Spell Checking
Motivation
Spell checking is an important feature in the data maintenance process. This feature is important for ensuring consistent data quality and an integrated user experience for the Enterprise PIM suite.
Basic functionality
The PIM spell-checker scans the text and extracts the words contained in it. Then it compares each word with a known list of correctly spelled words (a dictionary). This contains just a list of words. The spell-checker performs neither grammatical nor morphological analysis. It checks simply whether a word is contained in the corresponding dictionary. If yes, the word is correct, otherwise, the word is incorrect. All incorrect words are highlighted in a text field, if the spell-cheker is enabled for this control. Additionally the spell-checker provides suggestions for the incorrect words. So the user is able to replace an incorrect word with one of the suggested words. Furthermore the user can add an incorrect word to the corresponding dictionary, so that this word will be recognized as correct next time.
Architecture
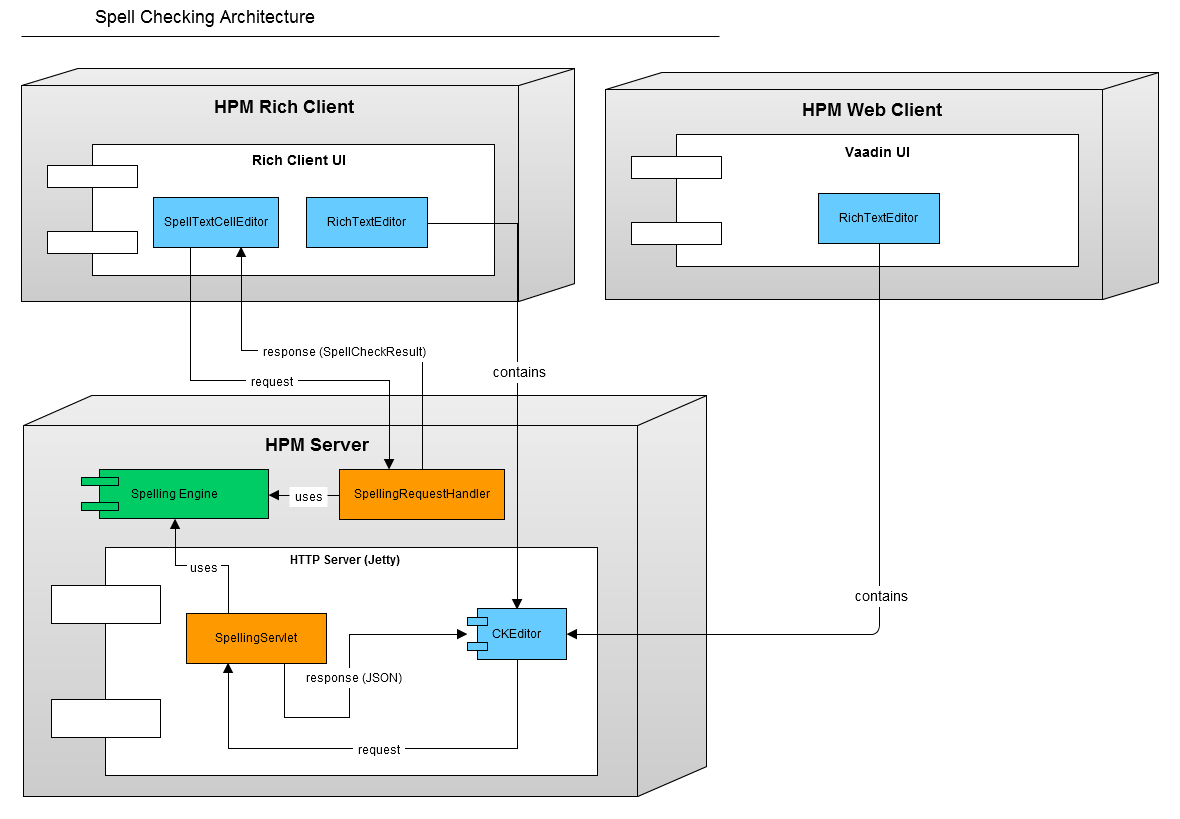
Handling of Multiple Languages
Unlike the standard Eclipse spell checker, multiple languages are supported. Spell checking is enabled by default for language dependent fields and attributes.
