データアクセスサービスコネクタの作成
Secure Agentでデータアクセスサービスコネクタを作成し、データベースから直接データにアクセスできます。
データアクセスサービスコネクタを使用して、次のデータベースに接続できます。
データアクセスサービスコネクタは、データベースと直接対話するためのプロパティを定義し、変数を指定することで作成できます。また、データアクセスサービスコネクタと関連付けられたアクションを定義することもできます。
データアクセスサービスコネクタを作成する前に、必要なJDBC JARファイルを次のディレクトリにコピーし、Secure Agentを再起動する必要があります。
<Secure Agentのインストールディレクトリ>/apps/process-engine/ext
使用するデータベースに基づいて、以下のJDBC JARファイルをダウンロードします。
データベース名 | JARファイル |
|---|
Databricks | DatabricksJDBC42.jar |
IBM DB2 | db2jcc4.jar |
Microsoft SQL Server | sqljdbc41.jar |
MySQL | mysql-connector-java-5.1.40-bin.jar |
Oracle | ojdbc8.jar |
Snowflake | snowflake-jdbc-<version>.jar |
注: JARファイルは、使用するデータベースのバージョンとの互換性がある必要があります。
データアクセスサービスコネクタを作成するには、次の手順を実行します。
- 1アプリケーション統合で、[新規] > [サービスコネクタ]をクリックします。
- 2[新しいアセット]ダイアログボックスで、[フォームを使用したデータアクセスサービスコネクタ]をクリックし、[作成]をクリックします。
プロパティの定義
データアクセスサービスコネクタを作成してプロパティを定義するには、次の手順を実行します。
- 1アプリケーション統合で、[新規] > [サービスコネクタ] > [フォームを使用したデータアクセスサービスコネクタ] > [作成]をクリックします。
データアクセスサービスコネクタエディタが表示されます。
次の図は、データアクセスサービスコネクタエディタを示しています。
- 2[定義]タブで、データアクセスサービスコネクタに次の基本プロパティを定義します。
- - 名前: 必須。データアクセスサービスコネクタをプロセスで使用できるようにする名前。名前の先頭の文字は英字または数字にする必要があり、名前には英数字、マルチバイト文字、アンダースコア(_)、およびハイフン(-)のみを含めることができます。名前は128文字以内にする必要があります。
- - 場所: 必須。データアクセスサービスコネクタを保存するプロジェクトまたはフォルダを指定します。
- - 説明: 必要に応じて、データアクセスサービスコネクタの説明を入力します。
- - エージェントのみ: データアクセスサービスコネクタはSecure Agentでのみ実行できるため、デフォルトで選択されています。
- - ODataの使用: ODataを使用しているWebサービスからデータにアクセスするには、このオプションを選択します。データアクセスサービスコネクタの[ODataの使用]オプションを有効にした後に、データアクセスサービス接続を使用するアプリケーション接続でODataを有効にして、OData許可ユーザーと許可グループを指定できます。
アプリケーション接続をパブリッシュした後に、アプリケーション接続の[プロパティの詳細]ページで、ODataサービスURLとOData Swagger URLを確認できます。
- - OAuth 2.0の使用: OAuth 2.0認証を有効にするには、このオプションを選択します。OAuth 2.0は、Webアプリケーションに特定の認証フローを提供し、クライアントとサーバー間の安全な情報送受信を支援する認証プロトコルです。OAuth 2.0は、ユーザーに代わってリソースにアクセスするための権限を表すアクセストークンを使用し、トークンの発行者がそのデータにアクセスできるようにします。
注: 応答時間は、クエリするデータベースのサイズに応じて異なる場合があります。
