1[データの変換]ページで、トランスフォーメーションを割り当てるテーブルとカラムを選択します。
[検索]ボックスを使用して、テーブル名またはカラム名に基づいて項目を検索できます。[検索]ボックスの横にある[テーブル名]または[カラム]を選択し、ボックスに完全な名前または名前の一部を入力します。見つかった場合、リストされた項目の名前で文字列が強調表示されます。
2トリムトランスフォーメーションを追加するには、[トランスフォーメーションの追加](その横にある下向きの矢印ではありません)をクリックします。
注:
トリムトランスフォーメーションと行レベルのフィルタは、同じテーブルとカラムに適用することができます。
[データの変換方法]ダイアログボックスが表示されます。
3+(新しい行の追加)アイコンをクリックして、行を追加します。次に、[トランスフォーメーションタイプ]リストで、次のいずれかのオプションを選択します。
- - 左側を切り詰め。文字カラム値の左側のスペースを切り詰めます。
- - 右側を切り詰め。文字カラム値の右側のスペースを切り詰めます。
- - 切り詰め。文字カラム値の左側と右側のスペースを切り詰めます。
[保存]アイコンをクリックして、エントリを追加します。
4[次へ]をクリックすると、[サマリ]タブに移動し、トランスフォーメーション設定を確認することができます。
5[サマリ]タブの設定が適切である場合は、[保存]をクリックして設定を保存し、最初の[データの変換]ページに戻ります。
6別のテーブルまたはテーブルのセットに別のトリムトランスフォーメーションタイプを追加するには、手順1から5を繰り返します。
最初の[データの変換]ページに戻ると、リストにトリムトランスフォーメーションが適用されたテーブルが表示されます。例:

ヒント:
トランスフォーメーションの割り当ては、[データの変換]ページで削除することができます。不要なトランスフォーメーションを含むテーブルを選択し、[すべてクリア]をクリックします。
7テーブルとカラムに行レベルのフィルタを追加するには、テーブルを選択してから[トランスフォーメーションの追加]の横にある下矢印をクリックし、[行フィルタの追加]を選択します。
[行フィルタの追加]オプションは、Db2 for i、Db2 for LUW、Db2 for z/OS、Microsoft SQL Server、Oracle、SAP HANAソーステーブルでのみ使用できます。タスクは任意のロードタイプを使用できます。
![行レベルのフィルタをテーブルとカラムに追加するための、[行フィルタの追加]オプションを選択します。](../ll-dmi-cloud-tasks/images/GUID-2E165889-3694-4663-A095-797614E1376B-low.png "行レベルのフィルタをテーブルとカラムに追加するための、[行フィルタの追加]オプションを選択します。")
[データをフィルタリングするための条件]ダイアログボックスが表示されます。
8フィルタ条件を適用するテーブルとフィルタのタイプを選択します。
- aフィルタを割り当てるテーブルを選択します。
- b以下のフィルタタイプのいずれか1つを選択してください。
- ▪ 基本
- ▪ 詳細
デフォルトのオプションは[基本]です。
9[基本]フィルタを追加するには、次の手順を実行します。
- a+(新しい行の追加)アイコンをクリックして、行を追加します。
- b[カラム名]で、カラムを選択します。
- c[演算子]で、値に使用する演算子のタイプを選択します。
