データベース取り込みとレプリケーション タスクの設定データ統合 で、データベース取り込みとレプリケーション タスクウィザードを使用してデータベース取り込みとレプリケーション タスクを設定します。
ウィザードページで、次の設定タスクを完了します。
1 2 3 4 [次へ] または[戻る] をクリックして別のページに移動します。いつでも[保存] をクリックして、これまでに入力した情報を保存できます。
すべてのウィザードページを完了したら、情報を保存し、[デプロイ] をクリックして、タスクを実行可能ジョブとしてSecure Agentで使用できるようにします。
始める前に 開始する前に、Administratorで次の要件タスクを完了してください。
• データベース取り込みとレプリケーション およびDBMIパッケージのライセンスがあることを確認してください。• データ取り込みおよびレプリケーション サービスにアクセスできることを確認します。• また、Oracleソースを使用して増分ロード操作を実行する場合は、Secure AgentシステムでORACLE_HOME環境変数が定義されていることを確認してください。
基本的なタスク情報の定義 データベース取り込みとレプリケーション タスクの定義を開始するには、最初に、タスク名、プロジェクトまたはプロジェクトフォルダの場所、ロード操作の種類など、タスクに関するいくつかの基本情報を入力する必要があります。
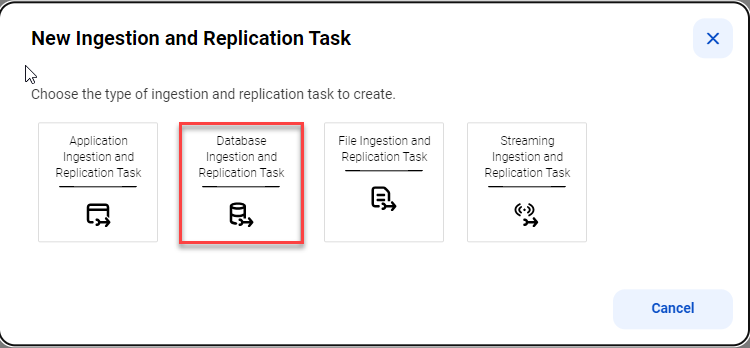
1 以下のいずれかの方法でタスクウィザードを開始します。
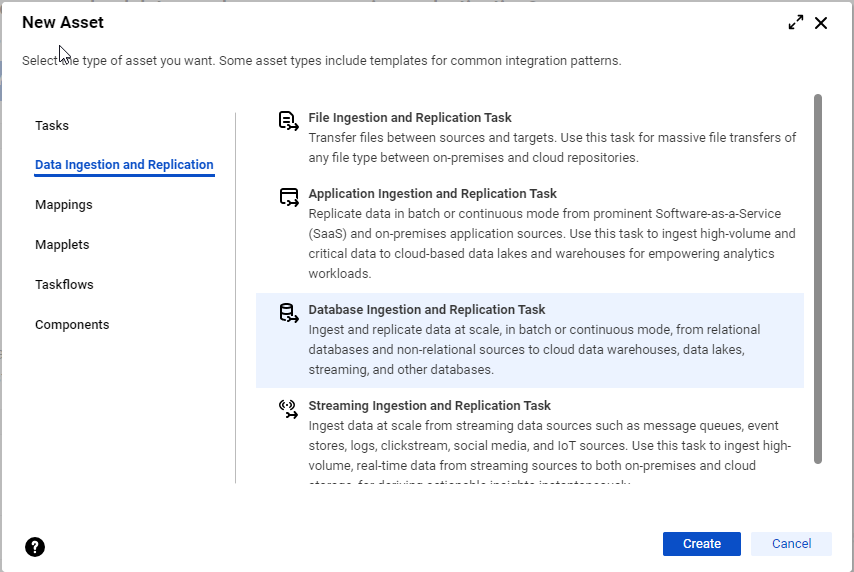
- [取り込み] パネルをクリックし、[データベース取り込みおよびレプリケーションタスク] を選択します。- [参照] ページまたはホームページのナビゲーションバーで、[新規] をクリックして、[新しいアセット] ダイアログボックスを開きます。次に、[データ取り込みおよびレプリケーション] > [データベース取り込みおよびレプリケーションタスク] を選択して、[作成] をクリックします。注: 組織に、アプリケーション、データベース、ファイル、またはストリーミングの各取り込みおよびレプリケーションのカスタムライセンスがない場合、[データ取り込みおよびレプリケーション] カテゴリは引き続き表示されますが、ライセンスのないタスクタイプの取り込みおよびレプリケーションタスクを選択して設定することはできません。
データベース取り込みとレプリケーション タスクウィザードの[定義] ページが表示されます。
2 以下のプロパティを設定します。
プロパティ
説明
名前
データベース取り込みとレプリケーション タスクの名前。
タスク名には、ラテン英数字、スペース、ピリオド(.)、コンマ(,)、アンダースコア(_)、プラス記号(+)、およびハイフン(-)を含めることができます。タスク名に他の特殊文字を含めることはできません。
タスク名では大文字と小文字は区別されません。
最大長は50文字です。
注: データベース取り込みとレプリケーション タスク名にスペースを含めると、タスクをデプロイした後、対応するジョブ名にスペースが表示されなくなります。
場所
タスク定義を含むプロジェクトまたはプロジェクト\フォルダ。デフォルトは、Exploreで現在選択されているプロジェクトまたはプロジェクトのサブフォルダです。プロジェクトまたはプロジェクトのサブフォルダが選択されていない場合、デフォルトは[デフォルト] プロジェクトになります。
ランタイム環境
タスクを実行するランタイム環境。
ランタイム環境は、1つ以上のSecure Agentで構成されるSecure Agentグループである必要があります。Secure Agentは、タスクを実行し、安全な通信を可能にする軽量のプログラムです。
データベース取り込みおよびレプリケーションタスクの場合、Cloudホステッドエージェントはサポートされておらず、[ランタイム環境] リストに表示されません。サーバーレスランタイム環境もサポートされていません。
ヒント: [更新] アイコンをクリックして、ランタイム環境のリストを更新します。
説明
タスクのオプションの説明。
最大長は4,000文字です。
ロードタイプ
データベース取り込みとレプリケーション タスクを実行するロード操作のタイプ。次のオプションがあります。
- 初期ロード 。特定の時点で読み取られたデータを、バッチ操作でソーステーブルからターゲットにロードします。初期ロードを実行して、増分変更データの送信先となるターゲットをマテリアライズできます。- 増分ロード 。ソースデータの変更を継続的に、またはジョブが停止または終了するまでターゲットにプロパゲートします。ジョブは、ジョブが最後に実行されてから、または最初のジョブ実行の特定の開始点から発生した変更をレプリケートします。- 初期ロードと増分ロード 。ターゲットへのポイントインタイムデータの初期ロードを実行してから、同じソーステーブルに対して継続的に行われた増分データ変更のレプリケートに自動的に切り替わります。注: 初期アンロードロードフェーズ中に変更レコードがキャプチャされた場合、その変更レコードはアンロードフェーズが完了するまで適用処理の対象から外されます。アンロードフェーズ中にキャプチャされた挿入行は、削除操作と挿入操作のペアに変換され、アンロードされたデータとキャプチャされた変更データの両方で挿入が発生した場合は、1つの挿入行のみがターゲットに適用されるようになります。
3 [次へ] をクリックします。
ソースの設定 データベース取り込みとレプリケーション タスクウィザードの[ソース] ページでソースを設定します。
注: MongoDBソースの場合のみ、タスクウィザードはスキーマの代わりにデータベースを表示し、テーブルの代わりにコレクションを表示します。ただし、このドキュメントでは、単純化するため、すべてのソースタイプを網羅するようにスキーマとテーブルという用語を使用しています。
1 [接続] リストで、ソースシステムの接続を選択します。接続タイプは、接続名の後の括弧内に表示されます。
組織が使用するランタイム環境の接続は、管理者 で事前定義する必要があります。
リストには、[定義] ページで選択されたロードタイプに有効な接続タイプのみが含まれます。ロードタイプを選択しなかった場合、接続は一覧表示されません。
ロードタイプを変更し、選択した接続が無効になると、警告メッセージが発行され、[接続] フィールドがクリアされます。更新されたロードタイプに有効な別の接続を選択する必要があります。
注: データベース取り込みとレプリケーション タスクをデプロイした後は、先に関連するジョブをデプロイ解除しないと、接続を変更することはできません。接続を変更した後、タスクを再度デプロイする必要があります。
2 [スキーマ] リストで、ソーステーブルを含むソーススキーマを選択します。接続プロパティでスキーマを指定した場合、そのスキーマはデフォルトで選択されますが、変更できます。
リストには、指定されたソース接続でアクセスされるデータベースで使用可能なスキーマのみが含まれます。
Oracle、Microsoft SQL Server、Netezza、またはPostgreSQLソースを持つタスクを作成する場合、接続プロパティで指定されたスキーマ名がデフォルトで表示されます。
3 増分ロードタスク用にDB2 for iソースを定義する場合は、 [ジャーナル名] フィールドで、ソーステーブルに加えられた変更を記録するジャーナルの名前を選択します。
4 増分ロードタスク、または初期ロードと増分ロードの組み合わせタスクのPostgreSQLソースを定義する場合は、次のフィールドに入力します。
フィールド
説明
レプリケーションスロット名
PostgreSQLレプリケーションスロットの一意の名前。
スロット名には、小文字のラテン英数字とアンダースコア(_)文字を含めることができます。
最大長は63文字です。
重要: 各データベース取り込みとレプリケーション タスクは、異なるレプリケーションスロットを使用する必要があります。
レプリケーションプラグイン
PostgreSQLレプリケーションプラグイン。次のオプションがあります。
- pgoutput 。このオプションは、PostgreSQLバージョン10以降でのみ選択できます。- wal2json パブリケーション
レプリケーションプラグインとしてpgoutput を選択した場合は、このプラグインが使用するパブリケーション名を指定します。
注: レプリケーションプラグインとしてwal2jsonを選択した場合、このフィールドは表示されません。
5 Db2 for LUW、Oracle、またはSQL Serverソースを持つ増分ロードタスク、または初期ロードと増分ロードの組み合わせタスクを定義する場合は、 [変更データキャプチャメソッド] で使用するキャプチャメソッドを選択します。
a [CDCメソッド] フィールドで、次のオプションのいずれかを選択して、ソースの変更をキャプチャするために使用するメソッドを指定します。 方法
サポートされるソース
説明
CDCテーブル
SQL Serverのみ
SQL Server CDCテーブルからデータ変更を直接読み取ります。
SQL Serverソースの場合は、この方法によって最高のレプリケーションパフォーマンスが得られ、結果の信頼性が最大になります。
ログベース
OracleおよびSQL Server
データベーストランザクションログを読み取ることによって、挿入、更新、削除、およびカラムのDDL変更を近似リアルタイムでキャプチャします。
Oracleソースの場合、データ変更はOracle REDOログから読み取られます。
SQL Serverソースの場合、データ変更はSQL Serverトランザクションログと有効なSQL Server CDCテーブルから読み取られます。例外: Azure SQL Databaseソースの場合、データ変更はCDCテーブルからのみ読み取られます。
クエリベース
Db2 for LUW、Oracle、およびSQL Server
CDCクエリカラムを指すSQL WHERE句を使用して、挿入と更新をキャプチャします。クエリカラムは、CDC間隔の開始以降にソーステーブルに加えられた変更を含む行の識別に使用されます。
増分ロードジョブおよび初期ロードと増分ロードの組み合わせジョブのDb2 for LUWソースの場合、このキャプチャメソッドのみ使用できます。
b [クエリベース] オプションを選択した場合は、次の追加フィールドに入力します。 ▪ CDCクエリカラムタイプ 。ソーステーブルにおけるCDCクエリカラムのカラムタイプです。利用可能な唯一のオプションは[タイムスタンプ] です。Note: 「タイムスタンプ」は、日付と時刻を組み合わせたカラムデータ型を表します。Oracleの場合、クエリカラムでサポートされるデータ型はTIMESTAMPです。SQL Serverの場合、クエリカラムでサポートされるデータ型はDATETIMEとDATETIME2です。
▪ CDCクエリカラム名 。ソーステーブルにおけるCDCクエリカラムの、大文字小文字が区別された名前です。カラムはソーステーブルに存在する必要があります。最大長は70文字です。▪ CDC間隔 。日数、時間数、分数で表される、クエリベースの変更データキャプチャサイクルの頻度です。少なくとも1つの間隔フィールドに正の数値を入力する必要があります。入力しない場合、タスクを保存しようとすると、エラーが発生します。デフォルト値は5分です。6 [テーブルの選択] で、以下のいずれかの方法を使用してソーステーブルを選択します。
7 データベースビューをソースとして含める場合は、[更新]アイコンの右側にある [ビューを含める] チェックボックスを選択します。このチェックボックスは、Db2 for i、Db2 for LUW、Microsoft SQL Server、MySQL、Oracle、PostgreSQL、またはTeradataソースを持つ初期ロードタスクでのみ使用できます。
ビューが取得され、[選択されたテーブル] のカウント、およびテーブル名のリストに含まれます。
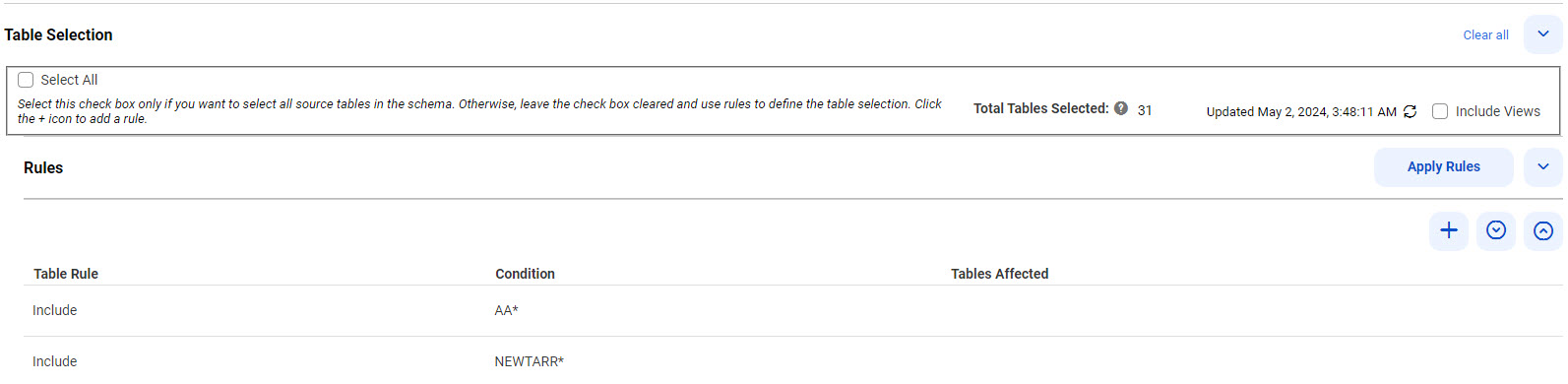
8 テーブル選択ルールを追加するには、まず [すべて選択] チェックボックスがオフになっていることを確認します。次に、以下のサブステップを実行します。
a [ルール] で、最初のテーブルの上にある[ルールの追加](+)アイコンをクリックします。テーブルに行が追加されます。 b [テーブルルール] カラムで [含める] または [除外する] を選択して、包含ルールまたは除外ルールを作成します。 c [条件] カラムに、テーブル名、または1つ以上のワイルドカードを含むテーブル名マスクを入力して、テーブル選択に含める、またはテーブル選択から除外するソーステーブルを特定します。次のガイドラインを使用します。 ▪ ▪ ▪ ▪ d 必要に応じて追加のルールを定義します。 含めるルールと除外ルールを複数定義すると、一覧表示されている順序で上から下に処理されます。矢印アイコンを使用して順序を変更します。複数のルールを使用する例については、「
ソーステーブルを選択するルールの例 」を参照してください。
e 終了したら、 [ルールの適用] をクリックします。 [選択されたテーブルの総数] と[テーブルビュー] の数が更新されます。[更新]アイコンをクリックすると、各ルールの[影響を受けるテーブル] の数が表示されます。
次の図は、[ソース] ページで定義した複数のルールを示しています。
ルールの適用後にルールを追加、削除、または変更する場合は、[ルールの適用] を再度クリックする必要があります。[更新]アイコンをクリックして、テーブル数を更新します。[ルールの適用] をクリックせずにすべてのルールを削除した場合、デプロイ時に検証エラーが発生します。[テーブルビュー] リストには引き続きテーブルが表示されます。[すべて選択] に切り替えると、ルールは無効になり、表示されなくなります。
9 ルールに基づいて選択されたソーステーブルの文字カラムに対して切り捨てアクションを実行するには、 [ルール] にある2番目の[アクション]テーブルでカラムアクションルールを作成します。
注: MongoDBソースに対してカラムアクションルールを作成することはできません。
a 2番目のテーブルの上にある[ルールの追加](+)アイコンをクリックします。 b [アクション] カラムで、次のいずれかのオプションを選択します。 ▪ LTRIM .文字カラム値の左側のスペースを切り捨てます。▪ RTRIM .文字カラム値の右側のスペースを切り捨てます。▪ TRIM .文字カラム値の左側と右側のスペースを切り捨てます。c [条件] カラムに、カラム名または1つ以上のアスタリスク(*)または疑問符(?)を含むカラム名マスクを入力します。ワイルドカード。値は、アクションが適用されるカラムを識別するために、選択したソーステーブルのカラムと照合されます。 注: 異なるアクションタイプに対して、あるいは条件が異なる同じアクションタイプに対して複数のルールを定義できます。ルールは、リストされている順序で上から下に処理されます。矢印アイコンを使用して順序を変更します。
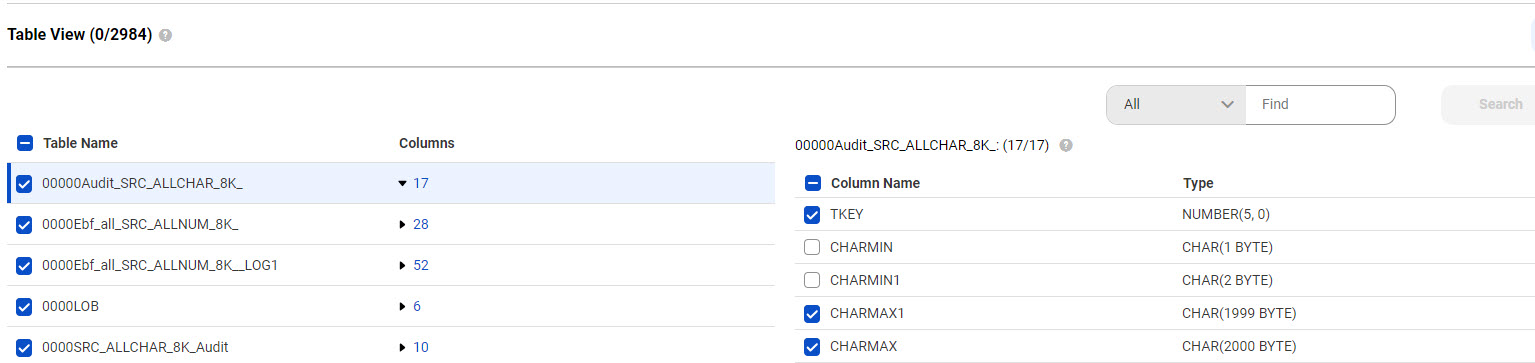
10 [テーブルビュー] で、選択したソーステーブルとカラムのセットを表示または編集します。
[すべて選択] を選択した場合、テーブルとカラムのリストは表示専用です。
ルールを適用した場合は、個々のテーブルの横にあるチェックボックスをクリックして、選択したテーブルのセットを絞り込むことができます。レプリケートしないテーブルの選択を解除するか、レプリケートする追加の項目を選択します。[更新]アイコンをクリックして、選択したテーブルの数を更新します。
OracleおよびSQL Serverソースの場合のみ、選択したソーステーブルのカラムを個別に選択解除または再選択することもできます。選択したテーブルのデータのレプリケート元のカラムを表示または変更するには、[カラム] カラムにある、強調表示されたカラム数をクリックします。カラム名とデータ型が右側に表示されます。デフォルトでは、選択したソーステーブルのすべてカラムが選択されています。カラムを選択解除または再選択するには、カラム名の横にあるチェックボックスをクリックします。プライマリキーカラムを選択解除することはできません。
次の図は、選択したテーブルと、最初のテーブルで選択したカラムを示しています。
注:
- [テーブル名] 、[カラム] 、または[すべて] を選択し、[検索]ボックスに検索文字列を入力して[検索] をクリックします。文字列の先頭または末尾にアスタリスク(*)ワイルドカードを1つ含めることができます。- [テーブルビュー] の選択内容が優先されます。ただし、[ルールの追加](+)アイコンを再度クリックすると、個別に選択解除または選択したテーブルが、新しいルールとして[ルール]リストに反映され、ルールが再び優先されます。[テーブルビュー] リストに戻るには、[ルールの適用] を再度クリックします。- [テーブルビュー] セクションには、文字カラムの長さがバイト単位で示されます。文字あたりのバイト数はデータベースで使用される文字セットエンコーディングによって異なるため、一部のソースでは、実際のカラムの長さの文字数が[テーブルビュー] に表示されるバイト数と異なる場合があります。- - 注: 選択したカラムを削除しても、再同期操作はトリガされず、エラーは報告されません。選択したカラムの削除は、カラム削除イベントと同じように扱われ、タスクのカラム削除スキーマのドリフト設定がトリガされます。
11 DB2 for i、DB2 for z/OS、Microsoft SQL Server、Oracle、PostgreSQL、SAP HANA、またはSAP HANA Cloudソースを持つ増分ロードタスク、または初期ロードタスクと増分ロードタスクの組み合わせを定義しようとしていて、選択したソーステーブルの1つ以上で変更データキャプチャが有効になっていない場合は、CDCを有効にするためのスクリプトを生成してから、スクリプトを実行またはダウンロードできます。
注: Db2 for LUW、Oracle、またはSQL ServerソースのCDCメソッドとして[クエリベース] を選択した場合、[CDCスクリプト] フィールドはクエリベースの変更キャプチャメソッドには適用できないため、使用できません。
a [CDCスクリプト] フィールドで、次のオプションのいずれかを選択します。 スクリプトは、ソースタイプに応じて、次の方法でCDCを有効にします。
▪ ▪ ▪ msdb.dbo.rds_cdc_enable_db プロシージャを実行してソースデータベースでCDCを有効にし、sys.sp_cdc_enable_table スクリプトを実行してテーブルのCDCを追跡します。▪ ▪ ▪ b スクリプトを実行するには、 [実行] をクリックします。 スクリプトを実行できるデータベースロールまたは特権がない場合は、[ダウンロード]アイコンをクリックしてスクリプトをダウンロードします。スクリプトファイル名の形式は次のとおりです。cdc_script_ taskname _ number .txt 次に、データベース管理者にスクリプトの実行を依頼します。
データベース取り込みとレプリケーション タスクを実行する前に、スクリプトが実行されていることを確認してください。
注: 後で[CDCスクリプト] オプションに変更して、スクリプトを再度実行すると、スクリプトは最初に元のカラムセットに対するCDCを削除し、次に現在のカラムセットに対してCDCを有効にします。SAP HANAソースの場合、PROCESSEDテーブルとPKLOGテーブルがすでに存在するときは、それらは新しいスクリプトから省略されます。シャドー_CDCテーブルとトリガが、選択されたいずれかのテーブルにすでに存在する場合、それらのオブジェクトを作成するSQL文は、新しいスクリプトではコメントアウトされます。
12 Microsoft SQL Serverソースの場合は、次のフィールドに入力します。
- [キャプチャファイルグループ] フィールドに、キャプチャ用に作成される変更テーブルに使用するファイルグループの名前を入力します。このフィールドを空のままにすると、変更テーブルはデータベースのデフォルトのファイルグループに配置されます。- [ゲートロール] フィールドに、データを変更するためのアクセスをゲートするために使用されるデータベースロールの名前を入力します。このフィールドを空のままにすると、データベースはゲートロールを使用しません。13 テーブル選択条件に一致するソーステーブルのリストを作成してダウンロードするには、次のサブ手順を実行します。
a ルールベースのテーブル選択を使用した場合は、 [ルールタイプ別のテーブルのリスト] で、使用する選択ルールのタイプを選択します。次のオプションがあります。 ▪ 含めるルールのみ ▪ 除外ルールのみ ▪ 含めるルールと除外ルール b 使用したテーブル選択方法に関係なく、リストにカラムを含めるには、 [カラムを含める] チェックボックスを選択します。 注: このオプションはMongoDBソースでは使用できません。
c [ダウンロード]アイコンをクリックします。 カラムを含むダウンロードしたリストの形式は次のとおりです。
status ,schema_name ,table_name ,object_type ,column_name ,comment
次の表に、ダウンロードしたリストに表示される情報を示します。
フィールド
説明
status
データベース取り込みとレプリケーション にサポートされていないタイプがある場合に、ソーステーブルまたはカラムを処理から除外するかどうかを示します。有効な値は以下のとおりです。
- E 。オブジェクトは、除外ルールによって処理から除外されます。- I : オブジェクトは処理に含まれます。- X 。このオブジェクトはサポートされていないタイプのオブジェクトであるため、処理から除外されます。例えば、サポートされていないタイプのオブジェクトには、サポートされていないデータ型のカラムと、サポートされていないカラムのみを含むテーブルが含まれます。コメントフィールドに、サポートされていないタイプの詳細が示されます。schema_name
ソーススキーマの名前を指定します。
table_name
ソーステーブルの名前を指定します。
object_type
ソースオブジェクトのタイプを指定します。有効な値は以下のとおりです。
column_name
ソースカラムの名前を指定します。この情報は、[カラム] チェックボックスを選択した場合にのみ表示されます。
comment
サポートされていないタイプのソースオブジェクトが、選択ルールに一致していても処理から除外される理由を指定します。
14 [詳細] で、ソースタイプとロードタイプに応じて使用できる詳細プロパティを設定します。
プロパティ
ソースとロードタイプ
説明
フラッシュバックの無効化
Oracleソース - 初期ロード
データベースからデータを取得するときにデータベース取り込みとレプリケーション がOracle Flashbackを使用できないようにするには、このチェックボックスを選択します。
