データベース取り込みとレプリケーション ターゲット - 準備と使用方法データベース取り込みとレプリケーション タスクを初期ロード操作、増分ロード操作、または初期ロードと増分ロードの組み合わせ操作に設定する前に、予期しない結果を回避するために、ターゲットタイプについて次のガイドラインを確認してください。
Amazon Redshiftターゲット 次のリストは、Amazon Redshiftターゲットを準備および使用する際の考慮事項を示しています。
• データベース取り込みとレプリケーション ジョブでは、Amazon RedshiftまたはAmazon Redshift Serverlessターゲットを使用できます。• データベース取り込みとレプリケーション ジョブはデータをAmazon S3バケットにステージングします。データベース取り込みとレプリケーション タスクを設定するときに、バケットの名前を指定する必要があります。データベース取り込みとレプリケーション ジョブはCOPY コマンドを使用して、Amazon S3バケットからAmazon Redshiftターゲットテーブルにデータをロードします。COPY コマンドの詳細については、Amazon Web Servicesのドキュメントを参照してください。• データベース取り込みとレプリケーション ジョブによってデータをステージングしてAmazon Redshiftターゲットテーブルにロードする、Amazon S3バケットのアクセスキーとシークレットアクセスキーを指定します。• • データベース取り込みとレプリケーション ジョブは、ソーステーブルのFLOATカラムの無限値とNaN値を、Amazon Redshiftターゲットテーブルではnull値に変換する。Amazon S3、フラットファイル、Google Cloud Storage、Microsoft Azure Data Lake Storage、Microsoft Fabric OneLake、およびOracle Cloud Object Storageターゲット 次のリストは、Amazon S3、フラットファイル、Google Cloud Storage、Microsoft Azure Data Lake Storage、Microsoft Fabric OneLake、およびOracle Cloud Infrastructure(OCI)Object Storageターゲットを使用する際の考慮事項を示しています。
• データベース取り込みとレプリケーション タスクを定義する場合、ターゲットに適用するソースデータを含む生成された出力ファイルに対してCSV形式、Avro形式、またはParquet形式のいずれかを選択できます。フラットファイルターゲットの場合、出力ファイル形式としてCSVまたはAvroを選択できます。• データベース取り込みとレプリケーション は、ソーステーブルごとに次のファイルをターゲットに作成します。- - データベース取り込みとレプリケーション は、日付と時刻が追加されたソーステーブルの名前に基づいて、これらのテキストファイルに名前を付けます。schema.iniファイルには、対応する出力ファイルの行の一連のカラムが一覧表示されます。次の表で、schema.iniファイルのカラムについて説明します。
カラム
説明
ColNameHeader
ソースデータファイルにカラムヘッダーが含まれているかどうかを示します。
Format
出力ファイルの形式を示します。データベース取り込みとレプリケーション はカンマ(,)を使用してカラムの値を区切ります。
CharacterSet
出力ファイルに使用される文字セットを指定します。データベース取り込みとレプリケーション はUTF-8文字セットでファイルを生成します。
COL<sequence_number>
カラムの名およびデータ型。
重要: schema.iniファイルは編集しないでください。
• スキーマ名 _テーブル名 .txtです。• • データベース取り込みとレプリケーション は空のソーステーブルごとに空のディレクトリを作成します。データベース取り込みとレプリケーション は、Amazon S3、Google Cloud Storage、およびOracle Cloud Object Storageターゲットに空のディレクトリを作成しません。• データベース取り込みとレプリケーション はDefaultAWSCredentialsProviderChainクラスによって実装されているデフォルトの資格情報プロバイダチェーンを使用して、AWS資格情報を見つけようとします。詳細については、Amazon Webサービス のドキュメントを参照してください。• データベース取り込みとレプリケーション の増分ロードジョブ、および初期ロードと増分ロードの組み合わせジョブが、ソースのプライマリキー値をCSV出力形式を使用するこれらのターゲットのいずれかに変更する更新操作をレプリケートする場合、ジョブは各更新レコードをターゲットでの2つのレコード(削除とそれに続く挿入)として処理します。削除には更新前のイメージが含まれています。挿入には同じ行の更新後のイメージが含まれています。プライマリキー値を変更しない更新操作の場合、データベース取り込みとレプリケーション ジョブは各更新を1つの操作として処理し、更新後のイメージのみをターゲットに書き込みます。
注: ソーステーブルにプライマリキーがない場合、データベース取り込みとレプリケーション はすべてのカラムがプライマリキーの一部であるかのようにテーブルを扱います。この場合、各更新操作は、削除とそれに続く挿入として処理されます。
• データベース取り込みとレプリケーション ジョブは、データがAmazon S3、フラットファイル、Microsoft Azure Data Lake Storage、またはMicrosoft Fabric OneLakeターゲットに送信されるときに、16進数形式でバイナリデータをアンロードします。各16進数カラムの値には、「0x」プレフィックスが付いています。出力ファイルを使用してデータをターゲットにロードする場合は、ファイルを編集して「0x」プレフィックスを削除する必要がある場合があります。• Databricksターゲット データベース取り込みとレプリケーション タスクでDatabricksターゲットを使用するには、最初にターゲットを準備し、使用に関する考慮事項を確認してください。
ターゲットの準備:
1 [JDBCドライバクラス名] プロパティをcom.databricks.client.jdbc.Driver に設定します。2 使用に関する考慮事項:
• • - - Databricks接続は、JDBC URLを使用してDatabricksクラスタに接続します。ターゲットを設定するときは、クラスタへの接続に使用するJDBC URLと資格情報を指定します。また、ターゲットがAmazon S3またはADLS Gen2のステージングロケーションに接続するために使用する接続情報を定義します。
• データベース取り込みとレプリケーション ジョブはデータをAmazon S3バケットまたはADLSディレクトリにステージングします。データベース取り込みとレプリケーション タスクを設定するときに、データのディレクトリを指定する必要があります。注: データベース取り込みとレプリケーション は、ディレクトリを決定する際にDatabricks接続プロパティの[ADLSステージングファイルシステム名] と[S3ステージングバケット] プロパティは使用しません。
• データベース取り込みとレプリケーション は、1回だけ実行されるジョブを使用して、Amazon S3またはAzure Data Lake Storage Gen2のステージングファイルから外部テーブルにデータをロードします。デフォルトでは、データベース取り込みとレプリケーション は、Databricks接続プロパティで指定されたクラスタでジョブを実行します。別のクラスタでジョブを実行する場合は、データベース取り込みとレプリケーション タスクウィザードの[ターゲット] ページでdbDeltaUseExistingCluster カスタムプロパティをFALSEに設定します。
• データベース取り込みとレプリケーション ジョブはクラスタが開始するまで待機します。デフォルトでは、ジョブは10分間待機します。クラスタが10分以内に開始されない場合、接続がタイムアウトし、ジョブのデプロイが失敗します。接続のタイムアウト値を増やす場合は、dbClusterStartWaitingTime カスタムプロパティを、クラスタが稼働するまで取り込みジョブが待機する必要がある最大時間(秒単位)に設定します。カスタムプロパティはデータベース取り込みとレプリケーション タスクウィザードの[ターゲット] ページで設定できます。
• データベース取り込みとレプリケーション は、DatabricksのCOPY INTO機能を使用して、ステージングファイルからDatabricksターゲットテーブルにデータをロードします。データベース取り込みとレプリケーション タスクウィザードの[ターゲット] ページでwriterDatabricksUseSqlLoad カスタムプロパティをFALSEに設定すると、すべてのロードタイプでこれを無効にできます。• [S3サービスリージョナルエンドポイント] の値を指定する必要があります。以下に例を示します。s3.us-east-2.amazonaws.com
LinuxでSecure Agentを使用してDatabricks接続をテストするには、Databricks接続プロパティの[SQLエンドポイントJDBC URL] フィールドでJDBC URLを指定する必要があります。接続をテストしたら、[SQLエンドポイントJDBC URL] の値を削除します。そうしないと、接続を使用するデータベース取り込みとレプリケーション タスクを定義するときに設計時エラーが発生します。これは、データ取り込みおよびレプリケーション が、JDBC URLの他に、必須の[Databricksホスト] 、[クラスタID] 、[組織ID] 、[Databricksトークン] の値を使用してターゲットに接続しようとし、ログインエラーを引き起こすためです。
• データベース取り込みとレプリケーション タスクを作成するとき、またはデータベース取り込みとレプリケーション ジョブを実行するときに、Windows上のSecure AgentでDatabricks接続を使用できます。• [スケジュールおよびランタイムオプション] ページで[カラム名の変更] オプションを[レプリケート] に設定した場合、タスクのデプロイ後、ジョブを実行する前に、生成されたターゲットテーブルを変更して、次のDatabricksテーブルプロパティを設定する必要があります。ALTER TABLE <target_table> SET TBLPROPERTIES (
これらのプロパティにより、必要なリーダーとライターのバージョンのDatabricksカラムマッピング機能が有効になります。これらのプロパティを設定しない場合、データベース取り込みとレプリケーション ジョブは失敗します。
• データベース取り込みとレプリケーション ジョブは、Databricks Unity Catalogからターゲットテーブルを生成するためのスキーマ情報を取得できます。Unity Catalog内の情報へのアクセスを有効にするには、Databricks接続プロパティの[カタログ名] フィールドにカタログ名を指定します。カタログ名は、データウェアハウスの[SQLウェアハウスJDBC URL] 値に追加されます。注: カタログの使用はSQLウェアハウスの場合はオプションであり、ジョブクラスタには適用されません。
Unity Catalogを使用する場合は、個人用ストレージの場所が自動的にプロビジョニングされます。個人用のステージング場所を使用するには、接続プロパティの[ステージング環境] フィールドで[個人用のステージング場所] を選択します。その後、取り込みおよびレプリケーションジョブのParquetデータファイルをローカルの個人用ストレージの場所にステージングできます。データ保持期間は7日間です。デフォルトでは、ステージング場所はAWSまたはAzureのルートの場所stage://tmp/<user_name> です。<user_name>は、[データベーストークン] 接続プロパティから取得されます。このユーザーには、個人用のステージング場所に対する読み取りおよび書き込みアクセス権が必要です。
• データベース取り込みとレプリケーション は、テーブルの特殊文字とソーステーブルのカラム名をサポートします。特殊文字は、Databricksターゲットテーブルまたはカラム名でアンダースコア(_)に置き換えられます。カスタムプロパティのキーと値のペアtargetReplacementValue=toHex は、データベース取り込みとレプリケーション によって、生成されたターゲットスキーマで特殊文字がアンダースコアに置換されないようにし、特殊文字を16進形式に変換します。
