Configuring a streaming ingestion and replication task
In Data Integration, use the streaming ingestion and replication task wizard to configure a streaming ingestion and replication task. You define a source and a target, and you can optionally define a transformation to transform the data.
On the wizard pages, complete the following configuration tasks:
1Define the basic information of a task, such as the task name, project location and runtime environment.
2Configure a source.
3Configure a target.
4Optionally, add one or multiple transformations.
5Optionally, set the runtime options.
As you work through the task wizard, you can click Save to save your work at any time after you configure the target. When you have completed the wizard, click Save to save the task.
Before you begin, verify that the conditions that are described in Before you begin.
Before you begin
Before you create streaming ingestion and replication tasks, verify that the following conditions are met:
•Check that your organization has licenses for Streaming Ingestion and Replication and the streaming ingestion and replication packages.
•The Streaming Ingestion and Replication is running on the Secure Agent.
•Source and target connections exist.
Defining basic task information
To begin defining a streaming ingestion and replication task, you must first enter some basic information about the task, such as task name, project or project folder location, and runtime environment.
1Start the task wizard in one of the following ways:
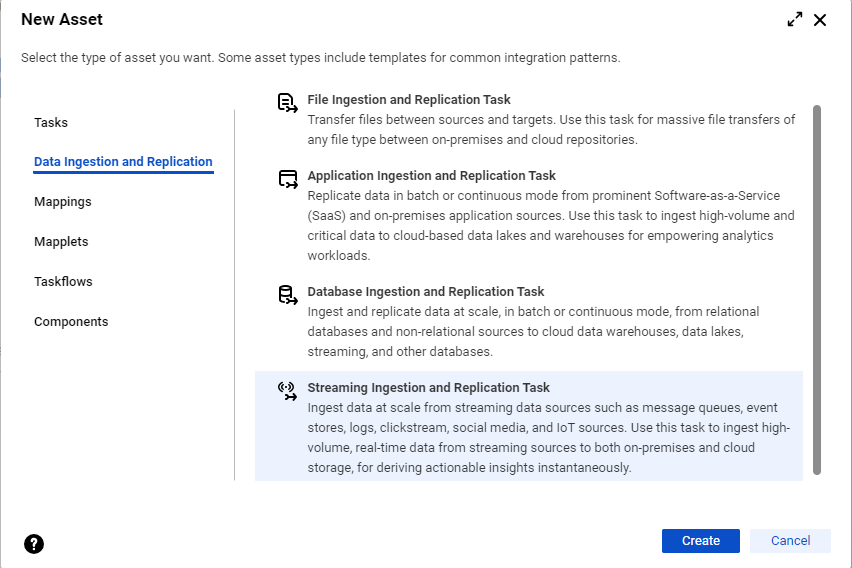
- On the Home page, click the Ingest panel and select Streaming Ingestion and Replication Task.
- In the navigation bar on the Explore page or the Home page, click New to open the New Asset dialog box. Then, select Data Ingestion and Replication > Streaming Ingestion and Replication Task and click Create.
Note:
If your organization does not have a custom license for application, database, file, or streaming ingestion and replication, the Data Ingestion and Replication category still appears but you cannot select and configure an ingestion and replication task of the unlicensed task type or types.
The Definition page of the streaming ingestion and replication task wizard appears.
2Configure the following properties:
Property
Description
Name
A name for the streaming ingestion and replication task.
The name of an streaming ingestion and replication task must be unique within the organization. The task name can contain alphanumeric characters, commas, plus signs, minus signs, spaces, and underscores. Names must begin with an alphabetic character or underscore.
Task names are not case-sensitive.
Location
The project folder to store the task.
Runtime Environment
Runtime environment that contains the Secure Agent. The Secure Agent runs the task.
For streaming ingestion and replication tasks, the Cloud Hosted Agent is not supported and does not appear in the Runtime Environment list. Serverless runtime environments are also not supported.
Description
Optional. Description about the task. Maximum length is 4,000 characters.
3Click Next
Configuring a source
To configure a source, select a source connection from which you want to ingest streaming data and then configure source properties. Before you configure a source, ensure that the connection to the source is created in the Administrator service.
1On the Source page, select a connection.
The streaming ingestion and replication task supports the following sources:
- Amazon Kinesis Streams
- AMQP
- Apache Kafka
- Business 360 Events
- Flat file
- Google PubSub
- JMS
- MQTT
- OPC UA
- REST V2
The connection type populates automatically based on the connection that you select.
2Based on the source that you select, enter the required details.
Options that appear on the Source tab of the task wizard vary based on the type of source that you select.
3Under Advanced Properties, enter the required information.
4Click Next.
The Target tab appears.
Amazon Kinesis Streams source properties
The following table describes the Amazon Kinesis Streams source properties on the Source tab when you define a streaming ingestion and replication task:
Property
Description
Connection
Name of the Amazon Kinesis Stream source connection.
Connection Type
The Amazon Kinesis connection type.
The connection type populates automatically based on the connection that you select.
Stream
Name of the Kinesis Stream from which you want to read data.
The following table describes the advanced properties for Amazon Kinesis Streams sources in the Source tab when you define a streaming ingestion and replication task:
Property
Description
Append GUID to DynamoDB table name
Specifies whether or not to add a GUID as a suffix to the Amazon DynamoDB table name. If disabled, you must enter the Amazon DynamoDB table name. Default is enabled.
