all the files in the source folder that match the defined file pattern, waits for 15 seconds, and processes only the stable files.
The interval ranges between 10 seconds to 300 seconds. Default is 10 seconds.
Batch Size
The number of files a file ingestion and replication task can transfer in a batch.
Default is 5.
Local folder source properties
When you define a file ingestion and replication task with an local folder source, you must enter source properties on the Source tab of the task wizard. The options vary based on the file pickup method that you select for the task.
Note:
You can overwrite the file name pattern, folder, and table parameters, and define your own variable for sources by using the job resource of the File Ingestion and Replication REST API. For more information, see Jobs.
The following table describes the source options:
Option
Description
File Pickup
The file ingestion and replication task supports the following file pickup methods:
- By Pattern. The file ingestion and replication task picks up files by pattern.
- By File List. The file ingestion and replication task picks up files based on a file list.
Source Directory
Directory from where files are transferred. The Secure Agent must be able to access the directory.
The use of slashes around the source folder path differs between connectors. Using slashes incorrectly will result in connection failures. For more information, see the Knowledge Base article 625869.
Note:
File listener can access files and directories on network shares with support for NFS and CIFS.
Add Parameters
Create an expression to add it as a Source Directory parameter. For more information, see Source and target parameters.
Include files from sub-folders
This applies when File Pickup is By Pattern. Transfer files from all subfolders under the defined source directory.
File Pattern
This applies when File Pickup is By Pattern. File name pattern used to select the files to transfer. Based on the file pattern that you have selected, enter the file name patterns.
The following file patterns are available:
- Wildcard. Use the following wildcard character filters:
- An asterisk (*) matches any number of characters.
- A question mark (?) matches a single character.
- Regex. Use regular expression to match the pattern type. Consider the following samples:
- ^(?!.*(?:out|baz|foo)).*$ all except
Identifies all files except for files whose name contains out, foo, and baz.
- ([a-zA-Z0-9\s_\\.\-\(\):])+(.doc|.docx|.pdf)$
Identifies all files that have an extension of doc, docx, or pdf.
- ^(?!out).*\.txt$
Identifies all text files except for files whose name contains out.txt.
File Date
This applies when File Pickup is By Pattern. A date and time expression for filtering the files to transfer.
Select one of the following options:
- Greater than or Equal. Filters files that are modified on or after the specified date and time.
To specify a date, click the calendar. To specify a time, click the clock.
- Less than or Equal. Filters files that are modified before or on the specified date and time.
- Equal. Filters files that are modified on the specified date and time.
Click the calendar to select the date and the clock to select the time.
- Days before today. Filters files that are modified within the specified number of days until the current date (today). Enter the number of days. The current date calculation starts from 00:00 hours.
For example, if you schedule the file ingestion and replication task to run weekly and want to filter for the files that were modified in the previous week, set Days before today to 7. The task will pick up any file with a date between 7 days ago and the date on which it runs.
Time Zone
This applies when File Pickup is By Pattern. If you selected a File Date option, enter the time zone of the location where the files are located.
File Size
This applies when File Pickup is By Pattern. Filters the files to transfer based on file size. Enter the file size, select the file size unit, and filter options.
Select one of the following options:
- Greater than or Equal. Filters files that are greater than or equal to the specified size.
- Less than or Equal. Filters files that are less than or equal to the specified size.
- Equal. Filters files that have the specified size.
File path containing the list of files
This applies when File Pickup is By File List. Select this option to provide the file path that contains the list of files to pick up. Ensure that you enter a comma-separated list of file names in the file.
File list
This applies when File Pickup is By File List. Select this option to provide the list of files to pick up and enter a comma-separated list of file names.
Skip Duplicate Files
Indicates whether to skip duplicate files. If you select this option, the file ingestion and replication task does not transfer files that have the same name and file size as another file. The file ingestion and replication task marks these files as duplicate in the job log. If you do not select this option, the task transfers all files, even files with duplicate names and creation dates.
Check file stability
Indicates whether to verify that a file is stable before a file ingestion and replication task attempts to pick it. The task skips unstable files it detects in the current run.
Stability check interval
This applies when you enable the Check file stability option. Time in seconds that a file ingestion and replication task waits to check the file stability.
For example, if the stability time is 15 seconds, the file ingestion and replication task detects all the files in the source folder that match the defined file pattern, waits for 15 seconds, and processes only the stable files.
The interval ranges between 10 seconds to 300 seconds. Default is 10 seconds.
Batch Size
The maximum number of files a file ingestion and replication task transfers in a batch.
Default is 5. The maximum number of files you can transfer in a batch is 20.
The maximum batch size varies, based on the following conditions:
- If the task transfers files from source to target with no intermediate staging, the maximum number of files the task can transfer in a batch is 8000.
- If the task transfers files from source to target with intermediate staging, the maximum number of files the task can transfer in a batch is 20.
Consider the following guidelines when you define the batch size:
- The task transfers files with no intermediate staging in the following scenarios:
- File transfers from Amazon S3 to Amazon Redshift when Amazon Redshift Connector is configured to upload files with no intermediate staging
- File transfers from Google Cloud Storage to Google BigQuery
- File transfers from Azure Blob to Microsoft Azure Data Warehouse
- File transfers from Amazon S3 and from Azure Blob to Snowflake
- When you use a command line to transfer files, the task transfers files with intermediate staging.
After File Pickup
Determines what to do with source files after the files transfer.
The following options are available:
- Keep files in the source directory.
- Delete files from the source directory.
- Rename the files in the source directory. You must specify a file name suffix that the file ingestion and replication task adds to the file name when renaming the files. Enter one of the following variables:
- ($date)
- ($time)
- ($timestamp)
- ($runId)
- Archive the files to a different location. You must specify an absolute path for the archive directory.
Microsoft Azure Blob Storage V3 source properties
When you define a file ingestion and replication task with an Microsoft Azure Blob Storage source, you must enter source options on the Source tab of the task wizard. The options vary based on the file pickup method that you select for the task.
Note:
You can overwrite the file name pattern, folder, and table parameters, and define your own variable for sources by using the job resource of the File Ingestion and Replication REST API. For more information, see Jobs.
The following table describes the source options:
Advance Source Property
Description
File Pickup
The file ingestion and replication task supports the following file pickup methods:
- By Pattern. The file ingestion and replication task picks up files by pattern.
- By File List. The file ingestion and replication task picks up files based on a file list.
Source Directory
Microsoft Azure Blob Storage directory from where files are transferred, including the container name. The default value is the container path specified in the connection.
You can enter a relative path to the source file system. To enter a relative path, start the path with a period, followed by a slash (./). The path is relative to the source directory specified in the connection.
Add Parameters
Create an expression to add it as a Folder Path parameter. For more information, see Source and target parameters.
Include files from sub-folders
This applies when File Pickup is By Pattern. Transfer files from sub-folders present in the folder path.
File Pattern
This applies when File Pickup is By Pattern. File name pattern used to select the files to transfer. You can use a regular expression or wildcard characters.
The following wildcard characters are allowed:
- An asterisk (*) to represent any number of characters.
- A question mark (?) to represent a single character.
For example, you can specify the following regular expression:
([a-zA-Z0-9\s_\\.\-\(\):])+(.doc|.docx|.pdf)$
File Date
This applies when File Pickup is By Pattern. A date and time expression for filtering the files to transfer.
Select one of the following options:
- Greater than or Equal. Filters files that are modified on or after the specified date and time.
To specify a date, click the calendar. To specify a time, click the clock.
- Less than or Equal. Filters files that are modified before or on the specified date and time.
- Equal. Filters files that are modified on the specified date and time.
Click the calendar to select the date and the clock to select the time.
- Days before today. Filters files that are modified within the specified number of days until the current date (today). Enter the number of days. The current date calculation starts from 00:00 hours.
For example, if you schedule the file ingestion and replication task to run weekly and want to filter for the files that were modified in the previous week, set Days before today to 7. The task will pick up any file with a date between 7 days ago and the date on which it runs.
Time Zone
This applies when File Pickup is By Pattern. If you selected a File Date option, enter the time zone of the location where the files are located.
File Size
This applies when File Pickup is By Pattern. Filters the files to transfer based on file size. Enter the file size, select the file size unit, and filter options.
Select one of the following options:
- Greater than or Equal. Filters files that are greater than or equal to the specified size.
- Less than or Equal. Filters files that are less than or equal to the specified size.
- Equal. Filters files that have the specified size.
File path containing the list of files
This applies when File Pickup is By File List. Select this option to provide the file path that contains the list of files to pick up. Ensure that you enter a comma-separated list of file names in the file.
File list
This applies when File Pickup is By File List. Select this option to provide the list of files to pick up and enter a comma-separated list of file names.
Skip Duplicate Files
Do not transfer duplicate files. If files with the same name and file size were transferred by the same file ingestion and replication task, the task does not transfer them again, and the files are marked as duplicate in the job log. If this option is not selected the task transfers all files.
Check file stability
Indicates whether to verify that a file is stable before a file ingestion and replication task attempts to pick it. The task skips unstable files it detects in the current run.
Stability check interval
This applies when you enable the Check file stability option. Time in seconds that a file ingestion and replication task waits to check the file stability.
For example, if the stability time is 15 seconds, the file ingestion and replication task detects all the files in the source folder that match the defined file pattern, it waits for 15 seconds, and then it processes only the stable files.
The interval ranges between 10 seconds to 300 seconds. Default is 10 seconds.
Batch Size
The number of files a file ingestion and replication task can transfer in a batch.
Default is 5.
The maximum batch size varies, based on the following conditions:
- If files are transferred from the source to target without an intermediate staging server, the maximum number of files the task can transfer in a batch is 8000.
- If files pass through an intermediate staging server, the maximum number of files the task can transfer in a batch is 20.
- If the task transfers files from any source to a Snowflake target, the maximum number of files the task can transfer in a batch is 1000.
Note:
If you transfer files from Azure Blob Storage to Azure SQL Data Warehouse and Snowflake, the task transfers files with no intermediate staging.