特殊文字を16進数値に変換するには、データベース取り込みとレプリケーション タスクをデプロイする前に、次のアクションを実行します。
1 targetReplacementValue=toHex のキーと値のペアをプロパティファイルに追加します。2 管理者 の[ランタイム環境] ページを開き、Secure Agentを編集します。[カスタム構成の詳細] 領域でカスタムプロパティを作成します。▪ [データベース取り込み] サービスを選択します。▪ [DBMI_AGENT_ENV] タイプを選択します。▪ ▪ 3 [ターゲット] ページで、targetReplacementValueカスタムプロパティをtoHexに設定します。タスクを実行する前に、<jobname>をプロパティファイルのtargetReplacementValueキーに追加します。
<jobname>.targetReplacementValue=toHex
プロパティがすべてのジョブに影響する場合は、「alljobs」をtargetReplacementValueキーに追加します。
alljobs.targetReplacementValue=toHex
• • Google BigQueryターゲット 次のリストは、Google BigQueryターゲットを準備および使用する際の考慮事項を示しています。
ターゲットの準備 • 1 Google Cloud 2 <Secure_Agent_installation_directory >/apps/Database_Ingestion/ext/
注: そのディレクトリに他のGoogle BigQueryドライバ.jarファイルが存在する場合は、それらを削除します。これらは現在、データベース取り込みとレプリケーション にバンドルされています。
3 • • [サービスアカウントID] 、[プロジェクトID] 、[サービスアカウントキー] 、および[リージョンID] 接続プロパティに値を入力します。 • [オプションのプロパティを指定] フィールドでタイムアウト間隔プロパティを指定します。次の形式を使用します。"timeout": "<timeout_interval_in_seconds >"
• - - データベース取り込みとレプリケーション がステージングファイルを作成するGoogle Cloud Storageパス• - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - ターゲットの用途 • データベース取り込みとレプリケーション は、ソースデータをバルクモードでGoogle BigQueryターゲットにロードします。• データベース取り込みとレプリケーション の増分ロードタスクの場合、すべてのソースカラムに対してソースデータベース変更データキャプチャ(CDC)が有効になっていることを確認します。• データベース取り込みとレプリケーション は、テーブルの特殊文字とソーステーブルのカラム名をサポートします。Google BigQueryターゲットテーブルまたはカラム名の特殊文字は、アンダースコア(_)に置き換えられます。カスタムプロパティのキーと値のペアtargetReplacementValue=toHex は、データベース取り込みとレプリケーション によって、生成されたターゲットスキーマで特殊文字がアンダースコアに置換されないようにし、特殊文字を16進形式に変換します。
特殊文字を16進数値に変換するには、データベース取り込みとレプリケーション タスクをデプロイする前に、次のアクションを実行します。
1 targetReplacementValue=toHex のキーと値のペアをプロパティファイルに追加します。2 管理者 の[ランタイム環境] ページを開き、Secure Agentを編集します。[カスタム構成の詳細] 領域でカスタムプロパティを作成します。▪ [データベース取り込み] サービスを選択します。▪ [DBMI_AGENT_ENV] タイプを選択します。▪ ▪ 3 [ターゲット] ページで、targetReplacementValueカスタムプロパティをtoHexに設定します。タスクを実行する前に、<jobname>をプロパティファイルの「targetReplacementValue」キーに追加します。
<jobname>.targetReplacementValue=toHex
プロパティがすべてのジョブに影響する場合は、「alljobs」を「targetReplacementValue」キーに追加します。
alljobs.targetReplacementValue=toHex
• データベース取り込みとレプリケーション タスクで[監査] 適用モードを選択した場合は、タスクウィザードの[ターゲット] ページの[詳細] で、ターゲットテーブルに含める監査メタデータカラムを選択できます。[メタデータカラムのプレフィックス] フィールドに値を指定する場合は、特殊文字を含めないようにしてください。特殊文字を含めた場合、タスクのデプロイメントが失敗します。• - - • データベース取り込みとレプリケーション ジョブをデプロイすると、データベース取り込みとレプリケーション はデフォルトでは、プライマリキーカラムまたは一意のキーカラムでクラスタ化されたGoogle BigQueryターゲットテーブルを生成します。各キーカラムには、Google BigQueryがクラスタリングでサポートする次のいずれかのデータ型が必要です。- - - - - - - - - プライマリキーまたはユニークキーのカラムにサポートされていないデータ型がある場合、クラスタリング時にそのカラムはスキップされます。例えば、プライマリキーにC1、C2、C3、C4、C5カラムが含まれていて、C2にサポートされていないデータ型がある場合、ターゲットテーブルはCLUSTER BY句にC1、C3、C4、およびC5カラムを使用して作成されます。
KafkaターゲットとKafka対応Azure Event Hubsターゲット 次のリストは、Kafkaターゲットを使用する際の考慮事項を示しています。
• データベース取り込みとレプリケーション は、増分ロードジョブのターゲットとして、Apache Kafka、Confluent Kafka、Amazon Managed Streaming for Apache Kafka(MSK)、およびKafka対応Azure Event Hubsをサポートします。これらすべてのKafkaターゲットタイプは、Kafka接続タイプを使用します。Kafkaターゲットタイプを指定するには、タスク定義またはKafka接続プロパティでKafkaプロデューサプロパティを指定する必要があります。タスクのこれらのプロパティを指定するには、タスクウィザードの[ターゲット] ページの[プロデューサ設定プロパティ] フィールドに、key :value ペアのカンマ区切りのリストを入力します。Kafka接続を使用するすべてのタスクのプロデューサプロパティを指定するには、プロパティのリストを接続プロパティの[追加接続プロパティ] フィールドに入力します。タスクレベルでプロデューサプロパティを定義することにより、特定のタスクの接続レベルのプロパティをオーバーライドできます。プロデューサプロパティの詳細については、Apache Kafka、Confluent Kafka、Amazon MSK、またはKafka用Azure Event Hubsのドキュメントを参照してください。
• [AVRO] をKafkaターゲットの出力形式として選択した場合、データベース取り込みとレプリケーション は次の形式の名前で、各テーブルのスキーマ定義ファイルを生成します。schemaname _tablename .txt
ソーススキーマの変更により、増分ロードジョブのターゲットが変更されることが予想される場合は、データベース取り込みとレプリケーション がタイムスタンプを含む一意の名前でAvroスキーマ定義ファイルを再生成します。
schemaname _tablename _YYYYMMDDhhmmss .txt
この一意の命名パターンにより、古いスキーマ定義ファイルが監査目的で保持されます。
• [ターゲット] ページで次の設定を行う必要があります。- [出力形式] フィールドで、[AVRO] を選択します。- [Avroシリアル化形式] フィールドで、[なし] を選択します。• [ターゲット] ページの[プロデューサ設定プロパティ] フィールド、またはKafka接続プロパティの[追加接続プロパティ] フィールドいずれかで指定できます。ビジネスニーズに合うように、Kafkaベンダーによってサポートされているproperty=valueのペアを入力します。例えば、Confluent Kafkaを使用する場合は、[プロデューサ設定プロパティ] フィールドまたは[追加接続プロパティ] フィールドで次のエントリを使用してスキーマレジストリのURLを指定し、基本認証を有効にすることができます。
schema.registry.url=http://schema-registry:8081,
Amazon MSKを使用する場合は、次の[追加接続プロパティ] エントリを使用して、Amazon MSKターゲットにアクセスするためのIAMロール認証を有効にすることができます。
security.protocol=SASL_SSL,sasl.mechanism=AWS_MSK_IAM,sasl.jaas.config=software.amazon.msk.auth.iam.IAMLoginModule required;,sasl.client.callback.handler.class=software.amazon.msk.auth.iam.IAMClientCallbackHandler
必ずSecure AgentがインストールされているAmazon EC2インスタンスでIAMロール認証を有効にしてください。
Kafkaプロパティの詳細については、Kafkaベンダーのドキュメントを参照してください。
• データベース取り込みとレプリケーション の増分ロードジョブで、Confluent Kafka、Amazon MSK、およびAzure Event Hubsターゲットを含め、SASL_SSLで保護されたアクセスをサポートするKafkaターゲットに変更データをレプリケートできます。Administratorで、[追加接続プロパティ] フィールドの適切なプロパティをはじめとするKafka接続を設定する必要があります。例えば、Azure Event Hubsの場合、次の[追加接続プロパティ] エントリを使用して、SASL_SSLを有効にすることができます。bootstrap.servers=NAMESPACENAME.servicebus.windows.net:9093
Kafkaターゲットのカスタムメッセージキーの生成 Avro形式を使用するすべてのKafkaターゲットタイプに対し、ソーステーブルごとに1つ以上のカラムで構成されるカスタムメッセージキーを生成するルールを設定できます。ルールの設定後、Kafkaターゲットを持つデータベース取り込みとレプリケーション の増分ロードジョブは、ターゲットメッセージングシステムに送信するメッセージのヘッダーに、生成されたメッセージキーをを含めることができます。ターゲットメッセージングシステムはメッセージキーを使用して、特定のキー値を持つメッセージをマルチパーティショントピック内の同じパーティションに書き込むことができます。
この機能を実装するには、各ソーステーブルのキーカラムを識別するルールを含んだ構成ファイルを手動で作成する必要があります。次に、タスクウィザードのカスタム設定プロパティにファイルを指定します。
構成ファイルの作成 テキストエディタでルール構成ファイルを作成し、Secure Agentシステム上の場所に保存します。このファイルには、各ソーステーブルのルールが含まれています。各ルールは、トピックパーティションへのデータの書き込みに使用するカスタムキーカラムを定義します。
注: データベース取り込みとレプリケーション タスクがデプロイされた後にルールを変更または追加するか、他のパラメータのいずれかを変更した場合、ルールの変更を有効にするには、タスクを再デプロイする必要があります。
ルールの構文:
次の構文を使用して構成ファイルにルールを定義します。
rule=(schema .tablename ,column1 ,column2 ,column3 ,… )additional rules... character ]
ファイルにコメントを含めるには、各コメント行を番号(#)記号で始めます。例:
#This text is for informational purposes only.