Amazon DynamoDB
Amazon DynamoDB table name to store the checkpoint details of the Kinesis source data.
The Amazon DynamoDB table name is generated automatically. However, if you enter a name of your choice, the streaming ingestion and replication task prefixes the given name to the auto-generated name.
For more information about Kinesis Streams, see the Amazon Web Services documentation.
AMQP source properties
The following table describes the Advanced Message Queuing Protocol (AMQP) source properties on the Source tab when you define a streaming ingestion and replication task:
Property
Description
Connection
Name of the AMQP source connection.
Connection Type
The AMQP connection type.
The connection type populates automatically based on the connection that you select.
Queue
Name of the existing AMQP queue from which the streaming ingestion and replication task reads the messages. This queue is pre-defined by the AMQP administrator.
Auto Acknowledge messages
You can choose True or False. If you choose True, the AMQP broker automatically acknowledges the received messages.
Batch Size
The maximum number of messages that must be pulled in a single session.
Default is 10 messages.
Azure Event Hubs Kafka source properties
You can create a Kafka connection with Azure Event Hubs namespace.
When you create a standard or dedicated tier Event Hubs namespace, the Kafka endpoint for the namespace is enabled by default. You can then use the Azure Event Hubs enabled Kafka connection as a source connection while creating a streaming ingestion and replication task. Enter the Event Hubs name as the topic name.
The following table describes the Kafka source properties on the Source tab when you define a streaming ingestion and replication task:
Property
Description
Connection
Name of the Kafka source connection.
Connection Type
The Kafka connection type.
The connection type populates automatically based on the connection that you select.
Topic
Name of the Event Hubs from which you want to read the events.
You can either enter the topic name manually or fetch the already created metadata of the Kafka enabled Event Hubs connection.
1Click Select.
The Select Source Object dialog box appears showing all the available topics.
2Select the required topic and click OK.
The following table describes the advanced properties for Kafka sources in the Source tab when you define a streaming ingestion and replication task:
Property
Description
Consumer Configuration Properties
Comma-separated list of configuration properties for the consumer to connect to Kafka. Specify the values as key-value pairs. For example, key1=value1, key2=value2.
The group.id property of Kafka consumer is autogenerated. You can override this property.
Note:
Event Hubs for Kafka is available only on standard and dedicated tiers. The basic tier doesn't support Kafka on Event Hubs.
Business 360 Events source properties
The following table describes the Business 360 Events source properties on the Source tab when you define a streaming ingestion and replication task:
Property
Description
Connection
Select a Business 360 Events connection to read events from the Business 360 data store.
Connection Type
The connection type, that is, Business 360 Events.
Note:
You can't modify this attribute.
Business Object
Select the publishing event asset from which you want to read the data.
Flat File source properties
The following table describes the flat file source properties on the Source tab when you define a streaming ingestion and replication task:
Property
Description
Connection
Name of the flat file source connection.
Connection Type
The Flat file connection type.
The connection type appears automatically based on the connection that you select.
Initial Start Position
Starting position from which the data is to be read in the file to tail. You can choose one of the following positions to start reading:
- Beginning of File. Read from the beginning of the file to tail. Do not ingest any data that has already been rolled over.
- Current Time. Read from the most recently updated part of the file to tail. Do not ingest any data that has already been rolled over or any data in the file to tail that has already been written.
Tailing Mode
Tail a file or multiple files based on the logging pattern.
You can choose one of the following modes:
- Single File. Tail only one file.
- Multiple Files. Tail all the files indicated in the base directory. In this mode, you can enter a regular expression to indicate the files to tail.
File
Absolute path with the name of the file you want to read.
Name of the file to tail or regular expression to find the files to tail. Enter the base directory for multiple files mode.
The following table describes the advanced properties that you can configure for flat file sources on the Source tab when you define a streaming ingestion and replication task:
Connection Property
Description
Rolling Filename Pattern
Name pattern for the file that rolls over.
If the file to tail rolls over, the file name pattern is used to identify files that have rolled over. The underlying streaming ingestion Secure Agent recognizes this file pattern. When the Secure Agent restarts, and the file has rolled over, it picks up from where it left off.
You can use asterisk (*) and question mark (?) as wildcard characters to indicate that the files are rolled over in the same directory. For example, ${filename}.log.*. Here, asterisk (*) represents the successive version numbers that would be appended to the file name.
Google PubSub source properties
The following table describes the Google PubSub source properties on the Source tab when you define a streaming ingestion and replication task:
Property
Description
Connection
Name of the Google PubSub source connection.
Connection Type
The Google PubSub connection type.
The connection type populates automatically based on the connection that you select.
Subscription
Name of the subscription on the Google PubSub service from which messages should be pulled.
The Google PubSub connection supports only the pull delivery type for a subscription.
Batch Size
Maximum number of messages that the Cloud service bundles together in a batch.
Default is 1.
JMS source properties
The following table describes the JMS source properties on the Source tab when you define a streaming ingestion and replication task:
Property
Description
Connection
Name of the JMS source connection.
Connection Type
JMS connection type. The connection type populates automatically based on the connection that you select.
Destination Type
Type of destination that the source service sends the JMS message to. You can choose one of the following destination types:
- Queue. The JMS provider delivers messages to a single consumer who is registered for the queue.