Microsoft Azure Data Lake Storage Gen2 source properties
In a file ingestion and replication task, you can configure the Microsoft Azure Data Lake Storage Gen2 source properties to transfer files from a Microsoft Azure Data Lake Storage Gen2 source to a Microsoft Azure Data Lake Storage Gen2 target or any target that a file ingestion and replication task supports. The source options vary based on the file pickup method that you select for the task.
When the task transfers files from a Microsoft Azure Data Lake Storage Gen2 source to a Databricks target, the files must be of Parquet format and must have the same schema as the Databricks target.
Note:
You can overwrite the file name pattern, folder, and table parameters, and define your own variable for sources by using the job resource of the File Ingestion and Replication REST API. For more information, see Jobs.
The following table describes the source options:
Advance Source Property
Description
File Pickup
The file ingestion and replication task supports the following file pickup methods:
- By Pattern. The file ingestion and replication task picks up files by pattern.
- By File List. The file ingestion and replication task picks up files based on a file list.
Source Directory
Microsoft Azure Data Lake Storage Gen2 folder path from where files are transferred. The default value is the container path specified in the connection. The source directory must start with a forward slash (/).
You can enter a relative path to the source file system. To enter a relative path, start the path with a period, followed by a slash (./). The path is relative to the source directory specified in the connection.
Add Parameters
Create an expression to add it as a Source Directory parameter. For more information, see Source and target parameters.
Include files from sub-folders
This applies when File Pickup is By Pattern. Transfer files from sub-folders present in the folder path.
File Pattern
This applies when File Pickup is By Pattern. File name pattern used to select the files to transfer. You can use a regular expression or wildcard characters.
The following wildcard characters are allowed:
- An asterisk (*) to represent any number of characters.
- A question mark (?) to represent a single character.
For example, you can specify the following regular expression:
([a-zA-Z0-9\s_\\.\-\(\):])+(.doc|.docx|.pdf)$
Note:
File names must exclude special characters that Microsoft does not support to avoid task failure.
File Date
This applies when File Pickup is By Pattern. A date and time expression for filtering the files to transfer.
Select one of the following options:
- Greater than or Equal. Filters files that are modified on or after the specified date and time.
To specify a date, click the calendar. To specify a time, click the clock.
- Less than or Equal. Filters files that are modified before or on the specified date and time.
- Equal. Filters files that are modified on the specified date and time.
Click the calendar to select the date and the clock to select the time.
- Days before today. Filters files that are modified within the specified number of days until the current date (today). Enter the number of days. The current date calculation starts from 00:00 hours.
For example, if you schedule the file ingestion and replication task to run weekly and want to filter for the files that were modified in the previous week, set Days before today to 7. The task will pick up any file with a date between 7 days ago and the date on which it runs.
Time Zone
This applies when File Pickup is By Pattern. If you selected a File Date option, enter the time zone of the location where the files are located.
File Size
This applies when File Pickup is By Pattern. Filters the files to transfer based on file size. Enter the file size, select the file size unit, and filter options.
Select one of the following filter options:
- Greater than or Equal. Filters files that are greater than or equal to the specified size.
- Less than or Equal. Filters files that are less than or equal to the specified size.
- Equal. Filters files that have the specified size.
File path containing the list of files
This applies when File Pickup is By File List. Select this option to provide the file path that contains the list of files to pick up. Ensure that you enter a comma-separated list of file names in the file.
File list
This applies when File Pickup is By File List. Select this option to provide the list of files to pick up and enter a comma-separated list of file names.
Skip duplicate files
Do not transfer duplicate files. If files with the same name and file size were transferred by the same file ingestion and replication task, the task does not transfer them again, and the files are marked as duplicate in the job log. If this option is not selected the task transfers all files.
Check file stability
Indicates whether to verify that a file is stable before a file ingestion and replication task attempts to pick it. The task skips unstable files it detects in the current run.
Stability check interval
This applies when you enable the Check file stability option. Time in seconds that a file ingestion and replication task waits to check the file stability.
For example, if the stability time is 15 seconds, the file ingestion and replication task detects all the files in the source folder that match the defined file pattern, it waits for 15 seconds, and then it processes only the stable files.
The interval ranges between 10 seconds to 300 seconds. Default is 10 seconds.
Batch Size
The number of files a file ingestion and replication task can transfer in a batch.
Default is 5.
The maximum batch size varies, based on the following conditions:
- If the task transfers files from source to target with no intermediate staging, the maximum number of files the task can transfer in a batch is 8000.
- If the task transfers files from source to target with intermediate staging, the maximum number of files the task can transfer in a batch is 20.
Note:
If you transfer files from Microsoft Azure Data Lake Storage Gen2 to Azure SQL Data Warehouse, the task transfers files with no intermediate staging.
Block Size (Bytes)
Divides a large file into smaller specified block size. When you read a large file, divide the file into smaller parts and configure concurrent connections to spawn the required number of threads to process data in parallel.
Default is 8388608 bytes (8 MB).
After File Pickup
Determines what to do with source files after the files transfer. The following options are available:
- Keep files in the source directory.
- Delete files from the source directory.
- Rename the files in the source directory. You must specify a file name suffix that the file ingestion and replication task adds to the file name when renaming the files. Enter one of the following variables:
- ($date)
- ($time)
- ($timestamp)
- ($runId)
- Archive the files to a different location. You must specify an archive directory, which must be the absolute path starting with a slash ("/") or a relative path from the source file system. This option allows to maintain a sub-folder structure from the source file system in the archive directory.
For example, if /root/archive is the archive directory, /root/test is the source directory, sub1 and sub2 are the directories within the source directory, and you choose to include files from sub-folders, then the folder structure of archive directory is /root/archive/sub1, /root/archive/sub2.
Microsoft Azure Data Lake Store Gen1 V3 source properties
When you define a file ingestion task with an Microsoft Azure Data Lake Store Gen1 V3 source, you must enter source options on the Source tab of the task wizard. The options vary based on the file pickup method that you select for the task.
Note:
You can overwrite the file name pattern, folder, and table parameters, and define your own variable for sources by using the job resource of the File Ingestion and Replication REST API. For more information, see Jobs.
The following table describes the source options:
Advance Source Property
Description
File Pickup
The file ingestion and replication task supports the following file pickup methods:
- By Pattern. The file ingestion and replication task picks up files by pattern.
- By File List. The file ingestion and replication task picks up files based on a file list.
Source Directory
Microsoft Azure Data Lake Store directory from where files are transferred. The default value is the container path specified in the connection.
You can enter a relative path to the source file system. To enter a relative path, start the path with a period, followed by a slash (./). The path is relative to the source directory specified in the connection.
Add Parameters
Create an expression to add it as a Source Directory parameter. For more information, see Source and target parameters.
Include files from sub-folders
This applies when File Pickup is By Pattern. Transfer files from sub-folders present in the folder path.
File Pattern
This applies when File Pickup is By Pattern. File name pattern to use for selecting the files to transfer. The pattern can be a regular expression or a pattern with wildcard characters.
The following wildcard characters are allowed:
- An asterisk (*) to represent any number of characters.
- A question mark (?) to represent a single character.
For example, you can specify the following regular expression:
([a-zA-Z0-9\s_\\.\-\(\):])+(.doc|.docx|.pdf)$
File Date
This applies when File Pickup is By Pattern. A date and time expression for filtering the files to transfer.
Select one of the following options:
- Greater than or Equal. Filters files that are modified on or after the specified date and time.
To specify a date, click the calendar. To specify a time, click the clock.
- Less than or Equal. Filters files that are modified before or on the specified date and time.
- Equal. Filters files that are modified on the specified date and time.
Click the calendar to select the date and the clock to select the time.
- Days before today. Filters files that are modified within the specified number of days until the current date (today). Enter the number of days. The current date calculation starts from 00:00 hours.
For example, if you schedule the file ingestion and replication task to run weekly and want to filter for the files that were modified in the previous week, set Days before today to 7. The task will pick up any file with a date between 7 days ago and the date on which it runs.
Time Zone
This applies when File Pickup is By Pattern. If you selected a File Date option, enter the time zone of the location where the files are located.
File Size
This applies when File Pickup is By Pattern. Filters the files to transfer based on file size. Enter the file size, select the file size unit, and filter options.
Select one of the following filter options:
- Greater than or Equal. Filters files that are greater than or equal to the specified size.
- Less than or Equal. Filters files that are less than or equal to the specified size.
- Equal. Filters files that have the specified size.
File path containing the list of files
This applies when File Pickup is By File List. Select this option to provide the file path that contains the list of files to pick up. Ensure that you enter a comma-separated list of file names in the file.
File list
This applies when File Pickup is By File List. Select this option to provide the list of files to pick up and enter a comma-separated list of file names.
Skip Duplicate Files
Indicates whether to skip duplicate files. If you select this option, the file ingestion and replication task does not transfer files that have the same name and file size as another file. The file ingestion and replication task marks these files as duplicate in the job log. If you do not select this option, the task transfers all files, even files with duplicate names and creation dates.
Check file stability
Indicates whether to verify that a file is stable before a file ingestion and replication task attempts to pick it. The task skips unstable files it detects in the current run.
Stability check interval
This applies when you enable the Check file stability option. Time in seconds that a file ingestion and replication task waits to check the file stability.
For example, if the stability time is 15 seconds, the file ingestion and replication task detects all the files in the source folder that match the defined file pattern, it waits for 15 seconds, and then it processes only the stable files.
The interval ranges between 10 seconds to 300 seconds. Default is 10 seconds.
Batch Size
The number of files a file ingestion and replication task can transfer in a batch.
Default is 5.
The maximum batch size varies, based on the following conditions:
- If files are transferred from source to target with no intermediate staging server, the maximum number of files the task can transfer in a batch is 8000.
- If files are transferred from source to target with intermediate staging server, the maximum number of files the task can transfer in a batch is 20.
Note:
If you transfer files from Azure Blob Storage to Azure SQL Data Warehouse and Snowflake, the task transfers files with no intermediate staging server.
