Export functions
Why do I need export functions? How do export functions work? How can I implement my own export function? ...
Why do I need export functions?
Export functions allow you to format or evaluate the data to be output. Numerous special functions are available to create specific output formats. General formatting functions are used to convert dates and numbers into the desired format or edit character strings.
Export functions allow you to
format the output data: numbers, dates, strings
do simple comparisons for conditional output: "translate" special values into output value, e.g. "true" --> "x", "false" --> "-"
create special output content
create XML tags from a list of values
create valid JSON content
encode string content according to the encoding defined for the output file
Export functions vs. data field validations
You can use export functions to control whether certain data records are output or not.
However, you should consider using data field validations. The advantage is that data is already checked and records are removed when reading the data. This could offer a considerable performance advantage. In addition, the logged information is more convenient because the number of affected objects is logged in the export protocoll, and the objects can be viewed later.
However, the data field validations can only be configured globally in the export template. It is not possible to define a module-specific validation for a data field.
How do export functions work?
Error logging
For each export function execution the result is returned, or an exception is thrown. The function result replaces the current function token text. If the function throws an exception, the function token text is replaced with an empty string, and an error respectively a warning is logged to the export protocol.
In addition to that, you can configure if errors or warnings should be written into the export file. This may be useful during the implementation of an export template or if you want to analyze a problem.
Processing sequence for export functions
You need to know how export functions are executed to understand how you can use it the right way.
Each export function is executed during an export. The only exception is a function call within a comment "{!...}". The innermost function is exceuted first.
Example:
{?Function1 {?Function2 {?Function3 "value1"}, "value2"}, {?Function4 {?Function5 "value3"}, "value4"} }The innermost functions are {?Function3 "value1"} and {?Function5 "value3"}. The processing sequence is the following:
{?Function3 "value1"} --> Result1
{?Function2
{?Function3 "value1"}Result1, "value2"} --> Result2{?Function5 "value3"} --> Result3
{?Function4
{?Function5 "value3"}Result3, "value4"} --> Result4{?Function1
{?Function2 Result1, "value2"}Result2,{?Function4 Result3, "value4"}Result4 } --> Result5
Conditional function call
A conditional export function call is not possible. Each export function is called during an export.
But if you arrange the nesting the right way, you'll get the correct result. Make sure each function is called with the correct parameter value.
Example: count all items with an "X" in the identifier
Why doesn't this export template work?
{?CompareNumeric "-1", {?StringLastIndexOfIgnoreCase {&Item.Item no.}, "x"}, {?NumberIncrement "noX"}, {?NumberIncrement "containsX"},}NumberIncrement functions are called for each row, that means noX and containsX variables don't count the rows with "X" and without "X" but each row.
Let's process two rows. First row's item no. is "ABC", second row's item no is "XYZ".
Processing first row:
{&Item.Item no.} --> ABC
{?StringLastIndexOfIgnoreCase "ABC", "x"} --> -1{?NumberIncrement "noX"} --> (no output)
{?NumberIncrement "containsX"} --> (no output)
{?CompareNumeric "-1", -1, , ,}
Processing second row:
{&Item.Item no.} --> XYZ{?StringLastIndexOfIgnoreCase "XYZ", "x"} --> 0{?NumberIncrement "noX"} --> (no output)
{?NumberIncrement "containsX"} --> (no output)
{?CompareNumeric "-1", 0, , ,}
The (wrong) result is:
noX = 2
containsX = 2
This export template works:
{?ValueSet "noX_increment", {?CompareNumeric "-1", {?StringLastIndexOfIgnoreCase {&Item.Item no.}, "x"},1,0,0}}{?ValueSet "containsX_increment", {?CompareNumeric "-1", {?StringLastIndexOfIgnoreCase {&Item.Item no.}, "x"},0,1,0}}{?NumberIncrement "noX",{?ValueGet "noX_increment"}}{?NumberIncrement "containsX",{?ValueGet "containsX_increment"}}In line 1 the noX_increment variable is set to 1 or 0 if there's a X or not, same is done in line 2 for containsX_increment variable. The NumberIncrement function is called in line 3 for both variables. At this position, both variable values contain the correct value.
