データベース取り込みとレプリケーション ソース - 準備と使用方法データベース取り込みとレプリケーション タスクを初期ロード操作、増分ロード操作、または初期ロードと増分ロードの組み合わせ操作に設定する前に、ソースデータベースを準備し、ソースの使用に関する考慮事項を確認して、予期しない結果を回避します。
DB2 for iソース データベース取り込みとレプリケーション タスクでDb2 for iソースを使用するには、最初にソースデータベースを準備し、使用に関する考慮事項を確認してください。
ソースの準備: • データベース取り込みとレプリケーション で使用するDb2ジャーナルオブジェクトおよびファイルオブジェクトにアクセスするための適切なレベルの権限を、データベース取り込みとレプリケーション ジョブを実行するユーザーIDに付与します。以下の表に、これらのオブジェクトとそのDB2権限要件を示します。オブジェクト
権限
ジャーナル
*USE *OBJEXIST
ジャーナルライブラリ
*USE
ジャーナルレシーバ
*USE
ジャーナルレシーバライブラリ
*USE
ファイル
*USE
ファイルライブラリ
*USE
• ソーステーブルの物理ファイルでジャーナルがアクティブになっていない場合、データベース取り込みとレプリケーション タスクを定義するときに、それをアクティブにするCDCスクリプトを生成できます。スクリプトは次のコマンドを発行します。これにより、ジャーナルがアクティブになり、IMAGESオプションがBOTHに設定されます。
CALL QSYS2.QCMDEXC('STRJRNPF FILE(library /physical-file ) JRN(library /journal-name )
ソーステーブルの物理ファイルに対してジャーナルがすでにアクティブになっている場合、CDCスクリプト出力には次のコメントが含まれます。
Table 'table_name ' is skipped because journaling is already enabled.
• データベース取り込みとレプリケーション はデフォルトで、DataDirect JDBC for IBM Db2ドライバを使用してDb2 for iデータベースに接続します。ソースデータベースへのDB2 for i接続を作成およびテストする最初のユーザーに、データベースに対するDBA権限を持たせることをお勧めします。この権限は、ドライバがDB2へのアクセスに使用するパッケージを作成してアップロードし、パッケージに対するEXECUTE特権をPUBLICに付与するために必要です。DBAユーザーが最初の接続テストを実行しない場合は、パッケージを作成するためのCRTSQLPKGコマンドに*USE権限を付与し、パッケージの作成先のライブラリに*CHANGE権限を付与する必要があります。• [JDBCドライバ] フィールドで[JTOpen] を選択し、[暗号化方法] フィールドで[SSL] を選択します。また、次のいずれかの場所にあるInformatica Cloud Secure Agent JRE cacertsキーストアに必要な証明書を追加します。
Linuxの場合:
Secure Agent Directory \jdk\jre\lib\security\cacerts
Windowsの場合:
Secure Agent Directory \apps\jdkLatestVersion \jre
証明書を追加したら、Secure Agentを再起動して、最新インスタンスのエージェントサービスのapp-truststore.jksファイルに変更が反映されていることを確認します。
使用に関する考慮事項: • データベース取り込みとレプリケーション では、ソーステーブルの各行が一意であることを想定しているため、各ソーステーブルにプライマリキーを持たせることをお勧めします。データベース取り込みとレプリケーション は、プライマリキーの代わりに一意のインデックスを許可しません。プライマリキーが指定されていない場合、データベース取り込みとレプリケーション はすべてのカラムをプライマリキーの一部であるかのように扱います。• データベース取り込みとレプリケーション タスクを定義する場合、[ソース] ページで、ジャーナルが有効になっているソーステーブルに関連付けられているジャーナル名を指定します。重要: [ジャーナル名] フィールドの大文字と小文字および名前のスペル、テーブルの選択ルールが、DB2ソースカタログのジャーナルとテーブル名の値と一致することを確認してください。
• データベース取り込みとレプリケーション の増分ロードジョブ、および初期ロードと増分ロードの組み合わせジョブで、Db2 for iソースに対して使用できます。[カラムの追加] オプションを[レプリケート] に設定してから、デフォルト値を持つカラムをDB2 for iソーステーブルに追加すると、データベース取り込みとレプリケーション は、ターゲットに新たに追加されたテーブル行にデフォルト値を追加します。ただし、ターゲットの既存の行は更新されず、デフォルト値が反映されません。既存のターゲット行に移入されたデフォルト値を取得するには、別の初期ロードを実行してターゲットを再実体化します。
• データベース取り込みとレプリケーション では、次のDb2 for iデータ型はサポートされません。- - - - - - - - データベース取り込みとレプリケーション ジョブは、これらのデータ型を持つカラムにはnullをプロパゲートします。
サポートされているソースデータ型からターゲットデータ型へのデフォルトのマッピングについては、
デフォルトデータ型のマッピング を参照してください。
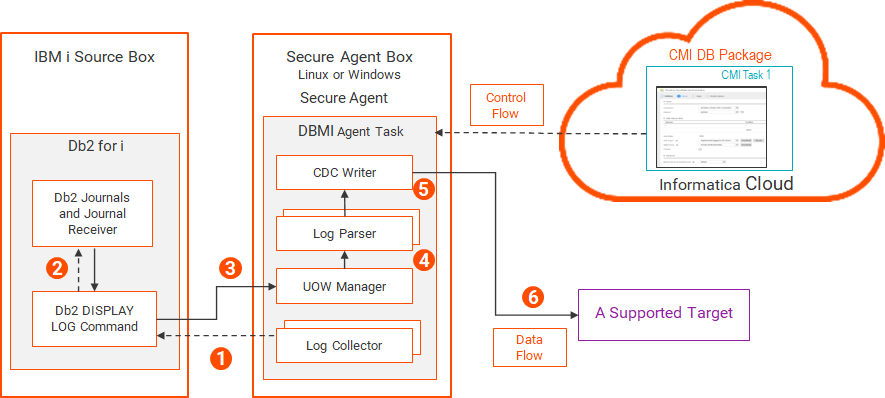
• データベース取り込みおよびレプリケーションのジャーナルレシーバ出口 データベース取り込みおよびレプリケーションのジャーナルレシーバ出口のインストール Db2 for iソースの変更キャプチャメカニズム データベース取り込みとレプリケーション は、IBM i上のDb2ソースから変更データをキャプチャしてそのデータをターゲットに適用するための、単一の変更キャプチャメカニズムとアーキテクチャを提供します。
Secure Agentは、IBM iソースシステムとは別に、LinuxまたはWindowsボックスで実行する必要があります。IBM iシステムとSecure Agentボックス間のネットワーク帯域幅は堅牢でなければなりません。Informaticaでは、数百ギガビットまたは1ギガバイト以上のログデータを処理できるネットワーク転送速度を推奨しています。Db2がCDC対象のログデータを生成する速度以上の速度でログデータをSecure Agentに配信できるほどのネットワーク転送速度ではない場合、データベース取り込みジョブはタイムリーにデータをターゲットに提供できません。データスループットがSLAを満たしていない場合は、ハードウェアを変更して、IBM iシステムとSecure Agentボックス間のイーサネット帯域幅を増やすことを検討してください。
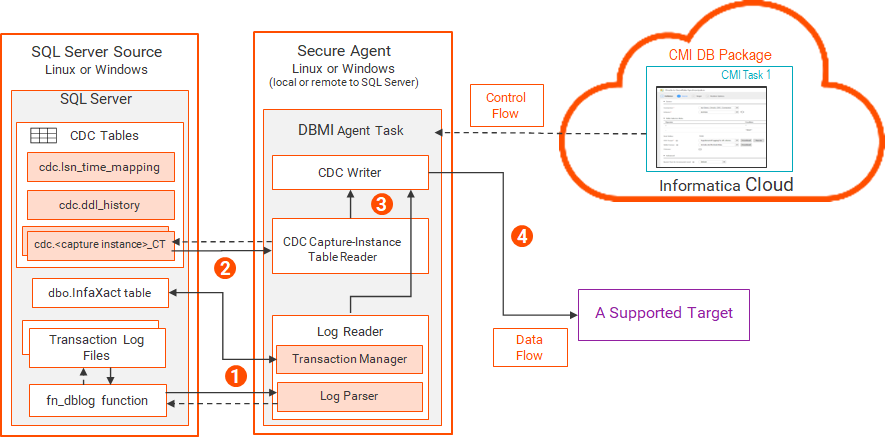
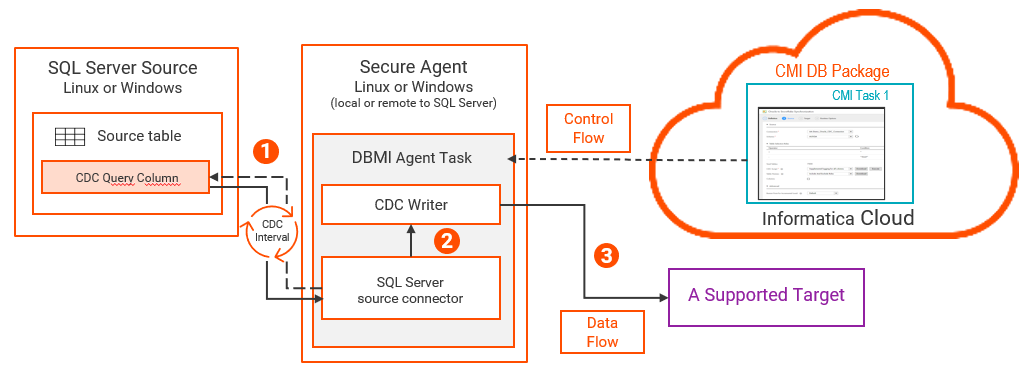
次の図は、Db2 for i変更キャプチャコンポーネントとデータフローを示しています。
1 各要求には、開始RBAと、データベースの取り込み用のCDC対象のテーブルのリストが含まれます。
2 3 4 5 注: このリソース集約型のアクティビティはSecure Agentボックスで発生するため、IBM iシステムのCPU消費は最小限に抑えられます。
6 データベース取り込みおよびレプリケーションのジャーナルレシーバ出口 データベース取り込みおよびレプリケーションは、変更データキャプチャ処理に使用されているDb2 for iジャーナルレシーバが削除されるのを防ぐための出口プログラムを提供しています。ジャーナルレシーバ出口を使用して、CDC中のジャーナルレシーバの削除に関連して発生する可能性があるエラーを防止します。
出口プログラムは、ジャーナルレシーバがデータベース取り込みおよびレプリケーションの増分ロードジョブまたは組み合わせロードジョブによって読み取られている間、ジャーナルレシーバをロックします。CDC処理中に出口プログラムがジャーナルレシーバのロックレコードを検出した場合、出口プログラムは、システムによってジャーナルレシーバが削除されないように防ぐ応答を返します。
データベース取り込みおよびレプリケーションジョブがチェーン上の次のジャーナルレシーバに切り替わると、データベース取り込みおよびレプリケーションは、最後に読み取られたジャーナルレシーバのロックレコードを削除し、次に読み取られるジャーナルレシーバのロックレコードを追加します。システムは、現在ロックされているレシーバの後に作成されたジャーナルレシーバは削除しません。
ジャーナルレシーバー出口の制御情報は、ソースシステム上のDb2 for iテーブルに格納されます。以下のカラムがテーブルに含まれています。
• • • • • JOURNAL_RECEIVER_LIBRARYエントリとJOURNAL_RECEIVER_NAMEエントリの各組み合わせによって、変更データキャプチャ中に削除できないようにロックされるジャーナルレシーバインスタンスが識別されます。
ジャーナルレシーバ出口を使用するには、次の手順を実行します。
1 データベース取り込みおよびレプリケーションのジャーナルレシーバ出口のインストール 2 [ソース] ページで、次のカスタムプロパティを指定します。カスタムプロパティ
説明
pwx.cdcreader.iseries.option.useJournalReceiverExit
このプロパティをtrueに設定すると、タスクからデプロイされたジョブインスタンスに対してジャーナルレシーバ出口を使用できるようになります。
pwx.cdcreader.iseries.option.JournalReceiverExitJobToken
pwx.cdcreader.iseries.option.useJournalReceiverExitがtrueに設定されている場合は、データベース取り込みおよびレプリケーションジョブのインスタンスごとに一意で最大256文字の長さのトークン文字列を指定する必要があります。
トークン文字列がすべてのジョブインスタンスの間で一意でない場合、特に複数のジョブが同じジャーナルレシーバにアクセスしていると、予測不能な結果が生じる可能性があります。
また、ジョブの再開操作または再デプロイ操作後もトークン値が変わらないことを確認してください。
pwx.cdcreader.iseries.option.useJournalReceiverQueries
このプロパティをtrueに設定すると、データベース取り込みおよびレプリケーションはDb2マシンのメンテナンスレベルを確認して、ジャーナルレシーバクエリを実行できるかどうかを判別できるようになります。
データベース取り込みおよびレプリケーションのジャーナルレシーバ出口のインストール データ取り込みおよびレプリケーション のジャーナルレシーバ出口を使用して、Db2 for iジャーナルレシーバが変更データキャプチャで使用されている間に削除されるのを防ぎます。ジャーナルレシーバ出口を手動でインストールするには、次の手順を実行します。
1 2 3 4 注: FTPを開始する前に、ジャーナルレシーバ出口プログラムが含まれているIBMi_SaveFile_V01.savfファイルがあるディレクトリに移動します。
5 注: SQLを実行する前に、<userId>をシステムの有効なユーザーIDに置き換えてください。
6 DB2 for LUWソース データベース取り込みとレプリケーション タスクでDb2 for Linux, UNIX, and Windows(LUW)ソースを使用するには、最初にソースデータベースを準備し、使用に関する考慮事項を確認してください。
ソースの準備: • データベース取り込みとレプリケーション では、ユーザーが複数のシステムカタログテーブルおよびビューに対するSELECT特権を持っている必要があります。次のgrant文を使用します。GRANT SELECT ON <catalog_table > TO <dbmi_user >
この付与を、次の各カタログテーブルまたはビューに対して発行します。
- - - - - - - - - - - • dbmi_user に付与されていることを確認します。GRANT BINDADD ON DATABASE TO <dbmi_user >
使用に関する考慮事項: • データベース取り込みとレプリケーション の増分ロードジョブ、および初期ロードと増分ロードの組み合わせジョブでは、[クエリベース] キャプチャメソッドを使用する必要があります。クエリベースの変更データキャプチャでは、共通のCDCクエリカラムを参照するWHERE句を含むSQL文を使用して、挿入および更新の変更がある行を識別します。ソースデータベースの設定は、各ソーステーブルへのCDCクエリカラムの追加に制限されます。ユーザーは、少なくともソーステーブルへの読み取り専用アクセス権を持つ必要があります。CDCクエリカラムタイプは、タイムゾーンがないタイムスタンプに相当する必要があります。現在、このCDC機能は Snowflakeターゲットでのみテストされています。• データベース取り込みとレプリケーション では、ソーステーブルの各行が一意であることを想定しているため、各ソーステーブルにプライマリキーを持たせることをお勧めします。データベース取り込みとレプリケーション は、プライマリキーの代わりに一意のインデックスを許可しません。プライマリキーが指定されていない場合、データベース取り込みとレプリケーション はすべてのカラムをプライマリキーの一部であるかのように扱います。• データベース取り込みとレプリケーション ジョブは、LOBデータ型を持つカラムからMicrosoft Azure Data Lake Storage Gen 2、Microsoft Azure Synapse Analytics、またはSnowflakeターゲットにデータをレプリケートできます。サポートされているソースデータ型からターゲットデータ型へのデフォルトのマッピングについては、デフォルトデータ型のマッピング DB2 for z/OSソース データベース取り込みとレプリケーション タスクでDb2 for z/OSソースを使用するには、最初にソースデータベースを準備し、使用に関する考慮事項を確認してください。
ソースの準備: • データベース取り込みとレプリケーション の増分ロードジョブは、ストアドプロシージャを使用してDb2 Instrumentation Facility Interface(IFI)を呼び出し、z/OSソースシステム上のDb2ログから変更データを読み取ります。データベース取り込みとレプリケーション は、ストアドプロシージャライブラリとJCLをDb2 for zOS Database IngestionコネクタパッケージのZIPファイルで提供します。ストアドプロシージャライブラリをAPF許可ライブラリで受け取り、ご使用の環境に合わせてJCLをカスタマイズする必要があります。ストアードプロシージャは、DB2ソースシステムのWorkload Manager(WLM)アドレススペースで実行されます。z/OSシステム要件、ストアドプロシージャのセットアップ、および必要な権限の詳細については、「Db2 for z/OS CDCのストアドプロシージャのインストールと設定 • データベース取り込みとレプリケーション の増分ロードタスクでDb2ソースを定義するときに、[CDCスクリプト] フィールドで[すべてのカラムのCDCを有効化] オプションを選択する必要があります。データベース取り込みとレプリケーション は、ソーステーブルおよびCDCに使用される特定のDb2カタログテーブルでDb2 DATA CAPTURE CHANGESを有効にするためのスクリプトを生成します。この属性が1つのジョブに設定されると、他のすべてのジョブは、Db2で必要なカタログテーブルに対してその属性が有効になったことを認識します。十分な権限がある場合はユーザーインタフェースからCDCスクリプトを実行するか、SYSDBA権限を持つDB2 DBAにスクリプトの実行を依頼することができます。• データベース取り込みとレプリケーション ユーザーに、データベース取り込みとレプリケーション ロードタイプを実行するために必要なDb2 for z/OS特権があることを確認してください。詳細については、DB2 for z/OSの権限 • データベース取り込みとレプリケーション は、Progress DataDirect JDBC IBM DB2ドライバを使用して、Db2 for z/OSソースに接続します。Db2 for z/OSソースを使用したデータベース取り込みとレプリケーション の新しい実装の場合、増分ジョブを最初に実行するユーザーは、JDBC接続を確立するためのSYSADMまたはSYSDBA権限を持っている必要があります。• 1 2 管理者 で接続アセットに明示的なユーザー権限を設定します。ジョブを実行するために接続を使用するには、ユーザーが実行権限を持っている必要があります。これにより、より低いレベルの特権を持つユーザーは、より高いレベルの権限を必要とするジョブを実行できなくなります。3 データベース取り込みとレプリケーション を作成する場合は、必要なDb2特権とアセット権限を持つユーザーが指定された接続を選択します。使用に関する考慮事項: Db2 for z/OS CDCのストアドプロシージャのインストールと設定 増分ロードジョブのDb2 for z/OS CDC処理を実行するために、データベース取り込みとレプリケーション は、z/OSソースシステムで実行されるストアドプロシージャを提供します。ストアドプロシージャは、Db2 Instrumentation Facility Interface(IFI)を呼び出して、Db2ログから変更データを収集します。