Microsoft Fabric OneLake source properties
When you define a File Ingestion and Replication task with a Microsoft Fabric OneLake source, you must enter source options on the Source tab of the task wizard.
Note:
You can overwrite the file name pattern, and folder, and define your own variable for sources by using the job resource of the File Ingestion and Replication REST API. For more information, see Jobs.
The following table describes the source options:
Option
Description
File Pickup
The File Ingestion and Replication task supports the following file pickup methods:
- By Pattern. The File Ingestion and Replication task picks up files by pattern.
- By File List. The File Ingestion and Replication task picks up files based on a file list.
Source Directory
Directory from where files are transferred.
You can enter a relative path to the source file system. To enter a relative path, start the path with a period, followed by a slash (./). The path is relative to the source directory specified in the connection.
Note:
A File Ingestion and Replication job fails if there's an empty file in the source directory. However, you can avoid selecting 0 KB files by using the size filter option.
Add Parameters
Create an expression to add it as a Source Directory parameter. For more information, see Source and target parameters.
Include files from sub-folders
Transfer files from all subfolders under the defined source directory.
File Pattern
File name pattern to use for selecting the files to transfer. The pattern can be a regular expression or a pattern with wildcard characters.
The following wildcard characters are allowed:
- An asterisk (*) to represent any number of characters.
- A question mark (?) to represent a single character.
For example, you can specify the following regular expression:
([a-zA-Z0-9\s_\\.\-\(\):])+(.doc|.docx|.pdf)$
File Date
A date and time expression for filtering the files to transfer.
Select one of the following options:
- Greater than or Equal. Filters files that are modified on or after the specified date and time.
To specify a date, click the calendar. To specify a time, click the clock.
- Less than or Equal. Filters files that are modified before or on the specified date and time.
- Equal. Filters files that are modified on the specified date and time.
Click the calendar to select the date and the clock to select the time.
- Days before today. Filters files that are modified within the specified number of days until the current date (today). Enter the number of days. The current date calculation starts from 00:00 hours.
For example, if you schedule the file ingestion and replication task to run weekly and want to filter for the files that were modified in the previous week, set Days before today to 7. The task will pick up any file with a date between 7 days ago and the date on which it runs.
Time Zone
If you selected a File Date option, enter the time zone of the location where the files are located.
File Size
Filters the files to transfer based on file size. Enter the file size, select the file size unit, and filter options.
Select one of the following filter options:
- Greater than or Equal. Filters files that are greater than or equal to the specified size.
- Less than or Equal. Filters files that are less than or equal to the specified size.
- Equal. Filters files that have the specified size.
Skip Duplicate Files
Indicates whether to skip duplicate files. If you select this option, the File Ingestion and Replication task does not transfer files that have the same name and file size as another file. The File Ingestion and Replication task marks these files as duplicate in the job log. If you do not select this option, the task transfers all files, even files with duplicate names and creation dates.
Check File Stability
Indicates whether to verify that a file is stable before a File Ingestion and Replication task attempts to pick it. The task skips unstable files it detects in the current run.
Stability Check Interval
This applies when you enable the Check file stability option. Time in seconds that a File Ingestion and Replication task waits to check the file stability.
For example, if the stability time is 15 seconds, the File Ingestion and Replication task detects all the files in the source folder that match the defined file pattern, waits for 15 seconds, and processes only the stable files.
The interval ranges between 10 seconds to 300 seconds. Default is 10 seconds.
Batch Size
The number of files a file ingestion and replication task can transfer in a batch.
Default is 5.
The maximum number of files you can transfer in a batch is 20.
After File Pickup
Determines the actions to be performed on the source files after the files transfer. The following options are available:
- Keep files in the source directory.
- Delete files from the source directory.
- Rename the files in the source directory. You must specify a file name suffix that the file ingestion and replication task adds to the file name when renaming the files. Enter one of the following variables:
- ($date)
- ($time)
- ($timestamp)
- ($runId)
- Archive the files to a different location. You must specify an archive directory, which is the absolute path or relative path from the source file system. An archive directory helps you maintain a sub-folder structure from the source file system.
For example, if lakehouse/Files/archive is the archive directory, lakehouse/Files/test is the source directory, sub1 and sub2 are the directories within the source directory, and you choose to include files from sub-folders, then the folder structure of the archive directory is lakehouse/Files/archive/sub1, lakehouse/Files/archive/sub2.
Oracle Cloud Object Storage source properties
When you define a file ingestion and replication task with a Oracle Cloud Object Storage source, you must enter source options on the Source tab of the task wizard.
Note:
You can overwrite the file name pattern, folder, and table parameters, and define your own variable for sources by using the job resource of the File Ingestion and Replication REST API. For more information, see Jobs.
The following table describes the source options:
Option
Description
File Pickup
Determines how the file ingestion and replication task picks up files.
You can choose from the following file pickup methods:
- By Pattern. The file ingestion and replication task picks up files by pattern.
- By File List. The file ingestion and replication task picks up files based on a file list.
Source Directory
Directory from where files are transferred.
You can enter a relative path to the source file system. To enter a relative path, start the path with a period, followed by a slash (./). The path is relative to the source directory specified in the connection.
Note:
You cannot specify a folder from outside of the Oracle Cloud Object Storage source folder path used in the connection.
Add Parameters
Variables that you can use to configure a parameter for the source that a file ingestion and replication task can use.
Create an expression to add it as a Source Directory parameter. For more information, see Source and target parameters.
Include files from sub-folders
Transfer files from all subfolders under the defined source directory.
File Pattern
File name pattern to use for selecting the files to transfer. The pattern can be a regular expression or a pattern with wildcard characters.
The following wildcard characters are allowed:
- An asterisk (*) to represent any number of characters.
- A question mark (?) to represent a single character.
For example, you can specify the following regular expression:
([a-zA-Z0-9\s_\\.\-\(\):])+(.doc|.docx|.pdf)$
File Date
A date and time expression for filtering the files to transfer.
Select one of the following options:
- Greater than or Equal. Filters files that are modified on or after the specified date and time.
To specify a date, click the calendar. To specify a time, click the clock.
- Less than or Equal. Filters files that are modified before or on the specified date and time.
- Equal. Filters files that are modified on the specified date and time.
Click the calendar to select the date and the clock to select the time.
- Days before today. Filters files that are modified within the specified number of days until the current date (today). Enter the number of days. The current date calculation starts from 00:00 hours.
For example, if you schedule the file ingestion and replication task to run weekly and want to filter for the files that were modified in the previous week, set Days before today to 7. The task will pick up any file with a date between 7 days ago and the date on which it runs.
Time Zone
If you selected a File Date option, enter the time zone of the location where the files are located.
File Size
Filters the files to transfer based on file size. Enter the file size, select the file size unit, and filter options.
Select one of the following filter options:
- Greater than or Equal. Filters files that are greater than or equal to the specified size.
- Less than or Equal. Filters files that are less than or equal to the specified size.
- Equal. Filters files that have the specified size.
Skip Duplicate Files
Indicates whether to skip duplicate files. If you select this option, the file ingestion and replication task does not transfer files that have the same name and file size as another file. The file ingestion and replication task marks these files as duplicate in the job log. If you do not select this option, the task transfers all files, even files with duplicate names and creation dates.
Check file stability
Indicates whether to verify that a file is stable before a file ingestion and replication task attempts to pick it. The task skips unstable files it detects in the current run.
Stability check interval
This applies when you enable the Check file stability option.
Time in seconds that a file ingestion and replication task waits to check the file stability.
For example, if the stability time is 15 seconds, the file ingestion and replication task detects all the files in the source folder that match the defined file pattern, waits for 15 seconds, and processes only the stable files.
The interval ranges between 10 seconds to 300 seconds. Default is 10 seconds.
Batch Size
The number of files a file ingestion and replication task can transfer in a batch.
The maximum number of files you can transfer in a batch is 20.
Default is 5.
Minimum Download Part Size (MB)
Minimum download part size in megabytes when downloading a large file as a set of multiple independent parts.
You can specify a value between 4 and 1,000.
Default is 32 MB.
Multipart Download Threshold (MB)
Multipart download minimum threshold in megabytes that is used to determine when to upload objects in multiple parts in parallel.
You can specify a value between 4 and 5,000.
Default is 64 MB.
After File Pickup
Determines the actions to be performed on the source files after the files transfer. The following options are available:
- Keep files in the source directory.
- Delete files from the source directory.
- Rename the files in the source directory. You must specify a file name suffix that the file ingestion and replication task adds to the file name when renaming the files. Enter one of the following variables:
- ($date)
- ($time)
- ($timestamp)
- ($runId)
- Archive the files to a different location. You must specify an archive directory, which is the absolute path or relative path from the source file system. An archive directory helps you maintain a sub-folder structure from the source file system.
For example, if /root/archive is the archive directory, /root/test is the source directory, sub1 and sub2 are the directories within the source directory, and you choose to include files from sub-folders, then the folder structure of the archive directory is /root/archive/sub1, /root/archive/sub2.
Note:
To avoid permission errors during archive and rename operations in Oracle Cloud Object Storage, apply the following policy at the tenancy or compartment level where the Object Storage resources reside: "Allow service objectstorage-us-ashburn-1 to manage object-family in compartment <compartment>"
Source and target parameters
You can configure the file name pattern, folder, and table parameters for sources and targets that a file ingestion and replication task reads from or writes to.
You can use one of the following types of variables to configure a parameter:
•System variables
•User-defined variables
Note:
You cannot run a task with user-defined variable from the user interface. The value of the user-defined variable must be passed using the job resource of the File Ingestion and Replication REST API. For more information, see Jobs.
Using system variables to add source and target parameters
Use system variables to add parameters to task sources and targets.
1Click Add Parameter next to the input field, such as Source Directory or Target Directory on the Source or Target tab of the task wizard. .
The Add Parameters window appears.
2Select the required variable from the System Variablescolumn and click . The selected system variable appears on theExpression column. Repeat this procedure to select multiple system variables.
