On the Definition tab of a profile, you can configure asset and source details. You can also select the columns and choose a filter for the profile run.
Asset Details
You can enter a name and choose a location for the profile.
The following table lists the options that you can configure in the Asset Details area:
Option
Description
Name
Enter a name for the profile.
The profile name must be unique in the folder where you save it. The profile name cannot contain special characters.
Description
Optionally, enter a description for the profile.
Location
Choose a location to save the profile. If you do not choose a location, the profile is saved in the Default project.
Source Details
You can choose a source object after you create a connection to the data source in Administrator.
The following table lists the options that you can configure in the Source Details area:
Option
Description
Connection
Choose an existing connection.
You can create a connection in Administrator.
Source object
Select a source object to run the profile on.
When you click Select to browse for a source object, the Select a Source Object dialog box shows a maximum of 200 source objects. Use the Find field to search for a source object in the list. Optionally, you can use the copy icon to copy the directory path for directory override in the Advanced Options for Azure Data Lake Store Gen2 and Amazon S3 V2 connections.
Formatting Options
Optional. Define the file format options.
Data Profiling supports CSV and TXT files that have UTF-8 encoding enabled. Appears when you select a file-based connection.
Advanced Options
Mandatory. Configure the advanced options for the source objects.
You can also use a source mapplet as a source connection for profiling tasks, or run a profiling task on a mapplet as a source object. For more information about source mapplets, see Source Mapplets.
Formatting Options
You can optionally configure the formatting options if you choose a file as a source object.
Flat File
You can run a profile on delimited flat files with multi-byte characters and fixed-width flat files.
The following table lists the options that you can configure for a delimited flat file:
Option
Description
Delimiter
Indicates the boundary between two columns of data.
Choose one of the following options:
- Comma
- Tab
- Colon
- Semicolon
- Non Printable. When you choose this option, the Non-printable character drop-down list appears. Select a non-printable character to use as the delimiter.
- Other. Select this option and specify the character to use as the delimiter.
- If you specify a comma, colon, or semicolon, the corresponding options are selected.
- If the character specified here matches with any of the values in the Non-printable character drop-down list, the value appears in the Non-printable character drop-down list.
If you use an escape character or a quote character as the delimiter, or if you use the same character as consecutive delimiter and qualifier, you might receive unexpected results.
Default is comma.
Text Qualifier
Character that defines the boundaries of text strings.
If you select a quote character, Data Profiling ignores delimiters within quotes.
Default is double quote (").
Escape Character
Character that immediately precedes a column delimiter character embedded in an unquoted string, or immediately precedes the quote character in a quoted string.
When you specify an escape character, Data Profiling reads the delimiter character as a regular character.
Field Labels
Choose one of the following options to display the column names in profile results:
- Auto-generate. Data Profiling auto-generates the column names.
- Import from Row <row_number>. Imports the column name from the specified row number.
First Data Row <row_number>
Row number from which Data Profiling starts to read when it imports the file. For example, if you enter 2, Data Profiling skips the first row.
Note: Data Profiling sets the First Data Row automatically when you set the Import from Row option. For example, if you set the Import from Row option to 10, Data Profiling sets the First Data Row to 11.
To run a profile on fixed-width flat file, select the fixed-width format that you configured in Data Integration.
Amazon S3 v2
The following table lists the options for the delimited format type:
Option
Description
Schema Source
You must specify the schema of the source file. You can select one of the following options to specify a schema:
- Read from data file. Amazon S3 V2 Connector imports the schema from the file in Amazon S3.
- Import from schema file. Imports schema from a schema definition file in your local machine.
Default is Read from data file.
Delimiter
Character used to separate columns of data. You can configure parameters such as comma, tab, colon, semicolon, or others. To set a tab as a delimiter, you must type the tab character in any text editor. Then, copy and paste the tab character in the Delimiter field.If you specify a multibyte character as a delimiter in the source object, the mapping fails.
Default is comma (,).
Escape Character
Character immediately preceding a column delimiter character embedded in an unquoted string, or immediately preceding the quote character in a quoted string.
Default is backslash (\).
Text Qualifier
Character that defines the boundaries of text strings.
If you select a quote character, Data Profiling ignores delimiters within quotes.
Default is double quote (").
Qualifier Mode
Specify the qualifier behavior for the target object. You can select one of the following options:
- Minimal. Default mode. Applies qualifier to data that have a delimiter value or a special character present in the data. Otherwise, the Secure Agent does not apply the qualifier when writing data to the target.
- All. Applies qualifier to all data.
Default is Minimal.
Code Page
UTF-8. Select for Unicode and non-Unicode data. Select the code page that the Secure Agent must use to read data.
Header Line Number
Specify the line number that you want to use as the header when you read data from Amazon S3. You can also read data from a file that does not have a header. Default is 1.
To read data from a file with no header, specify the value of the Header Line Number field as 0.To read data from a file with a header, set the value of the Header Line Number field to a value that is greater or equal to one.
This property is applicable during runtime and data preview to read a file. This property is applicable during data preview to write a file.
First Data Row
Specify the line number from where you want the Secure Agent to read data. You must enter a value that is greater or equal to one. To read data from the header, the value of the Header Line Number and the First Data Row fields should be the same. Default is 2.
This property is applicable during runtime and data preview to read a file. This property is applicable during data preview to write a file.
Row Delimiter
Character used to separate rows of data. You can set values as\r\n,\n, and \r.
The following table lists the options for the avro and parquet format type:
Option
Description
Schema Source
The schema of the source or target file. You can select one of the following options to specify a schema:
- Read from data file. Default. Amazon S3 V2 Connector reads the schema from the source file that you select.
- Import from Schema File. Imports schema from a schema definition file in your local machine.
Schema File
Upload a schema definition file. You cannot upload a schema file when you create a target at runtime.
The following table lists the options for the JSON format type:
Option
Description
Schema Source
The schema of the source or target file. You can select one of the following options to specify a schema:
- Read from data file. Default. Amazon S3 V2 Connector reads the schema from the source file that you select.
- Import from Schema File. Imports schema from a schema definition file in your local machine.
Schema File
Upload a schema definition file. You cannot upload a schema file when you create a target at runtime.
Sample Size
Specify the number of rows to read to find the best match to populate the metadata.
Memory Limit
The memory that the parser uses to read the JSON sample schema and process it.
The default value is 2 MB.If the file size is more than 2 MB, you might encounter an error. Set the value to the file size that you want to read.