Additionally it is possible to enable or disable the spell checking for certain fields by adding a field parameter to the corresponding repository field. The parameter name is "spellingEnabled". If the value is "true" the spell checking for this field will be enabled. If the parameter value is "false" the spell checking for this field is disabled. This affects language dependent as well as language independent fields.
When checking a field, the language qualifier of the field is used to identify the dictionary language. For the language independent fields (with enabled parameter "spellingEnabled") the client language is used.
User Interface
The spell checking is currently supported on the following controls in Product Manager: text field in a table, text field in a form and the rich text field (in a view or in a dialog).
In PIM Web Access also the rich text dialog, as well as all enabled language dependent fields in the detail views are spell checked.
Spell Checking in a Table Field
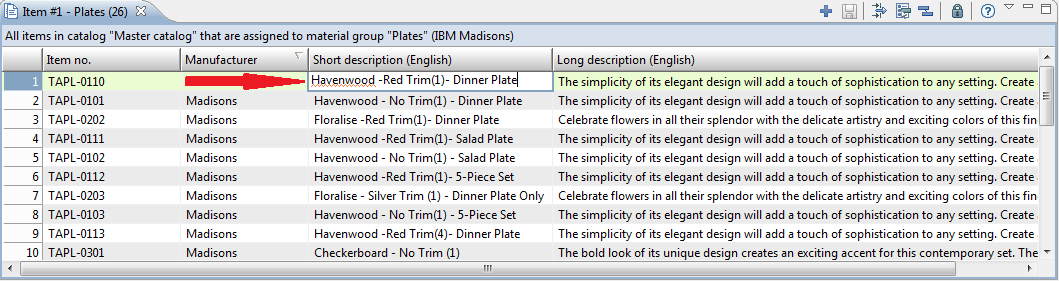
In a table the spell checking is only triggered when a table cell is activated.
Spell Checking in a Form View
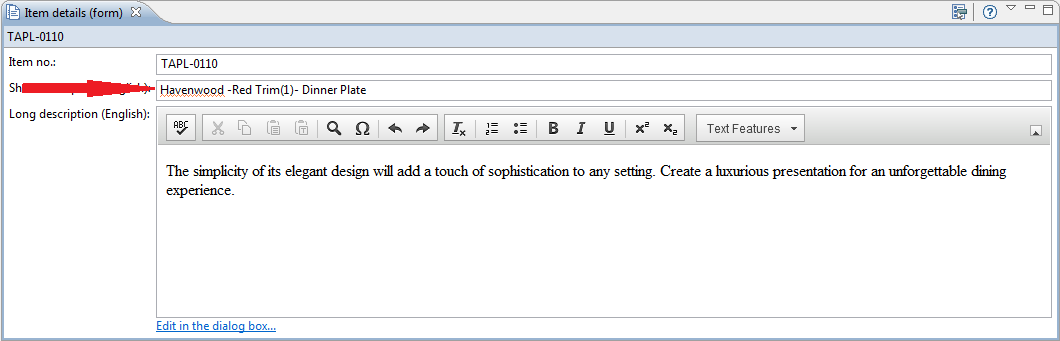
In a form view in a simple text field the spell checking is always active.
Spell Checking in the Richt Text Editor
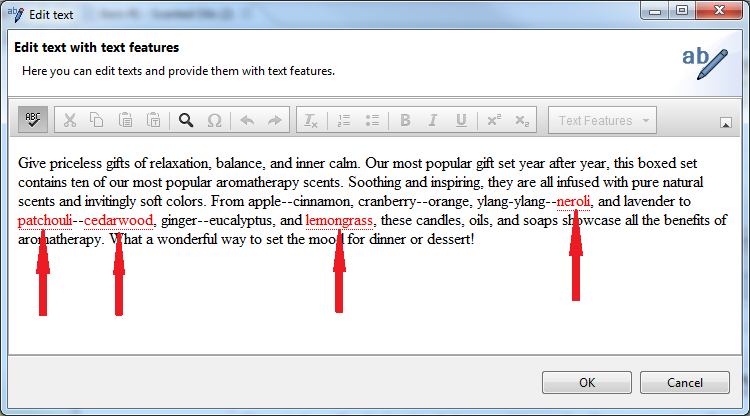
In the Rich Text Editor the spell checking is only active when the spell-checker button in the toolbar is pressed.
