Creating a Hadoop Connection as a Source
To use Hadoop Connector in Data Synchronization task, you must create a connection in Informatica Cloud.
Perform the following steps to create a Hadoop connection in Informatica Cloud:
1. In Informatica Cloud home page, click Configure.
The Configure menu appears.
2. Select Connections.
The Connections page appears.
3. Click New to create a connection.
The New connection page appears.
4. Specify the values to the connection parameters. The following table describes the connection properties:
Connection Property | Description |
|---|
Username | The Username of schema of Hadoop component. |
Password | The password of schema of Hadoop component. |
JDBC Connection URL | The JDBC URL to connect to the Hadoop Component. Refer JDBC URL |
Driver | |
Commit Interval | The Batch size, in rows, to load data to hive. |
Hadoop Installation Path | The Installation path of the Hadoop component. Not applicable to a kerberos cluster. |
Hive Installation Path | Hive Installation Path Not applicable to a kerberos cluster. |
HDFS Installation Path | The HDFS Installation Path. Not applicable to a kerberos cluster. |
HBase Installation Path | The HBase Installation Path. Not applicable to a kerberos cluster. |
Impala Installation Path | The Impala Installation Path. Not applicable to a kerberos cluster. |
Miscellaneous Library Path | The library that communicates with Hadoop. Not applicable to a kerberos cluster. |
Enable Logging | Enable logging enables the log messages. |
Hadoop Distribution | The Hadoop distributions for which you can use Kerberos Authentication. You can use Kerberos authentication for the Cloudera and HDP Hadoop distributions. |
Authentication Type | You can select native or Kerberos authentication. |
Key Tab File | The file that contains encrypted keys and Kerberos principals to authenticate the machine. |
Hive Site XML | The directory where the core-site.xml, hive-site.xml and hdfs-site.xml are located. The three XML files must locate in the same location. |
Superuser Principle Name | Users assigned to the superuser privilege can perform all the tasks that a user with the administrator privilege can perform. |
Impersonation Username | You can enable different users to run mappings in a Hadoop cluster that uses Kerberos authentication or connect to sources and targets that use Kerberos authentication. To enable different users to run mappings or connect to big data sources and targets, you must configure user impersonation. |
Note: Installation paths are the paths where you place the Hadoop jar. Hadoop Connector loads the libraries from installation paths before it sends instructions to Hadoop. When you use Kerberos Authentication type, you need not specify the Hadoop installation path, Hive installation path, HDFS installation path, HBase Installation path, Impala installation path, and Miscellaneous Library path.
If you do not use Kerberos Authentication and do not mention the installation path, you can set the Hadoop classpath for Amazon EMR, HortonWorks, MapR and Cloudera.
5. Click Test to evaluate the connection.
6. Click OK to save the connection.
JDBC URL
The connector connects to different components of Hadoop with JDBC. The URL format and parameters differ from components to components.
The Hive uses following JDBC URL format:
jdbc:<hive/hive2>://<server>:<port>/<schema>
The significance of URL parameters is discussed below:
- •hive/hive2 : Contains the protocol information. The version of the Thrift Server, that is, hive for HiveServer and hive2 for HiveServer2.
- •Server, port – server and port information of the Thrift Server.
- •Schema – The hive schema which the connector needs to access.
For example, jdbc:hive2://invrlx63iso7:10000/default connects the default schema of Hive, uses a Hive Thrift server HiveServer2 that starts on the server invrlx63iso7 on port 10000.
Hadoop Connecter uses the Hive thrift server to communicate with Hive.
The command to start the Thrift server is –hive –service hiveserver2.
Cloudera Impala uses the JDBC URL in the following format:
jdbc:hive2://<server>:<port>/;auth=<auth mechanism>
JDBC Driver Class
The JDBC Driver class varies among Hadoop components. For example, org.apache.hive.jdbc.HiveDriver for Hive and Impala.
Setting Hadoop Classpath for non-Kerberos Clusters
For non-Kerberos Hadoop clusters, if you do not mention the installation paths in connection properties, you can still perform the connection operations by setting the class path. You must simply set the classpath for the respective distributions.
This section helps you to set the classpath for Amazon EMR, HortonWorks, Pivotal, and MapR.
Setting Hadoop Classpath for Amazon EMR, HortonWorks, Pivotal, and MapR
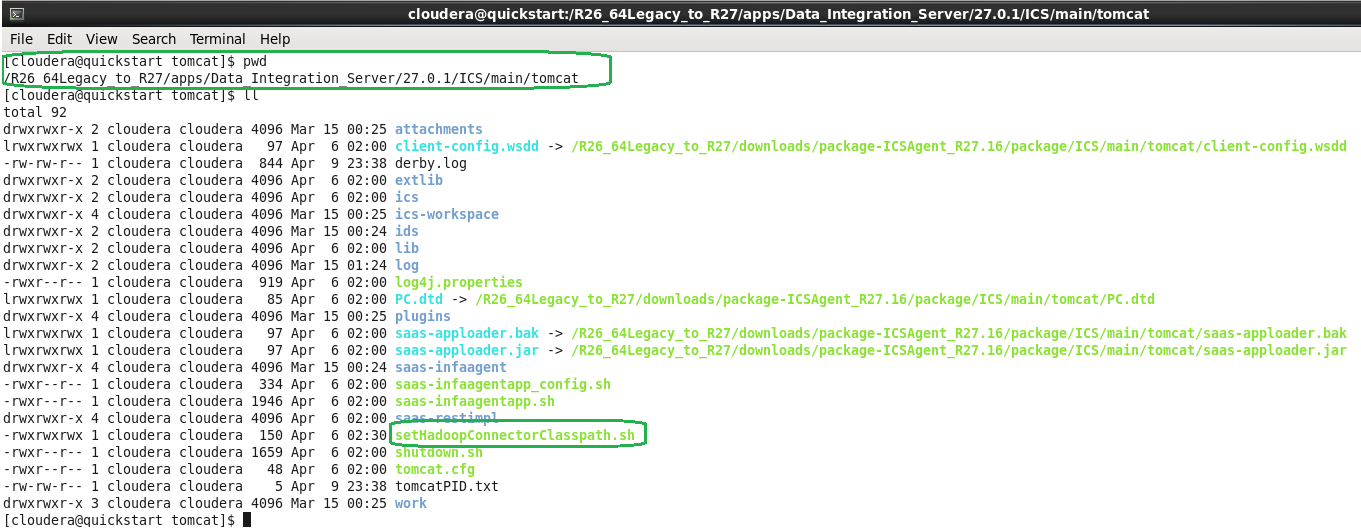
Perform the following steps to generate the setHadoopConnectorClasspath.sh for Amazon, Horton works, Pivotal, and MapR.
1. Use the command displayed in the following image to start the Secure Agent:
2. Create the Hadoop connection using the connector.
3. Test the connection. This generates the setHadoopConnectorClasspath.sh file in <Secure Agent installation directory>/apps/Data_Integration_Server/<latest DIS version>/ICS/main/tomcat path.
4. Stop the Secure Agent.
5. From <Secure Agent installation directory>, execute the . ./main/tomcat/setHadoopConnectorClasspath.sh command.
6. Start the Secure Agent and execute the Data Synchronization tasks:
Note: If you want to generate the setHadoopConnectorClasspath.sh file again, then delete the existing classpath and regenerate.
In certain cases the Hadoop classpath may point to the incorrect classpath. In this case, you must direct the Hadoop classpath to the correct classpath.
- a. Enter the command hadoop classpath from the terminal to display the stream of jars.
- b. Copy the stream of jars in a notepad.
- c. If the following entries are present in the notepad file, delete them:
- ▪ :/opt/mapr/hadoop/hadoop-0.20.2/bin/../hadoop*core*.jar
- ▪ :/opt/mapr/hadoop/hadoop-0.20.2/bin/../lib/commons-logging-api-1.0.4.jar (retain the latest version and delete the previous)
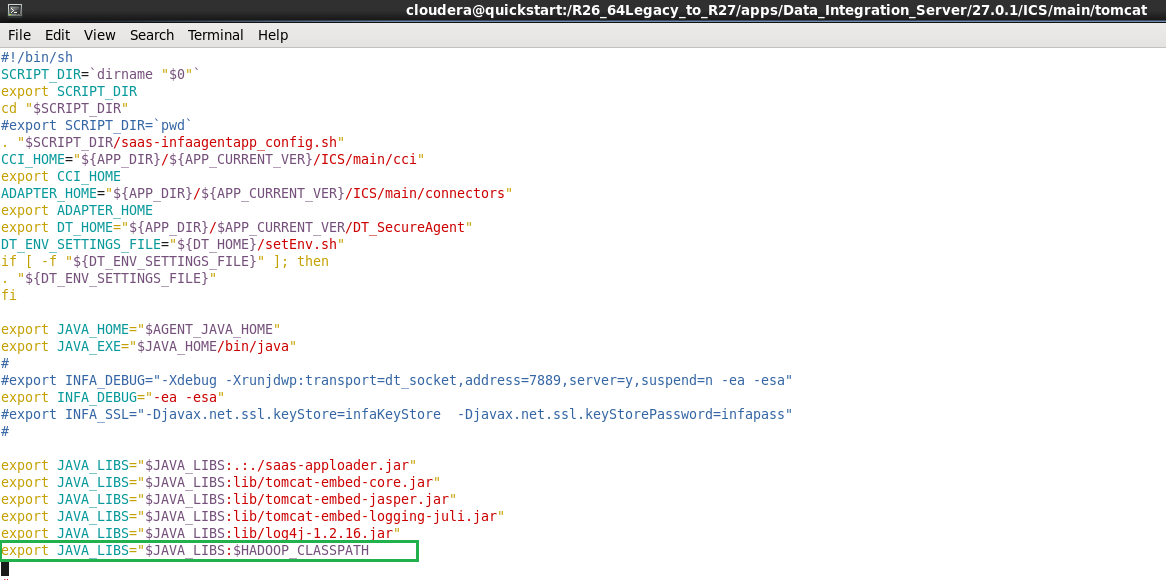
- d. Copy the remaining content and export it to a variable called HADOOP_CLASSPATH.
- e. In saas-infaagentapp.sh file make the following entry:
- f. Restart the Secure Agent.