- Topic. The JMS provider delivers messages to all active consumers who subscribe to the topic. When you use this destination type, multiple consumers can read the message.
Default is Queue.
Shared Subscription
Enables multiple consumers to access a single subscription. Applies to the topic destination type.
Default is false.
Durable Subscription
Enables inactive subscribers to retain messages and deliver retained messages when the subscribers reconnect. Applies to the topic destination type.
Default is false.
Subscription Name
Name of the subscription. Applies to the topic destination type, when the topic subscription is sharable, durable, or both. If no value is specified, the ingestion service generates a unique subscription name.
JMS Destination
Name of the queue or topic that the JMS provider delivers the message to.
Note:
If a JMS connection is created with the JMS Weblogic server, the queue or topic JMS Destination must start with a period, followed by a slash (./). For example:
./<JMS Server module name>!<Queue or topic name>
For more information about connecting Streaming Ingestion and Replication to an Oracle Weblogic JMS server, see Informatica Knowledge Base article 000186952.
The following table describes the advanced properties for JMS sources in the Source tab when you define a streaming ingestion and replication task:
Property
Description
Client ID
Optional. Unique identifier that identifies the JMS connection.
The streaming ingestion and replication task generates a unique client ID if a value isn't specified for an unshared durable subscription.
JMS Version
The JMS version to use with your JMS provider.
Select the JMS version that is compatible with your JMS provider:
- 3.0. Use this version only for the Oracle Weblogic JMS provider.
- 2.0. Use this version for all other JMS providers.
Default is 2.0.
Kafka source properties
When you define Kafka as the source of a streaming ingestion and replication task, you must configure the mandatory Kafka source properties on the Source tab. Optionally, provide a comma-separated list of consumer configuration properties.
The following table describes the mandatory Kafka source properties:
Property
Description
Connection
Name of the Kafka source connection.
Connection Type
The Kafka connection type.
The connection type populates automatically based on the connection that you select.
Topic
Kafka source topic name or a Java supported regular expression for the Kafka source topic name pattern to read the events from.
You can either enter the topic name manually or fetch the metadata of the Kafka connection. To select the metadata of the Kafka connection perform the following actions:
1Click Select.
The Select Source Object dialog box appears, showing all the topics or topic patterns available in the Kafka broker.
2Select the topic and click OK.
Note:
When you add a new Kafka source topic to a streaming ingestion and replication job that is in Up and Running state, redeploy the job immediately to avoid data loss from the new topics.
Consumer Configuration Properties
On the Advanced Properties section of the Source tab, in Consumer Configuration Properties, you can provide a comma-separated list of optional consumer configuration properties. Specify the values as key-value pairs.
The following table describes the consumer configuration properties that you can configure for Kafka sources:
Property
Description
group.id
Specifies the name of the consumer group the Kafka consumer belongs to. If group.id doesn't exist when you construct the Kafka consumer, the task creates the consumer group automatically. This property is auto-generated. You can override this property. Default is key1=value1, key2=value2.
auto.offset.reset
Specifies the behavior of the consumer when there is no committed position or when an offset is out of range.
You can use the following types of auto offset reset:
- Earliest. Resets the offset position to the beginning of the topic.
- Latest. Resets the offset position to the latest position of the topic.
- None.
When you read data from a Kafka topic or use a topic pattern and the offset of the last checkpoint is deleted during message recovery, provide the following property to recover the messages from the next available offset:
auto.offset.reset=earliest
Otherwise, the streaming ingestion and replication task reads data from the latest offset available.
message-demarcator
Kafka source receives messages in batches. You can contain all Kafka messages in a single batch for a given topic and partition. This property allows you to provide a string to use as a demarcation for multiple Kafka messages. If you don't provide a value, each Kafka message is triggered as a single event.
You can use the following delimiters as demarcators:
- New line. Separates the new content with a new line feed. Enter the following value to use a new line as a message demarcator:
Specifies the maximum number of records returned in a single call to poll.
For example, max.poll.records=100000
MQTT source properties
The following table describes the MQTT source properties on the Source tab when you define a streaming ingestion and replication task:
Property
Description
Connection
Name of the MQTT source connection.
Connection Type
The MQTT connection type.
The connection type populates automatically based on the connection that you select.
Topic
Name of the MQTT topic.
The following table describes the advanced properties for the MQTT source on the Source tab when you define a streaming ingestion and replication task:
Connection Property
Description
Client ID
Optional. Unique identifier that identifies the connection between the MQTT source and the MQTT broker. The client ID is the file-based persistence store that the MQTT source uses to store messages when they are being processed.
If you do not specify a client ID, the streaming ingestion and replication task uses the client ID provided in the MQTT connection. However, if you have not specified the client ID even in the MQTT connection, the streaming ingestion and replication task generates a unique client ID.
Max Queue Size
Optional. The maximum number of messages that the processor can store in memory at the same time.
Default value is 1024 bytes.
OPC UA source properties
The following table describes the OPC UA source properties on the Source tab when you define a streaming ingestion and replication task:
Property
Description
Connection
Name of the OPC UA source connection.
Connection Type
The OPC UA connection type.
The connection type populates automatically based on the connection that you select.
Tag List Specified As
Format in which the list of tags is specified.