パラメータ :
• rule 。ソーステーブルの複合メッセージキーを生成するためのルールを定義します。各ルールでは、最初にソーステーブルのスキーマとテーブル名を特定します。スキーマを変更するか、ターゲットのテーブルの名前変更ルールを定義する場合は、ターゲットのスキーマまたは名前が変更されたテーブルの名前を使用します。次に、メッセージキーを構成する1つ以上のテーブルカラムの名前を指定します。テーブルにカラムが定義されていることを確認します。カラムが定義されていないと、データベース取り込みジョブが失敗します。SQL Serverソースの場合は、データベースの名前もdatabase の形式で含めます。schema 。tablename 。同じルール構成ファイルに複数のルールを定義できます。
メッセージキーの生成時、データ取り込みおよびレプリケーション は、各カラム値の文字表現とそれに続く区切り文字を使用します。各カラムの値と区切り文字は、ルール定義にカラムが表示される順序で複合キー値に追加されます。その後、複合キーはレコードのKafkaメッセージキーとして使用されます。メッセージキーに空の値またはnull値があるカラムの位置は、区切り文字のみで表されます。
• delimiter 。オプション 。生成されたメッセージキーの各キーカラムの値の後に区切り文字として使用される単一の文字を指定します。このパラメータは、ルール構成ファイルに1回だけ指定できます。デフォルトはセミコロン(;)です。
• tableNotFound 。オプション 。このパラメータをABORTに設定すると、データベース取り込みとレプリケーション ジョブはソーステーブルのデータの処理を停止し、ルール構成ファイルにテーブルのルール定義がないと失敗します。各ソーステーブルには、複合メッセージキーを適切に生成させるためのルール定義が必要です。このパラメータは構成ファイルに1回だけ指定できます。このパラメータを指定せず、ルール構成ファイルにテーブルが見つからない場合は、ターゲットメッセージングシステムパラメータのデフォルトのルールによって、レコードに使用するキーが決定されます。
• trace 。オプション 。ルール定義に基づくメッセージキー生成のトレースを有効または無効にします。有効な値は以下のとおりです。- true 。ルール定義に基づくメッセージキー生成のトレースを有効にします。- false 。ルール定義に基づくメッセージキー生成のトレースを無効にします。このパラメータは、ルール構成ファイルに1回だけ指定できます。
デフォルトはfalse です。
サンプルルール:
rule=(testdb.ABC.DEPT,DEPTNO,DNAME)
このルールに基づいて生成されたキー出力の例:
1234;HR;
データベース取り込みおよびレプリケーションタスク設定 Kafkaターゲットを持つデータベース取り込みとレプリケーション の増分ロードタスクを作成する場合、次のオプションを設定して、カスタムメッセージキーの生成を有効にする必要があります。
• [ターゲット] ページで、[テーブル名をトピック名として使用] チェックボックスがオフになっていることを確認します。次に、トピック名を[トピック名] フィールドに入力します。• [出力形式] フィールドで、[Avro] を選択します。[Avro形式] フィールドで任意のAvro形式を選択できます。• [カスタムプロパティ] でcaptureColumnValuesFile プロパティに、Secure Agentシステム上で作成したルール構成ファイルを指すパス値を指定します。Microsoft Azure Synapse Analyticsターゲット 次のリストは、Microsoft Azure Synapse Analyticsターゲットを準備および使用する際の考慮事項を示しています。
• データベース取り込みとレプリケーション タスクをデプロイして実行するには、ターゲット接続でターゲットデータベースに対するCONTROL権限を持つデータベースユーザーを指定する必要があります。ユーザーにCONTROL権限を付与するには、次のSQL文を使用します。USE database_name ; user_name ;
この権限は、初期ロード、増分ロード、および初期ロードと増分ロードの組み合わせジョブに必要です。この権限により、データベース取り込みとレプリケーション は、ターゲットテーブルと、外部データソース、外部ファイル形式、データベーススコープの資格情報オブジェクト(データベースに存在しない場合)などのデータベースオブジェクトを作成できます。この権限は、外部データソースおよびデータベーススコープの資格情報オブジェクトを作成するために特に必要です。
注: マスターキーを手動で作成する必要があります。マスターキーを作成するには、データベースに対するCONTROL権限が必要です。
• データベース取り込みとレプリケーション ジョブは、データをMicrosoft Azure Synapse Analyticsターゲットテーブルに書き込む前に、まずMicrosoft Azure Data Lake Storage Gen2ステージングファイルにデータを送信します。ステージングファイルは、フィールド区切り文字として16進数のx1d区切り文字を使用します。データがターゲットに書き込まれた後、ステージングファイルを含むテーブル固有のディレクトリのコンテンツ全体が削除されます。• [階層型名前空間] オプションを有効にする必要があります。この設定では、blobストレージを使用することは推奨されません。• データベース取り込みとレプリケーション ジョブがMicrosoft Azure Synapse Analyticsターゲットにプロパゲートできるソーステーブルのカラム数は、508カラムを超えてはなりません。 • データベース取り込みとレプリケーション の増分ロードジョブ、および初期ロードと増分ロードの組み合わせジョブにより、ターゲット上にINFORMATICA_CDC_RECOVERYという名前のリカバリテーブルが生成され、障害後に再開されたジョブが以前に処理されたデータを再度プロパゲートするのを防ぐ内部サービス情報が格納されます。このリカバリテーブルは、ターゲットテーブルと同じスキーマで生成されます。• データベース取り込みとレプリケーション ジョブが外部テーブルを使用してMicrosoft Azure Synapse Analyticsターゲットにデータを読み込むと、ジョブの再開時にこれらのテーブルが再作成される場合でも、ジョブはターゲット上に作成されたログテーブルと外部テーブルを削除しません。Microsoft SQL ServerおよびAzure SQLデータベースのターゲット Microsoft SQL ServerまたはMicrosoft Azure SQL Databaseターゲットは、初期ロード、増分ロード、および初期ロードと増分ロードの組み合わせジョブで使用できます。SQL Serverターゲットには、オンプレミス、RDS、およびAzure SQL Managed Instanceターゲットが含まれます。
次のリストは、Microsoft SQL Serverターゲットを準備および使用する際の考慮事項を示しています。
• データベース取り込みとレプリケーション では、Microsoft SQL ServerはTeradataソースからデータをレプリケートするジョブのターゲットとしてサポートされていません。• データベース取り込みとレプリケーション とともに提供されます。個別にインストールする必要はありません。• データベース取り込みとレプリケーション ユーザーには、ターゲットテーブルの作成とテーブルへのデータの書き込みを行うため、少なくとも次のデータベースロールが必要です。- - - • - [SQL Server 2017] または[SQL Server 2019] を選択します。- [SQL Server認証] または[Windows認証v2] を選択します。- - - - - - - 必要に応じて、ターゲット接続にSSL暗号化を使用するには、[暗号化方式]プロパティを[SSL]、[要求SSL]、または[ログインSSL]のいずれかのオプションに設定します。暗号化を有効にする場合は、次のプロパティも設定します。
- - [True] を選択します。- - - 他の接続プロパティはサポートされていません。
• データベース取り込みとレプリケーション の増分ロードジョブ、および初期ロードと増分ロードの組み合わせジョブは、ターゲットテーブルスキーマに基づいて、いくつかの追加のメタデータカラムとともにLOGテーブルを生成します。LOGテーブルは、変更データがターゲットにフラッシュされる直前に作成されます。受信DMLデータは、ローカルCSVファイルをSQL ServerドライバのBulk Copy APIに提供することにでLOGテーブルに挿入されます。LOGテーブルの情報に基づいてmerge apply文が生成され、DML操作が実際のターゲットテーブルに適用されます。DMLの変更が適用されると、LOGテーブルは削除されます。複数のジョブ、または複数のテーブルを含むジョブを実行している場合、LOGテーブルによって、顧客データベースインスタンスの追加スペースまたはサイズ要件が一時的に急増する可能性があります。LOGテーブルに必要なスペースとサイズは、フラッシュサイクルの一部として受信される行数によって異なります。
• データベース取り込みとレプリケーション の増分ロードジョブ、または初期ロードと増分ロードの組み合わせジョブがSQL Serverターゲットにプロパゲートできるソーステーブル内のカラム数は、508カラムを超えることはできません。ソーステーブルに508を超えるカラムが含まれている場合、ジョブはLOGテーブルの作成中に失敗します。• データベース取り込みとレプリケーション の増分ロードジョブ、および初期ロードと増分ロードの組み合わせジョブにより、ターゲット上にINFORMATICA_CDC_RECOVERYという名前のリカバリテーブルが生成され、障害後に再開されたジョブが以前に処理されたデータを再度プロパゲートするのを防ぐ内部サービス情報が格納されます。このリカバリテーブルは、ターゲットテーブルと同じスキーマで生成されます。Oracleターゲット 次のリストは、Oracleターゲットを準備および使用する際の考慮事項を示しています。