Visibility of the 'spell-checker' button in the toolbar
The following table describes in wich cases the "spell-checker" button is visible in the toolbar (dependent on the field language qualification and the field parameter "spellingEnabled"):
|
Case |
Field language qualification |
Field param "spellingEnabled" |
Result |
|
1 |
missing |
missing |
button is not visible |
|
2 |
missing |
false |
button is not visible |
|
3 |
missing |
true |
button is visible, client language is used |
|
4 |
available |
missing |
button is visible, field qualification language is used |
|
5 |
available |
false |
button is not visible |
|
6 |
available |
true |
button is visible, field qualification language is used |
Spell Checking context menu
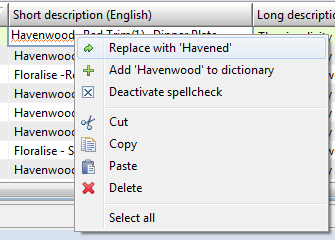
If a word in a text field is highlighted as incorrect, a spell checking context menu can be displayed. The spell checking context menu contains following options:
Replace with '...' - if there are suggestions for the incorrect word, each suggestion will be shown in the context menu (sorted by the relevance) as a menu item. When clicking this menu item, the incorrect word will be replaced with the corresponding suggestion.
Add '...' to dictionary - When clicking this menu item, the incorrect word will be added to the corresponding dictionary (if the user has required permissions)
Deactivate spellcheck - Disables the spell checking on the client. The spell checking can be enabled again in the client's preferences dialog (Preferences->General->Spellcheck).
Spell-checker settings
There are several settings for the spell-checker, which can be modified to affect the spell-checker functionality.
|
preference |
default value |
description |
|
spelling_problems_threshold |
100 |
the maximum number of problems reported during spell checking |
|
spelling_proposal_threshold |
20 |
the number of proposals offered during spell checking |
|
spelling_ignore_digits |
true |
determines whether words containing digits should be skipped during spell checking |
|
spelling_ignore_mixed |
true |
determines whether mixed case words should be skipped during spell checking |
|
spelling_ignore_sentence |
true |
determines whether sentence capitalization should be ignored during spell checking |
|
spelling_ignore_upper |
true |
determines whether upper case words should be skipped during spell checking |
|
spelling_ignore_urls |
true |
determines whether URLs should be ignored during spell checking |
|
spelling_ignore_single_letters |
true |
determines whether single letters should be ignored during spell checking |
All this setting can be modified in the plugin_customization.ini on the PIM server.
Spelling dictionaries
The PIM spell-checker uses spelling dictionaries to determine if a word is correct or not. Spelling dictionaries are language dependent. A spelling dictionary consists of a read-only standard dictionary and an editable additional dictionary. On the server-start both dictionaries are loaded and merged into a memory dictionary.
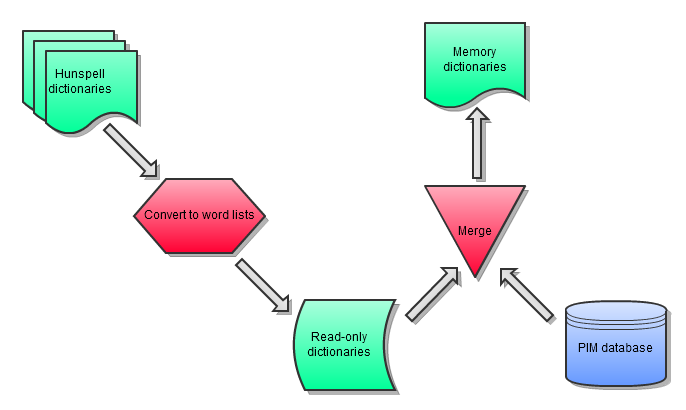
Standard dictionaries
Installation
Here is a suggestion of sites where you can find spellchecker dictionaries. Please check and respect the particular rights and licences.
These dictionaries consist of two files: one file with the basic words and one file with the grammatical rules. Once this files are copied in the specific dictionary folder (which can be configured in the plugin_customization.ini) on the PIM server, at the next server start they will be converted in the flat word lists, which can be used from the PIM spellchecker.