z/OSシステム要件 開始する前に、Db2 for z/OSソースシステムが次の要件を満たしていることを確認してください。
ストアドプロシージャライブラリをインストールし、JCLをカスタマイズします クライアントマシンで、次の手順を実行します。
1 Db2 for zOS Database Ingestionコネクタパッケージには、Db2 for z/OSストアドプロシージャライブラリが含まれています。コネクタがSecure Agent Group(ランタイム環境)に対して有効になっている場合、コネクタパッケージの.zipファイルがインストール場所のダウンロードフォルダにダウンロードされます。パッケージ名の形式はpackage-DB2ZMIです。nnnnn 。nnnnn は増分されたパッケージバージョン番号です。複数のパッケージバージョンが存在する場合は、最新のバージョンを使用してください。
2 nnnnn .zipファイルを解凍します。ストアドプロシージャファイルは、パッケージ名の下のDb2WLMStoredProcedureフォルダに追加されます。3 注:
- - 4 - - - 注:
z/OSシステムでは、TSOを使用して送信(XMI)データセットをAPF許可ライブラリで受信し、ストアドプロシージャJCLメンバを編集します。また、DB2ユーザー特権を設定し、使用されている場合はリソース制限テーブルに行を追加します。
1 RECEIVE INDATASET(DBMI.ZOS.DBRMLIB.XMI)
注:
- - INMR906A Enter restore parameters or 'DELETE' or 'END' + 」が表示されたら、APF許可ライブラリを入力します。DA(your.library_name ) UNIT(unit ) VOLUME(volume )
UNIT()およびVOLUME()オペランドはオプションです。インストールでRECEIVEファイルがデフォルトでワークユニットまたはボリュームに配置されない場合は、それらを含めてください。
2 RECEIVE INDATASET(DBMI.ZOS.LOADLIB.XMI)
手順1の注を参照してください。
3 RECEIVE INDATASET(DBMI.ZOS.USERJCL.XMI)
手順1の注を参照してください。
4 JCLは、データのDb2 IFIへの要求の結果を保持するストアドプロシージャとグローバル一時テーブルを作成します。また、ストアドプロシージャパッケージをバインドします。
注:
- - - プロシージャパラメータ:
//STARTING EXEC DSNBWLMG,DB2SSN=DSNB,APPLENV='DSNBWLM_GENERAL'
EXEC PARM:
PARM='DSNB,40,DSNBWLM_GENERAL '
- - 5 Db2 for z/OS USERJCLデータセット 6 DB2 for z/OSの権限 7 xx リソース制限テーブルに行を追加して、プロセッサリソースがストアドプロシージャの処理に十分であることを確認します。そうしないと、増分ロードジョブが異常終了する可能性があります。次のカラムを含む行を追加します。- データベース取り込みとレプリケーション タスクが使用する認証IDを持つAUTHIDカラムか、データベース取り込みとレプリケーション タスクと同じパッケージ名を持つRLFPDGカラム、またはこれら両方のカラム。- 次に、リソース制限テーブルへの変更を有効にするために、DB2 -START RLIMITコマンドを発行します。
Db2 for z/OS USERJCLデータセット ダウンロードされたUSERJCLデータセットは区分データセット(PDS)または拡張区分データセット(PDSE)であり、Informatica提供のWLM Db2ストアドプロシージャの使用時に他の方法では容易に入手できない情報を収集するジョブを実行するためのJCLメンバが含まれています。
メンバJCLは、USERJCL PDSまたはPDSEで完全にカスタマイズできます。元のメンバが参照用にそのまま保持されるように、提供されたJCLメンバのコピーを別の名前で作成し、そのコピーをカスタマイズすることをお勧めします。
複数のDb2サブシステムに複数のストアドプロシージャをインストールする場合、インストールできるUSERJCLライブラリは1つだけで、そのライブラリにDb2サブシステムごとに合わせてカスタマイズしたメンバを作成できます。あるいは、特定のDb2サブシステム用に別のライブラリを作成することもできます。データベース取り込みとレプリケーション ジョブに、Db2サブシステムの正しいライブラリおよびメンバ情報が含まれていることを確認してください。
USERJCL PDSまたはPDSEには、以下のメンバが含まれています。
LOGINVメンバ LOGINVには、Db2ログインベントリリストを取得するジョブのJCLが含まれています。タスクウィザードで取り込みタスクの[増分ロード操作の当初の開始点] プロパティを[特定の日付と時刻] に設定した場合、インベントリリストを使用して、データベース取り込みとレプリケーション ジョブの初回実行時または再開時にログ内の開始点が決定されます。ログインベントリリストはデータベース取り込みとレプリケーション に、開始RBAまたはLSNと終了RBAまたはLRSN、およびDb2サブシステムのすべてのアクティブログとアーカイブログの開始タイムスタンプと終了タイムスタンプを提供します。データベース取り込みとレプリケーション は、この情報を使用して適切なログアーカイブを選択し、要求された開始点を検索します。[増分ロード操作の当初の開始点] プロパティが[特定の日付と時刻] 以外のオプションに設定されている場合は、USERJCLライブラリをインストールする必要はありません。 LOGINVメンバの内容:
//<USERID>I JOB 'LOG INVENTORY',MSGLEVEL=(1,1),MSGCLASS=X,
USERJCLメンバジョブをサブミットし、サブミットされたジョブから出力を取得するために、
データベース取り込みとレプリケーション は、必要に応じてDb2提供のストアドプロシージャをバッチで実行します。
データベース取り込みとレプリケーション ユーザーが、これらのストアドプロシージャを実行するために必要な特権を持っていることを確認します。Db2提供のプロシージャの詳細については、
https://www.ibm.com/docs/en/db2-for-zos/12?topic=sql-procedures-that-are-supplied-db2 を参照してください。
USERJCLメンバは、次のように処理されます。
1 データベース取り込みとレプリケーション タスクウィザードの[ソース] ページで[増分ロード操作の当初の開始点] 詳細プロパティが[特定の日付と時刻] に設定されている場合、データベース取り込みとレプリケーション は、ソースに次のカスタムプロパティが指定されているかどうかをチェックします。- pwx.cdcreader.ZOS.Db2JobsDSN (インストールされているUSERJCL PDSまたはPDSEdの名前を指定)- pwx.cdcreader.ZOS.Db2JobLLOGINVMember (データベース取り込みとレプリケーション ジョブに使用されるLOGINVメンバ名を指定)2 データベース取り込みとレプリケーション は、Db2提供のストアドプロシージャADMIN_DS_BROWSEを使用してLOGINVメンバを読み取ります。3 データベース取り込みとレプリケーション は、ジョブの実行に必要なタグを置き換えます。4 データベース取り込みとレプリケーション は、Db2提供のストアドプロシージャADMIN_SUBMIT_JOBを使用して、ジョブをDb2 for z/OSデータベースにサブミットします。5 データベース取り込みとレプリケーション は、Db2提供のストアドプロシージャADMIN_JOB_QUERYを使用して、サブミットされたジョブのステータスを照会します。6 データベース取り込みとレプリケーション は、Db2提供のストアドプロシージャADMIN_JOB_FETCHを使用して、ジョブ出力を取得します。DB2 for z/OSの権限 Db2 for z/OSソースを持つデータベース取り込みとレプリケーション タスクをデプロイして実行するには、ソース接続で取り込みロードタイプに必要な特権を持つデータベース取り込みとレプリケーション ユーザーを指定する必要があります。
初期ロード処理の特権
• SELECT on schema .table TO user
ここで、schema .table はソーステーブルを表します。
• - - - - - - 増分ロード処理の特権
増分ロードジョブの場合は、次の特権を付与します。
注: これらを付与するために必要な権限がない場合は、SYSDBA権限以上の権限レベルを持つDB2管理者に発行を依頼してください。
• GRANT ALTER TABLE schema .table DATA CAPTURE CHANGES TO user <--for each source table
• - GRANT ALTER TABLE schema .table DATA CAPTURE CHANGES TO user <--for each source table
- GRANT MONITOR2 TO user ;
- GRANT INSERT ON !SCHEMA!.!STRPRC!_RS_TBL to user ;user ;user ;
ここで、!SCHEMA! および、!STRPRC! はジョブJCLの変数であり、それぞれストアドプロシージャスキーマ名とプロシージャ名を表します。
最初の2つの特権により、ユーザーは、ストアドプロシージャがログデータを書き込んでいるグローバル一時テーブルのコンテンツを読み取り、削除することができます。3番目の特権により、ユーザーはストアドプロシージャを実行できます。
注: GRANT INSERT ONまたはGRANT DELETE ON文がSQLCode -526で失敗した場合は、代わりに次のGRANTを使用してください。
GRANT ALL ON !SCHEMA!.!STRPRC!_RS_TBL to user ;
- GRANT BIND, EXECUTE ON PLAN !STRPRC! TO PUBLIC;
- ▪ ▪ ▪ ▪ ▪ ▪ ▪ z/OSでストアドプロシージャを実行するために必要な権限
ストアドプロシージャJCLジョブを実行する前に、次のDB2権限が付与されていることを確認します。
さらに、グローバル一時テーブルのJCLで指定されているスキーマおよびストアドプロシージャ名に対するINSERTおよびDELETE権限を付与します。
GRANT INSERT, DELETE ON schema .stored_procedure_name _RS_TBL TO user
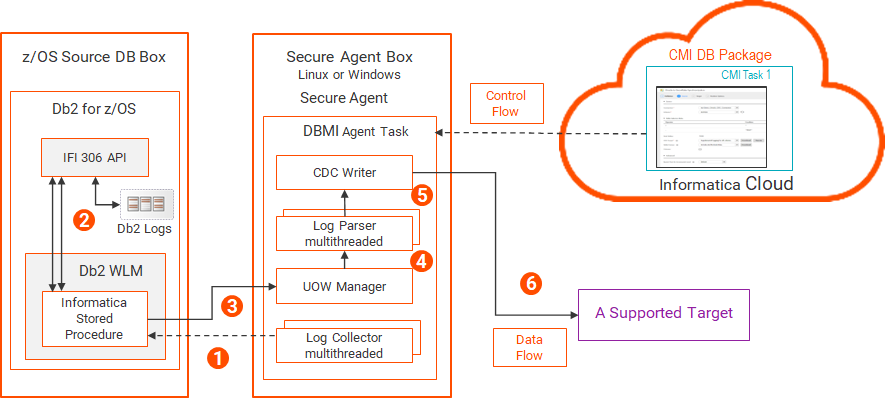
Db2 for z/OSソースの変更キャプチャメカニズム データベース取り込みとレプリケーション は、z/OS上のDb2ソースから変更データをキャプチャしてそのデータをターゲットに適用するための、単一の変更キャプチャメカニズムとアーキテクチャを提供します。このアーキテクチャはマルチスレッド処理を使用して、データの収集と、データの解析およびターゲットが受け入れる形式への変換のパフォーマンスを最適化します。
Secure Agentは、Db2 z/OSソースシステムとは別に、LinuxまたはWindowsボックスで実行する必要があります。z/OSシステムとSecure Agentボックス間のネットワーク帯域幅は堅牢でなければなりません。Informaticaでは、数百ギガバイトまたは1ギガビット以上のログデータを処理できるネットワーク転送速度を推奨しています。Db2がCDC対象のログデータを生成する速度以上の速度でログデータをSecure Agentに配信できるほどのネットワーク転送速度ではない場合、データベース取り込みとレプリケーション ジョブはタイムリーにデータをターゲットに提供できません。データスループットがSLAを満たしていない場合は、ハードウェアを変更して、z/OSシステムとSecure Agentボックス間のイーサネット帯域幅を増やすことを検討してください。
次の図は、Db2 for z/OS変更キャプチャコンポーネントとデータフローを示しています。
1 各要求には、開始RBA、またはログがデータ共有環境にある場合は開始LRSNと、データベース取り込み用のCDC対象のテーブルのリストが含まれます。
一連のログデータの処理中に、ログコレクタは次の一連のログデータを要求できます。
2 3 4 5 注: このリソース集約型のアクティビティはSecure Agentボックスで発生するため、z/OSシステムのCPU消費は最小限に抑えられます。
6 Microsoft SQL Server、RDS for SQL Server、Azure SQL Database、Azure Managed Instanceソース データベース取り込みとレプリケーション タスクでMicrosoft SQL Serverソースを使用するには、最初にソースデータベースを準備し、使用に関する考慮事項を確認してください。SQL Serverソースタイプには、オンプレミスのSQL Server、Relational Database Service(RDS)for SQL Server、Azure SQL Database、およびAzure SQL Managed Instanceが含まれます。
ソースの準備: • データベース取り込みとレプリケーション がサポートしているSQL Serverのエディションとバージョンを使用していることを確認します。KB記事「FAQ: What are the supported sources and targets for IICS Cloud Mass Ingestion service? • SQL Server権限 • ログベース または[CDCテーブル] のキャプチャメソッドを使用しているデータベース取り込みとレプリケーション の増分ロードジョブと組み合わせロードジョブの場合は、ソースデータベースでSQL Server変更データキャプチャ(CDC)を有効にする必要があります。- msdb.dbo.rds_cdc_enable_db ' database_name ' ストアドプロシージャを実行します。- sys.sp_cdc_enable_db ストアドプロシージャを実行します。sysadminロールが必要です。データベースとソーステーブルでSQL Server CDCが有効になると、SQL ServerはトランザクションログとCDCテーブルに追加情報を書き込みます。この情報は、データベース取り込みとレプリケーション が増分CDC処理中に使用します。
または、データベース取り込みとレプリケーション タスクを作成するときに、データベースおよび選択したソーステーブルのすべてのカラムでCDCを有効にするスクリプトを生成することもできます。CDCスクリプトを実行するには、適切な権限が必要です。
制約事項: データベース取り込みとレプリケーション では、1019個を超えるカラムを含むテーブルに対してCDCを有効にすることはできません。
• データベース取り込みとレプリケーション タスクを作成する前に、クエリカラムをソーステーブルに追加する必要があります。CDCクエリカラムタイプは、タイムゾーンがないタイムスタンプに相当する必要があります。クエリカラムでサポートされているSQL Serverデータ型は、DATETIMEとDATETIME2です。使用に関する考慮事項: • データベース取り込みとレプリケーション ジョブは、オンプレミスのSQL Server、Amazon RDS for SQL Server、Azure SQL Managed Instance、およびAzure SQL Databaseソースのすべてのロードタイプをサポートします。• データベース取り込みとレプリケーション では、増分ロードジョブ、または初期ロードと増分ロードの組み合わせジョブのSQL Serverソースに対して、次の代替キャプチャメソッドを提供しています。[CDCテーブル] オプションを使用すると最高のレプリケーションパフォーマンスが得られ、結果の信頼性が最大になります。
同じデータベースに対して同時に実行される複数のジョブに[ログベース] のメソッドを使用した場合は、パフォーマンスが大幅に低下する可能性があります。