Select one of the following formats:
- List of Tags. List of tags to be read by the OPC client, specified as a JSON array.
- Path for Tags File. File containing list of tags to be read by the OPC client, specified as a JSON array.
Tags or File Path
List of tags or path to the file containing the list of tags to be read, specified as a JSON array.
The list of tags or file path cannot exceed 2048 characters.
Minimum Publish Interval
The minimum publish interval of subscription notification messages, in milliseconds.
Set this property to a lower value to detect the rapid change of data.
Default is 1,000 milliseconds.
REST V2 source properties
The following table describes the REST V2 source properties on the Source tab when you define a streaming ingestion and replication task:
Property
Description
Connection
Name of the REST V2 source connection.
Connection Type
The REST V2 connection type.
The connection type populates automatically based on the connection that you select.
REST Endpoints
List of REST endpoints specified in the input Swagger file.
These endpoints appear based on the chosen REST connection.
Scheme
List of schemes specified in the Swagger definition.
The selected scheme is used to create a the URL.
Poll Interval
Interval between two consecutive REST calls.
Default is 10 seconds.
Action on Unsuccessful Response codes
Action required for unsuccessful REST calls.
You can choose of the following actions:
- Raise Alert
- Route to Downstream. Route the response to the downstream processors.
- Route to Reject Directory: Route the response to the reject directory configured in Runtime Options page.
Based on the defined operation ID in the selected REST Endpoints property, the dynamic properties such as, Path, Query, and Payload appear at the lower section of the REST V2 source page.
•Headers. Adds header to a REST call.
•Path. Consists of multiple path parameters as specified in Swagger definition. You cannot edit the Path Key. You can only enter corresponding values for the path keys.
•Query. Consists of query parameters. Query parameters are similar to path parameters.
•Payload.
- Sample Payload. A read-only text box that shows schema of request body for a PUT, POST, or PATCH request. For example, { "name" : "string", "salary" : "string", "age" : "string" }.
- Body. The request body to be sent incase of PUT, POST, or PATCH request. You can copy a sample request body from a sample payload and then can replace the values as appropriate.
You can define any of these properties as mandatory in the Swagger specification file. Then, the same property is considered mandatory while configuring a streaming ingestion and replication REST V2 source. If you do not define a REST endpoint in the Swagger specification file, the corresponding section does not appear on the streaming ingestion and replication REST V2 page.
Note:
When you configure a streaming ingestion and replication task, the absolute path of the Swagger specification file you provide must be available in the runtime environment.
Configuring a target
To configure a target, select a target connection to which you want to transfer the streaming data and then configure the target properties. Before you configure a target, ensure that the connection to the target is created in the Administrator service.
1On the Target page, select a connection.
The streaming ingestion and replication task supports the following targets:
- Amazon Kinesis Data Firehose
- Amazon Kinesis Streams
- Amazon S3 V2
- Apache Kafka
- Databricks
- Flat file
- Google BigQuery V2
- Google PubSub
- Google Cloud Storage V2
- JDBC V2
- Microsoft Azure Data Lake Storage Gen2
- Microsoft Azure Event Hubs
2Based on the target that you select, enter the required details.
Options that appear on the Target tab of the task wizard vary based on the type of target that you select.
3Under Advanced Properties, enter the required information.
The following table describes the Amazon Kinesis Data Firehose target properties on the Target tab when you define a streaming ingestion and replication task:
Property
Description
Connection
Name of the Amazon Kinesis Data Firehose target connection.
Connection Type
The Amazon Kinesis connection type.
The connection type populates automatically based on the connection that you select.
Stream Name/Expression
Kinesis stream name or a regular expression for the Kinesis stream name pattern.
Use the $expression$ format for the regular expression. $expression$ evaluates the data and sends the matching data to capturing group 1.
For more information about Kinesis Data Firehose, see the Amazon Web Services documentation.
Amazon Kinesis Streams target properties
The following table describes the Amazon Kinesis Streams target properties on the Target tab when you define a streaming ingestion and replication task:
Property
Description
Connection
Name of the Amazon Kinesis Stream target connection.
Connection Type
The Amazon Kinesis connection type.
The connection type populates automatically based on the connection that you select.
Stream Name/Expression
Kinesis stream name or a regular expression for the Kinesis stream name pattern.
Use the $expression$ format for the regular expression. $expression$ evaluates the data and sends the matching data to capturing group 1.
For more information about Kinesis Streams, see the Amazon Web Services documentation.
Amazon S3 target properties
The following table describes the Amazon S3 target properties on the Target tab when you define a streaming ingestion and replication task:
Property
Description
Connection
Name of the Amazon S3 target connection.
Connection Type
The Amazon S3 V2 connection type.
The connection type populates automatically based on the connection that you select.
Object Name/Expression
Amazon S3 file name or a regular expression for the Amazon S3 file name pattern.
Use the $expression$ format for a regular expression. $expression$ evaluates the data and sends the matching data to capturing group 1.
The following table describes the Amazon S3 advanced target properties that you can configure on the Target tab when you define a streaming ingestion and replication task:
Property
Description
Partitioning Interval
Optional. The time interval according to which the streaming ingestion task creates partitions in the Amazon S3 bucket. To use this option, you must add a ${Timestamp} expression to the object name in the Object Name/Expression field.
