Release Notes
This document contains important information about Informatica MDM - Product 360 Version 10.5 Do not upgrade to this release without carefully reading the relevant sections. If you skip a previous major release (i.e., Product 360 10.1) you may want to consult the corresponding release notes document from this one as well.
Informatica MDM - Product 360 – Release Notes Version 10.5 (June 2022)
Preface
Informatica introduces the latest evolution of its product information management application:
Informatica MDM - Product 360 (Version 10.5)
Informatica's strategy is to strengthen our customers with our leading multi-domain MDM solution for consolidating all master data and leveraging the potential of relationship insights across it. For that, Informatica offers trusted master data-fueled applications for dedicated use cases, industries, and roles. One important use case is around enabling collaboration for new product introduction across all channels. Product 360 10.5 caters to these product information and experience management use cases as a vital component of our master data management offerings.
Product 360 provides a unified user experience, built-in data quality engine, business process management, search, and metadata. All inherited from the MDM architecture it's built on. This allows you to start smart and grow fast, making it easy to adapt to both, market changes and the competitive landscape.
With this latest release we continue to deliver innovations which support your use cases and mark a true major release in June 2022. Informatica MDM - Product 360 10.5 comes with a rich set of new capabilities to further help you effectively manage product information and will also help you deliver more effective product content to customers across your digital sales channels. While delivering a huge number of features toward business user experience, an equal amount of new possibilities can be found in the underlying platform services and supported use cases for enterprise scalability.
We hope you enjoy this release and all the great new things that come with it. The key innovations are:
Automated content enrichment with AI-driven brand extraction derived from your product descriptions using the CLAIRE™ recommendation service
Real-time translation API integrations for automated content enrichment using the CLAIRE™ recommendation service
Increased data governance providing possibilities to dynamically filter lookup values on characteristics based on other field attributes of the product
Enhanced search query management through the web user interface, including new capabilities to bring user experience to the next level
User Experience
Search Query enhancements in web UI
In Product 360 web UI, it is now possible to configure and manage saved search queries. With all these new capabilities, users can enhance the search queries and have efficient access to any data through improved usability. By popular demand, users can also now reuse a single saved query in multiple instances which gives the greatest flexibility to do real-time database searches.
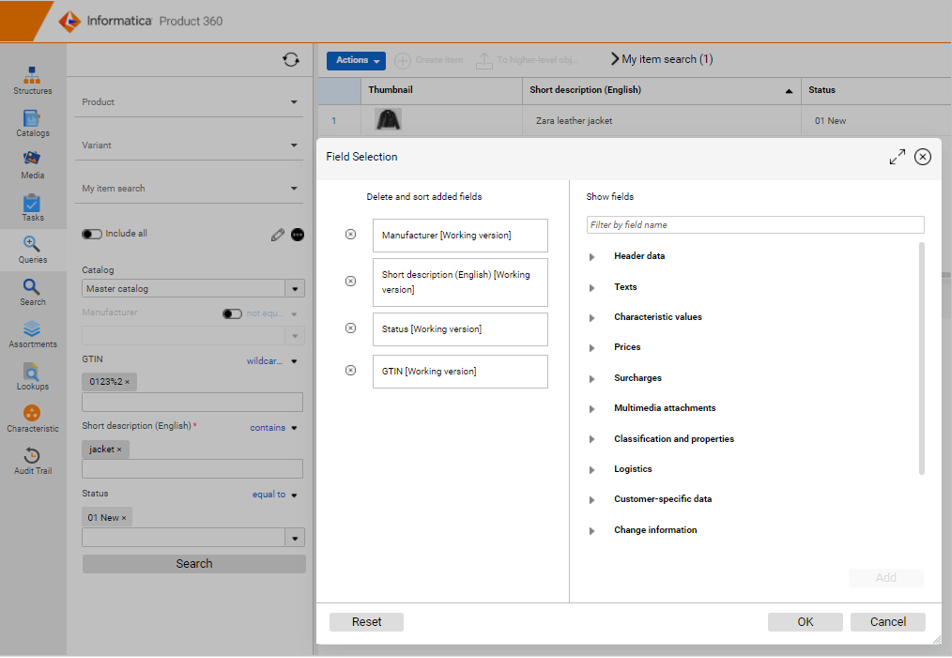
Configure fields within search queries
Clicking the pencil icon inside Queries, a field selection dialog appears, and the user can add or remove fields depending on how they want to fine-tune their search query. This includes the full flexibility to search across entities by expanding the tree and using transition fields in the search. It is also possible to search across dimensions, as the qualifiers are not mandatory, this allows to find a value independent of e.g., the language, channel, or any other qualifying key.
Also, the data type of the search fields is now being respected which increases the usability, e.g. a date picker and validations are being offered for date fields.
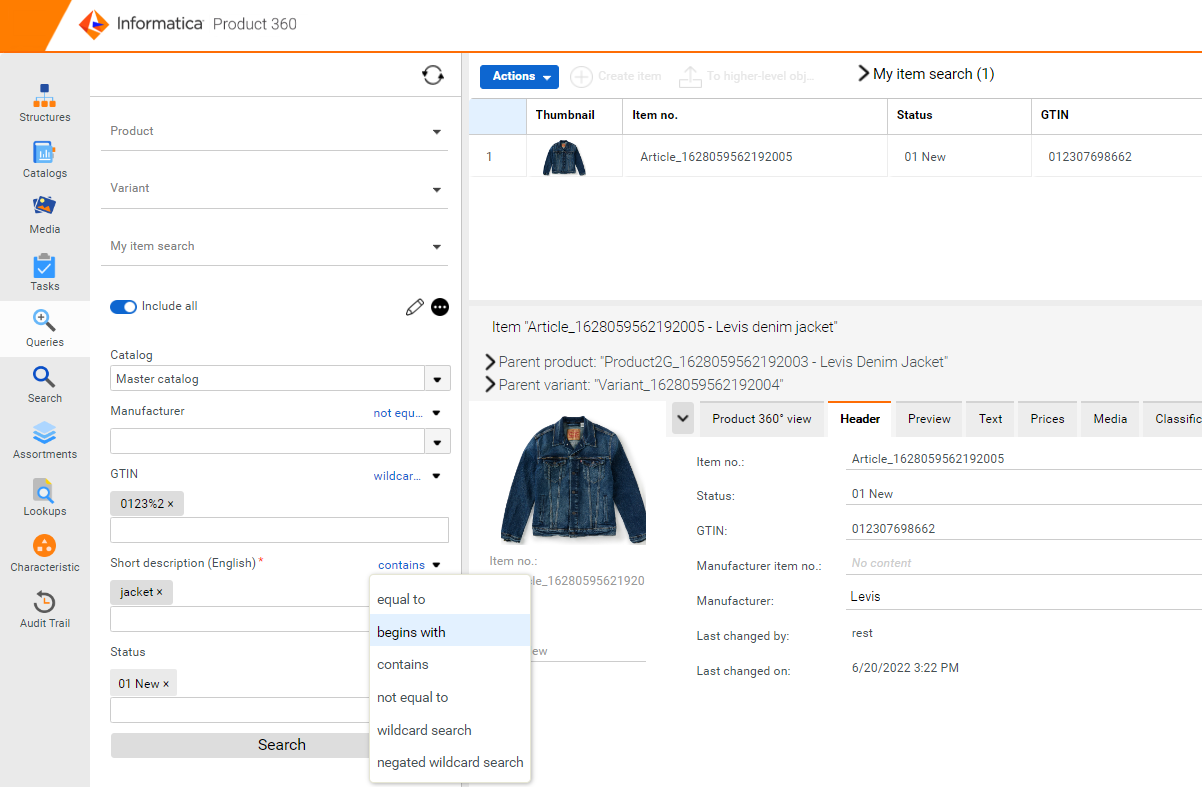
Select and switch comparators for fields
A new functionality to increase flexibility while working with search queries has been introduced. This enables all users to tailor field-based searches to their needs. Now, users can change the comparators on the web UI and choose the comparison logic of their choice, depending on the field. For example, a "contains" search can be altered to "begins with" instead.
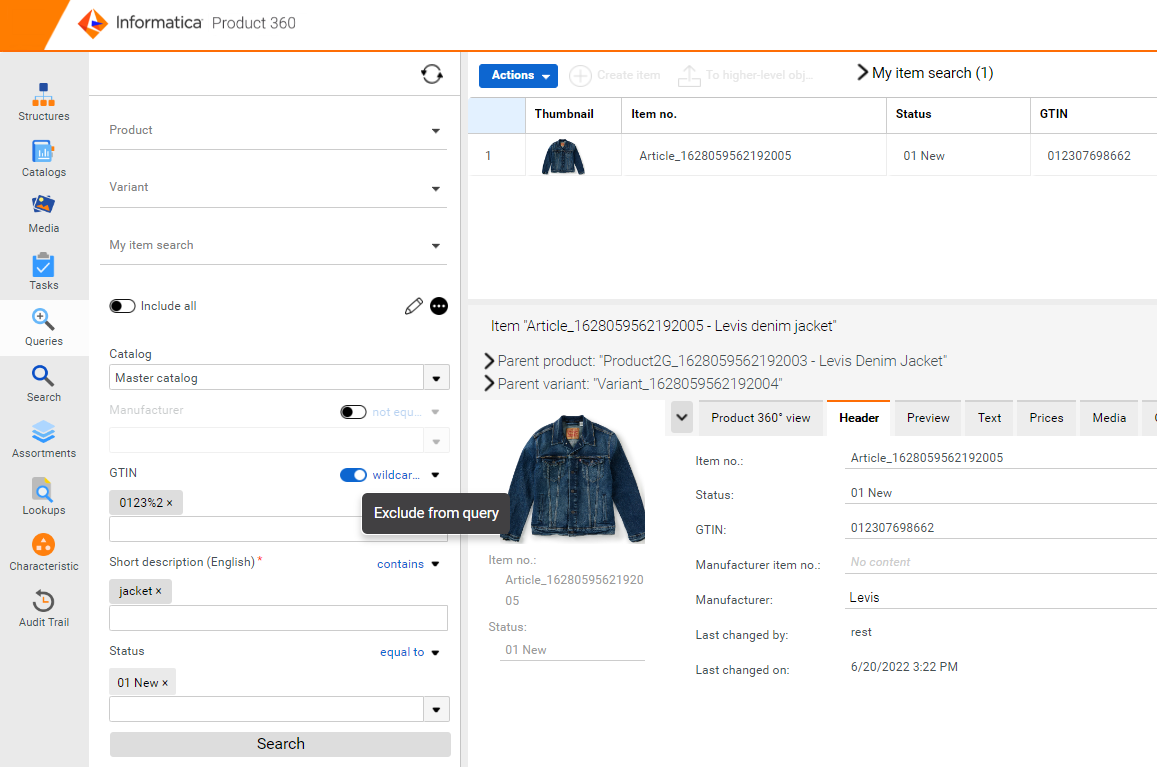
Ignore fields and use a single query for multiple searches
A new functionality that enables all users to fine-tune field-based searches by temporarily toggling individual fields on or off within the query has been introduced. The existing behavior considers also empty fields and searches for data without value. With the new functionality to easily ignore fields the flexibility of being able to reuse a single query for different granular use cases is being improved. It is also possible to enable/disable all the fields with a single click on top of the query and toggle the specific fields that one needs for their search to provide a more effective configuration experience.