各キャプチャメソッドの詳細については、
SQL Serverソースの変更キャプチャメカニズム を参照してください。
• sys.sp_cdc_help_jobs ストアドプロシージャを実行して結果の保持期間の値を確認すると、現在の保持期間を確認できます。ダウンタイムが3日を超えることが予想される場合は、sys.sp_cdc_change_job ストアドプロシージャまたはSQL Serverエージェントのクリーンアップジョブで保持期間を調整できます。クリーンアップジョブを一時停止することもできます。• データベース取り込みとレプリケーション はSQL Serverのページ圧縮とソースデータの行圧縮をサポートします。• データベース取り込みとレプリケーション では、ソーステーブルの各行が一意であることを想定しているため、各ソーステーブルにプライマリキーを持たせることをお勧めします。データベース取り込みとレプリケーション は、プライマリキーの代わりに一意のインデックスを許可しません。プライマリキーが指定されていない場合、データベース取り込みとレプリケーション はすべてのカラムをプライマリキーの一部であるかのように扱います。例外: SQL ServerクエリベースのCDCの場合、各ソーステーブルにプライマリキーが必要です。• データベース取り込みとレプリケーション には、ソースデータベースに対する読み取り/書き込みアクセス権が必要です。SQL Server Always On可用性グループを使用する場合、この要件が意味するのは、データベース取り込みとレプリケーション が読み取り/書き込みプライマリレプリカから変更データをキャプチャできるが、読み取り専用セカンダリレプリカからはキャプチャできないことです。• データベース取り込みとレプリケーション タスクの[ソース] ページの[CDCスクリプト] フィールドから生成されたCDCスクリプトは実行できません。この問題は、SQL Serverの制限が原因で発生します。この問題は、Transparent Data Encryption(TDE)では発生しません。• データベース取り込みとレプリケーション は、データベース取り込みおよびrepoliclationincrementalロードジョブでのMicrosoft SQL Serverソースのスキーマドリフトオプションをサポートしています。次の制限が適用されます。- - - データベース取り込みとレプリケーション がCDCテーブルから変更データを直接読み取った場合、作成後にCDCテーブルが変更されることはありません。ソーステーブルで発生したDDLの変更は、CDCテーブルにNULLとしてレプリケートされます。DDLの変更をCDCテーブルにレプリケートするには、タスクウィザードの[ソース] ページでpwx.custom.sslr_cdc_manage_instancesカスタムプロパティを1に設定します。このカスタムプロパティを使用すると、CDCテーブルを変更してソーステーブルのDDLの変更を反映し、DMLキャプチャを強化することができます。CDCテーブルのアクティブな管理を有効にするには、db_ownerロールが必要です。• データベース取り込みとレプリケーション は変更を処理して、データベース取り込みとレプリケーション ジョブがテーブルからDML変更をキャプチャし続けることができるようにします。• - - - - データベース取り込みとレプリケーション はこれらのカラムに対してNULLをプロパゲートします。- データベース取り込みとレプリケーション は再開してそのサイクルで発生した変更を処理します。• [ソース] ページの[詳細] で[LOBを含める] を選択した場合、データベース取り込みとレプリケーション ジョブで、Microsoft SQL Serverのラージオブジェクト(LOB)カラムからデータをレプリケートできます。サポートされるターゲットタイプは、ロードタイプによって異なります。
- - - LOBデータ型は、GEOGRAPHY、GEOMETRY、IMAGE、VARBINARY(MAX)、VARCHAR(MAX)、NVARCHAR(MAX)、TEXT、NTEXT、およびXMLです。LOBデータは、ターゲットに書き込まれる前に切り詰められる場合があります。切り詰めポイントは、データ型、ターゲットタイプ、およびロードタイプによって異なります。詳細については、
ソースの設定 の[LOBを含める]に関する説明を参照してください。
• データベース取り込みとレプリケーション は、SQL Serverの永続化されていない計算カラムからのデータをレプリケートしません。ログベースまたはクエリベースのCDCメソッドを使用する初期ロードジョブ、増分ロードジョブ、および初期ロードと増分ロードの組み合わせジョブの場合、永続化された計算カラムはターゲットにレプリケートされます。CDCテーブルからのみ変更をキャプチャする増分ロードジョブ、および初期ロードと増分ロードの組み合わせジョブの場合、永続化された計算カラムは、カラムがNULL値を許容するかどうかに応じて、NULLまたは空の値としてレプリケートされます。• データベース取り込みとレプリケーション の初期ロードジョブは、ターゲット上でsql_variantデータを16進形式に変換します。データを16進形式からvarbinary形式に変換するには、次のクエリを実行します。SELECT <column_name >, CONVERT(varbinary,<column_name >) from <table_name >;
<column_name >と<table_name >を実際のターゲットカラムとテーブル名に置き換えます。
• データベース取り込みとレプリケーション の増分ロード、およびSnowflakeターゲットを持つ初期ロードと増分ロードの組み合わせジョブではサポートされていません。データベース取り込みとレプリケーション は、このデータ型を持つカラムに対してnullをプロパゲートします。詳細については、デフォルトデータ型のマッピング • データベース取り込みとレプリケーション の初期ロードジョブ、増分ロードジョブ、および初期ロードと増分ロードの組み合わせジョブは、Secure Agentグループ内の別の使用可能なエージェントに自動的に切り替えることができます。自動スイッチオーバーは、15分のハートビート間隔が経過した後に行われます。自動スイッチオーバーは、任意のソースタイプとKafka以外のターゲットタイプの初期ロードジョブでサポートされています。また、SQL Serverソースを持つ増分ロードジョブと組み合わせロードジョブでもサポートされていますが、次の制限があります。- - - • データベース取り込みとレプリケーション の増分ロードジョブおよび組み合わせロードジョブは、プライマリノードまたはセカンダリノードのトランザクションログまたはCDCテーブルから変更データをキャプチャできます。また、ノードが使用できなくなった場合、可用性グループリスナを指すようにSQL Server接続を構成していれば、データベース取り込みとレプリケーション ジョブは可用性レプリカ内のプライマリデータベースまたはセカンダリデータベースにフェールオーバーして処理を続行できます。可用性グループリスナーは、SQL Server物理インスタンス名を知らなくても、データベース取り込みとレプリケーション が可用性グループの可用性レプリカ内のデータベースにアクセスするために使用できる仮想ネットワーク名(VNN)です。• データベース取り込みとレプリケーション ジョブの実行後、レプリケーション用に追加のソースカラムを選択してタスクを再デプロイした場合、ジョブは追加のカラムを使用してターゲットテーブルをすぐに再作成したり、それらのデータをレプリケートしたりしません。ただし、増分ロードジョブ、または初期ロードと増分ロードの組み合わせジョブでは、スキーマドリフトの[カラムの追加] オプションを[レプリケート] に設定した場合、次の新しいDML変更レコードを処理するときに、新しく選択したカラムがターゲットに追加され、データがレプリケートされます。初期ロードジョブでは、次回のジョブ実行時に、新しく選択したカラムがターゲットに追加され、データがレプリケートされます。• [クエリベース] のCDCメソッドを使用するデータベース取り込みとレプリケーション の増分ロードジョブ、および初期ロードと増分ロードの組み合わせジョブのソースとしてサポートされています。ただし、メモリ最適化テーブルは、[CDCテーブル] または[ログベース] のCDCメソッドを使用するジョブのソースとしてサポートされていません。• SQL Server権限 SQL Serverソースからデータをレプリケートするには、データベース取り込みとレプリケーションユーザーに一部のSQL Server権限を付与する必要があります。
SQL Server CDCの有効化の前提条件 変更をキャプチャするには、[ログベース]または[CDCテーブル]のキャプチャメソッドを使用している増分ロードジョブと組み合わせロードジョブのデータベースとソーステーブルでSQL Server CDCを有効にする必要があります。
データベースでCDCを有効にするには、次の手順を実行します。
• USE <DB>;
• USE <DB>;
SQL ServerソーステーブルでCDCを有効にするには、db_ownerロールが割り当てられていることを確認し、次のコマンドを実行します。
EXEC sys.sp_cdc_enable_table @source_schema = N'<schemaname>', @source_name = N'<tablename>', @role_name = NULL;
注: sp_cdc_enable_tableの構文には、最低限必要な引数が含まれています。より多くの引数を使用することができます。詳細については、WebSphereサーバーのマニュアルを参照してください。
データのレプリケートに必要な権限 必要な権限は、ジョブのロードタイプとCDCメソッドに応じて異なります。
ユーザーの作成
データベース接続には、マスタデータベースおよびソースデータベースでログインユーザーを作成する必要があります。
USE master;
初期ロードジョブに対する権限
初期ロードジョブには、次の最小限の権限が必要です。
GRANT SELECT ON <table> TO <user>;
増分ロードジョブ、および初期ロードと増分ロードの組み合わせジョブに対する権限
増分ロードジョブと組み合わせロードジョブの場合、初期ロードジョブに対して上記の最小限の権限に加えて、増分CDC処理に必要な追加の権限がいくつか必要となります。CDCの権限は、使用するCDCメソッドに応じて異なります。
• [CDCテーブル] メソッドで、SQL Server CDCテーブルに対する次の権限を付与します。USE <DB>;
CDCテーブルを管理できるようにするには、次のコマンドを実行します。
USE <DB>;
• [ログベース] メソッドを使用する場合は、次の権限を付与します。USE master;
• [クエリベース] メソッドを使用する場合は、初期ロードジョブに対して上記のものと同じ最小限の権限のみを付与します。SQL Serverソースの変更キャプチャメカニズム データベース取り込みとレプリケーション は、SQL Serverソースから変更データをキャプチャしてそのデータをターゲットに適用するための、複数の変更キャプチャメカニズムを提供します。
トランザクションログとCDCテーブルを使用するログベースの変更データキャプチャ ログベースのCDCを使用するデータベース取り込みとレプリケーション の増分ロードジョブは、アクティブなトランザクションログからレコードを解析し、CDCテーブルから変更レコードを直接読み取ることで、DMLとDDLの変更をキャプチャします。必要な再開ポイント(LSN)が利用可能な場合、変更データはアクティブなトランザクションログから読み取られます。キャプチャ開始点がトランザクションログ内のレコードより前の日付である場合、またはその他の特定の状況では、データベース取り込みとレプリケーション は自動的にCDCテーブルからの変更データの読み取りに移行します。CDCテーブルから変更を読み取った後、データベース取り込みとレプリケーション は、トランスペアレントな方法でアクティブなトランザクションログの読み取りに戻ります。
ログベースの変更キャプチャ処理には、次のコンポーネントが関わります。
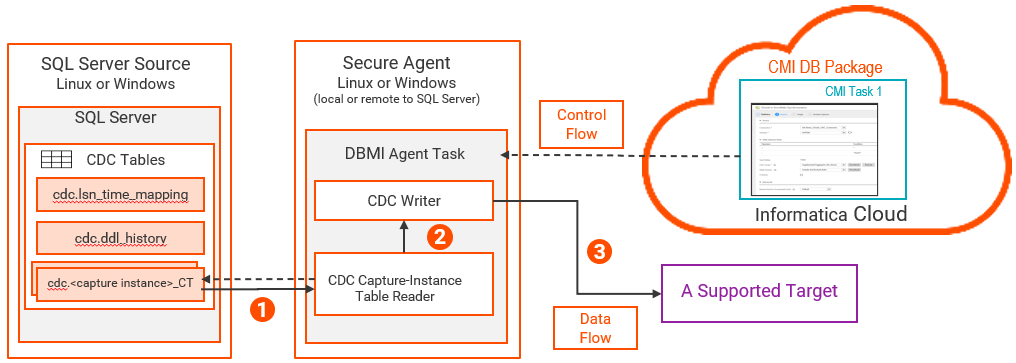
• • • • • capture instance >_CT。ソースデータベースでCDCが有効になっている場合、SQL ServerはこれらのテーブルをCDCスキーマに作成します。1つまたは2つのcdc.<capture instance >_CTテーブル。CDCが有効になっているソーステーブルごとに作成され、ネイティブログリーダーによってキャプチャされたDML変更を格納します。• capture_instance >_CTテーブルから変更レコードを読み取ります。• 次の図は、SQL Serverのログベースの変更データキャプチャコンポーネントとデータフローを示しています。
1 - - キャプチャプロセスは、コミットされたトランザクションが完了するか、致命的なエラーによってキャプチャプロセスが停止または中断されるか、cdc.<capture_instance >_CTテーブルからの変更レコードの読み取りへの切り替えがトリガーされるまで続行されます。
2 データベース取り込みとレプリケーション は、CDCキャプチャインスタンステーブルリーダーを使用して、cdc.<capture instance >_CTテーブルからの変更の読み取りに自動的に切り替わります。以下の条件下では、処理は、cdc.<capture instance >_CTテーブルに切り替わります。
- capture instance >_CTテーブル内に存在する場合、キャプチャプロセスの初期化および開始中である。- 注: 定期的なログバックアップでも、トランザクションログが切り詰められる可能性があります。データの損失を防ぐために、dbo.$InfaXactテーブルを使用するトランザクションは、アクティブなトランザクションログをロックします。
- capture instance >_CTテーブルからカラム情報を読み取ることにより、ログレコードに選択的にパッチを適用します。注: fn_dblog()関数から読み取られたレコードは、8000バイトに切り詰められます。
3 4 CDCテーブルのみを使用した変更キャプチャ データベース取り込みとレプリケーション の増分ロードジョブは、トランザクションログを使用せずにSQL Server CDCテーブルから直接変更をキャプチャできるようになりました。
CDCテーブルのみを使用する変更キャプチャ処理には、次のコンポーネントが関わります。
• • capture instance >_CT。ソースデータベースでCDCが有効になっている場合、SQL ServerはこれらのテーブルをCDCスキーマに作成します。1つまたは2つのcdc.<capture instance >_CTテーブル。CDCが有効になっているソーステーブルごとに作成され、ネイティブログリーダーによってキャプチャされたDML変更を格納します。• capture_instance >_CTテーブルから変更レコードを読み取ります。• 次の図は、SQL Serverのログベースの変更データキャプチャコンポーネントとデータフローを示しています。
1 capture instance >_CTテーブル内に存在する場合、キャプチャプロセスの初期化および開始中である。2 3 クエリベースの変更キャプチャ データベース取り込みとレプリケーション の増分ロードジョブは、変更が発生したときに更新されるタイムスタンプカラムを照会することにで、ソースにおける挿入と更新の変更をキャプチャします。ソースの設定は、各ソーステーブルへの共通CDCクエリカラムの追加に制限されます。クエリベースのCDCメソッドはクエリカラムを使用して、指定のCDC間隔の開始以降に変更された行を識別します。
クエリベースの変更キャプチャを実装するには、タスクウィザードの[ソース] ページで次のオプションを設定します。
• CDCメソッド 。[クエリベースの] を選択して、このキャプチャメソッドを有効にします。• CDCクエリカラム名 。ソーステーブルにおけるCDCクエリカラムの、大文字小文字が区別された名前です。クエリカラムでサポートされているSQL Serverデータ型は、DATETIMEとDATETIME2です。カラムはソーステーブルに存在する必要があります。• CDC間隔 。クエリベースの変更データキャプチャサイクルの頻度。デフォルトは5分です。• 増分ロード操作の当初の開始点 。変更キャプチャサイクルを開始するポイント。デフォルトは[使用可能な最新] です。CDC間隔が経過した後、データベース取り込みとレプリケーション は、CDCクエリカラムを参照するWHERE句を含むSQLクエリを使用して、CDC間隔の間に変更を受け取った行を識別します。変更データがキャプチャされ、ターゲットに適用されます。