Oracle Flashbackを使用するには、ユーザーにEXECUTE ON DBMS_FLASHBACK権限を付与する必要があります。これは、初期ロードには必要ありません。
このチェックボックスは、新しい初期ロードタスクに対してデフォルトで選択されています。既存の初期ロードタスクの場合、このチェックボックスはデフォルトでクリアされているため、Oracle Flashbackは有効のままになります。パーティション化が有効なタスクの場合、このチェックボックスは自動的に選択され、編集できません。
LOBを含める
Oracleソース:
- 増分ロードおよび組み合わせロードでは、[ログベース] または[クエリベース] のCDCメソッドのいずれかを使用できます。ただし、[ログベース] のCDCメソッドを使用するジョブは、LONG、LONG RAW、およびXMLカラムのデータを、生成されたターゲットカラムにレプリケートしません。
Db2 for LUWソース:
- [クエリベース] のCDCメソッドを使用する必要があります。PostgreSQLソース:
- - - SQL Serverソース:
- - [クエリベース] のCDCメソッドを選択した場合は無効になります。- [クエリベース] のCDCメソッドを選択した場合は無効になります。ターゲットにデータをレプリケートするラージオブジェクト(LOB)カラムがソースに含まれている場合は、このチェックボックスを選択します。
LOBデータ型:
- - - - LOBデータは、主にターゲットで許可されている最大サイズに応じて切り詰められる場合があります。
ターゲット側の切り詰めポイント:
- - - - - - - - - - - - ソース側の切り詰めに関する考慮事項:
- - 永続ストレージの有効化
Db2 for LUW(クエリベースのCDC)、MongoDB、Oracle(クエリベースのCDC)、PostgreSQL、SAP HANA、SAP HANA Cloud、およびSQL Server(クエリベースのCDC)を除くすべてのソース - 増分ロード、および初期ロードと増分ロードの組み合わせ。
クエリベースのCDCメソッドを使用するDb2 for LUW、Oracle、およびSQL Serverソースの場合、このフィールドは表示されません。これは、永続ストレージがデフォルトで有効になっていて変更できないためです。
MongoDB、PostgreSQL、SAP HANA、およびSAP HANA Cloud変更データソースの場合、永続ストレージがデフォルトで有効になっていて変更できないため、このフィールドは表示されません。
ターゲットへのデータの書き込みが遅い場合や遅延している場合でもデータを継続的に使用できるようにディスクバッファへのトランザクションデータの永続ストレージを有効にするには、このチェックボックスを選択します。
永続ストレージを使用する利点は、ソーストランザクションログの消費が高速になり、ログアーカイブやバックアップへの依存度が低くなるため、データベース取り込みジョブを再開した後もディスクストレージ内の永続データに引き続きアクセスできることです。
パーティション化の有効化
Oracleソース - 初期ロード、および初期ロードと増分ロードの組み合わせ
SQL Serverソース - 初期ロード、および初期ロードと増分ロードの組み合わせ
ソースオブジェクトのパーティション化を有効にする場合は、このチェックボックスを選択します。オブジェクトがパーティション化されると、データベース取り込みとレプリケーション ジョブは、各パーティションから読み取ったレコードを並列処理します。
Oracleソースの場合、データベース取り込みとレプリケーション はROWIDをパーティションキーとして使用して、パーティションの範囲を決定します。また、[パーティション化の有効化] チェックボックスを選択すると、[フラッシュバックの無効化] チェックボックスが自動的に選択されます。
SQL Serverソースの場合、パーティション化はプライマリキーに基づきます。
注: 初期ロードと増分ロードを組み合わせた場合、ソースオブジェクトのパーティション化は初期ロードフェーズでのみ行われます。
パーティションの数
Oracleソース - 初期ロード、および初期ロードと増分ロードの組み合わせ
SQL Serverソース - 初期ロード、および初期ロードと増分ロードの組み合わせ
ソースオブジェクトのパーティション化を有効にする場合、作成するパーティションの数を入力します。デフォルト数は5です。最小値は2です。
増分ロード操作の当初の開始点
すべてのソース - 増分ロード
ソースログ内の位置をカスタマイズする場合は、このフィールドを設定します。データベース取り込みとレプリケーション ジョブは、最初に実行されたときに変更レコードの読み取りをこの位置から開始します。
次のオプションがあります。
デフォルトは[使用可能な最新] です。
取得サイズ
MongoDB - 初期ロードと増分ロード
MongoDBソースの場合、データベース取り込みとレプリケーション ジョブがソースから一度に読み取る必要があるレコードの数。有効な値は1~2147483647です。デフォルトは5000。
15 [カスタムプロパティ] で、特別な要件を満たすためにInformaticaが提供するカスタムプロパティを指定できます。プロパティを追加するには、 [プロパティの作成] フィールドに、プロパティの名前と値を入力します。次に、 [プロパティの追加] をクリックします。
これらのプロパティを指定する場合は、Informaticaグローバルカスタマサポートにお問い合わせください。通常、これらのプロパティは、固有の環境または特別な処理のニーズに対応します。必要に応じて、複数のプロパティを指定できます。プロパティ名には、英数字と次の特殊文字のみを含めることができます: ピリオド(.)、ハイフン(-)、およびアンダースコア(_)。
ヒント: プロパティを削除するには、リストのプロパティ行の右端にある[削除]アイコンをクリックします。
16 [次へ] をクリックします。
ソーステーブルを選択するルールの例 データベース取り込みとレプリケーション タスクのソースを定義する場合、必要に応じてテーブル選択ルールを定義して、指定したスキーマのソーステーブルのサブセットを選択できます。この簡単な例は、選択ルールを使用して必要なテーブルを選択する方法を示しています。
2984個のテーブルがソーススキーマにあると仮定します。データをレプリケートする必要のないテーブルを除外したいとします。
次のルールを示されている順序で定義します。
ルールは上から下に処理されます。
• • • • [更新]アイコンをクリックした後、[選択されたテーブル] フィールドには2289個のテーブルが表示されます。これは、695個のテーブルが除外されたことを示します。
ターゲットの設定 データベース取り込みとレプリケーション タスクウィザードの[ターゲット] ページでターゲットを設定します。
1 [接続] リストで、ターゲットタイプの接続を選択します。接続タイプは、接続名の後の括弧内に表示されます。
ランタイム環境の接続を管理者 で事前に定義しておく必要があります。
リストには、[定義] ページで選択されたロードタイプに有効な接続タイプのみが含まれます。ロードタイプを選択しなかった場合、接続は一覧表示されません。
ロードタイプを変更し、選択した接続が無効になると、警告メッセージが発行され、[接続] フィールドがクリアされます。更新されたロードタイプに有効な別の接続を選択する必要があります。
注: データベース取り込みとレプリケーション タスクをデプロイした後は、先に関連するジョブをデプロイ解除しないと、接続を変更することはできません。その後、タスクを再度デプロイする必要があります。
2 [ターゲット] セクションで、ターゲットタイプに関連するプロパティを構成します。
これらのプロパティの説明については、次のトピックを参照してください。
3 選択したソーステーブルに関連付けられているターゲットオブジェクトの名前を変更する場合は、テーブルの名前変更ルールを定義します。
4 ソースデータ型からターゲットデータ型へデフォルトのマッピングをオーバーライドする場合は、データ型ルールを定義します。
この機能は、Oracle(いずれかのロードタイプ)ソースとSQLベースのターゲットタイプを持つタスクに対してのみサポートされています。詳細については、
データ型マッピングのカスタマイズ を参照してください。
5 [カスタムプロパティ] で、特別な要件を満たすためにInformaticaが提供するカスタムプロパティを指定できます。プロパティを追加するには、 [プロパティの作成] フィールドに、プロパティの名前と値を入力します。次に、 [プロパティの追加] をクリックします。
これらのプロパティを指定する場合は、Informaticaグローバルカスタマサポートにお問い合わせください。通常、これらのプロパティは、固有の環境または特別な処理のニーズに対応します。必要に応じて、複数のプロパティを指定できます。プロパティ名には、英数字と次の特殊文字のみを含めることができます: ピリオド(.)、ハイフン(-)、およびアンダースコア(_)。
ヒント: プロパティを削除するには、リストのプロパティ行の右端にある[削除]アイコンボタンをクリックします。
6 ある場合は [次へ] をクリックするか、または [保存] をクリックします。
ターゲットのテーブルの名前変更 既存のスキーマを使用してターゲットを設定する場合、オプションで、選択したソーステーブルに対応するターゲットテーブルの名前を変更するためのルールを定義できます。
Apache Kafkaなどのターゲットメッセージングシステムの場合、ルールは出力メッセージのテーブル名を変更します。
テーブルの名前を変更するためのルールを作成するには、次の手順を実行します。
1 [テーブルの名前変更ルール] の[ルールの作成] フィールドに、ソーステーブル名または1つ以上のワイルドカードを含むテーブル名マスクを入力します。次に、対応するターゲットテーブル名またはテーブル名マスクを入力します。 2 [ルールの追加] をクリックします。ルールがルールリストに表示されます。
複数のテーブルルールを定義できます。テーブルが複数のルールに一致していない限り、処理方法においてはルールの順序は重要ではありません。この場合、最後に一致するルールによってテーブルの名前が決まります。
ルールを削除するには、ルール行の右端にある[削除]アイコンをクリックします。
例:
選択したすべてのソーステーブルに対応するターゲットテーブルの名前にプレフィックス「PROD_」を追加するとします。次の値を入力します。
• • データ型マッピングのカスタマイズ データベース取り込みとレプリケーション タスクのターゲットを設定する場合、必要に応じてデータ型マッピングルールを定義して、ソースデータ型からターゲットデータ型へのデフォルトのマッピングをオーバーライドできます。
デフォルトのマッピングについては、「
デフォルトデータ型のマッピング 」を参照してください。
この機能は、次のソースとターゲットの組み合わせを持つタスクでサポートされています。
• • 例えば、Snowflake VARCHAR(255)データ型へのデフォルトのマッピングを使用する代わりに、精度のないOracle NUMBERカラムを、同じく精度のないSnowflakeターゲットのNUMBER()カラムにマッピングするデータ型ルールを作成できます。
データ型マッピングルールを作成するには、次の手順を実行します。
1 [データ型ルール] を展開します。2 [ルールの作成] フィールドに、ソースデータ型とそれをマッピングするターゲットデータ型を入力します。[ソース] フィールドでのみ、例えば、NUMBER(%,4)、NUMBER(8,%)、またはNUMBER(%)のように、パーセント(%)ワイルドカードを含めて、データ型の精度、スケール、またはサイズを表すことができます。同じデータ型だが精度、スケール、またはサイズ値が異なるソースカラムのそれぞれを個別に指定するのではなく、ワイルドカードを使用して、そのようなすべてのソース列をカバーします。例えば、FLOAT(16)、FLOAT(32)、FLOAT(84)をカバーするには、FLOAT(%)と入力します。ターゲットデータ型に%ワイルドカードを入力することはできません。%ワイルドカードを使用するソースデータ型は、特定の精度、スケール、またはサイズ値を使用するターゲットデータ型にマッピングする必要があります。例えば、ソースデータ型FLOAT(%)をNUMBER(38,10)などのターゲットデータ型の仕様にマッピングできます。
3 [ルールの追加] をクリックします。ルールがルールリストに表示されます。
ルールを削除するには、ルール行の右端にある[削除]アイコンをクリックします。
カスタムマッピングルールを使用してタスクをデプロイした後は、タスクがデプロイ解除されるまでルールを編集できません。
使用上の注意:
• • データベース取り込みとレプリケーション タスクを保存できなくなります。• • • • select dbms_metadata.get_ddl('TABLE', 'YOUR_TABLE_NAME','TABLE_OWNER_NAME') from dual;
• データベース取り込みとレプリケーション は、データ型マッピングルールのBYTEおよびCHARセマンティクスをサポートしていません。• Amazon Redshiftターゲットのプロパティ Amazon Redshiftターゲットのあるデータベース取り込みとレプリケーション タスクを定義する場合、タスクウィザードの[ターゲット] タブでターゲットのいくつかのプロパティを入力する必要があります。
次の表は、[ターゲット] に表示されるAmazon Redshiftターゲットのプロパティについて説明しています。
プロパティ
説明
ターゲット作成
利用可能なただ1つのオプションは、[ターゲットテーブルを作成する] であり、これによりソーステーブルをベースにしてターゲットテーブルを生成します。
注: ターゲットテーブルが作成された後、データベース取り込みとレプリケーション は、後続のジョブ実行でターゲットテーブルをインテリジェントに処理します。データベース取り込みとレプリケーション は、特定の状況に応じて、ターゲットテーブルを切り詰めたり再作成したりする場合があります。
スキーマ
データベース取り込みとレプリケーション がターゲットテーブルを作成するターゲットスキーマを選択します。
バケット
Amazon Redshiftに読み込むデータオブジェクトへのアクセスを保存、整理、制御するAmazon S3のバケットコンテナの名前を指定します。
データディレクトリまたはタスクターゲットディレクトリ
データベース取り込みとレプリケーション がタスクに関連付けられたジョブの出力ファイルを格納するサブディレクトリを指定します。このフィールドは、初期ロードジョブの場合は[データディレクトリ] 、増分ロードジョブ、または初期ロードと増分ロードの組み合わせジョブの場合は[タスクターゲットディレクトリ] と呼ばれます。
次の表は、[詳細] に表示されるターゲットの詳細プロパティについて説明しています。
プロパティ
説明
大文字と小文字の変換を有効にする
デフォルトでは、ターゲットテーブル名およびカラム名は、対応するソース名と同じ大文字と小文字で生成されます。ただし、ターゲットのクラスタレベルまたはセッションレベルのプロパティがこの大文字と小文字を区別する動作をオーバーライドしている場合を除きます。ターゲット名の大文字と小文字を制御する場合は、このチェックボックスを選択します。次に、[大文字と小文字の変換ストラテジ] オプションを選択します。
大文字と小文字の変換ストラテジ
[大文字と小文字の変換を有効にする] を選択した場合は、以下のいずれかのオプションを選択して、生成されたターゲットテーブル(またはオブジェクト)名およびカラム(またはフィールド)名の大文字と小文字の処理方法を指定します。
- ソースと同じ 。ソーステーブル(またはオブジェクト)名およびカラム(またはフィールド)名と同じ大文字と小文字を使用します。- UPPERCASE 。すべて大文字を使用します。- lowercase 。すべて小文字を使用します。デフォルト値は、[ソースと同じ] です。
注: 選択したストラテジは、大文字と小文字の制御に関するターゲットのクラスタレベルまたはセッションレベルのプロパティをオーバーライドします。
Amazon S3ターゲットのプロパティ Amazon S3ターゲットのあるデータベース取り込みとレプリケーション タスクを定義する場合、タスクウィザードの[ターゲット] タブでターゲットのいくつかのプロパティを入力する必要があります。
[ターゲット] では、次のAmazon S3ターゲットのプロパティを入力できます。
プロパティ
説明
出力形式
出力ファイルの形式を選択します。次のオプションがあります。
デフォルトの値は[CSV] です。
注: CSV形式の出力ファイルでは、各フィールドの区切り文字として二重引用符("")が使用されます。
CSVファイルへのヘッダーの追加
[CSV] が出力形式として選択されている場合は、このチェックボックスをオンにして、ソース列名を含むヘッダーを出力CSVファイルに追加します。
Avro形式
出力形式として[AVRO] を選択した場合、ソーステーブルごとに作成されるAvroスキーマの形式を選択します。次のオプションがあります。
- Avro-Flat 。すべてのAvroフィールドを1つのレコードに一覧表示する場合に、このAvroスキーマ形式を使用します。- Avro-Generic 。ソーステーブルのすべてのカラムをAvroフィールドの単一の配列に一覧表示する場合に、このAvroスキーマ形式を使用します。- Avro-Nested 。各タイプの情報を個別のレコードに編成する場合に、このAvroスキーマ形式を使用します。デフォルト値は[Avro-Flat] です。
Avroシリアル化形式
出力形式として[AVRO] が選択されている場合は、Avro出力ファイルのシリアル化形式を選択します。次のオプションがあります。
デフォルト値は[Binary] です。
Avroスキーマディレクトリ
出力形式として[AVRO] が選択されている場合は、データベース取り込みとレプリケーション が各ソーステーブルのAvroスキーマ定義を格納しているローカルディレクトリを指定します。スキーマ定義ファイルには、次の命名パターンがあります。
schemaname _tablename .txt
注: このディレクトリが指定されていない場合、Avroスキーマ定義ファイルは作成されません。
ファイル圧縮タイプ
CSVまたはAVRO出力形式の出力ファイルのファイル圧縮タイプを選択します。次のオプションがあります。
- なし - Deflate - Gzip - Snappy デフォルト値は[なし] 、これは圧縮が使用されないことを意味します。
暗号化タイプ
Amazon S3ファイルをターゲットに書き込むときに、ファイルの暗号化タイプを選択します。次のオプションがあります。
- なし - クライアントサイドの暗号化 - KMSを使用したクライアントサイドの暗号化 - サーバーサイドの暗号化 - KMSを使用したサーバーサイドの暗号化 デフォルトは[なし] です。これは暗号化が使用されないことを意味します。
Avro圧縮タイプ
[AVRO] が出力形式としてが選択されている場合は、Avro圧縮タイプを選択します。次のオプションがあります。
- なし - Bzip2 - Deflate - Snappy デフォルト値は[なし] 、これは圧縮が使用されないことを意味します。
Parquet圧縮タイプ
[PARQUET] 出力形式が選択されている場合、Parquetでサポートされている圧縮タイプを選択できます。次のオプションがあります。
デフォルト値は[なし] 、これは圧縮が使用されないことを意味します。
Deflate圧縮レベル
[Deflate] が[Avro圧縮タイプ] フィールドで選択されている場合、圧縮レベルとして0~9を指定します。デフォルトは0です。
ディレクトリタグの追加
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合、Hiveパーティショニングの命名規則と互換性を持たせるために適用サイクルディレクトリの名前に「dt=」プレフィックスを追加するには、このチェックボックスをオンにします。このチェックボックスはデフォルトでオフになっています。
タスクターゲットディレクトリ
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合、出力データファイル、スキーマファイル、およびCDCサイクルのコンテンツと完了ファイルを保持する他のディレクトリのルートディレクトリ。このフィールドを使用して、タスクのカスタムルートディレクトリを指定できます。[親としての接続ディレクトリ] オプションを有効にしている場合は、必要に応じて、接続プロパティで指定された親ディレクトリで使用するタスクターゲットディレクトリを指定できます。
このフィールドは、次のディレクトリフィールドのいずれかのパターンで{TaskTargetDirectory}プレースホルダが指定されている場合は必須です。
親としての接続ディレクトリ
ターゲット接続プロパティで指定されたディレクトリ値を、タスクターゲットプロパティで指定されたカスタムディレクトリパスの親ディレクトリとして使用するようにするには、このチェックボックスをオンにします。初期ロードタスクの場合、親ディレクトリは、データディレクトリ とスキーマディレクトリ で使用されます。増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合、親ディレクトリはデータディレクトリ 、スキーマディレクトリ 、サイクル完了ディレクトリ 、およびサイクルコンテンツディレクトリ で使用されます。
このチェックボックスはデフォルトで選択されています。オフにしたとき、初期ロードの場合は、[データディレクトリ] フィールドで出力ファイルへのフルパスを定義します。増分ロードの場合は、必要に応じて[タスクターゲットディレクトリ] でタスクのルートディレクトリを指定します。
データディレクトリ
初期ロードタスクの場合、データベース取り込みとレプリケーション が出力データファイルとオプションでスキーマを保存するディレクトリのディレクトリ構造を定義します。ディレクトリパターンを定義するには、次のタイプのエントリを使用できます。
- - - placeholder )の値を強制的に大文字または小文字に変換します。注: プレースホルダの値の大文字と小文字は区別されません。
例:
myDir1/{SchemaName}/{TableName}
デフォルトのディレクトリパターンは{TableName)_{Timestamp} です。
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合は 、cdc-dataデータファイルを含むサブディレクトリへのカスタムパスを定義します。ディレクトリパターンを定義する場合は、次のタイプのエントリを使用します。
デフォルトのディレクトリパターンは{TaskTargetDirectory}/data/{TableName}/data です。
注: Amazon S3、フラットファイル、Microsoft Azure Data Lake Storage Gen2、およびOracle Cloud Object Storeターゲットでは、[親としての接続ディレクトリ] が選択されている場合、データベース取り込みとレプリケーション は、ターゲット接続プロパティで指定されたディレクトリをデータディレクトリパスのルートとして使用します。Google Cloud Storageターゲットの場合、データベース取り込みとレプリケーション は取り込みタスクのターゲットプロパティで指定したバケット 名を使用します。Microsoft Fabric OneLakeターゲットの場合、親ディレクトリは、Microsoft Fabric OneLake接続プロパティの[レイクハウスのパス] フィールドで指定されたパスです。
スキーマディレクトリ
デフォルトディレクトリ以外のディレクトリにスキーマファイルを保存する場合は、スキーマファイルを保存するカスタムディレクトリを指定できます。初期ロードの場合、便利になるように、以前に使用した値を使用できる場合はそれがドロップダウンリストに表示されます。このフィールドはオプションです。
初期ロードの場合、デフォルトでは、スキーマはデータディレクトリに保存されます。増分ロード、および初期ロードと増分ロードの組み合わせの場合、スキーマファイルのデフォルトディレクトリは{TaskTargetDirectory}/data/{TableName}/schema です。
[データディレクトリ] フィールドと同じプレースホルダを使用できます。プレースホルダは必ず中かっこ{ }で囲んでください。
toUpperまたはtoLower関数を含める場合は、{toLower(SchemaName)} のように、プレースホルダ名を丸かっこで囲み、関数とプレースホルダの両方を中かっこで囲みます。
注: スキーマは、CSV形式で出力データファイルにのみ書き込まれます。ParquetおよびAvro形式のデータファイルには、独自の埋め込みスキーマが含まれています。
サイクル完了ディレクトリ
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合、サイクル完了ファイルを含むディレクトリへのパス。デフォルトは{TaskTargetDirectory}/cycle/completed です。
サイクルコンテンツディレクトリ
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合、サイクルコンテンツファイルを含むディレクトリへのパス。デフォルトは{TaskTargetDirectory}/cycle/contents です。
データディレクトリにサイクルのパーティション化を使用する
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合、各データディレクトリの下に、CDCサイクルごとにタイムスタンプサブディレクトリが作成されます。
このオプションが選択されていない場合、別のディレクトリ構造を定義しない限り、個々のデータファイルがタイムスタンプなしで同じディレクトリに書き込まれます。
サマリディレクトリにサイクルのパーティション化を使用する
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合は、サマリコンテンツサブディレクトリおよび完了サブディレクトリの下にCDCサイクルごとにタイムスタンプサブディレクトリが作成されます。
コンテンツ内の個々のファイルを一覧表示する
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合は、コンテンツサブディレクトリの下に個々のデータファイルが一覧表示されます。
[サマリディレクトリにサイクルのパーティション化を使用する] がオフの場合は、このオプションがデフォルトでオンになります。タイムスタンプや日付などのプレースホルダを使用してカスタムサブディレクトリを設定できる場合を除き、コンテンツサブディレクトリ内の個々のファイルがすべて一覧表示されます。
[データディレクトリにサイクルのパーティション化を使用する] が選択されている場合でも、必要に応じてこのチェックボックスを選択して、個々のファイルを一覧表示し、CDCサイクルごとにグループ化することができます。
[詳細] では、次のAmazon S3ターゲット詳細プロパティを入力できます。これらのプロパティは主に増分ロードに適用されます。
プロパティ
説明
操作タイプの追加
ジョブがターゲットにプロパゲートする出力にソースSQL操作タイプを記録するメタデータカラムを追加するには、このチェックボックスを選択します。
増分ロードの場合、ジョブは、挿入を表す「I」、更新を表す「U」、または削除を表す「D」を書き込みます。初期ロードの場合、ジョブは常に、挿入を表す「I」を書き込みます。
デフォルトでは、このチェック ボックスは、増分ロードジョブ、初期および増分ロードジョブの場合はオンになっており、初期ロードジョブの場合はオフになっています。
操作時間の追加
ジョブがターゲットにプロパゲートする出力にソースSQL操作タイムスタンプを記録するメタデータカラムを追加するには、このチェックボックスをオンにします。
初期ロードの場合、ジョブは常に現在の日付と時刻を書き込みます。
デフォルトでは、このチェックボックスは選択されていません。
操作所有者の追加
ジョブがターゲットにプロパゲートする出力にソースSQL操作の所有者を記録するメタデータカラムを追加するには、このチェックボックスを選択します。
初期ロードの場合、ジョブは常に所有者として「INFA」を書き込みます。
デフォルトでは、このチェックボックスは選択されていません。
このプロパティは、MongoDBソースまたはPostgreSQLソースを持つジョブでは使用できません。
注: このプロパティは、SQL Serverソースを持ち、CDCテーブルキャプチャメソッドを使用するおよびジョブではサポートされていません。
操作トランザクションIDの追加
ジョブがSQL操作のターゲットにプロパゲートする出力にソーストランザクションIDを含むメタデータカラムを追加するには、このチェックボックスを選択します。
初期ロードの場合、ジョブは常にIDとして「1」を書き込みます。
デフォルトでは、このチェックボックスは選択されていません。
前のイメージを追加
ジョブがターゲットに書き込む出力にUNDOデータを含めるには、このチェックボックスを選択します。
初期ロードの場合、ジョブはnullを書き込みます。
デフォルトでは、このチェックボックスは選択されていません。
Databricksターゲットのプロパティ Databricksターゲットのあるデータベース取り込みとレプリケーション タスクを定義する場合、タスクウィザードの[ターゲット] タブでターゲットのいくつかのプロパティを入力する必要があります。
次の表は、[ターゲット] に表示されるDatabricksターゲットのプロパティについて説明しています。
プロパティ
説明
ターゲット作成
利用可能なただ1つのオプションは、[ターゲットテーブルを作成する] であり、これによりソーステーブルをベースにしてターゲットテーブルを生成します。
注: ターゲットテーブルが作成された後、データベース取り込みとレプリケーション は、後続のジョブ実行でターゲットテーブルをインテリジェントに処理します。データベース取り込みとレプリケーション は、特定の状況に応じて、ターゲットテーブルを切り詰めたり再作成したりする場合があります。
スキーマ
データベース取り込みとレプリケーション がターゲットテーブルを作成するターゲットスキーマを選択します。
適用モード
増分ロードジョブ、および初期ロードと増分ロードの組み合わせジョブの場合に、挿入、更新、削除といったソースDMLの変更がターゲットにどのように適用されるかを示します。次のオプションがあります。
- 標準 。1回の適用サイクルの間の変更を累積し、それをターゲットに適用する前に、より少ないSQL文になるようにそれらをインテリジェントにマージします。例えば、ソース行で更新とそれに続く削除が発生した場合、ターゲットに行は適用されません。同じカラムまたはフィールドで複数の更新が発生した場合、最後の更新のみがターゲットに適用されます。異なるカラムまたはフィールドで複数の更新が発生した場合、更新はターゲットに適用される前に1つの更新レコードにマージされます。- 論理削除 。ソース削除操作を論理削除としてターゲットに適用します。論理削除では、削除された行をデータベースから実際には削除せずに、削除済みとしてマークします。例えば、ソースで削除を行うと、ターゲットの変更レコードのINFA_OPERATION_TYPEカラムに「D」が表示されます。処理を完了するために論理的に削除されたデータが必要となる、長期にわたるビジネスプロセスがある場合、誤って削除したデータを復元する必要がある場合、または削除された値を監査目的で追跡する必要がある場合は、論理削除の使用を検討してください。
注: [論理削除] モードを使用する場合は、ソーステーブルのプライマリキーに対して更新を実行しないでください。そうしないと、ターゲットでデータ破損が発生する可能性があります。
- 監査 。ソーステーブルで実行されたすべてのDML操作の監査証跡をターゲットに適用します。ソーステーブルの各DML変更の行が、[詳細] セクションで選択した監査カラムとともに、生成されたターゲットテーブルに書き込まれます。監査カラムには、DML操作タイプ、時刻、所有者、トランザクションID、生成された昇順シーケンス番号、前のイメージなどの変更に関するメタデータが含まれています。監査履歴を使用して、データをターゲットデータベースに書き込む前にダウンストリームの計算または処理を実行する場合、またはキャプチャされた変更に関するメタデータを調べる場合は、監査適用モードの使用を検討してください。デフォルト値は[標準] です。
注: タスクウィザードの[ソース] ページで手法として[クエリベースのCDC] を選択した場合、このフィールドは表示されません。
データディレクトリまたはタスクターゲットディレクトリ
データベース取り込みとレプリケーション がタスクに関連付けられたジョブの出力ファイルを格納するサブディレクトリを指定します。このフィールドは、初期ロードジョブの場合は[データディレクトリ] 、増分ロードジョブ、または初期ロードと増分ロードの組み合わせジョブの場合は[タスクターゲットディレクトリ] と呼ばれます。
次の表は、[詳細] に表示されるターゲットの詳細プロパティについて説明しています。
プロパティ
説明
操作タイプの追加
ジョブがターゲットデータベースにプロパゲートする出力、またはターゲットテーブルに挿入する出力にソースSQL操作タイプを記録するメタデータカラムを追加するには、このチェックボックスを選択します。
このフィールドは、[適用モード] オプションが[監査] または[論理削除] に設定されている場合にのみ使用できます。
監査モードでは、ジョブによって、挿入を表す「I」、更新を表す「U」、または削除を表す「D」が書き込まれます。
論理削除モードでは、ジョブは削除の場合は「D」を書き込み、挿入と更新の場合はNULLを書き込みます。操作タイプがNULLの場合、他の[操作の追加...]メタデータカラムもNULLです。操作タイプが「D」の場合にのみ、他のメタデータカラムにNULL以外の値が含まれます。
デフォルトでは、このチェックボックスは選択されています。論理削除を使用している場合は、選択を解除できません。
操作時間の追加
ジョブがターゲットデータベースにプロパゲートする出力、またはターゲットシステムの監査テーブルに挿入する出力にソースSQL操作のタイムスタンプを記録するメタデータカラムを追加するには、このチェックボックスを選択します。
このフィールドは、[適用モード] が[監査] または[論理削除] に設定されている場合にのみ使用できます。
デフォルトでは、このチェックボックスは選択されていません。
操作所有者の追加
ジョブがターゲットデータベースにプロパゲートする出力、またはターゲットシステムの監査テーブルに挿入する出力にソースSQL操作の所有者を記録するメタデータカラムを追加するには、このチェックボックスを選択します。
このフィールドは、[適用モード] が[監査] または[論理削除] に設定されている場合にのみ使用できます。
デフォルトでは、このチェックボックスは選択されていません。
このプロパティは、MongoDBソースまたはPostgreSQLソースを持つジョブでは使用できません。
注: このプロパティは、SQL Serverソースを持ち、CDCテーブルキャプチャメソッドを使用するおよびジョブではサポートされていません。
操作トランザクションIDの追加
ジョブがSQL操作のターゲットにプロパゲートする出力にソーストランザクションIDを含むメタデータカラムを追加するには、このチェックボックスを選択します。
このフィールドは、[適用モード] が[監査] または[論理削除] に設定されている場合にのみ使用できます。
デフォルトでは、このチェックボックスは選択されていません。
操作シーケンスの追加
ジョブがターゲットシステムの監査テーブルに挿入する変更操作ごとに、生成された昇順のシーケンス番号を記録するメタデータカラムを追加するには、このチェックボックスを選択します。シーケンス番号には、操作の変更ストリーム位置が反映されます。
このフィールドは、[適用モード] が[監査] に設定されている場合にのみ使用できます。
デフォルトでは、このチェックボックスは選択されていません。
前のイメージを追加
ジョブがターゲットテーブルに挿入する出力にUNDOの「操作前のイメージ」データを含む_OLDカラムを追加するには、このチェックボックスを選択します。これにより、各データカラムの以前の値と現在の値を比較できるようになります。削除操作の場合、現在の値はNULLになります。
このフィールドは、[適用モード] が[監査] に設定されている場合にのみ使用できます。
デフォルトでは、このチェックボックスは選択されていません。
メタデータカラムのプレフィックス
追加されたメタデータカラムの名前にプレフィックスを追加し、それらを簡単に識別して、既存のカラムの名前との競合を防ぐことができるようにします。
デフォルト値はINFA_です。
アンマネージドテーブルの作成
タスクでDatabricksターゲットテーブルをアンマネージドテーブルとして作成する場合は、このチェックボックスを選択します。タスクをデプロイした後は、このフィールドを編集してマネージドテーブルに切り替えることはできません。
デフォルトでは、このオプションはオフになっており、マネージドテーブルが作成されます。
Databricksのマネージドテーブルとアンマネージドテーブルの詳細については、Databricksのドキュメントを参照してください。
非管理対象テーブルの親ディレクトリ
Databricksアンマネージドテーブルを作成する場合は、キャプチャされたDMLレコードの処理時にターゲットテーブルごとに生成されるParquetファイルを保持するために、Amazon S3またはMicrosoft Azure Data Lake Storageに存在する親ディレクトリを指定する必要があります。
注: Unity Catalogを使用するには、既存の外部ディレクトリを指定する必要があります。
フラットファイルターゲットのプロパティ データベース取り込みとレプリケーション タスクを定義する場合は、フラットファイルターゲットのいくつかのプロパティをタスクウィザードの[ターゲット] ページで入力する必要があります。
注: フラットファイルターゲットの場合、これらのプロパティは初期ロードジョブにのみ適用されます。
[ターゲット] では、次のフラットファイルターゲットのプロパティを入力できます。
プロパティ
説明
出力形式
出力ファイルの形式を選択します。次のオプションがあります。
デフォルトの値は[CSV] です。
注: CSV形式の出力ファイルでは、各フィールドの区切り文字として二重引用符("")が使用されます。
CSVファイルへのヘッダーの追加
[CSV] が出力形式として選択されている場合は、このチェックボックスをオンにして、ソース列名を含むヘッダーを出力CSVファイルに追加します。
Avro形式
出力形式として[AVRO] を選択した場合、ソーステーブルごとに作成されるAvroスキーマの形式を選択します。次のオプションがあります。
- Avro-Flat 。すべてのAvroフィールドを1つのレコードに一覧表示する場合に、このAvroスキーマ形式を使用します。- Avro-Generic 。ソーステーブルのすべてのカラムをAvroフィールドの単一の配列に一覧表示する場合に、このAvroスキーマ形式を使用します。- Avro-Nested 。各タイプの情報を個別のレコードに編成する場合に、このAvroスキーマ形式を使用します。デフォルト値は[Avro-Flat] です。
Avroシリアル化形式
出力形式として[AVRO] が選択されている場合は、Avro出力ファイルのシリアル化形式を選択します。次のオプションがあります。
デフォルト値は[Binary] です。
Avroスキーマディレクトリ
出力形式として[AVRO] が選択されている場合は、データベース取り込みとレプリケーション が各ソーステーブルのAvroスキーマ定義を格納しているローカルディレクトリを指定します。スキーマ定義ファイルには、次の命名パターンがあります。
schemaname _tablename .txt
注: このディレクトリが指定されていない場合、Avroスキーマ定義ファイルは作成されません。
ファイル圧縮タイプ
CSVまたはAVRO出力形式の出力ファイルのファイル圧縮タイプを選択します。次のオプションがあります。
- なし - Deflate - Gzip - Snappy デフォルト値は[なし] 、これは圧縮が使用されないことを意味します。
Avro圧縮タイプ
[AVRO] が出力形式としてが選択されている場合は、Avro圧縮タイプを選択します。次のオプションがあります。
- なし - Bzip2 - Deflate - Snappy デフォルト値は[なし] 、これは圧縮が使用されないことを意味します。
Deflate圧縮レベル
[Deflate] が[Avro圧縮タイプ] フィールドで選択されている場合、圧縮レベルとして0~9を指定します。デフォルトは0です。
データディレクトリ
初期ロードタスクの場合、データベース取り込みとレプリケーション が出力データファイルとオプションでスキーマを保存するディレクトリのディレクトリ構造を定義します。ディレクトリパターンを定義するには、次のタイプのエントリを使用できます。
- - - placeholder )の値を強制的に大文字または小文字に変換します。注: プレースホルダの値の大文字と小文字は区別されません。
例:
myDir1/{SchemaName}/{TableName}
デフォルトのディレクトリパターンは{TableName)_{Timestamp} です。
注: フラットファイルターゲットの場合、[親としての接続ディレクトリ] が選択されていると、データベース取り込みおよびレプリケーションはターゲット接続プロパティで指定されたディレクトリをデータディレクトリパスのルートとして使用します。
親としての接続ディレクトリ
初期ロードタスクの場合、ターゲット接続プロパティで指定されたディレクトリ値を、タスクターゲットプロパティで指定されたカスタムディレクトリパスの親ディレクトリとして使用するようにするには、このチェックボックスを選択します。親ディレクトリは、データディレクトリ とスキーマディレクトリ で使用されます。
スキーマディレクトリ
初期ロードタスクの場合、デフォルトディレクトリ以外のディレクトリにスキーマファイルを保存する場合は、スキーマファイルを保存するカスタムディレクトリを指定できます。このフィールドはオプションです。
デフォルトでは、スキーマはデータディレクトリに保存されます。増分ロードの場合、スキーマファイルのデフォルトディレクトリは、{TaskTargetDirectory}/data/{TableName}/schema です。
[データディレクトリ] フィールドと同じプレースホルダを使用できます。プレースホルダが中括弧{}で囲まれていることを確認します。
[詳細] で次のような詳細ターゲットプロパティを入力できます。
プロパティ
説明
操作タイプの追加
ジョブがターゲットに伝播する出力にソースSQL操作タイプを含むメタデータカラムを追加するには、このチェックボックスを選択します。
初期ロードの場合、ジョブは常に挿入を表す「I」を書き込みます。
デフォルトでは、このチェックボックスはオフです。
操作時間の追加
ジョブがターゲットにプロパゲートする出力にソースSQL操作タイムスタンプを記録するメタデータカラムを追加するには、このチェックボックスをオンにします。
初期ロードの場合、ジョブは常に現在の日付と時刻を書き込みます。
デフォルトでは、このチェックボックスは選択されていません。
操作所有者の追加
ジョブがターゲットにプロパゲートする出力にソースSQL操作の所有者を記録するメタデータカラムを追加するには、このチェックボックスを選択します。
初期ロードの場合、ジョブは常に所有者として「INFA」を書き込みます。
デフォルトでは、このチェックボックスは選択されていません。
このプロパティは、MongoDBソースまたはPostgreSQLソースを持つジョブでは使用できません。
注: このプロパティは、SQL Serverソースを持ち、CDCテーブルキャプチャメソッドを使用するおよびジョブではサポートされていません。
操作トランザクションIDの追加
ジョブがSQL操作のターゲットにプロパゲートする出力にソーストランザクションIDを含むメタデータカラムを追加するには、このチェックボックスを選択します。
初期ロードの場合、ジョブは常にIDとして「1」を書き込みます。
デフォルトでは、このチェックボックスは選択されていません。
前のイメージを追加
ジョブがターゲットに書き込む出力にUNDOデータを含めるには、このチェックボックスを選択します。
初期ロードの場合、ジョブはnullを書き込みます。
デフォルトでは、このチェックボックスは選択されていません。
Google BigQueryターゲットのプロパティ Google BigQueryターゲットのあるデータベース取り込みとレプリケーション タスクを定義する場合、タスクウィザードの[ターゲット] タブでターゲットのいくつかのプロパティを入力する必要があります。
次の表は、[ターゲット] に表示されるGoogle BigQueryターゲットのプロパティについて説明しています。
プロパティ
説明
ターゲット作成
利用可能なただ1つのオプションは、[ターゲットテーブルを作成する] であり、これによりソーステーブルをベースにしてターゲットテーブルを生成します。
注: ターゲットテーブルが作成された後、データベース取り込みとレプリケーション は、後続のジョブ実行でターゲットテーブルをインテリジェントに処理します。データベース取り込みとレプリケーション は、特定の状況に応じて、ターゲットテーブルを切り詰めたり再作成したりする場合があります。
スキーマ
データベース取り込みとレプリケーション がターゲットテーブルを作成するターゲットスキーマを選択します。
適用モード
増分ロードジョブ、および初期ロードと増分ロードの組み合わせジョブの場合に、挿入、更新、削除といったソースDMLの変更がターゲットにどのように適用されるかを示します。次のオプションがあります。
- 標準 。1回の適用サイクルの間の変更を累積し、それをターゲットに適用する前に、より少ないSQL文になるようにそれらをインテリジェントにマージします。例えば、ソース行で更新とそれに続く削除が発生した場合、ターゲットに行は適用されません。同じカラムまたはフィールドで複数の更新が発生した場合、最後の更新のみがターゲットに適用されます。異なるカラムまたはフィールドで複数の更新が発生した場合、更新はターゲットに適用される前に1つの更新レコードにマージされます。- 監査 。ソーステーブルで実行されたすべてのDML操作の監査証跡をターゲットに適用します。ソーステーブルの各DML変更の行が、[詳細] セクションで選択した監査カラムとともに、生成されたターゲットテーブルに書き込まれます。監査カラムには、DML操作タイプ、時刻、所有者、トランザクションID、生成された昇順シーケンス番号、前のイメージなどの変更に関するメタデータが含まれています。監査履歴を使用して、データをターゲットデータベースに書き込む前にダウンストリームの計算または処理を実行する場合、またはキャプチャされた変更に関するメタデータを調べる場合は、監査適用モードの使用を検討してください。- 論理削除 。ソース削除操作を論理削除としてターゲットに適用します。論理削除では、削除された行をデータベースから実際には削除せずに、削除済みとしてマークします。例えば、ソースで削除を行うと、ターゲットの変更レコードのINFA_OPERATION_TYPEカラムに「D」が表示されます。処理を完了するために論理的に削除されたデータが必要となる、長期にわたるビジネスプロセスがある場合、誤って削除したデータを復元する必要がある場合、または削除された値を監査目的で追跡する必要がある場合は、論理削除の使用を検討してください。
注: [論理削除] モードを使用する場合は、ソーステーブルのプライマリキーに対して更新を実行しないでください。そうしないと、ターゲットでデータ破損が発生する可能性があります。
デフォルト値は[標準] です。
注: タスクウィザードの[ソース] ページで手法として[クエリベースのCDC] を選択した場合、このフィールドは表示されません。
バケット
Google Cloud Storageに読み込むデータオブジェクトへのアクセスを保存、整理、制御する既存のバケットコンテナの名前を指定します。
データディレクトリまたはタスクターゲットディレクトリ
データベース取り込みとレプリケーション がタスクに関連付けられたジョブの出力ファイルを格納するサブディレクトリを指定します。このフィールドは、初期ロードジョブの場合は[データディレクトリ] 、増分ロードジョブ、または初期ロードと増分ロードの組み合わせジョブの場合は[タスクターゲットディレクトリ] と呼ばれます。
次の表は、[詳細] に表示されるターゲットの詳細プロパティについて説明しています。
プロパティ
説明
最終レプリケート時刻を追加
ターゲットテーブルでレコードが挿入または最後に更新された時点のタイムスタンプを記録するメタデータカラムを追加するには、このチェックボックスをオンにします。初期ロードでは、ロードされたすべてのレコードのタイムスタンプが同じになります。増分ロード、および初期ロードと増分ロードの組み合わせの場合、このカラムには、ターゲットに適用された最後のDML操作のタイムスタンプが記録されます。
デフォルトでは、このチェックボックスは選択されていません。
操作タイプの追加
ジョブがターゲットデータベースにプロパゲートする出力、またはターゲットシステムの監査テーブルに挿入する出力にソースSQL操作タイプを記録するメタデータカラムを追加するには、このチェックボックスを選択します。
このフィールドは、[適用モード] オプションが[監査] または[論理削除] に設定されている場合にのみ使用できます。
監査モードでは、ジョブはこのメタデータカラムに、挿入の場合は「I」、更新の場合は「U」、更新/挿入の場合は「E」、削除の場合は「D」を書き込みます。
論理削除モードでは、ジョブによって、削除の場合は「D」が書き込まれ、挿入、更新、および更新/挿入の場合はNULLが書き込まれます。操作タイプがNULLの場合、他の[操作の追加...]メタデータカラムもNULLです。操作タイプが「D」の場合にのみ、他のメタデータカラムにNULL以外の値が含まれます。
デフォルトでは、このチェックボックスは選択されています。論理削除を使用している場合は、選択を解除できません。
操作時間の追加
ジョブがターゲットテーブルにプロパゲートする出力にソースSQL操作タイムスタンプを記録するメタデータカラムを追加するには、このチェックボックスを選択します。
このフィールドは、[適用モード] が[監査] または[論理削除] に設定されている場合にのみ使用できます。
デフォルトでは、このチェックボックスは選択されていません。
操作所有者の追加
ジョブがターゲットテーブルにプロパゲートする出力にソースSQL操作の所有者を記録するメタデータカラムを追加するには、このチェックボックスを選択します。
このフィールドは、[適用モード] が[監査] または[論理削除] に設定されている場合にのみ使用できます。
デフォルトでは、このチェックボックスは選択されていません。
このプロパティは、MongoDBソースまたはPostgreSQLソースを持つジョブでは使用できません。
注: このプロパティは、SQL Serverソースを持ち、CDCテーブルキャプチャメソッドを使用するおよびジョブではサポートされていません。
操作トランザクションIDの追加
ジョブがSQL操作のターゲットにプロパゲートする出力にソーストランザクションIDを含むメタデータカラムを追加するには、このチェックボックスを選択します。
このフィールドは、[適用モード] が[監査] または[論理削除] に設定されている場合にのみ使用できます。
デフォルトでは、このチェックボックスは選択されていません。
操作シーケンスの追加
ジョブがターゲットテーブルに挿入する変更操作ごとに、生成された昇順のシーケンス番号を記録するメタデータカラムを追加するには、このチェックボックスを選択します。シーケンス番号には、操作の変更ストリーム位置が反映されます。
このフィールドは、[適用モード] が[監査] に設定されている場合にのみ使用できます。
デフォルトでは、このチェックボックスは選択されていません。
前のイメージを追加
ジョブがターゲットテーブルに挿入する出力にUNDOの「操作前のイメージ」データを含む_OLDカラムを追加するには、このチェックボックスを選択します。これにより、各データカラムの以前の値と現在の値を比較できるようになります。削除操作の場合、現在の値はNULLになります。
このフィールドは、[適用モード] が[監査] に設定されている場合にのみ使用できます。
デフォルトでは、このチェックボックスは選択されていません。
メタデータカラムのプレフィックス
追加されたメタデータカラムの名前にプレフィックスを追加し、それらを簡単に識別して、既存のカラムの名前との競合を防ぐことができるようにします。
プレフィックスには特殊文字を含めないようにしてください。特殊文字を含めた場合、タスクのデプロイメントが失敗します。
デフォルト値はINFA_です。
大文字と小文字の変換を有効にする
デフォルトでは、ターゲットテーブル名およびカラム名は、対応するソース名と同じ大文字と小文字で生成されます。ただし、ターゲットのクラスタレベルまたはセッションレベルのプロパティがこの大文字と小文字を区別する動作をオーバーライドしている場合を除きます。ターゲット名の大文字と小文字を制御する場合は、このチェックボックスを選択します。次に、[大文字と小文字の変換ストラテジ] オプションを選択します。
大文字と小文字の変換ストラテジ
[大文字と小文字の変換を有効にする] を選択した場合は、以下のいずれかのオプションを選択して、生成されたターゲットテーブル(またはオブジェクト)名およびカラム(またはフィールド)名の大文字と小文字の処理方法を指定します。
- ソースと同じ 。ソーステーブル(またはオブジェクト)名およびカラム(またはフィールド)名と同じ大文字と小文字を使用します。- UPPERCASE 。すべて大文字を使用します。- lowercase 。すべて小文字を使用します。デフォルト値は、[ソースと同じ] です。
注: 選択したストラテジは、大文字と小文字の制御に関するターゲットのクラスタレベルまたはセッションレベルのプロパティをオーバーライドします。
Google Cloud Storageターゲットのプロパティ Google Cloud Storageターゲットのあるデータベース取り込みとレプリケーション タスクを定義する場合、タスクウィザードの[ターゲット] タブでターゲットのいくつかのプロパティを入力する必要があります。
[ターゲット] では、次のGoogle Cloud Storageターゲットのプロパティを入力できます。
プロパティ
説明
出力形式
出力ファイルの形式を選択します。次のオプションがあります。
デフォルトの値は[CSV] です。
注: CSV形式の出力ファイルでは、各フィールドの区切り文字として二重引用符("")が使用されます。
CSVファイルへのヘッダーの追加
[CSV] が出力形式として選択されている場合は、このチェックボックスをオンにして、ソース列名を含むヘッダーを出力CSVファイルに追加します。
Avro形式
出力形式として[AVRO] を選択した場合、ソーステーブルごとに作成されるAvroスキーマの形式を選択します。次のオプションがあります。
- Avro-Flat 。すべてのAvroフィールドを1つのレコードに一覧表示する場合に、このAvroスキーマ形式を使用します。- Avro-Generic 。ソーステーブルのすべてのカラムをAvroフィールドの単一の配列に一覧表示する場合に、このAvroスキーマ形式を使用します。- Avro-Nested 。各タイプの情報を個別のレコードに編成する場合に、このAvroスキーマ形式を使用します。デフォルト値は[Avro-Flat] です。
Avroシリアル化形式
出力形式として[AVRO] が選択されている場合は、Avro出力ファイルのシリアル化形式を選択します。次のオプションがあります。
デフォルト値は[Binary] です。
Avroスキーマディレクトリ
出力形式として[AVRO] が選択されている場合は、データベース取り込みとレプリケーション が各ソーステーブルのAvroスキーマ定義を格納しているローカルディレクトリを指定します。スキーマ定義ファイルには、次の命名パターンがあります。
schemaname _tablename .txt
注: このディレクトリが指定されていない場合、Avroスキーマ定義ファイルは作成されません。
ファイル圧縮タイプ
CSVまたはAVRO出力形式の出力ファイルのファイル圧縮タイプを選択します。次のオプションがあります。
- なし - Deflate - Gzip - Snappy デフォルト値は[なし] 、これは圧縮が使用されないことを意味します。
Avro圧縮タイプ
[AVRO] が出力形式としてが選択されている場合は、Avro圧縮タイプを選択します。次のオプションがあります。
- なし - Bzip2 - Deflate - Snappy デフォルト値は[なし] 、これは圧縮が使用されないことを意味します。
Parquet圧縮タイプ
[PARQUET] 出力形式が選択されている場合、Parquetでサポートされている圧縮タイプを選択できます。次のオプションがあります。
デフォルト値は[なし] 、これは圧縮が使用されないことを意味します。
Deflate圧縮レベル
[Deflate] が[Avro圧縮タイプ] フィールドで選択されている場合、圧縮レベルとして0~9を指定します。デフォルトは0です。
ディレクトリタグの追加
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合、Hiveパーティショニングの命名規則と互換性を持たせるために適用サイクルディレクトリの名前に「dt=」プレフィックスを追加するには、このチェックボックスをオンにします。このチェックボックスはデフォルトでオフになっています。
バケット
Google Cloud Storageに読み込むデータオブジェクトへのアクセスを保存、整理、制御する既存のバケットコンテナの名前を指定します。
タスクターゲットディレクトリ
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合、出力データファイル、スキーマファイル、およびCDCサイクルのコンテンツと完了ファイルを保持する他のディレクトリのルートディレクトリ。このフィールドを使用して、タスクのカスタムルートディレクトリを指定できます。[親としての接続ディレクトリ] オプションを有効にしている場合は、必要に応じて、接続プロパティで指定された親ディレクトリで使用するタスクターゲットディレクトリを指定できます。
このフィールドは、次のディレクトリフィールドのいずれかのパターンで{TaskTargetDirectory}プレースホルダが指定されている場合は必須です。
データディレクトリ
初期ロードタスクの場合、データベース取り込みとレプリケーション が出力データファイルとオプションでスキーマを保存するディレクトリのディレクトリ構造を定義します。ディレクトリパターンを定義するには、次のタイプのエントリを使用できます。
- - - placeholder )の値を強制的に大文字または小文字に変換します。注: プレースホルダの値の大文字と小文字は区別されません。
例:
myDir1/{SchemaName}/{TableName}
デフォルトのディレクトリパターンは{TableName)_{Timestamp} です。
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合は 、cdc-dataデータファイルを含むサブディレクトリへのカスタムパスを定義します。ディレクトリパターンを定義する場合は、次のタイプのエントリを使用します。
デフォルトのディレクトリパターンは{TaskTargetDirectory}/data/{TableName}/data です。
注: Amazon S3、フラットファイル、Microsoft Azure Data Lake Storage Gen2、およびOracle Cloud Object Storeターゲットでは、[親としての接続ディレクトリ] が選択されている場合、データベース取り込みとレプリケーション は、ターゲット接続プロパティで指定されたディレクトリをデータディレクトリパスのルートとして使用します。Google Cloud Storageターゲットの場合、データベース取り込みとレプリケーション は取り込みタスクのターゲットプロパティで指定したバケット 名を使用します。Microsoft Fabric OneLakeターゲットの場合、親ディレクトリは、Microsoft Fabric OneLake接続プロパティの[レイクハウスのパス] フィールドで指定されたパスです。
スキーマディレクトリ
デフォルトディレクトリ以外のディレクトリにスキーマファイルを保存する場合は、スキーマファイルを保存するカスタムディレクトリを指定できます。初期ロードの場合、便利になるように、以前に使用した値を使用できる場合はそれがドロップダウンリストに表示されます。このフィールドはオプションです。
初期ロードの場合、デフォルトでは、スキーマはデータディレクトリに保存されます。増分ロード、および初期ロードと増分ロードの組み合わせの場合、スキーマファイルのデフォルトディレクトリは{TaskTargetDirectory}/data/{TableName}/schema です。
[データディレクトリ] フィールドと同じプレースホルダを使用できます。プレースホルダは必ず中かっこ{ }で囲んでください。
toUpperまたはtoLower関数を含める場合は、{toLower(SchemaName)} のように、プレースホルダ名を丸かっこで囲み、関数とプレースホルダの両方を中かっこで囲みます。
注: スキーマは、CSV形式で出力データファイルにのみ書き込まれます。ParquetおよびAvro形式のデータファイルには、独自の埋め込みスキーマが含まれています。
サイクル完了ディレクトリ
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合、サイクル完了ファイルを含むディレクトリへのパス。デフォルトは{TaskTargetDirectory}/cycle/completed です。
サイクルコンテンツディレクトリ
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合、サイクルコンテンツファイルを含むディレクトリへのパス。デフォルトは{TaskTargetDirectory}/cycle/contents です。
データディレクトリにサイクルのパーティション化を使用する
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合、各データディレクトリの下に、CDCサイクルごとにタイムスタンプサブディレクトリが作成されます。
このオプションが選択されていない場合、別のディレクトリ構造を定義しない限り、個々のデータファイルがタイムスタンプなしで同じディレクトリに書き込まれます。
サマリディレクトリにサイクルのパーティション化を使用する
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合は、サマリコンテンツサブディレクトリおよび完了サブディレクトリの下にCDCサイクルごとにタイムスタンプサブディレクトリが作成されます。
コンテンツ内の個々のファイルを一覧表示する
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合は、コンテンツサブディレクトリの下に個々のデータファイルが一覧表示されます。
[サマリディレクトリにサイクルのパーティション化を使用する] がオフの場合は、このオプションがデフォルトでオンになります。タイムスタンプや日付などのプレースホルダを使用してカスタムサブディレクトリを設定できる場合を除き、コンテンツサブディレクトリ内の個々のファイルがすべて一覧表示されます。
[データディレクトリにサイクルのパーティション化を使用する] が選択されている場合でも、必要に応じてこのチェックボックスを選択して、個々のファイルを一覧表示し、CDCサイクルごとにグループ化することができます。
[詳細] では、次のGoogle Cloud Storageターゲット詳細プロパティを入力できます。これらのプロパティは主に増分ロードジョブに使用されます。
フィールド
説明
操作タイプの追加
ジョブがターゲットにプロパゲートする出力にソースSQL操作タイプを記録するメタデータカラムを追加するには、このチェックボックスを選択します。
増分ロードの場合、ジョブは、挿入を表す「I」、更新を表す「U」、または削除を表す「D」を書き込みます。初期ロードの場合、ジョブは常に、挿入を表す「I」を書き込みます。
デフォルトでは、このチェック ボックスは、増分ロードジョブ、初期および増分ロードジョブの場合はオンになっており、初期ロードジョブの場合はオフになっています。
操作時間の追加
ジョブがターゲットにプロパゲートする出力にソースSQL操作タイムスタンプを記録するメタデータカラムを追加するには、このチェックボックスをオンにします。
初期ロードの場合、ジョブは常に現在の日付と時刻を書き込みます。
デフォルトでは、このチェックボックスは選択されていません。
操作所有者の追加
ジョブがターゲットにプロパゲートする出力にソースSQL操作の所有者を記録するメタデータカラムを追加するには、このチェックボックスを選択します。
初期ロードの場合、ジョブは常に所有者として「INFA」を書き込みます。
デフォルトでは、このチェックボックスは選択されていません。
このプロパティは、MongoDBソースまたはPostgreSQLソースを持つジョブでは使用できません。
注: このプロパティは、SQL Serverソースを持ち、CDCテーブルキャプチャメソッドを使用するおよびジョブではサポートされていません。
操作トランザクションIDの追加
ジョブがSQL操作のターゲットにプロパゲートする出力にソーストランザクションIDを含むメタデータカラムを追加するには、このチェックボックスを選択します。
初期ロードの場合、ジョブは常にIDとして「1」を書き込みます。
デフォルトでは、このチェックボックスは選択されていません。
前のイメージを追加
ジョブがターゲットに書き込む出力にUNDOデータを含めるには、このチェックボックスを選択します。
初期ロードの場合、ジョブはnullを書き込みます。
デフォルトでは、このチェックボックスは選択されていません。
Kafkaターゲットのプロパティ データベース取り込みとレプリケーション タスクを定義する場合は、Kafkaターゲットのいくつかのプロパティをタスクウィザードの[ターゲット] ページで入力する必要があります。
これらのプロパティは、増分ロード操作にのみ適用されます。
次の表は、[ターゲット] に表示されるKafkaターゲットのプロパティについて説明しています。
プロパティ
説明
テーブル名をトピック名として使用
データベース取り込みとレプリケーション がソースデータを含むメッセージを、ソーステーブルごとに1つずつ個別のトピックに書き込むか、すべてのメッセージを1つのトピックに書き込むかを示します。
テーブル固有のトピックを区切るメッセージを書き込むには、このチェックボックスを選択します。トピック名は、[スキーマ名を含める] 、[テーブルプレフィックス] 、または[テーブルサフィックス] プロパティに追加しない限り、トピック名はソーステーブル名に一致します。
デフォルトでは、このチェックボックスはオフです。デフォルト設定では、[トピック名] プロパティにすべてのメッセージが書き込まれる単一のトピックの名前を指定する必要があります。
スキーマ名を含める
[テーブル名をトピック名として使用] が選択されている場合、このチェックボックスが表示され、デフォルトで選択されています。この設定により、テーブル固有のトピック名にソーススキーマ名が追加されます。トピック名の形式は次のとおりです。スキーマ名 _テーブル名 。
スキーマ名を含めない場合は、このチェックボックスをオフにします。
テーブルプレフィックス
テーブル名をトピック名として使用 を選択すると、このプロパティが表示され、オプションでプレフィックスを入力してテーブル固有のトピック名に追加できます。例えば、myprefix_を指定すると、トピック名の形式は「myprefix_テーブル名 」になります。プレフィックスの後のアンダースコア(_)を省略すると、プレフィックスがテーブル名の前に追加されます。
テーブルサフィックス
テーブル名をトピック名として使用 を選択すると、このプロパティが表示され、オプションでサフィックスを入力してテーブル固有のトピック名に追加できます。例えば、_mysuffixを指定すると、トピック名の形式は「テーブル名 _mysuffix」になります。サフィックスの前のアンダースコア(_)を省略すると、サフィックスがテーブル名に追加されます。
トピック名
[トピック名としてテーブル名を使用する] を選択しない 場合、ソースデータを含むすべてのメッセージが書き込まれる単一のKafkaトピックの名前を入力する必要があります。
出力形式
出力ファイルの形式を選択します。次のオプションがあります。
デフォルトの値は[CSV] です。
注: CSV形式の出力ファイルでは、各フィールドの区切り文字として二重引用符("")が使用されます。
KafkaターゲットがConfluent Schema Registryを使用して増分ロードジョブのスキーマを格納する場合は、形式として[AVRO] を選択する必要があります。
JSON形式
出力形式として[JSON] が選択されている場合は、出力の詳細レベルを選択します。次のオプションがあります。
- 簡潔 。この形式では、操作タイプやカラムの名前と値など、最も関連性の高いデータのみが出力に記録されます。- 詳細 。この形式では、テーブル名やカラムタイプなどの詳細情報が記録されます。Avro形式
出力形式として[AVRO] を選択した場合、ソーステーブルごとに作成されるAvroスキーマの形式を選択します。次のオプションがあります。
- Avro-Flat 。すべてのAvroフィールドを1つのレコードに一覧表示する場合に、このAvroスキーマ形式を使用します。- Avro-Generic 。ソーステーブルのすべてのカラムをAvroフィールドの単一の配列に一覧表示する場合に、このAvroスキーマ形式を使用します。- Avro-Nested 。各タイプの情報を個別のレコードに編成する場合に、このAvroスキーマ形式を使用します。デフォルト値は[Avro-Flat] です。
Avroシリアル化形式
出力形式としてAVRO が選択されている場合は、Avro出力ファイルのシリアル化形式を選択します。次のオプションがあります。
デフォルト値は[Binary] です。
Confluent Schema Registryを使用してスキーマを格納するConfluent Kafkaターゲットがある場合は、[なし] を選択します。それ以外の場合、Confluent Schema Registryはスキーマを登録しません。Confluent Scheme Registryを使用していない場合、[なし] は選択しないでください。
Avroスキーマディレクトリ
出力形式として[AVRO] が選択されている場合は、データベース取り込みとレプリケーション が各ソーステーブルのAvroスキーマ定義を格納しているローカルディレクトリを指定します。スキーマ定義ファイルには、次の命名パターンがあります。
schemaname _tablename .txt
注: このディレクトリが指定されていない場合、Avroスキーマ定義ファイルは作成されません。
ソーススキーマの変更によってターゲットが変更されることが予想される場合、Avroスキーマ定義ファイルは、タイムスタンプを含む一意の名前で次の形式で再生成されます。
schemaname _tablename _YYYYMMDDhhmmss .txt
この一意の命名パターンにより、古いスキーマ定義ファイルが監査目的で保持されます。
Avro圧縮タイプ
[AVRO] が出力形式としてが選択されている場合は、Avro圧縮タイプを選択します。次のオプションがあります。
- なし - Bzip2 - Deflate - Snappy デフォルト値は[なし] 、これは圧縮が使用されないことを意味します。
Deflate圧縮レベル
[Deflate] が[Avro圧縮タイプ] フィールドで選択されている場合、圧縮レベルとして0~9を指定します。デフォルトは0です。
[詳細] で次のような詳細ターゲットプロパティを入力できます。
プロパティ
説明
操作タイプの追加
ジョブがターゲットにプロパゲートする出力にソースSQL操作タイプを含むメタデータカラムを追加するには、このチェックボックスを選択します。
ジョブは、挿入を表す「I」、更新を表す「U」、または削除を表す「D」を書き込みます。
デフォルトでは、このチェックボックスは選択されています。
操作時間の追加
ジョブがターゲットにプロパゲートする出力にソースSQL操作タイムスタンプを記録するメタデータカラムを追加するには、このチェックボックスをオンにします。
デフォルトでは、このチェックボックスは選択されていません。
操作所有者の追加
ジョブがターゲットにプロパゲートする出力にソースSQL操作の所有者を記録するメタデータカラムを追加するには、このチェックボックスを選択します。
デフォルトでは、このチェックボックスは選択されていません。
このプロパティは、MongoDBソースまたはPostgreSQLソースを持つジョブでは使用できません。
注: このプロパティは、SQL Serverソースを持ち、CDCテーブルキャプチャメソッドを使用するおよびジョブではサポートされていません。
操作トランザクションIDの追加
ジョブがSQL操作のターゲットにプロパゲートする出力にソーストランザクションIDを含むメタデータカラムを追加するには、このチェックボックスを選択します。
デフォルトでは、このチェックボックスは選択されていません。
前のイメージを追加
ジョブがターゲットに書き込む出力にUNDOデータを含めるには、このチェックボックスを選択します。
デフォルトでは、このチェックボックスは選択されていません。
非同期書き込み
Kafkaへのメッセージの同期配信を使用するかどうかを制御します。
- データベース取り込みとレプリケーション が次のメッセージを送信する前に、各メッセージの受信を確認する必要があります。このモードでは、Kafkaが重複メッセージを受信する可能性はほとんどありません。ただし、パフォーマンスが低下する可能性があります。- データベース取り込みとレプリケーション は、ソースから変更が取得された順序に関係なく、できるだけ早くメッセージを送信します。デフォルトでは、このチェックボックスは選択されています。
プロデューサ設定プロパティ
key =value ペアをカンマで区切って指定して、Apache Kafka、Confluent Kafka、Amazon Managed Streaming for Apache Kafka(MSK)、またはKafka対応Azure Event HubsターゲットのKafkaプロデューサプロパティを入力します。
Confluent Schema Registryを使用してスキーマを格納するConfluentターゲットがある場合は、次のプロパティを指定する必要があります。
schema.registry.url=url ,
Kafkaプロデューサーのプロパティは、このフィールドまたはKafka接続の追加の接続プロパティ フィールドのいずれかに設定します。
このフィールドにプロデューサープロパティを入力すると、プロパティはこのタスクにのみ関連付けられたデータベース取り込みジョブに関係します。接続のプロデューサプロパティを入力する場合、[プロデューサ設定プロパティ] フィールドのプロパティを指定して特定のタスクの接続レベルのプロパティをオーバーライドしない限り、プロパティは接続定義を使用するすべてのタスクのジョブに関係します。
Kafkaプロデューサプロパティの詳細については、Apache Kafka、Confluent Kafka、Amazon MSK、またはAzure Event Hubs のドキュメントを参照してください。
Microsoft Azure Data Lake Storageターゲットのプロパティ Microsoft Azure Data Lake Storageターゲットのあるデータベース取り込みとレプリケーション タスクを定義する場合、タスクウィザードの[ターゲット] ページでターゲットのいくつかのプロパティを入力する必要があります。
[ターゲット] では、次のMicrosoft Azure Data Lake Storageターゲットのプロパティを入力できます。
プロパティ
説明
出力形式
出力ファイルの形式を選択します。次のオプションがあります。
デフォルトの値は[CSV] です。
注: CSV形式の出力ファイルでは、各フィールドの区切り文字として二重引用符("")が使用されます。
CSVファイルへのヘッダーの追加
[CSV] が出力形式として選択されている場合は、このチェックボックスをオンにして、ソース列名を含むヘッダーを出力CSVファイルに追加します。
Avro形式
出力形式として[AVRO] を選択した場合、ソーステーブルごとに作成されるAvroスキーマの形式を選択します。次のオプションがあります。
- Avro-Flat 。すべてのAvroフィールドを1つのレコードに一覧表示する場合に、このAvroスキーマ形式を使用します。- Avro-Generic 。ソーステーブルのすべてのカラムをAvroフィールドの単一の配列に一覧表示する場合に、このAvroスキーマ形式を使用します。- Avro-Nested 。各タイプの情報を個別のレコードに編成する場合に、このAvroスキーマ形式を使用します。デフォルト値は[Avro-Flat] です。
Avroシリアル化形式
出力形式として[AVRO] が選択されている場合は、Avro出力ファイルのシリアル化形式を選択します。次のオプションがあります。
デフォルト値は[Binary] です。
Avroスキーマディレクトリ
出力形式として[AVRO] が選択されている場合は、データベース取り込みとレプリケーション が各ソーステーブルのAvroスキーマ定義を格納しているローカルディレクトリを指定します。スキーマ定義ファイルには、次の命名パターンがあります。
schemaname _tablename .txt
注: このディレクトリが指定されていない場合、Avroスキーマ定義ファイルは作成されません。
ファイル圧縮タイプ
CSVまたはAVRO出力形式の出力ファイルのファイル圧縮タイプを選択します。次のオプションがあります。
- なし - Deflate - Gzip - Snappy デフォルト値は[なし] 、これは圧縮が使用されないことを意味します。
Avro圧縮タイプ
[AVRO] が出力形式としてが選択されている場合は、Avro圧縮タイプを選択します。次のオプションがあります。
- なし - Bzip2 - Deflate - Snappy デフォルト値は[なし] 、これは圧縮が使用されないことを意味します。
Parquet圧縮タイプ
[PARQUET] 出力形式が選択されている場合、Parquetでサポートされている圧縮タイプを選択できます。次のオプションがあります。
デフォルト値は[なし] 、これは圧縮が使用されないことを意味します。
Deflate圧縮レベル
[Deflate] が[Avro圧縮タイプ] フィールドで選択されている場合、圧縮レベルとして0~9を指定します。デフォルトは0です。
ディレクトリタグの追加
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合、Hiveパーティショニングの命名規則と互換性を持たせるために適用サイクルディレクトリの名前に「dt=」プレフィックスを追加するには、このチェックボックスをオンにします。このチェックボックスはデフォルトでオフになっています。
タスクターゲットディレクトリ
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合、出力データファイル、スキーマファイル、およびCDCサイクルのコンテンツと完了ファイルを保持する他のディレクトリのルートディレクトリ。このフィールドを使用して、タスクのカスタムルートディレクトリを指定できます。[親としての接続ディレクトリ] オプションを有効にしている場合は、必要に応じて、接続プロパティで指定された親ディレクトリで使用するタスクターゲットディレクトリを指定できます。
このフィールドは、次のディレクトリフィールドのいずれかのパターンで{TaskTargetDirectory}プレースホルダが指定されている場合は必須です。
親としての接続ディレクトリ
ターゲット接続プロパティで指定されたディレクトリ値を、タスクターゲットプロパティで指定されたカスタムディレクトリパスの親ディレクトリとして使用するようにするには、このチェックボックスをオンにします。初期ロードタスクの場合、親ディレクトリは、データディレクトリ とスキーマディレクトリ で使用されます。増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合、親ディレクトリはデータディレクトリ 、スキーマディレクトリ 、サイクル完了ディレクトリ 、およびサイクルコンテンツディレクトリ で使用されます。
このチェックボックスはデフォルトで選択されています。オフにしたとき、初期ロードの場合は、[データディレクトリ] フィールドで出力ファイルへのフルパスを定義します。増分ロードの場合は、必要に応じて[タスクターゲットディレクトリ] でタスクのルートディレクトリを指定します。
データディレクトリ
初期ロードタスクの場合、データベース取り込みとレプリケーション が出力データファイルとオプションでスキーマを保存するディレクトリのディレクトリ構造を定義します。ディレクトリパターンを定義するには、次のタイプのエントリを使用できます。
- - - placeholder )の値を強制的に大文字または小文字に変換します。注: プレースホルダの値の大文字と小文字は区別されません。
例:
myDir1/{SchemaName}/{TableName}
デフォルトのディレクトリパターンは{TableName)_{Timestamp} です。
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合は 、cdc-dataデータファイルを含むサブディレクトリへのカスタムパスを定義します。ディレクトリパターンを定義する場合は、次のタイプのエントリを使用します。
デフォルトのディレクトリパターンは{TaskTargetDirectory}/data/{TableName}/data です。
注: Amazon S3、フラットファイル、Microsoft Azure Data Lake Storage Gen2、およびOracle Cloud Object Storeターゲットでは、[親としての接続ディレクトリ] が選択されている場合、データベース取り込みとレプリケーション は、ターゲット接続プロパティで指定されたディレクトリをデータディレクトリパスのルートとして使用します。Google Cloud Storageターゲットの場合、データベース取り込みとレプリケーション は取り込みタスクのターゲットプロパティで指定したバケット 名を使用します。Microsoft Fabric OneLakeターゲットの場合、親ディレクトリは、Microsoft Fabric OneLake接続プロパティの[レイクハウスのパス] フィールドで指定されたパスです。
スキーマディレクトリ
デフォルトディレクトリ以外のディレクトリにスキーマファイルを保存する場合は、スキーマファイルを保存するカスタムディレクトリを指定できます。初期ロードの場合、便利になるように、以前に使用した値を使用できる場合はそれがドロップダウンリストに表示されます。このフィールドはオプションです。
初期ロードの場合、デフォルトでは、スキーマはデータディレクトリに保存されます。増分ロード、および初期ロードと増分ロードの組み合わせの場合、スキーマファイルのデフォルトディレクトリは{TaskTargetDirectory}/data/{TableName}/schema です。
[データディレクトリ] フィールドと同じプレースホルダを使用できます。プレースホルダは必ず中かっこ{ }で囲んでください。
toUpperまたはtoLower関数を含める場合は、{toLower(SchemaName)} のように、プレースホルダ名を丸かっこで囲み、関数とプレースホルダの両方を中かっこで囲みます。
注: スキーマは、CSV形式で出力データファイルにのみ書き込まれます。ParquetおよびAvro形式のデータファイルには、独自の埋め込みスキーマが含まれています。
サイクル完了ディレクトリ
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合、サイクル完了ファイルを含むディレクトリへのパス。デフォルトは{TaskTargetDirectory}/cycle/completed です。
サイクルコンテンツディレクトリ
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合、サイクルコンテンツファイルを含むディレクトリへのパス。デフォルトは{TaskTargetDirectory}/cycle/contents です。
データディレクトリにサイクルのパーティション化を使用する
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合、各データディレクトリの下に、CDCサイクルごとにタイムスタンプサブディレクトリが作成されます。
このオプションが選択されていない場合、別のディレクトリ構造を定義しない限り、個々のデータファイルがタイムスタンプなしで同じディレクトリに書き込まれます。
サマリディレクトリにサイクルのパーティション化を使用する
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合は、サマリコンテンツサブディレクトリおよび完了サブディレクトリの下にCDCサイクルごとにタイムスタンプサブディレクトリが作成されます。
コンテンツ内の個々のファイルを一覧表示する
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合は、コンテンツサブディレクトリの下に個々のデータファイルが一覧表示されます。
[サマリディレクトリにサイクルのパーティション化を使用する] がオフの場合は、このオプションがデフォルトでオンになります。タイムスタンプや日付などのプレースホルダを使用してカスタムサブディレクトリを設定できる場合を除き、コンテンツサブディレクトリ内の個々のファイルがすべて一覧表示されます。
[データディレクトリにサイクルのパーティション化を使用する] が選択されている場合でも、必要に応じてこのチェックボックスを選択して、個々のファイルを一覧表示し、CDCサイクルごとにグループ化することができます。
[詳細] で次のような詳細ターゲットプロパティを入力できます。これらは主に増分ロードジョブと組み合わせロードジョブに関係するものです。
フィールド
説明
操作タイプの追加
ジョブがターゲットにプロパゲートする出力にソースSQL操作タイプを記録するメタデータカラムを追加するには、このチェックボックスを選択します。
増分ロードの場合、ジョブは、挿入を表す「I」、更新を表す「U」、または削除を表す「D」を書き込みます。初期ロードの場合、ジョブは常に、挿入を表す「I」を書き込みます。
デフォルトでは、このチェック ボックスは、増分ロードジョブ、初期および増分ロードジョブの場合はオンになっており、初期ロードジョブの場合はオフになっています。
操作時間の追加
ジョブがターゲットにプロパゲートする出力にソースSQL操作タイムスタンプを記録するメタデータカラムを追加するには、このチェックボックスをオンにします。
初期ロードの場合、ジョブは常に現在の日付と時刻を書き込みます。
デフォルトでは、このチェックボックスは選択されていません。
操作所有者の追加
ジョブがターゲットにプロパゲートする出力にソースSQL操作の所有者を記録するメタデータカラムを追加するには、このチェックボックスを選択します。
初期ロードの場合、ジョブは常に所有者として「INFA」を書き込みます。
デフォルトでは、このチェックボックスは選択されていません。
このプロパティは、MongoDBソースまたはPostgreSQLソースを持つジョブでは使用できません。
注: このプロパティは、SQL Serverソースを持ち、CDCテーブルキャプチャメソッドを使用するおよびジョブではサポートされていません。
操作トランザクションIDの追加
ジョブがSQL操作のターゲットにプロパゲートする出力にソーストランザクションIDを含むメタデータカラムを追加するには、このチェックボックスを選択します。
初期ロードの場合、ジョブは常にIDとして「1」を書き込みます。
デフォルトでは、このチェックボックスは選択されていません。
前のイメージを追加
ジョブがターゲットに書き込む出力にUNDOデータを含めるには、このチェックボックスを選択します。
初期ロードの場合、ジョブはnullを書き込みます。
デフォルトでは、このチェックボックスは選択されていません。
Microsoft Azure Synapse Analyticsターゲットのプロパティ データベース取り込みとレプリケーション タスクを定義する場合は、Microsoft Azure Synapse Analyticsターゲットのいくつかのプロパティをタスクウィザードの[ターゲット] ページで入力する必要があります。
これらのプロパティは、初期ロード、増分ロード、および初期ロードと増分ロードの組み合わせ操作に適用されます。
次の表は、[ターゲット] に表示されるターゲットのプロパティについて説明しています。
プロパティ
説明
ターゲット作成
利用可能なただ1つのオプションは、[ターゲットテーブルを作成する] であり、これによりソーステーブルをベースにしてターゲットテーブルを生成します。
注: ターゲットテーブルが作成された後、データベース取り込みとレプリケーション は、後続のジョブ実行でターゲットテーブルをインテリジェントに処理します。データベース取り込みとレプリケーション は、特定の状況に応じて、ターゲットテーブルを切り詰めたり再作成したりする場合があります。
スキーマ
データベース取り込みとレプリケーション がターゲットテーブルを作成するターゲットスキーマを選択します。接続プロパティで指定されたスキーマ名がデフォルトで表示されます。このフィールドでは大文字と小文字が区別されるため、接続プロパティのスキーマ名が適切な大文字小文字表記で入力されていることを確認してください。
次の表は、[詳細] に表示されるターゲットの詳細プロパティについて説明しています。
プロパティ
説明
最終レプリケート時刻を追加
ターゲットテーブルでレコードが挿入または最後に更新された時点のタイムスタンプを記録するメタデータカラムを追加するには、このチェックボックスをオンにします。初期ロードでは、ロードされたすべてのレコードのタイムスタンプが同じになります。増分ロード、および初期ロードと増分ロードの組み合わせの場合、このカラムには、ターゲットに適用された最後のDML操作のタイムスタンプが記録されます。
デフォルトでは、このチェックボックスは選択されていません。
メタデータカラムのプレフィックス
追加されたメタデータカラムの名前にプレフィックスを追加し、それらを簡単に識別して、既存のカラムの名前との競合を防ぐことができるようにします。
プレフィックスには特殊文字を含めないようにしてください。特殊文字を含めた場合、タスクのデプロイメントが失敗します。
デフォルト値はINFA_です。
Microsoft Fabric OneLakeターゲットプロパティ Microsoft Fabric OneLakeターゲットを持つデータベース取り込みとレプリケーション タスクを定義する場合、タスクウィザードの[ターゲット] ページでいくつかのターゲットプロパティを入力する必要があります。
[ターゲット] では、次のMicrosoft Fabric OneLakeターゲットのプロパティを入力できます。
プロパティ
説明
出力形式
出力ファイルの形式を選択します。次のオプションがあります。
デフォルトの値は[CSV] です。
注: CSV形式の出力ファイルでは、各フィールドの区切り文字として二重引用符("")が使用されます。
CSVファイルへのヘッダーの追加
[CSV] が出力形式として選択されている場合は、このチェックボックスをオンにして、ソース列名を含むヘッダーを出力CSVファイルに追加します。
Avro形式
出力形式として[AVRO] を選択した場合、ソーステーブルごとに作成されるAvroスキーマの形式を選択します。次のオプションがあります。
- Avro-Flat 。すべてのAvroフィールドを1つのレコードに一覧表示する場合に、このAvroスキーマ形式を使用します。- Avro-Generic 。ソーステーブルのすべてのカラムをAvroフィールドの単一の配列に一覧表示する場合に、このAvroスキーマ形式を使用します。- Avro-Nested 。各タイプの情報を個別のレコードに編成する場合に、このAvroスキーマ形式を使用します。デフォルト値は[Avro-Flat] です。
Avroシリアル化形式
出力形式として[AVRO] が選択されている場合は、Avro出力ファイルのシリアル化形式を選択します。次のオプションがあります。
デフォルト値は[Binary] です。
Avroスキーマディレクトリ
出力形式として[AVRO] が選択されている場合は、データベース取り込みとレプリケーション が各ソーステーブルのAvroスキーマ定義を格納しているローカルディレクトリを指定します。スキーマ定義ファイルには、次の命名パターンがあります。
schemaname _tablename .txt
注: このディレクトリが指定されていない場合、Avroスキーマ定義ファイルは作成されません。
ファイル圧縮タイプ
CSVまたはAVRO出力形式の出力ファイルのファイル圧縮タイプを選択します。次のオプションがあります。
- なし - Deflate - Gzip - Snappy デフォルト値は[なし] 、これは圧縮が使用されないことを意味します。
Avro圧縮タイプ
[AVRO] が出力形式としてが選択されている場合は、Avro圧縮タイプを選択します。次のオプションがあります。
- なし - Bzip2 - Deflate - Snappy デフォルト値は[なし] 、これは圧縮が使用されないことを意味します。
Parquet圧縮タイプ
[PARQUET] 出力形式が選択されている場合、Parquetでサポートされている圧縮タイプを選択できます。次のオプションがあります。
デフォルト値は[なし] 、これは圧縮が使用されないことを意味します。
Deflate圧縮レベル
[Deflate] が[Avro圧縮タイプ] フィールドで選択されている場合、圧縮レベルとして0~9を指定します。デフォルトは0です。
ディレクトリタグの追加
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合、Hiveパーティショニングの命名規則と互換性を持たせるために適用サイクルディレクトリの名前に「dt=」プレフィックスを追加するには、このチェックボックスをオンにします。このチェックボックスはデフォルトでオフになっています。
タスクターゲットディレクトリ
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合、出力データファイル、スキーマファイル、およびCDCサイクルのコンテンツと完了ファイルを保持する他のディレクトリのルートディレクトリ。このフィールドを使用して、タスクのカスタムルートディレクトリを指定できます。
このフィールドは、次のディレクトリフィールドのいずれかのパターンで{TaskTargetDirectory}プレースホルダが指定されている場合は必須です。
データディレクトリ
初期ロードタスクの場合、データベース取り込みとレプリケーション が出力データファイルとオプションでスキーマを保存するディレクトリのディレクトリ構造を定義します。ディレクトリパターンを定義するには、次のタイプのエントリを使用できます。
- - - placeholder )の値を強制的に大文字または小文字に変換します。注: プレースホルダの値の大文字と小文字は区別されません。
例:
myDir1/{SchemaName}/{TableName}
デフォルトのディレクトリパターンは{TableName)_{Timestamp} です。
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合は 、cdc-dataデータファイルを含むサブディレクトリへのカスタムパスを定義します。ディレクトリパターンを定義する場合は、次のタイプのエントリを使用します。
デフォルトのディレクトリパターンは{TaskTargetDirectory}/data/{TableName}/data です。
注: Amazon S3、フラットファイル、Microsoft Azure Data Lake Storage Gen2、およびOracle Cloud Object Storeターゲットでは、[親としての接続ディレクトリ] が選択されている場合、データベース取り込みとレプリケーション は、ターゲット接続プロパティで指定されたディレクトリをデータディレクトリパスのルートとして使用します。Google Cloud Storageターゲットの場合、データベース取り込みとレプリケーション は取り込みタスクのターゲットプロパティで指定したバケット 名を使用します。Microsoft Fabric OneLakeターゲットの場合、親ディレクトリは、Microsoft Fabric OneLake接続プロパティの[レイクハウスのパス] フィールドで指定されたパスです。
スキーマディレクトリ
デフォルトディレクトリ以外のディレクトリにスキーマファイルを保存する場合は、スキーマファイルを保存するカスタムディレクトリを指定できます。初期ロードの場合、便利になるように、以前に使用した値を使用できる場合はそれがドロップダウンリストに表示されます。このフィールドはオプションです。
初期ロードの場合、デフォルトでは、スキーマはデータディレクトリに保存されます。増分ロード、および初期ロードと増分ロードの組み合わせの場合、スキーマファイルのデフォルトディレクトリは{TaskTargetDirectory}/data/{TableName}/schema です。
[データディレクトリ] フィールドと同じプレースホルダを使用できます。プレースホルダは必ず中かっこ{ }で囲んでください。
toUpperまたはtoLower関数を含める場合は、{toLower(SchemaName)} のように、プレースホルダ名を丸かっこで囲み、関数とプレースホルダの両方を中かっこで囲みます。
注: スキーマは、CSV形式で出力データファイルにのみ書き込まれます。ParquetおよびAvro形式のデータファイルには、独自の埋め込みスキーマが含まれています。
サイクル完了ディレクトリ
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合、サイクル完了ファイルを含むディレクトリへのパス。デフォルトは{TaskTargetDirectory}/cycle/completed です。
サイクルコンテンツディレクトリ
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合、サイクルコンテンツファイルを含むディレクトリへのパス。デフォルトは{TaskTargetDirectory}/cycle/contents です。
データディレクトリにサイクルのパーティション化を使用する
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合、各データディレクトリの下に、CDCサイクルごとにタイムスタンプサブディレクトリが作成されます。
このオプションが選択されていない場合、別のディレクトリ構造を定義しない限り、個々のデータファイルがタイムスタンプなしで同じディレクトリに書き込まれます。
サマリディレクトリにサイクルのパーティション化を使用する
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合は、サマリコンテンツサブディレクトリおよび完了サブディレクトリの下にCDCサイクルごとにタイムスタンプサブディレクトリが作成されます。
コンテンツ内の個々のファイルを一覧表示する
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合は、コンテンツサブディレクトリの下に個々のデータファイルが一覧表示されます。
[サマリディレクトリにサイクルのパーティション化を使用する] がオフの場合は、このオプションがデフォルトでオンになります。タイムスタンプや日付などのプレースホルダを使用してカスタムサブディレクトリを設定できる場合を除き、コンテンツサブディレクトリ内の個々のファイルがすべて一覧表示されます。
[データディレクトリにサイクルのパーティション化を使用する] が選択されている場合でも、必要に応じてこのチェックボックスを選択して、個々のファイルを一覧表示し、CDCサイクルごとにグループ化することができます。
Microsoft SQL Serverターゲットのプロパティ データベース取り込みとレプリケーション タスクを定義する場合は、Microsoft SQL Serverターゲットのいくつかのプロパティをタスクウィザードの[ターゲット] ページで入力する必要があります。
次の表は、[ターゲット] に表示されるターゲットのプロパティについて説明しています。
プロパティ
説明
ターゲット作成
利用可能なただ1つのオプションは、[ターゲットテーブルを作成する] であり、これによりソーステーブルをベースにしてターゲットテーブルを生成します。
注: ターゲットテーブルが作成された後、データベース取り込みとレプリケーション は、後続のジョブ実行でターゲットテーブルをインテリジェントに処理します。データベース取り込みとレプリケーション は、特定の状況に応じて、ターゲットテーブルを切り詰めたり再作成したりする場合があります。
スキーマ
データベース取り込みとレプリケーション がターゲットテーブルを作成するターゲットスキーマを選択します。
適用モード
増分ロードジョブ、および初期ロードと増分ロードの組み合わせジョブの場合に、挿入、更新、削除といったソースDMLの変更がターゲットにどのように適用されるかを示します。次のオプションがあります。
- 標準 。1回の適用サイクルの間の変更を累積し、それをターゲットに適用する前に、より少ないSQL文になるようにそれらをインテリジェントにマージします。例えば、ソース行で更新とそれに続く削除が発生した場合、ターゲットに行は適用されません。同じカラムまたはフィールドで複数の更新が発生した場合、最後の更新のみがターゲットに適用されます。異なるカラムまたはフィールドで複数の更新が発生した場合、更新はターゲットに適用される前に1つの更新レコードにマージされます。- 監査 。ソーステーブルで実行されたすべてのDML操作の監査証跡をターゲットに適用します。ソーステーブルの各DML変更の行が、[詳細] セクションで選択した監査カラムとともに、生成されたターゲットテーブルに書き込まれます。監査カラムには、DML操作タイプ、時刻、所有者、トランザクションID、生成された昇順シーケンス番号、前のイメージなどの変更に関するメタデータが含まれています。監査履歴を使用して、データをターゲットデータベースに書き込む前にダウンストリームの計算または処理を実行する場合、またはキャプチャされた変更に関するメタデータを調べる場合は、監査適用モードの使用を検討してください。- 論理削除 。ソース削除操作を論理削除としてターゲットに適用します。論理削除では、削除された行をデータベースから実際には削除せずに、削除済みとしてマークします。例えば、ソースで削除を行うと、ターゲットの変更レコードのINFA_OPERATION_TYPEカラムに「D」が表示されます。処理を完了するために論理的に削除されたデータが必要となる、長期にわたるビジネスプロセスがある場合、誤って削除したデータを復元する必要がある場合、または削除された値を監査目的で追跡する必要がある場合は、論理削除の使用を検討してください。
注: [論理削除] モードを使用する場合は、ソーステーブルのプライマリキーに対して更新を実行しないでください。そうしないと、ターゲットでデータ破損が発生する可能性があります。
デフォルト値は[標準] です。
注: タスクウィザードの[ソース] ページで手法として[クエリベースのCDC] を選択した場合、このフィールドは表示されません。
次の表は、[詳細] に表示されるターゲットの詳細プロパティについて説明しています。
プロパティ
説明
最終レプリケート時刻を追加
ターゲットテーブルでレコードが挿入または最後に更新された時点のタイムスタンプを記録するメタデータカラムを追加するには、このチェックボックスをオンにします。初期ロードでは、ロードされたすべてのレコードのタイムスタンプが同じになります。増分ロード、および初期ロードと増分ロードの組み合わせの場合、このカラムには、ターゲットに適用された最後のDML操作のタイムスタンプが記録されます。
デフォルトでは、このチェックボックスは選択されていません。
操作タイプの追加
ジョブがターゲットデータベースにプロパゲートする出力、またはターゲットシステムの監査テーブルに挿入する出力にソースSQL操作タイプを記録するメタデータカラムを追加するには、このチェックボックスを選択します。
このフィールドは、[適用モード] オプションが[監査] または[論理削除] に設定されている場合にのみ使用できます。
監査モードでは、ジョブによって、挿入を表す「I」、更新を表す「U」、または削除を表す「D」が書き込まれます。
論理削除モードでは、ジョブは削除の場合は「D」を書き込み、挿入と更新の場合はNULLを書き込みます。操作タイプがNULLの場合、他の[操作の追加...]メタデータカラムもNULLです。操作タイプが「D」の場合にのみ、他のメタデータカラムにNULL以外の値が含まれます。
デフォルトでは、このチェックボックスは選択されています。論理削除を使用している場合は、選択を解除できません。
操作時間の追加
ジョブがターゲットデータベースにプロパゲートする出力、またはターゲットシステムの監査テーブルに挿入する出力にソースSQL操作のタイムスタンプを記録するメタデータカラムを追加するには、このチェックボックスを選択します。
このフィールドは、[適用モード] が[監査] または[論理削除] に設定されている場合にのみ使用できます。
デフォルトでは、このチェックボックスは選択されていません。
操作所有者の追加
ジョブがターゲットデータベースにプロパゲートする出力、またはターゲットシステムの監査テーブルに挿入する出力にソースSQL操作の所有者を記録するメタデータカラムを追加するには、このチェックボックスを選択します。
このフィールドは、[適用モード] が[監査] または[論理削除] に設定されている場合にのみ使用できます。
デフォルトでは、このチェックボックスは選択されていません。
このプロパティは、MongoDBソースまたはPostgreSQLソースを持つジョブでは使用できません。
注: このプロパティは、SQL Serverソースを持ち、CDCテーブルキャプチャメソッドを使用するおよびジョブではサポートされていません。
操作トランザクションIDの追加
ジョブがSQL操作のターゲットにプロパゲートする出力にソーストランザクションIDを含むメタデータカラムを追加するには、このチェックボックスを選択します。
このフィールドは、[適用モード] が[監査] または[論理削除] に設定されている場合にのみ使用できます。
デフォルトでは、このチェックボックスは選択されていません。
操作シーケンスの追加
ジョブがターゲットシステムの監査テーブルに挿入する変更操作ごとに、生成された昇順のシーケンス番号を記録するメタデータカラムを追加するには、このチェックボックスを選択します。シーケンス番号には、操作の変更ストリーム位置が反映されます。
このフィールドは、[適用モード] が[監査] に設定されている場合にのみ使用できます。
デフォルトでは、このチェックボックスは選択されていません。
前のイメージを追加
ジョブがターゲットテーブルに挿入する出力にUNDOの「操作前のイメージ」データを含む_OLDカラムを追加するには、このチェックボックスを選択します。これにより、各データカラムの以前の値と現在の値を比較できるようになります。削除操作の場合、現在の値はNULLになります。
このフィールドは、[適用モード] が[監査] に設定されている場合にのみ使用できます。
デフォルトでは、このチェックボックスは選択されていません。
メタデータカラムのプレフィックス
追加されたメタデータカラムの名前にプレフィックスを追加し、それらを簡単に識別して、既存のカラムの名前との競合を防ぐことができるようにします。
プレフィックスには特殊文字を含めないようにしてください。特殊文字を含めた場合、タスクのデプロイメントが失敗します。
デフォルト値はINFA_です。
Oracleターゲットのプロパティ データベース取り込みとレプリケーション タスクを定義する場合は、Oracleターゲットのいくつかのプロパティをタスクウィザードの[ターゲット] ページで入力する必要があります。プロパティは、ロードタイプによってわずかに異なります。
次の表は、[ターゲット] に表示されるOracleターゲットのプロパティについて説明しています。
プロパティ
説明
ターゲット作成
利用可能なただ1つのオプションは、[ターゲットテーブルを作成する] であり、これによりソーステーブルをベースにしてターゲットテーブルを生成します。
注: ターゲットテーブルが作成された後、データベース取り込みとレプリケーション は、後続のジョブ実行でターゲットテーブルをインテリジェントに処理します。データベース取り込みとレプリケーション は、特定の状況に応じて、ターゲットテーブルを切り詰めたり再作成したりする場合があります。
スキーマ
データベース取り込みとレプリケーション がターゲットテーブルを作成するターゲットスキーマを選択します。
適用モード
増分ロードジョブ、および初期ロードと増分ロードの組み合わせジョブの場合に、挿入、更新、削除といったソースDMLの変更がターゲットにどのように適用されるかを示します。次のオプションがあります。
- 標準 。1回の適用サイクルの間の変更を累積し、それをターゲットに適用する前に、より少ないSQL文になるようにそれらをインテリジェントにマージします。例えば、ソース行で更新とそれに続く削除が発生した場合、ターゲットに行は適用されません。同じカラムまたはフィールドで複数の更新が発生した場合、最後の更新のみがターゲットに適用されます。異なるカラムまたはフィールドで複数の更新が発生した場合、更新はターゲットに適用される前に1つの更新レコードにマージされます。- 監査 。ソーステーブルで行われたすべてのDML操作の監査証跡をターゲットに適用します。ソーステーブルの各DML変更の行が、[詳細] セクションで選択した監査カラムとともに、生成されたターゲットテーブルに書き込まれます。監査カラムには、DML操作タイプ、時刻、所有者、トランザクションID、生成された昇順シーケンス番号などの変更に関するメタデータが含まれています。監査履歴を使用して、データをターゲットデータベースに書き込む前にダウンストリームの計算または処理を実行する場合、またはキャプチャされた変更に関するメタデータを調べる場合は、監査適用モードの使用を検討してください。デフォルト値は[標準] です。
注: タスクウィザードの[ソース] ページで手法として[クエリベースのCDC] を選択した場合、このフィールドは表示されません。
次の表は、[適用モード] を[監査] に設定している場合に[詳細] で設定できる詳細ターゲットプロパティについて説明します。
フィールド
説明
操作タイプの追加
ジョブがターゲットデータベースにプロパゲートする出力、またはターゲットテーブルに挿入する出力にソースSQL操作タイプを記録するメタデータカラムを追加するには、このチェックボックスを選択します。
ジョブは、挿入を表す「I」、更新を表す「U」、または削除を表す「D」を書き込みます。
デフォルトでは、このチェックボックスは選択されています。
操作時間の追加
ジョブがターゲットテーブルにプロパゲートする出力にソースSQL操作タイムスタンプを記録するメタデータカラムを追加するには、このチェックボックスをオンにします。
デフォルトでは、このチェックボックスは選択されていません。
操作所有者の追加
ジョブがターゲットにプロパゲートする出力にソースSQL操作の所有者を記録するメタデータカラムを追加するには、このチェックボックスを選択します。
デフォルトでは、このチェックボックスは選択されていません。
このプロパティは、MongoDBソースまたはPostgreSQLソースを持つジョブでは使用できません。
注: このプロパティは、SQL Serverソースを持ち、CDCテーブルキャプチャメソッドを使用するおよびジョブではサポートされていません。
操作トランザクションIDの追加
ジョブがSQL操作のターゲットにプロパゲートする出力にソーストランザクションIDを含むメタデータカラムを追加するには、このチェックボックスを選択します。
デフォルトでは、このチェックボックスは選択されていません。
操作シーケンスの追加
ジョブがターゲットテーブルに挿入する変更操作ごとに、生成された昇順のシーケンス番号を記録するメタデータカラムを追加するには、このチェックボックスを選択します。シーケンス番号には、操作の変更ストリーム位置が反映されます。
デフォルトでは、このチェックボックスは選択されていません。
前のイメージを追加
ジョブがターゲットテーブルに挿入する出力にUNDOの「操作前のイメージ」データを含む_OLDカラムを追加するには、このチェックボックスを選択します。これにより、各データカラムの以前の値と現在の値を比較できるようになります。削除操作の場合、現在の値はNULLになります。
デフォルトでは、このチェックボックスは選択されていません。
メタデータカラムのプレフィックス