データアクセスサービスコネクタを使用する際にODataプロトコルおよびOAuth 2.0認証を利用すると、Snowflakeデータベースに安全に接続し、データへのアクセスを有効にできます。
注: Snowflakeデータベースにアクセスするためのデータアクセスサービスコネクタを作成する場合は、OAuth 2.0認証とODataプロトコルを使用するために、付与タイプを[認可コード]に設定してください。
OAuth認証を使用するには、[OAuth2を使用]オプションを選択し、次のプロパティを設定します。
プロパティ | 説明 |
|---|
認証タイプ | 必須。ユースケースに基づいて必要なグラントタイプを選択してください。 |
認証URL | 必須。ユーザーの要求を承認するOAuthプロバイダのOAuth認証URLを入力します。 例: https://login.microsoftonline.com/xxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxx/oauth2/v2.0/authorize |
トークンリクエストのURL | 必須。トークン要求を処理するOAuthトークン要求URLを入力します。 例: https://login.microsoftonline.com/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/oauth2/v2.0/token 更新トークンの有効期限は、OAuthプロバイダに応じて異なります。トークンの有効期限が切れる前に、接続を再認証してパブリッシュする必要があります。 注: 更新トークンは、エージェントグループには適用されません。 |
クライアントID | 必須。OAuthプロバイダからの識別子の値を指定します。 |
クライアントシークレット | 必須。OAuthプロバイダに接続するためのクライアントシークレットを入力してください。 |
スコープ | 必須。スコープを指定します。OAuth認証のスコープは、アプリケーションからユーザーのアカウントへのアクセスを制限するものです。1つのクライアントに対して複数のスコープを選択できます。複数のスコープを入力するには、各値をスペースで区切ります。 |
SESSION DURATION | オプション。セッションを更新するまで待機する時間を分単位で入力してください。これは、OAuthプロバイダからトークンの有効期限を取得できない場合に使用されます。デフォルトは60分です。 |
その他のパラメータ | オプション。認証要求をカスタマイズするためのパラメータをセミコロンで区切って入力します。追加の情報を入力したり、OAuthプロバイダの要件を指定したりすることができます。 |
承認ステータス | オプション。現在のステータス、承認したユーザーの名前、最後に承認が完了した時刻を示します。 |
アクセスの承認 | OAuthを使用した承認ワークフローを開始するにはクリックします。 |
データアクセスサービスコネクタには、OAuth 2.0プロバイダによって発行されたアクセストークンを受け入れるすべてのサービスを使用する権限が割り当てられています。
- 3[接続プロパティ]セクションで、外部データベースに接続するための次の全般プロパティを定義します。
- - JDBCドライバ: 必須。JDBCドライバのJavaクラスの完全修飾名。
データベースに基づいて、次のいずれかのドライバクラス名を指定できます。
- ▪ Databricks: com.databricks.client.jdbc.Driver
- ▪ IBM DB2: com.ibm.db2.jcc.DB2Driver
- ▪ Microsoft SQL Server: com.microsoft.sqlserver.jdbc.SQLServerDriver
- ▪ MySQL: com.mysql.jdbc.Driver
- ▪ Oracle: oracle.jdbc.OracleDriver
- ▪ PostgreSQL: org.postgresql.Driver
- ▪ Snowflake: net.snowflake.client.jdbc.SnowflakeDriver
- - JDBC URL: 必須。外部データベースに接続するための接続URL。
データベースに基づいて、次のいずれかのURLを指定できます。