クエリベースのCDC用に選択されたソーステーブルにCDCクエリカラムがない場合、変更データキャプチャはこれらのテーブルを無視し、残りのテーブルで処理を続行します。スキップされたテーブルの場合、ターゲットデータベースで生成された、対応するテーブルは空になります。どのソーステーブルにもCDCクエリカラムがない場合、ジョブは実行時に失敗します。
次の図は、SQL Serverのクエリベースの変更データキャプチャコンポーネントとデータフローを示しています。
1 データベース取り込みとレプリケーション は、CDCクエリカラムを使用して変更データを抽出するSQLクエリをソースデータベースで実行します。2 3 MongoDBソース データベース取り込みとレプリケーション タスクでMongoDBソースを使用するには、以下の考慮事項を確認してください。
ソースの準備: • データベース取り込みとレプリケーション は、MongoDB変更ストリームを使用して、単一のコレクション、データベース、またはデプロイメント全体のリアルタイムのデータ変更にアクセスします。• • { resource:
例:
db.createRole({ role: "readAnyDatabase", privileges: [{ resource:
• { resource:
使用に関する考慮事項: • データベース取り込みとレプリケーション タスクは、MongoDBデータをキーと値のペアとしてターゲットに移動します。ここで、キーはObjectIDであり、値はBSONドキュメントを構成するJSON文字列です。• • • データベース取り込みとレプリケーション は、MongoDBソースを持つ増分ロードジョブの時系列コレクションをサポートしていません。• データベース取り込みとレプリケーション は、再開ポイントとして指定された日時から変更レコードを取得します。MongoDBソースの場合、再開ポイントのデフォルト値は現在の時刻です。別の日時をグリニッジ標準時(GMT)で指定できます。• データベース取り込みとレプリケーション はスキーマの変更を具体的に検出して報告するわけではありません。MySQLソース データベース取り込みとレプリケーション タスクでMySQLソースを使用するには、最初にソースデータベースを準備し、使用に関する考慮事項を確認してください。
ソースの準備: • データベース取り込みとレプリケーション タスクをデプロイして実行するには、ソース接続で、必要な特権を持つデータベースユーザーを指定する必要があります。次のSQL文を使用して、これらのユーザーに特権を付与します。GRANT SELECT ON database_name .* TO 'user_name '@'%';database_name .* TO 'user_name '@'%';
増分ロードジョブの場合、次の追加の特権をユーザーに付与します。
/* To fetch table and column details from system tables */user_name '@'%'; user_name ; user_name ;
• SHOW VARIABLES LIKE '%engine%';
出力で、default_storage_engine変数がInnoDBに設定されていることを確認します。
• データベース取り込みとレプリケーション は、ソースで変更イベントをキャプチャするために、MySQLによって生成されたバイナリログファイルを使用します。binlogは、MySQLサーバーインスタンスに対して行われたデータ変更に関する情報を含む一連のログファイルです。バイナリログを有効にするには、--log-bin オプションを使用してサーバーを起動するか、またはmy.cnfファイルでキーと値のlog-bin="[HostName]-bin" 設定を使用します。[HostName] は使用するホストの名前に置き換えてください。次に、MySQLサーバーを再起動します。バイナリログが有効になっていることを確認するには、次の文を使用します。
SHOW VARIABLES LIKE 'log_bin';
出力で、log_bin変数がONに設定されていることを確認します。
• SET GLOBAL binlog_format = 'ROW';
行ベースのログが有効になっていることを確認するには、次の文を使用します。
SHOW VARIABLES LIKE 'binlog_format';
出力で、binlog_formatシステム変数がROWに設定されていることを確認します。
• データベース取り込みとレプリケーション の増分ロードジョブと組み合わせロードジョブで更新と削除を処理できるようにするには、バイナリロギング用に次のシステム変数を設定します。binlog_row_image=full
この設定により、操作前イメージと操作後イメージの両方が、すべてのカラムのバイナリログに記録されます。これは、データベース取り込みとレプリケーション でサポートしているすべてのMySQLソースタイプとバージョンに適用できます。
この設定を確認するには、次の文を使用します。
SHOW VARIABLES LIKE 'binlog_row_image';
• データベース取り込みとレプリケーション は、次のいずれかの方法でbinlogファイルを読み取ることができます。- - GTIDモードを有効にするには、各MySQLサーバーで次の文を使用します。
SET @@GLOBAL.ENFORCE_GTID_CONSISTENCY = WARN;
各サーバーで、ステータス変数'Ongoing_anonymous_transaction_count'が 0(ゼロ)になるまで待ちます。次の文を使用して、ステータス変数の値を確認できます。
SHOW STATUS LIKE 'Ongoing_anonymous_transaction_count';
カウントが0の場合、次の文を使用してGTIDモードを有効にします。
SET @@GLOBAL.GTID_MODE = ON;
• - - - 注: MySQL Enterprise Editionソースを持つ初期ロードジョブのみを実行する場合は、ドライバをダウンロードする必要はありません。
MySQL JDBCドライバファイル、mysql-connector-java-<version>.jarをMySQL Community Downloads Webサイトからダウンロードし、次のディレクトリにコピーします。
<Secure_Agent_installation_directory >/ext/connectors/thirdparty/com.mysql/
接続プロパティを定義した後でAdministratorで接続をテストできるようにする場合は、Secure Agentのシステム構成の詳細でData Integration ServerサービスのMySQL_JDBC_DRIVER_JARNAMEパラメータも設定する必要があります。テスト後、パラメータを削除できます。このパラメータは、接続を使用してデータベース取り込みとレプリケーション タスクを作成したり、関連するジョブを実行する場合には使用されません。
使用に関する考慮事項: • データベース取り込みとレプリケーション は、初期ロード、増分ロード、および初期ロードと増分ロードの組み合わせジョブに対するMySQL、Amazon Aurora MySQL、Cloud SQL for MySQL、およびRDS for MySQLソースをサポートしています。また、データベース取り込みとレプリケーション は、すべてのロードタイプでAzure Database for MySQLソースとSnowflakeターゲットの組み合わせをサポートしており、増分ロードではConfluent Kafkaとの組み合わせをサポートしています。• データベース取り込みとレプリケーション では、ソーステーブルの各行が一意であることを想定しているため、各ソーステーブルにプライマリキーを持たせることをお勧めします。データベース取り込みとレプリケーション は、プライマリキーの代わりに一意のインデックスを許可しません。プライマリキーが指定されていない場合、データベース取り込みとレプリケーション はすべてのカラムをプライマリキーの一部であるかのように扱います。• • データベース取り込みとレプリケーション ジョブは、SETカラムとENUMカラムのデータを数値としてターゲットにレプリケートします。初期ロードジョブの場合は、タスクウィザードの[ソース] ページでmysql.set.and.enum.as.numericカスタムプロパティをfalseに設定して、SETまたはENUMデータを文字列またはvarchar形式でレプリケートすることができます。デフォルト値はtrueで、これにより、データベース取り込みとレプリケーション はSETまたはENUMデータを数値としてレプリケートします。注: 増分ロードジョブの場合は、SETまたはENUMカラムデータの数値表現と文字列表現またはvarchar表現を切り替えることはできません。mysql.set.and.enum.as.numericカスタムプロパティをfalseに設定し、初期ロードジョブを実行した後に増分ロードジョブを実行すると、データベース取り込みとレプリケーション はSETおよびENUMデータを数値のみとしてターゲットにレプリケートします。
• データベース取り込みとレプリケーション では、次のMySQLデータ型はサポートされません。- - - - - - - - - データベース取り込みとレプリケーション タスクで、JSONデータ型のカラムを含むソーススキーマを指定する場合、タスクをデプロイすると、JSONカラムが無視され、ターゲットに対応するカラムは作成されません。その他のサポートされないデータ型の場合、データベース取り込みジョブはnullをプロパゲートします。
サポートされているソースデータ型からターゲットデータ型へのデフォルトのマッピングについては、
デフォルトデータ型のマッピング を参照してください。
Netezzaソース データベース取り込みとレプリケーション タスクでNetezzaソースを使用するには、最初にソースデータベースを準備し、使用に関する考慮事項を確認してください。
ソースの準備: 使用に関する考慮事項: • データベース取り込みとレプリケーション では、次のNetezzaデータ型はサポートされません。データベース取り込みとレプリケーション ジョブは、このデータ型を持つカラムにはデプロイしたりnullをプロパゲートしたりすることはできません。
サポートされているソースデータ型からターゲットデータ型へのデフォルトのマッピングについては、
デフォルトデータ型のマッピング を参照してください。
Oracleソース データベース取り込みとレプリケーション タスクでOracleソースを使用するには、最初にソースデータベースを準備し、使用に関する考慮事項を確認してください。
ソースの準備: • - - [データベース接続文字列] プロパティでTNS名を指定している場合、ファイルがデフォルトの$ORACLE_HOME/network/adminディレクトリにないときは、この環境変数を使用してtsnnames.oraファイルのディレクトリの場所を指すようにします。tnsnames.oraファイルは、Oracleソースデータベースと通信するために、Oracle Call Interface(OCI)とともに使用されます。注: Administratorで、データベース取り込みエージェントサービス(DBMIエージェント)のociPathプロパティを、oci.dllまたはlibcIntsh.soファイルを含むOCIライブラリを指すように設定できます。OCIライブラリは、データベース取り込みとレプリケーション のCDCタスクによってOracleに接続するために使用されます。Oracleは、Linuxでは$ORACLE_HOME/lib、Windowsでは%ORACLE_HOME%\binのociPath値をデフォルトで使用します。
• データベース取り込みとレプリケーション ユーザーに、データベース取り込みとレプリケーション のロードタイプの実行に必要なOracle特権があることを確認してください。注: ログベースのCDCを使用した初期ロードと増分ロードの組み合わせの場合は、選択したソーステーブルごとにGRANT FLASHBACK特権が発行されていることを確認するか、ANY TABLEオプションを使用します。データベース取り込みとレプリケーション は、SELECT AS OF scn 文で構成されるOracle Flashback Queryを使用して、Oracleデータベースのソーステーブルの行データをクエリします。Oracleでは、このクエリを使用するにはGRANT FLASHBACK特権が必要です。
詳細については、
Oracle特権 を参照してください。
• • データベース取り込みとレプリケーション ジョブには、増分変更データを読み取るためにOracleのオンラインREDOログとアーカイブREDOログへの読み取りアクセスが必要です。REDOログが、Secure Agentが実行されているオンプレミスシステムからリモートにある場合は、ログへの読み取りアクセスが提供されていることを確認してください。例えば、Oracle Automatic Storage Management(ASM)を使用して、ログをネットワークファイルシステム(NFS)にマウントするか、またはOracleファイルシステム上にあるログへのBFILEアクセスを設定することによって、それを実現します。• • • - SHUTDOWN IMMEDIATE;
Amazon RDS for Oracleデータベースの場合、データベースをARCHIVELOGモードにして、自動バックアップを有効にするために、バックアップの保存期間を設定します。
- - - 注: データベース取り込みとレプリケーション タスクを作成するときに、選択したソーステーブルのすべてのカラムまたはプライマリキーカラムのみのサプリメンタルロギングを実装するスクリプトを生成するオプションがあります。
- いない ことを確認してください。EXTENDEDに設定されている場合、データベース取り込みとレプリケーション は、大きな(拡張サイズ)VARCHAR2、NVARCHAR2、またはRAWカラムで定義されたカラムを含むテーブルの挿入と更新をレプリケートできません。これらのタスクを実行する権限がない場合は、Oracleデータベース管理者に実行を依頼してください。詳細については、Oracleのマニュアルを参照してください。
• データベース取り込みとレプリケーション タスクを作成する前に、クエリカラムをソーステーブルに追加する必要があります。クエリカラムでサポートされるOracleデータ型はTIMESTAMPです。クエリベースのCDC用に選択されたソーステーブルにCDCクエリカラムがない場合、変更データキャプチャはこれらのテーブルを無視し、残りのテーブルで処理を続行します。スキップされたテーブルの場合、ターゲットデータベースで生成された、対応するテーブルは空になります。どのソーステーブルにもCDCクエリカラムがない場合、ジョブのデプロイは失敗します。
Oracleソース準備用のAmazon Relational Database Service(RDS):
1 exec rdsadmin.rdsadmin_master_util.create_archivelog_dir;
2 データベース取り込みとレプリケーション ユーザーに付与します。Amazon RDS for Oracleソースに必要な特権の詳細については、
Amazon RDS for Oracleソースに対するOracle特権 を参照してください。
3 exec rdsadmin.rdsadmin_util.set_configuration('archivelog retention days',number_of_days );
4 注: この手順では、データベースに対してARCHIVELOGモードを有効にします。
5 exec rdsadmin.rdsadmin_util.alter_supplemental_logging('ADD');
データベース取り込みとレプリケーション タスクを作成するときに、選択したソーステーブルのサプリメンタルロギングを有効にするスクリプトを生成できます。
6 - - - - 次に、ソースデータベースのパラメーターグループを選択します。