追加されたメタデータカラムの名前にプレフィックスを追加し、それらを簡単に識別して、既存のカラムの名前との競合を防ぐことができるようにします。
デフォルト値はINFA_です。
Oracle Cloud Object Storageターゲットのプロパティ Oracle Cloud Object Storageターゲットのあるデータベース取り込みとレプリケーション タスクを定義する場合、タスクウィザードの[ターゲット] タブでターゲットのプロパティをいくつか入力する必要があります。
[ターゲット] では、次のOracle Cloud Object Storageターゲットのプロパティを入力できます。
プロパティ
説明
出力形式
出力ファイルの形式を選択します。次のオプションがあります。
デフォルトの値は[CSV] です。
注: CSV形式の出力ファイルでは、各フィールドの区切り文字として二重引用符("")が使用されます。
CSVファイルへのヘッダーの追加
[CSV] が出力形式として選択されている場合は、このチェックボックスをオンにして、ソース列名を含むヘッダーを出力CSVファイルに追加します。
Avro形式
出力形式として[AVRO] を選択した場合、ソーステーブルごとに作成されるAvroスキーマの形式を選択します。次のオプションがあります。
- Avro-Flat 。すべてのAvroフィールドを1つのレコードに一覧表示する場合に、このAvroスキーマ形式を使用します。- Avro-Generic 。ソーステーブルのすべてのカラムをAvroフィールドの単一の配列に一覧表示する場合に、このAvroスキーマ形式を使用します。- Avro-Nested 。各タイプの情報を個別のレコードに編成する場合に、このAvroスキーマ形式を使用します。デフォルト値は[Avro-Flat] です。
Avroシリアル化形式
出力形式として[AVRO] が選択されている場合は、Avro出力ファイルのシリアル化形式を選択します。次のオプションがあります。
デフォルト値は[Binary] です。
Avroスキーマディレクトリ
出力形式として[AVRO] が選択されている場合は、データベース取り込みとレプリケーション が各ソーステーブルのAvroスキーマ定義を格納しているローカルディレクトリを指定します。スキーマ定義ファイルには、次の命名パターンがあります。
schemaname _tablename .txt
注: このディレクトリが指定されていない場合、Avroスキーマ定義ファイルは作成されません。
ファイル圧縮タイプ
CSVまたはAVRO出力形式の出力ファイルのファイル圧縮タイプを選択します。次のオプションがあります。
- なし - Deflate - Gzip - Snappy デフォルト値は[なし] 、これは圧縮が使用されないことを意味します。
Avro圧縮タイプ
[AVRO] が出力形式としてが選択されている場合は、Avro圧縮タイプを選択します。次のオプションがあります。
- なし - Bzip2 - Deflate - Snappy デフォルト値は[なし] 、これは圧縮が使用されないことを意味します。
Parquet圧縮タイプ
[PARQUET] 出力形式が選択されている場合、Parquetでサポートされている圧縮タイプを選択できます。次のオプションがあります。
デフォルト値は[なし] 、これは圧縮が使用されないことを意味します。
Deflate圧縮レベル
[Deflate] が[Avro圧縮タイプ] フィールドで選択されている場合、圧縮レベルとして0~9を指定します。デフォルトは0です。
タスクターゲットディレクトリ
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合、出力データファイル、スキーマファイル、およびCDCサイクルのコンテンツと完了ファイルを保持する他のディレクトリのルートディレクトリ。このフィールドを使用して、タスクのカスタムルートディレクトリを指定できます。[親としての接続ディレクトリ] オプションを有効にしている場合は、必要に応じて、接続プロパティで指定された親ディレクトリで使用するタスクターゲットディレクトリを指定できます。
このフィールドは、次のディレクトリフィールドのいずれかのパターンで{TaskTargetDirectory}プレースホルダが指定されている場合は必須です。
ディレクトリタグの追加
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合、Hiveパーティショニングの命名規則と互換性を持たせるために適用サイクルディレクトリの名前に「dt=」プレフィックスを追加するには、このチェックボックスをオンにします。このチェックボックスはデフォルトでオフになっています。
親としての接続ディレクトリ
ターゲット接続プロパティで指定されたディレクトリ値を、タスクターゲットプロパティで指定されたカスタムディレクトリパスの親ディレクトリとして使用するようにするには、このチェックボックスをオンにします。初期ロードタスクの場合、親ディレクトリは、データディレクトリ とスキーマディレクトリ で使用されます。増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合、親ディレクトリはデータディレクトリ 、スキーマディレクトリ 、サイクル完了ディレクトリ 、およびサイクルコンテンツディレクトリ で使用されます。
このチェックボックスはデフォルトで選択されています。オフにしたとき、初期ロードの場合は、[データディレクトリ] フィールドで出力ファイルへのフルパスを定義します。増分ロードの場合は、必要に応じて[タスクターゲットディレクトリ] でタスクのルートディレクトリを指定します。
データディレクトリ
初期ロードタスクの場合、データベース取り込みとレプリケーション が出力データファイルとオプションでスキーマを保存するディレクトリのディレクトリ構造を定義します。ディレクトリパターンを定義するには、次のタイプのエントリを使用できます。
- - - placeholder )の値を強制的に大文字または小文字に変換します。注: プレースホルダの値の大文字と小文字は区別されません。
例:
myDir1/{SchemaName}/{TableName}
デフォルトのディレクトリパターンは{TableName)_{Timestamp} です。
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合は 、cdc-dataデータファイルを含むサブディレクトリへのカスタムパスを定義します。ディレクトリパターンを定義する場合は、次のタイプのエントリを使用します。
デフォルトのディレクトリパターンは{TaskTargetDirectory}/data/{TableName}/data です。
注: Amazon S3、フラットファイル、Microsoft Azure Data Lake Storage Gen2、およびOracle Cloud Object Storeターゲットでは、[親としての接続ディレクトリ] が選択されている場合、データベース取り込みとレプリケーション は、ターゲット接続プロパティで指定されたディレクトリをデータディレクトリパスのルートとして使用します。Google Cloud Storageターゲットの場合、データベース取り込みとレプリケーション は取り込みタスクのターゲットプロパティで指定したバケット 名を使用します。Microsoft Fabric OneLakeターゲットの場合、親ディレクトリは、Microsoft Fabric OneLake接続プロパティの[レイクハウスのパス] フィールドで指定されたパスです。
スキーマディレクトリ
デフォルトディレクトリ以外のディレクトリにスキーマファイルを保存する場合は、スキーマファイルを保存するカスタムディレクトリを指定できます。初期ロードの場合、便利になるように、以前に使用した値を使用できる場合はそれがドロップダウンリストに表示されます。このフィールドはオプションです。
初期ロードの場合、デフォルトでは、スキーマはデータディレクトリに保存されます。増分ロード、および初期ロードと増分ロードの組み合わせの場合、スキーマファイルのデフォルトディレクトリは{TaskTargetDirectory}/data/{TableName}/schema です。
[データディレクトリ] フィールドと同じプレースホルダを使用できます。プレースホルダは必ず中かっこ{ }で囲んでください。
toUpperまたはtoLower関数を含める場合は、{toLower(SchemaName)} のように、プレースホルダ名を丸かっこで囲み、関数とプレースホルダの両方を中かっこで囲みます。
注: スキーマは、CSV形式で出力データファイルにのみ書き込まれます。ParquetおよびAvro形式のデータファイルには、独自の埋め込みスキーマが含まれています。
サイクル完了ディレクトリ
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合、サイクル完了ファイルを含むディレクトリへのパス。デフォルトは{TaskTargetDirectory}/cycle/completed です。
サイクルコンテンツディレクトリ
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合、サイクルコンテンツファイルを含むディレクトリへのパス。デフォルトは{TaskTargetDirectory}/cycle/contents です。
データディレクトリにサイクルのパーティション化を使用する
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合、各データディレクトリの下に、CDCサイクルごとにタイムスタンプサブディレクトリが作成されます。
このオプションが選択されていない場合、別のディレクトリ構造を定義しない限り、個々のデータファイルがタイムスタンプなしで同じディレクトリに書き込まれます。
サマリディレクトリにサイクルのパーティション化を使用する
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合は、サマリコンテンツサブディレクトリおよび完了サブディレクトリの下にCDCサイクルごとにタイムスタンプサブディレクトリが作成されます。
コンテンツ内の個々のファイルを一覧表示する
増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクの場合は、コンテンツサブディレクトリの下に個々のデータファイルが一覧表示されます。
[サマリディレクトリにサイクルのパーティション化を使用する] がオフの場合は、このオプションがデフォルトでオンになります。タイムスタンプや日付などのプレースホルダを使用してカスタムサブディレクトリを設定できる場合を除き、コンテンツサブディレクトリ内の個々のファイルがすべて一覧表示されます。
[データディレクトリにサイクルのパーティション化を使用する] が選択されている場合でも、必要に応じてこのチェックボックスを選択して、個々のファイルを一覧表示し、CDCサイクルごとにグループ化することができます。
[詳細] で次のような詳細ターゲットプロパティを入力して、監査テーブルに記録された各削除操作または各DML変更にメタデータカラムを追加することができます。
フィールド
説明
操作タイプの追加
ジョブがターゲットにプロパゲートする出力にソースSQL操作タイプを記録するメタデータカラムを追加するには、このチェックボックスを選択します。
増分ロードの場合、ジョブは、挿入を表す「I」、更新を表す「U」、または削除を表す「D」を書き込みます。初期ロードの場合、ジョブは常に、挿入を表す「I」を書き込みます。
デフォルトでは、このチェック ボックスは、増分ロードジョブ、初期および増分ロードジョブの場合はオンになっており、初期ロードジョブの場合はオフになっています。
操作時間の追加
ジョブがターゲットにプロパゲートする出力にソースSQL操作タイムスタンプを記録するメタデータカラムを追加するには、このチェックボックスをオンにします。
初期ロードの場合、ジョブは常に現在の日付と時刻を書き込みます。
デフォルトでは、このチェックボックスは選択されていません。
操作所有者の追加
ジョブがターゲットにプロパゲートする出力にソースSQL操作の所有者を記録するメタデータカラムを追加するには、このチェックボックスを選択します。
初期ロードの場合、ジョブは常に所有者として「INFA」を書き込みます。
デフォルトでは、このチェックボックスは選択されていません。
このプロパティは、MongoDBソースまたはPostgreSQLソースを持つジョブでは使用できません。
注: このプロパティは、SQL Serverソースを持ち、CDCテーブルキャプチャメソッドを使用するおよびジョブではサポートされていません。
操作トランザクションIDの追加
ジョブがSQL操作のターゲットにプロパゲートする出力にソーストランザクションIDを含むメタデータカラムを追加するには、このチェックボックスを選択します。
初期ロードの場合、ジョブは常にIDとして「1」を書き込みます。
デフォルトでは、このチェックボックスは選択されていません。
前のイメージを追加
ジョブがターゲットに書き込む出力にUNDOデータを含めるには、このチェックボックスを選択します。
初期ロードの場合、ジョブはnullを書き込みます。
デフォルトでは、このチェックボックスは選択されていません。
PostgreSQLターゲットプロパティ データベース取り込みとレプリケーション タスクを定義する場合は、PostgreSQLターゲットのいくつかのプロパティを、タスクウィザードの[ターゲット] ページで入力する必要があります。
次の表は、[ターゲット] に表示されるターゲットのプロパティについて説明しています。
プロパティ
説明
ターゲット作成
利用可能なただ1つのオプションは、[ターゲットテーブルを作成する] であり、これによりソーステーブルをベースにしてターゲットテーブルを生成します。
注: ターゲットテーブルが作成された後、データベース取り込みとレプリケーション は、後続のジョブ実行でターゲットテーブルをインテリジェントに処理します。データベース取り込みとレプリケーション は、特定の状況に応じて、ターゲットテーブルを切り詰めたり再作成したりする場合があります。
スキーマ
データベース取り込みとレプリケーション がターゲットテーブルを作成するターゲットスキーマを選択します。
適用モード
増分ロードジョブ、および初期ロードと増分ロードの組み合わせジョブの場合に、挿入、更新、削除といったソースDMLの変更がターゲットにどのように適用されるかを示します。次のオプションがあります。
- 標準 。1回の適用サイクルの間の変更を累積し、それをターゲットに適用する前に、より少ないSQL文になるようにそれらをインテリジェントにマージします。例えば、ソース行で更新とそれに続く削除が発生した場合、ターゲットに行は適用されません。同じカラムまたはフィールドで複数の更新が発生した場合、最後の更新のみがターゲットに適用されます。異なるカラムまたはフィールドで複数の更新が発生した場合、更新はターゲットに適用される前に1つの更新レコードにマージされます。- 監査 。ソーステーブルで実行されたすべてのDML操作の監査証跡をターゲットに適用します。ソーステーブルの各DML変更の行が、[詳細] セクションで選択した監査カラムとともに、生成されたターゲットテーブルに書き込まれます。監査カラムには、DML操作タイプ、時刻、所有者、トランザクションID、生成された昇順シーケンス番号、前のイメージなどの変更に関するメタデータが含まれています。監査履歴を使用して、データをターゲットデータベースに書き込む前にダウンストリームの計算または処理を実行する場合、またはキャプチャされた変更に関するメタデータを調べる場合は、監査適用モードの使用を検討してください。- 論理削除 。ソース削除操作を論理削除としてターゲットに適用します。論理削除では、削除された行をデータベースから実際には削除せずに、削除済みとしてマークします。例えば、ソースで削除を行うと、ターゲットの変更レコードのINFA_OPERATION_TYPEカラムに「D」が表示されます。処理を完了するために論理的に削除されたデータが必要となる、長期にわたるビジネスプロセスがある場合、誤って削除したデータを復元する必要がある場合、または削除された値を監査目的で追跡する必要がある場合は、論理削除の使用を検討してください。
注: [論理削除] モードを使用する場合は、ソーステーブルのプライマリキーに対して更新を実行しないでください。そうしないと、ターゲットでデータ破損が発生する可能性があります。
デフォルト値は[標準] です。
注: [監査] および[論理削除] の適用モードは、Oracleソースを持つジョブでサポートされます。
注: タスクウィザードの[ソース] ページで手法として[クエリベースのCDC] を選択した場合、このフィールドは表示されません。
次の表は、[詳細] に表示されるターゲットの詳細プロパティについて説明しています。
プロパティ
説明
操作タイプの追加
ジョブがターゲットデータベースにプロパゲートする出力、またはターゲットテーブルに挿入する出力にソースSQL操作タイプを記録するメタデータカラムを追加するには、このチェックボックスを選択します。
このフィールドは、[適用モード] オプションが[監査] または[論理削除] に設定されている場合にのみ使用できます。
監査モードでは、ジョブによって、挿入を表す「I」、更新を表す「U」、または削除を表す「D」が書き込まれます。
論理削除モードでは、ジョブは削除の場合は「D」を書き込み、挿入と更新の場合はNULLを書き込みます。操作タイプがNULLの場合、他の[操作の追加...]メタデータカラムもNULLです。操作タイプが「D」の場合にのみ、他のメタデータカラムにNULL以外の値が含まれます。
デフォルトでは、このチェックボックスは選択されています。論理削除を使用している場合は、選択を解除できません。
操作時間の追加
ジョブがターゲットデータベースにプロパゲートする出力、またはターゲットシステムの監査テーブルに挿入する出力にソースSQL操作のタイムスタンプを記録するメタデータカラムを追加するには、このチェックボックスを選択します。
このフィールドは、[適用モード] が[監査] または[論理削除] に設定されている場合にのみ使用できます。
デフォルトでは、このチェックボックスは選択されていません。
操作所有者の追加
ジョブがターゲットデータベースにプロパゲートする出力、またはターゲットシステムの監査テーブルに挿入する出力にソースSQL操作の所有者を記録するメタデータカラムを追加するには、このチェックボックスを選択します。
このフィールドは、[適用モード] が[監査] または[論理削除] に設定されている場合にのみ使用できます。
デフォルトでは、このチェックボックスは選択されていません。
操作トランザクションIDの追加
ジョブがSQL操作のターゲットにプロパゲートする出力にソーストランザクションIDを含むメタデータカラムを追加するには、このチェックボックスを選択します。
このフィールドは、[適用モード] が[監査] または[論理削除] に設定されている場合にのみ使用できます。
デフォルトでは、このチェックボックスは選択されていません。
操作シーケンスの追加
ジョブがターゲットシステムの監査テーブルに挿入する変更操作ごとに、生成された昇順のシーケンス番号を記録するメタデータカラムを追加するには、このチェックボックスを選択します。シーケンス番号には、操作の変更ストリーム位置が反映されます。
このフィールドは、[適用モード] が[監査] に設定されている場合にのみ使用できます。
デフォルトでは、このチェックボックスは選択されていません。
前のイメージを追加
ジョブがターゲットテーブルに挿入する出力にUNDOの「操作前のイメージ」データを含む_OLDカラムを追加するには、このチェックボックスを選択します。これにより、各データカラムの以前の値と現在の値を比較できるようになります。削除操作の場合、現在の値はNULLになります。
このフィールドは、[適用モード] が[監査] に設定されている場合にのみ使用できます。
デフォルトでは、このチェックボックスは選択されていません。
メタデータカラムのプレフィックス
追加されたメタデータカラムの名前にプレフィックスを追加し、それらを簡単に識別して、既存のカラムの名前との競合を防ぐことができるようにします。
デフォルト値はINFA_です。
Snowflake Data Cloudターゲットのプロパティ データベース取り込みとレプリケーション タスクを定義する場合は、Snowflake Data Cloudターゲットのいくつかのプロパティをタスクウィザードの[ターゲット] ページで入力する必要があります。プロパティは、ロードタイプによってわずかに異なります。
次の表は、[ターゲット] に表示されるSnowflakeターゲットのプロパティについて説明しています。
プロパティ
説明
ターゲット作成
利用可能なただ1つのオプションは、[ターゲットテーブルを作成する] であり、これによりソーステーブルをベースにしてターゲットテーブルを生成します。
注: ターゲットテーブルが作成された後、データベース取り込みとレプリケーション は、後続のジョブ実行でターゲットテーブルをインテリジェントに処理します。データベース取り込みとレプリケーション は、特定の状況に応じて、ターゲットテーブルを切り詰めたり再作成したりする場合があります。
スキーマ
データベース取り込みとレプリケーション がターゲットテーブルを作成するターゲットスキーマを選択します。
ステージ
データがターゲットテーブルに書き込まれる前にソースから読み取られたデータを保持する内部ステージング領域の名前。この名前にスペースを含めることはできません。指定されたステージング領域が存在しない場合、自動的に作成されます。
注: [詳細ターゲットプロパティ] で[Superpipe] オプションを選択した場合、このフィールドは使用できません。
適用モード
増分ロードジョブ、および初期ロードと増分ロードの組み合わせジョブの場合に、挿入、更新、削除といったソースDMLの変更がターゲットにどのように適用されるかを示します。次のオプションがあります。
- 標準 。1回の適用サイクルの間の変更を累積し、それをターゲットに適用する前に、より少ないSQL文になるようにそれらをインテリジェントにマージします。例えば、ソース行で更新とそれに続く削除が発生した場合、ターゲットに行は適用されません。同じカラムまたはフィールドで複数の更新が発生した場合、最後の更新のみがターゲットに適用されます。異なるカラムまたはフィールドで複数の更新が発生した場合、更新はターゲットに適用される前に1つの更新レコードにマージされます。- 論理削除 。ソース削除操作を論理削除としてターゲットに適用します。論理削除では、削除された行をデータベースから実際には削除せずに、削除済みとしてマークします。例えば、ソースで削除を行うと、ターゲットの変更レコードのINFA_OPERATION_TYPEカラムに「D」が表示されます。処理を完了するために論理的に削除されたデータが必要となる、長期にわたるビジネスプロセスがある場合、誤って削除したデータを復元する必要がある場合、または削除された値を監査目的で追跡する必要がある場合は、論理削除の使用を検討してください。