- ▪ Databricks: jdbc:databricks://<host>:443/default;transportMode=http;ssl=1;AuthMech=3;httpPath=<http-path>
Note: Databricksデータベースに接続する場合は、パーソナルアクセストークン(PAT)認証方法のみを使用できます。
- IBM DB2: jdbc:db2://<server>:<port>/<database>
- ▪ Microsoft SQL Server: jdbc:sqlserver://<host>:<port>;databaseName=<database>
Note: Active Directory認証方式を使用して、Microsoft SQL Serverデータベースに接続できます。この認証タイプを使用するには、次の形式に示すように、JDBC URLにauthentication=ActiveDirectoryPasswordを追加します。
jdbc:sqlserver://<ホスト>:<ポート>;databaseName=<データベース;authentication=ActiveDirectoryPassword
- ▪ MySQL: jdbc:mysql://<host>:<port>/<database>
- ▪ Oracle: jdbc:oracle:thin:@//<host>:<port>/<service>
- ▪ PostgreSQL: jdbc:postgresql://<host>:<port>/<database>
- ▪ Snowflake: jdbc:snowflake://{workspace_name}.snowflakecomputing.com/?warehouse={warehouse_name}&db={db_name}&schema={schema_name}&authenticator=oauth
Note: Snowflakeデータベースについては、URLにauthenticator=oauthが指定されていない場合、接続に基本認証方法が使用されます。
- - ユーザー名: 必須。データベースに接続するためのユーザー名。
- - パスワード: 必須。データベースに接続するためのパスワード。このフィールドに入力された値は、デフォルトで暗号化されます。開発者コンソールには、コネクタを保存するときに入力したパスワードが表示されます。コネクタを保存して閉じ、再度開くと、パスワードが暗号化されて表示されます。
注: Databricksデータベースに接続する場合は、[ユーザー名]フィールドにtokenと入力し、[パスワード]フィールドにPATの値を入力します。
- - スキーマ: メタデータに含めるテーブルまたは除外するテーブルを含むスキーマの名前を入力します。また、適切な結果を表示するには、データアクセスサービスコネクタを使用するアプリ接続にスキーマ名を入力する必要があります。
- - テーブルを含める: メタデータに含めるテーブルの名前を入力します。テーブルのリストを含めるには、カンマを使用して複数のテーブル名を区切ります。パターンマッチングの場合は、「.*」を使用することもできます。また、適切な結果を表示するには、データアクセスサービスコネクタを使用するアプリ接続に含まれるテーブル名を指定する必要があります。
- - テーブルを除外: メタデータから除外するテーブルの名前を入力します。テーブルのリストを除外するには、カンマを使用して複数のテーブル名を区切ります。パターンマッチングの場合は、「.*」を使用することもできます。また、適切な結果を表示するには、データアクセスサービスコネクタを使用しているアプリ接続から除外されるテーブル名を指定する必要があります。
- 4必要に応じて、[接続プロパティ]セクションで次の詳細プロパティを定義します。
SQLインジェクション保護およびセキュリティチェック
[SQLインジェクションチェック]オプションを有効にすると、悪意のあるクエリで使用されることが多い特定のパターンに一致するSQLパラメータをブロックすることで、データベースを保護できます。
このセキュリティオプションにより、次のカテゴリに分類される潜在的に有害な入力をチェックし、防止します。
- 論理条件チェック
