Server and Desktop Migration
Installation of Hotfix, EBF or One-Off-EBF (=Patch) on Server
EBF packages and One-Off-EBF (=Patch) packages contain only delta plugins which have been changed. In order to recognize such packages, the suffix delta is contained in its name. Hotfixes and Major releases have the suffix full in its name.
Generally this is an easy process. Please consider the following steps in order to migrate your PIM to a newer version.
Consider pre-migration checklists
Before applying an Hotfix or Major update, you have to update the Control Center itself. See chapter "Control Center Migration" of this Migration guide.
Login into the Control Center
Navigate to the installation tab
With the upload functionality, upload all packages you want to deploy. Do not rename or extract any of the packages that are delivered.
If you want to deploy also accelerator plugins or custom plugins, you can also upload them. Custom plugins have to be uploaded separately as jar file.
Please note that all uploaded files will be deployed and overwrite the existing files. But all files will be backuped in a folder, so you can revert them if something went wrong.
By clicking the upload button, the update process will start and all configured servers will be updated. All configuration files on all servers will be also replaced with the ones that are located in the Control Center.
Execute steps in chapter "Product 360 Core Database Migration" by running setup to your existing database connection in order to update existing database.
Generally, you should run your custom JUnit tests in order to ensure that your custom functionality is still working.
If you want to encrypt the passwords using standard implementation please refer to chapter Encryption of secure information in the Server Installation manual. Updating to newest Hotfix you should replace the Java JCE policy files in jre\lib\security folders of all Product 360 components with recommended ones. If you install an EBF, then this step is not needed.
Installation of Hotfix, EBF or One-Off-EBF (=Patch) on Desktop
Before updating the Desktop you should execute the migration of the Server first.
For Hotfix or Major updates:
Remove content of PIM Desktop Installation Folder and unzip the content of the new release package
Update the configuration files if you have any customizings here. Instead of copying the whole file, rather copy only your changes, since there might be some new settings which then will be overwritten.
For EBF's and One-Off-EBF's (=patches):
Remove the existing plugins with old revision and then place the plugin with new revision which are part of the EBF resp. One-Off-EBF.
Structure Migration
First of all, please read the following knowledge base article, in order to understand the impacts of the new structure paradigm: Structure Types
The Structure Migration Tool is part of the standard Product 360 8.0 Installation, so you do not have to install anything seperately. With the Structure Migration Tool you can migrate structures to maintenance structures. Therefor this tool first of all validates the given structures in means of the new structure paradigm. The validation (and also correction of invalid items) works the same as the Structure Migration Preperation Tool (see Product 360 Server and Desktop Pre-Migration Checklist). If the structures are valid they are migrated to maintenance structures.
Versioning
If you are using the Versioning functionality of Product 360, please be aware, that the selected structures will be migrated to maintenance structures only in the working version. All other versions affected by these structures will be closed, because possibly invalid object mappings in versions other than the working version are not correctable.
The following permissions are needed, when using the Structure Migration Tool:
Interface visibility "Structure systems"
For validation of structures:
Action right "Create item/variant/product assortments" (depending on which data types are used in the Product 360 system)
Action right "Delete item/variant/product assortments" (depending on which data types are used in the Product 360 system)
For migration of structures:
Action right "Edit structure systems"
Action right "Close versions" (only when using versioning)
Run Structure Migration Tool
Open the view "Structure systems".
Select all the structures you want to migrate to maintenance structures.
Right-click and choose "Migrate structures..."
You have the possibility, to recheck your selection and probably correct it.
Then click on "Migrate".
The migration process is scheduled as a background server job.
You can view the results of this job in the "Process overview" perspective. Here choose the job catego ry "Data maintenance", the job type "Migrate structures" and then your currently scheduled job.
In the "Log" view you can see the results of the migration job.
If all the selected structures can be migrated to maintenance structures, you see a corresponding info and they are migrated.
If the selected structures can not be migrated, you see a corresponding warning. Please then continue with the steps mentioned in chapter "Correct invalid item/variant/product mappings" on this page: Product 360 Server and Desktop Pre-Migration Checklist
After correction of all invalid object mapping, restart the Structure Migration Tool for the same structures as before, by executing again the steps mentioned above.
XML parsing exception while loading export templates or other data graph objects
If you experience unexpected errors during the serialization or deserialization of data graphs after an upgrade or change of your local environment, the following hints might be helpful.