Optional. Minimum upload part size when uploading a large file as a set of multiple independent parts, in megabytes. Use this property to tune the file load to Amazon S3.
Default value is 5120 MB.
Multipart Upload Threshold
Optional. Multipart download minimum threshold to determine when to upload objects in multiple parts in parallel.
Default value is 5120 MB.
Azure Event Hubs target properties
The following table describes the Azure Event Hubs target properties on the Target tab when you define a streaming ingestion and replication task:
Property
Description
Connection
Name of the Azure Event Hubs target connection.
Connection Type
The Azure Event Hubs connection type.
The connection type populates automatically based on the connection that you select.
Event Hub
The name of the Azure Event Hubs.
The following table describes the Azure Event Hubs advanced target properties that you can configure on the Target tab when you define a streaming ingestion and replication task:
Property
Description
Shared Access Policy Name
Optional. The name of the Event Hub Namespace Shared Access Policy.
The policy must apply to all data objects that are associated with this connection.
To read from Event Hubs, you must have Listen permission. To write to an Event Hub, the policy must have Send permission.
Shared Access Policy Primary Key
Optional. The primary key of the Event Hub Namespace Shared Access Policy.
Databricks target properties
The following table describes the Databricks target properties on the Target tab when you define a streaming ingestion and replication task:
Property
Description
Connection
Name of the Databricks target connection.
Connection Type
The Databricks connection type.
The connection type populates automatically based on the connection that you select.
Staging Location
Relative directory path to store the staging files.
- If the Databricks cluster is deployed on AWS, use the relative path of the Amazon S3 staging bucket.
- If the Databricks cluster is deployed on Azure, use the relative path of the Azure Data Lake Store Gen2 staging file system name.
Target Table Name
Name of the Databricks table to append.
The following table describes the Databricks target advanced properties that you can configure on the Target tab when you define a streaming ingestion and replication task:
Property
Description
Target Database Name
Overrides the database name provided in the Databricks connection in Administrator.
For a Databricks target, the source messages must be only in JSON format.
Note:
In a streaming ingestion and replication job with Databricks target, when you change the source schema to include additional data columns, Informatica recommends that you redeploy the job to include the change data capture.
When you use a Filter transformation in a streaming ingestion and replication task with a Databricks target, ensure that the ingested data conforms to a valid JSON data format. The Filter transformation with JSONPath filter type validates the incoming data. If the incoming data does not conform to a valid JSON data format, the streaming ingestion and replication task rejects the data. The rejected data then moves into the configured reject directory. If you do not have a reject directory already configured, the rejected data is lost.
Informatica recommends that you use a Combiner transformation in the streaming ingestion and replication task that contains a Databricks target. Add the Combiner transformation before writing to the target. The streaming ingestion and replication task then combines all the staged data before writing into the Databricks target. To optimize performance, batch 100 records or more.
Flat file target properties
The following table describes the flat file target properties on the Target tab when you define a streaming ingestion and replication task:
Property
Description
Connection
Name of the flat file target connection.
Connection Type
The flat file connection type.
The connection type appears based on the connection that you select.
Staging Directory Location
Path to the staging directory on the Secure Agent.
Specify the staging directory where to stage the files when you write data to a flat file target. Ensure that the directory has sufficient space and you have write permissions to the directory.
Rollover Size *
The file size, in KB, at which the task moves the file from the staging directory to the target.
For example, set the rollover size to 1 MB and name the file target.log. If the source service sends 5 MB to the target, the streaming ingestion and replication task first creates the target.log.<timestamp> file. When the size of target.log.<timestamp> reaches 1 MB, the task rolls the file over.
Rollover Events Count *
Number of events or messages to accumulate for file rollover.
For example, if you set the rollover events count to 1000, the task rolls the file over when the file accumulates 1000 events.
Rollover Time *
Length of time, in milliseconds, for a target file to roll over. After the time period has elapsed, the target file rolls over.
For example, if you set rollover time as 1 hour, the task rolls the file over when the file reaches a period of 1 hour.
File Name
The name of the file that the task creates on the target.
* Specify a value for at least one rollover option to perform target file rollover.
Google BigQuery V2 target properties
The following table describes the Google BigQuery V2 target properties on the Target tab when you define a streaming ingestion and replication task:
Property
Description
Connection
Name of the Google BigQuery V2 target connection.
Connection Type
The Google BigQuery V2 connection type.
The connection type populates automatically based on the connection that you select.
Dataset Name
Name of the Google BigQuery dataset. The dataset must exist in the Google Cloud Platform.
Table name
Name of the Google BigQuery table to insert data to in JSON format.
Google Cloud Storage target properties
The following table describes the Google Cloud Storage target properties on the Target tab when you define a streaming ingestion and replication task:
Property
Description
Connection
Name of the Google Cloud Storage target connection.
Connection Type
The Google Cloud Storage connection type.
The connection type populates automatically based on the connection that you select.
Number of Retries
The number of times the streaming ingestion and replication task retries to write to the Google Cloud Storage target.
Default is 6.
Bucket
The container to store, organize, and access objects that you upload to Google Cloud Storage.
Key
Name of the Google Cloud Storage target object.
The following table describes the Google Cloud Storage advanced target properties on the Target tab when you define a streaming ingestion and replication task:
Property
Description
Proxy Host
Host name of the outgoing proxy server that the Secure Agent uses.
Proxy Port
Port number of the outgoing proxy server.
Content Type
The file content type.
You can specify any MIME types, such as application.json, multipart, text, or html. These values are not case sensitive.
Default is text.
Object ACL
Access control associated with the uploaded object.
Choose one of the following types of authentication:
- Authenticated Read. Gives the bucket or object owner FULL_CONTROL permission and gives all authenticated Google account holders READ permission.
- Bucket Owner Full Control. Grants full control permission to the bucket or object owner and grants read permission to all the authenticated Google account holders.
- Bucket Owner Read Only. Grants full control permission to the object owner and grants read permission to the bucket owner. Use this type only with objects.
- Private. Gives the bucket or object owner FULL_CONTROL permission for a bucket or object.
- Project Private. Gives permission to the project team based on their roles. Anyone who is part of the team has READ permission and project owners and project editors have FULL_CONTROL permission. This is the default ACL for newly created buckets.
- Public Read Only. Gives the bucket owner FULL_CONTROL permission and gives all anonymous users READ and WRITE permission. This ACL applies only to buckets. When you apply this to a bucket, anyone on the Internet can list, create, overwrite, and delete objects without authenticating.
Server Side Encryption Key
Server-side encryption key for the Google Cloud Storage bucket. Required if the Google Cloud Storage bucket is encrypted with SSE-KMS.
Content Disposition Type
Type of RFC-6266 Content Disposition to be attached to the object. Choose either Inline or Attachment.
Google PubSub target properties
The following table describes the Google PubSub target properties on the Target tab when you define a streaming ingestion and replication task:
Property
Description
Connection
Name of the Google PubSub target connection.
Connection Type
The Google PubSub connection type.
The connection type populates automatically based on the connection that you select.
Topic
Name of the target Google PubSub topic.
Batch Size
Maximum number of messages that the Cloud service bundles together in a batch.
Default is 1.
JDBC V2 target properties
The following table describes the JDBC V2 target properties on the Target tab when you define a streaming ingestion and replication task:
Property
Description
Connection
Name of the JDBC V2 target connection.
Connection Type
The JDBC V2 connection type.
The connection type populates automatically based on the connection that you select.
Table name
Name of the table to insert data to in JSON format.
Kafka target properties
The following table describes the Kafka target properties that on the Target tab when you define a streaming ingestion and replication task:
Property
Description
Connection
Name of the Kafka target connection.
Connection Type
The Kafka connection type.
The connection type populates automatically based on the connection that you select.
Topic Name/Expression
Kafka topic name or a Java supported regular expression for the Kafka topic name pattern.
Use the $expression$ format for the regular expression. $expression$ evaluates the data and sends the matching data to capturing group 1.
You can either enter the topic name manually or fetch the already created metadata of the Kafka connection.
1Click Select.
The Select Target Object dialog box appears showing all the topics available in the Kafka broker. However, Kafka topic name patterns do not appear in the list.
2Select the required topic and click OK.
The following table describes the Kafka advanced target properties on the Target tab when you define a streaming ingestion and replication task:
Property
Description
Producer Configuration Properties
The configuration properties for the producer.
Metadata Fetch Timeout in milliseconds
The time after which the metadata is not fetched.
Batch Flush Size in bytes
The batch size of the events after which a streaming ingestion and replication task writes data to the target.
Microsoft Azure Data Lake Storage Gen2 target properties
The following table describes the Microsoft Azure Data Lake Storage Gen2 (ADLS Gen2) target properties on the Target tab when you define a streaming ingestion and replication task:
Property
Description
Connection
Name of the Microsoft Azure Data Lake Storage Gen2 target connection.
Connection Type
The ADLS Gen2 connection type.
The connection type populates automatically based on the connection that you select.
Write Strategy
The operation type to write data to ADLS Gen2 file.
If the file exists in ADLS Gen2 storage, you can select to overwrite, append, fail, or rollover the existing file.
Default is Append.
- Append. Add data to an existing file inside a directory.
- Overwrite. Delete existing data in an existing file and insert newly read data.
- Fail. Write data to an existing file fails.
- Rollover. Close the current file to which data is being written to and create a new file based on the configured rollover value.
Note:
- When you edit or redeploy a streaming ingestion and replication job that contains a target with the rollover strategy, all the files in the staging directory are moved to the target directory even if the defined rollover conditions are not met.
- The file name in the target directory has the timestamp in the following format:
Specify the staging directory where you want to stage the files when you write data to ADLS Gen2. Ensure that the directory has sufficient space and you have write permissions to the directory.
Applicable when you select the Write Strategy as Rollover.
While configuring an ADLS Gen 2 target in a streaming ingestion and replication job, if you do not specify any value for the rollover properties, the files remain in the interim directory. When you stop or undeploy the streaming ingestion and replication job, these files in the interim directory are moved to the target location, by default.
Rollover Size
Target file size, in kilobytes (KB), at which to trigger rollover.
Applicable when you select the Write Strategy as Rollover.
Rollover Events Count
Number of events or messages that you want to accumulate for the rollover.
Applicable when you select the Write Strategy as Rollover.
Rollover Time
Length of time, in milliseconds, for a target file to roll over. After the time period has elapsed, the target file rolls over.
Applicable when you select the Write Strategy as Rollover.