注: [論理削除] モードを使用する場合は、ソーステーブルのプライマリキーに対して更新を実行しないでください。そうしないと、ターゲットでデータ破損が発生する可能性があります。
- 監査 。ソーステーブルで実行されたすべてのDML操作の監査証跡をターゲットに適用します。ソーステーブルの各DML変更の行が、[詳細] セクションで選択した監査カラムとともに、生成されたターゲットテーブルに書き込まれます。監査カラムには、DML操作タイプ、時刻、所有者、トランザクションID、生成された昇順シーケンス番号、前のイメージなどの変更に関するメタデータが含まれています。監査履歴を使用して、データをターゲットデータベースに書き込む前にダウンストリームの計算または処理を実行する場合、またはキャプチャされた変更に関するメタデータを調べる場合は、監査適用モードの使用を検討してください。デフォルト値は[標準] です。
注: タスクウィザードの[ソース] ページで手法として[クエリベースのCDC] を選択した場合、このフィールドは表示されません。
次の表は、[詳細] に表示されるターゲットの詳細プロパティについて説明しています。
プロパティ
説明
最終レプリケート時刻を追加
ターゲットテーブルでレコードが挿入または最後に更新された時点のタイムスタンプを記録するメタデータカラムを追加するには、このチェックボックスをオンにします。初期ロードの場合、ロードされたすべてのレコードのタイムスタンプは同じですが、Superpipeオプションを使用するSnowflakeターゲットに限り、分と秒がわずかに異なる可能性があります。増分ロード、および初期ロードと増分ロードの組み合わせの場合、このカラムには、ターゲットに適用された最後のDML操作のタイムスタンプが記録されます。
デフォルトでは、このチェックボックスは選択されていません。
操作タイプの追加
ジョブがターゲットデータベースにプロパゲートする出力、またはターゲットシステムの監査テーブルに挿入する出力にソースSQL操作タイプを記録するメタデータカラムを追加するには、このチェックボックスを選択します。
このフィールドは、[適用モード] オプションが[監査] または[論理削除] に設定されている場合にのみ使用できます。
監査モードでは、ジョブはこのメタデータカラムに、挿入の場合は「I」、更新の場合は「U」、更新/挿入の場合は「E」、削除の場合は「D」を書き込みます。
論理削除モードでは、ジョブによって、削除の場合は「D」が書き込まれ、挿入、更新、および更新/挿入の場合はNULLが書き込まれます。操作タイプがNULLの場合、他の[操作の追加...]メタデータカラムもNULLです。操作タイプが「D」の場合にのみ、他のメタデータカラムにNULL以外の値が含まれます。
デフォルトでは、このチェックボックスは選択されています。論理削除を使用している場合は、選択を解除できません。
操作時間の追加
ジョブがターゲットデータベースにプロパゲートする出力、またはターゲットシステムの監査テーブルに挿入する出力にソースSQL操作のタイムスタンプを記録するメタデータカラムを追加するには、このチェックボックスを選択します。
このフィールドは、[適用モード] が[監査] または[論理削除] に設定されている場合にのみ使用できます。
デフォルトでは、このチェックボックスは選択されていません。
操作所有者の追加
ジョブがターゲットデータベースにプロパゲートする出力、またはターゲットシステムの監査テーブルに挿入する出力にソースSQL操作の所有者を記録するメタデータカラムを追加するには、このチェックボックスを選択します。
このフィールドは、[適用モード] が[監査] または[論理削除] に設定されている場合にのみ使用できます。
デフォルトでは、このチェックボックスは選択されていません。
このプロパティは、MongoDBソースまたはPostgreSQLソースを持つジョブでは使用できません。
注: このプロパティは、SQL Serverソースを持ち、CDCテーブルキャプチャメソッドを使用するおよびジョブではサポートされていません。
操作トランザクションIDの追加
ジョブがSQL操作のターゲットにプロパゲートする出力にソーストランザクションIDを含むメタデータカラムを追加するには、このチェックボックスを選択します。
このフィールドは、[適用モード] が[監査] または[論理削除] に設定されている場合にのみ使用できます。
デフォルトでは、このチェックボックスは選択されていません。
操作シーケンスの追加
ジョブがターゲットシステムの監査テーブルに挿入する変更操作ごとに、生成された昇順のシーケンス番号を記録するメタデータカラムを追加するには、このチェックボックスを選択します。シーケンス番号には、操作の変更ストリーム位置が反映されます。
このフィールドは、[適用モード] が[監査] に設定されている場合にのみ使用できます。
デフォルトでは、このチェックボックスは選択されていません。
前のイメージを追加
ジョブがターゲットテーブルに挿入する出力にUNDOの「操作前のイメージ」データを含む_OLDカラムを追加するには、このチェックボックスを選択します。これにより、各データカラムの以前の値と現在の値を比較できるようになります。削除操作の場合、現在の値はNULLになります。
このフィールドは、[適用モード] が[監査] に設定されている場合にのみ使用できます。
デフォルトでは、このチェックボックスは選択されていません。
メタデータカラムのプレフィックス
追加されたメタデータカラムの名前にプレフィックスを追加し、それらを簡単に識別して、既存のカラムの名前との競合を防ぐことができるようにします。
デフォルト値はINFA_です。
Superpipe
最初にデータをステージファイルに書き込むのではなく、Snowpipe Streaming APIを使用して、短い待ち時間でSnowflake Data Cloudターゲットテーブルにデータ行を直接すばやくストリーミングするには、このチェックボックスを選択します。このオプションは、すべてのロードタイプで有効にすることができます。
ターゲット接続を設定するときに、KeyPair認証を選択します。
デフォルトでは、このチェックボックスは選択されています。中間ステージファイルにデータを書き込む場合は、選択解除します。
マージ頻度
[Superpipe] が選択されている場合、必要に応じて、変更データ行がマージされてSnowflakeターゲットテーブルに適用される頻度を秒単位で設定できます。このフィールドは、増分ロードタスク、および初期ロードと増分ロードの組み合わせタスクに適用されます。有効な値は60から604800です。デフォルトは3600秒です。
大文字と小文字の変換を有効にする
デフォルトでは、ターゲットテーブル名およびカラム名は、対応するソース名と同じ大文字と小文字で生成されます。ただし、ターゲットのクラスタレベルまたはセッションレベルのプロパティがこの大文字と小文字を区別する動作をオーバーライドしている場合を除きます。ターゲット名の大文字と小文字を制御する場合は、このチェックボックスを選択します。次に、[大文字と小文字の変換ストラテジ] オプションを選択します。
注: このチェックボックスは、[Superpipe] オプションを選択した場合は使用できません。SnowflakeのSuperpipeオプションを使用している場合は、大文字と小文字の変換を有効にできません。
大文字と小文字の変換ストラテジ
[大文字と小文字の変換を有効にする] を選択した場合は、以下のいずれかのオプションを選択して、生成されたターゲットテーブル(またはオブジェクト)名およびカラム(またはフィールド)名の大文字と小文字の処理方法を指定します。
- ソースと同じ 。ソーステーブル(またはオブジェクト)名およびカラム(またはフィールド)名と同じ大文字と小文字を使用します。- UPPERCASE 。すべて大文字を使用します。- lowercase 。すべて小文字を使用します。デフォルト値は、[ソースと同じ] です。
注: 選択したストラテジは、大文字と小文字の制御に関するターゲットのクラスタレベルまたはセッションレベルのプロパティをオーバーライドします。
スケジュールとランタイムオプションの設定 データベース取り込みとレプリケーション タスクウィザードの[スケジュールおよびランタイムオプション] ページでは、初期ロードジョブを定期的に実行するスケジュールを指定し、任意のロードタイプのジョブのランタイムオプションを設定できます。
1 [詳細] の下で、必要に応じて [出力ファイルの行数] の値を編集して、 データベース取り込みとレプリケーション タスクが出力データファイルに書き込む最大行数を指定します。
注: Apache Kafkaターゲットを持つジョブの場合、詳細オプションは表示されません。
増分ロード操作と、初期ロード操作と増分ロード操作の組み合わせの場合、この行数に達したとき、またはフラッシュ待ち時間が経過して、トランザクションの処理の途中でジョブが実行されない 場合に、変更データがターゲットにフラッシュされます。フラッシュ待ち時間は、ジョブがデータをターゲットにフラッシュする前に、さらに変更データを待機する時間です。待ち時間は内部で10秒に設定されており、変更できません。
有効な値は1から100000000です。Amazon S3、Microsoft Azure Data Lake Storage Gen2、およびOracle Cloud Infrastructure(OCI)Object Storageターゲットのデフォルト値は1000行です。その他のターゲットの場合は、デフォルト値は100000行です。
注: Microsoft Azure Synapse Analyticsターゲットの場合、データは最初にMicrosoft Azure Data Lake Storageステージングファイルに送信されてから、ターゲットテーブルに書き込まれます。データがターゲットに書き込まれた後、ステージングファイルを含むテーブル固有のディレクトリのコンテンツ全体が消去されます。Snowflakeターゲットの場合、データは最初に内部ステージ領域に格納されてから、ターゲットテーブルに書き込まれます。
2 初期ロードジョブの場合のみ、フラットファイル、Amazon S3、Google Cloud Storage、Microsoft Azure Data Lake Storage、Microsoft Fabric OneLake、またはOracle Cloud Object Storageターゲットの出力データファイルに.dat拡張子を付ける場合は、必要に応じて [ファイルタイプに基づくファイル拡張子] チェックボックスをクリアします。このチェックボックスはデフォルトで選択されており、出力ファイルのファイルタイプに基づいてファイル名拡張子が付けられます。
注: これらのターゲットタイプの増分ロードジョブの場合、このオプションは使用できません。データベース取り込みとレプリケーション は、常にファイルタイプに基づいて出力ファイル名拡張子を使用します。
3 Amazon S3、Google Cloud Storage、Microsoft Azure Data Lake Storage Gen2、Microsoft Fabric OneLake、またはOracle Cloud Object Storageターゲットを持つ データベース取り込みとレプリケーション の増分ロードタスクの場合、次の適用サイクルオプションを設定します。
オプション
説明
サイクル間隔の適用
データベース取り込みとレプリケーション ジョブが適用サイクルを終了するまでに経過する必要のある時間を指定します。日、時間、分、秒を指定するか、これらの時間フィールドのサブセットに値を指定して、他のフィールドを空白のままにすることができます。
デフォルト値は15分です。
サイクル変更制限の適用
ジョブが適用サイクルを終了する前に処理する必要がある、データベース取り込みとレプリケーション ジョブのすべてのテーブル内のレコードの合計数を指定します。このレコード制限に達すると、データベース取り込みとレプリケーション ジョブは適用サイクルを終了し、変更データをターゲットに書き込みます。
デフォルト値は10000レコードです。
注: 起動中に、古いデータのバックログの処理に追いつく必要がある場合、ジョブは適用サイクル間隔よりも頻繁にこの制限に達する可能性があります。
低アクティビティのフラッシュ間隔
データベース取り込みとレプリケーション ジョブが適用サイクルを終了する前に、ソースで変更アクティビティがない期間中に経過する必要がある時間を時間、分、またはその両方で指定します。この時間制限に達すると、データベース取り込みとレプリケーション ジョブは適用サイクルを終了し、変更データをターゲットに書き込みます。
このオプションの値を指定しない場合、データベース取り込みとレプリケーション ジョブは、[サイクル変更制限の適用] または[サイクル間隔の適用] のいずれかの制限に達した後にのみ適用サイクルを終了します。
デフォルト値は指定されていません。
4 [スキーマドリフトオプション] で、スキーマドリフトの検出がソースとターゲットの組み合わせでサポートされている場合は、サポートされている各タイプのDDL操作に使用するスキーマドリフトオプションを指定します。
スキーマドリフトオプションは、次のソースとターゲットの組み合わせおよびロードタイプでサポートされています。
ソース
ロードタイプ
ターゲット
Db2 for i
差分
初期と増分の組み合わせ
Amazon Redshift、Amazon S3、Databricks、Google BigQuery、Google Cloud Storage、Kafka(増分ロードのみ)、Microsoft Azure Data Lake Storage、Microsoft Azure Synapse Analytics、Microsoft Fabric OneLake、Oracle、Oracle Cloud Object Storage、PostgreSQL、Snowflake、およびSQL Server
DB2 for LUW
差分
初期ロードと増分ロードの組み合わせ
Snowflake
Db2 for z/OS(Db2 11を除く)
差分
初期と増分の組み合わせ
Amazon Redshift、Amazon S3、Databricks、Google BigQuery、Google Cloud Storage、Kafka(増分ロードのみ)、Microsoft Azure Data Lake Storage、Microsoft Azure Synapse Analytics、Microsoft Fabric OneLake、Oracle、Oracle Cloud Object Storage、Snowflake、およびSQL Server
Microsoft SQL Server
差分
初期と増分の組み合わせ
Amazon Redshift、Amazon S3、Databricks、Google BigQuery、Google Cloud Storage、Kafka(増分ロードのみ)、Microsoft Azure Data Lake Storage、Microsoft Azure Synapse Analytics、Microsoft Fabric OneLake、Oracle、Oracle Cloud Object Storage、PostgreSQL、Snowflake、およびSQL Server
Oracle
差分
初期と増分の組み合わせ
Amazon Redshift、Amazon S3、Databricks、Google BigQuery、Google Cloud Storage、Kafka(増分ロードのみ)、Microsoft Azure Data Lake Storage、Microsoft Azure Synapse Analytics、Microsoft Fabric OneLake、Oracle、Oracle Cloud Object Storage、PostgreSQL、Snowflake、およびSQL Server
PostgreSQL
差分
初期と増分の組み合わせ
増分ロード: Amazon Redshift、Amazon S3、Databricks、Google BigQuery、Google Cloud Storage、Kafka(増分ロードのみ)、Microsoft Azure Data Lake Storage、Microsoft Azure Synapse Analytics、Microsoft Fabric OneLake、Oracle、Oracle Cloud Object Storage、PostgreSQL、およびSnowflake
初期ロードと増分ロードの組み合わせ: Oracle、PostgreSQL、およびSnowflake
サポートされているDDL操作のタイプは次のとおりです。
- - - - 注: [カラムの変更]および[カラムの名前変更]オプションはサポートされておらず、Google BigQueryターゲットを持つデータベース取り込みジョブでは表示されません。
次の表に、DDL操作タイプに設定できるスキーマドリフトオプションを示します。
オプション
説明
無視
ソースデータベースで発生するDDLの変更をターゲットにレプリケートしません。Amazon Redshift、Kafka、Microsoft Azure Synapse Analytics、PostgreSQL、Snowflake、およびSQL Serverターゲットの場合、このオプションは、[カラムの削除]および[カラム名の変更]操作タイプのデフォルトオプションです。
CSV出力形式を使用するAmazon S3、Google Cloud Storage、Microsoft Azure Data Lake Storage、およびOracle Cloud Object Storageターゲットの場合、[無視] オプションは無効です。AVRO出力形式の場合、このオプションは有効になっています。
レプリケート
DDL操作をターゲットにレプリケートします。Amazon S3、Google Cloud Storage、Microsoft Azure Data Lake Storage、Microsoft Fabric OneLake、およびOracle Cloud Object Storageターゲットの場合、このオプションはすべての操作タイプのデフォルトオプションです。他のターゲットの場合、このオプションは、[カラムの追加]および[カラムの変更]操作タイプのデフォルトオプションです。
ジョブの停止
データベース取り込みジョブ全体を停止します。
テーブルの停止
DDL変更が発生したソーステーブルの処理を停止します。1つ以上のテーブルが[テーブルの停止] スキーマドリフトオプションによってレプリケーションから除外された場合、ジョブの状態が[実行中(警告あり)] に変わります。
重要: データベース取り込みとレプリケーション ジョブは、ジョブが変更の処理を停止した後にソーステーブルで発生したデータ変更を取得できません。その結果、ターゲットでデータ損失が発生する可能性があります。データの損失を回避するには、ジョブを停止し、ジョブが処理を停止したソースオブジェクトとターゲットオブジェクトを再同期する必要があります。ジョブが停止した後に、
[オプションを指定して再開] >
[再同期] オプションを使用して、[テーブルの停止]操作によってエラー状態になっているテーブルを再同期することができます。詳細については、
データベース取り込みとレプリケーションジョブの再開時のスキーマドリフトオプションのオーバーライド を参照してください。
5 Apache Kafkaターゲットを持つ増分ロードジョブの場合、次のチェックポイントオプションを設定します。
オプション
説明
チェックポイントのすべての行
データベース取り込みとレプリケーション ジョブが、Kafkaターゲットに送信されるすべてのメッセージに対してチェックポイント処理を実行するかどうかを示します。
注: このチェックボックスが選択されている場合、[チェックポイントすべてのコミット] 、[チェックポイントの行数] 、および[チェックポイントの頻度(秒)] オプションは無視されます。
チェックポイントのすべてのコミット
データベース取り込みとレプリケーション ジョブがソースで発生するすべてのコミットに対してチェックポイント処理を実行するかどうかを示します。
チェックポイントの行数
チェックポイントを追加する前に、データベース取り込みとレプリケーション ジョブがターゲットに送信するメッセージの最大数を指定します。このオプションを0に設定すると、データベース取り込みとレプリケーション ジョブはメッセージの数に基づいてチェックポイント処理を実行しません。このオプションを1に設定すると、データベース取り込みとレプリケーション ジョブは各メッセージにチェックポイントを追加します。
チェックポイントの頻度(秒)
データベース取り込みとレプリケーション ジョブがチェックポイントを追加するまでに経過する必要がある最大秒数を指定します。このオプションを0に設定すると、データベース取り込みとレプリケーション ジョブは経過時間に基づいてチェックポイント処理を実行しません。
6 監視インタフェースの1つからデプロイされた後にジョブを手動で開始するのではなく、既存のスケジュールに基づいて初期ロードタスクのジョブインスタンスを実行する場合は、 [スケジュール] で [このタスクは指定したスケジュールを使用する] を選択して、事前定義されたスケジュールを選択します。デフォルトのオプションは [このタスクはスケジュールを使用しない] です。
このフィールドは、増分ロードおよび初期ロードタスクと増分ロードタスクの組み合わせには使用できません。
Administratorでスケジュールオプションを表示および編集できます。スケジュールを編集すると、変更はスケジュールを使用するすべてのジョブに適用されます。タスクのデプロイ後にスケジュールを編集する場合、タスクを再デプロイする必要はありません。
ジョブを実行するためのスケジュール条件が満たされていて、前のジョブ実行がまだアクティブである場合、データベース取り込みとレプリケーション は新しいジョブの実行をスキップします。
7 [カスタムプロパティ] で、特別な要件を満たすためにInformaticaが提供するカスタムプロパティを指定できます。プロパティを追加するには、 [プロパティの作成] フィールドに、プロパティの名前と値を入力します。次に、 [プロパティの追加] をクリックします。
これらのプロパティを指定する場合は、Informaticaグローバルカスタマサポートにお問い合わせください。通常、これらのプロパティは、固有の環境または特別な処理のニーズに対応します。必要に応じて、複数のプロパティを指定できます。プロパティ名には、英数字と次の特殊文字のみを含めることができます: ピリオド(.)、ハイフン(-)、およびアンダースコア(_)。
ヒント: プロパティを削除するには、リストのプロパティ行の右端にある[削除]アイコンボタンをクリックします。
8 [保存] をクリックします。