Important information
All fields are enabled by default every time a query is loaded, and the individual toggle preferences are not meant to be stored
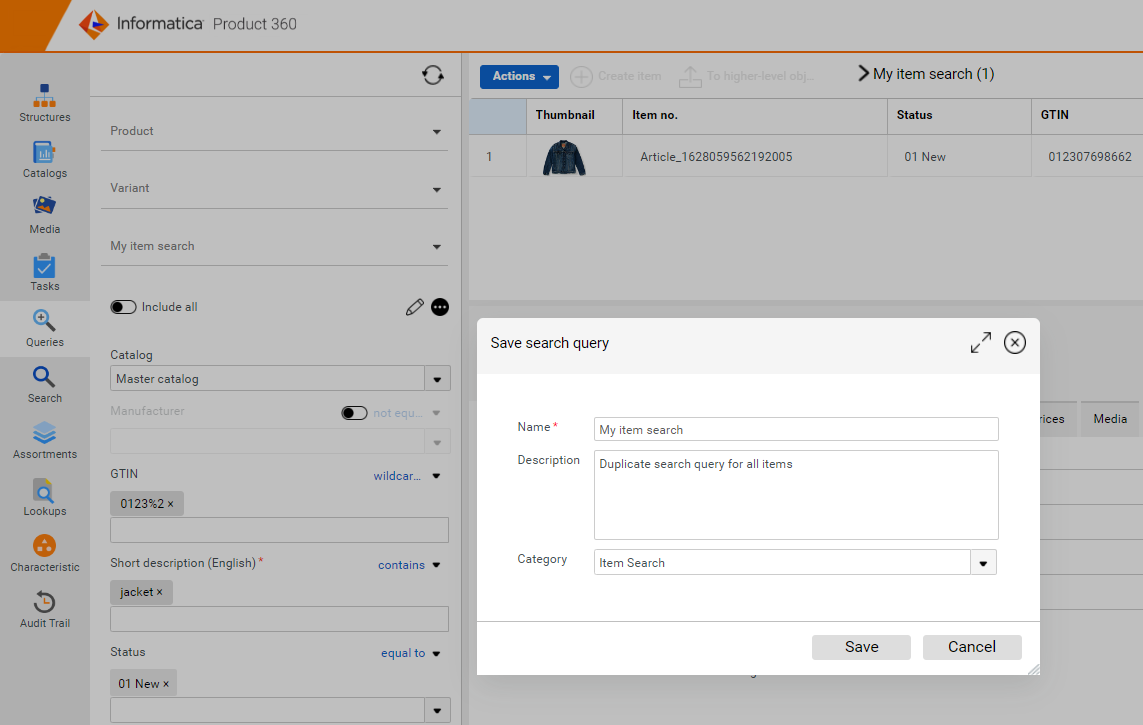
Save Query or create a new query using 'Save as'
Users can save all the changes to a query by clicking on 'Save' from the menu, when fields are added or removed within the query, or when comparators are changed for any of the fields.
Clicking on 'Save as' will enable users to make use of existing search queries and create a new query with a new name, description, and category. Users can then use the new query and modify the search parameters with full flexibility.
Delete Query
Users can now delete queries from web UI by opening the query and clicking on 'Delete' from the menu.
CLAIRETM recommendation services
Real-time translation service integration
Introducing the latest CLAIRE integration to Product 360. With the CLAIRE recommendation services accelerator, it is now possible to seamlessly integrate Product 360 with real-time translation API providers such as Google Translate. This new capability lifts content enrichment processes to the next level and significantly improves your international go-to-market efforts. The accelerator comes with a ready-built integration for Google Cloud and can be enhanced to tailor your real-time translation API service of choice. Any language-specific field can be taken up as source and the translated content in your desired target languages will be presented in a landing table for further adjustments by the users.
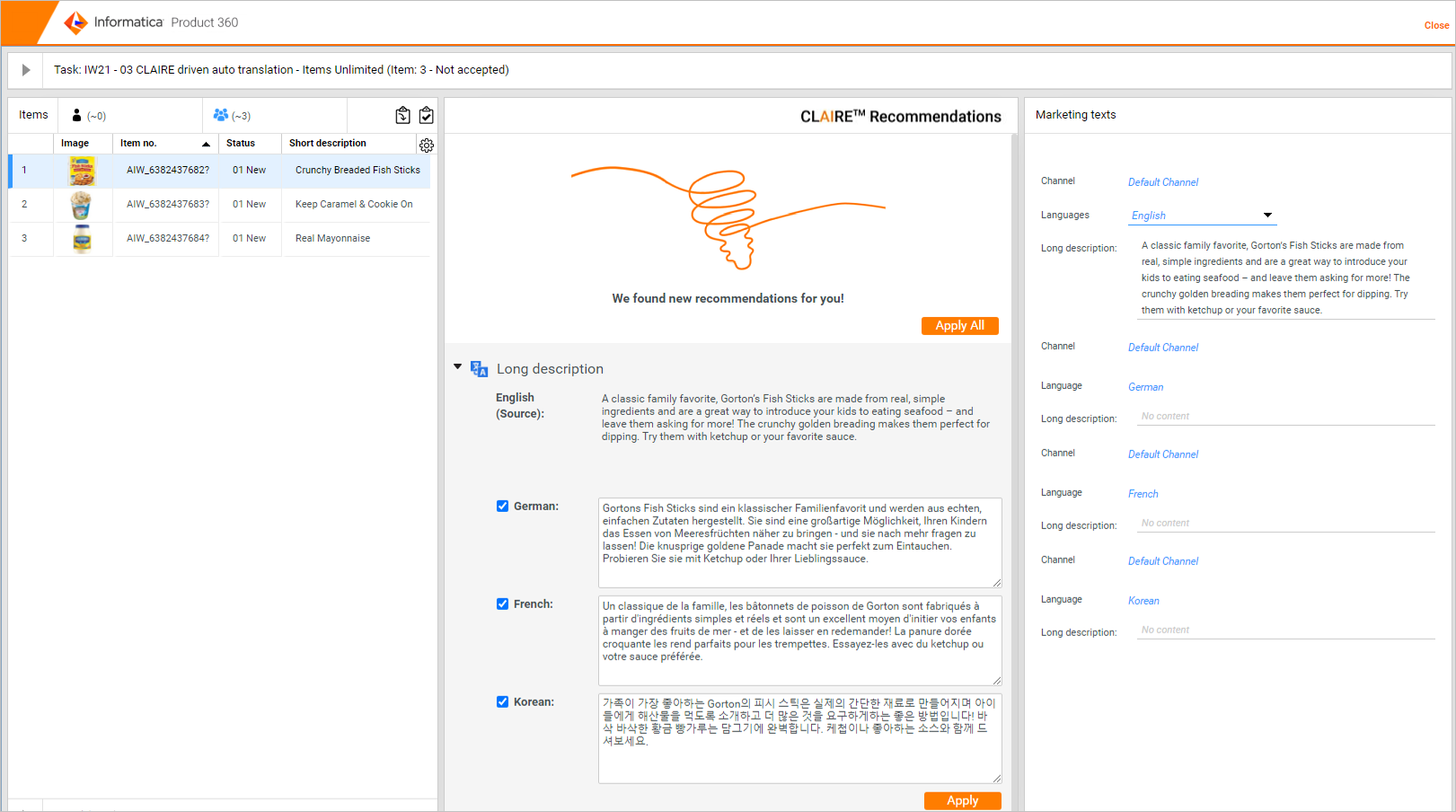
Besides this direct business user support, the same integration can be leveraged in batch via DQ rule configurations including flexible parameters to control if a new translation should be carried over or not. Further details on setup and usage can be found in the documentation shipped with the accelerator package of the release.
Brand extraction machine learning model
As additional CLAIRE integration to Product 360, it is now possible to follow a machine learning approach to automatically extrapolate brand names from product descriptions and fill the corresponding product field with it. The accelerator comes ready-built and doesn't require complex manual tuning to get you started. All that is needed is to generate a model from within Product 360 trained with existing product descriptions and brand names. It can then be used to auto-suggest brand names to be carried over into the desired field of the product. The "CLAIRE Recommendations" panel for Flex UIs has been enhanced accordingly to allow for business users to take advantage in a convenient fashion supporting you with those next-gen content enrichment efficiency improvements.
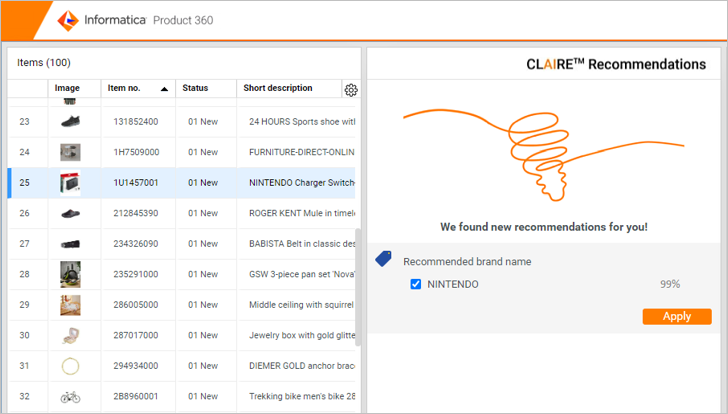
Further details on setup and usage can be found in the documentation shipped with the accelerator package of the release.
If you used the CLAIRETM Accelerator before please consult the "Migration Guide from 10.1 to 10.5" chapter in the Accelerator documentation.