We recommend using of following standard dictionaries:
|
German |
http://extensions.services.openoffice.org/en/project/dict-de_DE_frami |
|
US English |
http://extensions.services.openoffice.org/en/project/en_US-dict |
To install the spelling standard dictionaries please do following:
Download a spellchecking dictionary e.g from one of the sources listed above.
Extract the corresponding "*.dic" and "*.aff" files.
Make sure that both files are encoded with ANSI. If necessary - change the encoding of both files and save them (e.g. using "Notepad++" - file menu "Encoding" -> "Convert to ANSI").
Copy these files in the folder configured in the plugin_customization.ini as com.heiler.ppm.spelling.server/sourceDictionariesFolder.
The default value is {CONF}/dictionaries/source, where {CONF} is the placeholder of the configuration folder of the PIM-Server.The file pattern for the dictionary files is: {LANGUAGE}_{COUNTRY}.dic and {LANGUAGE}_{COUNTRY}.aff (e.g. en_US.dic, en_US.aff). So rename the copied files if necessary.
Then at the next server start the source files will be converted in the word lists and cached in the dictionary cache folder (which is also configured in the plugin_customization.ini).
User dictionaries
Additionally to the standard dictionaries the users are able to add the words for a specific language to the dictionaries. In this case the words are stored in the PIM database. For example if a word in a text seems to be correct, but it is not in the standard dictionary, it will be highlighted as incorrect in the text field. So the user can add this word (via context menu) to the dictionary. In this case this word will be stored in the database and it will be added to the corresponding memory dictionary. From this moment on this word is available for the spell-checker and will be recognized as correct. Next time at the PIM server start this word will be merged with the other words from the standard dictionary.
Maintenance
If a user has required permissions, he is able to maintain the user defined dictionaries. To do this open the Dictionaries perspective:
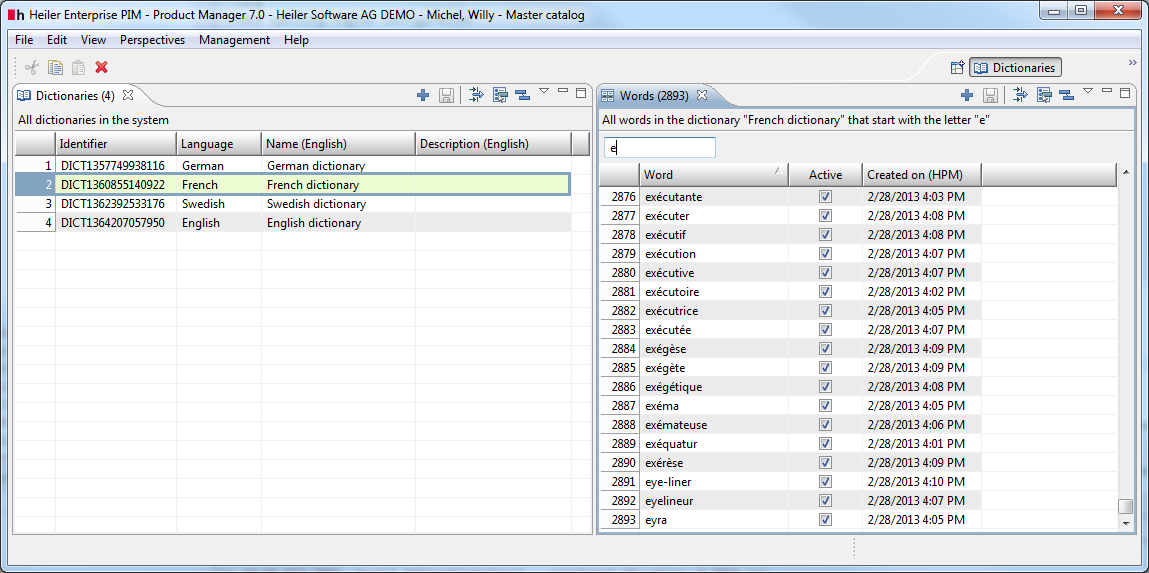
On the left hand you can create, delete and rename the dictionaries. On the right hand you can see the words containing in the selected dictionary. Here you can add new word, delete existing word or change the "active" flag of the words. If a word is active it is available for the spell-checker and will be recognized as correct, otherwise the word will be recognized as incorrect (also if this word exists in the standard dictionary). The words in a dictionary are unique, so if you try to add a word to the dictionary, which already exists in this dictionary, a warning dialog will be shown.