- d[値]で、カラムのタイプに応じて値を選択するか入力します。次に、行の右端にある[保存}アイコンをクリックして条件を保存します。
- e指定した条件の構文をテストするには、[検証]をクリックします。
- fテーブル内の同じカラムまたは別のカラムに別の基本条件を追加するには、手順aからeを繰り返します。
- g変更を検証して保存するには、[保存]をクリックします。
- h基本フィルタ条件の定義が完了した後に、[OK]をクリックして[データの変換]ページに戻ります。
行のフィルタリングでサポートされていないデータ型のカラムには、「サポートされていません」というマークが表示されます。
例えば、次の図は、2つのカラムに設定された条件を含む基本フィルタを示しています。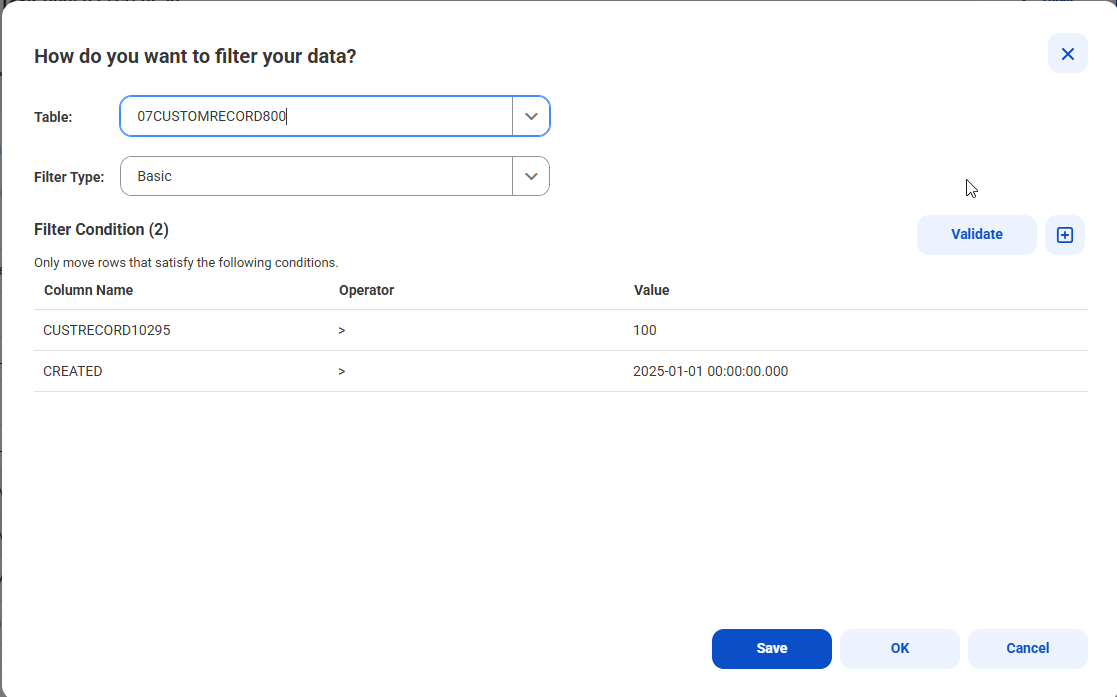
次のテーブルに、フィルタリングでサポートされているそれぞれのカラムのデータ型に有効な値について説明します。
カラムのデータタイプ | 説明 |
|---|---|
INTEGER | 数値を入力してください。「+」と「-」は、数字の前に一度だけ使用することができます。値は、-2147483648~2147483647文字の範囲にする必要があります。 |
Long | 数値を入力してください。「+」と「-」は、数字の前に一度だけ使用することができます。値は、-9,223,372,036,854,775,808~9,223,372,036,854,775,807文字の範囲にする必要があります。 |
BIGINT | 数値を入力してください。「+」と「-」は、数字の前に一度だけ使用することができます。最大長は50桁です。 |
BIGDEC | 数値を入力してください。「+」と「-」は、数字の前に一度だけ使用することができます。10進数を使用することができます。最大長は50桁です。 |
STRING | テキストを入力します。 |
DATE | 日付ピッカーを使用して日付を選択します。 |
TIME | 値はHH:MM:SS.MSの形式で入力します(ミリ秒はオプションで、最大長は9桁です)。 例: 13:14:15.123456789 |
DATETIME | 日付ピッカーを使用して、日付と時刻を選択します。 |
OFFSET_DATETIME | 日付ピッカーを使用して、日付、時刻、およびタイムゾーンを選択します。 |
注:
データベース取り込みとレプリケーションでは、BOOLEAN、BINARY、BLOB、CLOB、およびグラフィックカラムのデータ型はサポートされていません。
AND演算子は、複数の条件を組み合わせる場合に使用します。
10ANDまたはOR演算子を使用して組み合わせた複数の条件で構成される[詳細]フィルタを定義するには、ボックスに条件を手動で入力します。
注:
カラムに基本フィルタ条件を入力した後に詳細フィルタに切り替えた場合は、基本条件が表示されるため、その条件に追加を行うことで、より複雑なフィルタを作成することができます。
- a[カラム名]でカラムを選択し、「>」矢印をクリックします。
- b[フィルタ条件]ボックスに、選択したカラムに対する1つ以上の条件を入力します。サポートされている構文と適切な演算子(カラムのデータ型に応じて異なる場合があります)を使用して、条件を手動で入力します。条件は丸括弧を使用してネストすることもできます。行レベルのフィルタリングの構文を参照してください。完了した後に、行の右端にある[保存]アイコンをクリックして詳細フィルタを保存します。
- ▪ データベース取り込みとレプリケーションでは、BOOLEAN、BINARY、BLOB、CLOB、およびグラフィックカラムのデータ型はサポートされていません。