Dependent lookups for Characteristics and value providers
This new functionality adds a whole new dimension to Characteristics and enhances the ease of usage of lookups while adding characteristic values on a record. Configuring dependent lookups and value providers within Characteristics helps the user to choose only from a filtered set of values instead of the entire lookup list for the characteristic fields associated with it.
Dependent lookups
Introducing a new tab named 'Referenced values' in the web UI for each of the lookup values within a lookup list. Users can now configure and manage dependencies between individual lookup values from different lists by adding references between them via this tab. There are two tables introduced within it, one to include specific values as dependent values from another lookup (whitelisting use case) and the other to exclude specific values from another lookup thereby including all other values not explicitly mentioned (blacklisting use case).
Four buttons are displayed on top of each of these tables to manage the dependent values
Create lookup value reference
 : Add one or more reference values to the selected lookup value in context.
: Add one or more reference values to the selected lookup value in context.Remove referenced lookup value
 : Delete one or multiple selected reference values from the list in the table
: Delete one or multiple selected reference values from the list in the tableShow referenced lookup value
 : Navigate to the selected reference value from the table and directly access the details of it
: Navigate to the selected reference value from the table and directly access the details of itFilter referenced lookup values
 : Filter the values in the table by various parameters to easily find an existing referenced value
: Filter the values in the table by various parameters to easily find an existing referenced value
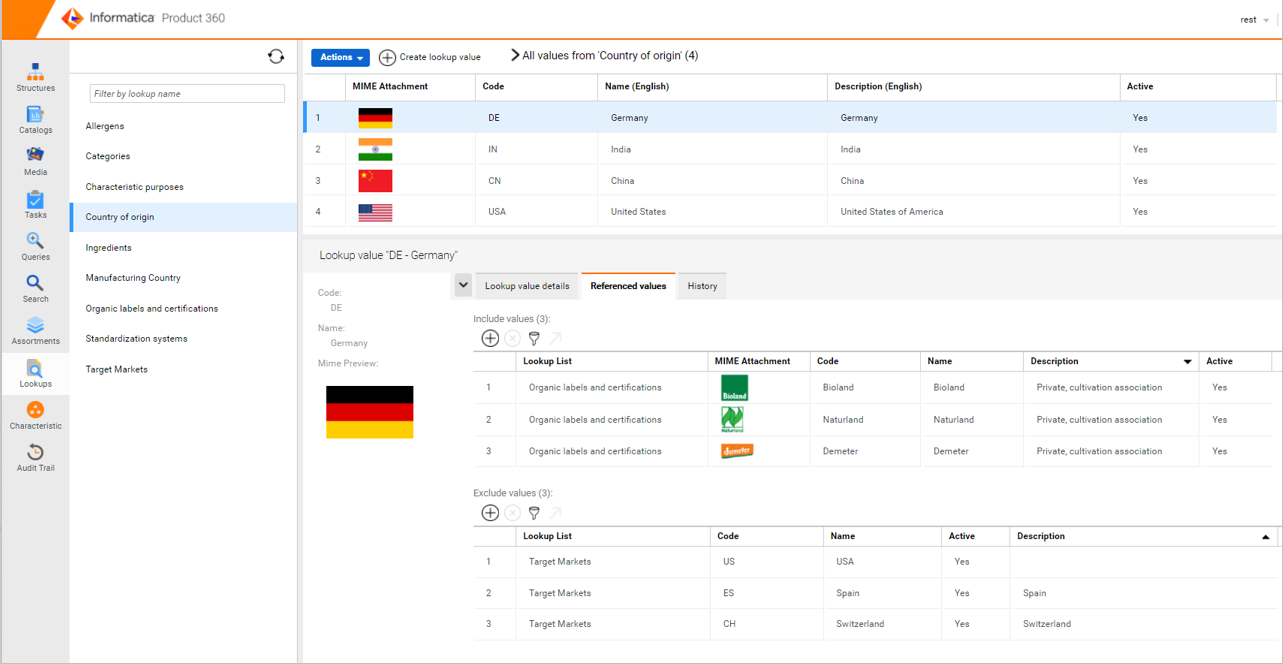
Clicking on 'Create lookup value reference' will lead the user to a window to navigate to the list of all lookups by default. They can then select one or more values from a lookup and add them as referenced values.
Users can add referenced values from a lookup either to the 'Include values' table or 'Exclude values' table at a time. However, it is not possible to mix between the two tables for the same lookup list.
Characteristic value providers
In order to have the characteristic model adhering to the referenced values configuration, users can now set up value providers directly within the characteristics model. Use the following value providers to define the dependencies between the lookup values:
Lookup of parent characteristic
Filters the lookup values based on the selected parent characteristic if it contains referenced values that match the lookup list of it.
Lookup of sibling characteristic
Filters the lookup value based on the selected sibling characteristic if it contains referenced values that match the lookup list of it.
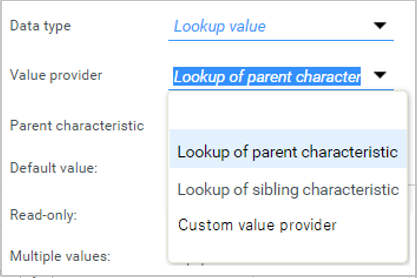
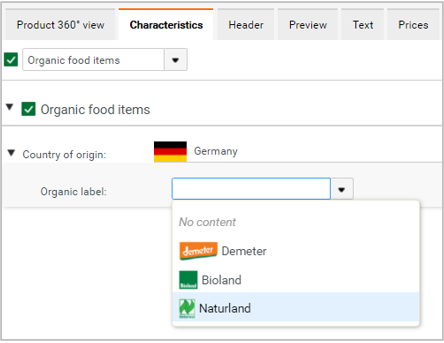
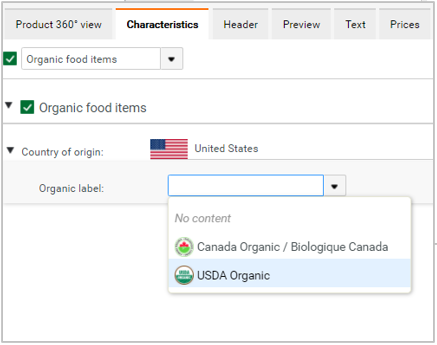
Example
Consider two lookup lists - 'Country of origin' and 'Organic labels and certifications'. Some values from 'Organic labels and certifications' are added as dependent values to 'Germany' from the 'Country of origin' lookup list shown above. Within Characteristics, 'Organic label' field is set to show values based on the parent characteristic 'Country of origin'. Now, the user can see only a subset of values for 'Organic label' dependent on the value selected for 'Country of origin' despite of having lot more values in the associated lookup list overall.
Custom value provider
In addition, it is also possible to contribute a customized value provider implementation via the CharacteristicValueProvider extension point. An SDK example has been added to this release to get a better idea of these enhancements. Customized value providers enhance the out-of-the-box possibilities and can for example filter lookup value lists based on the structure group and item is classified into, etc. Please refer to the customizing guide in the chapter "How to register and use a characteristic value provider with parameters" on how to use the value provider extension point for more information.
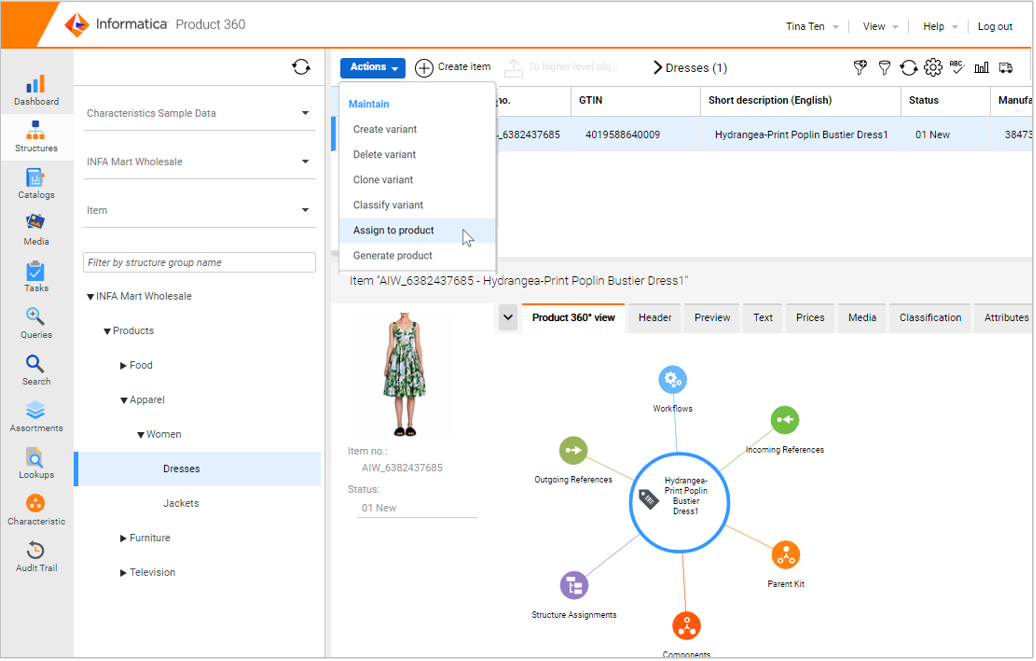
Assign items to products/variants or generate a product/variant directly in the web UI
Two new menu entries for Items and Variants have been introduced to the web UI to increase the efficiency when working with a multi-tier product paradigm.
Assign to product/variant
This functionality allows selecting one or multiple items/variants and choosing a parent product for them all in one go. In the case of an already existing assignment, it can be chosen to move the item/variant to the new product.
Generate product/variant
This functionality allows the generation of a parent product/variant based on one selected item or variant. Similar to the functionality in the Desktop UI relevant fields will be copied to the product/variant as well.
These menu entries are available in the Master catalog and for items as well as variants. The behavior and permission of these actions are similar to the functionality known within the Desktop UI already.
Provide additional confirmation for entire catalog merges
To further improve the user experience working with merge functionality, an additional confirmation pop-up has been introduced before a full catalog is merged. In instances where no records are selected before initiating the merge action, 'Full catalog' option is selected by default and there are high chances that the user accidentally merges an entire catalog that cannot be reverted. With this new update, business users can furthermore make sure of the full catalog merge.
Global exclusion of user groups in task view of web UI
If all users in a system setup share a common user group for proper rights distribution the node "Users of my user group" within the task view might become polluted. Hence, a new property "taskTree.includeGroups" has been introduced to the webfrontend.properties to allow the global exclusion of certain user groups from being used to fill this node with users.