Note:
When using a system variable within a task, it should be formatted as ${systemvariablename}.
The following table describes the system variables:
System Variables
Description
Expression
BadFileDir *
Directory for reject files. It cannot include the following special characters:
* ? < > " | ,
${$PMBadFileDir}
CacheFileDir *
The location for the cache file.
${$PMCacheDir}
Date **
The current date in ISO (yyyy-MM-dd) format.
${system.date}
Day **
The day of week
${system.day}
ExtProcDir *
Directory for external procedures. It cannot include the following special characters:
* ? < > " | ,
${$PMExtProcDir}
Hours **
Hours
${system.hours}
JobId
The id (or job number) of the current job.
${system.jobid}
LookupFileDir *
Directory for lookup files. It cannot include the following special characters:
* ? < > " | ,
${$PMLookupFileDir}
Minutes **
Minutes
${system.minutes}
Month **
Numerical month
${system.month}
Name
The name of the current Project.
${system.name}
RootDir *
Root directory accessible by the node. This is the root directory for other service process variables. It cannot include the following special characters:
* ? < > " | ,
${$PMRootDir}
RunId
The id when a job is run.
${system.runid}
Seconds **
Seconds
${system.seconds}
SessionLogDir *
Directory for session logs. It cannot include the following special characters:
* ? < > " | ,
${$PMSessionLogDir}
SourceFileDir *
Directory for source files. It cannot include the following special characters:
* ? < > " | ,
${$PMSourceFileDir}
StorageDir *
Directory for run-time files. Workflow recovery files save to the $PMStorageDir configured in the PowerCenter Integration Service properties. Session recovery files save to the $PMStorageDir configured in the operating system profile. It cannot include the following special characters:
* ? < > " | ,
${$PMStorageDir}
TargetFileDir *
Directory for target files. It cannot include the following special characters:
* ? < > " | ,
${$PMTargetFileDir}
TempDir *
Directory for temporary files. It cannot include the following special characters:
* ? < > " | ,
${$PMTempDir}
Timestamp **
The current date and time in ISO (yyyy-MM-dd HH:mm:ss) format.
${system.timestamp}
WorkflowLogDir *
The location for the workflow log file.
${$PMWorkflowLogDir}
Year **
Year
${system.year}
* Values are fetched from the Data Integration Server.
** Time zone is the Secure Agent time zone.
3Click OK.
The expression appears in the input field.
Using user-defined variables to add source and target parameters
Use user-defined variables to add parameters to add sources and targets.
1Click an input field, such as Source Directory or Target Directory on the Source or Target tab of the task wizard and enter the variable. The variable should be formatted as ${systemvariablename}.
2Click OK.
The expression appears in the input field.
Skip duplicate files
When you create a file ingestion and replication task, you can choose to skip duplicate files. On enabling the Skip Duplicate Files option, the file ingestion task doesn't transfer files with the same name and file size as a previously transferred file. The file ingestion task marks these files as duplicate in the job log.
You can save the information about skipped duplicate files in the following locations:
IDMC
The information about skipped duplicate files that is saved in IDMC is retained until the file ingestion job is purged. The retention period is based on the Job Log Service (JLS) purge policy. When this information is purged, subsequent runs of the file ingestion task transfers all files, including those previously marked as duplicates.
To transfer the information about skipped duplicate files from the Secure Agent to IDMC, set the agent-dedup-repository property to false in your Secure Agent. The Secure Agent deletes the information about skipped duplicate files after successfully transferring it to IDMC. You can configure the agent-dedup-repository property in Administrator. For more information, see the Getting Started guide.
By default, the information about skipped duplicate files is saved in IDMC.
Secure Agent
You can save the information about skipped duplicate files in the Secure Agent. The information is retained indefinitely and is subject to disk space availability in the Secure Agent. Currently, there is no retention policy applied on this information in the Secure Agent.
For more information about the log retention policy, see the Knowledge Base article 000209817.
The folder in which this information is stored can be configured and can be shared between agents in a Secure Agent group. You can configure the agent-dedup-repository property in Administrator. For more information, see the Getting Started guide.
To transfer the skipped duplicate files information from IDMC to the Secure Agent, set the agent-dedup-repository property to true in your Secure Agent. You can configure the path to store the information about skipped duplicate files in the Secure Agent using the mi-dedup-snapshot-dir property in Administrator. For more information, see the Getting Started guide.
The file ingestion task transfers the information about skipped duplicate files from IDMC to the Secure Agent when you run the subsequent file ingestion job. The skipped duplicate files information is deleted from IDMC after successfully transferring the information to the Secure Agent.
Configuring the target
To configure the target, select a connection type and a connection to which to transfer files and then configure target options.
1On the Target page, select a connection type.
If a new connection is created in your organization for the selected connection type while you are on this page, it might not appear in the connections list right away. Click the refresh icon to see all the available connections.
The file ingestion and replication task supports the following target connection types:
- Local folder
- Advanced FTP V2
- Advanced FTPS V2
- Advanced SFTP V2
- Amazon S3 V2
- Amazon Redshift V2
- Cloud Integration Hub
- Databricks
- Google BigQuery V2
- Google Cloud Storage V2
- Hadoop Files V2
- Microsoft Azure Blob Storage V3
- Microsoft Azure Data Lake Store Gen2
- Microsoft Azure Data Lake Store V3
- Microsoft Azure Synapse SQL
- Microsoft Fabric OneLake
- Oracle Cloud Object Storage
- Snowflake Data Cloud
2Select a connection.
3Based on the target connection that you select, enter the target options.
Options that appear on the Target tab of the task wizard vary based on the type of target connection that you select.
4Click Next.
The Schedule tab appears.
Advanced FTP V2 target properties
When you define a file ingestion and replication task with an Advanced FTP V2 target, you must enter target options on the Target tab of the task wizard.
The following table describes the target options:
Option
Description
Target Directory
Directory to where files are transferred.
The default value is the target directory specified in the connection.
You can enter a relative path. To enter a relative path, start the path with a period, followed by a slash (./). The path is relative to the target directory specified in the connection.
Add Parameters
Create an expression to add it as a Target Directory parameter. For more information, see Source and target parameters.
If File Exists
Determines what to do with a file if a file with the same name already exists in the target directory. Select one of the following options:
- Overwrite. Overwrites the existing file.
- Append Timestamp. Retains the existing file and appends a timestamp to the name of file being transferred.
- Error. The job fails if a file with the same name exists in the target directory.
Transfer Mode
File transfer mode. Select one of the following options:
- Auto. File ingestion and replication determines the transfer mode.
- ASCII.
- Binary.
Note:
If a binary file transfer is interrupted due to a network disruption, the file event displays an interrupted status. Run the file ingestion and replication job again to resume the transfer of the interrupted files.
Create intermediate file
Creates an intermediate file until the file is completely transferred to the target location.
For example, if you transfer a file named file.txt from a source to a target, you see an intermediate file named file.txt_644a1f88 in the target location until the file is completely transferred.
Advanced FTPS V2 target properties
When you define a file ingestion and replication task with an Advanced FTPS V2 target, you must enter target options on the Target tab of the task wizard.
The following table describes the target options:
Option
Description
Target Directory
Directory to where files are transferred.
The default value is the target directory specified in the connection.
You can enter a relative path. To enter a relative path, start the path with a period, followed by a slash (./). The path is relative to the target directory specified in the connection.
Add Parameters
Create an expression to add it as a Target Directory parameter. For more information, see Source and target parameters.
If File Exists
Determines what to do with a file if a file with the same name already exists in the target directory. Select one of the following options:
- Overwrite. Overwrites the existing file.
- Append Timestamp. Retains the existing file and appends a timestamp to the name of file being transferred.
- Error. The job fails if a file with the same name exists in the target directory.
Transfer Mode
File transfer mode. Select one of the following options:
- Auto. File ingestion and replication determines the transfer mode.
- ASCII.
- Binary.
Note:
If a binary file transfer is interrupted due to a network disruption, the file event displays an interrupted status. Run the file ingestion and replication job again to resume the transfer of the interrupted files.
Create intermediate file
Creates an intermediate file until the file is completely transferred to the target location.
For example, if you transfer a file named file.txt from a source to a target, you see an intermediate file named file.txt_644a1f88 in the target location until the file is completely transferred.
Advanced SFTP V2 target properties
When you define a file ingestion and replication task with an Advanced FTPS V2 target, you must enter target options on the Target tab of the task wizard.
The following table describes the target options:
Option
Description
Target Directory
Directory to where files are transferred.
The default value is the target directory specified in the connection.
You can enter a relative path. To enter a relative path, start the path with a period, followed by a slash (./). The path is relative to the target directory specified in the connection.
Add Parameters
Create an expression to add it as a Target Directory parameter. For more information, see Source and target parameters.
If File Exists
Determines what to do with a file if a file with the same name already exists in the target directory. Select one of the following options:
- Overwrite. Overwrites the existing file.
- Append Timestamp. Retains the existing file and appends a timestamp to the name of file being transferred.
- Error. The job fails if a file with the same name exists in the target directory.
Create intermediate file
Creates an intermediate file until the file is completely transferred to the target location.
For example, if you transfer a file named file.txt from a source to a target, you see an intermediate file named file.txt_644a1f88 in the target location until the file is completely transferred.
Amazon Redshift V2 target properties
When you define a file ingestion and replication task with an Amazon Redshift V2 target, you must enter target options on the Target tab of the task wizard.
Amazon Redshift V2 connection provides the following options that you must select to perform the copy command method:
•Define Redshift Copy Command Properties. Select this option to define the Amazon Redshift copy command properties.
•Enter Custom Redshift Copy Command. Select this option to provide a custom Amazon Redshift copy command that the file ingestion and replication task uses.
The following table describes the advanced target options that you can configure in a file ingestion and replication task if you select the Define Redshift Copy Command Properties option:
Option
Description
Target Table Name
Name of the table in Amazon Redshift to which the files are loaded.
Note:
You can only transfer files that match the source files' metadata. Ensure the target table is present before you run the job.