Let's process the two rows again:
Processing first row:
line 1:
{&Item.Item no.} --> ABC
{?StringLastIndexOfIgnoreCase ABC, "x"} --> -1
{?CompareNumeric "-1", -1, 1, 0, 0} --> 1
{?ValueSet "noX_increment", 1}
line 2:
{&Item.Item no.} --> ABC
{?StringLastIndexOfIgnoreCase ABC, "x"} --> -1
{?CompareNumeric "-1", -1, 0, 1, 0} --> 0
{?ValueSet "containsX_increment", 0}
line 3:
{?ValueGet "noX_increment"} --> 1
{?NumberIncrement "noX", 1}
{?ValueGet "containsX_increment"} --> 0
{?NumberIncrement "containsX", 0}
Processing second row:
line 1:
{&Item.Item no.} --> XYZ
{?StringLastIndexOfIgnoreCase XYZ, "x"} --> 0
{?CompareNumeric "-1", 0, 1, 0, 0} --> 0
{?ValueSet "noX_increment", 0}
line 2:
{&Item.Item no.} --> XYZ
{?StringLastIndexOfIgnoreCase XYZ, "x"} --> 0
{?CompareNumeric "-1", 0, 0, 1, 0} --> 1
{?ValueSet "containsX_increment", 1}
line 3:
{?ValueGet "noX_increment"} --> 0
{?NumberIncrement "noX", 0}
{?ValueGet "containsX_increment"} --> 1
{?NumberIncrement "containsX", 1}
The (correct) result is:
noX = 1
containsX = 1
Export functions and masking
When creating output files you always have to pay attention to which characters are allowed and which are not. Not allowed characters must be masked to get a valid file.
Usually the outermost function takes care of masking such characters. Whether masking is done and which characters are masked depends on the type of the output file. But sometimes this masking should be suppressed, so there are some special export functions.
The outermost function handles masking
The following simple example shows this.
The export template
In the export template a string variable has been defined which got the value <xml attribute> and "quoted" value
The main module of the template has the content
{?UpperCase {%StringValue}}The output depends on the file format you specify.
Output to a text file
There are no characters that are not allowed for text files, we expect the output to be just the variable value in capital letters:
<XML ATTRIBUTE> AND "QUOTED" VALUE
Output to a xml file
Certain characters are not allowed as content in xml files as they are used as control characters, they have to be masked. That's why the output to a xml file differs:
<XML ATTRIBUTE> AND "QUOTED" VALUE
Output to a json file
Json files don't allow double quotes, they have to be masked by a backslash, the content of the json file is the following:
<XML ATTRIBUTE> AND \"QUOTED\" VALUE
Desired exceptions
Sometimes you have to use control characters as part of function parameters to create the output you need. In this cases you must prevent those characters from being masked.
In the following example we want to create an xml tag only if we have content for that.
The most obvious way is just to use an export function that creates an output if a condition is fulfilled, here the condition is "the data field value is not empty" and we can use the IfNotEmptyThen function.
{?IfNotEmptyThen {&Item.Short description}, {?Concat "<name>", {&Item.Short description}, "</name>"}}But we don't get the output we've expected, the angle brackets ("<", ">") are masked too.
We have two ways to solve that problem.
Common functions that don't mask
There is another export function doing almost the same as the "IfNotEmptyThen" function - except of masking the return value. It is "IfNotEmptyThenNotEnc". The usage of that function creates the output we want.
{?IfNotEmptyThenNotEnc {&Item.Short description}, {?Concat "<name>", {&Item.Short description}, "</name>"}}Besides IfNotEmptyThenNotEnc we have the IfEmptyThenNotEnc export function that prevent the whole return value from being masked, but you should be careful using it.
Format-specific functions
The better way is to use special, output format-specific functions that handle masking issues in a more reliable way. We have a number of functions for generating XML and JSON files.
The best way to generate an xml tag only if it will not be empty is the following:
{?CreateXMLTagWithValue {&Item.Short description}, "<name>?</name>"}Valid function calls or how to prevent the output of unwanted quotes
Export functions in parallel context
In a parallel scenario there are two potential problems you have to be aware of when you write an export template.
Different Data Context
When an export is started, the data to be processed is split into packages. In standard configuration, each package contains 25.000 items to be exported. When enabling parallel processing, multiple packages will be processed simultaneously. For more information about this topic, see: Parallel Export. In case of such an parallel export, the scope of some export functions is limited by the packages that are being processed. We differentiate between two contexts during such exports.
Global Export Context
The global export context contains data about all information available during the whole export itself.
This is general read-only data like the error classification configuration for export functions or the encoding used for the current export module.