Escalation process for workflow tasks
As the idea of workflow tasks is to have them permanently active and objects simply flowing through them with their own independent lifecycle, the escalation of a whole workflow task is not a common practice or use case. Still, we have found some customer cases where the project design demanded to set the deadline or escalation date on workflow tasks. Hence, we've implemented a simplified escalation process for workflow tasks on the task level. If the deadline or escalation date is met, all objects currently included in it will be directly assigned to the substitute/responsible person and the deadline/escalation date will be reset to keep the workflow task clean for the next incoming objects.
There is no email notification about escalations and the escalated workflow task assigned to the responsible person will get its date reset only after the background job for escalated tasks is being executed.
Further note: If you follow the best practice implementation with the STEP workflow accelerator we ship with the software, you will now have another method for escalations by using classic tasks in the workflow. See chapter “Step workflow accelerator enhancements” in this document.
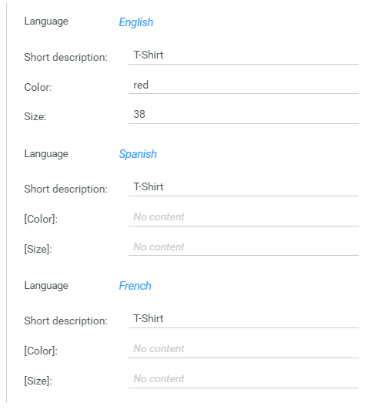
Fallback language for attribute names in detail tabs and Flex UI
In detail views and within the Flex UI, usually, the field name is displayed as the label of a value. For attributes, the attribute name in the corresponding language is displayed. If the attribute name might be missing for some language, the attribute name in the key language will now be displayed in brackets so that you can better distinguish between the attributes:
Platform Enhancements
Media Asset Management enhancements on Informatica Cloud
With Product 360 version 10.5 we enhanced the accelerator package with some basic Digital Asset Management (DAM) functionalities.
Important information about this package:
Designed with a focus on Product 360 Cloud Edition
Based on the Product 360 BPM workflow engine ActiveVOS
Detailed documentation and workflows are part of the accelerator package (section: "Informatica BPM Accelerator")
New capabilities introduced with the package:
Mass upload of digital assets via hotfolder
Creation of derivatives
Configuration of DAM settings
This accelerator package has been designed primarily for Product 360 Cloud Edition deployments and usage Customers not running Product 360 inside the Informatica Cloud may use this project and modify it to their needs. However, it is not officially under Informatica's standard support outside the Informatica cloud. In general, the accelerator offers an alternative approach to handling key DAM use cases without using the Media Manager component of Product 360.
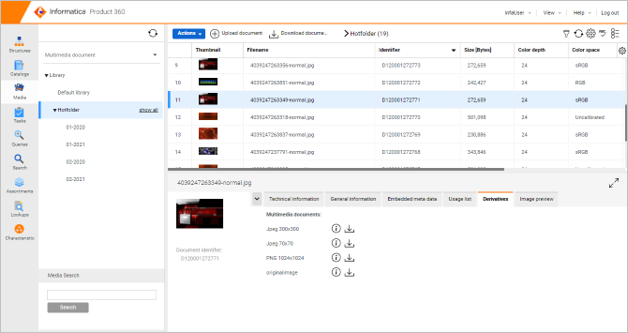
Digital Asset Management hotfolder
The DAM hotfolder enables Cloud Edition customers to upload new assets directly into their blob storage. We are supporting Amazon AWS S3 blob storage as well as the Microsoft Azure blob storage.
Important information
This hotfolder functionality works only for the asset provider "HMM", which is the default in the Cloud Edition settings.
Digital Asset Management configurator
With the Asset Management configurator, you can directly modify the following settings:
Main settings
Versioning behavior (versioning or overwrite)
Property fields
Derivatives for images
Important information
This functionality works only for the asset provider "HMM", which is the default in the Cloud Edition settings.
Digital Asset Management event listener (derivatives)
This BPM (AVOS) project enables Product 360 Cloud Edition customers to create derivatives for digital asset image files via converting them with ImageMagick. This functionality works only for the asset provider "HMM", which is the default in the Cloud Edition settings.
Important information about this package:
Create event supported
Modify event supported
Creating derivatives
Beta functionality for public access of derivatives
Auto assignment supported
This project can be enhanced by Informatica Professional Services or an implementation partner
Further Media Asset Management enhancements
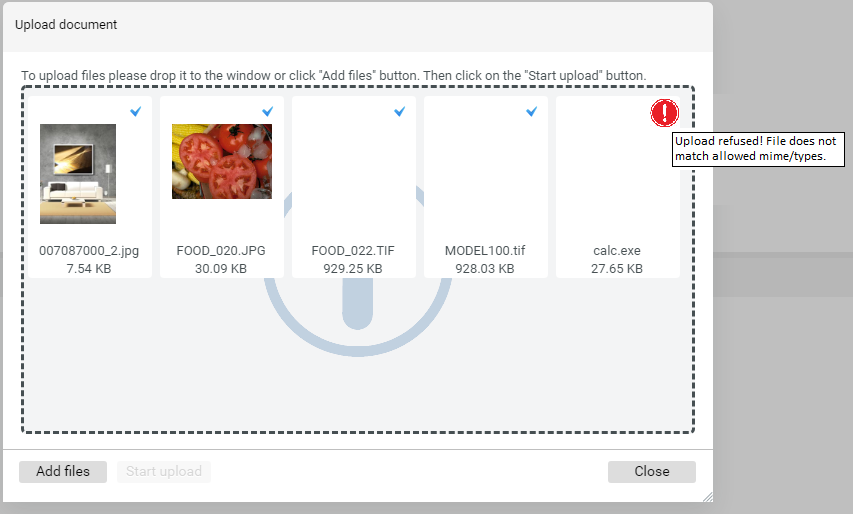
Filter for digital asset MIME type(s)
It is now possible to filter file types allowed for upload of media assets through the web UI by MIME type definition. This ensures that only expected file formats are picked up for consumption. The allowed MIME types can be maintained in plugin_cutomization.ini via the property com.heiler.ppm.web.common/media.filter.accepted.mime.types.
|
Key |
Value |
Description |
|
com.heiler.ppm.web.common/media.filter.accepted.mime.type |
* |
Accept all MIME Types |
|
image/png, image/jpeg, image/gif, image/tiff, application/pdf |
List of allowed MIME types separated by comma |
If a user tries to upload a file that is not allowed the upload for this specific file will be blocked.
Default MimeFilter value
By default, this section is disabled in the plugin_customization.ini file, so every file is allowed to not break existing setups.
Separate post-import trigger for auto-assignment and auto resolution
In previous releases, there was only one trigger (Assignment.postImportMode.activated) in the hmm.properites which turns on/off the post-import mode for auto-assignment and auto-resolution at the same time. From now on it is replaced with the following two triggers, so that users can separately turn on/off the post-import mode for the desired assignment mode. The default value for both settings is false. Administrators must know that activating the post-import mode for the auto-assignment may cause a performance reduction since it searches each imported object identifier (e.g., item number) as name segment of media asset in the Media Manager database for an auto assignment which by its nature comes with a certain overhead to the default setup of Product 360.
# Parameter for the auto assignment by which the media assets are firstly uploaded in Media Manager then the catalog information is imported in PIM Core# Turn on or off the post import mode for auto assignment# !!!ATTENTION!!!: be careful to activate this setting which might cause a performance problem since it searches each imported object identifier (e.g., item number)# as name segment of media asset in the media manager database for auto assignment.AutoAssignment.postImportMode.enabled=false# --------------------# Parameters for the reference assignment by which the media assets are firstly uploaded in Media Manager then the catalog information is imported in PIM Core## Turn on or off the post import mode for reference assignmentReferenceAssignment.postImportMode.enabled=falseStep workflow accelerator enhancements
With Product 360 10.1 we have released a new Business Process Management project called "StepWorkflow". And with version 10.5 we have further improved and enhanced the functionality and flexibility of it with new out-of-the-box steps:
Send emails from a workflow
Use classic tasks with escalations, deadlines, and emails
Configure dynamic user or user group names
Start another workflow from the current workflow
Trigger into the middle of a workflow (continuing a workflow)
Set rules to be ignored for data quality channels
New Urn Mapping
The URN mapping "urn:workflow.resource.project:" contains the name of the project (AVOS catalog) where the customer-specific mapfile and workflow files can be stored. So, the recommendation is to create a new project (i.e., "MyComanyNameResources" and store the customer-specific files in that project.
New examples
We also enhanced the example projects to get a better idea of these enhancements. The added examples can be found under 10 to 13:
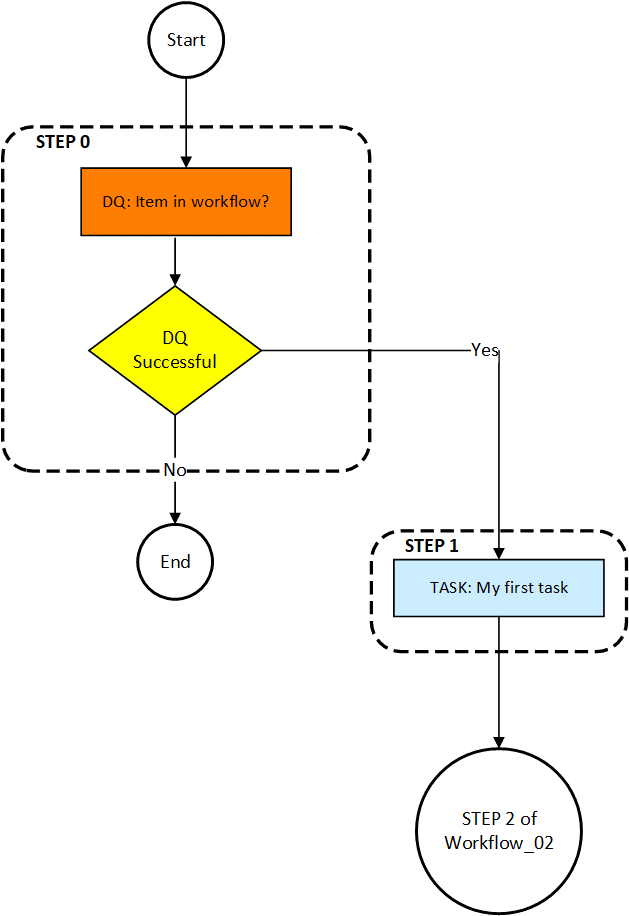
The eleventh workflow puts items into a workflow task called “My first task”. The first step checks whether the URN value for workflow_11.active is true, if not it will be put into the task. The second step checks to see if the affected items have a current status of 100, or “01 New” on most systems. If not, the items will not go into the task. The third step updates the current status of the items to 200. The fourth step puts the item in the task.