ターゲットの準備 • データベース取り込みとレプリケーション では、データをOracleターゲットデータベースにロードするために、ユーザーに特定の権限が必要です。オンプレミスOracleターゲットの場合、Oracleターゲットに接続するデータベース取り込みとレプリケーション ユーザー(cmid_user )に、次のユーザー特権を付与します。GRANT CREATE SESSION TO cmid_user ;cmid_user ;cmid_user ;cmid_user ;cmid_user ;cmid_user ;cmid_user ;cmid_user ;cmid_user ;schema.table > TO cmid_user ; <--Unless you grant on ANY TABLEcmid_user ;cmid_user ;cmid_user ;cmid_user ;cmid_user ; <-- If cmid_user is the owner of the target schemacmid_user >;cmid_user ;cmid_user ;cmid_user ;cmid_user ;cmid_user ;cmid_user ;cmid_user ;cmid_user ;cmid_user ;cmid_user ;cmid_user ;cmid_user ;cmid_user ;cmid_user ;cmid_user ;cmid_user ;cmid_user ;cmid_user ;cmid_user ;cmid_user ;
• データベース取り込みとレプリケーション ユーザー(cmid_user )に次のユーザー特権を付与します。GRANT CREATE SESSION TO cmid_user ;cmid_user ;cmid_user ;cmid_user ;cmid_user ;cmid_user ;schema.table > TO cmid_user ;cmid_user ;cmid_user ;cmid_user ;cmid_user ;
また、次のAmazon RDSプロシージャを実行して、追加のSELECT権限をcmid_user に付与します。
begincmid_user ',cmid_user ',cmid_user ',cmid_user ',cmid_user ',cmid_user ',cmid_user ',cmid_user ',cmid_user ',cmid_user ',cmid_user ',
使用に関する考慮事項: PostgreSQLターゲット Amazon Aurora PostgreSQLおよびRDS for PostgreSQLは、Db2 for i、Oracle、PostgreSQL、またはSQL Serverソースを持つ初期ロードジョブ、増分ロードジョブ、および初期ロードと増分ロードの組み合わせジョブでターゲットとして使用できます。
次のリストは、PostgreSQLターゲットを準備および使用する際の考慮事項を示しています。
• データベース取り込みとレプリケーション タスクをデプロイして実行するには、ターゲット接続で必要な特権を持つデータベースユーザーを指定する必要があります。ユーザーには、接続で指定されたデータベースに対するCONNECT特権とTEMPORARY特権、およびターゲットプロパティで指定されたターゲットスキーマに対するUSAGE特権とCREATE特権が必要です。
次のSQL文を使用して、これらの特権をユーザーロールに付与し、そのロールをユーザーに割り当てます。
CREATE ROLE dbmi_role ; database TO dbmi_role ; database TO dbmi_role ; schema TO dbmi_role ; schema TO dbmi_role ; dbmi_user with PASSWORD 'password '; dbmi_role to dbmi_user ;
注: ジョブの実行時に生成されるターゲットテーブルに対する特権は、ジョブを実行するユーザーに付与されます。
• データベース取り込みとレプリケーション の増分ロードジョブでは、ターゲットテーブルスキーマに基づいてLOGテーブルが生成され、いくつかのメタデータカラムが追加されます。LOGテーブルは、変更データがターゲットにフラッシュされる直前に作成されます。受信DMLデータは、ローカルCSVファイルをPostgreSQLドライバのBulk Copy APIに提供することにでLOGテーブルに挿入されます。LOGテーブルの情報に基づいて一連のmerge apply文が生成され、DML操作が実際のターゲットテーブルに適用されます。DMLの変更が適用されると、LOGテーブルは削除されます。複数のジョブ、または複数のテーブルを含むジョブを実行している場合、LOGテーブルによって、顧客データベースインスタンスの追加スペースまたはサイズ要件が一時的に急増する可能性があります。LOGテーブルに必要なスペースとサイズは、フラッシュサイクルの一部として受信される行数によって異なります。
• データベース取り込みとレプリケーション の増分ロードジョブがPostgreSQLターゲットにプロパゲートできるソーステーブル内のカラム数は、796カラムを超えることはできません。ソーステーブルに796を超えるカラムが含まれている場合、ジョブはLOGテーブルの作成中に失敗します。• データベース取り込みとレプリケーション タスクのデプロイは、検証中に失敗します。• - - データベース取り込みとレプリケーション は、PostgreSQLターゲットのinterval_typeカラムをサポートしていません。PostgreSQLソースを持つタスクの場合、任意のinterval_typeのINTERVALカラムはINTERVAL NULLとしてPostgreSQLターゲットにレプリケートされます。
• データベース取り込みとレプリケーション の増分ロードジョブにより、ターゲット上にINFORMATICA_CDC_RECOVERYという名前のリカバリテーブルが生成され、障害後に再開されたジョブが以前に処理されたデータを再度プロパゲートするのを防ぐ内部サービス情報が格納されます。このリカバリテーブルは、ターゲットテーブルと同じスキーマで生成されます。Snowflakeターゲット ターゲットの準備 ターゲットの準備は、Snowflakeターゲットテーブルへのデータの高パフォーマンスストリーミングにSuperpipe機能を使用するか、中間ステージファイルにデータを書き込むかによって異なります。
Superpipeを使用
Superpipe機能を使用する場合は、次の手順を実行します。
1 データ取り込みおよびレプリケーション ユーザーを作成します。次のSQL文を使用します。create user INFACMI_User password 'Xxxx@xxx';
2 データ取り込みおよびレプリケーション ユーザーに付与します。以下のSQL文を使用します。create role INFACMI_superpipe;
3 grant usage on warehouse warehouse_name to role INFACMI_superpipe;
4 grant usage on database INFACMI_DB1 to role INFACMI_superpipe;
5 use database INFACMI_DB1;
6 grant create stream, create view, create table, usage on schema INFACMI_DB1.sh_superpipe to role INFACMI_superpipe;
7 alter user INFACMI_User set default_role=INFACMI_superpipe;
8 [KeyPair] オプションを使用する必要があります。「コネクタと接続」>「Snowflake Data Cloud接続プロパティ」を参照してください。9 openssl genrsa 2048 | openssl pkcs8 -topk8 -inform PEM -v1 PBE-SHA1-3DES -out rsa_key.p8
10 openssl rsa -in rsa_key.p8 -pubout -out rsa_key.pub
11 alter user INFACMI_User set rsa_public_key='key_value’;
次の手順 : 取り込みおよびレプリケーションタスクを作成するときに、タスクウィザードの[ターゲット] ページで[Superpipe] オプションを選択します。必要に応じて、変更データ行がマージされてSnowflakeターゲットテーブルに適用される頻度を制御する[マージ頻度] 値を指定することもできます。
Superpipeを使用しない
SnowflakeターゲットにSuperpipe機能を使用しない場合は、ACCOUNTADMINユーザーとして次の手順を実行します。
1 データ取り込みおよびレプリケーション ユーザーを作成します。次のSQL文のいずれかを使用します。create user INFACMI_User password 'Xxxx@xxx';
または
replace user INFACMI_User password 'Xxxx@xxx';
2 データ取り込みおよびレプリケーション ユーザーに付与します。以下のSQL文を使用します。create role INFA_CMI_Role;
3 grant usage on warehouse CMIWH to role INFA_CMI_Role;
4 grant usage, CREATE SCHEMA on database CMIDB to role INFA_CMI_Role;
5 alter user INFACMI_User set default_role=INFA_CMI_Role;
また、INFACMI_Userとして新しいスキーマを作成します。
create schema CMISchema;
注: ユーザーのデフォルトロールが取り込みおよびレプリケーションタスクに使用され、必要な権限がない場合、実行時に次のエラーが発行されます。
SQL compilation error: Object does not exist, or operation cannot be performed.