Azure Data Lake Store Gen2
The following table lists the options for the delimited format type:
Option
Description
Schema Source
You must specify the schema of the source file. You can select one of the following options to specify a schema:
- Read from data file. Azure Data Lake Store Gen2 Connector imports the schema from the file in Azure Data Lake Store.
- Import from schema file. Imports schema from a schema definition file in your local machine.
Default is Read from data file.
Delimiter
Character used to separate columns of data. You can configure parameters such as comma, tab, colon, semicolon, or others.
Note: You cannot set a tab as a delimiter directly in the Delimiter field. To set a tab as a delimiter, you must type the tab character in any text editor. Then, copy and paste the tab character in the Delimiter field.
Default is comma (,).
Escape Character
Character immediately preceding a column delimiter character embedded in an unquoted string, or immediately preceding the quote character in a quoted string.
Default is backslash (\).
Text Qualifier
Character that defines the boundaries of text strings.
If you select a quote character, Data Profiling ignores delimiters within quotes.
Default is double quote (").
Qualifier Mode
Specify the qualifier behavior for the target object. You can select one of the following options:
- Minimal. Default mode. Applies qualifier to data that have a delimiter value or a special character present in the data. Otherwise, the Secure Agent does not apply the qualifier when writing data to the target.
- All. Applies qualifier to all data.
Default is Minimal.
Code Page
Select the code page that the Secure Agent must use to read data.
Microsoft Azure Data Lake Storage Gen2 Connector supports only UTF-8. Ignore rest of the code pages.
Header Line Number
Specify the line number that you want to use as the header when you read data from Microsoft Azure Data Lake Storage Gen2. You can also read a data from a file that does not have a header. To read data from a file with no header, specify the value of the Header Line Number field as 0.
Note: This property is applicable when you perform data preview.
Default is 1.
First Data Row
Specify the line number from where you want the Secure Agent to read data. You must enter a value that is greater or equal to one. To read data from the header, the value of the Header Line Number and the First Data Row fields should be the same. Default is 2.
Note: This property is applicable when you perform data preview.
Row Delimiter
Character used to separate rows of data. You can set values as\r\n,\n, and \r.
The following table lists the options for the avro and parquet format type:
Option
Description
Schema Source
The schema of the source or target file. You can select one of the following options to specify a schema:
- Read from data file. Default. Azure Data Lake Store Gen2 Connector reads the schema from the source file that you select.
- Import from Schema File. Imports schema from a schema definition file in your local machine.
Schema File
Upload a schema definition file. You cannot upload a schema file when you create a target at runtime.
The following table lists the options for the JSON format type:
Option
Description
Schema Source
The schema of the source or target file. You can select one of the following options to specify a schema:
- Read from data file. Default. Azure Data Lake Store Gen2 Connector reads the schema from the source file that you select.
- Import from Schema File. Imports schema from a schema definition file in your local machine.
Schema File
Upload a schema definition file. You cannot upload a schema file when you create a target at runtime.
Sample Size
Specify the number of rows to read to find the best match to populate the metadata.
Memory Limit
The memory that the parser uses to read the JSON sample schema and process it.
The default value is 2 MB.If the file size is more than 2 MB, you might encounter an error. Set the value to the file size that you want to read.
Google Cloud Storage V2
The following table lists the options for the delimited format type:
Option
Description
Schema Source
You must specify the schema of the source file. You can select one of the following options to specify a schema:
- Read from data file. Google Cloud Storage V2 Connector imports the schema from the file in Google Cloud Storage.
- Import from schema file. Imports schema from a schema definition file in your local machine.
Default is Read from data file.
Delimiter
Character used to separate columns of data. You can configure parameters such as comma, tab, colon, semicolon, or others. To set a tab as a delimiter, you must type the tab character in any text editor. Then, copy and paste the tab character in the Delimiter field.
If you specify a multibyte character as a delimiter in the source object, the mapping fails.
Note: To set a tab as a delimiter, you must type the tab character in any text editor. Then, copy and paste the tab character in the Delimiter field.
Escape Character
Character immediately preceding a column delimiter character embedded in an unquoted string, or immediately preceding the quote character in a quoted string.
Text Qualifier
Character that defines the boundaries of text strings.
If you select a quote character, Data Profiling ignores delimiters within quotes.
Default is double quote (").
Qualifier Mode
Specify the qualifier behavior for the target object. You can select one of the following options:
- Minimal. Default mode. Applies qualifier to data enclosed within a delimiter value or a special character.
- All. Applies qualifier to all data.
- Non_Numeric. Not applicable.
- All_Non_Null. Not applicable.
Code Page
Select the code page that the Secure Agent must use to read or write data.Google Cloud Storage V2 Connector supports the following code pages:
- MS Windows Latin 1. Select for ISO 8859-1 Western European data.
- UTF-8. Select for Unicode and non-Unicode data.
- Shift-JIS. Select for double-byte character data.
- ISO 8859-15 Latin 9 (Western European).
- ISO 8859-2 Eastern European.
- ISO 8859-3 Southeast European.
- ISO 8859-5 Cyrillic.
- ISO 8859-9 Latin 5 (Turkish).
- IBM EBCDIC International Latin-1.
Header Line Number
Specify the line number that you want to use as the header when you read data from Google Cloud Storage. You can also read a file that doesn't have a header. Default is 1.
To read data from a file with no header, specify the value of the Header Line Number field as 0. To read data from a file with a header, set the value of the Header Line Number field to a value that is greater than or equal to one. Ensure that the value of the Header Line Number field is lesser than or equal to the value of the First Data Row field. This property is applicable during runtime and data preview to read a file. When you create a mapping in advanced mode, set the value of the header line number to 0, 1, or empty to run the mapping successfully.
First Data Row
Specify the line number from where you want the Secure Agent to read data. You must enter a value that is greater or equal to one.
To read data from the header, the value of the Header Line Number and the First Data Row fields should be the same. Default is 1.
This property is applicable during runtime and data preview to read a file. This property is applicable during data preview to write a file.
Row Delimiter
Not applicable.
Character used to separate rows of data. You can set values as\r\n,\n, and \r.
The following table lists the options for the avro and parquet format type:
Option
Description
Schema Source
The schema of the source or target file. You can select one of the following options to specify a schema:
- Read from data file. Default. Azure Data Lake Store Gen2 Connector reads the schema from the source file that you select.
- Import from Schema File. Imports schema from a schema definition file in your local machine.