- 攻撃者がインジェクション攻撃で悪用することが多い、常に真または常に偽となる条件、あるいはAND演算子やOR演算子を使用した直接比較などの疑わしい論理式を含むクエリ。
- データ操作コマンド
- データの読み取りや変更を行う一般的なSQL文には、次のようなものがあります。
- - SELECT
- - INSERT INTO
- - UPDATE
- - DELETE
- - UPSERT
- トランザクションおよびプロシージャ制御
- 次のような、トランザクションの処理またはストアドプロシージャの呼び出しを行うSQL文。
- - SAVEPOINT
- - CALL
- - ROLLBACK
- - KILL(プロセスの終了に使用)
- スキーマおよびデータベース構造の変更
次のような、データベースオブジェクトやロックを作成、変更、または削除するコマンド。
- - CREATE(テーブル、インデックスなど)
- - ALTER(テーブル、インデックスなど)
- - DROP
- - TRUNCATE
- - ロックとアンロック、およびロック解除コマンド
- メタデータ検査
- 次のような、スキーマ情報を取得するクエリ。
- 不審なコメントおよび文の区切り文字
- インジェクション攻撃で使用されることが多い、SQLコメント(/* ... */、-- ...)または文の区切り文字(;)を含むクエリ。
注: この保護によりSQLインジェクションのリスクは大幅に低減されますが、すべてのケースで有効であるとは限りません。データフローを中断せずに完全な保護を確保するためには、追加のセキュリティベストプラクティスの適用やアプリケーション内で入力値の検証を行うことを検討してください。
変数の指定
データアクセスサービスコネクタを設定するには、変数を指定して出力フィールドを定義することが必要になる場合があります。
ビルトイン変数
次の変数は、XQuery式を使用してデータアクセスサービスコネクタで参照できます。
変数 | 変数型 | 説明 |
|---|
$VariableName | すべての接続プロパティ | 入力フィールドと出力フィールドは、この形式を使用して指定できます。 |
$Response | 出力フィールドマッピング | 応答XMLデータが含まれます。これは、データアクセスサービスコネクタの[テスト結果]タブに表示されます。 |
アクションの定義
[アクション]タブでは、データアクセスサービスコネクタと関連付けられた1つ以上のアクションを作成して記述できます。
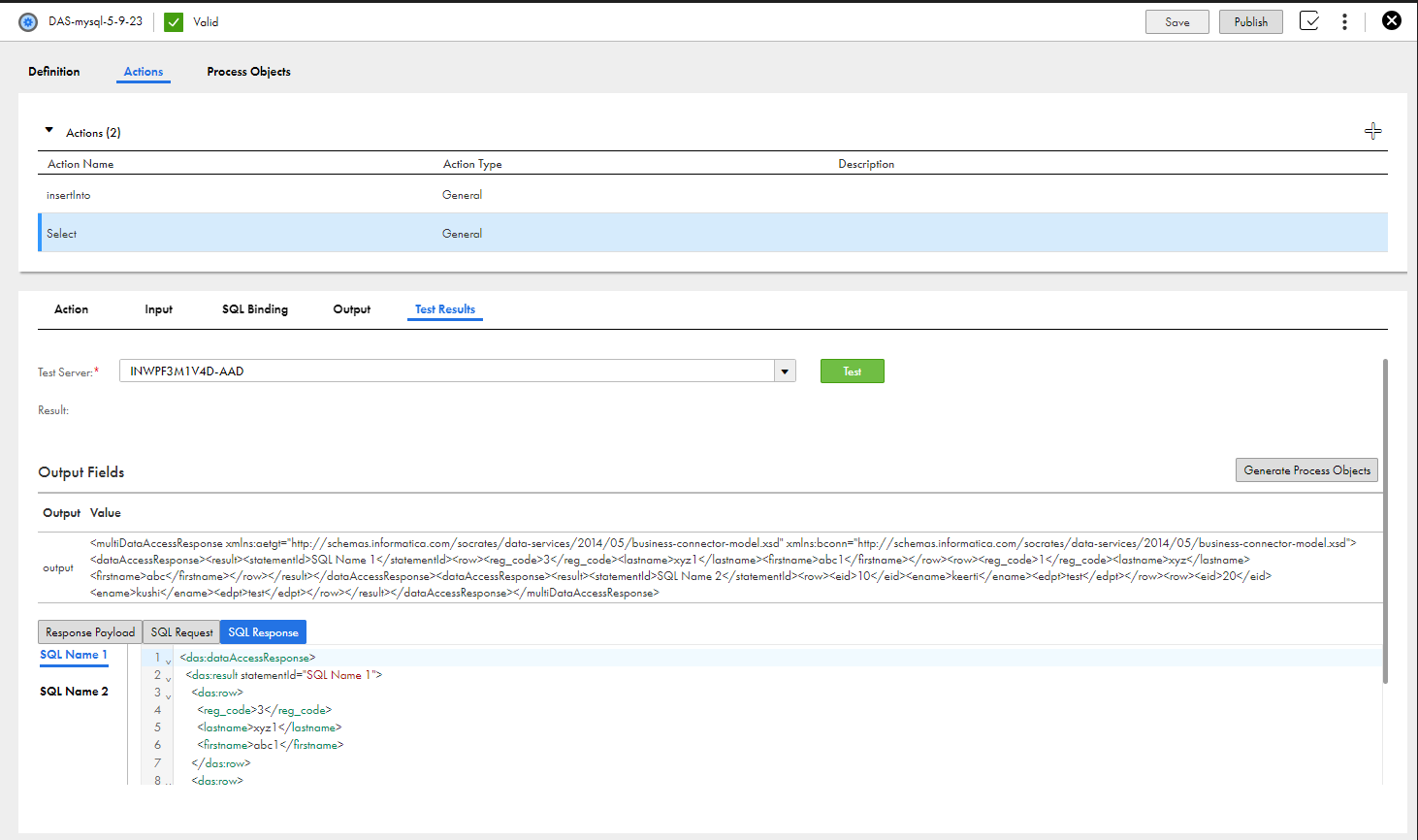
次の図は、[アクション]タブを示しています。
編集する行をクリックするか、[+]をクリックして新しい行を追加し、[アクション]タブで次の情報を入力します。
- •アクション名: データアクセスサービスコネクタと接続でこのアクションを参照するときにリストに表示する名前を入力します。アクション名にスペースまたは特殊文字は使用しないでください。これは必須フィールドです。
- •カテゴリ: データアクセスサービスコネクタが多数あり、それぞれに複数のアクションがある場合は、カテゴリを作成して、ユーザーがプロセス内を移動しやすくなるようにすることができます。
- •説明: このアクションの説明または付記を入力します。
各アクションについて、[入力]、[SQLバインディング]、[出力]、[テスト結果]の各タブに追加の詳細を指定します。
[入力]タブ
[入力]タブを使用して、データの送信先サービスに固有の入力データ項目を定義します。
次の図は、[入力]タブを示しています。
各項目に対し、次のプロパティを入力します。
[+]アイコンを使用し、新しい項目を追加します。[X]をクリックして現在の行を削除します。
[SQLバインディング]タブ
データアクセスサービスコネクタの各アクションについて、[SQLバインディング]タブを使用して、データソースからデータにアクセスするための複数のSQLクエリを指定します。SQLエントリが作成されると、タブには、SQL名、SQLテキスト、式のカラムの大文字と小文字、クエリタイプ、SQLクエリによって返される最大行数、最大待機時間(秒)などの詳細が表示されます。
複数のクエリを追加すると、テーブルに表示されているクエリの順序でSQL文が実行されます。矢印ボタンを使用してクエリを上下に移動できます。SQLクエリを削除することもできます。
SQLエントリの行を追加するには、[SQLバインディング]タブの[+]をクリックします。各SQLクエリの次の詳細を入力します。
- SQL名前
- SQLクエリの名前。
- SQLテキスト
- 少なくとも1行を返す有効なSQL文。
- カラムの大文字と小文字
式内の文字を小文字または大文字に変換する必要があるか、または変更しないままにするかを指定します。デフォルトは[小文字]です。
- タイプ
次のいずれかの値を選択します。
- - データの操作。情報をクエリし、その情報にロジックを適用して、異なるデータセットを生成します。
- - ストアドプロシージャ。保存して再利用できるあらかじめ用意されたSQLコードを使用します。ストアドプロシージャにより、データベースに対して複数のクエリを実行する代わりに、1回の呼び出しで複数の出力フィールドを返すことで、ネットワークトラフィックを削減します。データアクセスサービスコネクタでストアドプロシージャを使用する場合は、使用するデータベース管理システム(DBMS)に応じて出力フィールドを設定することができます。詳細については、「データアクセスサービスコネクタのストアドプロシージャへの出力フィールド設定」を参照してください。
- 最大行数
SQLクエリによって返され、SQL応答ペイロードに表示できる最大行数。デフォルトは100行です。最大行数は10,000行以下にする必要があります。
結果セットの場合は、設定した最大行数がストアドプロシージャ内のそれぞれのSQL文に適用されます。
- 最大待機時間(秒単位)
- データベースクライアントがセッションをタイムアウトするまでにデータベースからの応答を待機できる最大時間(秒)。
注: アプリケーション統合は、すべてのSQLクエリを実行した後にコミットを実行しません。SQLクエリが失敗した場合のロールバックを支援するために、コミットはすべてのSQLクエリが実行された後の最後にのみ行われます。一部のデータベースでは、CREATE TABLE、DROP TABLEなどのDDL文に対して暗黙的なコミットが発生します。これらの実行はロールバックできません。
データアクセスサービスコネクタのストアドプロシージャへの出力フィールド設定
データアクセスサービスコネクタでストアドプロシージャを使用する場合は、出力フィールドを設定できます。
ストアドプロシージャでは、MySQL、SQL Server、Oracle、PostgreSQL、またはDB2など、使用するDBMSに応じて出力フィールドを定義することができます。出力フィールドを使用して、データを呼び出し元のアプリケーションに戻すこともできます。ストアドプロシージャを使用すると、データベースに対して複数のクエリを実行する代わりに、1回の呼び出しで複数の出力フィールドを返すことで、ネットワークトラフィックを削減できます。また、出力フィールドでCursorデータ型を使用すると、データベースクエリから結果セットまたは行セットへのポインタを返すことができます。
データアクセスサービスコネクタのストアドプロシージャの出力フィールドでは、次のデータ型を使用できます。
- •Binary
- •Byte
- •CLOB
- •Cursor
- •日付型
- •倍精度浮動小数点数型
- •浮動小数点数型
- •整数型
- •長整数型
- •Short
- •String
ストアドプロシージャでの出力フィールドの設定
データアクセスサービスコネクタでストアドプロシージャを使用するときに出力フィールドを設定するには、次の手順を実行します。
1[SQLバインディング]タブで、[+]アイコンをクリックしてSQLエントリを追加します。
2[編集]アイコンをクリックして、SQLクエリを編集します。
複数のSQLクエリを設定するための[SQLの作成]ページが表示されます。
3SQLクエリの名前を入力します。
4[型]リストで、[ストアドプロシージャ]を選択します。
次の画像に示すように、[SQLの作成]ページの名前が[ストアドプロシージャの呼び出し]に変わります。
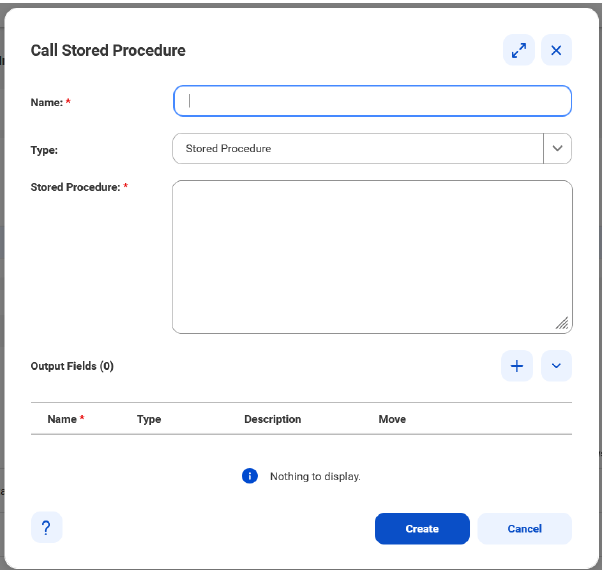
5[ストアドプロシージャ]フィールドに、次の形式でクエリを入力します。
<SQL文> <ストアドプロシージャの名前>(?);
例えば、次のサンプルに示すようにクエリを入力します。
CALL GetTotalSales(?)
注: [ストアドプロシージャ]テキストボックスに指定する? 記号の数は、[出力フィールド]セクションで定義する出力フィールドの数と一致している必要があります。ストアドプロシージャでINOUTパラメータを指定することはできません。
6[出力フィールド]セクションで、[+]をクリックします。
7それぞれの出力フィールドに対して次のプロパティを設定します。
- - 名前。出力フィールドの名前です。
- - タイプ。出力フィールドのタイプです。
- - 移動。出力フィールドの横にある矢印をクリックすると、[ストアドプロシージャ]テーブル内でそのフィールドが1レベル上または下に移動します。
8カラムのケースを選択します。
9SQLクエリによって返され、SQL応答ペイロードに表示できる最大行数を入力します。
10データベースクライアントがセッションをタイムアウトするまでにデータベースからの応答を待機できる最大時間(秒)を入力します。
11[作成]をクリックします。
次の画像に、ストアドプロシージャにサンプル値が指定された[ストアドプロシージャの呼び出し]ページを示します。
上記の例では、ユーザーは[ストアドプロシージャ]フィールドに次のクエリを入力しています。
CALL GetTotalSales(?);
対応する出力フィールドが、[出力フィールド]セクションに表示されています。そして、この出力フィールドは、次の図に示すようにデータアクセスサービスコネクタのプロパティページの[出力]タブにあるサービスコネクタの出力フィールドにマッピングされています。
次のスニペットは、CALL GetTotalSales(?)ストアドプロシージャが実行されたときの出力のサンプルの応答を示しています。
{
"outSPProcess":"<multiDataAccessResponse xmlns:aetgt=\"http:\/\/schemas.informatica.com\/socrates\/data-services\/2014\/05\/business-connector-model.xsd\" xmlns:bconn=\"http:\/\/schemas.informatica.com\/socrates\/data-services\/2014\/05\/business-connector-model.xsd\"><dataAccessResponse><result><statementId>StoredProc_WithOutputFields<\/statementId><row><TotalSales>3.00<\/TotalSales><\/row><\/result><\/dataAccessResponse><\/multiDataAccessResponse>"
}
複数のSQLクエリの設定
SQLクエリを追加および編集するには、次の手順を実行します。
1[SQLバインディング]タブで、[+]アイコンをクリックしてSQLエントリを追加します。
SQLエントリがテーブルに追加されます。
2[編集]アイコンをクリックして、SQLクエリを編集します。
[SQLの作成]ページが表示されます。次の図は、複数のSQLクエリを設定できる
[SQLの作成]ページを示しています。
![この図は、[SQLの作成]ページを示しています。](../cc-design/images/GUID-2692C0E1-86DB-4D76-88B7-F935DD522FBB-low.png "この図は、[SQLの作成]ページを示しています。")
3[SQLの作成]ページで、SQL名、SQLクエリ、クエリのカラムの大文字と小文字、クエリタイプ、最大行数、最大待機時間などのSQLクエリのプロパティを設定します。
SQLクエリを使用することで、SELECT、INSERT、DELETE、UPDATEなどのさまざまなデータ操作を実行できます。SQLクエリの入力フィールドをパラメータ化することができます。次の構文を使用して、実行時に入力フィールドをパラメータ化します。
'{$<input_field_name>}'
例えば、empIdが入力フィールドの名前である場合は、次のSQLクエリを入力してempIdフィールドをパラメータ化します。
select * from employee.contact where id = '{$empid}'
4[作成]をクリックします。
SQLクエリの応答形式
データアクセスサービスコネクタでは、単一および複数のSQLクエリに対するXML応答は、multiDataAccessResponseタグから始まります。
次のスニペット例は、プロセスまたはデータアクセスサービスの出力としての形式を示しています。
<multiDataAccessResponse xmlns:aetgt="http://schemas.informatica.com/socrates/data-services/2014/05/business-connector-model.xsd"
xmlns:bconn="http://schemas.informatica.com/socrates/data-services/2014/05/business-connector-model.xsd">
<dataAccessResponse>
<result>
<statementId>SQL Name 1</statementId>
<row>
<updatedRows>0</updatedRows>
</row>
</result>
</dataAccessResponse>
<dataAccessResponse>
<result>
<statementId>SQL Name 2</statementId>
<row>
<updatedRows>1</updatedRows>
</row>
</result>
</dataAccessResponse>
</multiDataAccessResponse>
次のスニペット例は、応答ペイロードとしてのXML形式を示しています。
<multiDataAccessResponse>
<dataAccessResponse>
<result statementId="SQL Name 1">
<row>
<updatedRows>0</updatedRows>
</row>
</result>
</dataAccessResponse>
<dataAccessResponse>
<result statementId="SQL Name 2">
<row>
<updatedRows>1</updatedRows>
</row>
</result>
</dataAccessResponse>
</multiDataAccessResponse>
[出力]タブ
[出力]タブを使用して、データアクセスサービスコネクタがデータベースから返されたデータをどのように解析するかを定義します。
次の図は、[出力]タブを示しています。
各出力データ項目について、次のプロパティを指定します。
- •名前: 返された値が配置されるフィールドの名前。
- •タイプ: フィールドに書き込まれる値のデータ型。タイプが[オブジェクトリスト]または[参照]である場合、Process Designerはプロセスオブジェクトのリストを表示し、[プロセスオブジェクト]タブ内で定義されたオブジェクトのいずれかを選択できるようにします。
- •説明: 出力フィールドの説明を入力します。
- •取得元: 次のいずれかのオプションを選択します。
- - カラム: 出力フィールド内に配置されるカラム名(データベースから返される出力内で使用されるデータベーステーブル内のカラム名)を入力します。
- - 式: データベースから返される出力を解析するための式を記述します。[f(x)]をクリックして、式を入力するための式エディタを開きます。
- - 結果セット: データベースからの応答の完全な内容を出力フィールドに割り当てます。
- - 添付ファイルとしてのすべての応答: 応答全体を添付ファイルとして処理します。
- - 添付ファイル: 複数の添付ファイルを処理して、添付ファイルの全リストを選択した変数(ペイロードとして使用されるパートを除く)に渡します。
プロセスオブジェクトの作成
[プロセスオブジェクト]タブでは、データアクセスサービスコネクタの1つ以上のプロセスオブジェクトを定義して、データをグループ化し、構造化オブジェクトを作成できます。データアクセスサービスコネクタで定義されたプロセスオブジェクトは、データアクセスサービスコネクタを使用するプロセスで利用可能になります。例えば、データベースが名前、住所、電話番号などの人口統計情報を返す場合、この情報を格納する単一の人口統計的プロセスオブジェクトを作成できます。
[アクション/出力]タブを使用して、データベースから返された1つ以上のデータ要素と各プロセスオブジェクトを関連付けることができます。
データアクセスサービスコネクタのプロセスオブジェクトを作成するには、次の手順を実行します。
- 1データアクセスサービスコネクタを作成するか、既存のコネクタを開きます。
- 2[プロセスオブジェクト]タブをクリックします。
- 3[+]をクリックして新しいプロセスオブジェクトを追加するか、既存のプロセスオブジェクトをリストから選択します。各プロセスオブジェクトは、タブ内に行項目として表示されます。
次の図は、[プロセスオブジェクト]タブを示しています。
- 4[プロパティ]タブで、各プロセスオブジェクトに対し、次の詳細を指定します。
- - 名前: プロセスオブジェクトを識別する名前を入力します。この名前は、プロセスオブジェクトを選択できるリストに表示されます。これは必須フィールドです。
- - 説明: プロセスオブジェクトの説明を入力します。
- 5[フィールド]タブで、各プロセスオブジェクトに対し、次の詳細を指定します。
データアクセスサービスコネクタのテスト
データアクセスサービスコネクタエディタを使用するときは、[テスト]をクリックしてデータベースに要求を送信し、応答データを[テスト結果]タブに表示します。
応答に1つ以上の添付ファイルが含まれている場合は、それらの添付ファイルをダウンロードすることもできます。
[応答ペイロード]および[SQL応答]セクションには最大10,000件のレコードが表示されます。[SQLバインディング]タブでは、制限に10,000を超える値を指定することはできません。
注: サービスコネクタに対してOAuth 2.0認証を設定している場合、テストアクションでは最初の認証プロセスで取得したOAuthトークンが使用されます。実行時にサービス呼び出しが行われた場合は、要求を行う前に、必要に応じてアプリケーション接続内のトークンが自動的に更新されます。
次の図は、[テスト結果]タブを示しています。
プロセスオブジェクトの生成
通常プロセスオブジェクトは、特定の要素セットに結び付けられます。場合によっては、多数の同一のオブジェクトを持ち、それぞれが1つの要素セットに適用されることがあります。例えば、返されるデータを定義するときに、返されるデータのサブセットを定義することのみを目的とするプロセスオブジェクトを作成します。これらのオブジェクトは再利用不可能であり、単一のプロセスオブジェクトフィールドのみが使用できます。オブジェクト名は、フィールドの名前でもあります。
再利用可能なオブジェクトを作成することもできます。例えば、NetSuiteのrefType要素には、nameとinternalIDという2つのフィールドがあります。これら2つのフィールドをそれぞれが含む多数のオブジェクトを作成するのでなく、1つの再利用可能なプロセスオブジェクトを作成できます。
- 1[プロセスオブジェクトの生成]をクリックして、データアクセスサービスコネクタ用に定義したプロセスオブジェクトを表示します。
- 2再利用可能にするプロセスオブジェクトを選択し、[次へ]をクリックします。
Process Designerに、生成されたプロセスオブジェクトの一覧が表示されます。
- 3[完了]をクリックします。
応答ペイロード内のメタデータパラメータ
特定のアプリケーション接続のメタデータの詳細を表示するには、メタデータパラメータを使用します。出力には、データと一緒に保存されているデータまたはデータセットに関するコンテキスト情報が含まれます。
アプリケーション接続のメタデータの詳細を表示するには、次のURIを使用します。
https://<Informatica Intelligent Cloud Services URL>/active-bpel/odata/v4/<app connection name>/$metadata
次のスニペット例は、応答ペイロードの形式を示しています。

多数のテーブルを含むデータベースからメタデータを適切に取得するには、アプリ接続で接続プロパティを定義するときに、[テーブルを含める]または[テーブルを除外]フィールドを使用してテーブルをフィルタリングします。
応答ペイロード内のOData拡張パラメータ
アプリケーション接続をパブリッシュした後、OData拡張パラメータを使用して、データに対してネストされたクエリを実行できます。サービス呼び出しでは、ナビゲーションプロパティの1レベルまでをクエリできます。
OData拡張パラメータを含む次のURIを使用します。
https://<Informatica Intelligent Cloud Services URL>/active-bpel/odata/v4/<app connection name>/<table name>?$expand=*
次のスニペット例は、拡張クエリの出力を示しています。

Databricksのルールとガイドライン
データアクセスサービスコネクタを使用してDatabricksデータベースに接続する場合は、次のルールとガイドラインを考慮してください。
- •Databricksデータベースに接続するデータアクセスサービスコネクタでは、ストアドプロシージャを使用することはできません。
- •Databricksデータベースへの一部の要求は、システムの遅延や実行速度の低下により、ランダムにタイムアウトする場合があります。要求のタイムアウトを回避するには、[最大待機時間(ミリ秒)]フィールドの値を増やします。
![この図は、[新しいアセット]ダイアログボックスを示しています。](../cc-design/images/GUID-5730C64B-EA2A-4EBE-BFCB-3E8D9E6BD0FC-low.png "この図は、[新しいアセット]ダイアログボックスを示しています。")
![[定義]ページに、[名前]、[場所]、および[説明]などの入力フィールドが表示され、ファイル選択用の[参照]オプションが表示されています。[エージェントのみ]、[ODataの使用]、および[OAuth 2.0の使用]のチェックボックスが表示されています。[保存]、[パブリッシュ]、およびその他のアクションが上部に表示されています。](../cc-design/images/GUID-6D124C1E-0D14-4EE0-80CE-40B68B3122E1-low.png "[定義]ページに、[名前]、[場所]、および[説明]などの入力フィールドが表示され、ファイル選択用の[参照]オプションが表示されています。[エージェントのみ]、[ODataの使用]、および[OAuth 2.0の使用]のチェックボックスが表示されています。[保存]、[パブリッシュ]、およびその他のアクションが上部に表示されています。")
![この図は、[アクション]タブを示しています。](../cc-design/images/GUID-805284DE-89A2-4015-9A94-93CA21845D9C-low.png "この図は、[アクション]タブを示しています。")
![この図は、[入力]タブを示しています。](../cc-design/images/GUID-8768A557-4176-473D-964C-5045811CB44D-low.png "この図は、[入力]タブを示しています。")
![この画像は、ストアドプロシージャにサンプル値が指定された[ストアドプロシージャの呼び出し]ページを示しています。](../cc-design/images/GUID-8C75DA4E-D0CE-441A-B4EE-486231053E1F-low.png "この画像は、ストアドプロシージャにサンプル値が指定された[ストアドプロシージャの呼び出し]ページを示しています。")
![この画像は、[出力]タブのサービスコネクタの出力フィールドにマッピングされた出力フィールドを示しています。](../cc-design/images/GUID-B6C792AF-31AF-45AB-90CD-922DABE45923-low.png "この画像は、[出力]タブのサービスコネクタの出力フィールドにマッピングされた出力フィールドを示しています。")
![この図は、[出力]タブを示しています。](../cc-design/images/GUID-54836657-3746-47C4-86DB-C743DA7FC1E6-low.png "この図は、[出力]タブを示しています。")
![この図は、[プロセスオブジェクト]タブを示しています。](../cc-design/images/GUID-DD9DD2D5-C011-432D-8663-863B5DF259F9-low.png "この図は、[プロセスオブジェクト]タブを示しています。")