Configuration and Operation
Configuration of CLAIRE Brand Extraction Service
The configuration for the brand extraction service is specified under section "[ATTRIBUTE EXTRACTION]" in the config.ini file in the CLAIRE accelerator package under the server.ai folder in addition to the default configuration set in the "[DEFAULT]" section (See section Configuration of CLAIRE product classification service form CLAIRE Product Classification Configuration and Operation chapter for details about the default configuration of CLAIRE service).
[ATTRIBUTE_EXTRACTION]# path to data and models foldersdata_path_extraction = c:/informatica/ai/data/attribute_extractionmodel_path_extraction = c:/informatica/ai/model/attribute_extraction# NER model model_extraction_spacy = S1# flag indicate dev environment (used for testing purpose)dev_env = FalseThe parameters are mandatory and described in table below:
|
Parameter name |
Description |
Valid values |
Default |
|
data_path_extraction |
Path to the folder where data (.csv files) used for the training process will be saved |
any valid path to an existing folder |
c:/informatica/ai/data/attribute_extraction |
|
model_path_extraction |
Path to the folder where trained models used for the classification process will be stored |
any valid path to an existing folder |
c:/informatica/ai/model/attribute_extraction |
|
model_extraction_spacy |
The model to be used in training. Model S1 is faster to train with lower efficiency while model S2 is slower to train with higher accuracy. |
S1, S2 |
S1 |
|
dev_env |
Boolean parameter indicating if development environment is in use |
true, false |
false |
Product360 configuration
In the file claire.properties which is located in the conf folder of the Product 360 server the connection to the CLAIRE brand extraction server should be configured:
################################################################################# General Claire server settings# # These settings describe the connection with the claire server#claire.server.url = http://localhost:5000claire.server.user = adminclaire.server.password = admin################################################################################# Brand Extraction# # Connection settings for claire server used for brand extraction training and prediction# If these values are empty, the brand extraction feature is considered to be inactive.#claire.brand.extraction.server.url = ${claire.server.url}claire.brand.extraction.server.user = ${claire.server.user}claire.brand.extraction.server.password = ${claire.server.password}Brand Extraction Training
Brand name extraction is the task of identifying a brand of a product from a given text assuming the text contains the brand. For example, given a text "2009 Nissan rogue sl used gray silver suvs for sale lakeland fl", "Nissan" should be identified as the brand of the product (a SUV).
Brand name extraction is a supervised learning, and the first step is to train a model based on existing data. To generate a model the CLAIRE accelerator leverages the power of Product 360´s export. To train a model, an export template has to be used in order to define the data for the training. The training data required to train the model basically consists of brand and text pairs. The text can be the product's title or description. The brand can be the manufacturer of the product. in your data there could be multiple text fields that contain brand information. If that is the case, we recommend choosing the field with the most data (most number of rows) and/or the field with shorter length of texts (See the Recommendation chapter for more details). In addition, the export template must configure the post processing step "Brand extraction training". This post processing step will send the created file to the CLAIRE brand extraction service which will eventually train a model based on the data.
Standard export templates for brand extraction training
With the CLAIRE accelerator package 3 pre-built export templates are provided under Resources/Export Templates and can be used as is or as template for your own brand extraction training exports.
AI Brand Extraction Training Items.ext
AI Brand Extraction Training Products.ext
AI Brand Extraction Training Variants.ext
Training data
Please ensure that there is enough training data to create your machine learning model. A training based on a few thousand records only might not bring best results. Also, the labels should be meaningful and more than just a short description like "Blue T-Shirt". Generally, the prediction results are heavily dependent on the quantity and quality of the data you feed the training with.
Create your own export templates for brand extraction training
It is possible to create custom export templates for brand extraction training, e.g., if the data you want to train on is in custom fields. Some preconditions to keep in mind are:
It must be a csv file
The purpose of the export template must be "AI Training"
Column headers have to be "brand" and "title". The columns need to contain respectively the brand name and the textual data defined as label for the training. As mentioned above, there could be multiple text fields that contain brand information. If that is the case, we recommend choosing the field with the most data (most number of rows) and/or the field with shorter length of texts See our Recommendation chapter for more details).