- ▪ すべての日付、時刻、および日時の値は、ソースの日付と時刻と照合されます。夏時間と標準時間の時間変更はサポートされていません。
- c指定した条件の構文をテストするには、[検証]をクリックします。
- d変更を検証して保存するには[保存]をクリックし、[OK]をクリックして[データの変換]ページに戻ります。
カラム名が[フィルタ条件]ボックスに表示されます。
注:
組み合わせロードタスクの場合は、CDC処理中に更新される可能性があるカラムを含めないようにしてください。カラムが更新されるとレプリケーションに適した状態ではなくなるため、予期しない結果が生じる可能性があります。この場合は、ジョブを再同期する必要があります。
次のテーブルに、フィルタリングでサポートされているそれぞれのカラムのデータ型に有効な値について説明します。
カラムのデータタイプ | 説明 |
|---|---|
INTEGER | 数値を入力してください。「+」と「-」は、数字の前に一度だけ使用することができます。値は、-2147483648~2147483647文字の範囲にする必要があります。 |
Long | 数値を入力してください。「+」と「-」は、数字の前に一度だけ使用することができます。値は、-9,223,372,036,854,775,808~9,223,372,036,854,775,807文字の範囲にする必要があります。 |
BIGINT | 数値を入力します。「+」と「-」は、数字の前に一度だけ使用することができます。最大長は50桁です。 |
BIGDEC | 数値を入力してください。「+」と「-」は、数字の前に一度だけ使用することができます。10進数を使用することができます。最大長は50桁です。 |
STRING | 入力属性を一重引用符(')で囲んで入力します。 |
DATE | 値をYYYY-MM-DDの形式で入力します。入力属性を一重引用符(')で囲んで入力します。 |
TIME | 値をHH:MM:SS.MSの形式で入力します(ミリ秒(MS)はオプションで、最大長は9桁です)。入力属性を一重引用符(')で囲んで入力します。 例: 13:14:15.123456789 |
DATETIME | 以下の形式で日付と時刻を入力します。 YYYY-MM-DDTHH:MM:SS:MS 例: 2024-12-31T03:04:05.123456789 入力属性を一重引用符(')で囲んで入力します。 |
OFFSET_DATETIME | 日付、時刻、およびタイムゾーンを次の形式で入力します。 YYYY-MM-DDTHH:MM:SS.MS+05:00 例: 2024-03-15T10:03:04.123456789+05:00 入力属性を一重引用符(')で囲んで入力します。 |
注:
注:
詳細フィルタ条件を作成または編集した後に[詳細]フィルタタイプから[基本]フィルタタイプに切り替えると、保存を行った場合でも、フィルタ条件に対する変更内容はすべて削除されます。
注:
タスクのデプロイ後に、フィルタに含まれるカラムを変更しないようにしてください。この操作を行うと、行レベルのフィルタリングが適切に機能しなくなる可能性があります。
[データの変換]ページの[フィルタ]カラムに、適用されたフィルタがハイパーリンクとして表示されます。リンクをクリックすると、選択したフィルタが編集モードで開きます。詳細フィルタが設定されたテーブルには、[フィルタ]カラムのフィルタ条件の横に[詳細]と表示されます。