Schema
The Amazon Redshift schema name.
Default is the schema that is used while establishing the target connection.
Add Parameters
Create an expression to add it as Schema and Target Table Name parameters. For more information, see Source and target parameters.
Truncate Target Table
Truncate the target table before loading data to the table.
Analyze Target Table
The analyze command collects statistics about the contents of tables in the database to help determine the most efficient execution plans for queries.
Note:
This operation runs on every batch even if the Parallel Batch value is greater than 1.
Vacuum Target Table
You can select to vacuum the target table to recover disk space and sorts rows in a specified table.
Select one of the following recovery options:
- Full. Sorts the specified table and recovers disk space occupied by rows marked for deletion by previous update and delete operations.
- Sort. Sorts the specified table without recovering space freed by deleted rows.
- Delete. Recovers disk space occupied by rows marked for deletion by previous update and delete operations, and compresses the table to free up used space.
Note:
This operation runs on every batch even if the Parallel Batch value is greater than 1.
File Format and Copy Options
Select the format with which to copy data. Select one of the following options:
- DELIMITER. A single ASCII character to separate fields in the input file. You can use characters such as pipe (|), tilde (~), or a tab (\t). The delimiter you specify cannot be a part of the data.
- QUOTE. Specifies the quote character used to identify nvarchar characters and skip them.
- COMPUPDATE. Overrides current compression encoding and applies compression to an empty table.
- AWS_IAM_ROLE. Specify the Amazon Redshift Role Resource Name to run on an Amazon EC2 system.
- IGNOREHEADER. Select to ignore headers. For example, if you specify IGNOREHEADER 0, the task processes data from row 0.
- DATEFORMAT. Specify the format for date fields.
- TIMEFORMAT. Specify the format for time fields.
The following table describes the advanced target options that you can configure in a file ingestion and replication task if you select the Enter Custom Redshift Copy Command option:
Property
Description
Copy Command
Amazon Redshift COPY command appends the data to any existing rows in the table.
If the Amazon S3 staging directory and the Amazon Redshift target belongs to different regions, you must specify the region in the COPY command.
For example,
copy public.messages from '{{FROM-S3PATH}}' credentials 'aws_access_key_id={{ACCESS-KEY-ID}};aws_secret_access_key={{SECRET-ACCESS-KEY-ID}}' MAXERROR 0 REGION '' QUOTE '"' DELIMITER ',' NULL '' CSV;
Where public is the schema and messages is the table name.
For more information about the COPY command, see the AWS documentation.
The following table describes the Amazon Redshift advanced target options that you can configure in a file ingestion and replication task after you select one of the copy command methods:
Property
Description
Pre SQL
SQL command to run before the file ingestion and replication task runs the COPY command.
Note:
This operation runs on every batch even if the Parallel Batch value is greater than 1.
Post SQL
SQL command to run after the file ingestion and replication task runs the COPY command.
Note:
This operation runs on every batch even if the Parallel Batch value is greater than 1.
S3 Staging Directory
Specify the Amazon S3 staging directory.
You must specify the Amazon S3 staging directory in <bucket_name/folder_name> format.
The staging directory is deleted after the file ingestion and replication task runs.
Upload to Redshift with no Intermediate Staging
Upload files from Amazon S3 to Amazon Redshift directly from the Amazon S3 source directory with no additional, intermediate staging.
If you select this option, ensure that the Amazon S3 bucket and the Amazon S3 staging directory belong to the same region.
If you do not select this option, ensure that the Amazon S3 staging directory and Amazon Redshift target belong to the same region.
File Compression*
Determines whether or not files are compressed before they are transferred to the target directory. Select one of the following options:
- None. Files are not compressed.
- GZIP. Files are compressed using GZIP compression.
File Encryption Type*
Type of Amazon S3 file encryption to use during file transfer. Select one of the following options:
- None. Files are not encrypted during transfer.
- S3 server-side encryption. Amazon S3 encrypts the file using AWS-managed encryption keys.
- S3 client-side encryption. Ensure that unrestricted policies are implemented for the AgentJVM, and that the master symmetric key for the connection is set.
Note:
Client-side encryption does not apply to tasks where Amazon S3 is the source.
S3 Accelerated Transfer*
Select whether to use Amazon S3 Transfer Acceleration on the S3 bucket. To use Transfer Acceleration, accelerated transfer must be enabled for the bucket. Select one of the following options:
- Disabled. Do not use Amazon S3 Transfer Acceleration.
- Accelerated. Use Amazon S3 Transfer Acceleration.
- Dualstack Accelerated. Use Amazon S3 Transfer Acceleration on a dual-stack endpoint.
Minimum Upload Part Size*
Minimum upload part size in megabytes when uploading a large file as a set of multiple independent parts. Use this option to tune the file load to Amazon S3.
Multipart Upload Threshold*
Multipart download minimum threshold in megabytes to determine when to upload objects in multiple parts in parallel.
*Not applicable when you read data from Amazon S3 to Amazon Redshift V2.
Amazon S3 V2 target properties
When you define a file ingestion and replication task with an Amazon S3 V2 target, you must enter target options on the Target tab of the task wizard.
The following table describes the target options:
Option
Description
Folder Path
Amazon S3 folder path to where files are transferred, including bucket name. The default value is the folder path specified in the connection.
You can enter a relative path. To enter a relative path, start the path with a period, followed by a slash (./). The path is relative to the target directory specified in the connection.
Add Parameters
Create an expression to add it as a Folder Path parameter. For more information, see Source and target parameters.
File Compression
Determines whether or not files are compressed before they are transferred to the target directory. Select one of the following options:
- None. Files are not compressed.
- GZIP. Files are compressed using GZIP compression.
File Encryption Type
Type of Amazon S3 file encryption to use during file transfer. Select one of the following options:
- None. Files are not encrypted during transfer.
- S3 server-side encryption. Amazon S3 encrypts the file using AWS-managed encryption keys.
- S3 client-side encryption. Ensure that unrestricted policies are implemented for the AgentJVM, and that the master symmetric key for the connection is set.
If File Exists
Determines what to do with a file if a file with the same name already exists in the target directory. Select one of the following filter options:
- Overwrite. Overwrites the existing file.
- Append Timestamp. Retains the existing file and appends a timestamp to the name of file being transferred.
S3 Accelerated Transfer
Select whether to use Amazon S3 Transfer Acceleration on the S3 bucket. To use Transfer Acceleration, accelerated transfer must be enabled for the bucket. Select one of the following options:
- Disabled. Do not use Amazon S3 Transfer Acceleration.
- Accelerated. Use Amazon S3 Transfer Acceleration.
- Dualstack Accelerated. Use Amazon S3 Transfer Acceleration on a dual-stack endpoint.
Minimum Upload Part Size
Minimum upload part size in megabytes when uploading a large file as a set of multiple independent parts. Use this option to tune the file load to Amazon S3.
Multipart Upload Threshold
Multipart download minimum threshold in megabytes to determine when to upload objects in multiple parts in parallel.
Checksum Algorithm
The checksum algorithm to use while loading files to the Amazon S3 target. Including checksum information helps verify file integrity and detect changes efficiently during file ingestion.
By default, the AWS SDK’s standard checksum algorithm is applied.
You can select from the following options that suits your data integrity needs:
- CRC64NVME
- CRC32
- CRC32C
- SHA1
- SHA256
If you do not specify an option, the default AWS SDK’s standard checksum algorithm is used.
Note:
Retain the default checksum algorithm for connections that use S3 Compatible Storage.
Cloud Integration Hub target properties
When you define a file ingestion and replication task with Cloud Integration Hub as the target, select a connection type and a connection to which to transfer files. There are no further target options to configure.
Note:
•You can't configure a file ingestion and replication task using Cloud Integration Hub as both source and target.
•You can't manually run a file ingestion and replication task with Cloud Integration Hub as a source or a target. You must run the file ingestion and replication task from the Cloud Integration Hub service. For more information about running the task from the Cloud Integration Hub service, see Cloud Integration Hub user guide.
Databricks target properties
When you define a file ingestion and replication task with a Databricks target, you must enter target options on the Target tab of the task wizard.
Note:
You can transfer only Parquet files from Amazon S3 V2 source and a Microsoft Azure Data Lake Store Gen2 source to a Databricks target, and all the files must have the same metadata.
The following table describes the target options:
Option
Description
Database
Required. Name of the database in Databricks Lake that contains the target table.
You can use a relative value to pick the database value passed in the connection. To use a relative value, enter an ellipses (...).
Add Parameters
Create an expression to add it as Database and Table Name parameters. For more information, see Source and target parameters.
Table Name
Required. Name of an existing table in Databricks.
If Table Exists
Determines the action that the Secure Agent must take on a table if the table name matches the name of an existing table in the target database. Select one of the following options:
- Overwrite
- Append
Default is Overwrite.
Note:
If a job fails with the following error, see the cluster logs for more information:
"[ERROR] Job execution failed. State : JOB_FAILED ; State Message :"
Google BigQuery V2 target properties
.
When you define a file ingestion and replication task with a Google BigQuery V2 target, you must enter target options on the Target tab of the task wizard.
Note:
When you define a file ingestion and replication task with a Google BigQuery V2 target, you can configure only Google Cloud Storage V2 as a source.
The following table describes the target options:
Option
Description
Target Table Name
Specify the Google BigQuery target table name.
Note:
You can only transfer files that match the source files' metadata. Ensure the target table is present before you run the job.
Dataset ID
Specify the Google BigQuery dataset name.
Add Parameters
Create an expression to add it as Target Table Name and Dataset ID parameters. For more information, see Source and target parameters.
Field Delimiter
Indicates whether Google BigQuery V2 Connector must allow field separators for the fields in a .csv file.
Quote Character
Specifies the quote character to skip when you write data to Google BigQuery. When you write data to Google BigQuery and the source table contains the specified quote character, the task fails. Change the quote character value to a value that does not exist in the source table.
Allow Quoted Newlines
Indicates whether Google BigQuery V2 Connector must allow the quoted data sections with newline character in a .csv file.
Allow Jagged Rows
Indicates whether Google BigQuery V2 Connector must accept the rows without trailing columns in a .csv file.
Skip Leading Rows
Specifies the number of top rows in the source file that Google BigQuery V2 Connector skips when loading the data.
The default value is 0.
Data format of the File
Specifies the data format of the source file. You can select one of the following data formats:
- JSON (Newline Delimited)
- CSV
- Avro
- Parquet
- ORC
Write Disposition
Specifies how Google BigQuery V2 Connector must write data in bulk mode if the target table already exists.
You can select one of the following values:
- Write Append. If the target table exists, Google BigQuery V2 Connector appends the data to the existing data in the table.
- Write Truncate. If the target table exists, Google BigQuery V2 Connector overwrites the existing data in the table.
- Write Empty. If the target table exists and contains data, Google BigQuery V2 Connector displays an error and does not write the data to the target. Google BigQuery V2 Connector writes the data to the target only if the target table does not contain any data.
Google Cloud Storage V2 target properties
When you define a file ingestion and replication task with a Google Cloud Storage V2 target, you must enter target options on the Target tab of the task wizard.
The following table describes the target options:
Option
Description
Folder Path
Path in Google Cloud Storage where files are transferred. You can either enter the bucket name or the bucket name and folder name.
For example, enter <bucket name> or <bucket name>/<folder name>
Do not use a single slash (/) in the beginning of path.
You can enter a relative path. To enter a relative path, start the path with a period, followed by a slash (./). The path is relative to the bucket specified in the connection.
Note:
Files are uploaded to Google Cloud Storage as text/plain regardless of their original file extension.
Add Parameters
Create an expression to add it as a Folder Path parameter. For more information, see Source and target parameters.
File Compression
Determines whether or not files are compressed before they are transferred to the target directory. Select one of the following options:
- None. Files are not compressed.
- GZIP. Files are compressed using the GZIP compression format.
If File Exists
Determines the action that the Secure Agent must take with a file if a file with the same name exists in the target directory. Select one of the following options:
- Overwrite
- Append Timestamp
Hadoop Files V2 target properties
When you define a file ingestion and replication task with a Hadoop Files V2 target, you must enter target options on the Target tab of the task wizard.
The following table describes the target option:
Option
Description
Target Directory
Directory to where files are transferred.
Add Parameters
Create an expression to add it as a Target Directory parameter. For more information, see Source and target parameters.
Local folder target properties
When you define a file ingestion and replication task with a local folder target, you must enter target properties on the Target tab of the task wizard.
The following table describes the target options:
Option
Description
Target Directory
Directory to where files are transferred. The Secure Agent must be able to access the directory.
Add Parameters
Create an expression to add it as a Target Directory parameter. For more information, see Source and target parameters.
If File Exists
Determines what to do with a file if a file with the same name exists in the target directory. Select one of the following options:
- Overwrite. Overwrites the existing file.
- Append Timestamp. Retains the existing file and appends a timestamp to the name of file being transferred.
- Error. The job fails if a file with the same name exists in the target directory.
Create intermediate file
Creates an intermediate file until the file is completely transferred to the target location.
For example, if you transfer a file named file.txt from a source to a target, you see an intermediate file named file.txt_644a1f88 in the target location until the file is completely transferred.
Important:
Not applicable when you read data from Amazon S3 V2, Google Cloud Storage V2, Microsoft Azure Blob Storage v3, Microsoft Azure Data Lake Storage Gen2, and Hadoop Files V2.
Microsoft Azure Blob Storage V3 target properties
When you define a file ingestion and replication task with a Microsoft Azure Blob Storage target, you must enter target options on the Target tab of the task wizard.
The following table describes the target options:
Option
Description
Blob Container
Microsoft Azure Blob Storage container, including folder path and container name.
Add Parameters
Create an expression to add it as a Blob Container parameter. For more information, see Source and target parameters.
Blob Type
Type of blob. Select one of the following options:
- Block Blob. Ideal for storing text or binary files, such as documents and media files.
- Append Blob. Optimized for append operations, for example, logging scenarios.
File Compression
Determines whether or not files are compressed before they are transferred to the target directory. The following options are available:
- None. Files are not compressed.
- GZIP. Files are compressed using GZIP compression.
Number of Concurrent Connections to Blob Store
Number of concurrent connections to the Microsoft Azure Blob Store Storage container.
Microsoft Azure Data Lake Storage Gen2 target properties
When you define a file ingestion and replication task with a Microsoft Azure Data Lake Storage Gen2 target, you must enter target options on the Target tab of the task wizard.
The following table describes the target options:
Target Property
Description
Target Directory
Directory to where files are transferred. The directory is created at run time if it does not exist. The directory path specified at run time overrides the path specified while creating a connection.
The default value is the target directory specified in the connection.
You can enter a relative path. To enter a relative path, start the path with a period, followed by a slash (./). The path is relative to the target directory specified in the connection.
Add Parameters
Create an expression to add it as a Target Directory parameter. For more information, see Source and target parameters.
File Compression
Determines whether or not files are compressed before they are transferred to the target directory. The following options are available:
- None. Files are not compressed.
- GZIP. Files are compressed using GZIP compression.
If File Exists
Determines what to do with a file if a file with the same name exists in the target directory. The following options are available:
- Overwrite
- Append
- Fail
Block Size (Bytes)
Divides a large file into smaller specified block size. When you write a large file, divide the file into smaller parts and configure concurrent connections to spawn the required number of threads to process data in parallel.
Default is 8388608 bytes (8 MB).
Microsoft Azure Data Lake Store Gen1 V3 target properties
When you define a file ingestion and replication task with a Microsoft Azure Data Lake Store Gen1 V3 target, you must enter target options on the Target tab of the task wizard.
The following table describes the target options:
Target Property
Description
Target Directory
Directory to where files are transferred.
The default value is the target directory specified in the connection.
You can enter a relative path. To enter a relative path, start the path with a period, followed by a slash (./). The path is relative to the target directory specified in the connection.
Add Parameters
Create an expression to add it as a Target Directory parameter. For more information, see Source and target parameters.
File Compression
Determines whether or not files are compressed before they are transferred to the target directory. The following options are available:
- None. Files are not compressed.
- GZIP. Files are compressed using GZIP compression.
If File Exists
Determines what to do with a file if a file with the same name exists in the target directory. The following options are available:
- Overwrite
- Append
- Fail
Microsoft Azure Synapse SQL target properties
When you define a file ingestion and replication task with a Microsoft Azure Synapse SQL target, you must enter target options on the Target tab of the task wizard.
The following table describes the target options:
Property
Description
Ingestion Method
The ingestion method to load data to Microsoft Azure Synapse SQL.
Select one of the following options:
- Polybase
- COPY Command
Command Type
The command type for the ingestion method.
Select one of the following options:
- Auto Generated. Select this option to define the command properties.
- Custom. Select this option to provide a custom command that the file ingestion and replication task uses.
The following table describes the Microsoft Azure Synapse SQL advanced target options when you select Polybase or COPY Command ingestion method and Auto Generated command type:
Note:
The Auto Generated command type is applicable only for files in text and CSV formats.
Property
Description
Target Table Name
Name of the table in Microsoft Azure Synapse SQL to which the files are loaded.
Note:
You can only transfer files that match the source files' metadata. Ensure the target table is present before you run the job.
Add Parameters
Create an expression to add it as Target Table Name and Schema parameters. For more information, see Source and target parameters.
Schema
The Microsoft Azure Synapse SQL schema name. You can enter a relative value to pick the schema value passed in the connection. To use a relative value, enter an ellipses (...).
Truncate Target Table
Truncate the target table before loading.
Pre SQL
SQL command to run before the file ingestion and replication task runs the PolyBase or Copy command.
Note:
This operation runs on every batch even if the Parallel Batch value is greater than 1.
Post SQL
SQL command to run after the file ingestion and replication task runs the PolyBase or Copy command.
Note:
This operation runs on every batch even if the Parallel Batch value is greater than 1.
Field Delimiter
Character used to separate fields in the file. Default is 0x1e. You can select the following field delimiters from the list:
~ ` | . TAB 0x1e
Quote Character
Specifies the quote character to skip when you write data to Microsoft Azure Synapse SQL. When you write data to Microsoft Azure Synapse SQL and the source table contains the specified quote character, the task fails. Change the quote character value to a value that does not exist in the source table.
External Stage*
Specifies the external stage directory to use for loading files into Microsoft Azure Synapse SQL. You can stage files in Microsoft Azure Blob Storage or Microsoft Azure Data Lake Storage Gen2.
File ingestion and replication tasks automatically populates the external stage path property with the values provided in the following properties in the Microsoft Azure Synapse SQL connection in Administrator:
- File system name, if ADLS Gen2 is the connection storage type.
- Container name, if Azure Blob is the connection storage type
You can override the value.
File Compression*
Determines whether or not files are compressed before they are transferred to the target directory.
The following options are available:
- None. Files are not compressed.
- GZIP. Files are compressed using GZIP compression.
Number of Concurrent Connections*
Number of concurrent connections to extract data from the Microsoft Azure Blob Storage or Microsoft Azure Data Lake Storage Gen2. When reading a large file or object, you can spawn multiple threads to process data. Configure Blob Part Size or Block Size to divide a large file into smaller parts.
Default is 4. Maximum is 10.
*Not applicable when you read data from Microsoft Azure Blob Storage or Microsoft Azure Data Lake Storage Gen2.
The following table describes the Microsoft Azure Synapse SQL advanced target properties when you select Polybase or COPY Command ingestion method and Custom command type:
Property
Description
File Format Definition
Applies to Polybase ingestion method.
Transact-SQL CREATE EXTERNAL FILE FORMAT statement. For example:
CREATE EXTERNAL FILE FORMAT {{fileFormatName}} WITH ( FORMAT_TYPE = DELIMITEDTEXT, FORMAT_OPTIONS (FIELD_TERMINATOR = ',', STRING_DELIMITER = '"') )
The following is an example to create an external file in parquet format:
CREATE EXTERNAL FILE FORMAT {{fileFormatName}} WITH (FORMAT_TYPE = PARQUET)
Similarly, you can create an external file in JSON, Avro, and ORC formats.
For more information about the CREATE EXTERNAL FILE FORMAT statement, see the Microsoft documentation.
External Table Definition
Applies to Polybase ingestion method.
Transact-SQL CREATE EXTERNAL TABLE statement. For example:
CREATE EXTERNAL TABLE {{externalTable}} ( id INT, name NVARCHAR ( 100 ) ) WITH (LOCATION = '{{blobLocation}}', DATA_SOURCE = {{dataSourceName}}, FILE_FORMAT = {{fileFormatName}})
The following is an example to create an external table in parquet format:
Similarly, you can create an external table in JSON, Avro, and ORC formats.
For more information about the CREATE EXTERNAL TABLE statement, see the Microsoft documentation.
Insert SQL Definition
Applies to Polybase ingestion method.
Transact-SQL INSERT statement. For example:
INSERT INTO schema.table (id, name) SELECT id+5, name FROM {{externalTable}}
The following is an example for defining insert SQL in parquet format:
INSERT INTO testing.test_parq(username,number,colour) SELECT username, number,colour FROM {{externalTable}};
Similarly, you can define insert SQL in JSON, Avro, and ORC formats.
For information about the INSERT statement, see the Microsoft documentation.
Copy Command Definition
Applies to COPY Command ingestion method.
Transact-SQL COPY INTO statement. For example:
COPY INTO schema.table FROM EXTERNALLOCATION WITH(CREDENTIAL = (AZURECREDENTIALS), FIELDTERMINATOR = ',', FIELDQUOTE = '')
The following is an example for defining COPY Command in parquet format:
COPY INTO testing.test_parq FROM EXTERNALLOCATION WITH(CREDENTIAL = (AZURECREDENTIALS), FILE_TYPE = 'PARQUET')
Similarly, you can define COPY Command in JSON, Avro, and ORC formats.
For more information about the COPY INTO statement, see the Microsoft documentation.
Pre SQL
SQL command to run before the file ingestion and replication task runs the PolyBase command.
Note:
This operation runs on every batch even if the Parallel Batch value is greater than 1.
Post SQL
SQL command to run after the file ingestion and replication task runs the PolyBase command.
Note:
This operation runs on every batch even if the Parallel Batch value is greater than 1.
External Stage*
Specifies the external stage directory to use for loading files into Microsoft Azure Synapse SQL. You can stage the files in Microsoft Azure Blob Storage or Microsoft Azure Data Lake Storage Gen2.
Number of Concurrent Connections*
Number of concurrent connections to extract data from the Microsoft Azure Blob Storage or Microsoft Azure Data Lake Storage Gen2. When reading a large file or object, you can spawn multiple threads to process data. Configure Blob Part Size or Block Size to divide a large file into smaller parts.
Default is 4. Maximum is 10.
*Not applicable when you read data from Microsoft Azure Blob Storage or Microsoft Azure Data Lake Storage Gen2.
Microsoft Fabric OneLake target properties
When you define a file ingestion and replication task with a Microsoft Fabric OneLake target, you must enter target options on the Target tab of the task wizard.
The following table describes the target options:
Option
Description
Target Directory
Directory to which files are transferred. The Secure Agent must be able to access the directory.
Add Parameters
Create an expression to add it as a Folder Path parameter. For more information, see Source and target parameters.
File Compression
Determines whether or not files are compressed before they are transferred to the target directory. Select one of the following options:
- None. Files are not compressed.
- GZIP. Files are compressed using the GZIP compression format.
If File Exists
Determines the action that the Secure Agent must take with a file if a file with the same name exists in the target directory. Select one of the following options:
- Overwrite
- Append
Note:
When you run a job with the append option for binary files, the content of the files does not get appended.
Oracle Cloud Object Storage target properties
When you define a file ingestion and replication task with an Oracle Cloud Object Storage target, you must enter target options on the Target tab of the task wizard.
The following table describes the target options:
Option
Description
Folder Path
Oracle Cloud Object Storage path to where files are transferred. The default value is the folder path specified in the connection.
You can enter a relative path. To enter a relative path, start the path with a period, followed by a slash (./). The path is relative to the target directory specified in the connection.
Note:
You cannot specify a folder from outside of the Oracle Cloud Object Storage target folder path used in the connection.
Add Parameters
Variables that you can use to configure a parameter for the target that a file ingestion and replication task can use.
Create an expression to add it as a Folder Path parameter. For more information, see Source and target parameters.
File Compression
Determines whether or not files are compressed before they are transferred to the target directory. Select one of the following options:
- None. Files are not compressed.
- GZIP. Files are compressed using GZIP compression.
Minimum Upload Part Size (MB)
Minimum upload part size in megabytes when uploading a large file as a set of multiple independent parts. Use this option to tune the file load to Oracle Cloud Object Storage.
You can specify a value between 1 and 50,000.
Default is 128 MB.
Multipart Upload Threshold (MB)
Multipart download minimum threshold in megabytes to determine when to upload objects in multiple parts in parallel.
You can specify a value between 1 and 50,000.
Default is 128 MB.
Note:
In the Windows Secure Agent workspace, temporary staging files for Oracle Cloud Object Storage are not automatically deleted after job completion. You must manually delete these files.
Snowflake Data Cloud target properties
When you define a file ingestion and replication task with a Snowflake Data Cloud target, you must enter target options on the Target tab of the task wizard.
The following table describes the target options:
Property
Description
Warehouse
Overrides the name specified in the Snowflake Data Cloud connection. You can enter a relative value to pick the warehouse value passed in the connection. To enter a relative value, enter three periods (...).
Add Parameters
Create an expression to add it as Warehouse, Database, Schema, and Target Table Name parameters. For more information, see Source and target parameters.
Database
The database name of Snowflake Data Cloud.
Schema
The schema name in Snowflake Data Cloud.
Target Table Name
The table name of the Snowflake Data Cloud target table.
The target table name is case-sensitive.
Note:
You can only transfer files that match the source files' metadata. Ensure the target table is present before you run the job.
Role
Overrides the Snowflake Data Cloud user role specified in the connection. You can enter a relative value to pick the role value passed in the connection. To use a relative value, enter an ellipses (...).
Pre SQL
SQL statement to run on the target before the start of write operations.
Note:
This operation runs on every batch even if the Parallel Batch value is greater than 1.
Post SQL
SQL statement to run on the target table after a write operation completes.
Note:
This operation runs on every batch even if the Parallel Batch value is greater than 1.
Truncate Target Table
Truncates the database target table before inserting new rows. Enable the option to truncate the target table before inserting all rows. Disabling the option inserts new rows without truncating the target table.
File Format and Copy Options
The copy option and the file format to load the data to Snowflake Data Cloud.
The copy option specifies the action that the task performs when an error is encountered while loading data from a file:
You can specify the following copy option to abort the COPY statement if any error is encountered:
ON_ERROR = ABORT_STATEMENT
When you load files, you can specify the file format and define the rules for the data files. The task uses the specified file format and rules while bulk loading data into Snowflake Data Cloud tables.
The following formats are supported:
- CSV
- JSON
- Avro
- ORC
- Parquet
External Stage
Specifies the external stage directory to use for loading files into Snowflake Data Cloud tables.
Ensure that the source folder path you specify is the same as the folder path provided in the URL of the external stage for the specific connection type in Snowflake Data Cloud.
Applicable when the source for file ingestion and replication is Microsoft Azure Blob Storage and Amazon S3. The external stage is mandatory when you use the connection type Microsoft Azure Blob Storage V3, but is optional for Amazon S3 V2. If you do not specify an external stage for Amazon S3 V2, Snowflake Data Cloud creates an external stage by default.
File Compression
Determines whether or not files are compressed before they are transferred to the target directory.
The following options are available:
- None. Files are not compressed.
- GZIP. Files are compressed using GZIP compression.
Applicable for all sources that support the file ingestion and replication task except for Microsoft Azure Blob Storage V3 and Amazon S3 V2.
File format and copy options
When you configure a file ingestion and replication task to transfer a large number of files to Snowflake Data Cloud, specify the copy option and the file format to load the data.
Select a Snowflake Data Cloud connection in a file ingestion and replication task and then specify the copy option and the file format in the target options to determine how to load the files to a Snowflake Data Cloud target table.
The copy option specifies the action that the task performs when an error is encountered while loading data from a file.
You can specify the following copy option to abort the COPY statement if any error is encountered:
ON_ERROR = ABORT_STATEMENT
Note:
The file ingestion and replication task for Snowflake Data Cloud is certified for only the ABORT_STATEMENT for ON_ERROR copy option.
When you load files, you can specify the file format and define the rules for the data files. The task uses the specified file format and rules while bulk loading data into Snowflake Data Cloud tables.
The following list describes some of the format type options:
•RECORD_DELIMITER = '<character>' | NONE. Single character string that separates records in an input file.
•FIELD_DELIMITER = '<character>' | NONE. Specifies the single character string that separates records in an input file.
•FILE_EXTENSION = '<string>' | NONE. Specifies the extension for files unloaded to a stage.
•SKIP_HEADER = <integer>. Number of lines at the start of the file to skip.
•DATE_FORMAT = '<string>' | AUTO. Defines the format of date values in the data files or table.
•TIME_FORMAT = '<string>' | AUTO. Defines the format of time values in the data files or table.
•TIMESTAMP_FORMAT = <string>' | AUTO. Defines the format of timestamp values in the data files or table.
Example of File format and copy options for loading files to Snowflake
You want to create a CSV file format and define the following rules to load files to Snowflake:
•Delimit the fields using the pipe character ( |).
•Files include a single header line that will be skipped.