The twelfth workflow puts items into a workflow task called “Contact external team”. The first step checks whether the affected item is already in this workflow, if not it will be put into the task. The second step puts the items in the “Contact external team” task. The workflow then stops until it is triggered again by an import, export, or entity change. Once the workflow is triggered again, it moves to an approval task. Items, that are approved, get merged, and items that are rejected just end their workflow. Any items that fail to merge go into a “Failed to Merge” task.
The thirteenth workflow puts items into a workflow task called “My first task” and then to another workflow. The first step checks whether the affected item is already in this workflow, if not it will be put into the task. Once the items are finished in the task, they will move to another workflow at a specific step.
Sanity workflow
The StepWorkflow package now also includes a sanity process to check whether all configurations are fine. The sanity workflow contains three main sections:
URN check: Verifies that urn values required for StepWorkflow exist. It does this based on the values in the config file with the "urn" tag. It verifies they each exist, and the test is considered SUCCESS if and FAILED if it doesn’t.
Workflow map files: Goes through the StepWorkflow.map file and verifies that it can access each workflow file in the map file. It also verifies that the workflow identifier in the map file matches the one in the workflow file.
Access to Product 360. The config file has to get field and update field descriptor values to verify the connection to Product 360. First, it does a GET and verifies the response. Then it uses the same value to do a POST. Using the same value makes sure nothing is changed for the sanity test but also verifies the connection.
The sanity test also allows for a task to be created and/or an email sent out. For the task and email, the sanity test is labeled a SUCCESS if no tests fail. Otherwise, it is considered FAILED.
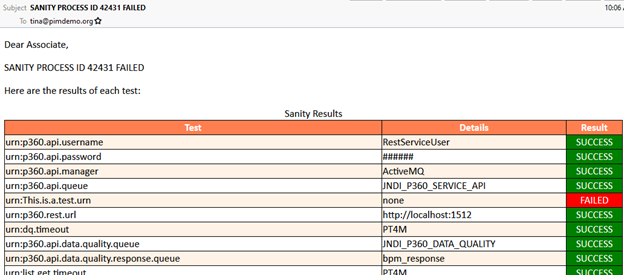
Sample Sanity Mail
Informatica Data Quality SDK update 10.5.2
The embedded data quality rule engine has been updated to the current release of Informatica Data Quality 10.5.2 bringing the latest of Informatica's leading data quality solution to Product 360. With that, an exchange of the standard rules shipped with Product 360 as well as an upgrade of custom rules to IDQ 10.5.2 is recommended.
There are some further actions required:
for new customers using Windows Server as OS, please check on "Operating system - Data Quality" section of the Step by Step installation guide how to install the latest MS VC Redistributable.
for customers doing a P360 upgrade, please refer to the section "Data Quality - Update - Data Quality SDK and Engine Update" in the Migration documentation.
GDSN Accelerator enhancements
GDSN Accelerator - Additionally supported scenarios for Product 360 Cloud Edition
Other than on-premises, only the 1WorldSync Item Management Scenario for Data Source was supported in the Cloud Edition so far. Now also the 1World Sync Recipient Scenario and the atrify Data Source scenario are supported.
|
GDSN Accelerator for Product 360 Cloud Edition |
Data Source (e.g., Manufacturing) |
Data Recipient (e.g., Retail) |
|
1WorldSync - Item Management |
already supported |
supported with 10.5 |
|
atrify - Data Sync Engine (Standard GDSN XML) |
supported with 10.5 |
not yet supported |
Data recipient scenario enhancements
For companies that act as recipients of the item management data pool and want to receive data from their trading partners (e.g., retail), several enhancements have been made
The "Confirmation Status" data model has been adjusted and the Dialog in the Desktop UI to define the feedback for the trading partner has been optimized
A pre-import step for the hotfolder distributes the received files to be imported with the respective mappings and updates status information
Processes and logs are visualized inside Product 360 now in the respective categories of the process overview
The published packaging information of received items is imported as well and allows identifying items that are the root of the packaging hierarchy - typically pallets
New reports help find and access the received information. These reports can be used to find items by many parameters, e.g., root items only, items with specific feedback, or exceptions. Reports can also be used in assortments or in dashboards.
When the feedback is being sent to the data source (e.g., the manufacturer), the status is imported back, so that it is transparent what information has been sent, or if there was an exception
The confirmation status view in the Desktop UI features a button to see historic values, e.g., "previously sent feedback"
Data source scenario enhancements
For companies that act as data sources (e.g., Consumer Packaged Goods) and want to send data to their trading partners several enhancements have been made
A post-export XSLT transformation splits the standard GDSN messages into smaller files that can be consumed by the data pool after another
A post-export XSLT transformation nests the individual items into a hierarchical structure to create standard GDSN messages that can be consumed by the data pool after another
A pre-import step for the hotfolder distributes the received files to be imported with the respective mappings, identifies and updates status information
Processes and logs are visualized inside Product 360 now in the respective categories of the process overview
The publication status view in the Desktop UI features a button to see historic values, e.g., "previously sent publications"
GDSN update to 3.1.19
We've updated our GDSN Accelerator to the GDSN version 3.1.19. There are several new fields, updated valid values lists, DQ rule configurations, new and deprecated units, as well as changes in the export templates. For an overview of all changes please view "GDSN Migration Guide for version 3.1.19" in the accelerator documentation. Please be aware that fields added additionally as part of the customer's project need to be evaluated on any impact and potentially modified as well.
Some codes of enumerations had to be deleted as they are no longer supported. Please read the section in the migration guide before updating. Changes affect the following values:
Nutrient types: Water (WATER-)
Allergen types: Methyl 2-Octynoate (MO)
Packaging material type codes: Wire
We've cleaned the unit valid value lists. Some previously maintained values may no longer be shown in the UI, however, there are database statements to find such data provided in the Migration Guide.
OpenAS2 software supported for data pool connection
For companies interested in receiving and sharing information with the GDSN, using the OpenAS2 software is now a lightweight alternative to Informatica B2B DX. OpenAS2 is focused on the single-use case to send/receive files using the AS2 protocol.
Cost savings
No database server is required, less memory is required as well as less CPU power. Using fewer resources minimizes the costs of the corresponding infrastructure. Due to the focus on its specific use case the installation and configuration efforts are lower, and startup times are quicker.
Having everything in one place - operational efficiencies
To support the GDSN choreography using OpenAS2, many functionalities have been introduced as standard Product 360 capabilities, leveraging for example the hotfolder and the import. The only part which is left to OpenAS2 is encrypting / decryption of the messages and the AS2 connection to the GDSN data pool. Having all the functionality in one place is a great advantage for any GDSN update which is made on a regular basis. You only have to update one application which lowers the efforts and costs, as well as minimizes the risk any update might contain. Finally, it is easier for any user as most of the steps including errors are now shown in Product 360 directly and it's not required anymore to check multiple applications to trace the complete process.
Supported Scenarios
Currently, 1WorldSync Item Management - Data Source, 1WorldSync Item Management - Data Recipient, and Standard GDSN - Data Source (atrify DSE) scenarios are supported.
License Details Dialog
A new information dialog presenting details of the license issued for the usage of Product 360 has been added to the Desktop UI. The dialog can be opened via the "About" section of the "Help" menu and grants an overview of license consumption in a convenient fashion.
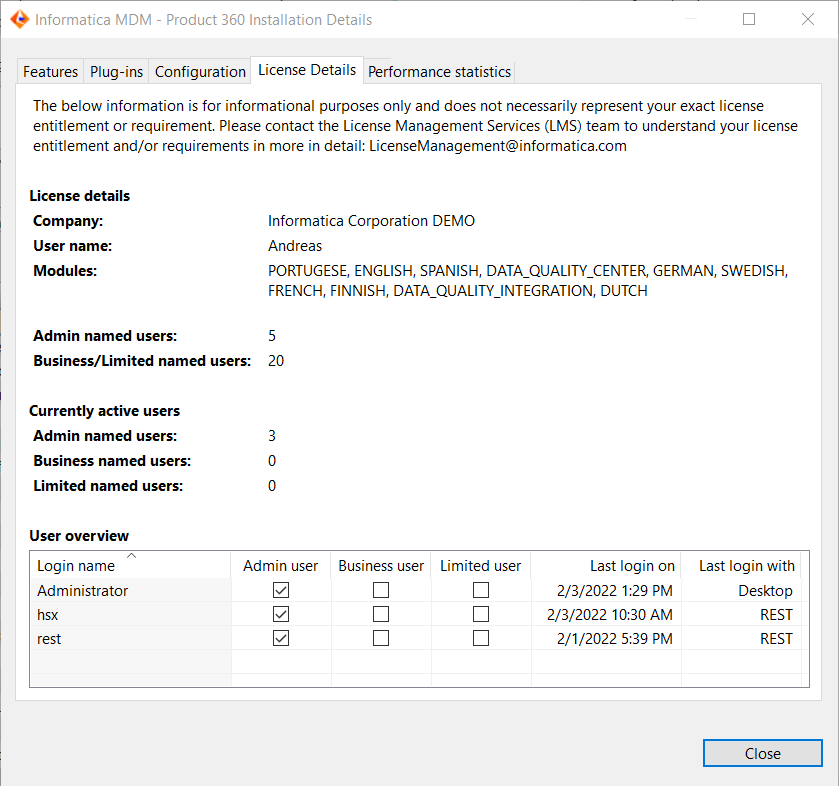
It shows the current license details including the allowed amount of named users and languages. In addition, an overview of the currently active users and how those are distributed across user types can be tracked.
The information within the dialog is meant for informational purposes only and does not necessarily represent your exact license entitlement or requirement. The user count does not include Supplier Portal or Media Manager specific user accounts.
Simplified Windows Desktop Client SSO
Whitelisting of allowed client domain used for Windows Desktop Client SSO
It is now possible to specify the user domains which are able to use the Windows Desktop Client SSO mechanism.