使用に関する考慮事項: • データベース取り込みとレプリケーション は、ソースから変更データをキャプチャし、そのデータをターゲットに適用するための代替キャプチャメソッドを提供します。使用可能な変更キャプチャメソッドは次のとおりです。- データベース取り込みとレプリケーション は、Oracle REDOログからデータ変更を読み取ります。この方法では、ユーザーの権限を拡張する必要があります。- • データベース取り込みとレプリケーション では、ソーステーブルの各行が一意であることを想定しているため、各ソーステーブルにプライマリキーを持たせることをお勧めします。データベース取り込みとレプリケーション は、プライマリキーの代わりに一意のインデックスを許可しません。プライマリキーが指定されていない場合、データベース取り込みとレプリケーション はすべてのカラムをプライマリキーの一部であるかのように扱います。例外: OracleクエリベースのCDCの場合、各ソーステーブルにプライマリキーが必要です。• • データベース取り込みとレプリケーション は、ファイルシステム、ASM、またはOracle Key Vault(OKV)などPKCS11インタフェースを提供する外部ハードウェアセキュリティモジュール(HSM)にあるTDEキーストアへのマスター暗号化キーの保存をサポートします。詳細については、Informaticaグローバルカスタマサポートにお問い合わせください。• データベース取り込みとレプリケーション ジョブは、Amazon S3、フラットファイル、Microsoft Azure Data Lake、またはMicrosoft Azure Synapse Analyticsターゲットにデータを書き込むときに、null値を二重引用符(")マークまたはその他の区切り文字で区切りません。• データベース取り込みとレプリケーション は、Oracle Data Guardの論理および物理スタンバイデータベースおよびFar Syncインスタンスをソースとしてサポートします。詳細については、ソースとしてのOracle Data GuardデータベースまたはFar Syncインスタンス • データベース取り込みとレプリケーション は、RESETLOGS境界を越えてデータを処理できます。ソースとターゲットが同期しなくなるのを避けるため、RESETLOGSを実行する前にキャプチャ処理を停止し、RESETLOGSイベントの後にキャプチャ処理を再開することをお勧めします。そうしないと、キャプチャプロセスによってデータがターゲットに送信され、その後RESETLOGSイベントによって元に戻されて、ソースとターゲットが同期しなくなる可能性があります。• CDCのOracleログアクセス方法 • データベース取り込みとレプリケーション の増分ロードタスクまたは初期ロードと増分ロードの組み合わせタスクに、30文字を超えるOracleソーステーブル名または1つ以上のカラム名が含まれている場合、Oracleではプライマリキーと外部キーを含むテーブル全体の補足ログが抑制されます。その結果、テーブルに対するほとんどの操作が失敗します。この問題は、Oracleの制限が原因で発生します。この状況では、テーブルをキャプチャ処理から除外するか、長いテーブル名とカラム名を30文字以下の名前に変更してください。• データベース取り込みとレプリケーション で、Oracle BLOB、CLOB、NCLOB、LONG、LONG RAW、およびXMLカラムからAmazon Redshift、Amazon S3、Databricks、Google BigQuery、Google Cloud Storage、Microsoft Azure Data Lake Storage Gen2、Microsoft Azure Synapse Analytics、Microsoft Fabric OneLake、Oracle、Oracle Cloud Object Storage、PostgreSQL、Snowflake、およびSQL Serverターゲットにデータをレプリケートできます。タスクを設定するときに、[ソース] ページの[詳細] で[LOBを含める] を選択する必要があります。LOBカラムデータのサイズがターゲットタイプで許可されているバイト制限よりも大きい場合、ターゲットで切り詰められることがあります。注: LONG、LONG RAW、およびXMLデータ型を持つカラムは、初期ロードジョブ、および[クエリベース]のCDCメソッドを使用する増分ロードジョブと組み合わせロードジョブでサポートされています。ただし、[ログベース]のCDC方式を使用するジョブでは、生成されたターゲットテーブルにこれらのタイプのカラムのデータがレプリケートされることはありません。
• データベース取り込みとレプリケーション では、どのターゲットタイプとロードタイプでも次のOracleソースデータ型はサポートされません。- - - - - - - - サポートされていないデータ型を持つソースカラムは、ターゲット定義から除外されます。
サポートされているOracleデータ型からターゲットデータ型へのデフォルトのマッピングについては、「
デフォルトデータ型のマッピング 」を参照してください。
• [編集] をクリックします。[カスタム構成の詳細] で、環境変数に次の詳細を追加します。- サービス : データベース取り込み- タイプ : DBMI_AGENT_ENV- 名前 : DBMI_ORACLE_SOURCE_ENABLE_TIMESTAMP_WITH_TZまたはDBMI_ORACLE_SOURCE_ENABLE_TIMESTAMP_WITH_LOCAL_TZ- 値 : true• データベース取り込みとレプリケーション タスクのデプロイが失敗する可能性があります。• データベース取り込みとレプリケーション では、ターゲットタイプに関係なく、Oracleソースカラムの非表示カラムはサポートされていません。これらのカラムについては、データベース取り込みとレプリケーション の増分ロードジョブ、および初期ロードと増分ロードの組み合わせジョブは、対応するターゲットカラムにnullをプロパゲートします。• • データベース取り込みとレプリケーション は、実際に値を変更しない更新行を無視します。また、ほとんどのデータベースターゲットにおいて、データベース取り込みとレプリケーション はターゲットに変更を書き込む前にマイクロバッチレベルで変更レコードの集計を行います。この場合、監視統計の更新カウントとターゲットに適用された行との間に不一致が発生する可能性もあります。• データベース取り込みとレプリケーション の増分ロードまたは組み合わせロードジョブの結果は予測できません。• データベース取り込みとレプリケーション は、Oracleソースを持つジョブの派生カラムをサポートしていません。• • データベース取り込みとレプリケーション の初期ロードジョブ、増分ロードジョブ、および初期ロードと増分ロードの組み合わせジョブは、Secure Agentグループ内の別の使用可能なエージェントに自動的に切り替えることができます。自動スイッチオーバーは、15分のハートビート間隔が経過した後に行われます。自動スイッチオーバーは、任意のソースタイプとKafka以外のターゲットタイプの初期ロードジョブでサポートされています。また、Oracleソースを持つ増分ロードジョブと組み合わせロードジョブでもサポートされていますが、次の制限があります。- - - • - - - - データベース取り込みとレプリケーション は再開してそのサイクルで発生した変更を処理します。夏時間またはタイムゾーンの変更を適用するには、Oracleデータベースを再起動する必要があります。- データベース取り込みとレプリケーション の初期ロードと増分ロードの組み合わせジョブでは、アーカイブREDOログのコピーから変更を読み取ることができます。Oracleデータベース取り込み接続プロパティの[読み取りモード] プロパティをARCHIVECOPYに設定し、ソースのカスタムプロパティpwx.cdcreader.oracle.reader.additionalをdirおよびfileパラメータを指定して設定する必要があります。dirパラメータでは、CDCログリーダーがアーカイブログコピーをスキャンするベースディレクトリの名前を指すようにし、fileパラメータでは、ログコピーのフィルタリングに使用するマスクを指定します。• データベース取り込みとレプリケーション ジョブの実行後、レプリケーション用に追加のソースカラムを選択してタスクを再デプロイした場合、ジョブは追加のカラムを使用してターゲットテーブルをすぐに再作成したり、それらのデータをレプリケートしたりしません。ただし、増分ロードジョブ、または初期ロードと増分ロードの組み合わせジョブでは、スキーマドリフトの[カラムの追加] オプションを[レプリケート] に設定した場合、次の新しいDML変更レコードを処理するときに、新しく選択したカラムがターゲットに追加され、データがレプリケートされます。初期ロードジョブでは、次回のジョブ実行時に、新しく選択したカラムがターゲットに追加され、データがレプリケートされます。 • データベース取り込みとレプリケーション は、Oracle Exadataマシンから変更データをキャプチャできますが、Oracle Exadata Hybrid Columnar Compression(EHCC)はサポートしていません。• データベース取り込みとレプリケーション ジョブでも、Oracleのシノニムをソースとして使用することはできません。• [LOBを含める] オプションが有効になっていてソースを処理するデータベース取り込みとレプリケーション ジョブは、次のような警告メッセージを発行します。PWX-36678 ORAD WARN: Failed to fetch LOB data for table <schema>.<table> column <column> to resolve partially logged data.
通常、データのログが不完全である原因は、既存のLOBカラムに追加されたためです。この問題は、どのロードタイプでも発生する可能性があります。
この問題を解決するには、タスクウィザードの[ソース] ページで、pwx.cdcreader.oracle.option.additionalカスタムプロパティをLOB_FETCHBACK=Yパラメータとともに指定します。この設定により、現在のデータはログからではなく、データベースから直接取得されます。このソリューションを正常に使用するには、ユーザーにSELECT ON ANY TABLE特権が付与されている必要があります。
• データベース取り込みとレプリケーション BFILEアクセスは、プライマリデータベースとスタンバイデータベース、RDSデータベースインスタンス、またはUSE_DB_RECOVERY_FILE_DESTパラメータが指す高速リカバリ領域がある環境など、複数のログの場所をサポートします。データベース取り込みおよびレプリケーションは、ARCHIVELOG_DIRおよびONLINELOG_DIRで始まり、ARCHIVELOG_DIR_01、ARCHIVE_LOG_DIR_02などのサフィックスで終わるすべてのディレクトリオブジェクトを問い合せることで、ログを自動的に見つけることができます。カスタムプロパティpwx.cdcreader.oracle.database.additional BFILEARCHIVEDIR=<directory_object>およびpwx.cdcreader.oracle.database.additional BFILEONLINEDIR=<directory_object>を使用して、ARCHIVELOG_DIR名とONLINELOG_DIR名をオーバーライドすることができます。データベース取り込みおよびレプリケーションジョブを実行するデータベースユーザーにCREATE ANY DIRECTORY特権とDROP ANY DIRECTORY特権を付与すると、必要に応じてディレクトリオブジェクトを実行時に作成できるようになります。例えば、データベースに複数のアーカイブログとオンラインログの格納先が存在する場合は、ディレクトリオブジェクトを次の命名規則で作成することができます。
- - - - データベース取り込みおよびレプリケーションは、これらの生成されたディレクトリオブジェクトに対してクリーンアップ処理を実行しません。
USE_DB_RECOVERY_FILE_DESTパラメータを使用しており、CREATE ANY DIRECTORY特権およびDROP ANY DIRECTORY特権が付与されていない場合、DBAは次のようなスクリプトを使用して、データベース取り込みおよびレプリケーションジョブを実行する前に、毎日または毎週ディレクトリオブジェクトを作成する必要があります。
create or replace directory ARCHIVELOG_DIR_2024_08_19 as '<DB_RECOVERY_FILE_DEST>/2024_08_19'
USE_DB_RECOVERY_FILE_DESTパラメータを使用しており、データベースユーザーにCREATE ANY DIRECTORY特権とDROP ANY DIRECTORY特権が付与されている場合、ディレクトリオブジェクトは実行時に必要に応じて作成され、14日後に削除されます。これらのディレクトリオブジェクトには、<ARCHIVEDIRNAME>_YYYY_MM_DDという命名規則があります。
• [CDCスクリプト] フィールドを[プライマリキーカラムのCDCを有効化] に設定した場合、更新されたカラムの値とプライマリキーカラムの値のみがターゲットにレプリケートされます。他のカラムの場合、ジョブはNULLをターゲットにレプリケートします。これは、それらのカラムに対してredoログへのデータの補足ロギングが有効になっていないためです。ファイルベースのターゲットにレプリケートされた更新のすべてのカラム値が必要な場合は、[CDCスクリプト] フィールドを[すべてのカラムのCDCを有効化] に設定します。
データベース取り込みとレプリケーション 環境に関する情報の収集データベース取り込みとレプリケーション タスクの作成を開始する前に、以下の情報を収集してください。
全般的な情報 どのOracleバージョンを使用しているか。 答え: ___________________________________________________ Oracleをオンプレミスで実行するか、それともクラウドベースのAmazon RDS for Oracle環境で実行するか。 答え: ___________________________________________________ ターゲットタイプは何か。 答え: ___________________________________________________ どのタイプのロード操作を実行する予定か。初期ロード(ポイントインタイムバルクロード)、増分ロード(変更のみ)、または初期ロードと増分ロードの組み合わせ(初期ロードとそれに続く増分ロード)のどれか。 答え: ___________________________________________________ Secure Agentを実行するシステムのコア数、メモリ量、およびディスク容量はいくつか。 答え: ___________________________________________________ Oracle環境 Oracleソースデータベースサーバーのホスト名とポート番号は何か。 答え: ___________________________________________________ データベースのOracleシステム識別子(SID)は何か。 答え: ___________________________________________________ データベースへの接続に使用するOracleデータベースのユーザー名とパスワードは何ですか? 答え: ___________________________________________________ Secure Agentを実行するシステムにOracle Database ClientまたはInstant Clientがインストールされていますか? 答え: ___________________________________________________ データベースはOracle Real Application Cluster(RAC)で実行されますか? 非アクティブなノードを含め、RACメンバーの最大数はいくつですか? 答え: ___________________________________________________ Oracle Data Guardの論理または物理スタンバイデータベースから変更データをキャプチャする必要があるか。 答え: ___________________________________________________ Oracleマルチテナント環境のプラガブルデータベース(PDB)のテーブルから変更データをキャプチャする必要がありますか? 答え: ___________________________________________________ Oracle Transparent Data Encyrption(TDE)を使用するテーブルスペースから変更データをキャプチャする必要がありますか? はいの場合、TDEウォレットディレクトリとパスワードは何ですか? 答え: ___________________________________________________ ソーステーブルのUnit of Work(UOW)の一般的なサイズはいくつか。 答え: ___________________________________________________ Oracle REDOログ REDOログはOracle Automatic Storage Management(ASM)環境にありますか? ASMインスタンスに接続してREDOログを読み取る場合に、SYSDBAまたはSYSASM権限を持つASMのログインユーザーIDの作成を許可されているか。 