In addition to that, some export functions (ValueGet and ValueSet as well as NumberSet, NumberIncrement and NumberGet) use that context to store data. This may be memory heavy as it is only being cleared once the export has finished. Keep in mind that data inside this context may lead to inconsistent states when packages are processed in parallel. For this reason we advise that you replace functions such as ValueGet and ValueSet by their newly introduced counterparts ValueGetLocal and ValueSetLocal when processing data in parallel.
Local Export Context
The local export context contains data that is only available in the currently processed main data record. This will require less memory than the global export context, as each local context will be cleared after the main data record itself has been processed. In addition to the lower memory consumption, the advantage of the local context is that there is no parallel access.
For this reason we introduced two other export functions: ValueGetLocal and ValueSetLocal. These two functions only cater to data which is being exported in their currently processed main data record and will reset created data in memory as soon as the currently processed main data record has finished.
We recommend the usage of ValueGetLocal and ValueSetLocal whenever possible and advise you to use ValueGet and ValueSet only if data is cross-module when exporting data in parallel.
Memory consumption
In a sequential export one data set is executed at a time. In a parallel export, not one but multiple items are processed at the same time.
Additional data that consumes memory can be created by using the functions ValueGet/ValueGetLocal and ValueSet/ValueSetLocal. All data that is written, exists until it is overwritten, cleared or until the export is finished.
The chosen key is important here.
Example:
ValueSet "{&Item.Item no.}{&Language-specific data.Language}" <someValue> A1german
A1english
A1french
A2german
A2english
A2french
A3german
A3english
A3french
A4german
A4english
A4french
ValueSet "{&Language-specific data.Language}" <someValue> german
english
french
Some standard export functions
ValueGet/ValueSet, ValueGetLocal/ValueSetLocal
If you need some logic to store certain data and read it again later, you can use these functions.
{?ValueSet "MyDate", "2019-12-06"}...{?ValueGet "MyDate"} -> Output: 2019-12-06OR{?ValueSetLocal "MyDate", "2019-12-06"}...{?ValueGetLocal "MyDate"} -> Output: 2019-12-06The ValueGet and ValueSet functions use the global export function context. This ensures that all parallel processed packages can access that data.
But you have to make sure that the names under which you want to store data are unique and that the values are not overwritten by others.
If you only want to collect data of sub-modules within one main module, you should use the ValueSetLocal/ValueGetLocal export functions.
Example
Data
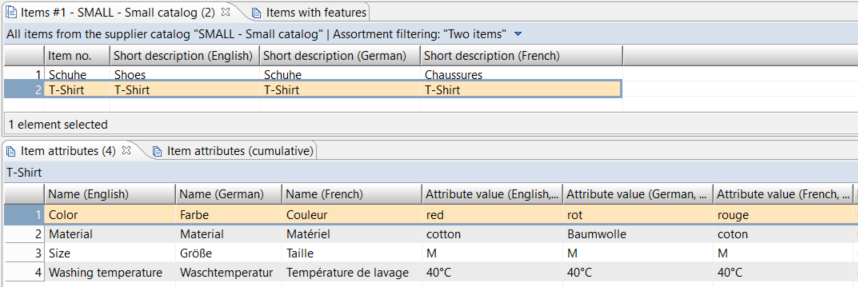
You have some items with short descriptions and attributes:
Output format
You want to export a XML file containing the item no. and a text built from short description and the attributes with their values for each item:

Data source
The export template must use a data source for items. In the corresponding main module we can output the item no. The short descriptions can be retrieved in a sub-module for "Language-specific data", the attributes are available under "Attribute values".
Language-specific data and attributes
Now we have to somehow get the short descriptions and attributes together. We'll do it by collecting and storing the attributes and their values grouped by their languages, and then - during writing the short descriptions - read them language by language.
When we collect the attributes, we have to consider that there can be multiple records per language. That means we have to append each attribute name and value to the existing data. The key under which we'll store the attribute data is the language.
If we use the language name as the key to store the data with ValueSet, we may get inconsistent data during parallel export since multiple items will be processed simultaneously. That's why we should use the ValueSetLocal function.
{?ValueSetLocal {&Attribute values.Language}, {?Concat {?ValueGetLocal {&Attribute values.Language}}, ", ", {&Attribute values.Name}, ": ", {&Attribute values.Attribute value}}The data we collect in this way looks like this for the item "T-Shirt":
English = , Color: redEnglish = , Color: red, Material: cottonEnglish = , Color: red, Material: cotton, Size: MEnglish = , Color: red, Material: cotton, Size: M, Washing temperature: 40°CGerman = , Farbe: rot...German = , Farbe: rot, Material: Baumwolle, Größe: M, Waschtemperatur: 40°C...When the language-specific data is processed, we read the stored attribute data by the language of the current record:
{&Language-specific data.Short description}{?ValueGetLocal {&Language-specific data.Language}}Language code
We can output the value of the "Language" data field of both sub-modules. But we rather want some kind of code for the languages. That's why we store the language codes we want to use at the beginning of our export template.
{?ValueSet "lang", "7", "de"}{?ValueSet "lang", "9", "en"}{?ValueSet "lang", "12", "fr"}In the "Language-specific data" module we "translate" the language into out code:
<text lang="{?ValueGet "lang", {?EnumerationKey {&Language-specific data.Language}}}">The whole solution
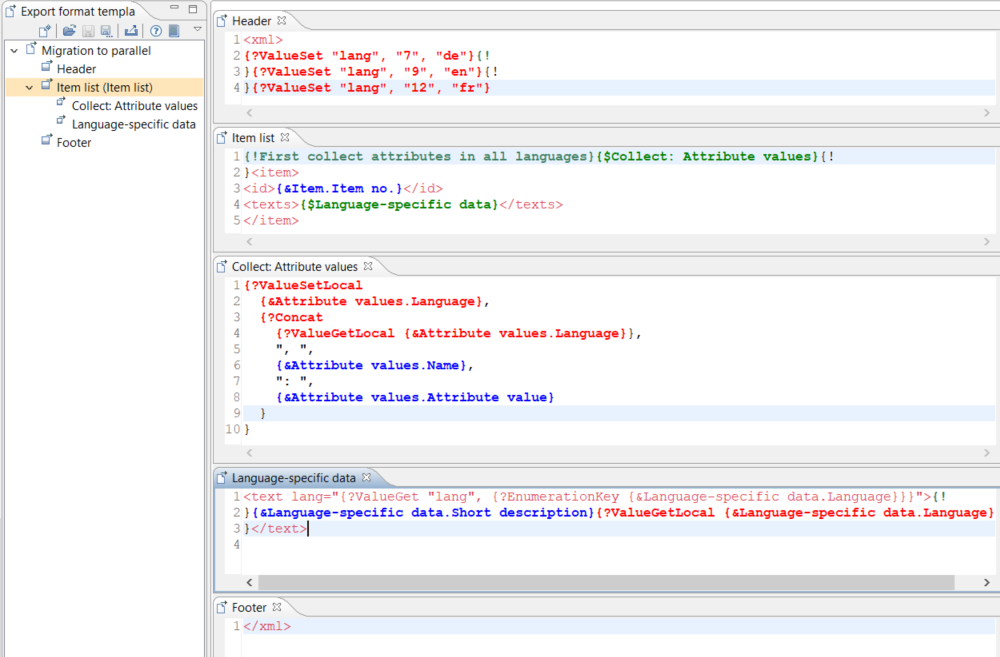
Summary
We use ValueSet to global provide a list of language codes we need for each item text. These are only some values and don't need much memory.
We use ValueSetLocal to store the attribute names and values by their languages. That function uses the local function context which means that for each new item the old context is deleted and a new one is created which fits exactly to our needs and prevents the memory from being filled with too much data..
NumberGet/NumberSet/NumberIncrement
Similar to ValueSet and ValueGet, you can use NumberSet and NumberGet to store and read a number by a certain name. Additionally, you can increment a number using NumberIncrement.
{?NumberSet "MyNumber", 37}{?NumberIncrement "MyNumber"} -> MyNumber = 38{?NumberIncrement "MyNumber"} -> MyNumber = 39{?NumberIncrement "MyNumber", 3} -> MyNumber = 42{?NumberGet "MyNumber"} -> Output: 42These functions use the global export function context. This ensures unique numbers when incrementing.
But due to parallel processing, you could get another number with NumberGet than you've just set by NumberIncrement within a module because that number could have just been changed by another - parallel - export package. That means, the counting with NumberIncrement works in parallel mode, but it is not possible with certainty to get the current number within a module that is processed in parallel mode.
What does work is to set a number in a first module, increment that number in a second module in parallel mode, and read the number in a third module.
LoopCounter/DatasetCounter
Both functions return the consecutive number of the current data record within an export module or sub-module where LoopCounter starts at 0 and DatasetCounter at 1.
Important for parallel export mode is that if data rows are removed by data field validation, there may be gaps in the numbering. If you need consecutive numbering without gaps, you cannot use parallel mode for that export.
The reason for that is, that each package gets its own range for data set counters.
Example:
You have 20 items in two packages of ten each. The first package will use 0 - 9 or 1 - 10, the second package 10 - 19 or 11 - 20. If an item of the first package is removed, there will be a gap; the last number reserved for the first package is not used.
Format-specific functions: XML
There are some functions to create xml tags:
CreateXMLTagWithValue
CreateXMLTagWithContent
CreateCDataSection
Format-specific functions: JSON
If you want to create JSON files you can use the following functions:
JSONArray
JSONObject
JSONObjectElement
JSONStringElement
JSONStringValue
How to implement a custom export function
Rules
no data access within export functions (performance problems: export functions are executed for each exported entry)
implementation in a core plugin --> install on server and client
function instances will be reused, that's why functions have to be stateless, i.e. parameter values must not be stored in class variables
Extension point
Export functions have to be contributed at the com.heiler.ppm.script.core.functionClass extension point:
<plug-in> <extension point="com.heiler.ppm.script.core.functionClass"> <functionClass class="com.heiler.ppm.custom.export.core.function.MyExportFunction " name="MyExportFunction"> </functionClass> </extension></plug-in>This extension point can be contributed for different standard contexts: "export", "general", "editablePreview" and "fileName"
The context is used in the standard functions implementation to enable functions for a specific context.
"general": It's the default context of functions if nothing else is set. All functions with this context are generally available in export template module's content
"export" : Actually it's identical to the "general" context
"editablePreview": Functions with this context mark a preview export template as making the preview editable
"fileName": Functions with this context are available for export file name definition
Interface
A custom export function should be a subclass of com.heiler.ppm.script.core.FunctionBaseImpl. That base implementation contains some default implementations already.
public class MyExportFunction extends FunctionBaseImpl{ public MyExportFunction() { super( "MyExportFunction", "The description of my export function", null ); } @Override public int getMinParameterCount() { return 0; } @Override public int getMaxParameterCount() { return 0; } @Override public Object execute( Object[] parameters, Map context ) throws CoreException { String result = StringUtils.EMPTY; // 1. check parameters // 2. business logic // 3. return the result return result; }}Function name
The name of an export function must be unique, it's the identifier the export function is registered at the function manager.
You should also provide a useful description for the export function.
Parameter count
There're two functions that provide information about the parameter count the function expects. That information is used in the GUI to generate appropriate error messages to the user.
Execute method
The execute method implements the busines logic. The parameters array contains strings which may be empty. The result must be a string too.
If any error occurs, or if the parameter values are not valid the method should throw a CoreException that contains a useful description and an error code. Warnings and errors will be logged to the export protocol according to the log configuration, exceptions with OK severity won't be logged.
Parameter values or temporary computed values must not be stored in class variables but passed to other methods as parameter if necessary. In contrast to export data providers or export post steps, export functions must be stateless.
Example
This is a simple example of an export function that provides the functionality of org.apache.commons.lang.StringUtils.substring(String str, int start) and org.apache.commons.lang.StringUtils.substring(String str, int start, int end).
It expects two or three parameters. A CoreException is thrown if too less (< 2) or too many (> 3) parameters are passed or if the second or third parameter is invalid.
This function returns a substring of the string given with the first parameter, according to the second and third parameter values.
/** * Gives back a sequence of chars from a starting to an end position of a string. * <li><b>param1:</b> mandatory, the string to get the substring from</li> * <li><b>param2:</b> mandatory, start position (int)</li> * <li><b>param3:</b> optional, end position (int)</li> */public class FunctionStringSubstringExample extends FunctionBaseImpl{ /** The minimum count of parameters - count of mandatory parameters */ private static final int MIN_PARAM_COUNT = 2; /** The maximum count of parameters - count of all parameters */ private static final int MAX_PARAM_COUNT = 3; public FunctionStringSubstringExample() { super( "SubstringExample", Messages.getString( "FunctionStringSubstringExample.Description" ), null ); //$NON-NLS-1$ //$NON-NLS-2$ } @Override public int getMinParameterCount() { return MIN_PARAM_COUNT; } @Override public int getMaxParameterCount() { return MAX_PARAM_COUNT; } /** * Gives back a sequence of chars from a starting to an end position of a string * @param parameters [ String to get the substring from, starting position, end position ] * @throws CoreException */ @Override public Object execute( Object[] parameters, Map context ) throws CoreException { if ( parameters != null && parameters.length <= MAX_PARAM_COUNT && parameters.length >= MIN_PARAM_COUNT ) { String result = StringUtils.EMPTY; String text = ( String ) parameters[ 0 ]; String startString = ( String ) parameters[ 1 ]; int start = NumberUtil.getInt( startString ); if ( parameters.length == MAX_PARAM_COUNT ) { String endString = ( String ) parameters[ 2 ]; int end = NumberUtil.getInt( endString ); result = StringUtils.substring( text, start, end ); } else { result = StringUtils.substring( text, start ); } return result; } String message = Messages.getString( "function.error.wrongparams" ); //$NON-NLS-1$ message = StringUtils.replace( message, "{functionname}", getName() ); //$NON-NLS-1$ CoreException exception = ErrorUtil.createError( message, ErrorCodes.ERR_FUNCTION__WRONG_PARAM_COUNT, null ); throw exception; }}Enhancements: error level configuration (since PIM 7.1.02.00)
Export functions are usually called for every exported data set. That's why you may get many errors if some data fields are empty. If you don't want this cases to be handled as errors you can enable your function to provide an error level configuration.
The function provides the list of error cases
public class FunctionStringSubstringExample extends FunctionBaseImpl{ // ... private static int ERROR_EMPTY_TEXT = 4200; private static int ERROR_EMPTY_START = 4201; private static int ERROR_EMPTY_END = 4202; // ... @Override public FunctionStatus[] getFunctionStatuses() { FunctionStatus[] result = new FunctionStatus[3]; // 1. parameter #1 is empty result[ 0 ] = new FunctionStatusBuilder( "Empty text", ERROR_EMPTY_TEXT, Severities.WARNING ).build(); // 2. start position parameter is empty result[ 1 ] = new FunctionStatusBuilder( "Empty start position", ERROR_EMPTY_START, Severities.WARNING ).build(); // 3. end position parameter is given but empty result[ 2 ] = new FunctionStatusBuilder( "Empty end position", ERROR_EMPTY_END, Severities.WARNING ).build(); return result; } // ...}Such error cases will be displayed in the GUI and can be configured there:
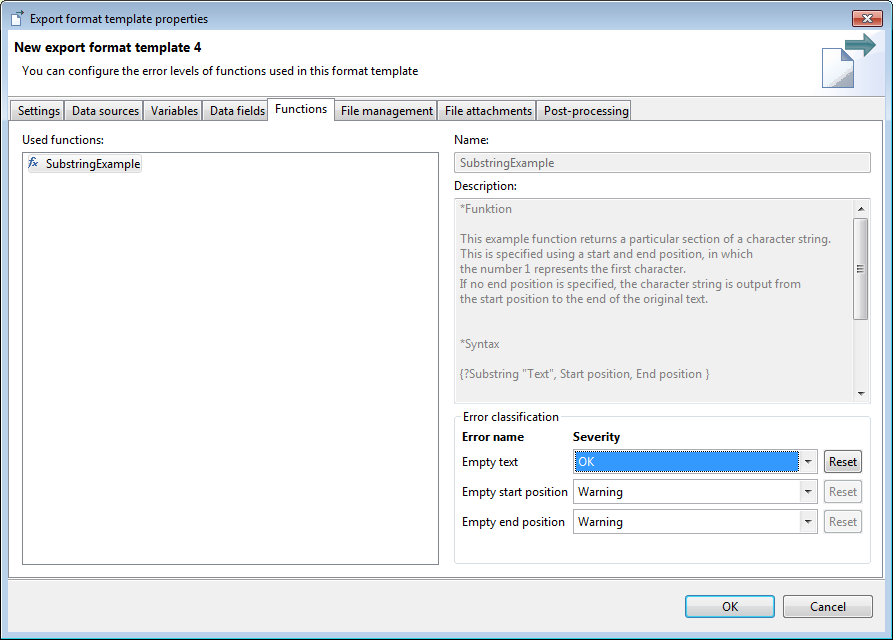
Error cases are handled according to the given error level configuration
public class FunctionStringSubstringExample extends FunctionBaseImpl{ // ... private static int ERROR_EMPTY_TEXT = 4200; private static int ERROR_EMPTY_START = 4201; private static int ERROR_EMPTY_END = 4202; // ... @Override public Object execute( Object[] parameters, Map context ) throws CoreException { if ( parameters != null && parameters.length <= MAX_PARAM_COUNT && parameters.length >= MIN_PARAM_COUNT ) { // get current error level configuration Map< FunctionLogSeverityKey, Severities > functionSeverityLogLevels = FunctionStatusLogUtil.getFunctionLogConfig( context ); String result = StringUtils.EMPTY; String text = ( String ) parameters[ 0 ]; // check error case #1: is given text empty? checkIfEmpty( text, ERROR_EMPTY_TEXT, "Empty text parameter given", functionSeverityLogLevels ); String startString = ( String ) parameters[ 1 ]; // check error case #2: is given start position empty? checkIfEmpty( startString, ERROR_EMPTY_START, "Empty start parameter given", functionSeverityLogLevels ); int start = NumberUtil.getInt( startString ); if ( parameters.length == MAX_PARAM_COUNT ) { String endString = ( String ) parameters[ 2 ]; // check error case #3: is given end position empty? checkIfEmpty( endString, ERROR_EMPTY_END, "Empty end parameter given", functionSeverityLogLevels ); int end = NumberUtil.getInt( endString ); result = StringUtils.substring( text, start, end ); } else { result = StringUtils.substring( text, start ); } return result; } String message = Messages.getString( "function.error.wrongparams" ); //$NON-NLS-1$ message = StringUtils.replace( message, "{functionname}", getName() ); //$NON-NLS-1$ CoreException exception = ErrorUtil.createError( message, ErrorCodes.ERR_FUNCTION__WRONG_PARAM_COUNT, null ); throw exception; } private void checkIfEmpty( String text, int errorCode, String errorMessage, Map< FunctionLogSeverityKey, Severities > functionSeverityLogLevels ) throws CoreException { if ( StringUtils.isEmpty( text ) ) { // get configured severity for the current error code Severities severity = FunctionStatusLogUtil.getSeverity( getName(), errorCode, functionSeverityLogLevels, Severities.WARNING ); CoreException coreException = ErrorUtil.createException( Categories.RANGE, severity, errorCode, errorMessage, null ); throw coreException; } }}The new function is used in an export template:
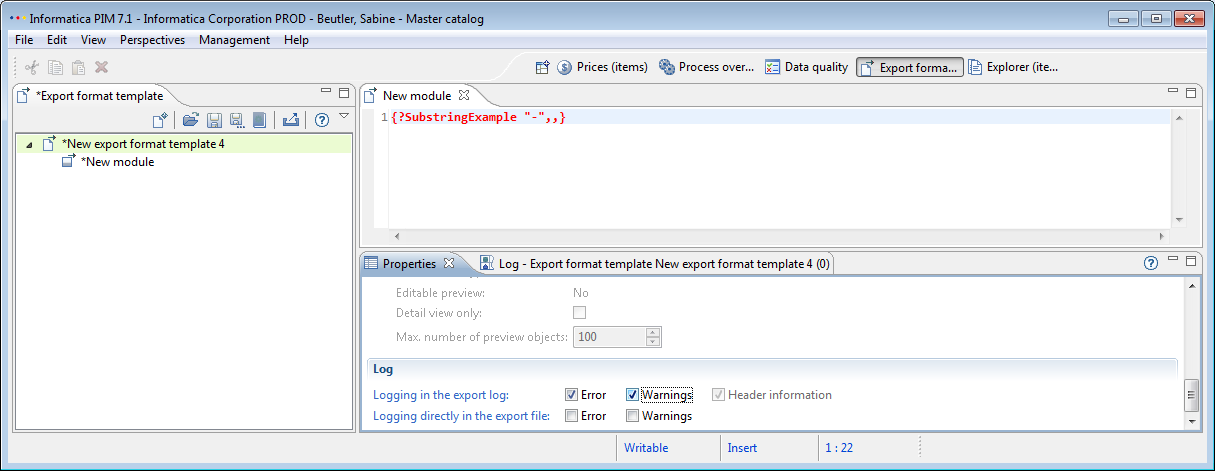
The export protocol contains a warning:
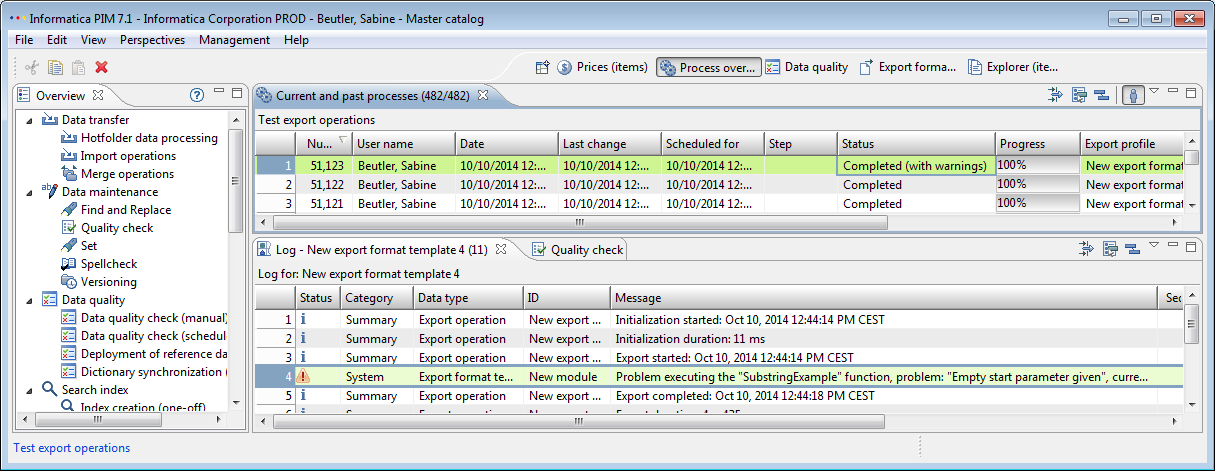
Export file name functions
One of the basic problems was that files which are recurring created by the export get overwritten, because they had the same file name. More flexibility to define the pattern and add additional information is possible by using functions in the file configuration. Therefore you can use a defined set of functions to configure your output file name. The replacement of those variables and functions will be done at the start of the export, invalid characters will be changed to underscore.
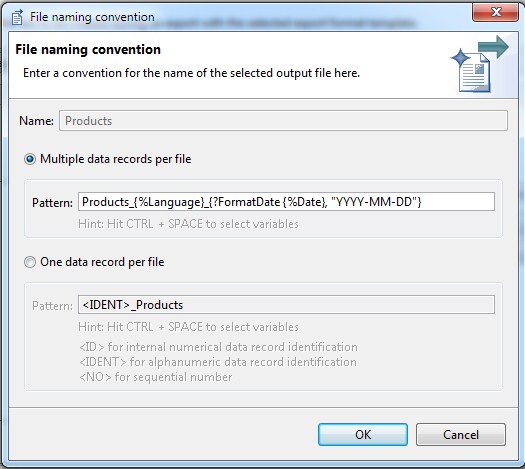
The output file name for the defined export template on the screenshot could be for example: Products_English_2015-06-17.csv
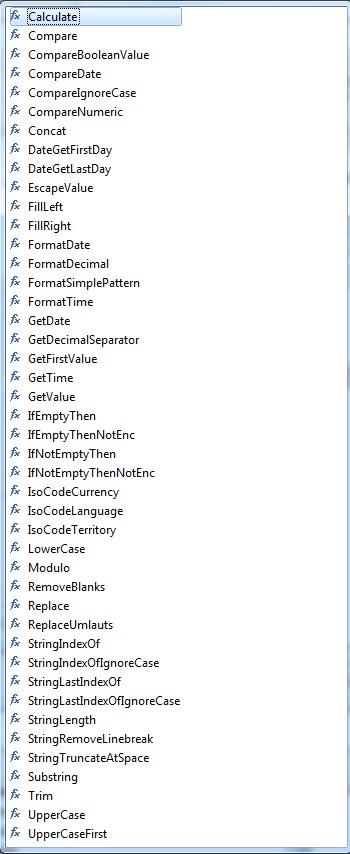
Provided "fileName" export functions:
Further information
A new file name is not saveable if a variable or function isn't available during configuration
Invalid characters which are not allowed in the file name will be replaced
If the file name is empty after replacement, an error occur
If the variable is used in the file name pattern, the variable is not be deletable
If there is any exception while replacing variables with their value during export, the export will continue with the file name without replacement.