The whitelist gets defined via
# Whitelist of allowed domain of user to connect for SSO. Separated via semicolon.# If empty, the client machine's domain has to be the same like the server machine's domain or has to be a subdomain of the server machine's domain.com.heiler.ppm.security.server/login.sso.userDomain.whitelist =If no whitelisting is defined, the domain of the client machine will be checked against the domain of the server machine. The client machine domain has to be the same or a subdomain of the server machine domain. Once a whitelist is specified the user domain of the client machine gets validated against the whitelist. None of the server machine domains is taken into account anymore in that case. A given whitelist can address issues with client machines that are not domain enabled and where only a user domain is available.
Waffle SSO
The newly introduced Simple SSO is a lightweight single-sign-on mechanism that is available for Product 360 servers running on Windows or Linux. No 3rd party services like LDAP or SAML are required with it. The Waffle-based SSO mechanism is deprecated. Simple SSO can be used instead and will be the new default for Windows Desktop Client SSO. For details, please refer to Configuration Guide → Server Configuration → Chapter ' Windows Desktop Client SSO'.
Simple SSO requires an encrypted connection between the client and the server. See Configuration Guide → Server Configuration → Chapter 'Network Configuration (NetworkConfig.xml)' and Configuration Guide → Desktop Client Configuration → Chapter 'Server Connection Configuration' on how to comply with this setup.
Simple SSO is active by default. This can be changed via
# Specifies if the Rich Client tries to authenticate a windows user on start up using Single-Sign-On.# If set to true the Simple SSO is activated. # Simple SSO also works if P360 server runs on Linux. # TCPS communication between client and server is required for this.com.heiler.ppm.security.server/login.sso.simpleSSO = trueSecurity
Prevent automated login attempts
We have added protection against brute force login attacks which aim to gain access to user accounts by repeatedly trying to guess a username and corresponding password. A user account will be locked out for a set period of time after a number of failed login attempts to prevent automated attacks. All failed attempts of the same user on each server are counted individually, no matter from where the request is coming, e.g., from Desktop UI, web UI, or via a REST call. The count of failed attempts is automatically reset once the lock period is reached, or a login has been successful before the number of maximumFailedAttempts has been reached. The corresponding maximum allowed attempts count and lock period are configurable within the following settings in the plugin_customization.ini.
# Specifies the maximum number of failed login attempts with wrong password. If this number is reached, then the user account will be temporarily locked.# Default value is 10. com.heiler.ppm.security.server/security.preventLoginAttempts.maximumFailedAttempts = 10 # Specifies how long the user account will be temporarily locked if the maximum login attempts is reached.# Default value is 1800 seconds(= 30 minutes). com.heiler.ppm.security.server/security.preventLoginAttempts.lockPeriodInSecond = 1800HTTP response header
It is now possible to apply arbitrary numbers of HTTP response headers to the HTTP responses for all resources below the context /pim. Use the prefix web.client.headers.response. to define a response header.
# It is possible add http response headers to each http response send to the client.# This applies for all http resources below /pim context.# Use prefix 'web.client.headers.response.' to add arbitrary number of http response header.# The following sample adds the header 'Strict-Transport-Security' with value 'max-age=31536000; includeSubDomains' to each response.# web.client.headers.response.Strict-Transport-Security = max-age=31536000; includeSubDomainsAbility to disable concurrent logins
A new property has been added to the server.properties file to configure whether concurrent logins of the same user account shall be allowed in the deployed setup.
com.heiler.ppm.security.server/login.concurrentLogin.enabled = trueDelete operation executed on the server-side
The previous delete operation entailed a user to wait until it gets completed. For a large number of objects, this can result in users waiting for a long period of time before being able to continue their work on the UI. Now we are pushing the deletion operation to a server job, thereby allowing the deletion to execute asynchronously and without keeping the user waiting until completion. Once deletion has been scheduled as a job, this allows the user to either navigate to a different page or close the UI altogether and come back later.
They can check the related summary information for delete jobs in the Process Overview (under Data Maintenance) in the Desktop UI after completion and the information is retained for seven days.
The current default threshold for delete jobs has been set as 100 which is configurable within the following setting:
#Override the default preference for the deletion job threshold#If number of objects to be deleted are greater or equal than this threshold number then a server job would be scheduled for deletion# ---------------------------------------------------------------------------com.heiler.ppm.delete.core/entity.deletion.threshold=100It is also possible to set the delete job threshold parameter at an entity level by creating an Entity Param (entity.delete.jobThreshold) in the repository and specifying a non-zero value. The current thresholds for Supplier Catalog and Structure Group have been set to 1 and 10 respectively.
Audit Trail
Legacy Audit Trail migration (upgrading from a release prior to Product 360 10.1)
This chapter is not applicable if you are using the new Audit Trail introduced with the release of version 10.1 already.
Legacy audit trail database migration preparation
We have provided MSSQL and Oracle database scripts for the legacy audit trail database/schema to speed up the migration by removing unnecessary indexes and creating new optimized indexes. Scripts are available in the configuration folder of the audit trail migration: \
server\configuration\HPM\audittrail\migration\dbPreparationScripts
The corresponding script has to be executed on the legacy audit trail database/schema before migration can be started. Please note that this can take a few hours, depending on the database size.
Configuration
Repository
Please ensure the repository has all needed Audit Trail configurations in place. This is important because only data for Audit Trail enabled root entities will be migrated, and all other data will be skipped.
The entities in the 10.1 and 10.5 repository enabled for Audit Trail do not exactly match those in previous versions. Please check all settings and adapt them to your needs.
In addition to the root entity Audit Trail settings, the "Supports Audit Trail" setting for repository fields will be checked. Only Audit Trail enabled fields and logical keys will be migrated.
audittrail.migration.server.properties
Access to the legacy Audit Trail database should be configured in <PIM_SERVER_INSTALLATION_ROOT>\configuration\HPM\audittrail\migration\audittrail.migration.server.properties.
This file can be created from a corresponding template. The essential settings here are the host and schema configuration. You can take the settings from the old configuration for Audit Trail.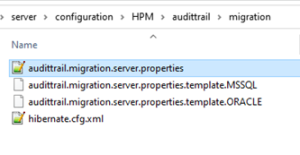
### General Hostdest.host = host ### Default database settingsdb.default.type = MSSQL ... ### AuditTrail database/schemadb.audittrail.schema = HPM_AUDITTRAILdb.audittrail.schema.backup = ${db.audittrail.schema}_BAKdb.audittrail.server = ${dest.host}db.audittrail.port = 1433db.audittrail.user = userdb.audittrail.password = passwordplugin_customization.ini
In order to use the migration, you have to configure the time period for which you want to migrate changes, in the <PIM_SERVER_INSTALLATION_ROOT>\configuration\HPM\plugin_customization.ini
# ---------------------------------------------------------------------------# Audit Trail migration preferences# ---------------------------------------------------------------------------## Audit trail migration starts from today or from the specified 'migrationFromDate' and runs back# to the specified 'migrationToDate' into the past.### 'migrationToDate' 'migrationFromDate' now# e.g. 2020-01-01 e.g. 2021-04-02# | | |# ----------+-------------------------------------------------------+-------------+------> time# # Initial start date of the migration means that all old audit trail entries between 'migrationToDate' and# this 'migrationFromDate' will be transformed to the new audit trail format and stored in elastic.# This value is optional.# Date is included.# Format: yyyy-MM-dd# com.heiler.ppm.audittrail.migration.server/migrationFromDate = # All old audit trail entries between today or a defined 'migrationFromDate' and this specified 'migrationToDate' will be transformed# to the new audit trail format and stored in elastic.# This value is mandatory.# Date is included.# Format: yyyy-MM-dd# com.heiler.ppm.audittrail.migration.server/migrationToDate = # Locale to be used for the Audit Trail migration job.# This should be the same value as it was for the "audittrail.atcsbuilder.locale" property# in the audittrail.properties file of older versions.# Default is en_US.# com.heiler.ppm.audittrail.migration.server/locale=en_US # Fetchsize of retrieving migration data from the legacy Audit Trail database.# This value should be between 1 and the maximum database-specific possible fetchsize# defined in property 'db.default.rowPrefetchSize' (10000).# In case of some memory issues during the migration, this value should be decreased.# com.heiler.ppm.audittrail.migration.server/migration.fetch.size = 10000 # Number of threads for retrieving migration data from the legacy Audit Trail database.# Usually all CPU threads are used for the migration. In case of working with PIM and migrate from the legacy# Audit Trail database it is worth to decreased the number of maximum thread to work fluid with PIM.# This value is optional.# Minimum value is 1, maximum value is number of CPU cores.migration.maxThreads =The 'migrationToDate' is the end date of the migration. All changes between the given 'migrationToDate' and the given 'migrationFromDate' (or today if 'migrationFromDate' is not set) are migrated to Elasticsearch. The 'migrationToDate' value is mandatory. The 'migrationFromDate' is optional. When the 'migrationFromDate' is not set, then today will be used as 'migrationFromDate'.
The locale is needed to resolve labels of the objects to be migrated. When the data was written, the locale configured for the attribute audittrail.atcsbuilder.locale in the audittrail.properties file was used. The same value should be used for the data migration. Audit Trail migration uses all CPU cores by default. If the server should run in parallel to the Audit Trail migration, the number of used CPU cores for the Audit Trail migration should be decreased. This can be done by setting the property migration.maxThreads to a value between 1 and the number of CPU cores.
Rights
There is a new action right the user must have in order to execute the migration: "Audit Trail, migration" - "Permission to start audit trail migration job". Other rights are not considered in the migration process.
Start Migration
In order to start the migration, start the Desktop UI and open the Management menu. You will find a new entry at the bottom "Start audit trail migration". If the entry is missing, the user probably does not have the corresponding action right to perform the migration. Only one migration job can run at a time, so if the menu entry is disabled, a job instance might already be running.
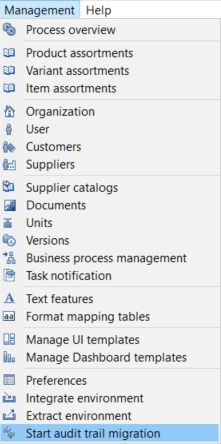
You can find the executed server job in the process overview perspective under System processes. The problem log of the job will show the progress as well as possible errors.
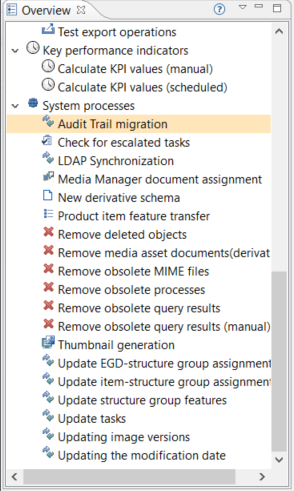
The number of migrated changes is logged for every processed day. This includes also the number of errors or skipped changes. A change will be skipped if it could not be migrated, details will also be logged, or if its entity is not configured to support Audit Trail.
After migration
After the migration, you can revoke the migration right from your users. It is not needed to start the audit trail server and the old audit trail database is not used anymore. If you didn't migrate all data and you are not sure if you might need the data again sometime, think about keeping a backup from the database.
FAQ and Troubleshooting
Please see the FAQ and Troubleshooting sections of the Audit Trail Migration in the Migration Guide for further guidance on the process.
Audit Trail entity item change document
Entity item change documents will not have a change type of CHANGED_CHILD anymore at the top level, only CREATED, CHANGED and DELETED are used. The change summary is not affected, it will still use CREATED, CHANGED, CHANGED_CHILD and DELETED for the records contained.
Improved performance
We have further optimized the Audit Trail data insertions specifically for simple imports with a smaller number of columns. The time taken by import with and without Audit Trail is almost similar now in such scenarios.
Improved stability
The Audit Trail data is stored in Elasticsearch and in order to have Product 360 operate in a stable way even if the Elasticsearch connection might be temporarily unavailable, a buffer table is introduced, and Audit Trail data is buffered on these tables before sending to Elasticsearch.
Audit trail backup job for automated archival of audit-enabled entities
While Elasticsearch maintains the A udit Trail data, the audit data gets deleted as per the time configured in the lifecycle policies, which could lead to the deletion of important historical data over time. A new automated job named 'Audit trail backup' has been introduced to cope with this problem and administrators can now choose to enable this job, by setting the relevant property to true and specifying the folder location for archive file creation. Users can also configure a schedule for the archival process to take place at required intervals. Audit Trail archival is not enabled by default. Once the scheduled job is initiated, users can overview the process on the Desktop UI in the Process Overview.
For more information, refer to the server configuration and view the latest updates made in the plugin_customization.ini file
Import
Sub entity deletion on import now supports error mode 'Tolerant'
It is now possible to use the existing "sub entity deletion on import" feature which makes it possible to replace existing data in the system with the content of an import file, in combination with the error mode 'Tolerant'. In the past, only the 'Restrictive' mode was supported, which rejected the row on detection of any error in the data. Tolerant enables to import as much data as possible, even if some cannot be imported due to invalid values. It is required to enable the 'Tolerant' mode for sub entity deletion in the server's plugin_customization.ini.
# Allows using error mode 'Tolerant' in case an import mapping has a sub entity deletion configuration defined.# Not enabling the error mode 'Tolerant' prevents possible unintentional deletion of data.# The error mode 'Tolerant', if enabled here, will delete sub entities if there is no properly qualified import data for a respective sub entity which is marked for deletion.# Boolean value, default is falsecom.heiler.ppm.importer5.core/importer.subEntityDeletion.allowTolerantMode = trueSub entity deletion on import for prices
If prices are maintained in a different source system, it is often required to replace existing data that is already available in Product 360. The sub entity deletion logic for prices is now supporting the logical key "Time of validity". The behavior is as follows: all existing prices having a valid-from-to-range, which includes the configured "Time of validity" of the sub entity deletion configuration, are deleted on import.
For example:
have a selling price with validity from 1/1/2021 to 6/30/2021 and a second one with validity from 7/1/2021 to 12/31/2021
have an import mapping with sub entity deletion configured for "selling price" and configure a qualification for "time of validity", e.g., 3/28/2021
import a Selling Price for the same item with validity from 3/1/2021 to 4/30/2021
Result:
the first existing price (with validity from 1/1/2021 to 6/30/2021) is deleted since it is matching the configured qualification of "time of validity" = 3/28/2021
the new selling price with validity from 3/1/2021 to 4/30/2021 is imported.
Clean up for the purposes of import mappings
Multiple purposes for import mappings are not possible as per design. However, due to some issues in the past, it might have happened that import mappings contained multiple different or same purposes in the database. This should not be the case any longer.
For detailed documentation, please refer to the section 'Multiple Purposes for Import Mappings in the GenericData Table' in the P360 Core Database Migration article in the Database Migration guide.
Export and Web Search
Data source "All supplier catalogs"
All export data sources that provide a "Supplier catalogs" parameter have been extended with a new parameter "Use all supplier catalogs".
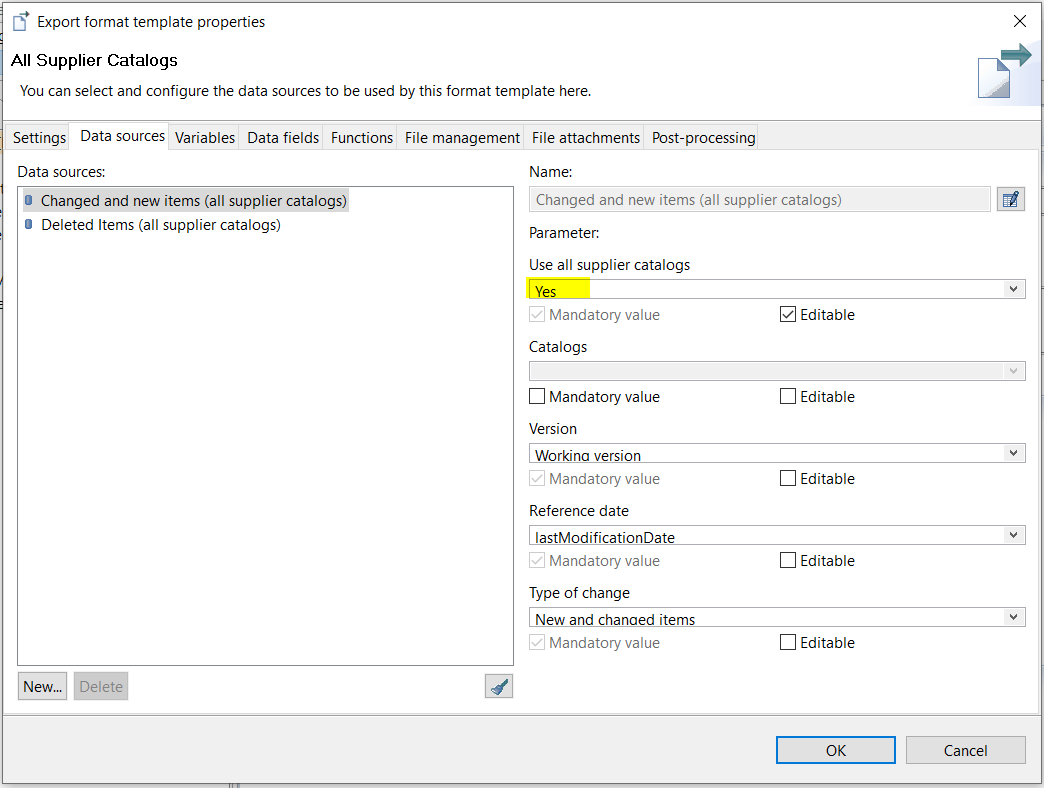
With this new functionality, it is no longer needed to manually add each newly created supplier catalog to the list of selected catalogs within an existing export template. Instead, every new supplier catalog will be included automatically in your scheduled exports or search index update jobs. Note that this is a complementary addition, and the data source can still be used as before. All existing export templates and scheduled export jobs will remain valid and not change their behavior implicitly.
User restriction for post export step file uploads
The ability to upload any file as part of a post export step can now be restricted to a limited set of users. The manage files dialog will show a corresponding message in its header area and the select and upload buttons are disabled if the user wouldn't have sufficient rights.
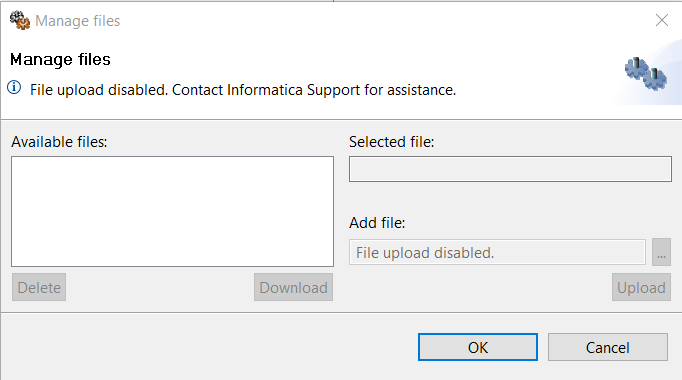
To disable the file upload, adjust the plugin_customization.ini file on the application server.
# ---------------------------------------------------------------------------# Export Server Settings# ---------------------------------------------------------------------------# Disables the PostExport File Upload for all users except those which have the same login name as one# of the users in this preference# e.g. fileUploadRestrictedExceptFor = Administrator (only the Administrator user can upload files)# e.g. fileUploadRestrictedExceptFor = tom,jenny (only tom and jenny can upload files)# e.g. fileUploadRestrictedExceptFor = (everyone can upload files, this is the same as if the preference is commented)# e.g. fileUploadRestrictedExceptFor = NonexistingUser (no one can upload files, not even the Administrator)# com.heiler.ppm.export.server/fileUploadRestrictedExceptFor = AdministratorService API
Object API Read
A new multi-object endpoint to request multiple objects with one single call has been introduced. This endpoint uses the POST command. Internal thread pools and queues make sure to not overload the server with too many and too large requests.
In addition, a new parameter: includeLabels has been added. If set to true (default = false) the label for enumeration values will be returned additionally to the key and code. Also, for Characteristic values the label will be returned then in case the value is a lookup value.
A Postman collection has been added to provide examples for the REST Object API Read. It's included as a page attachment of the HTML-based technical documentation shipped with this release.
Object API Write
A version 2 of the Object API has been introduced which supports now also write operations. This will allow extending the use case of the object API from only consuming system integrations to writing back updates to a record in a similar fashion as you would read the data from Product 360. In order to streamline the usability of the API, also the payload of the READ requests has been adjusted and is not compatible with V1 payloads any longer. Please find all details of the new Object API version in the Service API Documentation.
List API
REST List API Read for Sub Entities: A new fieldFilter parameter has been introduced. Similar to the qualificationFilter parameter it allows to filter sub-entity records for field values. A Postman collection has been added to provide examples for the REST List API. It's included as a page attachment of the HTML-based technical documentation shipped with this release.
Meta API
The Meta API for entities has been adjusted to always include the identifier and shortIdentifier for Entities, Fields, and Qualifications from now on. Additionally, supportsListApi and supportsObjectApi is now part of the Entity and Field objects. Here is an example of the HTML output:
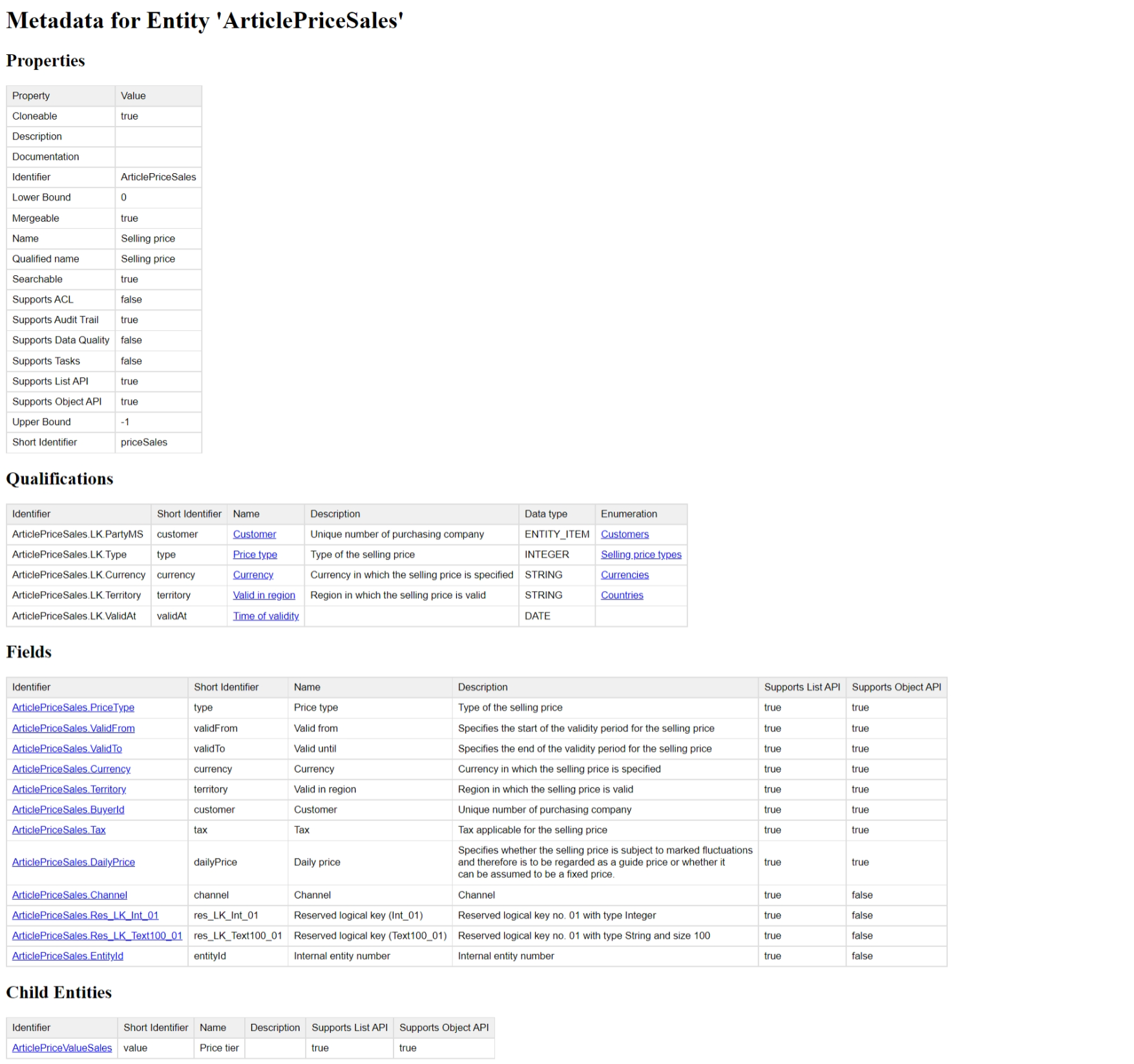
For technical integrations, we strongly recommend not using the HTML output but the JSON or XML which can be fetched by providing application/json or application/xml as accept header.
Here is an example of a field definition in JSON:
{ "averageLength": "0", "category": "Ordering information", "clonable": "true", "dataType": "ENTITY_ITEM", "description": "Unit for the item within an order unit\r\n\r\nExample: Case of mineral water with 6 bottles, \r\nContent unit: Bottle", "editable": "true", "enumeration": { "name": "Order units", "identifier": "Enum.OrderUnits" }, "identifier": "Article.ContentUnit", "lowerBound": "0", "maxLength": "0", "mergeable": "true", "minLength": "0", "multiline": "false", "name": "Content unit", "pictureClause": "", "qualifiedName": "Content unit", "richtext": "false", "scale": "0", "searchable": "true", "supportsDQ": "true", "upperBound": "1", "value": "", "visible": "true", "shortIdentifier": "contentUnit", "supportsListApi": "true", "supportsObjectApi": "true"}Repository Manager
Validation
We have introduced a new repository validation to ensure that there is at most one field assigned to a field type per entity. In other words, it is not allowed to use the same field type more than once within an entity. If the validation fails, it will be reported as an error in the repository manager. Note that the Product 360 server will still start but an exception is logged if a repository with such a wrong field configuration is used.
Performance
Status cache
The memory consumption of the status cache has been improved by up to 50% - depending on the number of data quality results per item. The more DQ statuses attached to a record, the larger the saving.
Multiple load strategies have been implemented which are used in combination to provide the fastest startup time of the cluster. If a server is started, it first will check if it can load the status cache from the local persistence storage. If not, it will check if there are other servers in the cluster already started, and if so, it will load the status cache from them. Only in case the server is the first one or the network load is disabled, the server would have to load the status entries from the database. This logic ensures that the resources on the database are used with care and the most performant way to load the cache content is used at all times.
Load from database
The status cache initialization will now use multiple threads to load the data quality results from the database. The way to store the data quality results in the database has been enhanced for faster load performance as well. Please note that this will require additional space in the MAIN schema and the very first server start will take some time to optimize the persisted data. Please factor this in when upgrading larger deployments.
New preferences have been added which control the database load:
# Status cache initialization will utilize multiple threads once the threshold has been reached.# Default: 200000com.heiler.ppm.status.server/statusCache.parallelTreshold = 200000 # The maximum amount of concurrent threads to query the database.# Default: empty (using "number of DB CPU cores" configured in server.properties)com.heiler.ppm.status.server/statusCache.parallelDegree =Load over network
In multi-server scenarios, we additionally provide the load of the status cache from already running servers. So, in a multi-server scenario, all but the first server will load the cache from another server. This improves the startup time even further and reduces the overall load on the database during cluster startup (as only one server needs to access the persisted data there). This is especially useful in deployment scenarios in which the IOPS of the database are limited.
# Allows the status cache initialization over network.# Default: truecom.heiler.ppm.status.server/statusCache.networkEnabled = true # The amount of status cache elements contained in every network request.# Default: 500000com.heiler.ppm.status.server/statusCache.networkBatchSize = 500000 # The maximum amount of parallel threads to transfer the status cache over the network.# While there can be only one active socket at a time, the other threads will be preparing their payload.# In case there are less CPU cores available, all CPU cores except one will be utilized.# Default: 4com.heiler.ppm.status.server/statusCache.networkParallelDegree = 4Load from local storage
In case a server is orderly shutdown, it will also store the status cache on the local disk to improve the startup time for the next startup. A corresponding check file will be saved to recognize if the server has been orderly shutdown. The shutdown of the server takes a few minutes extra time now to persist the cache locally depending on the size of the cache.
# Allows the status cache initialization from local storage.# Default: truecom.heiler.ppm.status.server/statusCache.localStorageEnabled = true # The local file path of the status cache snapshot# Default: empty (using workspace)com.heiler.ppm.status.server/statusCache.localStoragePath = # The maximum amount of parallel threads to read the status cache from the local storage.# This process is I/O bound, i.e. increasing parallel degree could lead to worse performance.# In case there are less CPU cores available, all CPU cores except one will be utilized.# Default: 4com.heiler.ppm.status.server/statusCache.localStorageParallelDegree = 4Proxy cache
The initial preload of the proxy cache has been improved by up to 30% for all ArticleType based entities as MASTER and SUPPLIER schemas are now loaded concurrently. With that, we expect an improvement in memory consumption by up to 20%.
Product 360 Core
Server
Check for short identifiers
With the redesign of the Audit Trail in the release of 10.1 we introduced "short identifiers". By now, these are not only used by the Audit Trail component, but also by the Object API and the event triggers. Therefore, we ensure on server start that all entities, fields, and logical keys have valid short identifiers. More information about short identifiers can be found in Installation and Operation → Customizing → Server and Platform → Domain Model (Repository)
From now on, your server won't start if short identifiers are missing in your repository setup.
Priority job server
Some jobs are more important than others, some jobs should be executed on a dedicated server. To be able to support those use cases we introduced the new priority job server feature. A new role for servers has been introduced: PRIORITY_JOB_SERVER. This role can be added to the NetworkConfiguration.xml file. Additionally, a new preference has been added:
# Comma separated list of job type identifiers which should be executed on the priority job server in case one is availablecom.heiler.ppm.job.server/prioritizedJobs =Only job types that are declared as "priority jobs" using this preference will be routed to the priority job servers (as long as the current network has at least one priority job server). If there is no priority server currently running, the job will be executed like any other job. The list of available job types can be found in the Configuration Manual's Server Job Types section. Please note that this priority logic is only available with the out-of-the-box resource-based (default) or round-robin distribution logic. If there are multiple priority servers, the jobs will be distributed among those. A server node can be PRIORITY_JOB_SERVER as well as JOB_SERVER in which case, priority jobs will only be forwarded to this server, but normal jobs might be assigned to this server as well, based on the distribution algorithm.
Improved execution time and cache synchronization in multi-server setups
With the introduction of improvements in the server notification time, we are happy to announce the removal of the delivery delay for message queue messages. With that, we have also removed the property queue.default.delivery.delay in server.properties introduced with the release of Product 360 10.0, which results in a much faster execution experience of single message queue calls in multi-server deployments. In case the property has been modified in your deployment, we strongly recommend removing it to benefit from the new performance.
SDK Samples
Characteristic data provider export example
The SDK has been extended with an example for exporting characteristics that are available but not yet filled for items. Details can be found in the corresponding plugin com.heiler.ppm.customizing.export.core.