Import
You can also import words to the user defined dictionaries. Therefor you need a text file with a word list. The words should be separated by the newline. Then use the import perspective to load this file and map the words to the "Word" entity:
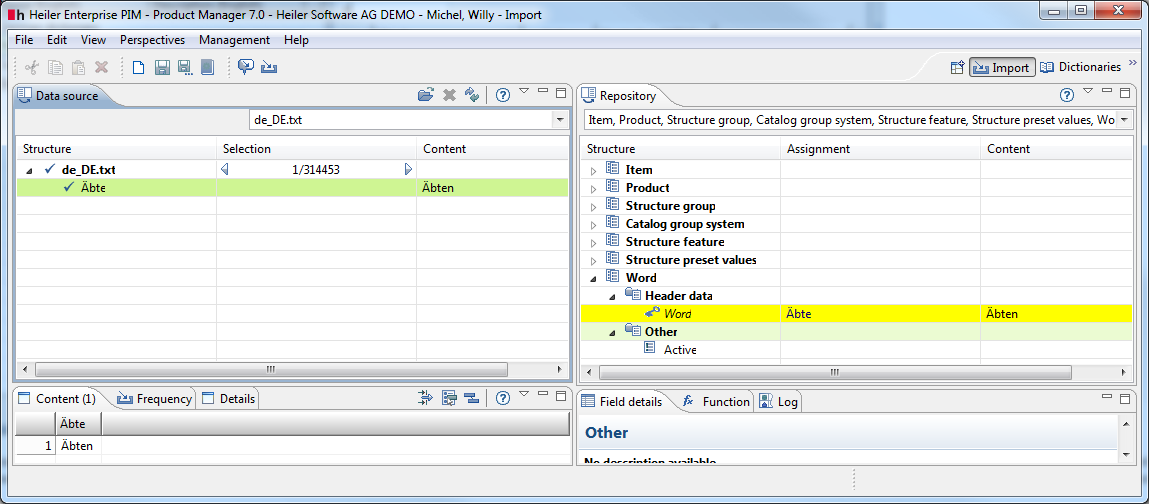
Then in the schedule dialog select the dictionary, where the words should be added:
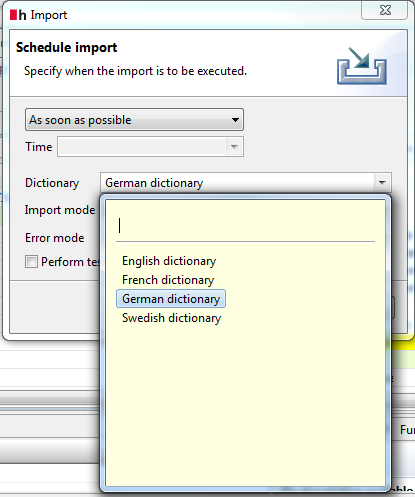
and perform the import.
Memory usage
On the server start the dictionaries are loaded from files and from the database in the memory to provide a fast access to the words on the spell checking. But if you use large dictionaries for many languages, it can lead to high memory usage.
The additional memory consumption by the dictionaries can be calculated as follows: (files_size x 3) + (word_count x 1KB) *
files_size - the size of all files in the dictionary cache folder (in kilobytes)
word_count - the number of all active words in the database
Action rights
|
Permission |
description |
|
Dictionaries, general access |
The user is able to open the Dictionaries perspective and the views Dictionaries and Words and has a read access to all user defined dictionaries and words |
|
Dictionaries, read object rights |
The user has a read access to all dictionary object rights |
|
Dictionaries, manage object rights |
The user has a write access to all dictionary object rights |
|
Manage dictionaries |
The user is able to create, delete and edit dictionaries |
|
Manage words |
The user is able to create, delete and edit words |
|
Add words to dictionary |
The user is able to add words |
|
Suggest words |
The user is able to suggest words |
The spell-checker context menu item "Add '...' to dictionary" appears only if the user has either the permission "add words" or "suggest words".
If the user has the permission "add words" - the word will be stored in the database, the flag active will be set to true, the word will be added to the memory dictionary and is immediate available for the spell-checker.
If the user has the permission "suggest words" - the word will be stored in the database, the flag active will be set to false and the word will be not available for the spell-checker.