The export template must have the post processing step "Brand extraction training" attached
Create AI brand extraction training export profiles
After creating an export template or importing the examples you can create AI brand extraction trainings in the context selection view. Although the "AI Brand Extraction Trainings" are basically exports we separated them from the "regular" export profiles for a better user experience.
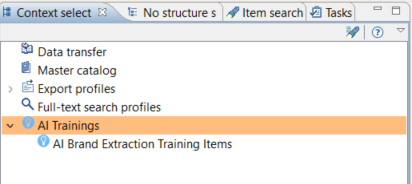
Also, in the process overview the AI trainings are separated from the "regular" export job executions for better process traceability

As we are using the export functionality of Product 360 you have the full power of configuring and scheduling export profiles to manage your AI trainings.
Please note that we currently don´t have any delta training. That means you have to retrain the model including exporting all of your data for every training.
Start AI brand extraction training
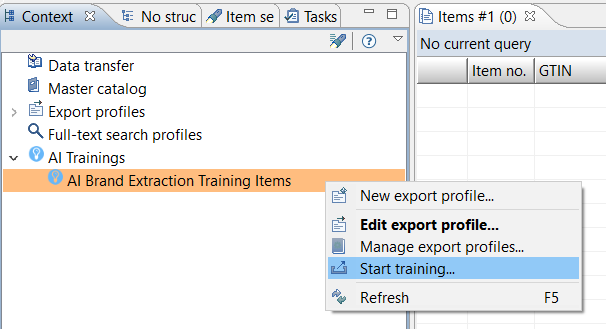
To start an AI Brand Extraction Training, follow the steps bellow:
Right click on the export profile
Select Start training...
The export parameter configuration dialog will open up. At this stage you set the export parameters for executing the training including the training language variable which confirms the language of the text field exported to train the model.
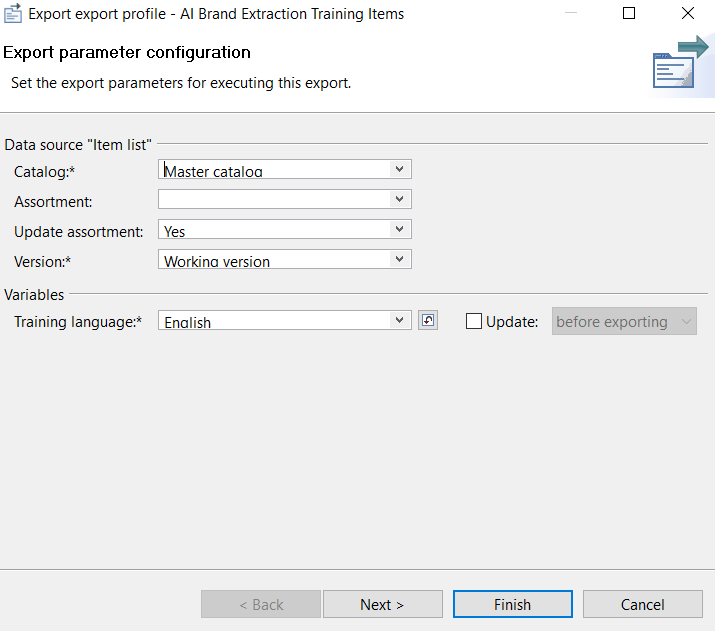
Click on Finish and wait until the training is successfully completed.