答え: ___________________________________________________ OracleソースデータベースのARCHIVELOGモードと最少グローバル補足ログが有効になっているか。されていない場合は、有効にできるか。 答え: ___________________________________________________ 変更データを読み取るアーカイブREDOログのプライマリおよびセカンダリアーカイブ先はどこか。 答え: ___________________________________________________ Oracleデータベースのピーク期間中とピーク期間外に作成されるアーカイブREDOログの1時間あたりの平均量はいくつか。 答え: ___________________________________________________ 使用している環境のREDOログへの読み取りアクセスを持っているか。 答え: ___________________________________________________ REDOログを直接読み取る権限を持っていない場合、アーカイブREDOログファイルを共有ディスクまたはファイルシステムにコピーし、その共有ディスクまたはファイルシステムから、コピーしたREDOログファイルにアクセスできるか。 答え: ___________________________________________________ データベース取り込みとレプリケーション で、アーカイブログだけでなくオンラインログから変更データを読み取れるようにするか。答え: ___________________________________________________ CDC処理中のエラーまたは異常を診断するために、必要に応じて、診断に使用するアーカイブREDOログをInformaticaグローバルカスタマサポートに提供できるか。 答え: ___________________________________________________ データベース取り込みを設定するための詳細情報 データのレプリケート元となるソーステーブルのスキーマ名は何か。 答え: ___________________________________________________ スキーマ内のすべてのテーブルまたはそれらのテーブルのサブセットからデータをレプリケートするか。サブセットの場合は、それらのリストを作成してください。 答え: ___________________________________________________ ソーステーブルにプライマリキーがあるか。すべてのプライマリキーに対して補足ログを有効にできるか。 答え: ___________________________________________________ キーなしのソーステーブルはあるか。 答え: ___________________________________________________ ソーステーブルに、サポートされていないデータ型のカラムが含まれているか。ソースタイプでサポートされていないデータ型を判別するには、データベース取り込みとレプリケーション ヘルプの「データベース取り込みとレプリケーション のソースに関する考慮事項」のソース固有のトピックを参照してください。 答え: ___________________________________________________ UTF-8のデフォルトのコードページは容認できるか。できない場合、どのコードページを使用するか。 答え: ___________________________________________________ SSLを使用して、Secure Agentとデータベースサーバー間で交換するデータを暗号化するか。暗号化SSLまたはTLSプロトコルはどれを使用するか。 答え: ___________________________________________________ 新しいOracleユーザーを作成し、データベース取り込みとレプリケーション で必要となる特権をそのユーザーに割り当てることができるか。使用するユーザー名を決定してください。 答え: ___________________________________________________ ソーステーブルに、データベース取り込みとレプリケーション がサポートしていないOracleデータ型が含まれているか。 答え: ___________________________________________________ カラムの追加、削除、変更、名前変更操作など、ソースでのスキーマドリフトの変更をキャプチャするか。 答え: ___________________________________________________ Oracle特権 Oracleソースを持つデータベース取り込みとレプリケーション タスクをデプロイして実行するには、ソース接続で取り込みロードタイプに必要な特権を持つデータベース取り込みとレプリケーション ユーザーを指定する必要があります。
ログベースのCDCを使用した増分ロード処理の権限
注: OracleログがASMによって管理されている場合、ユーザーはSYSASMまたはSYSDBA権限を持っている必要があります。
ログベースのCDCメソッドを使用した増分ロードまたは、初期ロードと増分ロードの組み合わせを実行するデータベース取り込みとレプリケーション タスクの場合、データベース取り込みとレプリケーション ユーザー(cmid_user )に次の権限が付与されていることを確認してください。
GRANT CREATE SESSION TO <cmid_user >;table TO <cmid_user >; -- For each source table created by usercmid_user >;table |ANY TABLE TO <cmid_user >; table |ANY TABLE TO <cmid_user >; cmid_user >;cmid_user >;cmid_user >;cmid_user >;cmid_user >;cmid_user >;cmid_user >;cmid_user >; cmid_user >;cmid_user >;cmid_user >;cmid_user >; -- For Oracle multitenant environmentscmid_user >;cmid_user >;cmid_user >; -- For Oracle TDE accesscmid_user >;cmid_user >;cmid_user >;cmid_user >; -- For Oracle multitenant environmentscmid_user >;cmid_user >;cmid_user >;cmid_user >;cmid_user >;cmid_user >;cmid_user >;cmid_user >;cmid_user >;cmid_user >;cmid_user >;cmid_user >; cmid_user >; cmid_user >;cmid_user >;cmid_user >;cmid_user >;cmid_user >;cmid_user >;cmid_user >;cmid_user >;
クエリベースのCDCを使用した増分ロード処理の権限
クエリベースのCDCメソッドを使用した増分ロード、または初期ロードと増分ロードの組み合わせを実行するデータベース取り込みとレプリケーション タスクの場合、ユーザーが少なくとも次の特権を持っていることを確認してください。
GRANT CREATE SESSION TO <cmid_user >;cmid_user >;cmid_user >;cmid_user ;cmid_user >;cmid_user >;cmid_user >; -- Only if you unload data from viewscmid_user >;table TO <cmid_user >; -- For each source table created by usercmid_user >;cmid_user >;cmid_user >;cmid_user >; cmid_user >; cmid_user >;cmid_user >;cmid_user >;cmid_user ;cmid_user ;cmid_user >;cmid_user >;cmid_user >; cmid_user >;cmid_user >;cmid_user >;cmid_user ;cmid_user >;cmid_user >;cmid_user >;
初期ロード処理の特権
初期ロードを実行するデータベース取り込みとレプリケーション タスクの場合、ユーザーが少なくとも次の権限を持っていることを確認してください。
GRANT CREATE SESSION TO <cmid_user >;cmid_user >;cmid_user >;cmid_user ;cmid_user >;cmid_user >;cmid_user >; -- Only if you unload data from viewscmid_user >;table TO <cmid_user >; -- For each source table created by usercmid_user >;cmid_user >;cmid_user >;cmid_user >; cmid_user >; cmid_user >;cmid_user >;cmid_user >;cmid_user ;cmid_user ;cmid_user >;cmid_user >;cmid_user >; cmid_user >;cmid_user >;cmid_user >;cmid_user ;cmid_user >;cmid_user >;cmid_user >;
Amazon RDS for Oracleソースに対するOracle特権 Amazon RDS for Oracleソースを使用している場合は、データベース取り込みとレプリケーション ユーザーに特定の権限を付与する必要があります。
重要: GRANT文とプロシージャを実行するには、マスターユーザー名でAmazon RDSにログインする必要があります。
少なくとも、CDC処理に必要なオブジェクトおよびシステムテーブルに対するSELECT特権を、データベース取り込みとレプリケーション ユーザー(cmid_user )に付与します。特定の状況では、追加の権限の付与が必要になります。
次のGRANT文を使用します。
GRANT SELECT ON "PUBLIC"."V$ARCHIVED_LOG" TO "cmid_user ";cmid_user ";cmid_user ";cmid_user ";cmid_user ";cmid_user ";cmid_user ";cmid_user ";cmid_user ";cmid_user ";cmid_user ";cmid_user ";cmid_user ";cmid_user ";cmid_user ";cmid_user ";cmid_user ";cmid_user ";cmid_user ";cmid_user ";cmid_user ";cmid_user ";cmid_user ";cmid_user ";
さらに、マスターユーザーとしてログインし、次のAmazon RDSプロシージャを実行して、さらにいくつかのオブジェクトに対するSELECT特権を付与します。
begincmid_user ',cmid_user ',cmid_user ',cmid_user ',cmid_user ',cmid_user ',cmid_user ',cmid_user ',cmid_user ',cmid_user ',cmid_user ',cmid_user ',cmid_user ',cmid_user ',cmid_user ',cmid_user ',sadmin_util.grant_sys_object( ',cmid_user ',cmid_user ',cmid_user ',cmid_user ',cmid_user ',cmid_user ',cmid_user ',cmid_user ',cmid_user ',
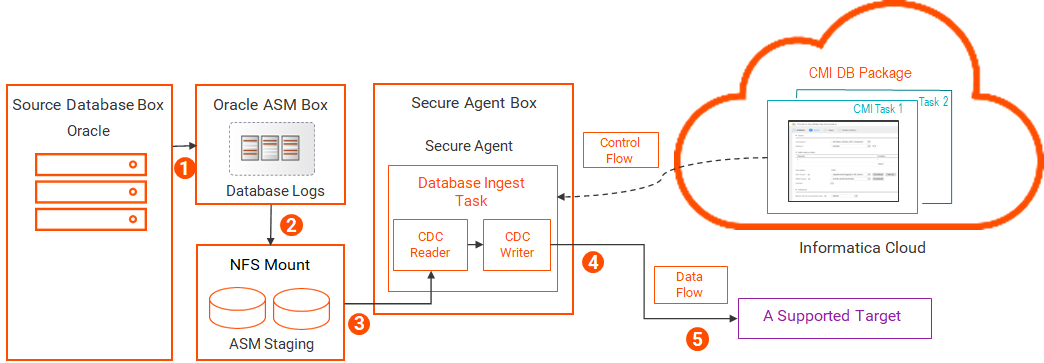
CDCのOracleログアクセス方法 データベース取り込みとレプリケーション の増分ロードジョブ、および初期ロードと増分ロードの組み合わせジョブは、環境と要件に応じて、CDC処理のために別の方法でOracle REDOログにアクセスできます。
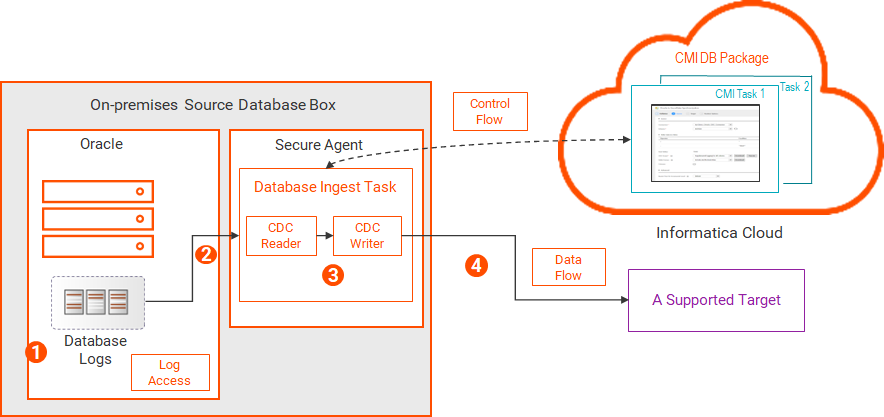
直接ログアクセス データベース取り込みとレプリケーション ジョブは、オンプレミスのソースシステム上の物理Oracle REDOログに直接アクセスして、変更データを読み取ることができます。
注: ログをソリッドステートディスク(SSD)に保存すると、この方法で最高のパフォーマンスを実現できます。
次の図は、データフローを示しています。
1 2 データベース取り込みとレプリケーション のCDCリーダーが、物理ログファイルを読み取り、CDCの対象となるソーステーブルのログファイルから変更レコードを抽出します。3 データベース取り込みとレプリケーション のCDCライターが変更レコードを読み取ります。4 NFSマウントされたログ データベース取り込みとレプリケーション ジョブは、ネットワークファイル共有(NFS)マウント、またはネットワーク接続ストレージ(NAS)やクラスタ化されたストレージなど別の方法を使用して、共有ディスクからOracleデータベースログにアクセスできます。
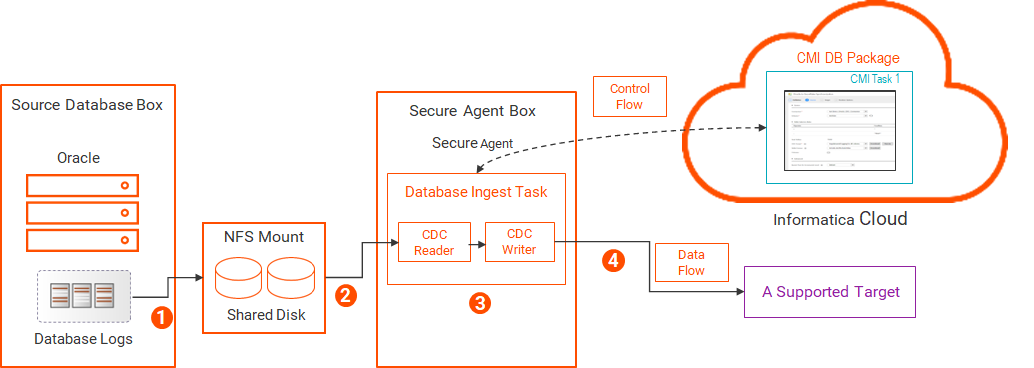
次の図は、データフローを示しています。
1 共有ディスクは、ファイルをデータベースとSecure Agentホストの両方に対してローカルとして見える任意のシステムに配置できます。この共有は、上記のようにNFSを使用するか、ネットワーク接続ストレージ(NAS)またはクラスタ化されたストレージを使用して実現できます。
2 データベース取り込みとレプリケーション のCDCリーダーが、ネットワークを介してNFSサーバーからログファイルを読み取り、CDCの対象となるソーステーブルの変更レコードを抽出します。3 データベース取り込みとレプリケーション のCDCライターが変更レコードを読み取ります。4 ASM管理によるログ データベース取り込みとレプリケーション ジョブは、Oracle Automatic Storage Management(ASM)システムに格納されているOracle REDOログにアクセスできます。ASM管理によるREDOログから変更データを読み取るには、ASMユーザーが、ASMインスタンスに対するSYSASMまたはSYSDBA権限を持っている必要があります。
Oracle Database Ingestion接続を設定するときは、名前に「ASM」を含むプロパティを入力します。
また、Informaticaでは、Oracle ASMのREDOログファイルからデータを読み取る場合、ローカルのsqlnet.oraファイルのsqlnet.recv_timeoutパラメータを5分未満に設定することをお勧めします。このパラメータは、クエリがタイムアウトになるまでにOracleクライアントがASMからの応答を待機する時間を指定します。ネットワークの中断やその他の要因により、Oracle接続が応答しなくなることがあります。この値を設定すると、リーダーがそのような状況に適時応答してリカバリできるようになります。
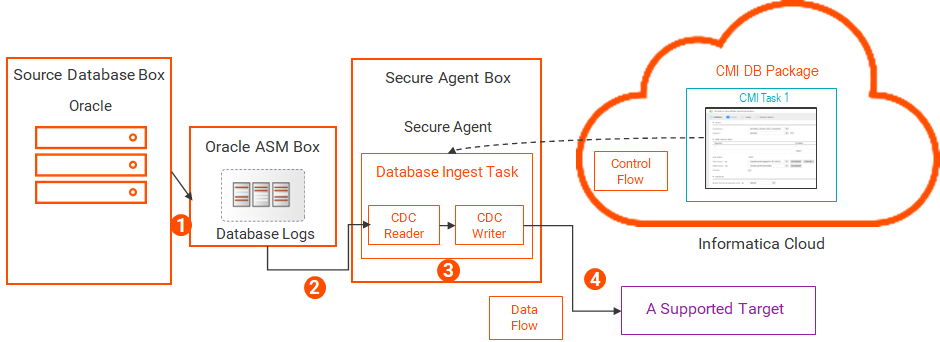
次の図は、データフローを示しています。
1 2 データベース取り込みとレプリケーション のCDCリーダーが、ASM管理によるログファイルを読み取り、CDCの対象となるソーステーブルの変更レコードを抽出します。3 データベース取り込みとレプリケーション のCDCライターが変更レコードを読み取ります。4 ステージングディレクトリを使用したASM管理によるログ データベース取り込みジョブは、ASM環境のステージングディレクトリからASM管理によるREDOログにアクセスできます。ASMのみを使用する場合と比較して、この方法ではログファイルへのアクセスが高速になり、ASMシステムのI/Oが低減されます。ASM管理によるログから変更データを読み取るには、ASMユーザーが、ASMインスタンスに対するSYSASMまたはSYSDBA権限を持っている必要があります。
次の図は、データフローを示しています。
1 2 ステージングディレクトリは、NFSマウントなどの共有ディスク上にある必要があります。そうすることにより、ASMはそこにデータを書き込み、データベース取り込みとレプリケーション ジョブはそこからデータを読み取ることができます。
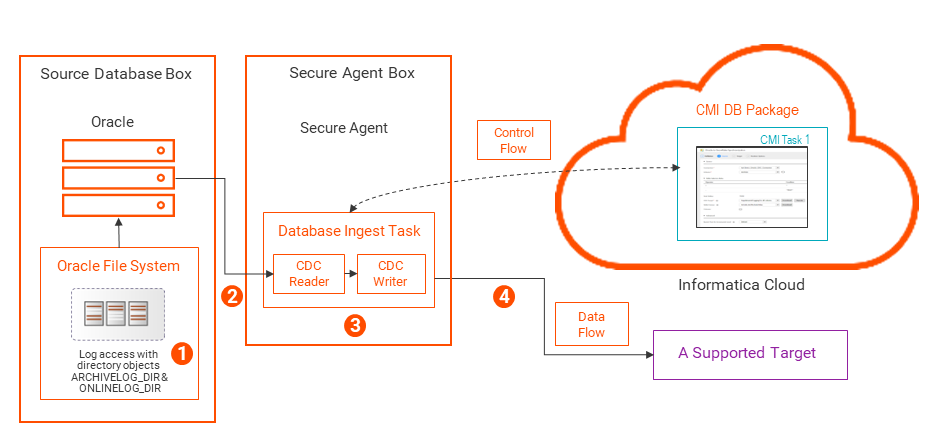