In the past we had problems with the SDK deployment mechanism, specifically with the target platform refreshing. When you define the target platform in the SDK by using the update-site, eclipse is copying all bundles of the update site to an internal cache directory.
Now, when you switch to a different target platform release, eclipse is updating it's internal cache only in case the bundles have changed. The fact that a bundle has changed is determined by the bundle name and the version inkl. build identifier suffix of the version. If none of these changed, the bundle is not refreshed in the internal cache which leads to ClassNotFoundException as soon as someone wants to access a new class of that bundle.
In most of our cases there is no issue with this since nearly all bundles have a build identifier which changes with every build.
Most of them, but not all. The com.heiler.ppm.xml bundle has no build identifier. This bundle contains the XML parser implementations which must be used with Product 360 - those parsers are also used within the Java SDK since we're using the so called "endorsed-directory" mechanism. During launch (either by cmd, by service or by launch config of the SDK) we provide the full path to the com.heiler.ppm.xml/endorsed directory to java.
So, in case the directory is not there, or the path is not correct in the launch scenarios, the default XML parser will be used which does currently not work with the used XML serialization of the EMF based data graph objects.
Strange XML parsing exceptions are the symptoms of this problem.
With Product 360 version 7.0.04 we increased the version number of the com.heiler.ppm.xml bundle from 5 to 6. So you need to make sure you also update all configuration files (incl. wrapper.conf) as well as your launch configs - unless you will also experience those exceptions.
A typical stacktrace of such exception can look like this:
Caused by: org.eclipse.emf.ecore.xmi.IllegalValueException: Value ';i'is not legal. (file:///D:/informatica/pim/client/all.datagraph,7, 21)at org.eclipse.emf.ecore.xmi.impl.XMLHandler.setFeatureValue(XMLHandler.java:2648)at org.eclipse.emf.ecore.xmi.impl.XMLHandler.setAttribValue(XMLHandler.java:2702)at org.eclipse.emf.ecore.xmi.impl.SAXXMLHandler.handleObjectAttribs(SAXXMLHandler.java:83)at org.eclipse.emf.ecore.xmi.impl.XMLHandler.createObjectFromFactory(XMLHandler.java:2178)at org.eclipse.emf.ecore.sdo.util.DataGraphResourceFactoryImpl$DataGraphResourceImpl$LoadImpl$1.createObjectFromFactory(DataGraphResourceFactoryImpl.java:670)at org.eclipse.emf.ecore.xmi.impl.XMLHandler.createObjectByType(XMLHandler.java:1316)at