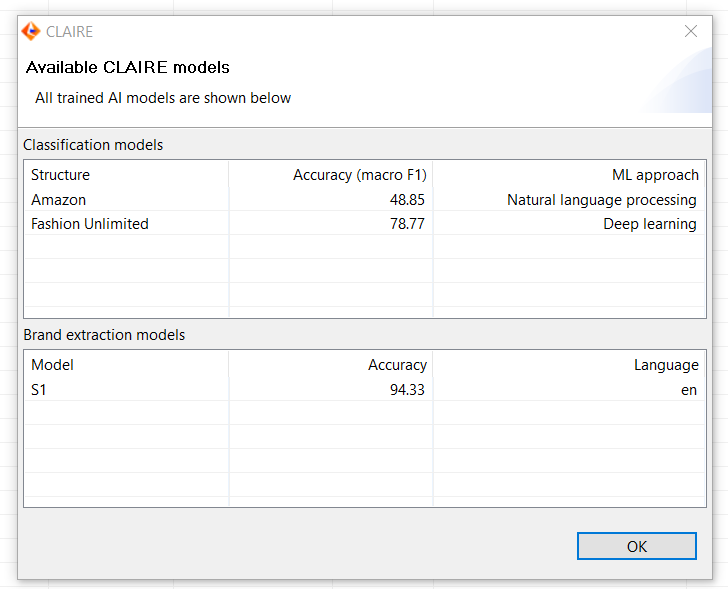
Display available models
To check the accuracy of the brand extraction model, you can use the entry in the "Management" menu of the Desktop UI called "Show CLAIRE models". The table "Brand extraction models" displays all brand extraction trained models with their corresponding details.
Configuration of Brand Extraction Flex UI
The CLAIRE panel can be integrated into any flex UI with a component for brand extraction. Below you see an example of how to configure a CLAIRE panel into your flex UI definition.
<group identifier="Claire info"> <layoutData> <parameter key="colSpan" value="1"/> <parameter key="rowSpan" value="1"/> </layoutData> <component i18NKey="Claire" identifier="claire full" type="claire"> <layoutData> <parameter key="collapsible" value="false"/> <parameter key="collapsed" value="false"/> </layoutData> <parameter key="context" value="brandExtraction"/> <parameter key="brandExtractSourceField" value="ArticleLang.DescriptionShort(en)"/> <parameter key="brandExtractTargetField" value="Article.ManufacturerName"/> <parameter key="threshold" value="80"/> <parameter key="selectionThreshold" value="80"/> </component> </group>|
Parameter name |
Description |
Valid values examples |
Default |
|
context |
The context or use case the CLAIRE panel will be used for. Only recommendations for this use case will be shown. If empty, the server will attempt to load all available CLAIRE Panels, for example classification, translation and brand extraction. |
brandExtraction |
<empty> |
|
brandExtractSourceField |
The source field which will be used for brand extraction. The field has to be fully qualified and formatted according to the REST API syntax. |
ArticleLang.DescriptionShort(en) |
<empty> |
|
brandExtractTargetField |
The target field to which the predicted brand name shall be written to. |
Article.ManufacturerName |
<empty> |
|
threshold |
All brand predictions with a confidence score below or equal to this threshold will not be shown in the flex UI component. |
0-100 |
80 |
|
selectionThreshold |
All brand predictions with a confidence score above or equal to this threshold will be automatically selected in the CLAIRE flex UI component checkbox In addition to the selectionThreshold, the check box for the predicted brand will only be automatically selected in the flex UI component if no value already exists for the brand name in the brandExtractTargetField to prevent unwanted overwriting. |
0-100 |
80 |
You can make the example flex UI template available in Product 360 Web by using the Desktop UI through Management → Manage UI templates → Load UI templates from file. The example file can be found under CLAIRE_Services → Resources → Flex UI Templates. From this point on, you can open the brand extraction flex UI in the web UI by selecting one or multiple items and clicking on Actions → Open Flex UI → Brand Extraction with Claire.
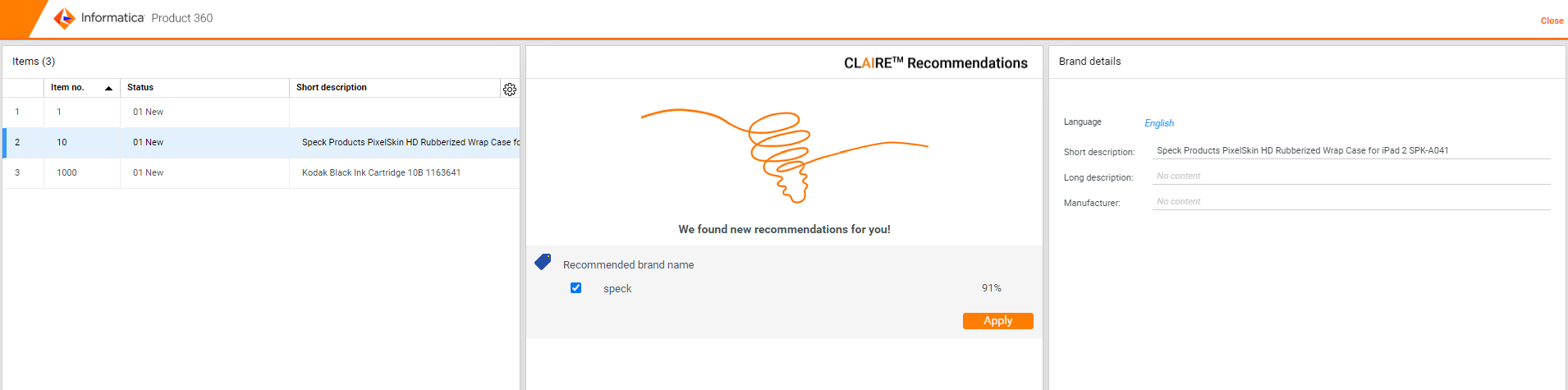
Batch Execution of Brand Extraction
In order to provide the brand extraction in a batch process setup (for example after the import of data) the Claire accelerator comes with the following capabilities:
After installation and configuration of the accelerator there is a new data quality category named CLAIRE which also contains example rule configurations for brand extraction:
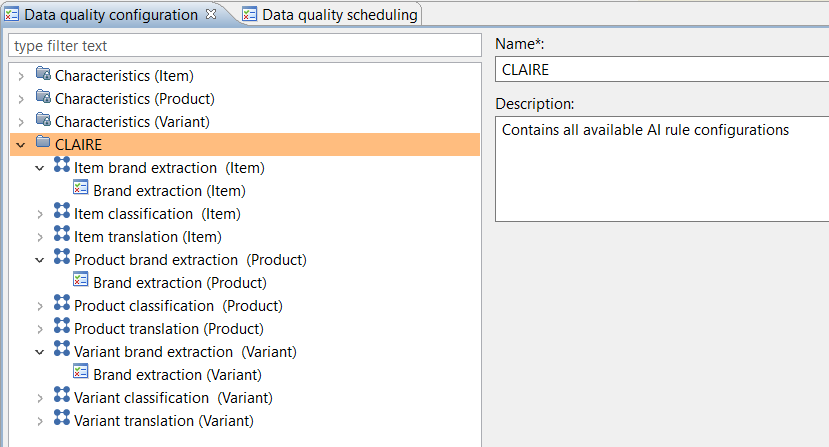
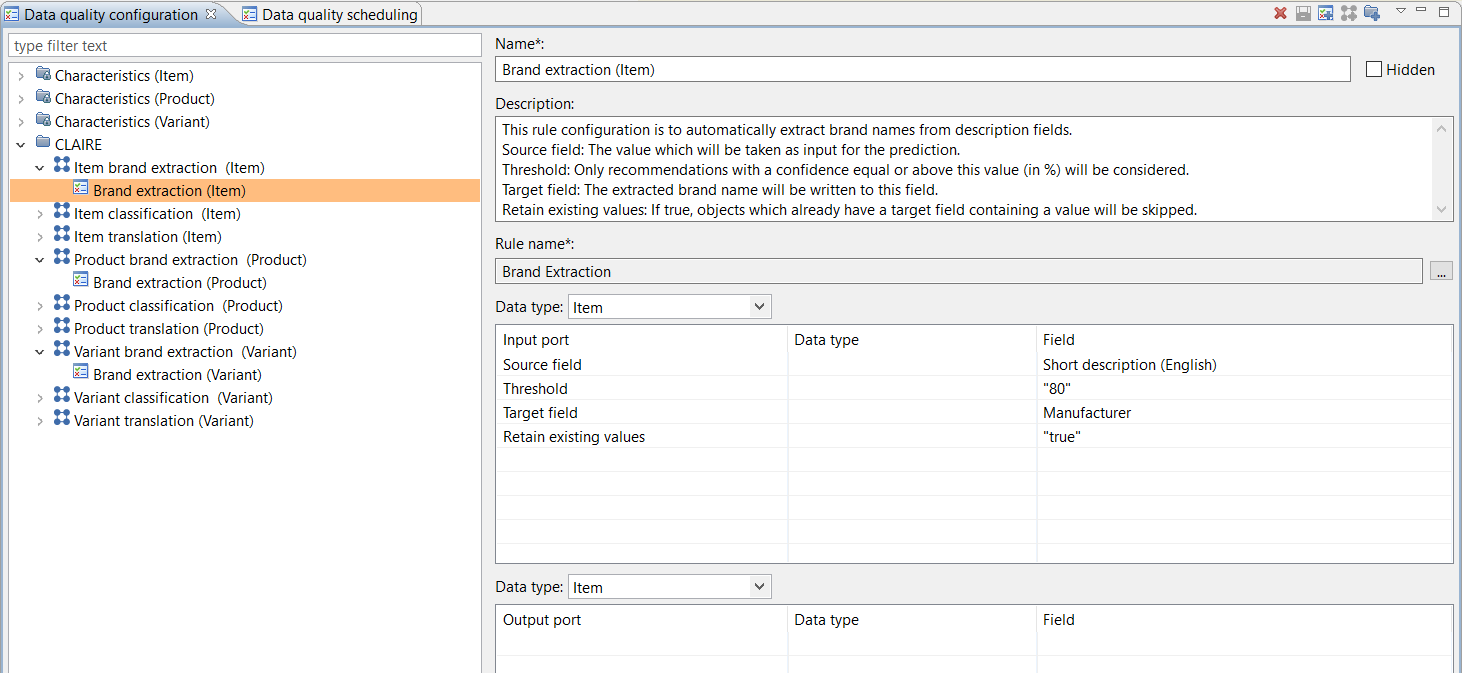
How to use the brand extraction rule configuration
It is highly recommended to clone one of the existing brand extraction rule configurations and then modify the input ports according to your needs. The "default" rule configuration is just a template and should not be used as is. Even if you delete this rule configuration, category or group, it will come up on next server start again.
After the data quality rule configuration has been cloned and the parameter adjusted, it can be used for triggers or direct execution to extract brands from language specific values of product records just as any other data quality rule configuration. The parameters are mandatory and described here:
|
Parameter |
Description |
|
Source Field |
The brand will be extracted from a language specific field value. The selected field must be a string field qualified with a language. Note: Only fully qualified fields are supported. Please don't select another data type for your rule configuration. |
|
Target Field |
The field, the extracted brand shall be written into. It must be a string field. |
|
Threshold |
Every prediction comes with a confidence score. In order to only add good predictions automatically to your data, you can adjust the minimum confidence score in percent. |
|
Retain existing values |
If true, already existing values in the target field will not be overwritten. |
In case no quality status entry is written for a product, variant or item after you triggered the execution of the rule, have a look into the process overview. There could be some reasons (like missing permissions) that might prevent the execution of a rule configuration for a product, variant or item.
Our internal tests on batch executions of brand extraction based on one source and one target field using real customer data have shown the following performance results:
|
Number of product records |
Duration |
|
100 |
3 seconds |
|
1.000 |
28 seconds |
|
2.240 |
1 minute |
|
10.000 |
4 minutes 6 seconds |