11アクセス管理を設定するには、データアクセスポリシーを適用するテーブルを選択し、[トランスフォーメーションの追加]の横にある下矢印をクリックし、[アクセス管理]を選択します。
[アクセス管理]オプションはSQL Serverソーステーブルでのみ使用できます。

[アクセス管理]ダイアログボックスが表示されます。
12データアクセスポリシーを追加するには、次のフィールドを設定します。
フィールド | 説明 |
|---|---|
コンシューマ | データにアクセスするユーザーのロールは、データガバナンス&カタログ内で定義されています。このロールはデータベース取り込みとレプリケーションタスクのすべてのテーブルに適用されます。 |
使用率 | ユーザーがデータを使用する目的となる利用状況コンテキストを特定します。 ユーザーは、データガバナンス&カタログで使用状況コンテキストを作成および管理します。 |
一貫性シード | トランスフォーメーションがデータ要素の分類に適用するルールロジックを表す値を指定します。 一貫性シードにより、データ要素の分類に対するルールの動作が、すべてのタスクで同じ一貫性シード値、使用状況コンテキスト、およびユーザーに対して一貫性を持つようにします。例えば、姓の「Smith」を常に「Abcd」に置き換えるといったルールを設定することができます。 異なるアクセス管理トランスフォーメーション間で一貫性のあるトークン化が必要な場合は、他のアクセス管理トランスフォーメーションに同じ一貫性シードを挿入します。異なるアクセス管理トランスフォーメーション間で一貫したトークン化が必要ない場合は、一意のシードを生成します。 |
接続 | この接続で参照するデータベースからデータガバナンス&カタログスキャナでスキャンされた関連するデータカタログとデータアセットを取得するために使用する接続を定義します。デフォルトでは、これは設定済みのデータベース取り込みとレプリケーションタスクでソーステーブルにアクセスするために使用される接続と同じです。 |
カタログ | 接続で参照するデータベースからデータガバナンス&カタログスキャナでスキャンされたカタログのコレクション内にある特定のカタログを指定します。このカタログは、対応するデータアセットを特定する目的でソーステーブルと照合するために使用されます。デフォルトでは、直近でスキャンされたカタログが選択されます。 |
前のステップでアクセス管理トランスフォーメーション用に選択したすべてのテーブルに対して、デフォルトのデータアセットが表示されます。
デフォルトのデータアセットは、関連する接続とカタログを使用して、ソーステーブル名とカタログ化されたデータアセット名の完全一致を照合することで取得します。対応するデータアセットが見つからない場合、例えばソーステーブルがスキャンされていない場合や、データアセット名がソーステーブルと完全には一致していない場合、見つからないアセットは赤い縦線で示されます。[見つからないデータを表示]チェックボックスを選択して、対応するデータアセットがないソーステーブルのみをフィルタリングして表示できます。
[OK]をクリックすると、[データの変換]ページに戻ります。
[データの変換]ページの[アクセス管理]カラムには、各テーブルに対して選択したデータアセットがハイパーリンクとして表示されます。リンクをクリックすると、選択したデータアセットが編集モードで開きます。
[データの変換]ページで、右上隅にある[すべてクリア]ボタンをクリックすると、トリムトランスフォーメーション、行レベルのフィルタ、およびアクセス管理ポリシーを含むすべてのフィルタが、選択したテーブルから削除されます。
13完了した後に、[次に]をクリックします。