org.eclipse.emf.ecore.sdo.util.DataGraphResourceFactoryImpl$DataGraphResourceImpl$LoadImpl$1.handleFeature(DataGraphResourceFactoryImpl.java:554)at org.eclipse.emf.ecore.xmi.impl.XMLHandler.processElement(XMLHandler.java:1023)at org.eclipse.emf.ecore.xmi.impl.XMLHandler.startElement(XMLHandler.java:1001)at org.eclipse.emf.ecore.xmi.impl.XMLHandler.startElement(XMLHandler.java:712)at com.sun.org.apache.xerces.internal.parsers.AbstractSAXParser.startElement(Unknown Source)at com.sun.org.apache.xerces.internal.impl.XMLDocumentFragmentScannerImpl.scanStartElement(Unknown Source)at com.sun.org.apache.xerces.internal.impl.XMLDocumentFragmentScannerImpl$FragmentContentDriver.next(Unknown Source)at com.sun.org.apache.xerces.internal.impl.XMLDocumentScannerImpl.next(Unknown Source)at com.sun.org.apache.xerces.internal.impl.XMLDocumentFragmentScannerImpl.scanDocument(Unknown Source)at com.sun.org.apache.xerces.internal.parsers.XML11Configuration.parse(Unknown Source)at com.sun.org.apache.xerces.internal.parsers.XML11Configuration.parse(Unknown Source)at com.sun.org.apache.xerces.internal.parsers.XMLParser.parse(Unknown Source)at com.sun.org.apache.xerces.internal.parsers.AbstractSAXParser.parse(Unknown Source)at com.sun.org.apache.xerces.internal.jaxp.SAXParserImpl$JAXPSAXParser.parse(Unknown Source)at com.sun.org.apache.xerces.internal.jaxp.SAXParserImpl.parse(Unknown Source)at org.eclipse.emf.ecore.xmi.impl.XMLLoadImpl.load(XMLLoadImpl.java:181)... 70 more Caused by: java.lang.NumberFormatException: For input string:";i"at java.lang.NumberFormatException.forInputString(Unknown Source)at java.lang.Long.parseLong(Unknown Source)at java.lang.Long.valueOf(Unknown Source)at org.eclipse.emf.ecore.impl.EcoreFactoryImpl.createELongObjectFromString(EcoreFactoryImpl.java:958)at org.eclipse.emf.ecore.impl.EcoreFactoryImpl.createFromString(EcoreFactoryImpl.java:157)at org.eclipse.emf.ecore.xmi.impl.XMLHelperImpl.createFromString(XMLHelperImpl.java:1613)at org.eclipse.emf.ecore.xmi.impl.XMLHelperImpl.setValue(XMLHelperImpl.java:1154)at org.eclipse.emf.ecore.xmi.impl.XMLHandler.setFeatureValue(XMLHandler.java:2643)Entity IDs for ArticleLangType and ArticleExtensionType repository custom entities
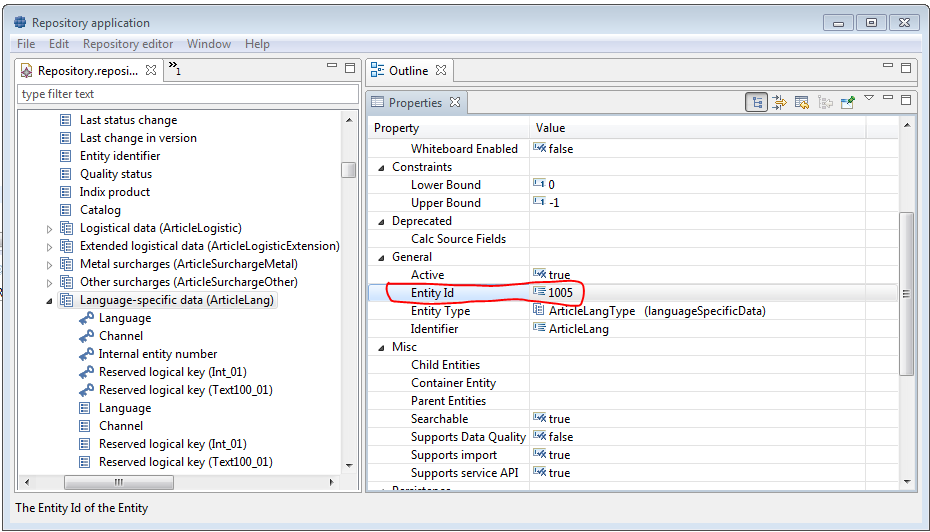
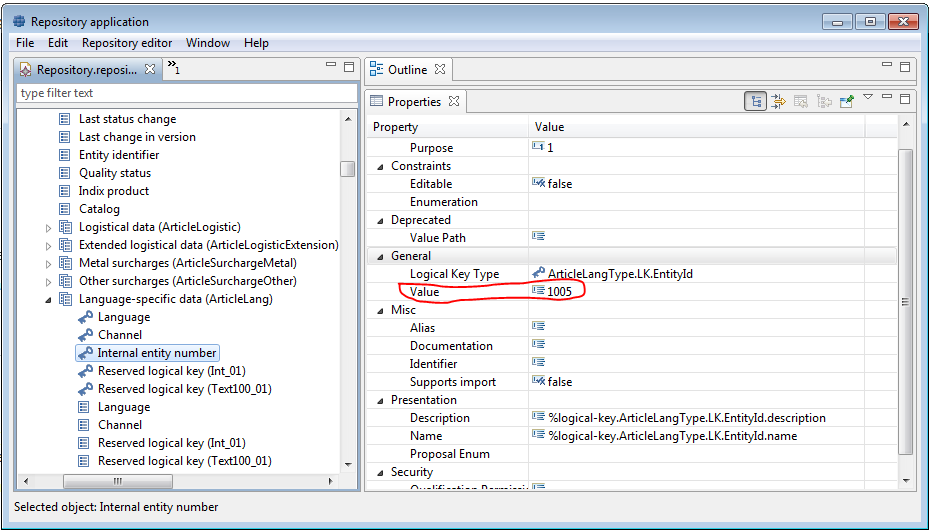
With Product 360 7.1.04.00 a new data base column "EntityID" has been introduced for data base tables "ArticleLang" and "ArticleExtension". The content of this column has to be the same as in the corresponding repository logical key for custom entities based on "ArticleLangType" and "ArticleExtensionType" repository entity types.
The "ArticleExtensionType" based standard repository entities cannot be migrated automatically because it's not possible to determine the entity of the data base entries. Those entities got a valid Entity ID but use "0" as corresponding logical key value.
Database
All "ArticleLangType" based standard and custom repository entities have been considered in corresponding data base update scripts.
If you have to migrate own custom entities based on "ArticleExtensionType" repository entity type, you have to migrate the corresponding data base entries manually. Please use the following sql scripts.
-- 1st step ----------- are there entries to be migrated?SELECT COUNT(ID) AS 'Count of entries to be migrated' FROM ArticleExtension WHERE EntityID = 0-- 2nd step ----------- migrateDECLARE @ArticleEntityID varchar(10)DECLARE @ArticleExtensionEntityID varchar(10)/* TODO set appropriate value */SET @ArticleEntityID = <entity id used for your ArticleType based custom entity> -- example: 1000 for "Article" repository entity/* TODO set appropriate value */SET @ArticleExtensionEntityID = <entity id used for your ArticleExtensionType based custom entity> -- example: 1050 for "ArticleExtension.EANUCC" repository entityEXEC ('UPDATE ae SET EntityID=' + @ArticleExtensionEntityID + ' FROM ArticleExtension AS ae ' + ' INNER JOIN ArticleRevision AS ar ON ae.ArticleRevisionID = ar.ID ' + ' WHERE ar.EntityID = ' + @ArticleEntityID + /* only not converted values */ ' AND ae.EntityID = 0' + /* TODO set specific values for logical key columns */ ' AND ae.ExtensionType IN (''Extension1_a'', ''Extension1_b'')' + ' AND ae.BuyerID in (1, 2, 3)' + ' AND ae.LanguageID < 0' + ' AND ae.Territory IN (''WORLD'', ''US'')')-- 1st step ----------- are there entries to be migrated?SELECT COUNT(ID) AS "Entries to be migrated" FROM "ArticleExtension" WHERE "EntityID" = 0;-- 2nd step ----------- migrateDECLARE /* TODO set appropriate value */ ArticleEntityID NUMBER :=<entity id used for your ArticleType based custom entity>; -- example: 1000 for "Article" repository entity /* TODO set appropriate value */ ArticleExtensionEntityID NUMBER :=<entity id used for your ArticleExtensionType based custom entity>; -- example: 1050 for "ArticleExtension.EANUCC" repository entity BEGIN EXECUTE IMMEDIATE 'UPDATE (SELECT "ArticleExtension"."EntityID" FROM "ArticleExtension" INNER JOIN "ArticleRevision" ON "ArticleExtension"."ArticleRevisionID" = "ArticleRevision"."ID" WHERE "ArticleRevision"."EntityID" = ' || ArticleEntityID || /* only not converted values */ ' AND "ArticleExtension"."EntityID" = 0 ' || /* TODO set specific values for logical key columns */ ' AND "ArticleExtension"."ExtensionType" IN (''Extension1_a'', ''Extension1_b'') AND "ArticleExtension"."BuyerID" in (1, 2, 3) AND "ArticleExtension"."LanguageID" < 0 AND "ArticleExtension"."Territory" IN (''WORLD'', ''US'') ) SET "EntityID" = ' || ArticleExtensionEntityID; END;Repository
Ensure all affected custom entities have the corresonding logical key with an appropriate value.
Server Jobs
With version 8.0.5 the preference for defining the number of threads for server jobs in the quartz.properties has become obsolete.
If changes have been made to this preference, the number should be set to the new default, which is 3.
org.quartz.threadPool.threadCount=3
The maximum number of running jobs can now be configured in the plugin_customization.ini with the preference:
com.heiler.ppm.job.server/maxRunningServerJobs = 40
Data Quality
Migration
Rule mapplets, configurations and dictionaries
To migrate dq rules, configurations and dictionaries from one system to another,
Make a backup of the dataquality shared folder in the target system before migrating the new packages.
ensure to copy the shared server folder 'dataquality' to the target system.
In order to also have a synced version between custom dictionaries in the database and the files in the dataquality/dictionaries folder, zip the complete dataquality/dictionaries folder.
Or make a zip file containing only the custom dictionaries (latter is recommended and should be also the way customers/partners build their custom packages).
This ensures that not only dictionaries from OOB standard are considered, but also customer dictionaries that are used for custom rules mapplets.
Update
Data Quality SDK and Engine Update
Warning
Starting with version 10.1.0.02 the IDQ SDK and engine have been upgraded to version 10.5.
This requires some check actions to ensure that server is starting properly and Data Quality features can be used further.
Two things to check:
Only if Microsoft Server is used: install MSVC Redistributable as described in the "Operating system - Data Quality" section of the Step by Step installation guide.
Ensure that the library paths are updated to the new IDQ version in the according wrapper.conf file
For Windows :
set.PIM_IDQ_BIN_PATH = %PIM_SERVER_PATH%/plugins/com.informatica.sdk.dq.win32.x86_64_10.5.0/os/win32/x86_64set.PIM_IDQ_LIB_PATH = %PIM_SERVER_PATH%/plugins/com.informatica.sdk.dq_10.5.0/libFor Linux:
set.PIM_IDQ_BIN_PATH = %PIM_SERVER_PATH%/plugins/com.informatica.sdk.dq.linux.x86_64_10.5.0/os/linux/x86_64set.PIM_IDQ_LIB_PATH = %PIM_SERVER_PATH%/plugins/com.informatica.sdk.dq_10.5.0/lib
Rule mapplets, configurations and dictionaries
For a full update, updating of the rule mapplet files, the dictionaries and in case of GDSN predefined rule configurations is needed.
Please refer to the appropriate sections in the New & Noteworthy and release notes for further specific details of a dataquality update.
If there is no specific information in the New & Noteworthy, it is recommended to do a full update using standard steps and default settings during dictionary update described as followed
Make a backup of the dataquality shared folder before updating the new packages.
Update Rule mapplets:
Following rule files must be updated: 'Informatica_PIM_Content.xml' and depending of whether GDSN accelerator is used also 'Informatica_PIM_GDSN.xml'. If both files are needed these are part of the GDSN accelerator package. There is also a standalone version of the standard rule mapplet file 'Informatica_PIM_Content.xml' file in the dqRuleset zip artefact.
For an update make sure that these the two rule files are deployed into the shared server folder 'dataquality/rules'.
Do this by either
- uploading the new version to the server via upload mapplet feature in the 'Data Quality' Perspective of the Desktop Client (strongly recommended).
- copying the new version to that folder prior to server startUpdate rule configurations:
There are only OOB predelivered rule configurations for GDSN Accelerator package. The file 'StandardDataQualityMappingProfile.xml' is located in the GDSN accelerator package.
For an update make sure to copy that file to the shared server folder 'dataquality/config' prior to server start. Overwrite the file if already existing.Update dictionaries:
Following dictionaries must be updated: Dictionary information contained in 'Informatica_PIM_Content.zip' and depending of whether GDSN accelerator is used also 'Informatica_PIM_GDSN.zip'. If both files are needed these are part of the GDSN accelerator package. There is also a standalone version of the 'Informatica_PIM_Content.zip' file.
Customer dictionaries are updated to the target system by providing a zip file containing the complete content (see migration steps above) or only the custom dictionary files (latter is recommended).
Import mappings
By introducing subentity deletion on import new checks were put in place in order to ensure import results are correct and consistent.
This requires existing import mappings to be validated again manually, because the error tolerance is slimmer than before.
If an import mapping is invalid, e.g. due to a non-matching repository, the import will always fail. This is also true for already existing import mappings. In order to fix this, the import mapping has to be loaded once into the Product 360 Desktop Client's "Import" perspective and to be saved again. By doing this, the invalid mappings are automatically removed.
Affected versions
This step has to be performed whenever the previous release version was lower than 10.0 and the new version is equal or greater than 10.0.
Upgrades from versions greater than 10.0 to any newer version are not affected by this.
Migration of Subentity Deletion customizing
For customers with an existing customization for the "Subentity deletion on import" feature it is required to remove the customization from their Product 360 System and migrate the Subentity Deletion Configuration to this new standard feature, via the Import Perspective in the Product 360 Desktop Client. For more details, see subchapter "Subentity deletion on import" in the Knowledge Base chapter of the Technical Documentation.
Affected versions
This step has to be performed whenever the previous release version was lower than 10.0 and the new version is equal or greater than 10.0.
Upgrades from versions greater than 10.0 to any newer version are not affected by this.
Media Manager Integration
Adjust Media Manager database connection string (MSSQL only)
Since 10.0.0.01 a different database connection string is required to connect to the Media Manager database. The database connection is defined in the hmm.properties file.
The new connection string pattern looks like
...hmm.db.url=jdbc:sqlserver://localhost:1433;databaseName=opasdb...Previous versions used the jTDS database driver pattern. jTDS has been replaced by Microsoft's JDBC driver.