使用に関する考慮事項: • データベース取り込みとレプリケーション は、Snowflake Data Cloudターゲットにデータを移動する代替方法を提供しています。- [Superpipe] オプションを選択した場合、取り込みジョブはSnowpipe Streaming APIを使用して、短い待ち時間でデータ行をターゲットテーブルに直接ストリーミングします。この方法は、すべてのロードタイプで使用できます。[KeyPair] 認証を使用する必要があります。- • データベース取り込みとレプリケーション は、次のSQLコマンドを実行してステージを自動的に作成します。Create stage if not exists "Schema"."Stage_Bucket"”
コマンドを正常に実行するには、次の特権をユーザーロールに付与する必要があります。
GRANT CREATE STAGE ON SCHEMA "Schema" TO ROLE <your_role >;
• [JDBC URLの追加パラメータ] フィールドにdatabase= target_database_name と設定する必要があります。それ以外の場合は、データベース取り込みとレプリケーション タスクウィザードでターゲットを定義しようとすると、スキーマのリストを取得できないことを示すエラーメッセージが表示されます。• [KeyPair] オプションを認証方法として使用してSnowflakeターゲットの接続を定義し、OpenSSL 3.x.xバージョンでプライベートキーを生成する場合は、プライベートキーの生成時にPBE-SHA1-2DES またはPBE-SHA1-3DES の暗号を使用します。以下のコマンドのいずれかを実行します。openssl genrsa 2048 | openssl pkcs8 -topk8 -inform PEM -v1 PBE-SHA1-3DES -out rsa_key.p8
または
openssl genrsa 2048 | openssl pkcs8 -topk8 -inform PEM -v1 PBE-SHA1-2DES -out rsa_key.p8
PBE-SHA1-2DES またはPBE-SHA1-3DES の暗号なしで汎用コマンドを使用すると、データベース取り込みとレプリケーション タスクウィザードのターゲット定義ステップでターゲットスキーマを取得するときに、プライベートキーが無効またはサポートされていないことを示すエラーメッセージが表示される場合があります。
OpenSSL 1.1.1を使用してプライベートキーを生成すると、エラーメッセージは表示されません。
• データベース取り込みとレプリケーション の増分ロードジョブ、および初期ロードと増分ロードの組み合わせジョブにより、ターゲット上にINFORMATICA_CDC_RECOVERYという名前のリカバリテーブルが生成され、障害後に再開されたジョブが以前に処理されたデータを再度プロパゲートするのを防ぐ内部サービス情報が格納されます。このリカバリテーブルは、ターゲットテーブルと同じスキーマで生成されます。• • 生成されたターゲットスキーマの特殊文字を指定した文字列に置き換えるには、データベース取り込みとレプリケーション タスクをデプロイする前に、次の操作を実行します。
1 targetReplacementValue=<string> のキーと値のペアをプロパティファイルに追加します。2 管理者 の[ランタイム環境] ページを開き、Secure Agentを編集します。[カスタム構成の詳細] 領域でカスタムプロパティを作成します。▪ [データベース取り込み] サービスを選択します。▪ [DBMI_AGENT_ENV] タイプを選択します。▪ ▪ 3 [ターゲット] ページで、targetReplacementValue=<string>カスタムプロパティを設定します。タスクを実行する前に、<jobname>をプロパティファイルのtargetReplacementValueキーに追加します。
<jobname>.targetReplacementValue=<string>
プロパティがすべてのジョブに影響する場合は、「alljobs」をtargetReplacementValueキーに追加します。
alljobs.targetReplacementValue=<string>
Snowflakeへのプライベート接続の設定 AWSまたはAzureプライベートリンクエンドポイントを使用してSnowflakeにアクセスできます。
AWSまたはAzureプライベートリンクの設定によって、Snowflakeへの接続がAWSまたはAzure内部ネットワークを使用して確立され、パブリックインターネットを介して行われないようにします。
プライベートAWSネットワーク経由でSnowflakeアカウントに接続するには、
AWS Private Link and Snowflake を参照してください。
プライベートAzureネットワーク経由でSnowflakeアカウントに接続するには、
Azure Private Link and Snowflake を参照してください。
Amazon S3、Google Cloud Storage、Microsoft Azure Data Lake Storage Gen2、およびMicrosoft Fabric OneLakeターゲット上のCDCファイルのデフォルトのディレクトリ構造 データベース取り込みとレプリケーション ジョブは、Amazon S3、Google Cloud Storage、Microsoft Azure Data Lake Storage Gen2、およびMicrosoft Fabric OneLakeターゲットにディレクトリを作成して、変更データ処理に関する情報を格納します。
次のディレクトリ構造がデフォルトでターゲットに作成されます。
Bucketconnection_folder job_folder completed_cycle_folder timestamp .csvcompleted_cycle_folder timestamp .csvcycle_folder timestamp .csvcycle_folder timestamp .csvtable_name cycle_folder table_name _timestamp .csvcycle_folder table_name _timestamp .csvtable_name .schema
次の表に、デフォルト構造に含まれるディレクトリを示します。
フォルダ
説明
connection_folder
データベース取り込みとレプリケーション オブジェクトが含まれています。このフォルダは、Amazon S3接続プロパティの[フォルダパス] フィールド、Microsoft Azure Data Lake Storage Gen2接続プロパティの[ディレクトリパス] フィールド、またはMicrosoft Fabric OneLake接続プロパティの[レイクハウスパス] フィールドで指定されています。
注: このフォルダは、Google Cloud Storageターゲット用には作成されていません。
job_folder
ジョブ出力ファイルが含まれています。このフォルダは、データベース取り込みとレプリケーション タスクウィザードの[ターゲット] ページの[ディレクトリ] フィールドで指定されています。
cycle/completed
各完了CDCサイクルのサブフォルダが含まれています。各完了サイクルサブフォルダには、完了サイクルファイルが含まれています。
cycle/contents
各CDCサイクルのサブフォルダが含まれます。各サイクルサブフォルダには、サイクルコンテンツファイルが含まれています。
data
各テーブルの出力データファイルとスキーマファイルが含まれています。
data/table_name /schema/V1
スキーマファイルが含まれています。
注: 出力ファイルがParquet形式を使用している場合、データベース取り込みとレプリケーション はスキーマファイルをこのフォルダに保存しません。
data/table_name /data
出力データファイルを生成する各CDCサイクルのサブフォルダが含まれています。
サイクルディレクトリ データベース取り込みとレプリケーション は、次のパターンを使用してサイクルディレクトリに名前を付けます。
[dt=]yyyy -mm -dd -hh -mm -ss
データベース取り込みとレプリケーション タスクウィザードの[ターゲット] ページの[ディレクトリタグの追加] チェックボックスを選択すると、サイクルフォルダ名に「dt=」プレフィックスが追加されます。
サイクルコンテンツファイル サイクルコンテンツファイルはcycle/contents/cycle_folder サブディレクトリにあります。サイクルコンテンツファイルには、サイクル中にDMLイベントが発生した各テーブルのレコードが含まれています。サイクル内のテーブルでDML操作が発生しなかった場合、そのテーブルはサイクルコンテンツファイルに表示されません。
データベース取り込みとレプリケーション は、次のパターンを使用してサイクルコンテンツファイルに名前を付けます。
Cycle-contents-timestamp .csv
サイクルコンテンツのcsvファイルには、次の情報が含まれています。
• • • • • • • • • 複合ロードジョブのみ : 切り捨て操作の数• 複合ロードジョブのみ : 初期ロードフェーズ中に発生した挿入操作の数• 複合ロードジョブのみ : 初期ロードフェーズ中に発生した削除操作の数• • 注: 出力データファイルがParquet形式を使用している場合、データベース取り込みとレプリケーション は、サイクルコンテンツファイルで指定されたパスにスキーマファイルを保存しません。代わりに、データベース取り込みとレプリケーション タスクウィザードの[ターゲット] ページの[Avroスキーマディレクトリ] フィールドで指定されているフォルダ内のスキーマファイルを使用できます。
完了サイクルファイル 完了サイクルファイルはcycle/completed/completed_cycle_folder サブディレクトリにあります。データベース取り込みとレプリケーション ジョブは、サイクルが完了した後、このサブディレクトリにサイクルファイルを作成します。このファイルが存在しない場合、サイクルはまだ完了していません。
データベース取り込みとレプリケーション は、次のパターンを使用して完了サイクルファイルに名前を付けます。
Cycle-timestamp .csv
完了サイクルのcsvファイルには、次の情報が含まれています。
• • • • • • 有効な理由の値は、以下のとおりです。
- - - 複合初期ロードジョブのみ : BACKLOG_COMPLETED。CDCバックログ処理が完了したため、サイクルが終了しました。CDCバックログは、ジョブの組み合わせの初期ロードフェーズ中にキャプチャされたイベントで構成されます。バックログには、初期ロードフェーズの開始時または終了時、および初期ロードフェーズからメインのCDC増分処理への移行中にキャプチャされた可能性のあるDML変更が含まれます。- 複合ロードジョブのみ: INITIAL_LOAD_COMPLETED。初期ロードが完了したため、サイクルが終了しました。- 複合ロードジョブのみ: RESYNC_STARTED。テーブルの再同期が開始されたため、サイクルが終了しました。出力データファイル データファイルには、次の情報を含むレコードが含まれています。
Amazon S3、Google Cloud Storage、フラットファイル、Microsoft Fabric OneLake、およびADLS Gen2ターゲット上の出力ファイルのカスタムディレクトリ構造 デフォルトの構造を使用しない場合は、初期ロードジョブ、増分ロードジョブ、または初期ロードと増分ロードの組み合わせジョブがAmazon S3、Google Cloud Storage、フラットファイル、またはMicrosoft Azure Data Lake Storage(ADLS)Gen2、またはMicrosoft Fabric OneLakeターゲットに書き込む出力ファイルのカスタムディレクトリ構造を設定できます。
初期ロード デフォルトでは、初期ロードジョブは出力ファイルを親ディレクトリの下のtablename _timestamp サブディレクトリに書き込みます。Amazon S3、フラットファイル、およびADLS Gen2ターゲットについては、タスクウィザードの[ターゲット] ページで[親としての接続ディレクトリ] チェックボックスが選択されている場合、親ディレクトリはターゲット接続プロパティで指定されます。
• [フォルダパス] フィールドで指定されます。• [ディレクトリ] フィールドで指定されます。• [ディレクトリパス] フィールドで指定されます。Google Cloud Storageターゲットでは、親ディレクトリは、タスクウィザードの[ターゲット] ページにある[バケット] フィールドで指定されたバケットコンテナです。
Microsoft Fabric OneLakeターゲットの場合、親ディレクトリは、Microsoft Fabric OneLake接続プロパティの[レイクハウスのパス] フィールドで指定されたパスです。
ニーズに合うようにディレクトリ構造をカスタマイズできます。例えば、初期ロードの場合、環境に合わせてファイルを整理したり、ファイルを見つけやすくしたりするために、ルートディレクトリや、接続プロパティで指定された親ディレクトリとは異なるディレクトリパスに出力ファイルを書き込むことができます。または、すべてのファイルの自動処理を容易にするために、タイムスタンプ付きのサブディレクトリにファイルを別々に書き込むのではなく、テーブルのすべての出力ファイルをテーブル名の付いたディレクトリに直接統合できます。
ディレクトリ構造を設定するには、取り込みタスクウィザードの[ターゲット] ページにある[データディレクトリ] フィールドを使用する必要があります。デフォルト値は{TableName}_{Timestamp} です。これにより、出力ファイルが親ディレクトリの下のtablename _timestamp サブディレクトリに書き込まれます。大文字と小文字を区別しないプレースホルダとディレクトリ名の任意の組み合わせで構成されるディレクトリパターンを作成することにより、カスタムディレクトリパスを設定できます。プレースホルダは次のとおりです。
• • • • • • • パターンには、次の関数を含めることもできます。
• • デフォルトでは、ターゲットスキーマもデータディレクトリに書き込まれます。スキーマに別のディレクトリを使用する場合は、[スキーマディレクトリ] フィールドでディレクトリパターンを定義できます。
例1 :
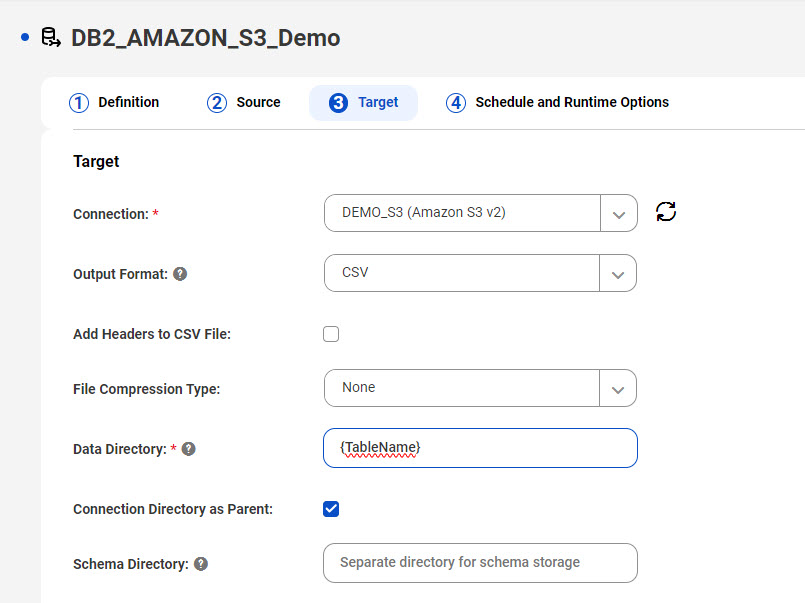
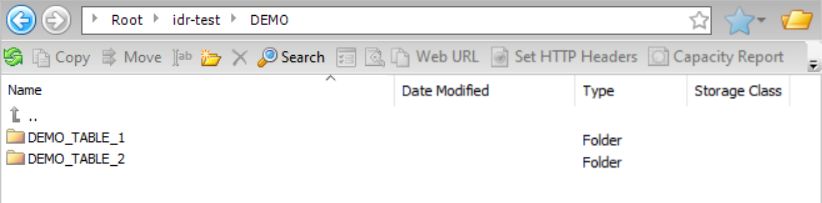
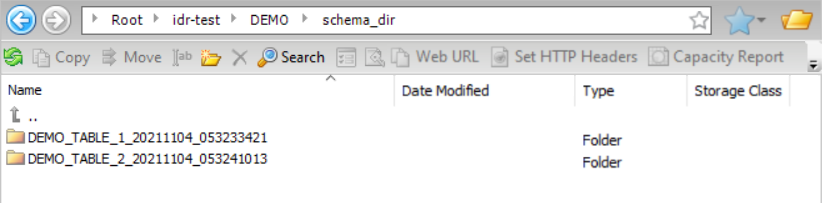
Amazon S3ターゲットを使用していて、出力ファイルとターゲットスキーマを、接続プロパティの[フォルダパス] フィールドで指定された親ディレクトリの下にある同じディレクトリに書き込みたいとします。この場合、親ディレクトリはidr-test/DEMO/ です。テーブルのすべての出力ファイルを、タイムスタンプなしでテーブル名と一致する名前を持つディレクトリに書き込みたいと考えています。[データディレクトリ] フィールドに入力し、[親としての接続ディレクトリ] チェックボックスを選択する必要があります。次の画像は、タスクウィザードの[ターゲット] ページにあるこの設定を示しています。
この設定に基づき、結果として得られるディレクトリ構造は次のようになります。
例2
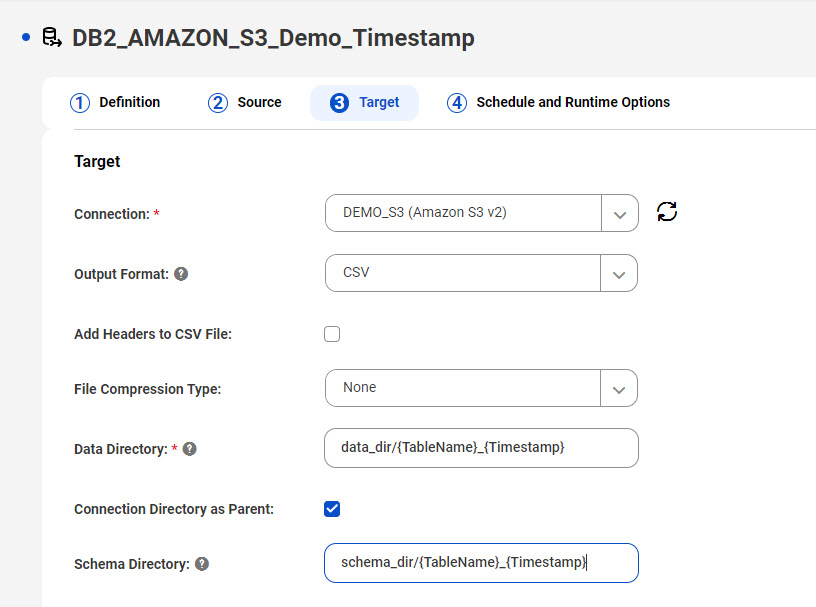
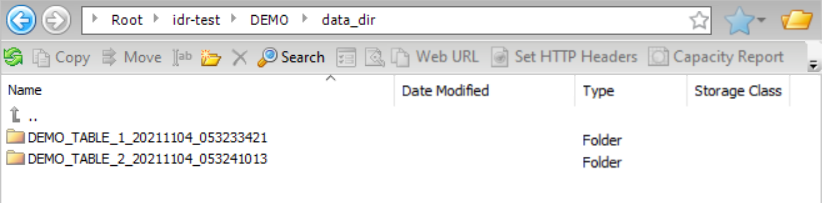
Amazon S3ターゲットを使用していて、出力データファイルをカスタムディレクトリパスに書き込み、ターゲットスキーマを別のディレクトリパスに書き込みたいとします。Amazon S3接続プロパティの[フォルダパス] フィールドで指定されたディレクトリをデータディレクトリとスキーマディレクトリの親ディレクトリとして使用するには、[親としての接続ディレクトリ] を選択します。この場合、親ディレクトリはidr-test/DEMO/ です。[データディレクトリ] フィールドと[スキーマディレクトリ] フィールドで、data_dirやschema_dirなどの特定のディレクトリ名を使用して、その後にデフォルトの{TableName}_{Timestamp}プレースホルダ値を指定することによって、ディレクトリパターンを定義します。プレースホルダは書き込み先のtablename _timestamp ディレクトリを作成します。次の画像は、タスクウィザードの[ターゲット] ページにあるこの設定を示しています。
この設定に基づき、結果として得られるデータディレクトリ構造は次のようになります。
結果として得られるスキーマディレクトリ構造は次のようになります。
増分ロード、および初期ロードと増分ロードの組み合わせ デフォルトでは、増分ロードジョブ、および初期ロードジョブと増分ロードジョブの組み合わせは、サイクルファイルとデータファイルを親ディレクトリの下のサブディレクトリに書き込みます。ただし、カスタムディレクトリ構造を作成して、組織の要件に最も合うようにファイルを整理できます。
この機能は、Amazon S3、Google Cloud Storage、Microsoft Fabric OneLake、またはMicrosoft Azure Data Lake Storage(ADLS)Gen2ターゲットを持つデータベース取り込み増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクに適用されます。
Amazon S3およびADLS Gen2のターゲットについては、タスクウィザードの[ターゲット] ページで[親としての接続ディレクトリ] チェックボックスが選択されている場合、親ディレクトリはターゲット接続プロパティで設定されます。
• [フォルダパス] フィールドで指定されます。• [ディレクトリパス] フィールドで指定されます。Google Cloud Storageターゲットでは、親ディレクトリは、タスクウィザードの[ターゲット] ページにある[バケット] フィールドで指定されたバケットコンテナです。
Microsoft Fabric OneLakeターゲットの場合、親ディレクトリは、Microsoft Fabric OneLake接続プロパティの[レイクハウスのパス] フィールドで指定されたパスです。
ニーズに合うようにディレクトリ構造をカスタマイズできます。例えば、データファイルとサイクルファイルは、接続プロパティで指定された親ディレクトリではなく、タスクのターゲットディレクトリに書き込むことができます。または、1)テーブル名を含むサブディレクトリの下にテーブル固有のデータとスキーマファイルを統合する、2)CDCサイクルごとにデータファイルとサマリコンテンツおよび完了したファイルをパーティション化する、または3)リテラル値とプレースホルダを含むパターンを定義することによって完全にカスタマイズされたディレクトリ構造を作成することができます。例えば、SQLタイプの式を実行して時間に基づいてデータを処理する場合は、CDCサイクルごとにパーティション化せずに、すべてのデータファイルをタイムスタンプサブディレクトリに直接書き込むことができます。
増分ロードタスクのカスタムディレクトリ構造を設定するには、取り込みタスクウィザードの[ターゲット] ページで、次のオプションフィールドのいずれかのパターンを定義します。
フィールド
説明
デフォルト
タスクターゲットディレクトリ
増分ロードタスクの出力ファイルを保存するために使用するルートディレクトリの名前。
[親としての接続ディレクトリ] オプションを選択した場合でも、必要に応じてタスクターゲットディレクトリを指定できます。これは親ディレクトリに追加され、データ、スキーマ、サイクル完了、およびサイクルコンテンツディレクトリのルートを形成します。
このフィールドは、次のディレクトリフィールドのいずれかのパターンで{TaskTargetDirectory}プレースホルダが指定されている場合は必須です。
なし
親としての接続ディレクトリ
接続プロパティで指定された親ディレクトリを使用するには、このチェックボックスを選択します。
このフィールドは、Microsoft Fabric OneLakeターゲットでは使用できません。
選択済み
データディレクトリ
データファイルを含むサブディレクトリへのパス。
データファイルとスキーマファイルがCDCサイクルごとにパーティション化されていない 場合、ディレクトリパスでは、{TableName}プレースホルダが必要です。
{TaskTargetDirectory}/data/{TableName}/data
スキーマディレクトリ
スキーマファイルをデータディレクトリに保存しない場合は、スキーマファイルを保存するサブディレクトリへのパス。
データファイルとスキーマファイルがCDCサイクルごとにパーティション化されていない場合、ディレクトリパスでは、{TableName}プレースホルダが必要です。
{TaskTargetDirectory}/data/{TableName}/schema
サイクル完了ディレクトリ
サイクル完了ファイルが含まれているディレクトリへのパス。
{TaskTargetDirectory}/cycle/completed
サイクルコンテンツディレクトリ
サイクルコンテンツファイルが含まれているディレクトリへのパス。
{TaskTargetDirectory}/cycle/contents
データディレクトリにサイクルのパーティション化を使用してください
各データディレクトリの下に、CDCサイクルごとにタイムスタンプサブディレクトリが作成されます。
このオプションが選択されていない場合、別のディレクトリ構造を定義しない限り、個々のデータファイルがタイムスタンプなしで同じディレクトリに書き込まれます。
選択済み
サマリディレクトリにサイクルのパーティション化を使用してください
サマリコンテンツサブディレクトリおよび完了サブディレクトリの下に、CDCサイクルごとにタイムスタンプサブディレクトリが作成されます。
選択済み
コンテンツ内の個々のファイルを一覧表示します
コンテンツサブディレクトリの下にある個々のデータファイルを一覧表示します。
[サマリディレクトリにサイクルのパーティション化を使用する] がオフの場合、このオプションはデフォルトで選択されています。タイムスタンプや日付などのプレースホルダを使用してカスタムサブディレクトリを設定できる場合を除き、コンテンツサブディレクトリ内の個々のファイルがすべて一覧表示されます。
[データディレクトリにサイクルのパーティション化を使用する] が選択されている場合でも、必要に応じてこのチェックボックスを選択して、個々のファイルを一覧表示し、CDCサイクルごとにグループ化できます。
[サマリディレクトリにサイクルのパーティション化を使用する] が選択されている場合は選択されません。
[サマリディレクトリにサイクルのパーティション化を使用する] をオフにした場合は選択されます。
ディレクトリパターンは、中括弧{ }で示される大文字と小文字を区別しないプレースホルダと特定のディレクトリ名の任意の組み合わせで構成されます。次のプレースホルダがサポートされています。
• • • • • • • • 注: タイムスタンプ、年、月、および日のプレースホルダは、データ、コンテンツ、および完了ディレクトリのパターンで指定した場合はCDCサイクルの開始時点、スキーマディレクトリパターンで指定した場合はCDCジョブの開始時点を表します。
例1 :
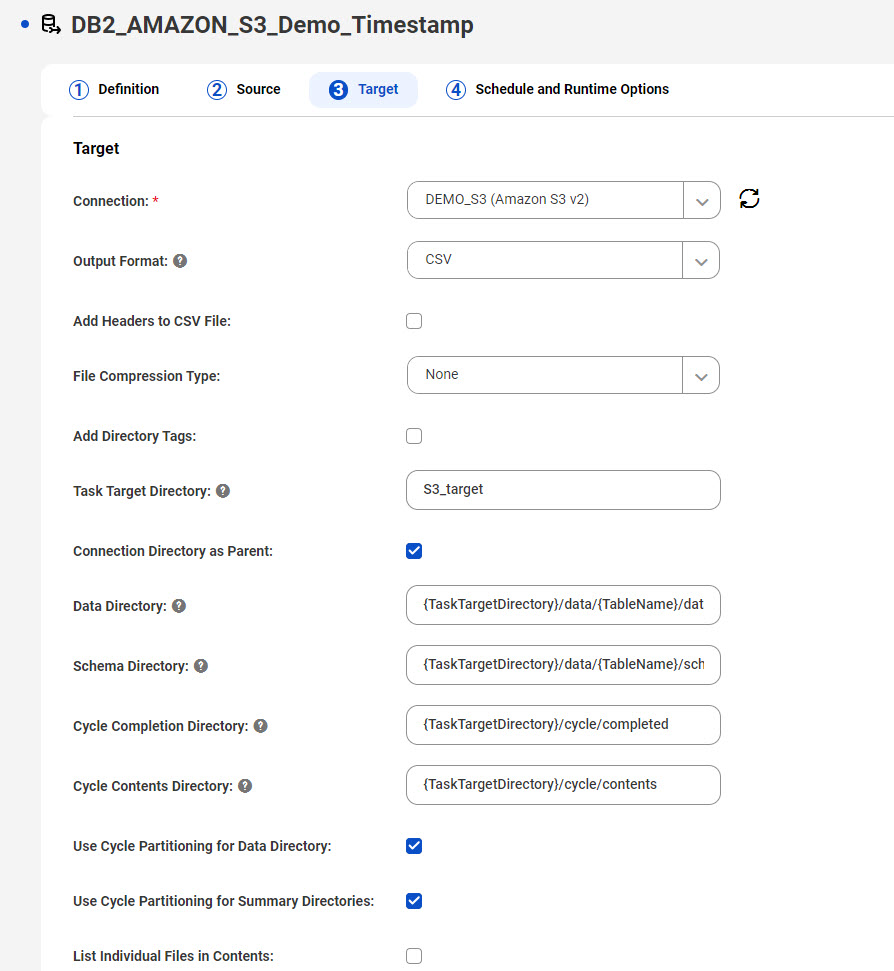
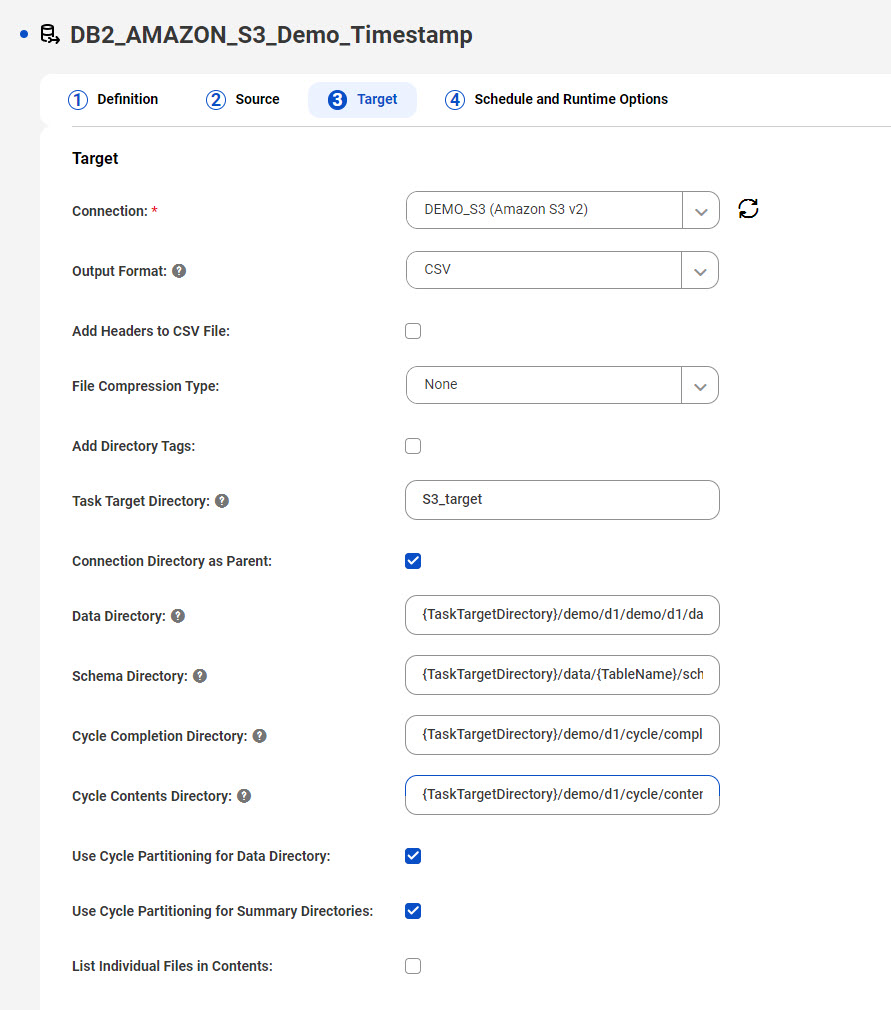
タスクウィザードに表示される増分ロードジョブ、または初期ロードジョブと増分ロードジョブの組み合わせのデフォルトのディレクトリ設定を使用するつもりだとします。ターゲットタイプはAmazon S3です。[親としての接続ディレクトリ] チェックボックスがデフォルトで選択されているため、Amazon S3接続プロパティの[フォルダパス] フィールドで指定されている親ディレクトリパスが使用されます。この親ディレクトリはidr-test/dbmi/ です。{TaskTargetDirectory}プレースホルダは、後続のディレクトリフィールドのデフォルトパターンで使用されるため、タスクターゲットディレクトリ名(この場合はs3_target)も指定する必要があります。{TableName}プレースホルダはデフォルトのパターンに含まれているため、データディレクトリとスキーマディレクトリ内のファイルはテーブル名でグループ化されます。また、サイクルのパーティション化が有効になっているため、データディレクトリ、スキーマディレクトリ、およびサイクルサマリディレクトリ内のファイルは、CDCサイクルごとにさらに分割されます。次の画像は、指定されたタスクターゲットディレクトリ名を除く、タスクウィザードの[ターゲット] ページのデフォルトの設定を示しています。
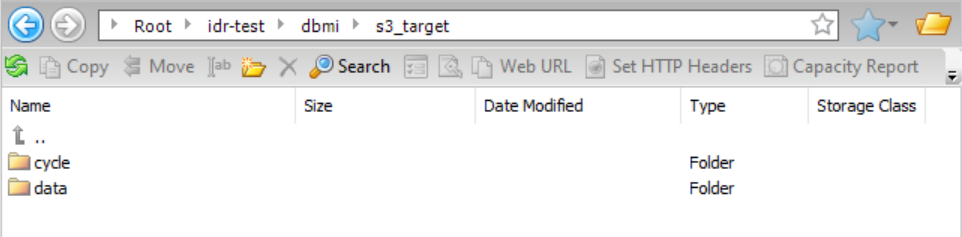
この設定に基づき、結果として得られるデータディレクトリ構造は次のようになります。
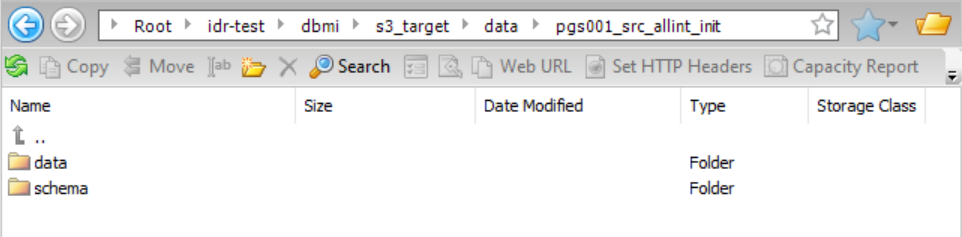
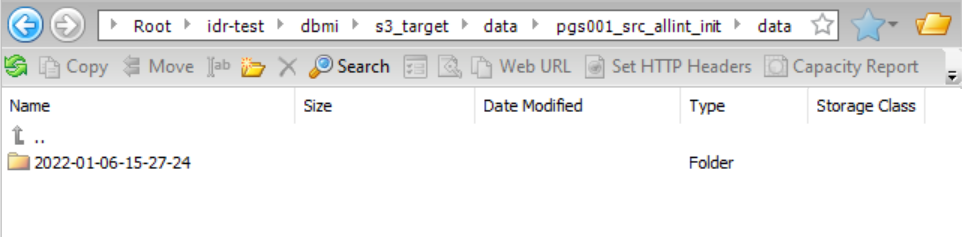
データフォルダをドリルダウンしてから、そのフォルダ内のテーブル(pgs001_src_allint_init)をドリルダウンすると、データサブディレクトリとスキーマサブディレクトリにアクセスできます。
データフォルダをドリルダウンすると、データファイルのタイムスタンプディレクトリにアクセスできます。
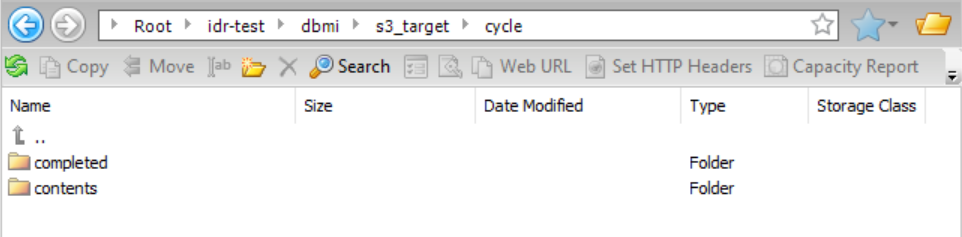
サイクルをドリルダウンすると、サマリコンテンツサブディレクトリと完了サブディレクトリにアクセスできます。
例2
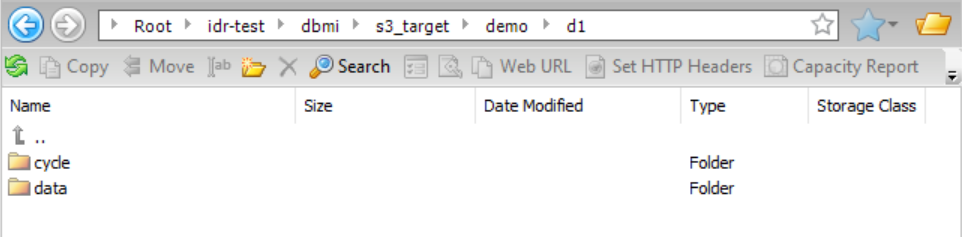
スキーマディレクトリを除くすべてのディレクトリパスにサブディレクトリ「demo」と「d1」を追加する増分ロードジョブ、または初期ロードジョブと増分ロードジョブの組み合わせ用のカスタムディレクトリ構造を作成して、デモ用のファイルを簡単に見つけられるようにしたいと考えています。[親としての接続ディレクトリ] チェックボックスが選択されているため、Amazon S3接続プロパティの[フォルダパス] フィールドで指定されている親ディレクトリパス(idr-test/dbmi/ )が使用されます。{TaskTargetDirectory}プレースホルダは、後続のディレクトリフィールドのパターンで使用されるため、タスクターゲットディレクトリも指定する必要があります。データディレクトリとスキーマディレクトリ内のファイルは、テーブル名でグループ化されます。また、サイクルのパーティション化が有効になっているため、データディレクトリ、スキーマディレクトリ、およびサイクルサマリディレクトリ内のファイルは、CDCサイクルごとにさらに分割されます。次の画像は、タスクウィザードの[ターゲット] ページにあるカスタム設定を示しています。
この設定に基づき、結果として得られるデータディレクトリ構造は次のようになります。
サポートされているAvroデータ型 データベース取り込みとレプリケーション は、Avroスキーマが提供するプリミティブデータ型と論理データ型の一部をサポートします。これらのデータ型は、AvroまたはParquet出力形式をサポートするターゲット型に関連しています。
プリミティブデータ型は、単一のデータ値を表します。論理データ型は、派生型を表す追加の属性を持つAvroプリミティブデータ型または複合データ型です。
次の表に、データベース取り込みとレプリケーション がサポートするプリミティブAvroデータ型を示します。
プリミティブデータ型
説明
INT
32ビット符号付き整数
Long
64ビット符号付き整数
FLOAT
単精度(32ビット)IEEE 754浮動小数点数
DOUBLE
倍精度(64ビット)IEEE 754浮動小数点数
BYTES
8ビットの符号なしバイトのシーケンス
STRING
Unicode文字シーケンス
次の表に、データベース取り込みとレプリケーション がサポートする論理Avroデータ型を示します。
論理データ型
説明
DECIMAL
スケーリングされていない形式の任意精度の符号付き10進数×10 - scale
DATE
時刻またはタイムゾーンへの参照を含まない日付。
TIME
タイムゾーンまたは日付への参照を含まない、1ミリ秒または1マイクロ秒の精度の時刻。
TIMESTAMP
特定のカレンダーまたはタイムゾーンへの参照を含まない、1ミリ秒または1マイクロ秒の精度の日時値。
Databricksターゲットの場合、データベース取り込みとレプリケーション は中間Parquetファイルで次のデータ型を使用しません。
• •