3 データベース取り込みとレプリケーション のCDCリーダーが、ステージングディレクトリにあるログファイルを読み取り、CDCの対象となるソーステーブルの変更レコードを抽出します。4 データベース取り込みとレプリケーション のCDCライターが変更レコードを読み取ります。5 ディレクトリオブジェクトを使用したOracleサーバーファイルシステムのログへのBFILEアクセス オンプレミスのOracleソースシステムでは、BFILEロケータを備えたOracleディレクトリオブジェクトを使用して、ローカルOracleサーバーファイルシステムからオンラインREDOログとアーカイブREDOログを読み取るように、
データベース取り込みとレプリケーション を設定できます。Oracle REDOログファイルの場所を指すARCHIVELOG_DIRおよびONLINELOG_DIRという名前のOracleディレクトリオブジェクトを作成する必要があります。BFILEアクセスの設定については、
OracleファイルシステムのOracle REDOログへのBFILEアクセスの設定 を参照してください。
次の図は、データフローを示しています。
1 データベース取り込みとレプリケーション タスクがログファイルを読み取る必要があるときに、Oracleに接続し、ARCHIVELOG_DIRまたはONLINELOG_DIRディレクトリオブジェクトを参照してログにアクセスするためのselect要求を発行します。注: スタンバイデータベース、RDSデータベースインスタンス、または高速リカバリ領域がある環境など、複数のログの場所に格納されているOracleデータへのBFILEアクセスを使用した場合、データベース取り込みおよびレプリケーションは、ARCHIVELOG_DIRおよびONLINELOG_DIRで始まり、ARCHIVELOG_DIR_01、ARCHIVE_LOG_DIR_02などのサフィックスで終わるすべてのディレクトリオブジェクトを問い合せることで、ログを自動的に見つけることができます。データベース取り込みおよびレプリケーションジョブを実行するデータベースユーザーにCREATE ANY DIRECTORY特権とDROP ANY DIRECTORY特権が付与されている場合は、必要に応じてディレクトリオブジェクトを実行時に作成できます。
2 データベース取り込みとレプリケーション のCDCリーダーが、Secure AgentボックスにインストールされているOCIクライアントを使用してログファイルを読み取り、CDC対象のソーステーブルの変更レコードを抽出します。3 4 OracleファイルシステムのOracle REDOログへのBFILEアクセスの設定 REDOログをローカルのOracleサーバーファイルシステムに保存し、BFILEでOracleディレクトリオブジェクトを使用してログにアクセスする場合は、次の設定タスクを実行します。
BFILEアクセスに固有ではない、次の通常のOracleソース前提条件タスクを完了します。
• データベース取り込みとレプリケーション でOracle Call Interface(OCI)を使用してOracleソースデータベースと通信するためにSecure Agentが実行されるLinuxまたはWindowsシステムで、ORACLE_HOME環境変数を定義します。• データベース取り込みとレプリケーション ユーザーに、データベース取り込みとレプリケーション の増分ロード処理に必要なOracle権限があることを確認してください。詳細については、Oracle特権 • • • • 注: データベース取り込みとレプリケーション タスクを作成するときに、選択したソーステーブルのすべてのカラムまたはプライマリキーカラムのみのサプリメンタルロギングを実装するスクリプトを生成するオプションがあります。
• [LOBを含める] チェックボックスを選択しない限り、それらのカラムはキャプチャ処理から除外されます。詳細については、「
Oracleソース 」を参照してください。
さらに、BFILEアクセスの場合は、次の手順を実行して、オンラインログの格納先とのアーカイブログの格納先を設定します。
1 オンラインREDOログの場所を取得するには、次の手順を実行します。
select * from v$logfile;
ログのアーカイブ先を取得するには、次の手順を実行します。
select dest_id, dest_name, destination, status from V$ARCHIVE_DEST;
2 CREATE DIRECTORY ONLINELOG_DIR AS '/u01/oracle/data';
Oracle Database Ingestion接続でリーダーモードを[ARCHIVEONLY]に設定して、アーカイブログからのみ変更を読み取る場合は、ONLINELOG_DIRディレクトリまたはディレクトリオブジェクトを作成する必要はありません。
Oracleデータベースは、指定したディレクトリが存在することを確認しません。Oracleファイルシステムに存在する有効なディレクトリを指定していることを確認してください。
3 select * from all_directories;
4 データベース取り込みとレプリケーション ユーザーに、ONLINELOG_DIRおよびARCHIVELOG_DIRディレクトリオブジェクトへの読み取りアクセスを付与します。以下に例を示します。grant read on directory "ARCHIVELOG_DIR" to "cmid_user ";cmid_user ";
注: ONLINELOG_DIRパスが存在しないか、アクティブなREDOログのパスと一致する場合、データベース取り込みおよびレプリケーションはディレクトリの作成を試みます。ディレクトリオブジェクトを作成するための十分な権限がない場合は、エラーメッセージが発行されます。その場合は、DBAに、正しいパスでディレクトリオブジェクトを作成するよう依頼してください。
5 [BFILEアクセス] チェックボックスを選択します。重要: 複数のログの場所に格納されているOracleデータへのBFILEアクセスを使用した場合、データベース取り込みおよびレプリケーションは、ARCHIVELOG_DIRおよびONLINELOG_DIRで始まり、ARCHIVELOG_DIR_01、ARCHIVE_LOG_DIR_02などのサフィックスで終わるすべてのディレクトリオブジェクトを問い合せることで、ログを自動的に見つけることができます。この機能により、データベース取り込みおよびレプリケーションは、プライマリデータベースとは異なるログの場所、Amazon RDSデータベースインスタンス上のレプリカログ、およびUSE_DB_RECOVERY_FILE_DESTパラメータが指す高速リカバリエリア内のアーカイブログを使用するOracleスタンバイデータベースをサポートします。
必要に応じて、カスタムプロパティpwx.cdcreader.oracle.database.additional BFILEARCHIVEDIR=<directory_object>およびpwx.cdcreader.oracle.database.additional BFILEONLINEDIR=<directory_object>を使用して、ARCHIVELOG_DIR名とONLINELOG_DIR名をオーバーライドすることができます。
データベース取り込みおよびレプリケーションジョブを実行するデータベースユーザーにCREATE ANY DIRECTORY特権とDROP ANY DIRECTORY特権を付与すると、必要に応じてディレクトリオブジェクトを実行時に作成できるようになります。例えば、データベースに複数のアーカイブログとオンラインログの格納先が存在する場合は、ディレクトリオブジェクトを次の命名規則で作成することができます。
• • • • データベース取り込みおよびレプリケーションは、これらの生成されたディレクトリオブジェクトに対してクリーンアップ処理を実行しません。
USE_DB_RECOVERY_FILE_DESTパラメータを使用しており、CREATE ANY DIRECTORY特権およびDROP ANY DIRECTORY特権が付与されていない場合、DBAは次のようなスクリプトを使用して、データベース取り込みおよびレプリケーションジョブを実行する前に、毎日または毎週ディレクトリオブジェクトを作成する必要があります。
create or replace directory ARCHIVELOG_DIR_2024_08_19 as '<DB_RECOVERY_FILE_DEST>/2024_08_19'
USE_DB_RECOVERY_FILE_DESTパラメータを使用しており、データベースユーザーにCREATE ANY DIRECTORY特権とDROP ANY DIRECTORY特権が付与されている場合、ディレクトリオブジェクトは実行時に必要に応じて作成され、14日後に削除されます。これらのディレクトリオブジェクトには、<ARCHIVEDIRNAME>_YYYY_MM_DDという命名規則があります。
ソースとしてのOracle Data GuardデータベースまたはFar Syncインスタンス データベース取り込みとレプリケーション は、Oracle Data Guardプライマリデータベース、論理および物理スタンバイデータベース、およびFar Syncインスタンスから変更データをキャプチャできます。
Far Syncインスタンスは、プライマリデータベースからREDOを受け入れ、そのREDOをOracle Data Guard構成の他のメンバーに送信する、リモートOracle Data Guardの宛先です。
Oracle Data Guardプライマリデータベースまたは読み取りモードで開いているスタンバイデータベースからデータをターゲットに初期ロードできます。
設定
Oracle変更キャプチャの設定は、Oracle Data Guardデータベースタイプによって異なります。
• データベース取り込みとレプリケーション ユーザーに付与します。GRANT SELECT ON "PUBLIC".V$STANDBY_LOG TO <cmid_user >;
プライマリデータベースがAmazon RDS for Oracle環境にある場合は、次のように設定します。
begincmid_user ',
• マウントモードの物理スタンバイデータベース (読み取り専用アクセス権では開かない)の場合は、次のOracle Database Ingestion接続プロパティを設定します。- - - - 注: マウントモードのデータベースでは、ユーザー認証にパスワードファイルを使用できます。最初に、SYSDBA権限をユーザーに付与する必要があります。ユーザーに永続的なSYSDBA権限を付与することを回避するには、プライマリパスワードファイルを物理スタンバイまたはFar Syncインスタンスにコピーしてから、ユーザーのSYSDBA権限を取り消します。パスワードファイルを更新するたびに、このプロセスを繰り返します。
必要に応じて、次の追加の接続プロパティを設定します。
- - 詳細については、「コネクタと接続 」の「Oracle Database Ingestion接続プロパティ」を参照してください。
• 論理スタンバイデータベース の場合、特別な設定タスクは必要ありません。Data Guard環境にないOracleデータベースと同じ方法で設定します。スタンバイからプライマリロールへの遷移
Oracle Data Guard環境では、物理スタンバイデータベースがプライマリロールに遷移する可能性があります。通常、ロールの遷移はフェイルオーバーまたはスイッチオーバーが原因で発生します。遷移中は、物理スタンバイデータベースへのすべてのアクティブな接続が終了します。
物理スタンバイデータベースがプライマリロールに遷移した後にCDC処理を再開できるようにするには、データベース取り込みとレプリケーション が遷移ポイントを過ぎて処理できるように、元のスタンバイシステムでいくつかの接続設定プロパティを調整することが必要になる場合があります。遷移が完了したら、新しいプライマリデータベース環境でパフォーマンスを最適化するようプロパティを再度調整できます。
次の表で、この接続プロパティについて遷移段階別に説明します。
接続プロパティ
遷移前
遷移中
遷移後
RACメンバ
プライマリデータベース上のアクティブなスレッドの数を指定します。
スタンバイデータベースとプライマリデータベースの両方 のデータベース上で一意のスレッドIDを持つアクティブなスレッドの総数を指定します。
例えば、プライマリデータベースがスレッドID 1と2を使用する2ノードのRACデータベースであり、スタンバイデータベースがスレッドID 2、3、4を使用する3ノードのRACデータベースの場合、プロパティ値を4に指定します。
再開ポイントが遷移ポイントを超えるまで進行したら、必要に応じてこのプロパティ値を編集し、新しいプライマリデータベースからの変更データキャプチャのパフォーマンスを最適化します。
CDCのスレッド追跡によるオーバーヘッドを最小限に抑えるため、環境に適した最小値を使用することをお勧めします。
リーダースタンバイログマスク
スタンバイ接続文字列
スタンバイユーザー名
スタンバイパスワード
すべてのスタンバイプロパティを削除します。読み取り専用アクセス用に開いている物理スタンバイデータベースには適用されません。
プロパティは削除されたままです。
これらのプロパティは指定しないでください。これらはプライマリデータベースでは使用されません。
データベース接続文字列
スタンバイデータベースが開かれていない場合、プライマリデータベース用の接続文字列を定義します。
スタンバイデータベースが開かれている場合、スタンバイデータベース用の接続文字列を定義します。
ロールの遷移後にプライマリロールになるデータベース用の接続文字列を指定します。
この接続プロパティが、新しいプライマリデータベースの接続文字列を定義していることを確認してください。
Oracleアーカイブログの保持に関する考慮事項 データベース取り込みとレプリケーション の増分ロードジョブ、および初期ロードと増分ロードの組み合わせジョブは、OracleオンラインREDOログおよびアーカイブREDOログのトランザクションデータにアクセスできる必要があります。ログを利用できない場合、データベース取り込みとレプリケーション ジョブはエラーで終了します。
通常、Oracle DBAは、組織の特定のビジネスニーズとOracle環境に基づいて、アーカイブログの保持期間を設定します。ログを再起動処理に使用できるように、変更キャプチャが停止または潜在的な状態になると予想される最長期間プラス約1時間にわたって、ソースアーカイブログが保持されていることを確認してください。
環境内の現在のログ保持ポリシーが、データベース取り込みとレプリケーション の変更キャプチャ処理に対応するのに十分かどうかを判断するには、次の要素を考慮してください。
• • • • データベース取り込みとレプリケーション ジョブをスケジュールに基づいて実行していますか? そうである場合、どのようなスケジュールですか?• [ソース] ページで、pwx.cdcreader.oracle.option.additional ageOutPeriod=minutes カスタムプロパティが設定されていますか?注: このプロパティは、CDC対象の変更レコードのない未処理のUOWを次の再開ポイントの計算から削除する際の条件となる経過時間を指定します。このプロパティを使用すると、トランザクションが未処理で、UOWが開始されたREDOログが使用できないときにキャプチャ処理をシャットダウンして再開した場合に発生する可能性のあるCDC障害を防ぐことができます。
• • ログのキャプチャ処理を再開する必要があるときにアーカイブログを使用できない場合は、DBAに、アーカイブログを復元して必要に応じて保存期間を変更するよう依頼してください。それ以外の場合は、別の初期ロードを実行してターゲットを再マテリアライズしてから、増分変更データ処理を再度開始してください。ただし、この場合、一部の変更が失われる可能性があります。
PostgreSQLソース データベース取り込みとレプリケーション タスクでPostgreSQLソースを使用するには、最初にソースデータベースを準備し、使用に関する考慮事項を確認してください。
ソースの準備: データベース取り込みとレプリケーション タスクでPostgreSQLソースを使用するには、最初にソースデータベースを準備し、使用に関する考慮事項を確認してください。
Secure Agent システム上 で、オペレーティングシステムに適したODBCドライバをインストールします。
• 1 注: ソースデータベースにマルチバイト文字名のオブジェクト(テーブル名、カラム名、パブリケーション名など)が含まれている場合は、PostgreSQL Unicode ODBCドライバまたはPostgreSQL用DataDirect ODBCドライバのいずれかを使用する必要があります。この要件は、Amazon Aurora PostgreSQL、Azure Database for PostgreSQL - Flexible Server、Cloud SQL for PostgreSQL、およびRDS for PostgreSQLなどのすべてのPostgreSQLソースタイプに適用されます。Unicode互換のODBCドライバを使用しない場合、マルチバイト文字の名前が検出されると、増分ロードジョブは失敗します。