Schema File
Upload a schema definition file. You cannot upload a schema file when you create a target at runtime.
The following table lists the options for the JSON format type:
Option
Description
Schema Source
The schema of the source or target file. You can select one of the following options to specify a schema:
- Read from data file. Default. Azure Data Lake Store Gen2 Connector reads the schema from the source file that you select.
- Import from Schema File. Imports schema from a schema definition file in your local machine.
Schema File
Upload a schema definition file. You cannot upload a schema file when you create a target at runtime.
Sample Size
Specify the number of rows to read to find the best match to populate the metadata.
Memory Limit
The memory that the parser uses to read the JSON sample schema and process it.
The default value is 2 MB.If the file size is more than 2 MB, you might encounter an error. Set the value to the file size that you want to read.
Read multiple-line JSON files
Not applicable.
Oracle Cloud Object Storage
The following table lists the options for the delimited format type:
Option
Description
Schema Source
You must specify the schema of the source file. You can select one of the following options to specify a schema:
- Read from data file. Oracle Cloud Object Storage Connector imports the schema from the file in Oracle Cloud Object Storage.
- Import from schema file. Imports schema from a schema definition file in your local machine.
Default is Read from data file.
Delimiter
Character used to separate columns of data. You can configure parameters such as comma, tab, colon, semicolon, or others.
Note: You cannot set a tab as a delimiter directly in the Delimiter field. To set a tab as a delimiter, you must type the tab character in any text editor. Then, copy and paste the tab character in the Delimiter field.
Default is comma (,).
Escape Character
Character immediately preceding a column delimiter character embedded in an unquoted string, or immediately preceding the quote character in a quoted string.
Default is backslash (\).
Text Qualifier
Character that defines the boundaries of text strings.
If you select a quote character, Data Profiling ignores delimiters within quotes.
Default is double quote (").
Qualifier Mode
Specify the qualifier behavior for the target object. You can select one of the following options:
- Minimal. Default mode. Applies qualifier to data that have a delimiter value or a special character present in the data. Otherwise, the Secure Agent does not apply the qualifier when writing data to the target.
- All. Applies qualifier to all data.
Default is Minimal.
Code Page
Select the code page that the Secure Agent must use to read data.
Oracle Cloud Object Storage Connector supports only UTF-8. Ignore rest of the code pages.
Header Line Number
Specify the line number that you want to use as the header when you read data from Oracle Cloud Object Storage. You can also read a data from a file that does not have a header. To read data from a file with no header, specify the value of the Header Line Number field as 0.
Note: This property is applicable when you perform data preview.
Default is 1.
First Data Row
Specify the line number from where you want the Secure Agent to read data. You must enter a value that is greater or equal to one. To read data from the header, the value of the Header Line Number and the First Data Row fields should be the same. Default is 2.
Note: This property is applicable when you perform data preview.
Row Delimiter
Character used to separate rows of data. You can set values as\r\n,\n, and \r.
Advanced Options
For certain source objects, you can configure advanced options.
Amazon Athena
The following table lists the options that you can configure for an Amazon Athena source object:
Property
Description
Retain Athena Query Result On S3 File
Specifies whether you want to retain the Amazon Athena query result on the Amazon S3 file. Select the check box to retain the Amazon Athena query result on the Amazon S3 file.
The Amazon Athena query result in stored in a CSV file.
By default, the Retain Athena Query Result On S3 File check box is not selected.
If you select this property for a workgroup with Athena managed query results, it is ignored.
S3OutputLocation
Specifies the location of the Amazon S3 file that stores the result of the Amazon Athena query.
You can also specify the Amazon S3 file location in the S3OutputLocation parameter in the JDBC URL connection property.
If you specify the Amazon S3 output location in both the connection and the advanced source properties, the Secure Agent uses the Amazon S3 output location specified in the advanced source properties.
Fetch Size
Determines the number of rows to read in one result set from Amazon Athena.
Default is 10000.
Encryption Type
Encrypts the data in the Amazon S3 staging directory.
You can select the following encryption types:
- None
- SSE-S3
- SSE-KMS
- CSE-KMS
Default is None.
Schema Name
Overrides the schema name of the source object.
Source Table Name
Overrides the table name used in the metadata import with the table name that you specify.
SQL Query
Overrides the default SQL query.
Enclose column names in double quotes. The SQL query is case sensitive. Specify an SQL statement supported by the Amazon Athena database.
When you specify the columns in the SQL query, ensure that the column name in the query matches the source column name in the mapping.
Amazon S3 v2
The following table lists the options that you can configure for an Amazon S3 source object:
Option
Description
Source Type
Type of the source from which you want to read data.
Optional. Overwrites the bucket name or folder path of the Amazon S3 source file.If applicable, include the folder name that contains the source file in the <bucket_name>/<folder_name> format.
If you do not provide the bucket name and specify the folder path starting with a slash (/) in the /<folder_name> format, the folder path appends with the folder path that you specified in the connection properties.
For example, if you specify the /<dir2> folder path in this property and <my_bucket1>/<dir1> folder path in the connection property, the folder path appends with the folder path that you specified in the connection properties in <my_bucket1>/<dir1>/<dir2> format.
File Name
Optional. Overwrites the Amazon S3 source file name.
Allow Wildcard Characters
Use the ? and * wildcard characters to specify the folder path or file name if you run a mapping in advanced mode to read data from an Avro, flat, JSON, ORC, or Parquet file.
Enable Recursive Read
Use the recursive read option for flat, Avro, JSON, ORC, and Parquet files. The files that you read using recursive read must have the same metadata. Enable recursive read when you specify wildcard characters in a folder path or file name. To enable recursive read, select the source type as Directory.
Incremental File Load
Incrementally load source files in a directory to read and process only the files that have changed since the last time the mapping task ran.
Staging Directory
Optional. Path of the local staging directory. Ensure that the user has write permissions on the directory. In addition, ensure that there is sufficient space to enable staging of the entire file. Default staging directory is the /temp directory on the machine that hosts the Secure Agent.
When you specify the directory path, the Secure Agent create folders depending on the number of partitions that you specify in the following format: InfaS3Staging<00/11><timestamp>_<partition number> where, 00 represents read operation and 11 represents write operation.
For example, InfaS3Staging000703115851268912800_0 The temporary files are created within the new directory. The staging directory in the source property does not apply to an advanced cluster. However, you must specify a staging directory on Amazon S3 in the advanced configuration.
For more information, see Administrator.
Hadoop Performance Tuning Options
Optional. This property is not applicable for Amazon S3 V2 Connector.
Compression Format
Decompresses data when you read data from Amazon S3.
You can choose to decompress the data in the following formats:
- None
- Gzip
Default is None.
Note: Amazon S3 V2 Connector does not support the Lzo and Bzip2 compression format even though the option appears in this property.
Downloads the part size of an Amazon S3 object in bytes.
Default is 5 MB. Use this property when you run a mapping to read a file of flat format type.
Multipart Download Threshold
Minimum threshold size to download an Amazon S3 object in multiple parts.
To download the object in multiple parts in parallel, ensure that the file size of an Amazon S3 object is greater than the value you specify in this property. Default is 10 MB.
Temporary Credential Duration
The time duration during which an IAM user can use the dynamically generated temporarily credentials to access the AWS resource. Enter the time duration in seconds.
Default is 900 seconds. If you require more than 900 seconds, you can set the time duration maximum up to 12 hours in the AWS console and then enter the same time duration in this property.
Azure Data Lake Store Gen2
The following table lists the options that you can configure for an Azure Data Lake Store source object:
Option
Description
Concurrent Threads
Optional. Number of concurrent connections to load data from the Microsoft Azure Data Lake Storage Gen2. When writing a large file, you can spawn multiple threads to process data. Configure Block Size to divide a large file into smaller parts. Default is 4. Maximum is 10.
Filesystem Name Override
Optional. Overrides the default file name.
Source Type
Type of the source from which you want to read data.
Use the ? and * wildcard characters to specify the folder path or file name if you run a mapping in advanced mode to read data from an Avro, flat, JSON, ORC, or Parquet file.
Directory Override
Optional. Microsoft Azure Data Lake Storage Gen2 directory that you use to write data. Default is root directory. The Secure Agent creates the directory if it does not exist. The directory path specified at run time overrides the path specified while creating a connection.
File Name Override
Optional. Target object. Select the file from which you want to write data. The file specified at run time overrides the file specified in Object.
Block Size
Optional. Divides a large file or object into smaller parts each of specified block size. When writing a large file, consider dividing the file into smaller parts and configure concurrent connections to spawn required number of threads to process data in parallel. Default is 8 MB.
Compression Format
Optional. Compresses and writes data to the target. Select Gzip to write flat files.
Timeout Interval
Optional. The number of seconds to wait when attempting to connect to the server. A timeout will occur if the connection cannot be established in the specified amount of time.
Interim Directory
Optional. Path to the staging directory in the Secure Agent machine.
Specify the staging directory where you want to stage the files when you read data from Microsoft Azure Data Lake Store. Ensure that the directory has sufficient space and you have write permissions to the directory.
Default staging directory is /tmp.
You cannot specify an interim directory for an advanced cluster.
Incremental File Load
Incrementally load source files in a directory to read and process only the files that have changed since the last time the mapping task ran.
Enable Recursive Read
Use the recursive read option for flat, Avro, JSON, ORC, and Parquet files. The files that you read using recursive read must have the same metadata. Enable recursive read when you specify wildcard characters in a folder path or file name. To enable recursive read, select the source type as Directory.
Google Cloud Storage
The following table lists the options that you can configure for a Google Cloud Storage source object:
Option
Description
Google Cloud Storage Path
Overrides the Google Cloud Storage path that you specified in the connection. This property is required when the source is not a flat file. Use the following format: gs://<bucket name> or gs://<bucket name>/<folder name>
Source File Name
Optional. Overrides the Google Cloud Storage source file name that you specified in the Source transformation.
Note: Does not apply when you configure Is Directory option to read multiple files from a directory.
Is Directory
Select this property to read all the files available in the folder specified in the Google Cloud Storage Path property.
Encryption Type
Method to decrypt data.
You can select one of the following encryption types:
- Informatica Encryption
- None
Default is None .
Snowflake Data Cloud
The following table lists the options that you can configure for a Snowflake Data Cloud source object:
Option
Description
Database
Overrides the database specified in the connection.
Schema
Overrides the schema specified in the connection.
Warehouse
Overrides the Snowflake warehouse name specified in the connection.
Role
Overrides the Snowflake role assigned to user specified in the connection.
Table Name
Overrides the table name of the imported Snowflake Data Cloud source table.
Amazon Redshift V2
The following table lists the options that you can configure for an Amazon Redshift V2 source object:
Option
Description
S3 Bucket Name
Amazon S3 bucket name for staging the data. You can also specify the bucket name with the folder path.
Enable Compression
Compresses the staging files into the Amazon S3 staging directory. The task performance improves when the Secure Agent compresses the staging files. Default is selected.
Staging Directory Location
Location of the local staging directory. When you run a task in Secure Agent runtime environment, specify a directory path that is available on the corresponding Secure Agent machine in the runtime environment.Specify the directory path in the following manner: <staging directory>
For example, C:\Temp. Ensure that you have the write permissions on the directory.
Does not apply to an advanced cluster.
Temporary Credential Duration
The time duration during which an IAM user can use the dynamically generated temporarily credentials to access the AWS resource. Enter the time duration in seconds. Default is 900 seconds.
If you require more than 900 seconds, you can set the time duration up to a maximum of 12 hours in the AWS console and then enter the same time duration in this property.
Encryption Type
Encrypts the data in the Amazon S3 staging directory. You can select the following encryption types:
- None
- SSE-S3
- SSE-KMS
- CSE-SMK
You can only use SSE-S3 encryption in a mapping that runs on an advanced cluster.
Default is None.
Download S3 Files in Multiple Parts
Downloads large Amazon S3 objects in multiple parts. When the file size of an Amazon S3 object is greater than 8 MB, you can choose to download the object in multiple parts in parallel. Default is 5 MB. Does not apply to an advanced cluster.
Multipart Download Threshold Size
The maximum threshold size to download an Amazon S3 object in multiple parts. Default is 5 MB. Does not apply to an advanced cluster.
Schema Name
Overrides the default schema name.
Note: You cannot configure a custom query when you use the schema name.
Source Table Name
Overrides the default source table name.
Note: When you select the source type as Multiple Objects or Query , you cannot use the Source Table Name option.
Databricks Delta
The following table lists the options that you can configure for a Databricks Delta source object:
Option
Description
Database Name
Overrides the database name provided in connection and the database name provided during metadata import.
Note: To read from multiple objects. ensure that you have specified the database name in the connection properties.
Table Name
Overrides the table name used in the metadata import with the table name that you specify.
SQL Override
Overrides the default SQL query used to read data from a Databricks Delta custom query source.
The column names in the SQL override query should match with the column names in the custom query in a SQL transformation.
Note: The metadata of the source should be the same as SQL override to override the query.
You can use the option when you run the profiling task on a Data Integration Server.
Staging Location
Relative directory path to the staging file storage.
- If the Databricks cluster is deployed on AWS, use the path relative to the Amazon S3 staging bucket.
- If the Databricks cluster is deployed on Azure, use the path relative to the Azure Data Lake Store Gen2 staging filesystem name.
Note: When you use the unity catalog, a pre-existing location on the user's cloud storage must be provided in the Staging Location. The Staging Location is not required for the Unity Catalog when you run the profiling task on a Data Integration Server.
Job Timeout
Maximum time in seconds that is taken by the Spark job to complete processing. If the job is not completed within the time specified, the Databricks cluster terminates the job and the mapping fails.
If the job timeout is not specified, the mapping shows success or failure based on the job completion.
Job Status Poll Interval
Poll interval in seconds at which the Secure Agent checks the status of the job completion.
Default is 30 seconds.
DB REST API Timeout
The Maximum time in seconds for which the Secure Agent retries the REST API calls to Databricks when there is an error due to network connection or if the REST endpoint returns 5xx HTTP error code.
Default is 10 minutes.
DB REST API Retry Interval
The time Interval in seconds at which the Secure Agent must retry the REST API call, when there is an error due to network connection or when the REST endpoint returns 5xx HTTP error code.
This value does not apply to the Job status REST API. Use job status poll interval value for the Job status REST API.
Default is 30 seconds.
JDBC V2
The following table lists the options that you can configure for a JDBC V2 source object:
Option
Description
Pre SQL
The SQL query that the Secure Agent runs before reading data from the source.
Post SQL1
The SQL query that the Secure Agent runs after reading data from the source.
Fetch Size
The number of rows that the Secure Agent fetches from the database in a single call.
Table Name
Overrides the table name used in the metadata import with the table name that you specify.
Schema Name
Overrides the schema name of the source object.
If you specify the schema name both in the connection and the source properties, the Secure Agent uses the schema name specified in the source properties.
SQL Override
The SQL statement to override the default query and the object name that is used to read data from the JDBC V2 source.
1Doesn't apply to mappings in advanced mode.
Microsoft Azure Synapse SQL
The following table lists the options that you can configure for a Microsoft Azure Synapse SQL source object:
Option
Description
Azure Blob Container Name
Microsoft Azure Blob Storage container name. Required if you select Azure Blob storage in the connection properties.
ADLS FileSystem Name
The name of the file system in Microsoft Azure Data Lake Storage Gen2.
Required if you select ADLS Gen2 storage in the connection properties. You can also provide the path of the directory under given file system.
Schema Name Override
Overrides the schema specified in the connection.
Table Name Override
Overrides the table name of the imported Microsoft Azure Synapse SQL source table.
Field Delimiter
Character used to separate fields in the file. Default is 0x1e. You can specify 'TAB' or 0-256 single-char printable and non-printable ASCII characters. Non-printable characters must be specified in hexadecimal.
Number of concurrent connections to Blob Store
Number of concurrent connections to extract data from the Microsoft Azure Blob Storage. When reading a large-size blob, you can spawn multiple threads to process data. Configure Blob Part Size to partition a large-size blob into smaller parts. Default is 4. Maximum is 10.
Blob Part Size
Partitions a blob into smaller parts each of specified part size. When reading a large-size blob, consider partitioning the blob into smaller parts and configure concurrent connections to spawn required number of threads to process data in parallel. Default is 8 MB.
Quote Character
The Secure Agent skips the specified character when you read data from Microsoft Azure Synapse SQL. Default is 0x1f .
Interim Directory
Optional. Path to the staging directory in the Secure Agent machine.Specify the staging directory where you want to stage the files when you read data from Microsoft Azure Synapse SQL. Ensure that the directory has sufficient space and you have write permissions to the directory.
Default staging directory is /tmp.
You cannot specify an interim directory for an advanced cluster.
Microsoft Fabric Data Warehouse
The following table lists the options that you can configure for a Microsoft Fabric Data Warehouse source object:
Option
Description
Schema Name Override
Overrides the schema specified in the connection.
Table Name Override
Overrides the table name of the Microsoft Fabric Data Warehouse source table.
SQL Override
The SQL statement to override the default query and the object name that is used to read data from the Microsoft Fabric Data Warehouse source.
pre SQL
The SQL query that the Secure Agent runs before reading data from the source.
post SQL
The SQL query that the Secure Agent runs after reading data from the source.
On Pre-Post SQL Error
Required if the you use pre SQL or post SQL options.
If you select Stop, the SQL query does not run if an error occurs.
If you select Continue, the SQL query continues to run regardless of errors.
Microsoft SQL Server
The following table lists the options that you can configure for a Microsoft SQL Server source object:
Option
Description
Schema Name
Overrides the schema name of the source object.
Table Name
Overrides the table name used in the metadata import with the table name that you specify.
Tracing Level
The amount of detail that appears in the log file. Select terse, normal, verbose initialization, or verbose data. Default is normal.
Pre SQL
The SQL query that the Secure Agent runs before reading data from the source.
Post SQL
The SQL query that the Secure Agent runs after reading data from the source.
SQL Override
The SQL statement to override the default query generated from the specified source type.
Ensure that the number of columns, order of columns, and the data type you specify in the query matches the Microsoft SQL Server source object.
ODBC
The following table lists the options that you can configure for an ODBC source object:
Option
Description
Schema Name
Overrides the schema name of the source object.
Table Name
Overrides the table name used in the metadata import with the table name that you specify.
Tracing Level
The amount of detail that appears in the log file. Select terse, normal, verbose initialization, or verbose data. Default is normal.
Pre SQL
The SQL query that the Secure Agent runs before reading data from the source.
Post SQL
The SQL query that the Secure Agent runs after reading data from the source.
SQL Override
The SQL statement to override the default query generated from the specified source type to read data from the ODBC source.
Output is deterministic
Relational source or transformation output that does not change between session runs when the input data is consistent between runs.
When you configure this property, the Secure Agent does not stage source data for recovery if transformations in the pipeline always produce repeatable data.
Specify only when the source output does not change between session runs.
Output is repeatable
Relational source or transformation output that is in the same order between session runs when the order of the input data is consistent.
When output is deterministic and output is repeatable, the Secure Agent does not stage source data for recovery.
Specify only when the order of the source output is the same between the session runs. Select Never or Always.
Oracle
The following table lists the options that you can configure for an Oracle source object:
Option
Description
Schema Name
Overrides the schema name of the source object.
Table Name
Overrides the table name used in the metadata import with the table name that you specify.
Tracing Level
The amount of detail that appears in the log file. Select terse, normal, verbose initialization, or verbose data. Default is normal.
Pre SQL
The SQL query that the Secure Agent runs before reading data from the source.
Post SQL
The SQL query that the Secure Agent runs after reading data from the source.
SQL Override
The SQL statement to override the default query generated from the specified source type to read data from the Oracle source.
Output is deterministic
Relational source or transformation output that does not change between session runs when the input data is consistent between runs.
When you configure this property, the Secure Agent does not stage source data for recovery if transformations in the pipeline always produce repeatable data.
Specify only when the source output does not change between session runs.
Output is repeatable
Relational source or transformation output that is in the same order between session runs when the order of the input data is consistent.
When output is deterministic and output is repeatable, the Secure Agent does not stage source data for recovery.
Specify only when the order of the source output is the same between the session runs. Select Never or Always.
Oracle Cloud Object Storage
The following table lists the options that you can configure for an Oracle Cloud Object Storage source object:
Option
Description
Folder Path
Overrides the folder path value in the Oracle Cloud Object Storage connection.
File Name
Overrides the Oracle Cloud Object Storage source file name.
Staging Directory
Path of the local staging directory. Ensure that the user has write permissions on the directory. In addition, ensure that there is sufficient space to enable staging of the entire file. Default staging directory is the /temp directory on the machine that hosts the Secure Agent. The temporary files are created within the new directory.
Multipart Download Threshold
Minimum threshold size to download an Oracle Cloud Object Storage object in multiple parts. To download the object in multiple parts in parallel, ensure that the file size of an Oracle Cloud Object Storage object is greater than the value you specify in this property.
Range :
- Minimum: 4 MB
- Maximum: 5 GB
Default is 64 MB.
Download Part Size
Downloads the part size of an Oracle Cloud Object Storage object in bytes.
Range:
- Minimum: 4 MB
- Maximum: 1GB
Default is 32 MB.
PostgreSQL
The following table lists the options that you can configure for a PostgreSQL source object:
Option
Description
Pre-SQL
The SQL query that the Secure Agent runs before reading data from the source.
Post-SQL
The SQL query that the Secure Agent runs after reading data from the source.
Fetch Size
Determines the number of rows to read in one result set from the PostgreSQL database.
Default is 100000.
Schema Name
Overrides the schema name of the source object.
Source Table Name
Overrides the default source table name.
SQL Override
The SQL statement to override the default query and the object name that is used to read data from the PostgreSQL source.
SAP BW
The following table lists the options that you can configure for a SAP BW source object:
Option
Description
Packet size in MB
Size of the HTTP packet that SAP sends to the Secure Agent. The unit is MB. Default is 10 MB.
Package size in ABAP in rows
Number of rows that are read and buffered in SAP at a time. Default is 1000 rows.
Enable Compression
When selected, the ABAP program compresses the data in the gzip format before it sends the data to the Secure Agent. If the Secure Agent and the SAP system are not on the same network, you might want to enable the compression option to optimize performance. Default is not selected.
SAP Table
The following table lists the options that you can configure for a SAP ERP and SAP S/4 HANA source object:
Option
Description
Number of rows to be fetched
The number of rows that are randomly retrieved from the SAP Table. Default value of zero retrieves all the rows in the table.
Number of rows to be skipped
The number of rows to be skipped.
Packet size in MB
Packet size. Default is 10 MB.
Data extraction mode
You can use one of the following modes to read data from an SAP Table:
- Normal Mode. Use this mode to read small volumes of data from an SAP Table.
- Bulk Mode. Use this mode to read large volumes of data from an SAP Table. Use bulk mode for better performance.
For more information about the data extraction mode, see the Data Extraction mode section in the Performance Tuning Guidelines for SAP Table Reader Connector How-To Library article.
Enable Compression
Enables compression.
If the Secure Agent and the SAP System are not located in the same network, you may want to enable the compression option to optimize performance.
Update Mode
When you read data from SAP tables, you can configure a mapping to perform delta extraction. You can use one of the following options based on the update mode that you want to use:
- 0- Full. Use this option when you want to extract all the records from an SAP table instead of reading only the changed data.
- 1- Delta initialization without transfer. Use this option when you do not want to extract any data but want to record the latest change number in the Informatica custom table /INFADI/TBLCHNGN for subsequent delta extractions.
- 2- Delta initialization with transfer. Use this option when you want to extract all the records from an SAP table to build an initial set of the data and subsequently run a delta update session to capture the changed data.
- 3- Delta update. Use this option when you want to read only the data that changed since the last data extraction.
- 4- Delta repeat. Use this option if you encountered errors in a previous delta update and want to repeat the delta update.
- Parameter. When you use this option, the Secure Agent uses the update mode value from a parameter file.
Default is 0- Full.
For more information about the update mode, see the Update modes for delta extraction section in the SAP connector help.
Parameter Name for Update Mode
The parameter name that you defined for update mode in the parameter file.
Override Table Name for Delta Extraction
Overrides the SAP table name with the SAP structure name from which you want to extract delta records that are captured with the structure name in the CDPOS table.
Profile Settings
You can choose a sampling option for the profile run. You can also choose whether to drill down on the profile results.
The following table lists the options that you can choose in the Profile Settings area:
Property
Description
Run profile on
Choose one of the following sampling options to run the profile:
- All rows. The profile runs on all the rows in the source object.
- First n rows. The profile runs on the first n number of rows in the source.
- Random sample n rows. The profile runs on the configured number of random rows.
Drilldown
Choose one of the following drill-down options:
- Choose On to drill down on the profile results to display specific data. In the profiling results, when you choose a data type, pattern, or value, Data Profiling displays the relevant data in the Data Preview area. If you choose this option, you can run queries on the source object after you run the profile.
- Choose Off to not drill down on the source object.
To drill down and to query the source object, you need Data Preview privileges in Data Profiling.
Note: You cannot perform drill down on the profile results or queries if you select the Avro or Parquet source object for Amazon S3 and Azure Data Lake Store connections.
The following table lists the connections and supported sampling options:
Connection
Sampling Option
Amazon Athena
All Rows
First N Rows
Amazon Redshift V2
All Rows
Random N Rows
Amazon S3 v2
All Rows
Azure Data Lake Store Gen2
All Rows
Databricks Delta
All Rows (Data Integration Server and advanced mode execution)
Sample N Rows (Data Integration Server execution)
Flat File
All Rows
Google Big Query v2
All Rows
Google Cloud Storage V2
All Rows
JDBC V2
All Rows
First N Rows
Mapplets
All Rows
Microsoft Azure Synapse SQL
All Rows
First N Rows
Random N Rows
Microsoft Fabric Data Warehouse
All Rows
First N Rows
ODBC
All Rows
First N Rows. For Postgres and IBM DB2 data sources over an ODBC connection.
Oracle
All Rows
First N Rows
PostgreSQL
All Rows
First N Rows
SAP BW Reader
All Rows
SAP Table
All Rows
To retrieve random number of rows from the data source, you can configure the Number of rows to be fetched option in the advanced options for the source connection.
SQL Server
All Rows
First N Rows
Salesforce
All Rows
First N Rows
Snowflake Data Cloud
All Rows
First N Rows
Random N Rows
To run a Databricks profile in advanced mode, ensure you can access an advanced cluster.
Columns
The Columns tab displays the columns that are supported by Data Profiling. You can select or clear the columns on the Columns tab. The profile runs on the selected columns to extract column statistics.
Data Profiling supports the following data types and column precision:
•Non-numeric data types. Supports columns with a precision from 0 through 4000.
By default, Data Profiling selects the columns with a precision from 0 through 150 on the Columns tab.
•Numeric data types. Supports columns with a precision from 0 through 38.
By default, Data Profiling selects the columns with a precision from 0 through 15 on the Columns tab.
Note: If you select columns with precision greater than 255 in the Columns tab, Data Profiling truncates the value frequency and calculates the statistics based on the first 255 characters on the Results page.
The following table lists the properties that you can view on the Columns tab:
Property
Description
Columns
The column names in the selected source object.
Type
The data type that appears in the transformations. They are internal data types based on ANSI SQL-92 generic data types, which the Secure Agent uses to move data across platforms. Transformation data types appear in all transformations in a mapping
Precision
The number of characters in a column.
Native Data Type
The data type specific to the source database or flat files.
Scale
The number of numeric characters after the decimal point.
Nullable
Indicates whether the column can accommodate a NULL value.
Key
Indicates whether the column has been designated as a primary key in the data source.
To sort the list of columns in ascending or descending order, click the column name or a property name. Use the Find field to search for columns.
When a column is added or deleted in the data source, the list of columns on the Columns tab gets updated when you edit the profile. The changes appear only if the runtime environment is up and running. When a column is added, the column appears on the Columns tab and is unmarked. You can choose the column for the next profile run. When a column is deleted, the deleted column does not appear on the Columns tab.
Example
You are a data steward user. You have created and run a profile called CustP on the Customer table. You want to modify the profile based on a business need to classify customers for a new rewards program. To accomplish this task, add the rule to the profile and select the columns in the profile that meet the business need.
To add the rules and select the relevant columns in the profile, perform the following steps:
1Modify the CustP profile.
2Choose the columns that meet the business need.
3In Data Quality, create a rule specification for the business need.
4In Data Profiling, add the rule specification to the profile.
5Run the profile.
6View the profile results to measure the quality of data.
7Export the results to a Microsoft Excel file for further analysis.
Override Column Metadata
You can edit the column metadata of delimited and fixed-width flat file, Azure Data Lake Store Gen2, and Amazon S3 v2 connections. Edit the column metadata of delimited files before you run a profile.
You can edit metadata if you want to change the data type, precision, or scale of the columns in the source object. For example, when you run a profile on a flat file connection that does not have an embedded schema, the profile results sometimes display inaccurate inferred data types. You might want to identify such columns and edit the metadata of the columns to change the data type, precision, or scale values.
You can edit the Native Data Types, Precision, and Scale properties of a column. When you edit metadata, you can change the precision and scale, if applicable for the data type.
To edit the column properties, select a column and click the property value, and then edit metadata based on your requirements. Alternatively, you might want to edit the column properties in bulk.
To edit the column properties in bulk, perform the following steps:
1Click Actions > Override Column Metadata.
The Override Column Metadata window appears.
2In the Define Metadata section, specify the following options:
- Native Data Type. Click the menu icon and select the data type.
- Precision. Enter a precision value. The precision must be greater than or equal to 1.
- Scale. Enter a scale value. Scale must be greater than or equal to 0. The scale of a number must be less than its precision.
3In the Columns to Override section, select the columns that you want to edit and click Apply.
Filters
You can use filters to select the values that a profile can read in a column of source data. You can create filters based on the simple and query filter types.
When you add a filter to a data column, the profile runs only on the data values that meet the filter criteria that you specify. You can add, delete, or update the filters in subsequent runs. After you add the filters, you can choose the filter that you want for the next profile run.
When you delete a column from the source object, any filter on the column is deleted from the profile during the profile run. When a filter applies to more than one column and you delete one of the columns, Data Profiling ignores the filter or filter condition that uses the deleted column during the profile run.
Creating Filters
You can create one or more filters in a profile. You can add a simple conditional or SQL filters to a profile.
Note: You can create filters on the partitioned fields for profiles that you create with Avro and Parquet source objects for Amazon S3 or Azure Data Lake Store connection.
1On the Filter tab, click Add ().
2In the New Filter dialog box, enter a name for the filter. Optionally, add a description for the filter.
3In the New Filter dialog box, create the following filter types:
- Simple. To enter a simple filter condition, click Add (). Choose a column and an operator, and enter a valid value. If required, continue to add more filter conditions.
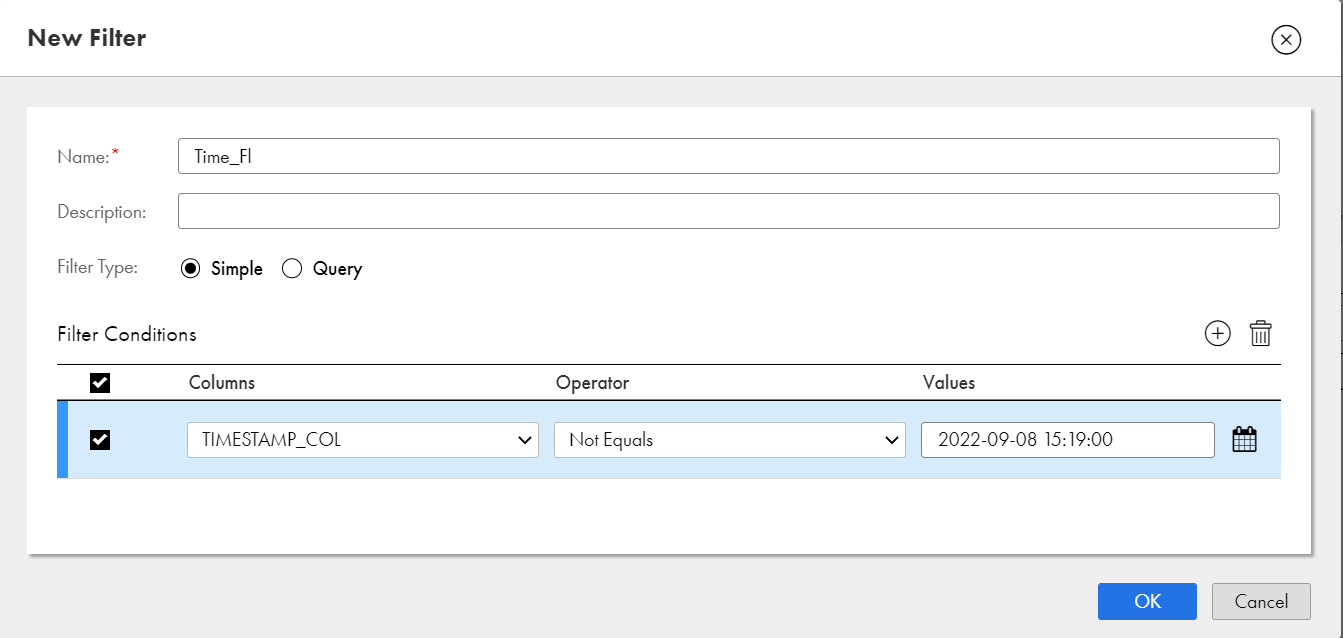
The following image shows a sample New Filter dialog box with a simple filter condition:
- Query. To add a SQL query as a filter, select Query from the filter type options, and then type in or paste an SQL query in the text box.
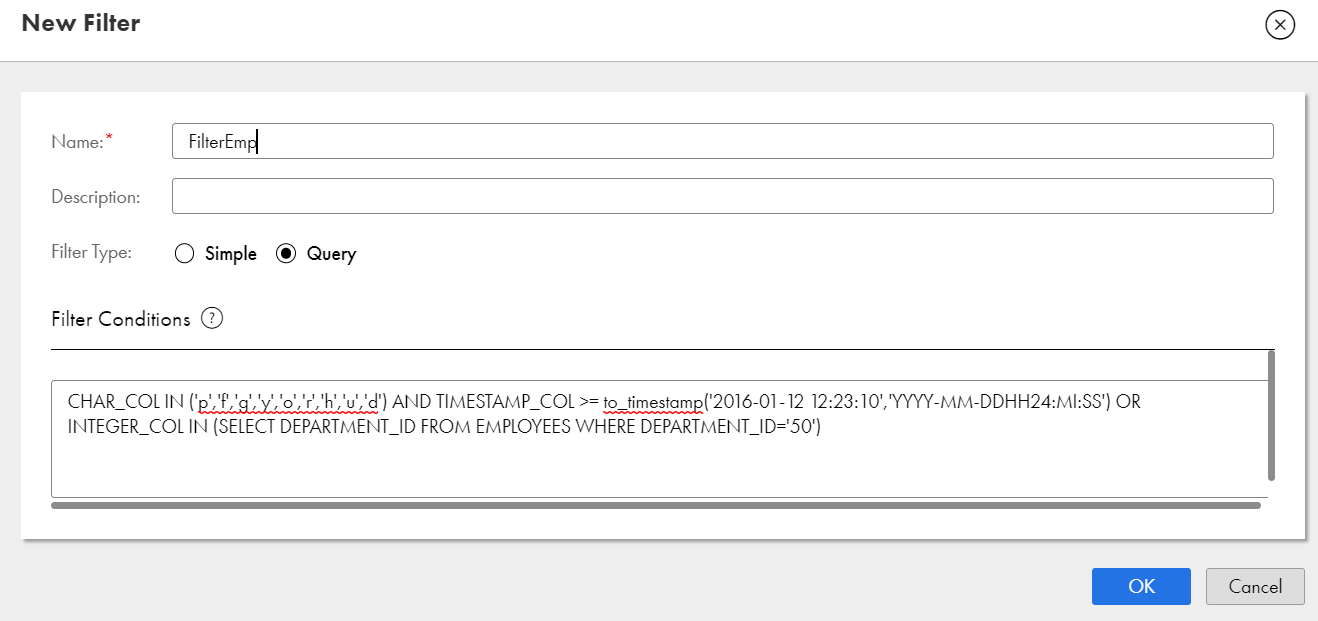
The following image shows a sample New Filter dialog box with a query filter:
4Click OK.
The filter appears on the Filter tab. Add multiple filters if required.
Adding a filter to the profile run
You can add one filter to the profile for a profile run. You can change the filter in subsequent runs. On the Filters tab, after you create one or more filters, the Use in Profile option is enabled and selected by default.
1Choose the required filter for the profile run.
2Click Save.
When you run the profile, the filter is applied to the source object and the profile runs on the filtered results.
Data preview
The Data Preview section displays the first 10 rows and all the columns in the source object. To view this section, you need the Data Integration - Data Preview role in Data Profiling.
The Data Preview section displays a checkmark for the selected columns if the column data type is supported by Data Profiling. The profile scope shows the number of rows that the profile runs on.
To preview data of columns that are profiled, select the Show only profiled columns option.
You cannot preview data of columns if you select Avro or Parquet source object for Amazon S3 and Azure Data Lake Store connections.
If you configure a profiling task to run in advanced mode, Data preview functionality is not available for Databricks sources.
If you run profiling tasks on an advanced cluster, data preview functionality is not available for the Databricks Delta connector.
 icon to copy the directory path for directory override in the Advanced Options for Azure Data Lake Store Gen2 and Amazon S3 V2 connections.
icon to copy the directory path for directory override in the Advanced Options for Azure Data Lake Store Gen2 and Amazon S3 V2 connections. ).
).