Specify the following file format: file_format = (type = csv field_delimiter = '|' skip_header = 1)
You can specify both the copy options and file format by using the following character: &&
For example, file_format = (type = csv field_delimiter = ',' skip_header = 2)&&on_error=ABORT_STATEMENT
Similarly, use the following file format in the File Format and Copy Options field to load data into separate columns:
The string MATCH_BY_COLUMN_NAME specifies whether to load the semi-structured data into the columns in the target table that match the corresponding columns represented in the data. CASE_SENSITIVE, CASE_INSENSITIVE, and NONE are the supported options. Default is NONE.
Consider the following criteria for a column to match between the data and table:
•The column represented in the data must have the same name as the column in the table. The column names are either case-sensitive (CASE_SENSITIVE ) or case-insensitive (CASE_INSENSITIVE).
•The column can be in any order.
•The column in the table must have a data type that is compatible with the values in the column represented in the data. For example, string, number, and Boolean values can be loaded into a variant column.
Consider the following rule and guideline when you load files of the JSON format to Snowflake Data Cloud.
When you load files of the JSON format to Snowflake Data Cloud, the target table must have only one column of variant type.
To load files of JSON format to columnar format, consider the following tasks:
For example, see the following data view in a table with variant column:
To update the table to columnar format, run the following SQL query from the Post-processing Commands field in the mapping task:
INSERT INTO PERSONS_JSON SELECT parse_json($1):email, parse_json($1):first_name, parse_json($1):gender, parse_json($1):id, parse_json($1):ip_address, parse_json($1):last_name from PERSONS_JSON_VARIANT
After you run the mapping task, the Secure Agent copies the data in columnar format to Snowflake:
External stage
When you configure a file ingestion and replication task to load files from a Microsoft Azure Blob Storage or Amazon S3 source to the Snowflake Data Cloud tables, specify the external staging directory to use in Snowflake.
You must specify the external stage name for the specific connection type that you want to use in the Target Options section in the file ingestion and replication task.
The external stage field value is mandatory when you run a file ingestion and replication task to load files from Microsoft Azure Blob Storage to Snowflake Data Cloud where the connection type in the source is Microsoft Azure Blob Storage V3. When the source connection type is Amazon S3 V2, and you do not specify an external stage for Amazon S3 V2 in the Snowflake Data Cloud target options, Snowflake creates an external stage directory by default. You must have the create external stage and copy command permissions to connect to Snowflake.
Ensure that the source directory path in the Source Options of the file ingestion and replication task is the same as the directory path provided in the URL of the external stage created for the Microsoft Azure Blob Storage V3 or Amazon S3 V2 connection in Snowflake Data Cloud.
For example, an external stage for Microsoft Azure Blob Storage created using an Azure account name and a blob container with a folder path has the following stage URL: 'azure://<URL>/<blob container>/<folder path>'. The stage uses the file format you specify in the Target Options of the file ingestion and replication task.
The following image shows the stage name and the stage URL for a Microsoft Azure Blob Storage V3 connection in Snowflake Data Cloud:
In the example, the stage URL is azure://adapterdevblob.blob.core.windows.net/snowflakemi/MI/ and the external stage name is MFT_BLOB1.
When you create a file ingestion and replication job, in the Folder Path field in the Source Options of the Microsoft Azure Blob Storage V3 source, specify the following <Blob Container>/<folder path> path from the stage URL: /snowflakemi/MI
The following image shows the specified source folder path in the Source Options section:
In the Target Options for Snowflake Data Cloud, specify the following name of the created external stage: MFT_BLOB1
The following figure shows the configured external stage field in the Target Options section:
Rules and Guidelines for Snowflake Data Cloud file ingestion and replication tasks
When you configure a file ingestion and replication task to write to Snowflake Data Cloud from the supported file ingestion and replication sources, you must specify a batch size for the maximum number of files to be transferred in a batch. Specify a value for the batch size in the required source properties of the file ingestion and replication task. When you specify a batch size, the performance of the task is optimized.
The default batch size is 5. When you write from Amazon S3 or Azure Blob Storage sources to a Snowflake target, you can specify a maximum batch size of 1000 in the Amazon S3 or Azure Blob Storage source properties. For other file ingestion and replication supported sources, you must specify a batch size between 1 and 20.
Configuring file processing actions
You can define file processing actions, such as compress and encrypt, that File Ingestion and Replication performs on files before it transfers them.
1To add file processing actions, click the plus sign in the Actions tab.
The Action Details window appears.
2Perform the following file processing actions:
Action
Description
Compress
To compress the files, select Compress. Then select one of the following action types:
- Zip
- Gzip
- Tar
- Bzip2
You can choose to protect a .zip file by entering a password. If the .zip file contains multiple files, the same password applies to all the compressed files.
Decompress
To decompress compressed files, select Decompress. Then select one of the following action types:
- Unzip
- Gunzip
- Untar
- Bunzip2
Use the action type that corresponds to the compression action type that was used to compress the file. For example, for a .zip file, use the Unzip method.
Enter the correct password to decompress a password-protected .zip file. A job fails if you decompress zipped files with incorrect passwords. For example: If you have five files and four of them are protected with the same password, but one file has a different password, then the job fails to run when it tries to decompress the file with the different password.
When you open compressed files that don't use a password, file ingestion and replication ignores the password that you entered in the action. For example: If you have five files and only four of them are password protected, then the job runs successfully and decompresses all the five files.
Encrypt
To encrypt files by using the PGP encryption method, select Encrypt. Then, select PGP and enter the key ID of the user who decrypts the file.
- To add your sign key, select Sign.
The key ID and the key passphrase are enabled.
- Enter the file suffix. Default is .pgp. You can override the default value.
- Enter your private key ID and key passphrase. Do not include spaces in key passphrases.
Note:
For more information about securing files that file ingestion and replication transfers, see File Ingestion and Replication security.
Decrypt
To decrypt PGP-encrypted files, select Decrypt. Then, select PGP and enter the key passphrase of the user of the target directory. Do not include spaces in key passphrases.
File Operations
To perform operations on the files in the target directory, select File Operations. Then select one of the following action types:
- Flatten. To move files from multiple folders to a single folder in the target directory.
- Rename Files. To rename files in the target directory.
If you choose to rename files as the action, enter a variable to suffix the renamed file.
Virus scan
To scan files for viruses by using the ICAP protocol, select Virus Scan. Then select ICAP and enter the ICAP Server URL or the server where the files are scanned. ICAP sends a response code that indicates whether the malwares are detected in the files.
Note:
Use the ICAP server of the organization.
3Click Save.
To add another action, click the plus sign. To delete an action, click Delete. To change the order in which the file ingestion and replication task processes files, drag and drop the sequence of actions.
4Click Next. The Runtime Options tab appears.
Configuring runtime options
You can run a file ingestion and replication task manually, or you can schedule the task to run at a specific time or when a file is ready to transfer. You can receive notifications if the task fails. You can run multiple jobs and file batches concurrently. You can also select the log level that a job creates.
1On the Runtime Options page, under Schedule Details, select one of the following options:
- Do not run this task on a schedule. The task does not run according to a defined schedule. You can run the task manually.
- Run this task on a schedule. Select a schedule by which the task runs.
- Run this task by file listener. The task runs when the file listener notifies the task of a file event. A file event occurs when files arrive to the monitored folder or the files in the monitored folder are updated or deleted.
You must create a file listener that listens to the folder where files arrive. For more information about creating a file listener, see the section "File listeners" in the Components help.
2Under Failure Management, select the Send a notification on failure option to receive notifications if the task fails and if the task detects infected files. Enter a comma-separated list of email addresses to which to send the notifications.
If the file ingestion and replication task detects an infected file, it copies the file from the source to the quarantine directory. The default directory path is <agent location>/data/quarantine.
3Under Advanced Options, select Allow concurrency to run multiple file ingestion and replication task jobs concurrently.
Warning:
Running concurrent jobs might cause unexpected results if the targets include duplicate files.
4Select the number of file batches to run in parallel. Default is 1.
Note:
For database connectors that use the Truncate Target Table option, the Parallel Batch value must be 1.
5Select the log level to determine the level of detail in the logs that the job creates. Select one of the following options:
- Normal. Logs project-level information, such as the name of the user that ran the project, when the project started, any variables that were passed, and when the project stopped. It also logs any errors encountered.
- Silent. Additionally logs the start and stop times of tasks.
- Verbose. Additionally logs task-level details, such as the names of the files that were processed.
- Debug. Additionally logs detailed debugging information, such as message responses from servers.

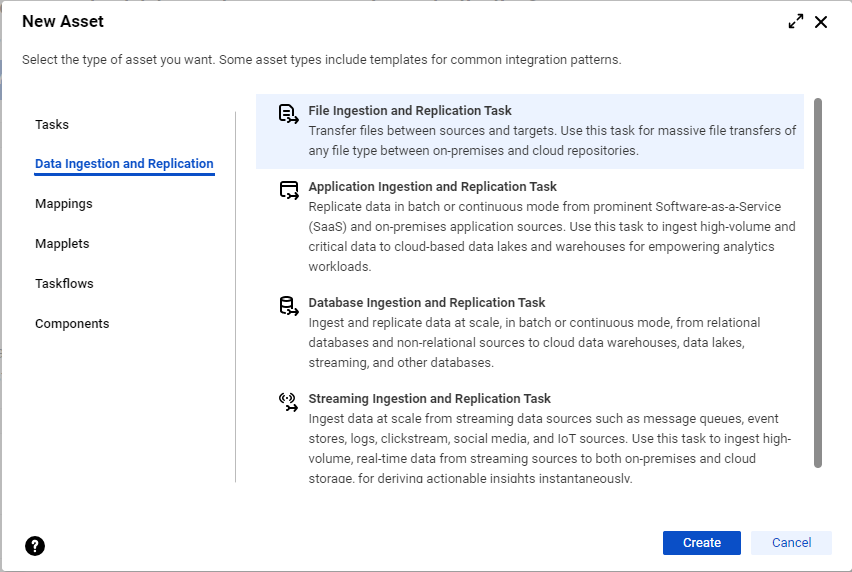

 . The selected system variable appears on the
. The selected system variable appears on the