File Name/Expression
File name or a regular expression for the file name pattern.
Use the $expression$ format for the regular expression. $expression$ evaluates the data and sends the matching data to capturing group 1.
The following table describes the Microsoft Azure Data Lake Storage Gen2 (ADLS Gen2) advanced target properties on the Target tab when you define a streaming ingestion and replication task:
Property
Description
Filesystem Name Override
Overrides the default file system name provided in connection. This file system name is used write to a file at run time.
Directory Override
Overrides the default directory path.
The ADLS Gen2 directory that you use to write data.
Default is root directory.
The directory path specified while creating the target overrides the path specified while creating a connection.
Compression Format
Optional. Compression format to use before the streaming ingestion and replication task writes data to the target file.
Use one of the following formats:
- None
- Gzip
- Bzip2
- Zlib
- Deflate
Default is None.
To read a compressed file from the data lake storage, the compressed file must have specific extensions. If the extensions used to read the compressed file are not valid, the Secure Agent does not process the file.
Configuring a transformation
You can specify the data format of the streaming data. Based on the data format, you can configure a transformation.
1On the Transformation page, select the format of the streaming data.
The streaming ingestion and replication transformations support the following data formats:
- Binary
- JSON
- XML
2Based on the selected data format, select one of the supported transformations, and configure it.
3To add more than one transformation, click Add Transformations.
aOn the Transformation tab, click Add Transformation.
The New Transformation dialog box appears.
bBased on the transformation type you select, enter the required properties.
cClick Save.
The saved transformation appears under Transformations in the Transformation Details wizard.
4Perform one of the following tasks:
- To configure the runtime options for the task, click Next.
1On the Transformation tab, click + to add a transformation.
The New Transformation dialog box appears.
2Based on the transformation type you select, enter the required properties.
3Click Save.
The saved transformation appears under Transformations in the Transformation Details wizard.
Combiner transformation properties
The following table describes the properties you can configure for a Combiner transformation:
Property
Description
Transformation Type
Select Combiner.
Transformation Name
Name of the Combiner transformation.
Minimum Number of Events
Minimum number of events to collect before the transformation combines the events into a single event.
Default is 1.
Maximum Aggregate Size
Maximum size of the combined events in megabytes.
If not specified, this transformation waits to meet any of the other two conditions before combining the events.
Time Limit
Maximum time to wait before combining the events.
If not specified, this transformation waits for the other conditions before combining the events or waits forever.
Delimiter
Symbols used to specify divisions between data strings in the transformed data.
Applicable only for the binary data format.
Append the delimiter character to the last record in each batch
When there are many batches with events or records, you can choose whether to use the delimiter character at the end of the last record in each batch. This enables the delimiter character to act as the division between each batch.
Filter transformation properties
The following table describes the properties you can configure for a Filter transformation:
Property
Description
Transformation Type
Select Filter.
Transformation Name
Name of the Filter transformation.
Filter Type
Type of filter to evaluate the incoming data.
Use one of the following filter types:
- JSON Path. An expression that consists of a sequence of JSON properties.
- Regular Expression. A range or pattern of values.
- XPath. An expression that selects nodes or node-sets in an XML document.
Expression
Expression for the filter type that you select.
Format Converter transformation properties
When you define a streaming ingestion and replication task and add a Format Converter transformation, provide values for transformation properties on the New Transformation page of the task wizard.
The following table describes the properties you can configure for a Format Converter transformation:
Property
Description
Transformation Type
Select Format Converter.
Transformation Name
Name of the Format Converter transformation.
Convert to Format
The streaming ingestion and replication task converts incoming data to the selected format. Currently, the Format Converter transformation converts the incoming data only to Parquet format.
Date Format *
Enter the format of dates in input fields. For example, MM/dd/yyyy.
Time Format *
Enter the format of time in input fields. For example, HH/mm/ss.
Timestamp Format *
Enter the format of timestamps in input fields.
For example, the epoch timestamp for 10/11/2021 12:04:41 GMT (MM/dd/yyyy HH:mm:ss) is 1633953881 and the timestamp in milliseconds is 1633953881000.
Expect Records as Array
Determines whether to expect a single record or an array of records. Select this property to expect arrays in each record. Applies only to XML incoming messages. By default, this property is deselected.
* If the format is not specified, it is considered in milliseconds since the epoch (Midnight, January 1, 1970, GMT).
Java transformation properties
The following table describes the properties you can configure for a Java transformation:
Property
Description
Transformation Type
Select Java.
Transformation Name
Name of the Java transformation.
Classpath
The JAR file used to run the Java code. You can use a separator to include multiple JAR files. On UNIX, use a colon to separate multiple classpath entries. On Windows, use a semicolon to separate multiple classpath entries.
For example, /home/user/commons-text-1.9.jar; /home/user/json-simple-1.1.1.jar
Import code
Import third-party, built-in, and custom Java packages. You can import multiple packages. Use a semicolon to separate multiple packages. You can use the following syntax to import packages:
import <package name>
For example, import java.io.*;
Main code
A Java code that provides the transformation logic.
If the input records doesn't match the Jolt specification, the transformation writes null records to the target.
Python transformation properties
The following table describes the properties you can configure for a Python transformation:
Property
Description
Transformation Type
Select Python.
Transformation Name
Name of the Python transformation.
Script Input Type
Python script input type. You can either enter the Python script in Script Body or provide the path to the Python script available in the Script Path.
Python Path
Directory to the Python path libraries.
Splitter transformation properties
The following table describes the properties you can configure for a Splitter transformation for binary message format:
Property
Description
Transformation Type
Select Splitter.
Transformation Name
Name of the Splitter transformation.
Split Type
Split condition to evaluate the incoming data.
Use one of the following split types:
- Line Split.
- Content Split.
Line Split Count
The maximum number of lines that each output split file contains, excluding header lines.
Byte Sequence
Specified sequence of bytes on which to split the content.
The following table describes the properties you can configure for a Splitter transformation for JSON message format:
Property
Description
Split Expression
Split condition to evaluate the incoming data.
Use one of the following split types:
- Array Split.
- JSONPath Expression.
JSONPath Expression
A JSONPath expression that specifies the array element to split into JSON or scalar fragments.
The default JSONpath Expression is $.
The following table describes the properties you can configure for a Splitter transformation for XML message format:
Property
Description
Split Depth
The XML nesting depth to start splitting the XML fragments.
The default split depth is 1.
Configuring runtime options
You can configure additional runtime options for the streaming ingestion and replication task. Runtime options include settings to manage reject events and to notify users about errors.
1On the Runtime Options page, under Notification Management, select to either disable the notifications or set the time limit after which you want to receive a notification if an error occurs.
You can set the time in minutes or hours. Default is 10 minutes.
2 Enter a list of email addresses to which you want to send notifications if a task runs with error.
Use commas to separate a list of email addresses. Note that email notification options configured for the organization are not used here.
3Under Agent Parameters, perform the following tasks:
aSpecify a directory to store the rejected events.
Rejected events are not stored by default.
Note that filtered events in a regular expression are not moved to the reject directory.
bTo purge the log files, specify the maximum file size for the log file after which the log file is purged.
You can set the file size in megabytes or gigabytes. Default is 10 MB.
cChoose the severity of an event that you want to log.
The default log level is Info.
The supported log levels are:
▪ Debug. Logs all messages along with additional debug level messages.
▪ Error. Logs only the error messages.
▪ Info. Logs all errors, warnings, and important informational messages.
▪ Warn. Logs all errors and warning messages.
4Under Advanced Parameters, perform the following tasks to improve the performance of the streaming ingestion and replication task:
aClick the icon next to Advanced Parameters.
The Key and Value fields appear.
bSpecify a valid parameter property and its value.
Deploying a streaming ingestion and replication task
After you create a streaming ingestion and replication task, you must deploy it on the Secure Agent for the task to run as a job. Before deploying the task, ensure that the Secure Agent configured for the task is running.
To deploy a task, perform one of the following actions:
- After you save a task, click Deploy.
- In Data Integration, on the Explore page, open the project that contains the task, and then select Deploy from the Actions menu for the task.
A message about successful deployment of the task appears. Your job is now queued to run.
When you edit or undeploy a job, deploying the job again does not affect any other jobs running on the same Secure Agent or Secure Agent group.
When you edit or redeploy a streaming ingestion and replication job that contains a target with the rollover strategy, all the files in the staging directory are moved to the target directory even if the defined rollover conditions are not met.
Undeploying a streaming ingestion and replication job
You can undeploy a streaming ingestion and replication job from the Secure Agent.
In Data Integration, on the Explore page, open the project that contains the job, and then select Undeploy from the Actions menu for the job.
Navigate to the row for the job that you want to undeploy in any of the following monitoring interfaces:
•My Jobs page that's accessed from the navigation bar of the Home page
•All Jobs page in Monitor
•All Jobs tab on the Data Ingestion and Replication page in Operational Insights
When you undeploy a streaming ingestion and replication job, the Secure Agent does not save the previous state histories of the job. So, when you deploy the streaming ingestion and replication task again, the task runs as completely new job.
Stopping and resuming streaming ingestion and replication jobs
You can stop and resume streaming ingestion and replication jobs. Stop or resume a job on the My Jobs page in Data Integration, the All Jobs and Running Jobs pages in Monitor, or the Data Ingestion and Replication page in Operational Insights.
Stop a job.
You can stop a streaming ingestion and replication job that is Up and Running, Running with Error, or Running with Warnings.
To stop a job, open the My Jobs page in Data Integration, or the All Jobs and Running Jobs pages in Monitor, and then select Stop from the Actions menu for the job.
Alternatively, you can stop a streaming ingestion and replication job from the Actions menu in a job row on the Data Ingestion and Replication page in Operational Insights.
You can also use the Stop icon beside the Actions menu to stop the job.
Resume a job.
You can resume a stopped streaming ingestion and replication job.
To resume a job, open the My Jobs page in Data Integration, or the All Jobs and Running Jobs pages in Monitor, and then select Resume from the Actions menu for the job.
Alternatively, you can resume a streaming ingestion and replication job from the Actions menu in a job row on the Data Ingestion and Replication page in Operational Insights.
You can also use the Resume icon beside the Actions menu to resume the job.
When you stop a streaming ingestion and replication job, the Secure Agent saves the previous state histories of the job. When you resume the stopped streaming ingestion and replication job, the job starts running from the last saved state.


 icon next to
icon next to