2 注: タスクウィザードの[ソース]ページでpwx.custom.pgsql_odbc_driverカスタムプロパティを設定することにより、データベース取り込みとレプリケーション タスクのこのドライバをオーバーライドできます。
• 1 注: ソースデータベースにマルチバイト文字名のオブジェクト(テーブル名、カラム名、パブリケーション名など)が含まれている場合は、PostgreSQL Unicode ODBCドライバまたはPostgreSQL用DataDirect ODBCドライバのいずれかを使用する必要があります。この要件は、Amazon Aurora PostgreSQL、Azure Database for PostgreSQL - Flexible Server、Cloud SQL for PostgreSQL、およびRDS for PostgreSQLなどのすべてのPostgreSQLソースタイプに適用されます。Unicode互換のODBCドライバを使用しない場合、マルチバイト文字の名前が検出されると、増分ロードジョブは失敗します。
2 [PGSQL]
3 ▪ ▪ ▪ 例:
export ODBCSYSINI=/root/infaagent
PostgreSQLデータベースシステム で、次の設定手順を実行します。
1 このパラメータは、PostgreSQLがログ先行書き込み(WAL)に書き込む情報の量を決定します。論理の設定によって、論理デコードのサポートに必要な情報が追加されます。
Amazon Aurora PostgreSQLまたはAmazon RDS for PostgreSQLソースでwal_levelをlogicalに設定するには、クラスタパラメータグループでrds.logical_replicationパラメータを1に設定します。Azure Database for PostgreSQL - フレキシブル サーバ-の場合、Azureポータルの[サーバーパラメータ]ページでwal_levelパラメータをlogicalに設定します。
Cloud SQL for PostgreSQLソースの場合は、次のアクションを実行します。
a 注: Google Cloudコンソールの[承認済みネットワーク] に必要なIPを必ず追加してください。
b c alter database postgres set default_transaction_read_only = off;database_replica --user=postgres --quiet;password ';
d ▪ cloudsql.logical_decoding 。値をon に設定します。▪ max_replication_slots .値を64 に設定します。▪ cloudsql.enable_pglogical .値をon に設定します。▪ max_wal_senders 。値を64 に設定します。e 2 注: PostgreSQL ODBCドライバは、SCRAM-SHA-256認証方法をサポートしています。PostgreSQL 13では、この認証方法がデフォルトの方法になりました。
3 データベース取り込みとレプリケーション タスクをデプロイして実行するには、ソース接続で、必要な特権を持つデータベースユーザーを指定する必要があります。次の方法でユーザーを作成し、そのユーザーに特権を付与します。- CREATE USER dbmi_user WITH PASSWORD 'password ';schema TO dbmi_user ;
- CREATE USER dbmi_user WITH PASSWORD 'password ' REPLICATION;
Amazon Aurora PostgreSQLソースとRDS for PostgreSQLソースの場合、次の文を使用します。
CREATE USER dbmi_user WITH PASSWORD 'password ';dbmi_user ;
また、pgoutputプラグインを使用する場合は、次のSQL文を使用して、pgoutputパブリケーションに追加するデータベース内のテーブルの所有権を、作成したdbmi_user に付与します。
GRANT CREATE ON DATABASE database TO dbmi_user ;
4 5 CREATE PUBLICATION publication_name [FOR TABLE [ONLY] table_name [*] [,...] | FOR ALL TABLES ];
ターゲットにレプリケートするすべてのテーブルがパブリケーションに含まれていることを確認してください。
6 SELECT pg_create_logical_replication_slot('slot_name' , 'plugin_type' );
ここで、plugin_type はpgoutputプラグインまたはwal2jsonプラグインのどちらかです。
7 重要: すべてのレプリケーションスロットは、すべての同時ジョブで一意である必要があります。
8 9 使用に関する考慮事項: • データベース取り込みとレプリケーション では、任意のロードタイプを使用しているデータベース取り込みとレプリケーション ジョブで、PostgreSQLソースのタイプとしてオンプレミスPostgreSQL、Amazon Aurora PostgreSQL、Azure Database for PostgreSQL - Flexible Server、Cloud SQL for PostgreSQL、およびRDS PostgreSQLがサポートされます。• データベース取り込みとレプリケーション では、任意のターゲットタイプを持つデータベース取り込みとレプリケーション ジョブでPostgreSQLソースがサポートされます。• データベース取り込みとレプリケーション は、Google BigQueryまたはSnowflakeターゲットのみを持つあらゆるロードタイプのCloud SQL for PostgreSQLソースをサポートします。• データベース取り込みとレプリケーション では、ソーステーブルの各行が一意であることを想定しているため、各ソーステーブルにプライマリキーを持たせることをお勧めします。データベース取り込みとレプリケーション は、プライマリキーの代わりに一意のインデックスを許可しません。プライマリキーが指定されていない場合、データベース取り込みとレプリケーション はすべてのカラムをプライマリキーの一部であるかのように扱います。• データベース取り込みとレプリケーション は、データベース取り込みとレプリケーション の増分ロードジョブ、初期ロードと増分ロードの組み合わせジョブでPostgreSQLソースのスキーマドリフトオプションをサポートしますが、次の制限があります。- - データベース取り込みとレプリケーション ジョブは、テーブルパーティションIDが変更されたソーステーブルからのDML変更をキャプチャできません。• データベース取り込みとレプリケーション では、PostgreSQLソースを含む増分ロードジョブで生成されたカラムはサポートされていません。生成されたカラムがソーステーブルに含まれている場合、変更データキャプチャはそれらのカラムを無視し、残りのカラムの処理を続行します。• [ソース] ページの[詳細] で[LOBを含める] を選択した場合、データベース取り込みとレプリケーション ジョブで、PostgreSQL BYTEA、JSON、JSONB、TEXT、およびXMLカラムからデータをレプリケートできます。サポートされるターゲットタイプは、ロードタイプによって異なります。
- - - タスクウィザードの[ソース] ページで、pwx.custom.pgsql_enable_lobsカスタムプロパティをtrueに設定した場合、データベース取り込みとレプリケーション の増分ロードジョブ、初期ロードと増分ロードの組み合わせジョブは、長さ制限のないTEXT、XML、BIT VARYING、およびCHARACTER VARYINGカラムからデータをレプリケートできます。増分ロードジョブ、初期および増分ロードジョブも常に、BYTEA、JSON、およびJSONBカラムからデータをレプリケートします。
LOBカラムデータは、LOBタイプとターゲットタイプによって異なるバイト制限よりもサイズが大きい場合、ターゲットに書き込まれる前に切り詰められます。詳細については、
ソースの設定 を参照してください。
• • データベース取り込みとレプリケーション では次のPostgreSQLデータ型はサポートされていません。- - - - - - - - 増分ロードジョブ、初期ロードと増分ロードの組み合わせジョブの場合、データベース取り込みとレプリケーション では、初期ロードジョブでサポートされていないものに加えて、次のPostgreSQLデータ型はサポートされていません。
- ▪ ▪ ▪ ▪ ▪ ▪ ▪ - データベース取り込みとレプリケーション ジョブは、これらのデータ型を持つカラムにはデプロイしたりnullをプロパゲートしたりすることはできません。
サポートされているPostgreSQLデータ型からターゲットタイプへのデフォルトのマッピングについては、
デフォルトデータ型のマッピング を参照してください。
• SAP HANAおよびSAP HANA Cloudソース データベース取り込みとレプリケーション タスクでSAP HANAおよびSAP HANA Cloudソースを使用するには、最初にソースデータベースを準備し、使用に関する考慮事項を確認してください。
ソースの準備: • 1 ダウンロードするファイルが最新バージョンであることを確認します。ファイルのダウンロードで問題が発生した場合は、SAPカスタマサポートにお問い合わせください。
2 <Secure Agent installation directory >/ext/connectors/thirdparty/informatica.hanami
3 • データベース取り込みとレプリケーション ユーザーを作成します。管理者権限を持つユーザーとしてソースデータベースに接続し、次の文を実行します。CREATE USER dbmi_user password "<password >" NO FORCE_FIRST_PASSWORD_CHANGE;
この文は、デフォルトの権限を使用してデータベースにユーザーを作成します。これにより、基本的なデータディクショナリビューを読み取ることができ、必要なCDCオブジェクトをユーザー自身のスキーマに作成することができます。
• データベース取り込みとレプリケーション タスクをデプロイして実行するには、ソース接続で、次のシステムビューからメタデータやその他の情報を読み取る権限を持つデータベース取り込みとレプリケーション ユーザー(dbmi_user )を指定する必要があります。- - - - - - - • - dbmi_user のPKLOGおよびシャドー_CDCテーブルに行を書き込むトリガの場合は、dbmi_user のスキーマに対するINSERTアクセス権を、ソーステーブルのスキーマを所有するユーザー( schema_user )に付与します。GRANT INSERT ON SCHEMA dbmi_user TO schema_user ;
- GRANT TRIGGER ON SCHEMA schema_user TO dbmi_user ;
この文は、スキーマ内のすべてのテーブルに対するトリガアクセス権を付与します。
- or -
GRANT TRIGGER ON database .table_name TO dbmi_user ;
この文は、特定のソーステーブルに対するトリガアクセス権を付与します。選択した少数のテーブルからデータをキャプチャする場合は、この文を使用します。CDC対象のソーステーブルごとに、付与を繰り返します。
• GRANT SELECT ON SCHEMA schema_user TO dbmi_user ;
この文は、スキーマ内のすべてのテーブルに対するSELECTアクセス権を付与します。
- or -
GRANT SELECT ON database .table_name TO dbmi_user ;
この文は、特定のソーステーブルに対するSELECTアクセス権を付与します。データを読み取るソーステーブルごとに、この付与を繰り返します。
• [詳細接続プロパティ] フィールドに次のプロパティを入力します。encrypt=true&validateCertificate=false
使用に関する考慮事項: • データベース取り込みとレプリケーション は、初期ロードジョブと増分ロードジョブではRed Hat LinuxまたはSUSE Linux上のSAP HANAおよびSAP HANA Cloudソースをサポートしますが、初期ロードと増分ロードの組み合わせジョブではサポートしません。• データベース取り込みとレプリケーション の増分ロードジョブは、最大120文字の長さのテーブル名をサポートします。• • データベース取り込みとレプリケーション では、初期ロードジョブまたは増分ロードジョブの場合、SAP HANAソーステーブルにプライマリキーは必要ありません。• データベース取り込みとレプリケーション は、ターゲットのデフォルトのカラムデータ型にマッピングされている場合でも、次のソースデータ型をサポートしていません。- - - - - - - - データベース取り込みとレプリケーション ジョブは、これらのデータ型を持つカラムにはnullをプロパゲートします。
注: ALPHANUM、BINTEXT、CHAR、およびCLOBデータ型は、SAP HANA Cloudでは使用できません。
SAP HANAデータ型からターゲットデータ型へのデフォルトのマッピングについては、
デフォルトデータ型のマッピング を参照してください。
• データベース取り込みとレプリケーション では、ソースデータベースに次のテーブルが必要です。- - - スキーマ >。<テーブル名 >_CDCテーブル。トランザクションIDやタイムスタンプなどのメタデータとともに、ソーステーブルからキャプチャされた更新の操作前のイメージと、挿入、更新、および削除の操作後のイメージが含まれます。変更がキャプチャされるソーステーブルごとにシャドーテーブルが存在する必要があります。また、データベース取り込みとレプリケーション は、AFTER DELETE、AFTER INSERT、およびAFTER UPDATEトリガを使用して、各ソーステーブルのDML変更の操作前のイメージと操作後のイメージを取得し、変更のエントリをPKLOGテーブルとシャドー_CDCテーブルに書き込みます。データベース取り込みとレプリケーション は、処理された挿入、更新、削除行ごとに、SAP HANAシーケンス値をPKLOGテーブルとシャドー_CDCテーブルにも書き込みます。シーケンス値は、CDC処理中にシャドー_CDCテーブルの行をPKLOGテーブルの行にリンクします。
タスクをデプロイすると、データベース取り込みとレプリケーション は、PKLOG、PROCESSED、およびシャドー_CDCテーブル、トリガ、およびシーケンスが存在することを検証します。これらのアイテムが存在しない場合、デプロイ操作は失敗します。
• [ソース] ページから、PKLOG、PROCESSED、シャドー_CDCテーブル、トリガ、およびシーケンスを作成するCDCスクリプトをダウンロードまたは実行できます。SAP HANA Database Ingestionプロパティで[トリガプレフィックス] の値を指定した場合、生成されたトリガの名前の先頭にはプレフィックス _が付きます。デフォルトでは、トリガはアプリケーションのシステムユーザーをキャプチャします。代わりにトランザクションユーザーをキャプチャする場合は、CDCスクリプトをダウンロードし、スクリプト内の「APPLICATIONUSER」の箇所をすべて「XS_APPLICATIONUSER」に置き換えます。例えば、AFTER DELETEトリガでこの置換を行うと、アーカイブプロセスに関連する削除を識別して除外できます。
• • • [ログのクリア] フィールドで、0より大きい値を指定します。デフォルト値は14日間で、最大値は366です。0の値を指定すると、ハウスキーピングは無効になります。ハウスキーピングは増分ロードジョブの実行中に行われます。複数のジョブが異なるテーブルに対して実行されている場合、各ジョブはPKLOGテーブルと、そのジョブに対してのみ定義されているシャドー_CDCテーブルに対してハウスキーピングを実行します。ジョブからソーステーブルを削除しても、対応するシャドー_CDCテーブルのパージは行われません。
• データベース取り込みとレプリケーション タスクのデプロイで、ソーステーブルに長さの長い複数カラムのプライマリキーが含まれている場合、デプロイに失敗することがあります。この場合、プライマリキーの長さを短くしてから、タスクを再度デプロイしてください。Teradataソース データベース取り込みとレプリケーション タスクでTeradataソースを使用するには、最初にソースデータベースを準備し、使用に関する考慮事項を確認してください。
ソースの準備: 使用に関する考慮事項: